Inhoudsopgave[Zich verstoppen][Laten zien]
De deep learning-technieken die bekend staan als "graph neural networks" (GNN's) werken in het grafdomein. Deze netwerken zijn de laatste tijd gebruikt op verschillende gebieden, waaronder computervisie, aanbevelingssystemen en combinatorische optimalisatie, om er maar een paar te noemen.
Bovendien kunnen deze netwerken worden gebruikt om complexe systemen weer te geven, waaronder sociale netwerken, eiwit-eiwitinteractienetwerken, kennisgrafieken en andere in verschillende vakgebieden.
De niet-euclidische ruimte is waar grafiekgegevens werken, in tegenstelling tot andere soorten gegevens zoals afbeeldingen. Om knooppunten te classificeren, koppelingen en clustergegevens te voorspellen, wordt grafiekanalyse gebruikt.
In dit artikel bekijken we de grafiek Neural Network in detail, zijn typen, evenals praktische voorbeelden met PyTorch.
Dus, wat is Grafiek?
Een grafiek is een type gegevensstructuur die bestaat uit knooppunten en hoekpunten. De verbindingen tussen de verschillende knooppunten worden bepaald door de hoekpunten. Als de richting wordt aangegeven in de knooppunten, wordt gezegd dat de grafiek gericht is; anders is het ongericht.
Een goede toepassing van grafieken is het modelleren van de relaties tussen verschillende individuen in een sociaal netwerk. Bij complexe omstandigheden, zoals koppelingen en uitwisselingen, zijn grafieken erg handig.
Ze worden gebruikt door aanbevelingssystemen, semantische analyse, sociale netwerkanalyse en patroonherkenning
. Het creëren van op grafieken gebaseerde oplossingen is een gloednieuw veld dat een inzichtelijk begrip biedt van complexe en onderling gerelateerde gegevens.
Grafiek neuraal netwerk
Graph neurale netwerken zijn gespecialiseerde neurale netwerktypes die kunnen werken op een grafiekgegevensformaat. Inbedding van grafieken en convolutionele neurale netwerken (CNN's) hebben een aanzienlijke impact op hen.
Graph Neural Networks worden gebruikt bij taken die het voorspellen van knooppunten, randen en grafieken omvatten.
- CNN's worden gebruikt om afbeeldingen te classificeren. Evenzo, om een klasse te voorspellen, worden GNN's toegepast op het pixelraster dat de grafiekstructuur vertegenwoordigt.
- Tekstcategorisatie met behulp van neurale netwerken met herhalingen. GNN's worden ook gebruikt bij grafiekarchitecturen waarbij elk woord in een zin een knooppunt is.
Om knooppunten, randen of volledige grafieken te voorspellen, worden neurale netwerken gebruikt om GNN's te maken. Een voorspelling op knooppuntniveau kan bijvoorbeeld een probleem als spamdetectie oplossen.
Linkvoorspelling is een typisch geval in aanbevelingssystemen en kan een voorbeeld zijn van een edge-wise voorspellingsprobleem.
Grafiek Neurale netwerktypes
Er bestaan vele soorten neurale netwerken en in de meeste daarvan zijn convolutionele neurale netwerken aanwezig. We zullen in dit deel meer te weten komen over de meest bekende GNN's.
Grafiek Convolutionele Netwerken (GCN's)
Ze zijn vergelijkbaar met klassieke CNN's. Het verwerft kenmerken door naar nabijgelegen knooppunten te kijken. De activeringsfunctie wordt door GNN's gebruikt om niet-lineariteit toe te voegen na het aggregeren van knooppuntvectoren en het verzenden van de uitvoer naar de dichte laag.
Het bestaat in wezen uit Graph-convolutie, een lineaire laag en een activeringsfunctie voor niet-leerlingen. GCN's zijn er in twee hoofdvarianten: spectrale convolutionele netwerken en ruimtelijke convolutionele netwerken.
Grafieken van Auto-Encoder-netwerken
Het gebruikt een encoder om te leren grafieken weer te geven en een decoder om te proberen invoergrafieken te reconstrueren. Er is een bottleneck-laag die de encoder en decoder verbindt.
Omdat auto-encoders uitstekend de klassenbalans afhandelen, worden ze vaak gebruikt bij het voorspellen van links.
Terugkerende Graph Neural Networks (RGNN's)
In multi-relationele netwerken, waar een enkel knooppunt talrijke relaties heeft, leert het het optimale diffusiepatroon en kan het de grafieken beheren. Om de soepelheid te vergroten en overparameterisatie te verminderen, worden regularizers gebruikt in deze vorm van graaf-neuraal netwerk.
Om betere resultaten te krijgen, hebben RGNN's minder verwerkingskracht nodig. Ze worden gebruikt voor het genereren van tekst, spraakherkenning, machinevertaling, beeldbeschrijving, video-tagging en tekstsamenvatting.
Gated Neural Graph Networks (GGNN's)
Als het gaat om afhankelijke taken op de lange termijn, presteren ze beter dan RGNN's. Door node-, edge- en temporele poorten op lange termijn afhankelijkheden op te nemen, verbeteren gated neurale graafnetwerken terugkerende neurale graafnetwerken.
De poorten werken op dezelfde manier als Gated Recurrent Units (GRU's), omdat ze worden gebruikt om gegevens in verschillende fasen op te roepen en te vergeten.
Graph Neural Network implementeren met Pytorch
Het specifieke probleem waar we ons op zullen concentreren, is een veelvoorkomend probleem met het categoriseren van knooppunten. We hebben een groot sociaal netwerk genaamd musae-github, die is samengesteld vanuit de open API, voor GitHub-ontwikkelaars.
Edges tonen de wederzijdse volgerrelaties tussen de knooppunten, die ontwikkelaars (platformgebruikers) vertegenwoordigen die in ten minste 10 repositories hebben gespeeld (merk op dat het woord wederzijds een ongerichte relatie aangeeft).
Op basis van de locatie van het knooppunt, opslagplaatsen met ster, werkgever en e-mailadres worden knooppuntkenmerken opgehaald. Voorspellen of een GitHub-gebruiker een webontwikkelaar is of een machine learning ontwikkelaar is onze taak.
De functietitel van elke gebruiker diende als basis voor deze targetingfunctie.
PyTorch installeren
Om te beginnen, moeten we eerst installeren: PyTorch. U kunt het configureren volgens uw machine vanaf: hier. Hier is de mijne:
Modules importeren
Nu importeren we de benodigde modules
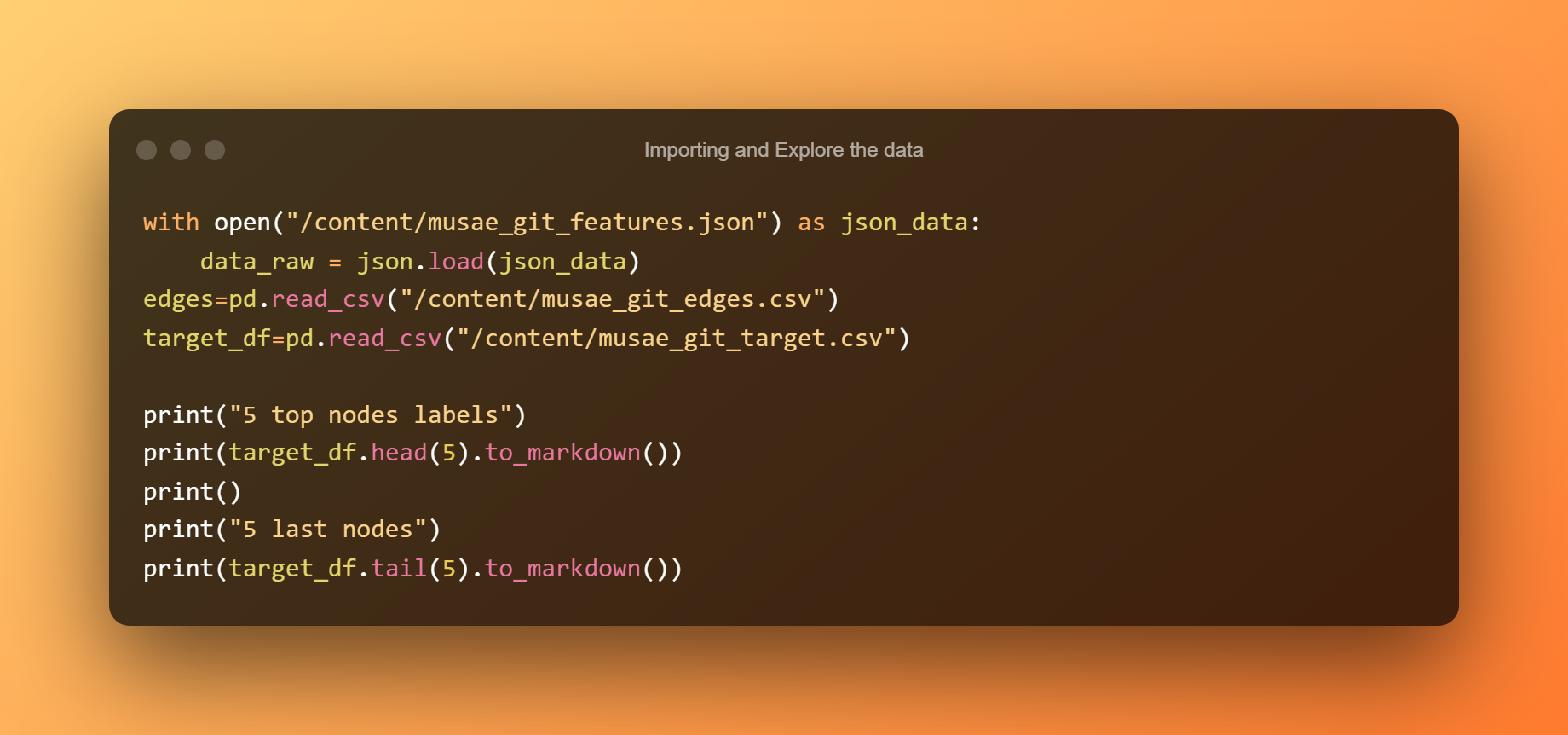
De gegevens importeren en verkennen
De volgende stap is om de gegevens te lezen en de eerste vijf rijen en de laatste vijf rijen uit het labelbestand te plotten.
Slechts twee van de vier kolommen - de id van het knooppunt (dwz gebruiker) en ml_target, wat 1 is als de gebruiker lid is van de machine learning-gemeenschap en 0 anders - zijn voor ons relevant in deze situatie.
Aangezien er slechts twee klassen zijn, kunnen we er nu zeker van zijn dat onze taak een kwestie van binaire classificatie is.

Als gevolg van aanzienlijke klassenonevenwichtigheden kan de classifier gewoon aannemen welke klasse de meerderheid is in plaats van de ondervertegenwoordigde klasse te evalueren, waardoor klassenbalans een andere cruciale factor wordt om te overwegen.
Het plotten van het histogram (frequentieverdeling) onthult enige onbalans omdat er minder klassen uit machine learning zijn (label=1) dan uit de andere klassen.


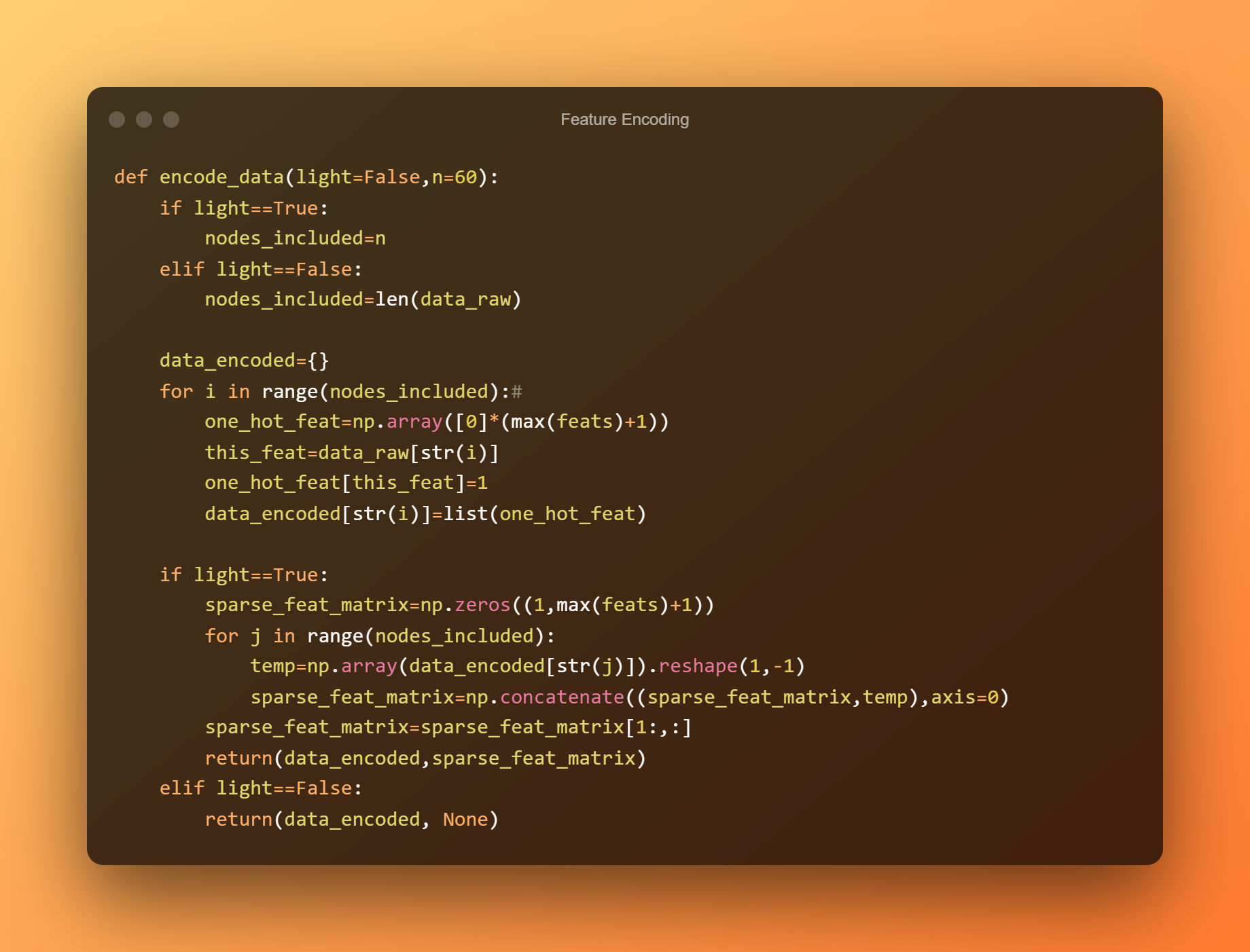
Functiecodering
De kenmerken van de knooppunten informeren ons over de functie die aan elk knooppunt is gekoppeld. Door onze methode te implementeren om gegevens te coderen, kunnen we die kenmerken onmiddellijk coderen.
We willen deze methode gebruiken om een klein deel van het netwerk (bijvoorbeeld 60 nodes) in te kapselen voor weergave. De code staat hier vermeld.
Grafieken ontwerpen en weergeven
We zullen toorts geometrische gebruiken. gegevens om onze grafiek te bouwen.
Om een enkele grafiek met verschillende (optionele) eigenschappen te modelleren, worden gegevens gebruikt die een eenvoudig Python-object zijn. Door deze klasse en de volgende attributen te gebruiken - die allemaal toortstensoren zijn - zullen we ons grafiekobject maken.
De vorm van de waarde x, die wordt toegekend aan de gecodeerde knooppuntkenmerken, is [aantal knooppunten, aantal kenmerken].
De vorm van y is [aantal knooppunten] en wordt toegepast op de knooppuntlabels.
randindex: om een ongerichte graaf te beschrijven, moeten we de oorspronkelijke randindices uitbreiden om het bestaan van twee verschillende gerichte randen mogelijk te maken die dezelfde twee knooppunten verbinden maar in tegengestelde richtingen wijzen.
Een paar randen, de ene wijzend van knooppunt 100 naar 200 en de andere van 200 naar 100, is vereist, bijvoorbeeld tussen knooppunten 100 en 200. Als de randindices worden gegeven, dan is dit hoe de ongerichte grafiek kan worden weergegeven. [2,2*aantal originele randen] is de tensorvorm.
We maken onze tekengrafiekmethode om een grafiek weer te geven. De eerste stap is om ons homogene netwerk om te zetten in een NetworkX-grafiek, die vervolgens kan worden getekend met NetworkX.draw.
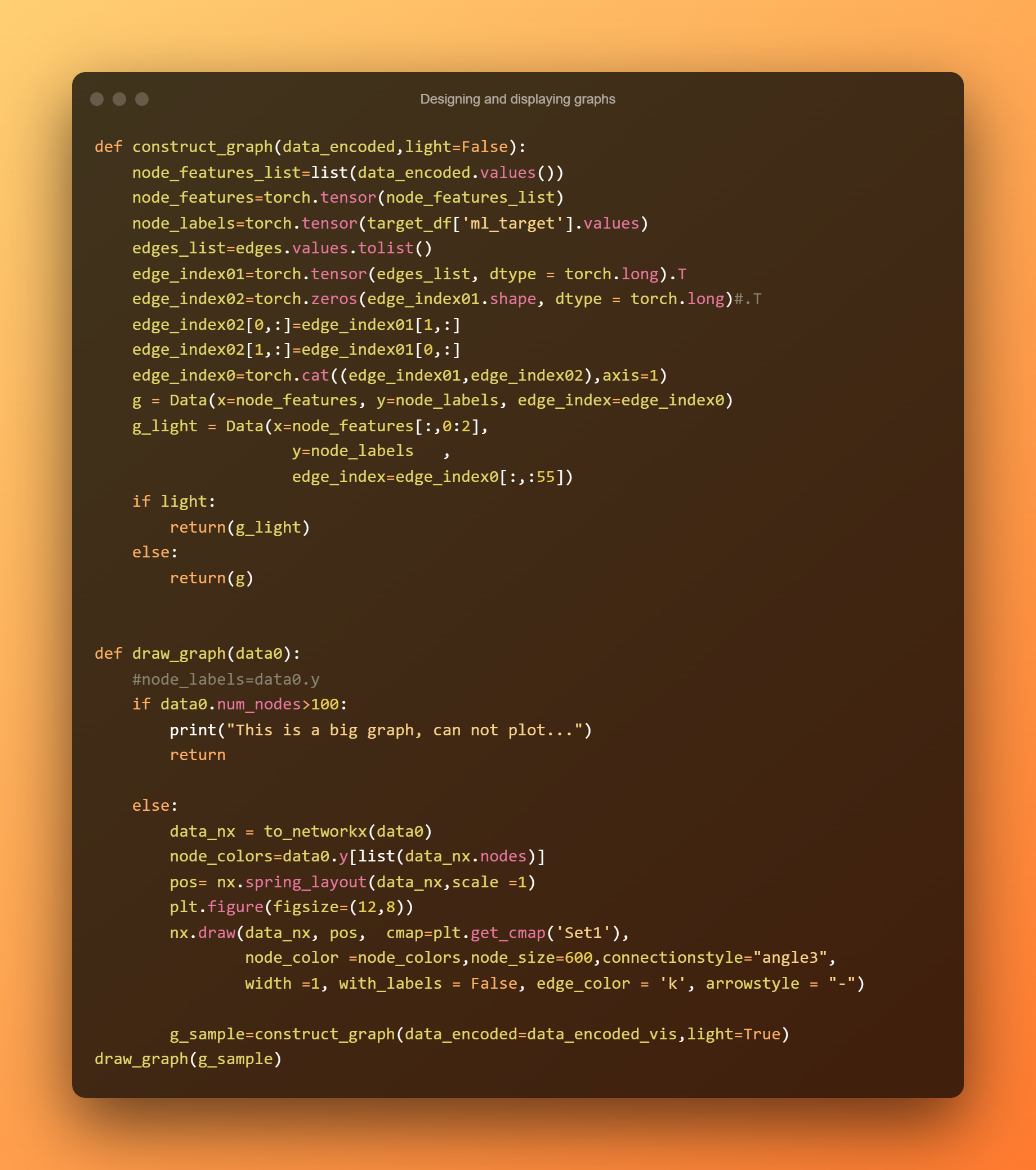
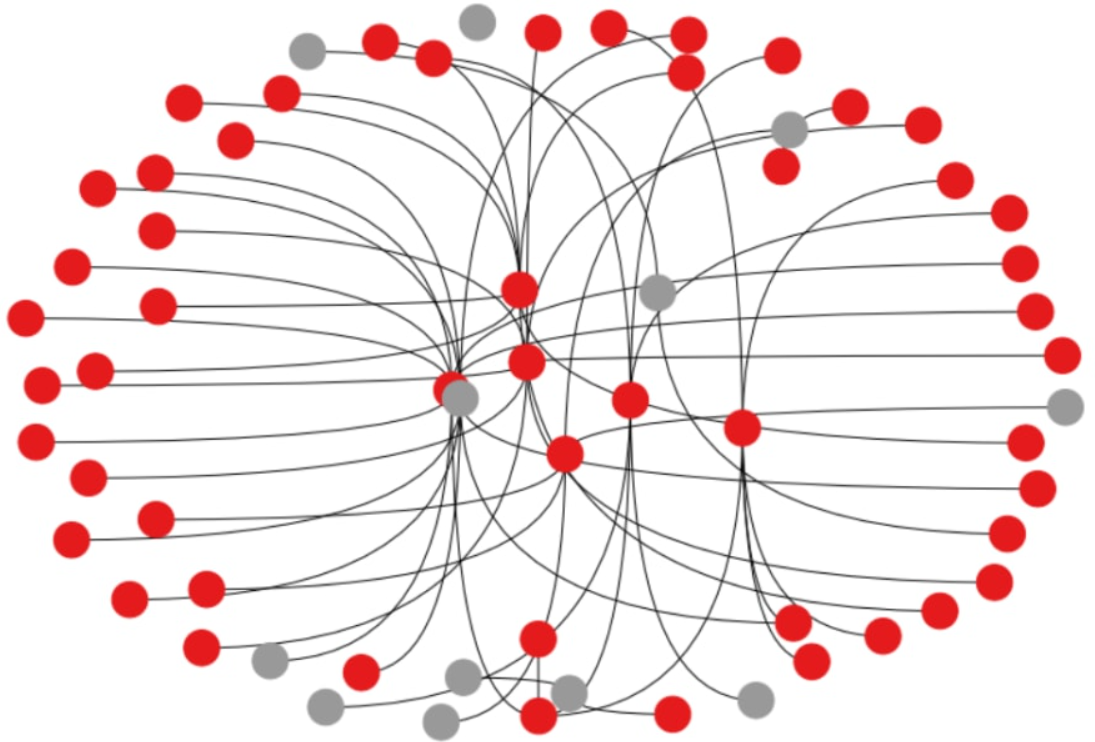
Maak ons GNN-model en train het
We beginnen met het coderen van de hele set gegevens door coderingsgegevens uit te voeren met light=False en vervolgens construct graph aan te roepen met light=False om de hele grafiek te bouwen. We zullen niet proberen deze grote grafiek te tekenen, omdat ik aanneem dat u een lokale machine gebruikt met beperkte middelen.

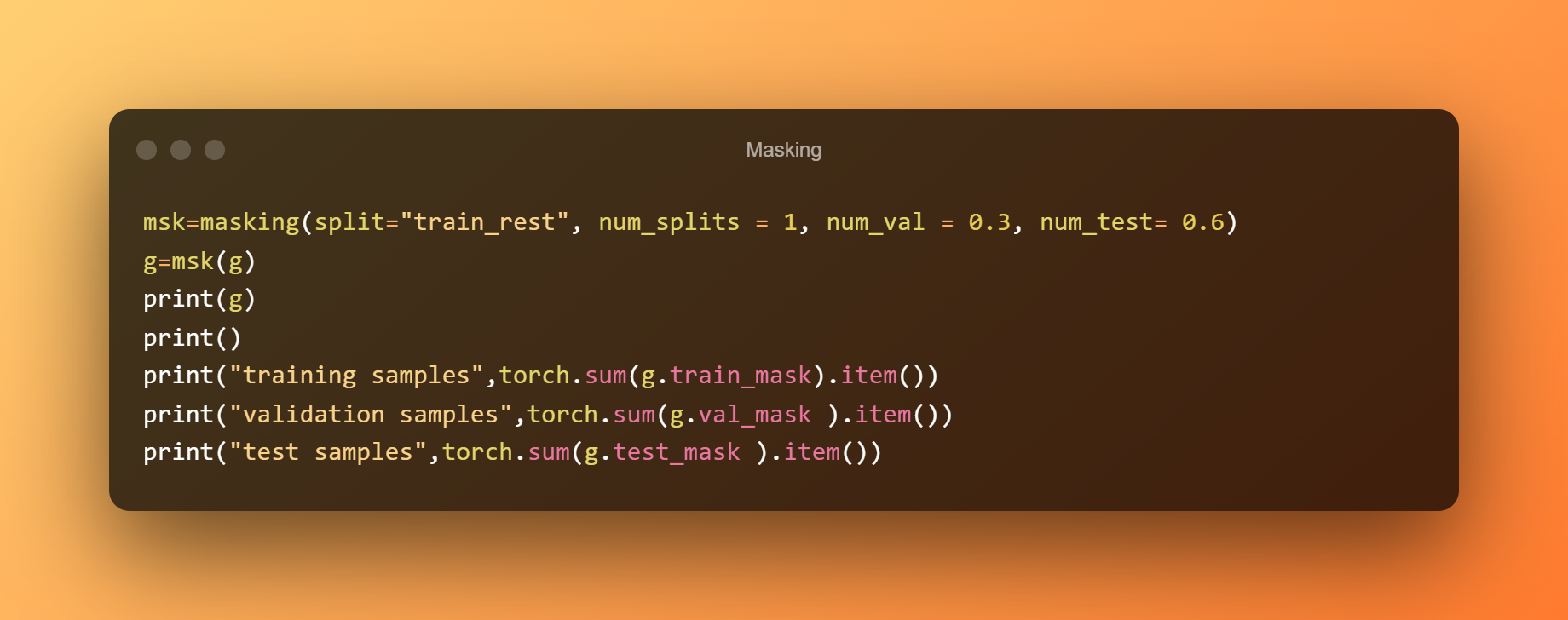
Maskers, dit zijn binaire vectoren die identificeren welke knooppunten bij elk specifiek masker horen met behulp van de cijfers 0 en 1, kunnen worden gebruikt om de trainingsfase te melden welke knooppunten tijdens de training moeten worden opgenomen en om de inferentiefase te vertellen welke knooppunten de testgegevens zijn. Fakkel geometrische.transformeert.
Een splitsing op knooppuntniveau kan worden toegevoegd met behulp van de trainingsmasker-, valmasker- en testmaskereigenschappen van de AddTrainValTestMask-klasse, die kan worden gebruikt om een grafiek te maken en ons in staat te stellen te specificeren hoe we willen dat onze maskers worden geconstrueerd.
We gebruiken slechts 10% voor training en gebruiken 60% van de gegevens als testset terwijl we 30% gebruiken als validatieset.
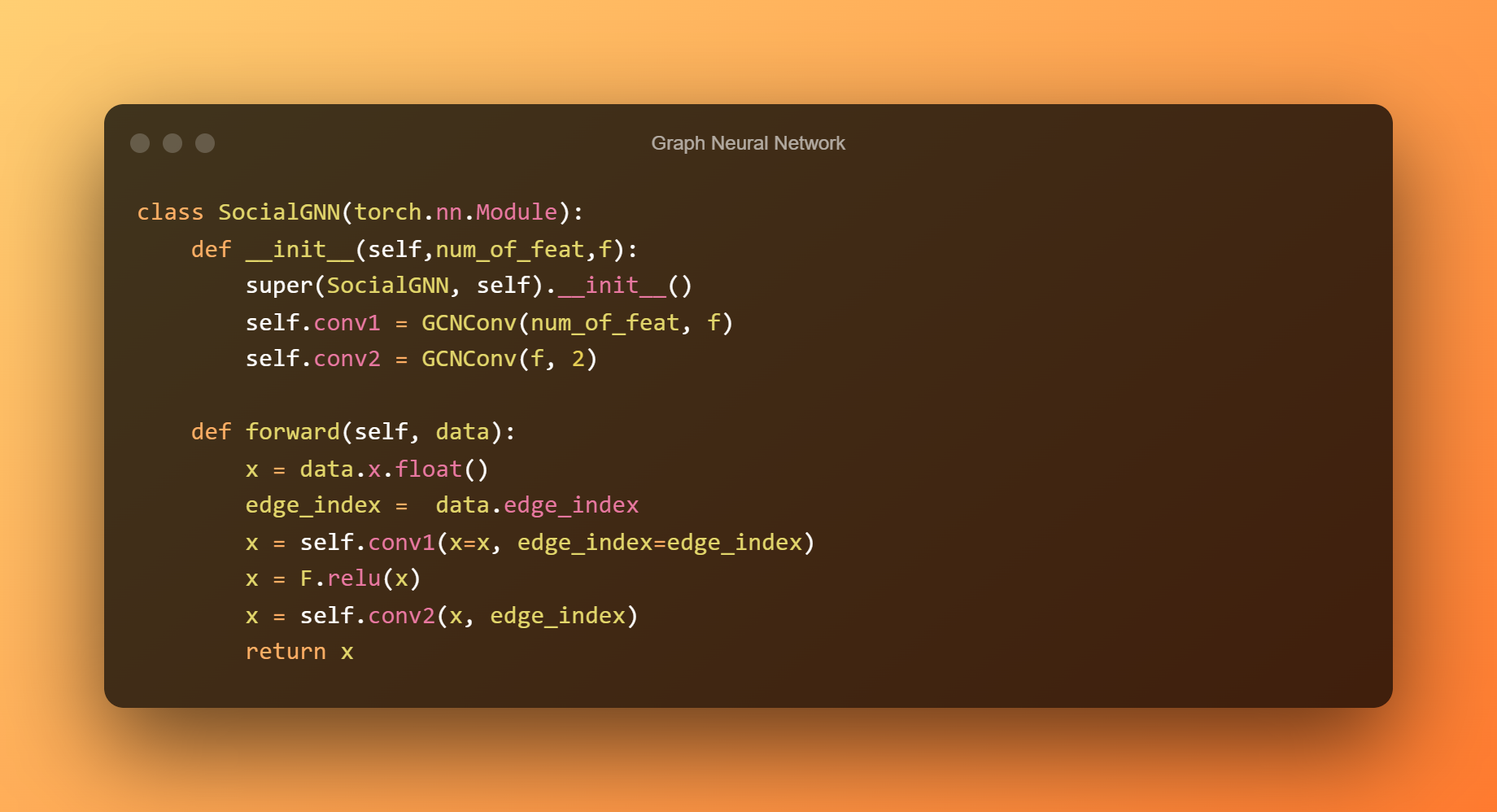
Nu gaan we twee GCNConv-lagen stapelen, waarvan de eerste een uitvoerfunctietelling heeft die gelijk is aan het aantal objecten in onze grafiek als invoerfuncties.
In de tweede laag, die uitvoerknooppunten bevat die gelijk zijn aan het aantal van onze klassen, passen we een relu-activeringsfunctie toe en leveren de latente kenmerken.
Randindex en randgewicht zijn twee van de vele opties x die GCNConv kan accepteren in de voorwaartse functie, maar in onze situatie hebben we alleen de eerste twee variabelen nodig.
Ondanks het feit dat ons model de klasse van elk knooppunt in de grafiek kan voorspellen, moeten we nog steeds de nauwkeurigheid en het verlies voor elke set afzonderlijk bepalen, afhankelijk van de fase.
Zo willen we tijdens de training de trainingsset alleen gebruiken om de nauwkeurigheid en het trainingsverlies te bepalen en daarom komen onze maskers goed van pas.
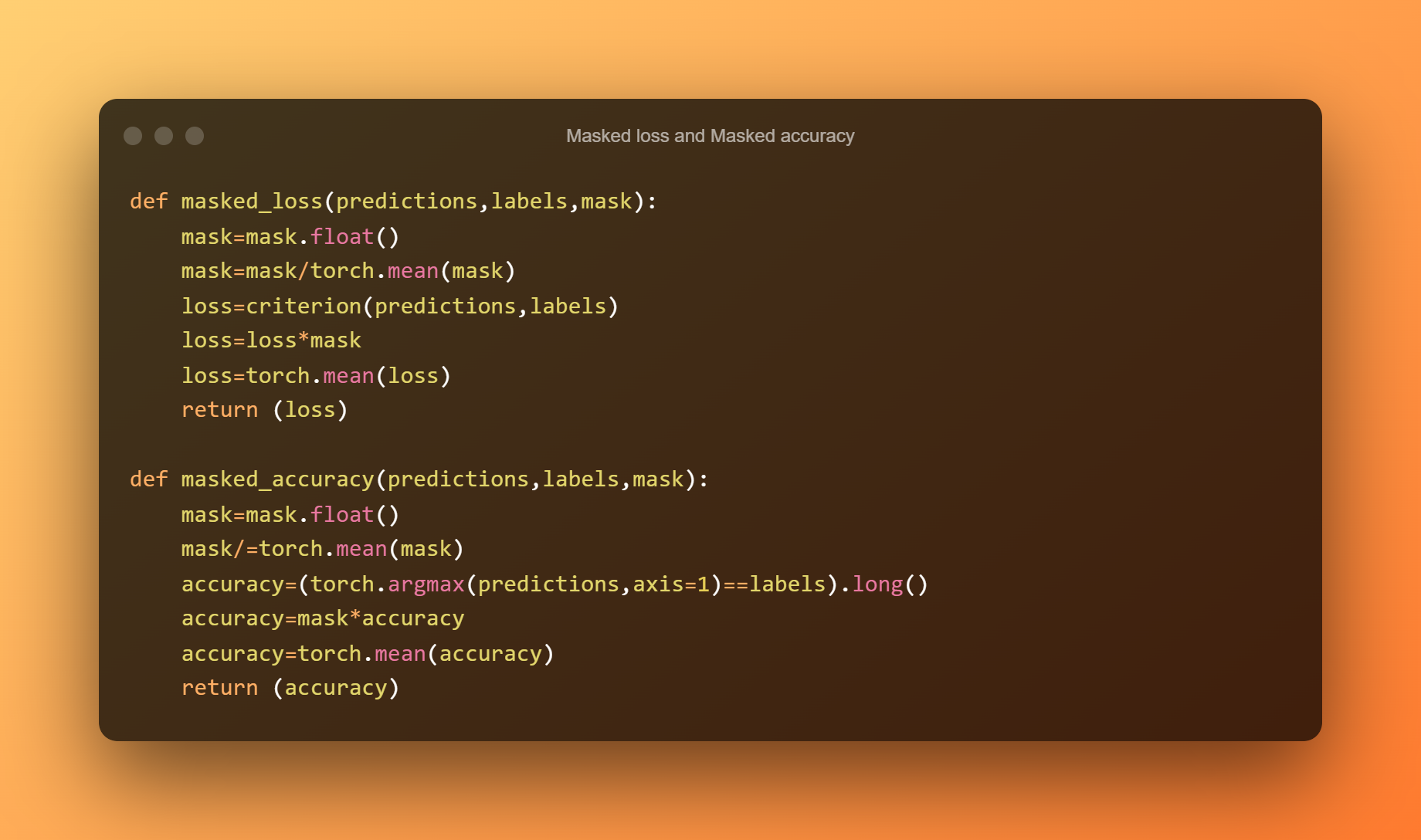
Om het juiste verlies en de juiste nauwkeurigheid te berekenen, zullen we de functies van gemaskeerd verlies en gemaskeerde nauwkeurigheid definiëren.
Het model trainen
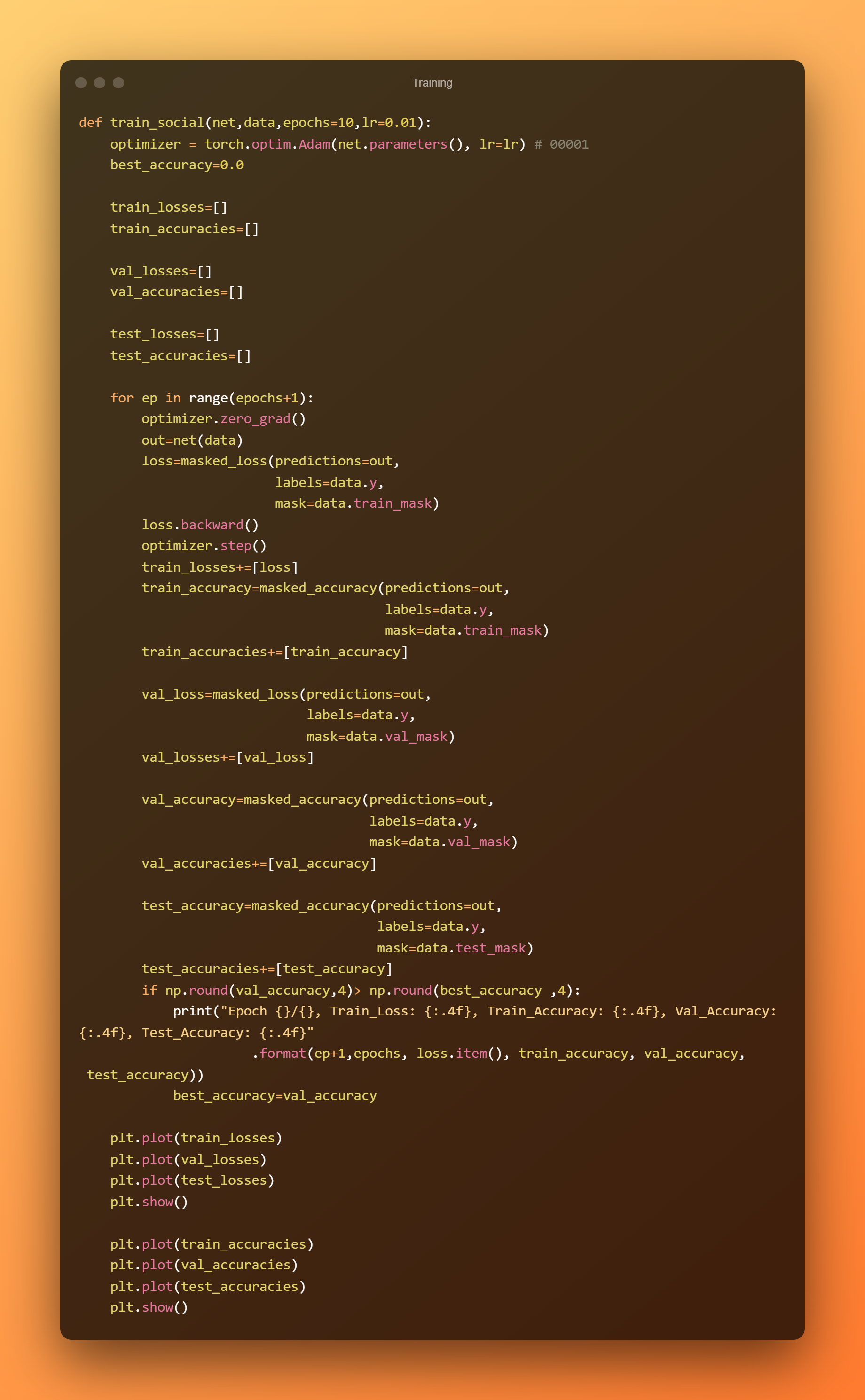
Nu we het trainingsdoel hebben gedefinieerd waarvoor de zaklamp zal worden gebruikt. Adam is een meester-optimizer.
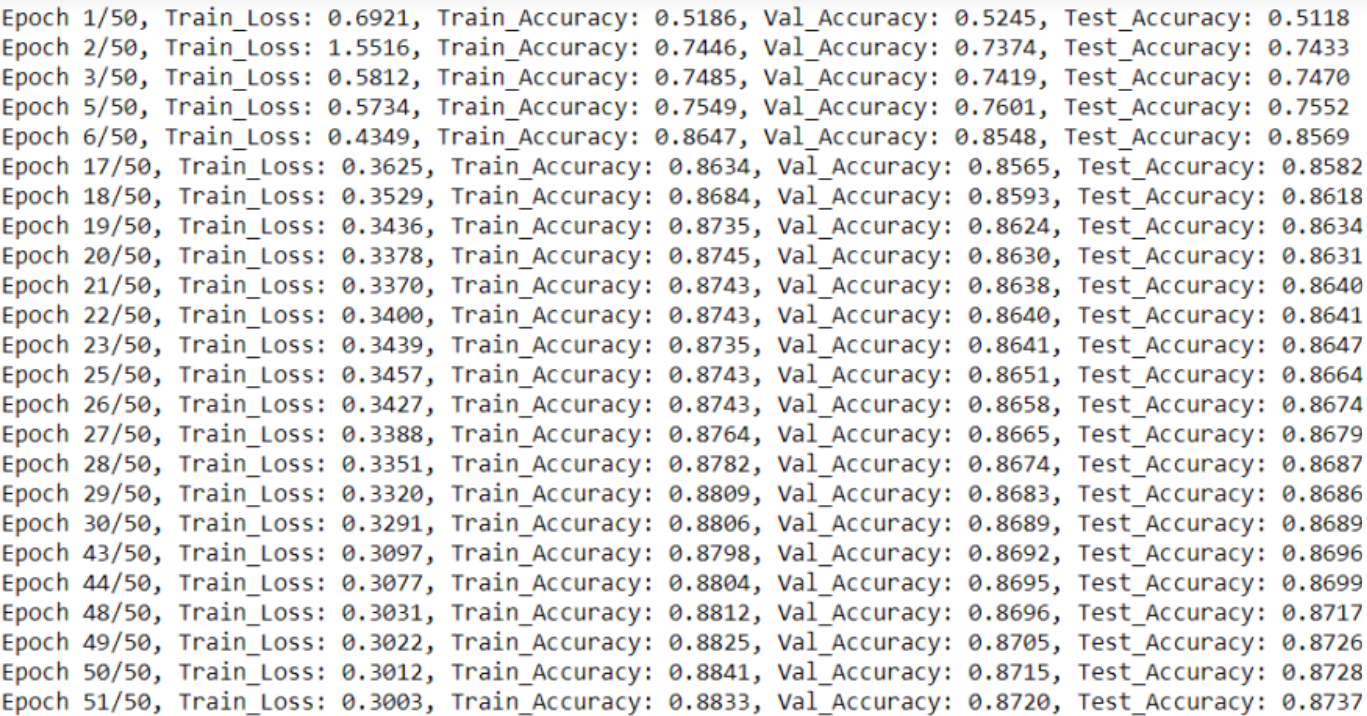
We zullen de training gedurende een bepaald aantal tijdperken geven terwijl we de validatienauwkeurigheid in de gaten houden.
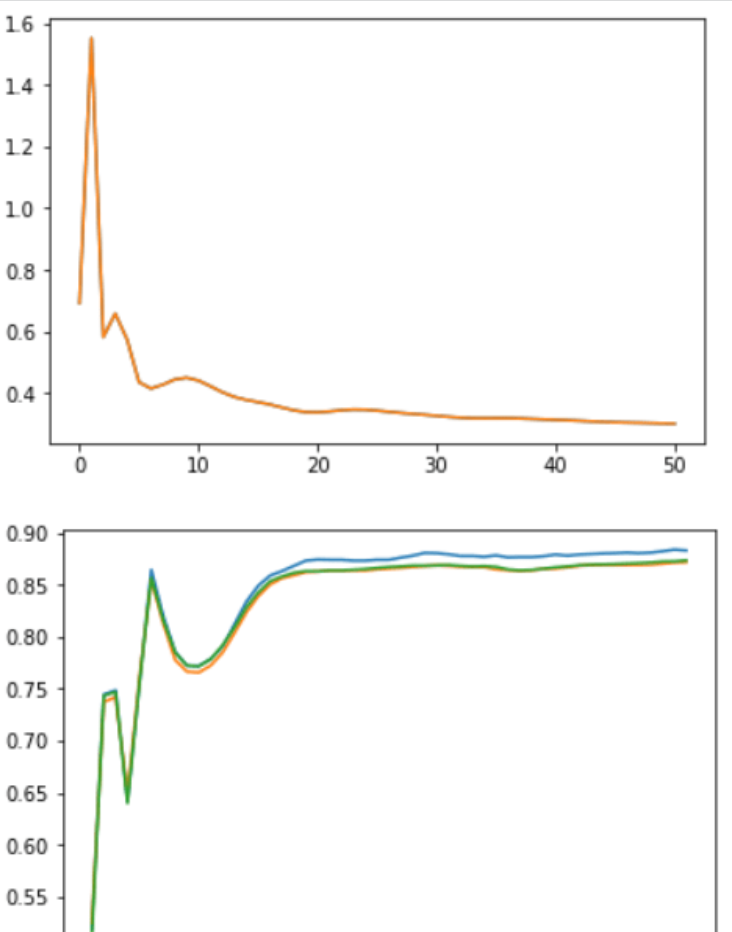
We plotten ook de verliezen en nauwkeurigheid van de training in verschillende tijdperken.
Nadelen van Graph Neural Network
Het gebruik van GNN's heeft enkele nadelen. Wanneer we GNNa moeten gebruiken en hoe we de prestaties van onze machine learning-modellen kunnen verbeteren, zullen we allebei duidelijk worden nadat we ze beter begrijpen.
- Hoewel GNN's ondiepe netwerken zijn, meestal met drie lagen, kunnen de meeste neurale netwerken diep gaan om de prestaties te verbeteren. Vanwege deze beperking kunnen we niet op het snijvlak van grote datasets presteren.
- Het is moeilijker om een model op grafieken te trainen, omdat hun structurele dynamiek dynamisch is.
- Vanwege de hoge rekenkosten van deze netwerken is het schalen van het model voor productie een uitdaging. Het schalen van de GNN's voor productie zal een uitdaging zijn als uw grafiekstructuur enorm en gecompliceerd is.
Conclusie
In de afgelopen jaren hebben GNN's zich ontwikkeld tot krachtige en effectieve tools voor machine learning-problemen in het grafische domein. Een fundamenteel overzicht van grafische neurale netwerken wordt in dit artikel gegeven.
Daarna kunt u beginnen met het maken van de dataset die zal worden gebruikt om het model te trainen en te testen. Om te begrijpen hoe het werkt en waartoe het in staat is, kun je ook veel verder gaan en het trainen met een ander soort dataset.
Gelukkig codering!





Laat een reactie achter