Webscraping is een cruciale methode geworden voor het verkrijgen van inzichtelijke gegevens van internetplatforms in de huidige datagestuurde samenleving.
Als extreem populaire sociale-mediasite biedt Instagram veel door gebruikers gegenereerd materiaal. En deze gegenereerde gegevens kunnen worden gebruikt voor marketing, onderzoek en andere redenen.
Gebruikers kunnen gemakkelijk en effectief gegevens van Instagram extraheren dankzij Bright Data's feature-rijke Instagram-scrapers, een toonaangevende web schrapen hulpmiddel. In dit bericht geven we een grondige, stapsgewijze uitleg van het Instagram-scrapingproces.
Laten we dus eens kijken hoe we gegevens van Instagram kunnen schrapen.
Inzicht in Instagram Scrapers van Bright Data
Met behulp van twee universele webschrapers en een vooraf gecompileerde dataset biedt Bright Data een verscheidenheid aan Instagram-scrapingservices. Deze technologieën bieden veelzijdigheid in gegevensextractie en passen zich aan verschillende eisen aan.
Laten we elk van deze keuzes in meer detail bekijken:
a. Schrapende browser
De innovatieve technologie die bekend staat als Scraping Browser is gemaakt om te voldoen aan de eisen van projecten voor het schrapen van gegevens. Het biedt alles wat nodig is om op schaal te schrapen in een enkele browser. Het valt op dankzij de geïntegreerde automatisering voor het deblokkeren van websites, waardoor het de enige browser in zijn soort ter wereld is.
Scraping Browser geeft gebruikers toegang tot robuuste functies die verder gaan dan geautomatiseerde en headless browsers, waardoor ze zelfs de moeilijkste scripts en websitebarrières voor botdetectie kunnen omzeilen.
Het schrapen van gegevens is effectiever en probleemloos vanwege de geautomatiseerde aanpassingsfuncties, die gemakkelijk nieuwe blokken, CAPTCHA-oplossingen, vingerafdrukken en nieuwe pogingen beheren en verschijnen als een echte gebruiker.
AI gebruiken om botdetectiesystemen te slim af te zijn
Door gebruik te maken van geavanceerde AI-technologie, kan Scraping Browser botdetectiesystemen te slim af zijn en zich voortdurend aanpassen aan hun veranderende strategieën. Om webpagina's beter te ontgrendelen, leert Scraping Browser van de pogingen van deze systemen om scrappogingen te detecteren en te blokkeren en past het zijn gedrag op de juiste manier aan.
Het overtreft de efficiëntie van conventionele proxy's door het gedrag van een browser na te bootsen die door een echte gebruiker wordt gebruikt. Als gevolg hiervan kunnen klanten zich concentreren op hun doelen voor het schrapen van gegevens zonder te maken te hebben met de moeilijkheid en kosten van lopende botdetectieprocedures.
b. Webschraper IDE
Web Scraper IDE is een robuuste webscraping-tool die is gemaakt voor ontwikkelaars en kan complexe scraping-taken aan. Het verkort de ontwikkeltijd aanzienlijk en biedt oneindige schaalbaarheid dankzij de volledig gehoste oplossing en vooraf gebouwde scraping-functies. De applicatie maakt het snel en schaalbaar bouwen van online scrapers mogelijk door codesjablonen en kant-en-klare JavaScript-functies van populaire websites te bieden.
Alles wat nodig is voor succesvol webschrapen wordt geleverd door de Web Scraper IDE. Het is een complete oplossing voor online gegevensextractie, aangezien klanten dankzij integratieopties crawls kunnen plannen of starten via API en kunnen koppelen met de belangrijkste opslagsystemen.
Hoe te gebruiken? - Zelfstudie
Navigeer eerst naar het gebruikersdashboard op de website.

Laten we beginnen met onze stappen om Instagram te schrapen.
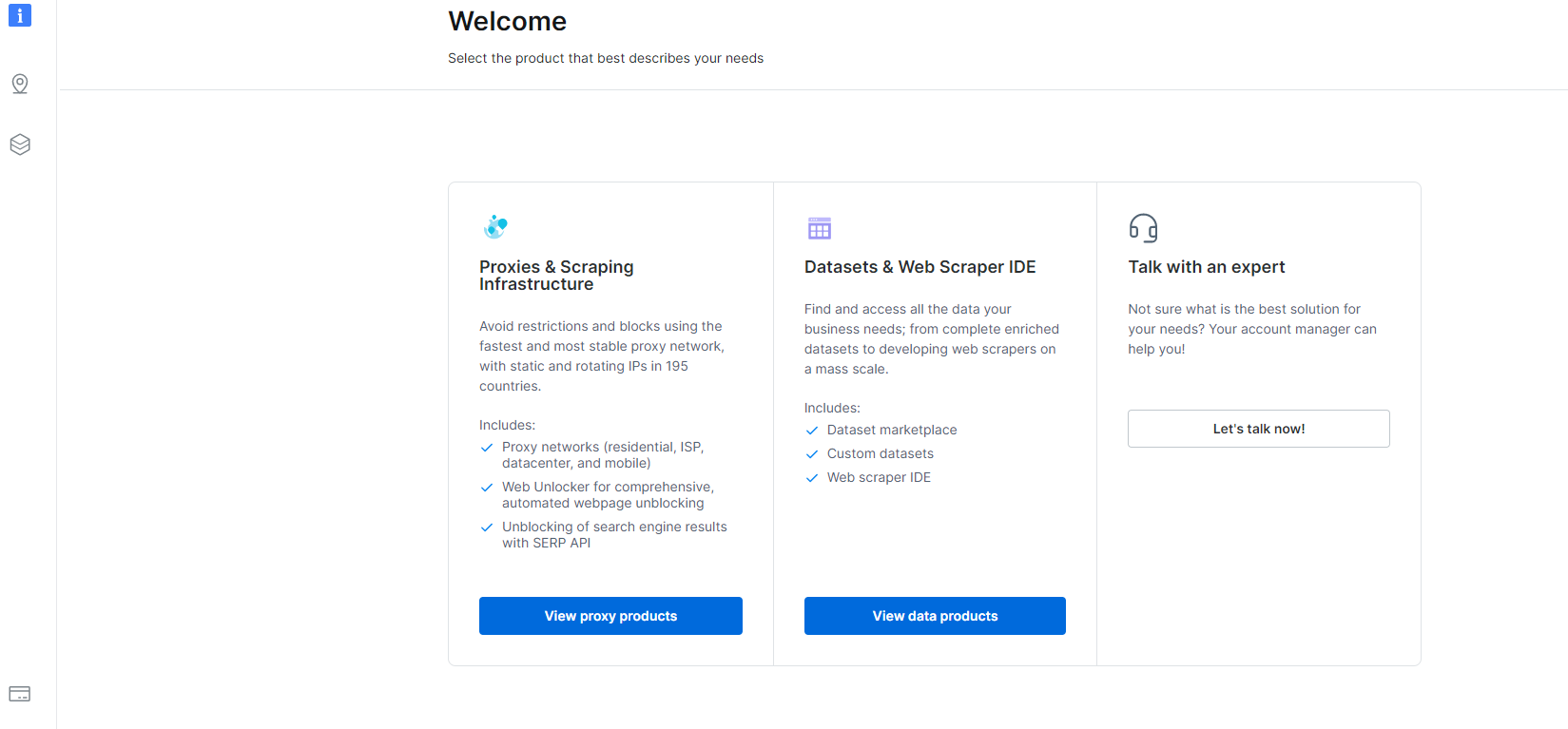
1- Navigeer naar de Overzicht en klik op het gedeelte Datasets & Web Scraper IDE.
2- Eenmaal daar, klik je op Mijn Scrapers.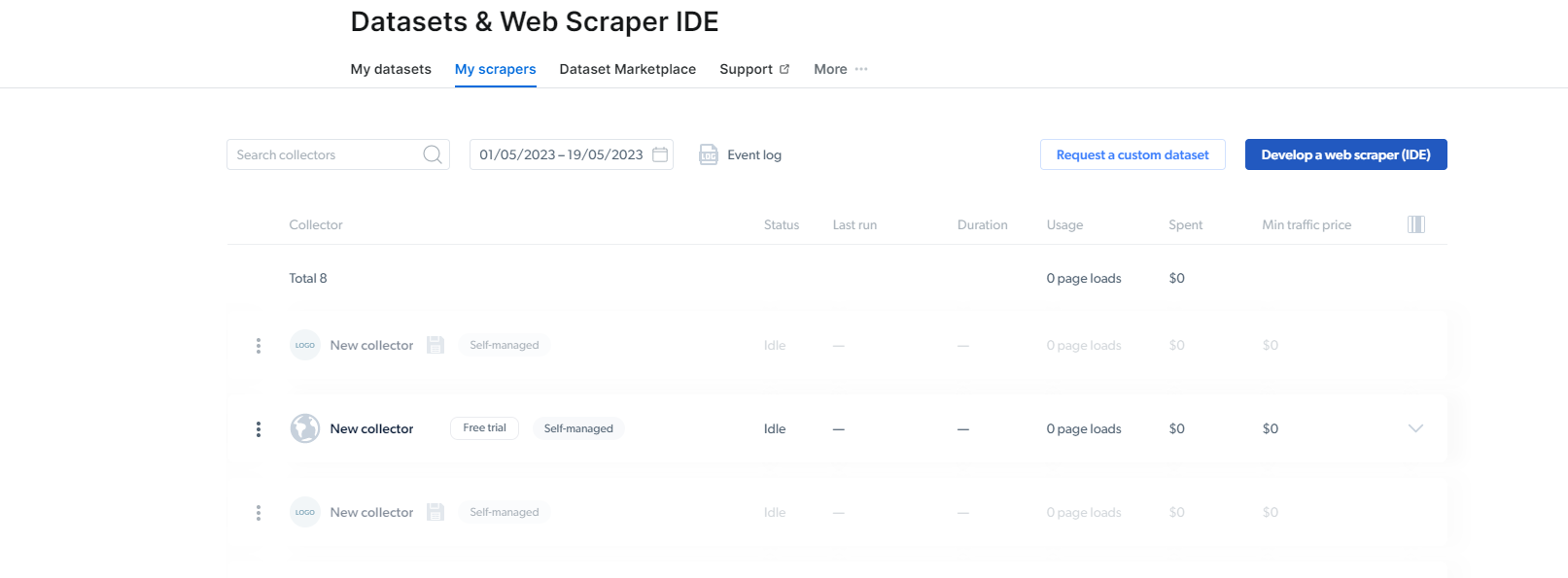
Klik hier op "Ontwikkel een webschraper (IDE)". Hier zullen we onze schraper voor Instagram maken.
3-Nu moeten we een nieuwe webschraper ontwikkelen. Alleen al voor dit voorbeeld kies ik ervoor om het "NASA" -account te schrappen. Dit is alleen ter wille van dit voorbeeld.
Mijn code ziet er dus als volgt uit:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
U moet rechtsboven op de knop 'afspelen' klikken om deze code uit te voeren.
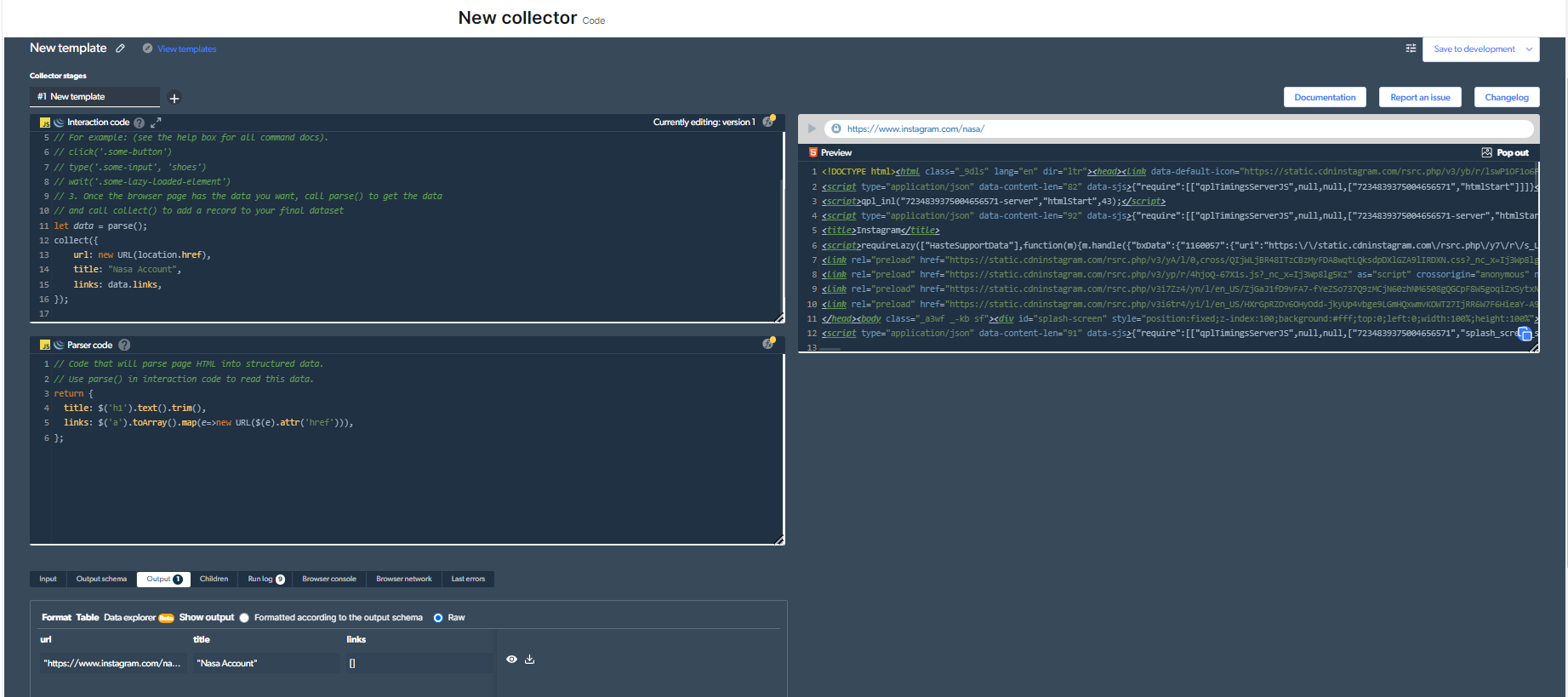
4- Nu zullen we een uitvoer hebben.
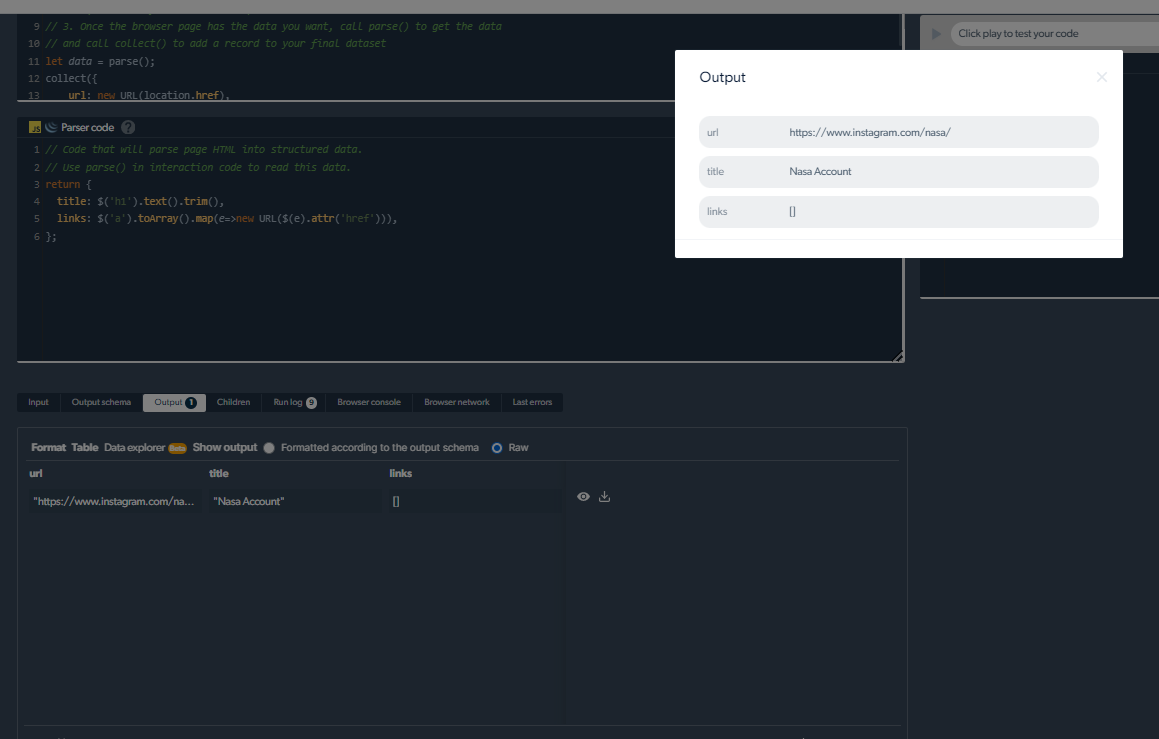
Schraapproblemen beheren
Instagram-berichten met de knop 'meer weergeven' kunnen voor scrapers moeilijk vast te leggen zijn. Instagram-scrapers van Bright Data zijn echter gemaakt om dergelijke complexiteit succesvol aan te kunnen. Deze schrapers hebben geavanceerde vaardigheden om door de paginering en het laden van extra knoppen te bladeren.
De Instagram-scrapers van Bright Data pakken deze problemen effectief aan om grondige gegevensextractie mogelijk te maken, zodat u de volledige verzameling informatie kunt verzamelen die nodig is voor uw analyse of onderzoek.
Je kunt de uitdagingen van de dynamische aard van Instagram-berichten omzeilen door deze scraping-tools te gebruiken.
c. Vooraf verzamelde dataset
Bright Data begrijpt dat niet iedereen zijn scraper wil laten draaien. Ze leveren een vooraf verzamelde dataset voor Instagram om dergelijke consumenten aan te spreken.
Deze dataset biedt een schat aan nuttige informatie, zoals volgers, profielen, berichten en meer.
Bright Data biedt aanpassingsmogelijkheden om de dataset aan te passen aan uw behoeften, of u nu een hele dataset of een subset van gespecialiseerde gegevens wilt. Deze aanpak vermijdt het bouwen en beheren van een schraper, waardoor u kant-en-klare gegevens krijgt voor analyse en inzichten.
Laten we nu eens kijken naar de infrastructuur die deze tools zo effectief maakt: de proxy-infrastructuur en Web Unlocker.
Ontketen de kracht van proxy's
gebruik proxies is cruciaal tijdens webscraping om te garanderen dat uw acties onopgemerkt blijven.
Bright Data biedt een ruime keuze aan proxy-services die zijn aangepast aan uw wensen. U kunt kiezen uit Residentiële proxy's, die meer dan 72 miljoen IP's bieden die zijn geroteerd vanaf echte peer-apparaten in 195 landen.
U kunt ISP-proxy's kiezen, die wereldwijd meer dan 700,000 echte thuis-IP's bieden voor langdurig gebruik; Datacenter Proxies, die meer dan 770,000 gedeelde IP's hebben vanaf elke geolocatie; en Mobile Proxies, die het grootste real-peer 3G/4G mobiele netwerk vormen met meer dan 7,000,000 IP's.
Met het gebruik van deze proxy's kan men gemakkelijk gegevens verzamelen terwijl men zich op tal van plaatsen voordoet als een geautoriseerde gebruiker.

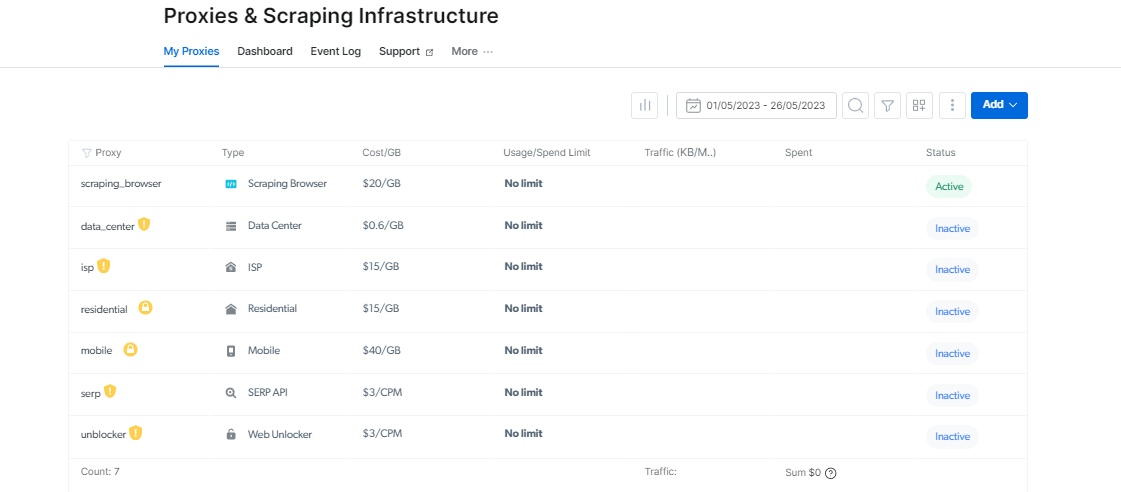
Proxy Manager: maak proxybeheer eenvoudiger
Het beheren van meerdere proxy's kan moeilijk zijn, maar Proxy Manager maakt het gemakkelijk.
Met deze open-source interface kunt u al uw proxy's vanaf één platform beheren. Zeg vaarwel tegen het handmatig instellen en wisselen van proxy's. Proxy Manager vereenvoudigt de procedure en bespaart u tijd en moeite.
Proxybrowserextensie: verander eenvoudig uw locatie
Moet u webgegevens uit meerdere regio's verzamelen? U bent gedekt door onze Proxy Browser Extension. U kunt uw browselocatie met een enkele klik wijzigen om regiospecifieke informatie te verkrijgen.
Profiteer van de flexibiliteit en eenvoud van het verzamelen van gegevens uit verschillende regio's zonder enige technologische complicaties.
Hoe werkt het? - Zelfstudie
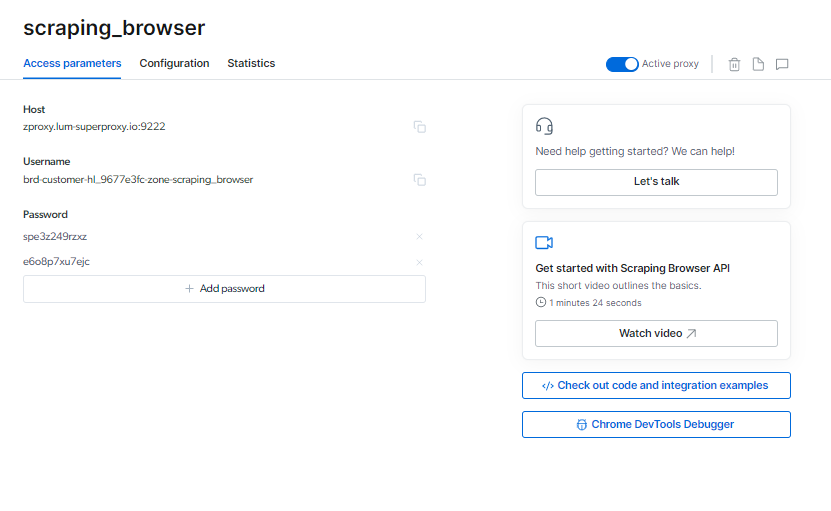
U kunt uw Schrapende browser aanmeldingsgegevens op de pagina Toegangsparameters, die worden gebruikt wanneer u een nieuwe browsersessie start.
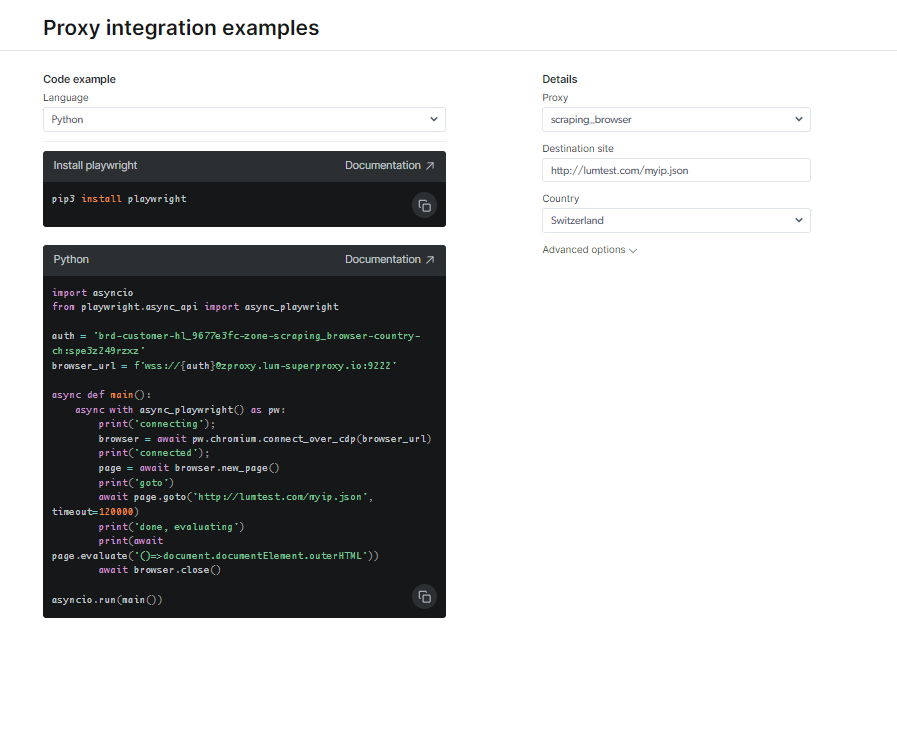
Bekijk documentatie en codevoorbeelden, inclusief een volledig functioneel voorbeeldscript dat klaar is voor gebruik, of bekijk een korte instructievideo om te beginnen. Bijvoorbeeld; hier is een Python-code voorbeeld voor integratie:
Wil je hulp? Voor een gesprek met een van de specialisten kunt u op het chat icoontje klikken.
Houd er rekening mee dat u volledige controle heeft over de browsersessies terwijl u Scraping Browser gebruikt en elke bewerking kunt uitvoeren die wordt ondersteund door Puppeteer, Playwright of direct gebruik van het Chrome DevTools-protocol.
Website ontgrendelen zonder blokken
Scraping Browser is gemaakt om op schaal en naar behoefte te werken. Je hoeft je geen zorgen te maken dat je verbannen wordt; u kunt zoveel browsersessies starten als u nodig heeft.
Deze capaciteit, in combinatie met de kracht van proxy's, garandeert een continue gegevensverzameling, waardoor u effectief de gewenste gegevens kunt verkrijgen.
De ingebouwde ontgrendelingsvaardigheden en het robuuste proxy-netwerk van Scraping Browser helpen u tijd te besparen, de productiviteit te verhogen en nieuwe kansen te ontdekken.
U kunt de statistieken ook rechtstreeks van dezelfde pagina bekijken.
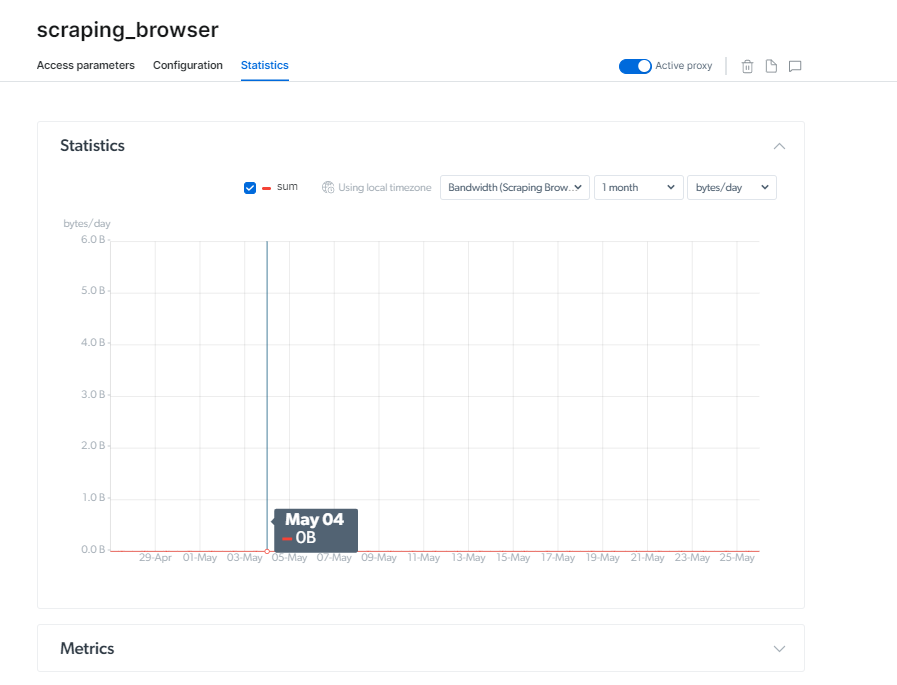
Prijzen van Scraping Browser
Bright Data biedt aanpasbare prijskeuzes voor verschillende doeleinden. U kunt kiezen voor een maandelijkse of jaarlijkse factureringsperiode.
Met de Pay as You Go-optie kunt u betalen voor wat u gebruikt, zonder enige verplichting, beginnend bij $ 20.00/GB en $ 0.1/uur.
Het groeiplan van $ 500 is geschikt voor groeiende bedrijven, met een gereduceerd tarief van $ 15.30/GB en $ 0.1/uur.
De Zakelijk pakket, die $ 1000 kost, is de meest populaire optie, waarbij de Scraping Browser API $ 13.50 / GB en $ 0.1 / uur kost.
Door rechtstreeks contact op te nemen met het Bright Data-team, kunnen zakelijke gebruikers profiteren van oneindige schaalmogelijkheden en gepersonaliseerde prijzen. Start vandaag nog een gratis proefperiode om het potentieel van Bright Data's Scraping Browser te ontdekken en uw online scraping-inspanningen te veranderen.
Website-ontgrendelaar
Web Unlocker is een krachtige tool die is gemaakt om verder te gaan dan websitebeperkingen en om eenvoudig gegevens te verzamelen. Het overwint verschillende uitdagingen, waaronder cookies, sitespecifieke browsergebruikersagenten en captcha-oplossingen, door gebruik te maken van geautomatiseerde procedures.
Door automatische IP-adresrotatie te gebruiken, kunnen gebruikers van Web Unlocker voortdurend doelwebsites schrapen, waardoor ze constant toegang hebben tot belangrijke gegevens.
Verbetering van reisverzoeken van ontwikkelaars
Verschillende functies maken Web Unlocker populair onder ontwikkelaars. Het programma stroomlijnt het gegevensverzamelingsproces door automatisch de user-agents te identificeren die nodig zijn voor elke website, waardoor kostbare tijd en middelen worden bespaard.
Web Unlocker past zich in realtime aan om detectie te voorkomen als reactie op de voortdurend veranderende strategieën die worden gebruikt door bots te blokkeren, waardoor continue toegang tot de interessante websites wordt gegarandeerd. De algoritmen voor machine learning van het platform kunnen snel captcha's oplossen, een veel voorkomend obstakel voor initiatieven voor het verzamelen van gegevens.

Prijzen van Web Unlocker
Vanaf ongeveer $ 2.03 per duizend verzoeken (CPM) biedt Web Unlocker meerdere prijsopties om aan verschillende eisen te voldoen. Er is een gratis proefperiode van 7 dagen beschikbaar voor gebruikers om ze op weg te helpen en ze de functies van Web Unlocker te laten testen voordat ze zich vastleggen.
Web Unlocker heeft het aanpassingsvermogen om verschillende gebruikspatronen te ondersteunen, ongeacht of consumenten een pay-as-you-go-benadering willen of een op maat gemaakt plan nodig hebben dat is aangepast aan hun specifieke vereisten. Bovendien kunnen degenen die kiezen voor prijsplannen op lange termijn 32% besparen.
Vergelijking tussen Web Unlocker met zelfbeheerde proxy's
Web Unlocker biedt tal van directe voordelen ten opzichte van zelfbeheerde proxy's. Voor een soepele implementatie biedt het een uitgebreide integratietechniek die de functies Super Proxy en Proxy Manager combineert. Gebruikers kunnen hun gegevensverzamelingsactiviteiten effectief opschalen met een oneindig aantal gelijktijdige verbindingen.
Web Unlocker zorgt voor automatische deblokkering, lost CAPTCHA's op en beheert met succes markup-wijzigingen op doelwebsites.
Het platform garandeert continue en betrouwbare gegevensextractie door een systeem voor automatisch opnieuw proberen te implementeren en asynchrone oproepen te doen voor bepaalde domeinen. Bovendien zorgen online Unlocker's groeiende verzameling HTTP-headerverzoeken, sitespecifieke browsercookies en gesimuleerde gadgets ervoor dat gebruikers onopgemerkt blijven, terwijl ze in realtime online gegevens kunnen verkrijgen.
Laatste gedachten en belangrijke dingen om te onthouden
Ten slotte is het bij het gebruik van Bright Data voor Instagram-scraping van cruciaal belang om enkele essentiële punten in gedachten te houden.
Houd er rekening mee dat hun schrapmogelijkheden beperkt zijn tot openbaar beschikbare gegevens, door ethische praktijken.
Je moet altijd de servicevoorwaarden en het privacybeleid van Instagram volgen. Scraping moet ethisch en verantwoord gebeuren, zonder inbreuk te maken op de rechten van gebruikers of wetten te overtreden.
Ten tweede, update en verfijn uw schraapparameters regelmatig om de nauwkeurigheid en relevantie van de opgehaalde gegevens te garanderen. Het platform en de algoritmen van Instagram zijn aan verandering onderhevig, daarom moet u uw scrapstrategieën dienovereenkomstig aanpassen.
Gebruik ten slotte de hulp en bronnen van het platform van Bright Data om het succes van uw Instagram-scraping-inspanningen te optimaliseren. Neem contact op met hun documentatie, tutorials en klantenservice om uw kennis van hun scraping-tools te verbeteren.
Je kunt nuttige inzichten krijgen, verstandige besluitvorming beïnvloeden en slagen in je datagestuurde initiatieven op het Instagram-platform door deze best practices te volgen en de kracht van Bright Data's Instagram-scraping-mogelijkheden te gebruiken.





Laat een reactie achter