Inhoudsopgave[Zich verstoppen][Laten zien]
Gegevens zijn overal om je heen. In feite beïnvloedt het elk aspect van uw bedrijf. Het kan lijken alsof er niet genoeg tijd is om de details te onderzoeken van hoe goed het uw bedrijf van dienst is wanneer u bezig bent met beslissingen over hoe u met uw gegevens om moet gaan.
Observeer dit. Uw organisatie gebruikt 24 uur per dag data. Begrijpen waar het vandaan komt, hoe het daar terecht is gekomen en hoe het zich door het bedrijf beweegt, is dus cruciaal om de waarde ervan te begrijpen.
Gegevensafstamming wordt belangrijk in deze situatie. Het is eenvoudiger te begrijpen hoe gegevens zijn gevormd, waar ze vandaan komen en waar ze naartoe gaan als we de oorsprong, migraties en wijzigingen van de gegevens kunnen volgen.
In dit bericht zullen we nauwkeurig kijken naar Data Lineage, hoe het werkt, de use cases, technieken en nog veel meer.
Wat is datalijn?
Data lineage dient als een soort digitaal paspoort. Het is het meest uitgebreide verslag van een gegevensreis, met alle tussenstops, omwegen en wijzigingen vanaf het begin tot de uiteindelijke bestemming.
IIn essentie beschrijft data lineage de oorsprong, wijziging en het gebruik van een stuk data op vele systemen en platforms. Het functioneert als een hulpmiddel voor detectives door gebruikers informatie te geven over hoe gegevens zijn geproduceerd, waar ze vandaan komen en hoe ze zijn gebruikt. Met deze informatie kunnen gebruikers mogelijke problemen herkennen en oplossen.
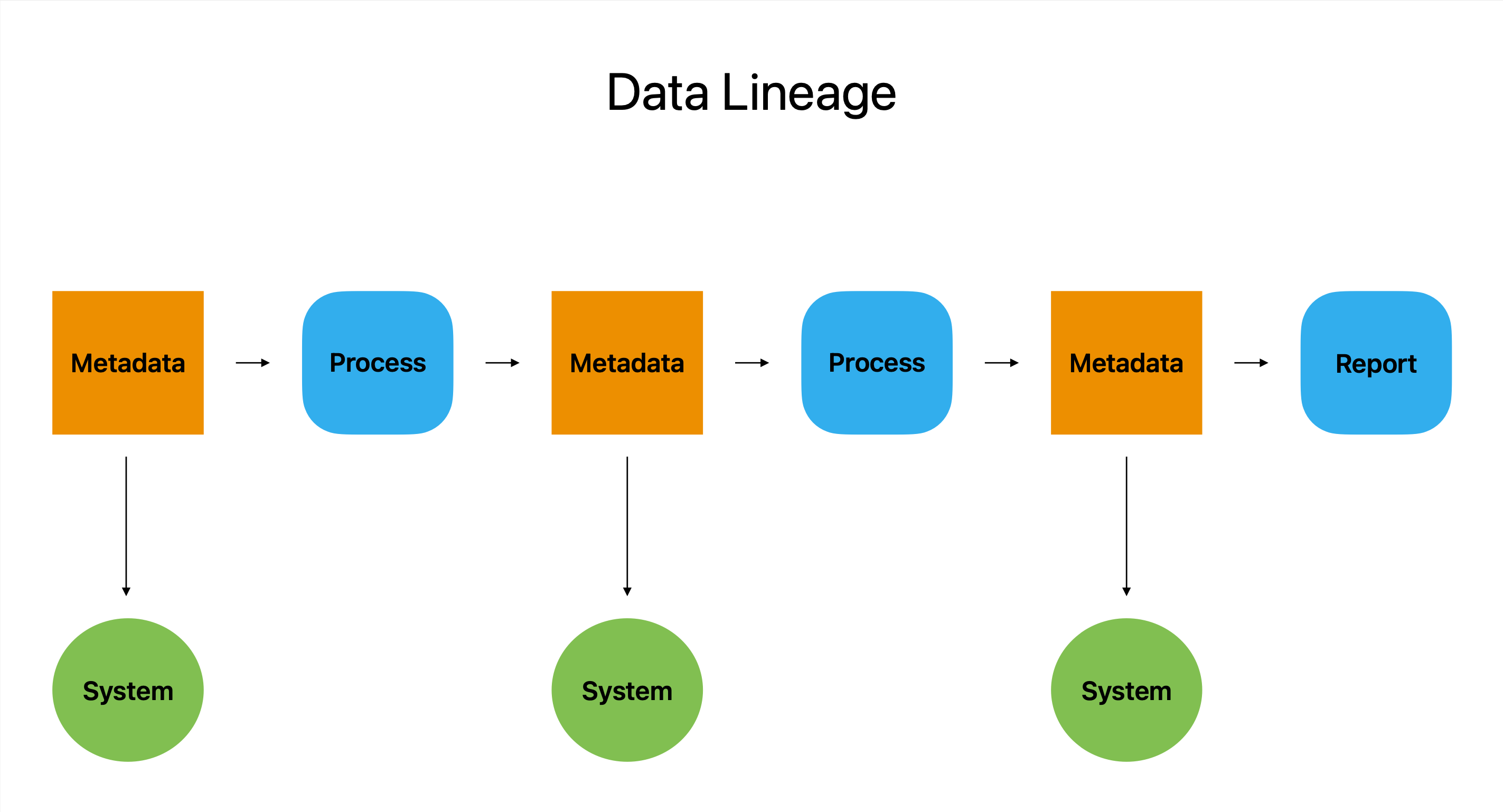
Data lineage is een onschatbare bron voor bedrijven die afhankelijk zijn van data om hun activiteiten uit te voeren, omdat het gebruikers in staat stelt te reageren op cruciale vragen zoals wie, wat, wanneer en waar.
Data lineage is, om het simpel te zeggen, het ultieme dataspoor dat de nauwkeurigheid, volledigheid en consistentie van data garandeert en tegelijkertijd een duidelijk en beknopt perspectief biedt van het volledige pad van een data.
Hoe werkt datalijn?
Data lineage is de routekaart die ons in staat stelt om een stuk data te volgen van het beginpunt tot het eindpunt. Beschouw een datapunt als een reiziger en zijn paspoort als zijn datalijn om beter te begrijpen hoe het functioneert.
Gegevensbronnen, gegevenstransformatie, gegevensopslag en gegevensuitvoer vormen de vier hoofdcomponenten van het paspoort.
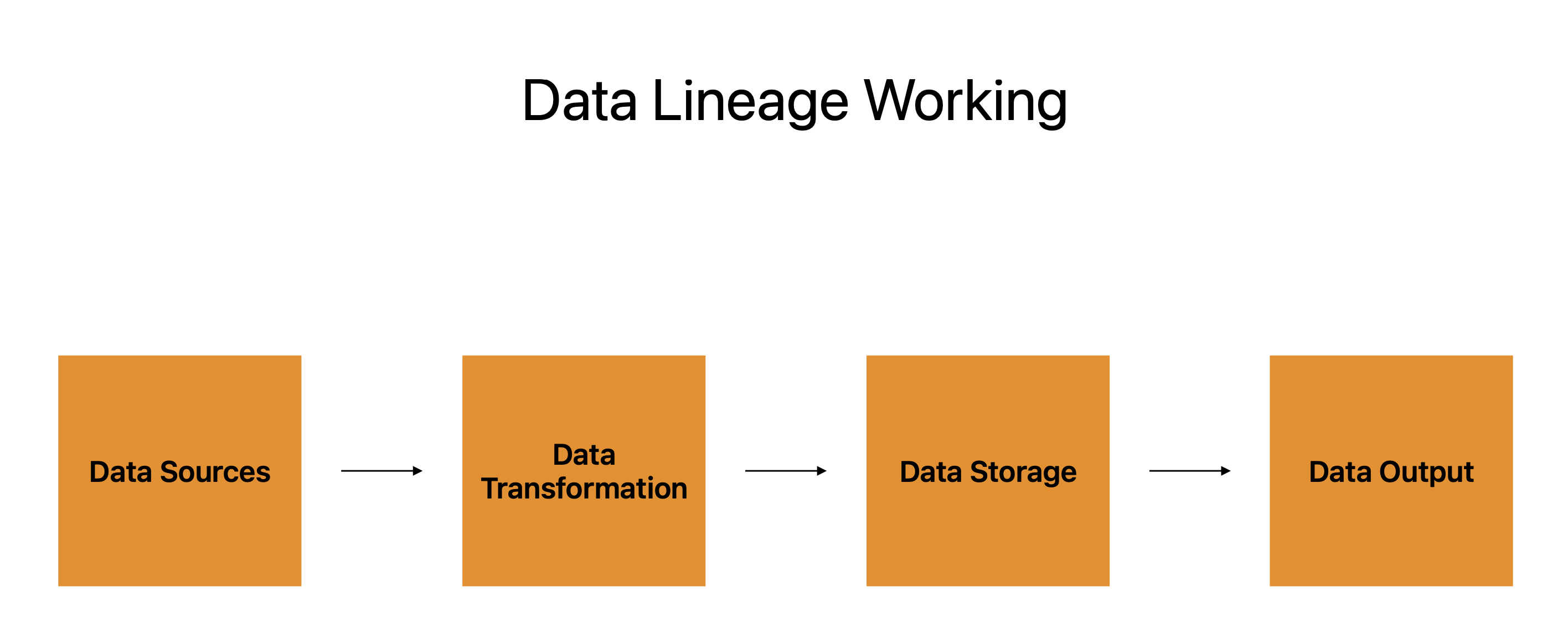
De vele systemen, applicaties en platforms waarvan de gegevens afkomstig zijn, worden vertegenwoordigd door gegevensbronnen, die dienen als beginpunt voor de reis van de gegevens. Gegevenstransformatie is de volgende fase, en de gegevenslijn brengt de voortgang van de gegevens van deze bronnen ernaartoe in kaart.
Datatransformatie verwijst naar het vormen, wijzigen en manipuleren van gegevens om aan de behoeften van de gebruiker te voldoen. Het functioneert als een tussenstop tijdens de reis van de gegevens en bereidt deze voor op het volgende deel.
De gegevens worden vervolgens opgeslagen voordat ze naar de definitieve locatie gaan. Het kan worden bewaard op cloudservers, databases of een ander soort opslagapparaat. Data lineage houdt bij waar de gegevens zijn opgeslagen, en hoe deze worden beschermd, geback-upt en hersteld.
De laatste stap is de gegevensuitvoer, waar de gegevens naartoe worden gestuurd om te worden gebruikt. Rapporten, infographics of elk ander type gegevensproduct kunnen worden gebruikt om het te presenteren. Data lineage houdt de output bij en garandeert de consistentie, nauwkeurigheid en volledigheid van de data.
Gegevensafstamming werkt in feite door elke fase van de reis van de gegevens vast te leggen, van het begin tot de uitvoer, en ervoor te zorgen dat deze betrouwbaar, consistent en correct blijft. Gegevensafstamming helpt organisaties om weloverwogen beslissingen te nemen, problemen op te lossen en zich te houden aan wettelijke verplichtingen door een volledig beeld te geven van het bestaan van gegevens.
Om inzicht te krijgen in de data-assets en hoe ze zich door de datapijplijn bewegen, is metadata een cruciaal onderdeel van het data-afstammingsproces.
U kunt zien hoe gegevens worden geconverteerd en gebruikt binnen de organisatie met behulp van data lineage-tools, die gebruikmaken van metadata om een visuele weergave van de gegevensstroom te geven. Hierdoor kunnen gebruikers het potentieel van de gegevens beoordelen, waardoor ze beter geïnformeerde beslissingen kunnen nemen.
Soorten datalijn
Er zijn drie basisvormen van gegevenslijn: voorwaartse gegevenslijn, achterwaartse gegevenslijn en bidirectionele gegevenslijn.
Gegevenslijn doorsturen
Net als bij een eenrichtingsverkeer, omvat voorwaartse datalijn het volgen van een stuk data van het beginpunt tot het eindpunt. Beginnend bij de gegevensbron, volgt het de gegevens terwijl deze verschillende transformaties en opslagsystemen doorloopt om de uitvoer te bereiken.
Het begrijpen van de verwerking en transformatie van gegevens, evenals eventuele problemen die zich onderweg kunnen voordoen, wordt vergemakkelijkt door een dergelijke datalijn te hebben. Elke stap leidt naar de volgende; het is alsof je een spoor van broodkruimels volgt.
Achterwaartse gegevenslijn
Backward data lineage is vergelijkbaar met een reis in omgekeerde richting, waarbij we de uitvoer van de gegevens terugvoeren naar de bron. Het proces begint op de uiteindelijke locatie van de gegevens en gaat achteruit door een verscheidenheid aan opslag- en transformatietechnieken totdat het de gegevensbron bereikt.
Identificatie van de oorspronkelijke bron van de gegevens, begrip van de transformatie ervan en verificatie van de juistheid en volledigheid ervan zijn allemaal mogelijk met behulp van dit soort datalijn. Het werkt als een detectivetool, waardoor we het pad van de gegevens achterwaarts kunnen volgen.
Bidirectionele gegevenslijn
Een bidirectionele datalijn in twee richtingen combineert de voordelen van voorwaartse en achterwaartse datalijn. Het biedt een uitgebreid overzicht van de route van de gegevens door deze te volgen van de bron tot de bestemming en van die locatie tot het startpunt.
Om de oorspronkelijke bron van de gegevens te bepalen, te begrijpen hoe ze zijn gewijzigd en de kwaliteit, consistentie en volledigheid ervan te garanderen, is het handig om de afstamming van de gegevens te volgen. Met real-time informatie over de locatie en status is het alsof u een GPS-tracker voor gegevens heeft.
Implementatie van Data Lineage
Het implementeren van data lineage in een organisatie omvat vaak de volgende fasen.
Definieer de gegevensbronnen
De systemen en databases die de gegevens bevatten die u wilt volgen, moeten allemaal worden geïdentificeerd. Om dit te doen, moet u eerst de verschillende gegevensbronnen identificeren, waaronder bestanden, API's en cloudservices.
Verzamel de metagegevens
De volgende fase is het verkrijgen van details over de gegevens, inclusief de locatie, het formaat en de organisatie. Het begrijpen van de kenmerken van de gegevens en hoe deze worden gebruikt, wordt mogelijk gemaakt door deze metadata.
Identificeer datafouten
Het is eenvoudiger te begrijpen hoe gegevens worden bijgewerkt en gebruikt binnen de organisatie als de gegevensstroom van de bron naar de bestemming in kaart wordt gebracht, inclusief eventuele transformaties of verwerkingen die onderweg plaatsvinden.
Houd gegevenstoegang bij
Om gegevensbeveiliging en naleving te behouden, volgt en registreert u wie toegang heeft tot de gegevens.
Bewaar en visualiseer de afstamming
Gebruik visualisatietools om de afstamming te presenteren voor eenvoudig begrip en analyse. Sla de verzamelde metadata en gegevensstroominformatie op in één enkele repository.
Implementeer een geautomatiseerde oplossing
U kunt controleren of de datalijn wordt verzameld en gecontroleerd door middel van automatisering, wat ook zal helpen om fouten te verminderen en de productiviteit te verhogen.
Review & Update
Zorg ervoor dat de afstammingsgegevens regelmatig correct en actueel zijn en werk deze waar nodig bij.
Het implementatieproces moet mogelijk worden aangepast of aan fasen worden toegevoegd, afhankelijk van de unieke vereisten en beperkingen van elke organisatie.
Data Lineage-technieken
Op patronen gebaseerde afstamming
Met deze methode wordt afstamming uitgevoerd zonder interactie met de programmering die de gegevens heeft gegenereerd of getransformeerd. Metadata-evaluatie voor tabellen, kolommen en zakelijke rapporten maken er allemaal deel van uit. Het onderzoekt afstamming door naar trends te zoeken met behulp van deze metadata.
Het is bijvoorbeeld vrij waarschijnlijk dat een kolom in twee datasets met dezelfde naam en identieke datawaarden dezelfde data vertegenwoordigt in verschillende fasen van zijn bestaan. Een gegevenslijndiagram wordt vervolgens gebruikt om die twee kolommen met elkaar te verbinden.
Op patronen gebaseerde afstamming heeft het grote voordeel dat het technologie-onafhankelijk is, omdat het alleen gegevens controleert, geen gegevensverwerkingsmethoden. Elke databasetechnologie, inclusief Oracle, MySQL en Spark, kan deze op dezelfde manier implementeren. Het nadeel is dat deze benadering niet altijd nauwkeurig is.
Wanneer de gegevensverwerkingslogica verborgen zit in de computercode en niet direct duidelijk is in voor mensen leesbare metadata, kan het af en toe verbanden tussen datasets over het hoofd zien.
Afstamming door gegevenstagging
Deze methode is gebaseerd op het idee dat een transformatie-engine gegevens tagt of anderszins markeert. Het traceert de tag van begin tot eind om afstamming te vinden. Deze aanpak kan alleen succesvol zijn als u een betrouwbare transformatietool heeft die alle gegevensoverdracht beheert en u bekend bent met de tagstructuur die de tool gebruikt.
Zelfs als zo'n tool zou bestaan, zouden gegevens die zonder deze tool zijn gemaakt of gewijzigd, niet kunnen worden onderworpen aan afstamming via data-tagging. Het is in dit opzicht beperkt tot het uitvoeren van datalineage op gesloten datasystemen.
Zelfstandige afstamming
Sommige bedrijven hebben een gegevensomgeving met opslag van metagegevens, verwerkingslogica en beheer van mastergegevens (MDM). Deze instellingen bevatten vaak een data lake waar alle gegevens gedurende de gehele levensduur worden bewaard.
Afstamming kan op natuurlijke wijze worden geleverd door dit soort op zichzelf staand systeem zonder dat er extra middelen nodig zijn. Echter, net als bij de methode voor het taggen van gegevens, zal de afstamming zich niet bewust zijn van iets dat buiten deze gereguleerde omgeving gebeurt.
Gegevensafstamming door te parseren
Het meest geavanceerde type afstamming is er een die automatisch gegevensverwerkingslogica leest. Voor grondige, end-to-end-tracering voert deze methode reverse-engineering uit op de logica voor gegevenstransformatie.
Aangezien deze oplossing alle programmeertalen en tools die worden gebruikt om de gegevens te converteren en te transporteren, is de implementatie ervan gecompliceerd. Hierbij kan gebruik worden gemaakt van ETL-logica (extract-transform-load), op SQL en Java gebaseerde oplossingen, oude gegevensindelingen, op XML gebaseerde oplossingen en andere technieken.
Gebruikscasussen voor gegevensafstamming
Datamodellering
Bedrijven moeten de onderliggende gegevensstructuren opzetten die hen ondersteunen om de vele gegevensitems en de onderlinge verbanden binnen een bedrijf te visualiseren. Deze verbindingen worden gemodelleerd met behulp van data lineage, wat ook de vele afhankelijkheden laat zien die aanwezig zijn in het data-ecosysteem.
Aangezien gegevens in de loop van de tijd veranderen, verschijnen er constant nieuwe gegevensbronnen, die nieuwe gegevensintegraties vereisen, enz. Hierdoor moeten de algemene gegevensmodellen van bedrijven voor het beheer van hun gegevens eveneens veranderen om de omgeving te weerspiegelen.
Conformiteit
Data lineage biedt een nalevingsmethode voor auditing, het verbeteren van risicobeheer en ervoor zorgen dat gegevens worden bewaard en verwerkt in overeenstemming met het beleid en de wetten op het gebied van gegevensbeheer.
Impactanalyse
De effecten van bepaalde bedrijfsveranderingen, zoals downstream-rapportage, kunnen worden bekeken met behulp van data lineage-tools. Gegevensafstamming kan leidinggevenden bijvoorbeeld helpen bij het bepalen op hoeveel dashboards een naamswijziging van invloed is en, bijgevolg, hoeveel mensen toegang hebben tot die rapportage.
Data migratie
Organisaties passen gegevensmigratie toe om te begrijpen waar de gegevens zich bevinden en hoe lang ze daar al zijn voordat ze naar een nieuw opslagsysteem worden verplaatst of nieuwe software worden geïmplementeerd.
Gegevensafstamming helpt teams zich voor te bereiden op systeemupgrades of migraties door hen een overzicht te geven van hoe de gegevens zich door de organisatie hebben verplaatst. Dit versnelt de overdracht naar de nieuwe opslagomgeving in het algemeen.
Bovendien geeft het teams de kans om het datasysteem te ontsleutelen door verouderde of nutteloze data te archiveren of te verwijderen. Door dit te doen, zal het datasysteem over het algemeen beter presteren en minder databeheer nodig hebben.
Uitdagingen bij het implementeren van gegevensafstamming
- Gegevensbeveiliging: gegevensbeveiliging is een primaire zorg bij het opbouwen van gegevensafstamming. Om een datareis vanaf het startpunt tot aan de eindbestemming te volgen, moet toegang worden verleend tot gevoelige gegevens en moeten deze gegevens worden beschermd tegen ongeoorloofde toegang en inbreuken.
- Gebrek aan standaardisatie: een van de belangrijkste belemmeringen voor het omarmen van data-afstamming is het gebrek aan standaarden. Aangezien veel platforms, apps en systemen unieke methoden gebruiken voor het volgen en vastleggen van de herkomst van gegevens, kan het moeilijk zijn om een samenhangend beeld van een gegevenstraject samen te stellen.
- Datasilo's: Datasilo's zijn een ander probleem dat zich voordoet bij het implementeren van datalijn. Wanneer gegevens verspreid zijn over verschillende applicaties en systemen, kan het een uitdaging zijn om de reis van de ene naar de andere te volgen. Dit kan leiden tot onnauwkeurige of onvolledige gegevensafstamming.
Conclusie
Concluderend, data-afstamming is een essentieel onderdeel van elke datagedreven onderneming. Het biedt een alomvattend perspectief van het pad van een gegevens vanaf het beginpunt tot het eindpunt, waardoor de nauwkeurigheid, volledigheid en consistentie worden gegarandeerd.
Verwacht wordt dat automatisering en standaardisatie van toekomstige datalijnen zal toenemen, waardoor implementatie en onderhoud voor organisaties eenvoudiger wordt. Uiteindelijk kan het belang van data-afstamming niet worden benadrukt.
Het geeft bedrijven de tools die ze nodig hebben om verstandige keuzes te maken, hun activiteiten efficiënter uit te voeren en succes te behalen.





Laat een reactie achter