AI is overal, maar soms kan het een uitdaging zijn om de terminologie en het jargon te begrijpen. In deze blogpost leggen we meer dan 50 AI-termen en -definities uit, zodat je deze snelgroeiende technologie beter kunt begrijpen.
Of je nu een beginner of een expert bent, we wedden dat er een paar termen zijn die je niet kent!
1. Kunstmatige intelligentie
Artificial Intelligence (AI) verwijst naar de ontwikkeling van computersystemen die het vermogen hebben om onafhankelijk te leren en te functioneren, vaak door menselijke intelligentie na te bootsen.
Deze systemen analyseren gegevens, herkennen patronen, nemen beslissingen en passen hun gedrag aan op basis van ervaring. Door gebruik te maken van algoritmen en modellen, probeert AI intelligente machines te creëren die in staat zijn hun omgeving waar te nemen en te begrijpen.
Het uiteindelijke doel is om machines in staat te stellen taken efficiënt uit te voeren, te leren van gegevens en cognitieve vaardigheden te vertonen die vergelijkbaar zijn met die van mensen.
2. Algoritme
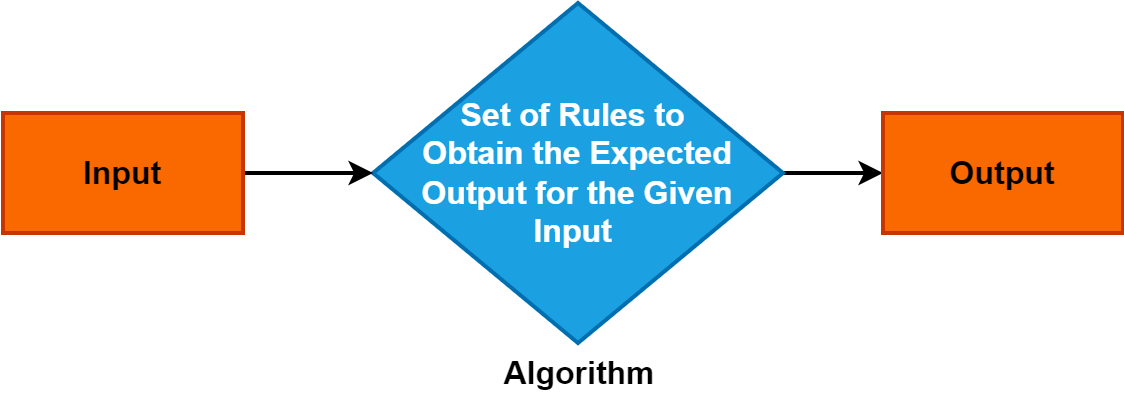
Een algoritme is een nauwkeurige en systematische set instructies of regels die het proces van het oplossen van een probleem of het volbrengen van een specifieke taak begeleiden.
Het dient als een fundamenteel concept in verschillende domeinen en speelt een centrale rol in informatica, wiskunde en probleemoplossende disciplines. Het begrijpen van algoritmen is cruciaal omdat ze efficiënte en gestructureerde probleemoplossende benaderingen mogelijk maken, waardoor technologische vooruitgang en besluitvormingsprocessen worden gestimuleerd.
3. Big data
Big data verwijst naar extreem grote en complexe datasets die de mogelijkheden van traditionele analysemethoden te boven gaan. Deze datasets worden doorgaans gekenmerkt door hun volume, snelheid en verscheidenheid.
Volume verwijst naar de enorme hoeveelheid gegevens die wordt gegenereerd uit verschillende bronnen, zoals social media, sensoren en transacties.
Snelheid verwijst naar de hoge snelheid waarmee gegevens worden gegenereerd en in realtime of bijna in realtime moeten worden verwerkt. Verscheidenheid betekent de diverse soorten en formaten van gegevens, inclusief gestructureerde, ongestructureerde en semi-gestructureerde gegevens.
4. Datamining
Datamining is een veelomvattend proces gericht op het extraheren van waardevolle inzichten uit enorme datasets.
Het omvat vier hoofdfasen: gegevensverzameling, waarbij relevante gegevens worden verzameld; gegevensvoorbereiding, zorgen voor gegevenskwaliteit en compatibiliteit; de gegevens ontginnen, algoritmen gebruiken om patronen en relaties te ontdekken; en data-analyse en interpretatie, waarbij de geëxtraheerde kennis wordt onderzocht en begrepen.
5. Neuraal netwerk
Een computersysteem is ontworpen om te werken zoals het menselijk brein, samengesteld uit onderling verbonden knooppunten of neuronen. Laten we dit een beetje beter begrijpen, aangezien de meeste AI is gebaseerd op neurale netwerken.
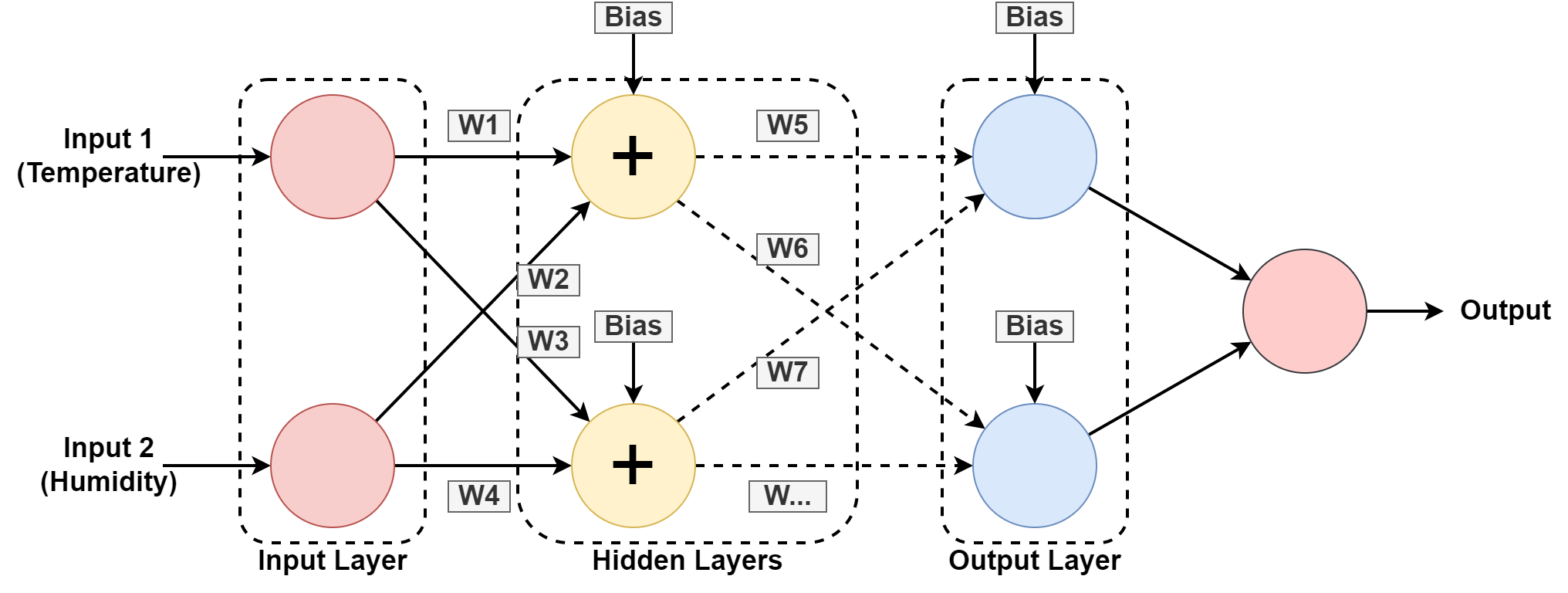
In de bovenstaande afbeeldingen voorspellen we de vochtigheid en temperatuur van een geografische locatie door te leren van het patroon uit het verleden. De invoer is de dataset voor het vorige record.
De neuraal netwerk leert het patroon door met gewichten te spelen en biaswaarden toe te passen in de verborgen lagen. W1, W2….W7 zijn de respectievelijke gewichten. Het traint zichzelf op de verstrekte dataset en geeft output als voorspelling.
U kunt overweldigd raken door deze complexe informatie. Als dit het geval is, kun je beginnen met onze eenvoudige handleiding hier.
6. Machine learning
Machine learning richt zich op het ontwikkelen van algoritmen en modellen die in staat zijn om automatisch van gegevens te leren en hun prestaties in de loop van de tijd te verbeteren.
Het omvat het gebruik van statistische technieken om computers in staat te stellen patronen te identificeren, voorspellingen te doen en gegevensgestuurde beslissingen te nemen zonder expliciet geprogrammeerd te zijn.
Algoritmen voor het leren van machines analyseer en leer van grote datasets, waardoor systemen hun gedrag kunnen aanpassen en verbeteren op basis van de informatie die ze verwerken.
7. Diep leren
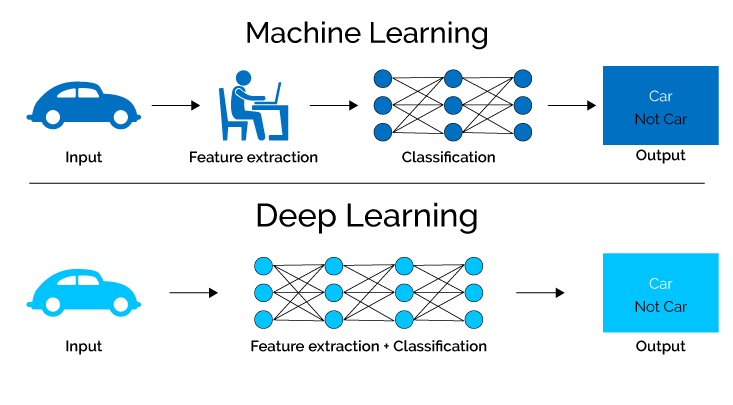
Diepe leer, een deelgebied van machine learning en neurale netwerken, maakt gebruik van geavanceerde algoritmen om kennis uit gegevens te halen door de ingewikkelde processen van het menselijk brein te simuleren.
Door gebruik te maken van neurale netwerken met tal van verborgen lagen, kunnen deep learning-modellen autonoom ingewikkelde kenmerken en patronen extraheren, waardoor ze complexe taken met uitzonderlijke nauwkeurigheid en efficiëntie kunnen uitvoeren.
8. Patroonherkenning
Patroonherkenning, een data-analysetechniek, maakt gebruik van de kracht van machine learning-algoritmen om autonoom patronen en regelmatigheden binnen datasets te detecteren en te onderscheiden.
Door gebruik te maken van rekenmodellen en statistische methoden, kunnen patroonherkenningsalgoritmen betekenisvolle structuren, correlaties en trends in complexe en diverse gegevens identificeren.
Dit proces maakt het extraheren van waardevolle inzichten mogelijk, classificatie van gegevens in verschillende categorieën en voorspelling van toekomstige resultaten op basis van erkende patronen. Patroonherkenning is een essentieel hulpmiddel in verschillende domeinen, waardoor besluitvorming, afwijkingsdetectie en voorspellende modellen mogelijk worden.
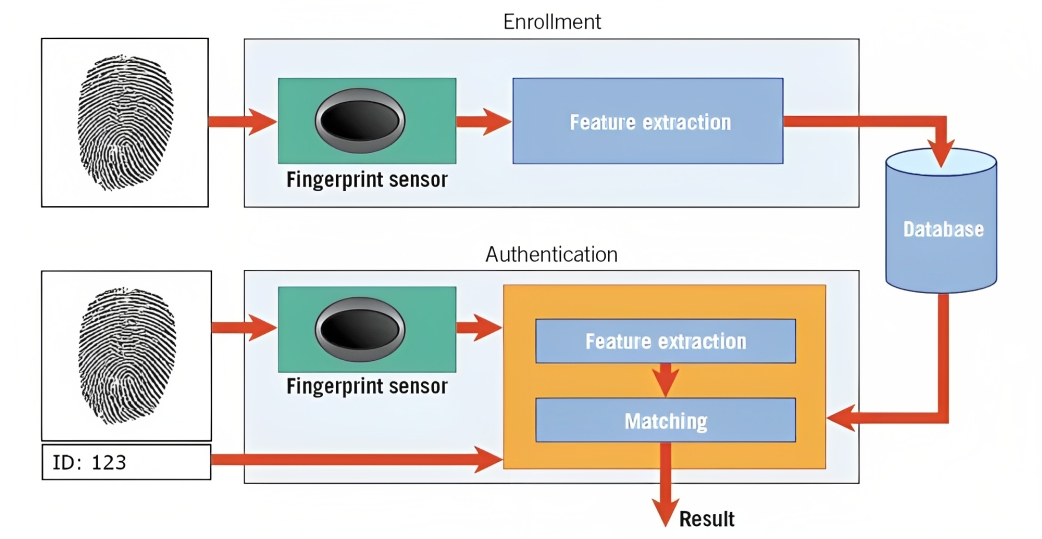
Biometrie is daar een voorbeeld van. Bij vingerafdrukherkenning analyseert het algoritme bijvoorbeeld de ribbels, rondingen en unieke kenmerken van iemands vingerafdruk om een digitale representatie te creëren die een sjabloon wordt genoemd.
Wanneer u probeert uw smartphone te ontgrendelen of toegang te krijgen tot een beveiligde faciliteit, vergelijkt het patroonherkenningssysteem de vastgelegde biometrische gegevens (bijvoorbeeld vingerafdrukken) met de opgeslagen sjablonen in zijn database.
Door de patronen te matchen en het niveau van overeenkomst te beoordelen, kan het systeem bepalen of de verstrekte biometrische gegevens overeenkomen met de opgeslagen sjabloon en dienovereenkomstig toegang verlenen.
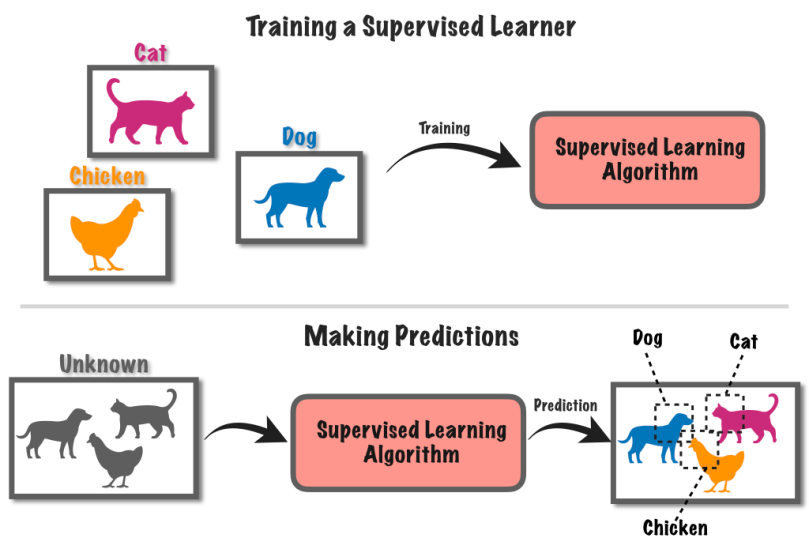
9. Begeleid leren
Supervised learning is een machine learning-benadering waarbij een computersysteem wordt getraind met behulp van gelabelde gegevens. Bij deze methode wordt de computer voorzien van een set invoergegevens samen met bijbehorende bekende labels of uitkomsten.
Laten we zeggen dat je een heleboel foto's hebt, sommige met honden en sommige met katten.
Je vertelt de computer op welke foto's honden staan en op welke katten. De computer leert vervolgens de verschillen tussen honden en katten te herkennen door patronen in de plaatjes te zoeken.
Nadat het leert, kunt u de computer nieuwe afbeeldingen geven en zal het proberen te achterhalen of ze honden of katten hebben op basis van wat het heeft geleerd van de gelabelde voorbeelden. Het is alsof je een computer traint om voorspellingen te doen op basis van bekende informatie.
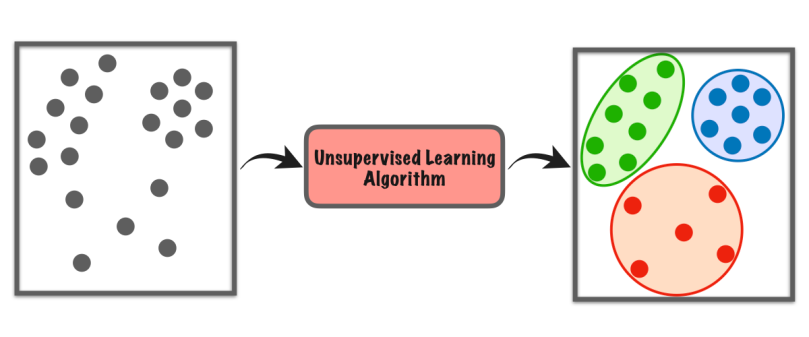
10. Ongecontroleerd leren
Unsupervised learning is een vorm van machinaal leren waarbij de computer zelf een dataset verkent om patronen of overeenkomsten te vinden zonder specifieke instructies.
Het is niet afhankelijk van gelabelde voorbeelden zoals bij begeleid leren. In plaats daarvan zoekt het naar verborgen structuren of groepen in de gegevens. Het is alsof de computer zelf dingen ontdekt, zonder dat een leraar hem vertelt waarnaar hij moet zoeken.
Dit type leren helpt ons nieuwe inzichten te vinden, gegevens te ordenen of ongebruikelijke dingen te identificeren zonder voorafgaande kennis of expliciete begeleiding.
11. Natuurlijke taalverwerking (NLP)
Natural Language Processing richt zich op hoe computers menselijke taal begrijpen en ermee omgaan. Het helpt computers menselijke taal te analyseren, interpreteren en erop te reageren op een manier die voor ons natuurlijker aanvoelt.
NLP maakt het voor ons mogelijk om te communiceren met spraakassistenten en chatbots, en zelfs om onze e-mails automatisch in mappen te laten sorteren.
Het gaat erom computers te leren de betekenis achter woorden, zinnen en zelfs hele teksten te begrijpen, zodat ze ons bij verschillende taken kunnen helpen en onze interacties met technologie naadloos kunnen laten verlopen.
12. Computervisie
Computer visie is een fascinerende technologie waarmee computers afbeeldingen en video's kunnen zien en begrijpen, net zoals wij mensen dat doen met onze ogen. Het gaat erom computers te leren visuele informatie te analyseren en te begrijpen wat ze zien.
In eenvoudiger bewoordingen helpt computervisie computers de visuele wereld te herkennen en te interpreteren. Het omvat taken zoals ze leren om specifieke objecten in afbeeldingen te identificeren, afbeeldingen in verschillende categorieën te classificeren of zelfs afbeeldingen in betekenisvolle delen te verdelen.
Stel je een zelfrijdende auto voor die computervisie gebruikt om de weg en alles eromheen te 'zien'.
Het kan voetgangers, verkeersborden en andere voertuigen detecteren en volgen, zodat ze veilig kunnen navigeren. Of bedenk hoe gezichtsherkenningstechnologie computervisie gebruikt om onze smartphones te ontgrendelen of onze identiteit te verifiëren door onze unieke gelaatstrekken te herkennen.
Het wordt ook gebruikt in bewakingssystemen om drukke plaatsen in de gaten te houden en verdachte activiteiten op te sporen.
Computervisie is een krachtige technologie die een wereld aan mogelijkheden opent. Door computers in staat te stellen visuele informatie te zien en te begrijpen, kunnen we toepassingen en systemen ontwikkelen die de wereld om ons heen kunnen waarnemen en interpreteren, waardoor ons leven gemakkelijker, veiliger en efficiënter wordt.
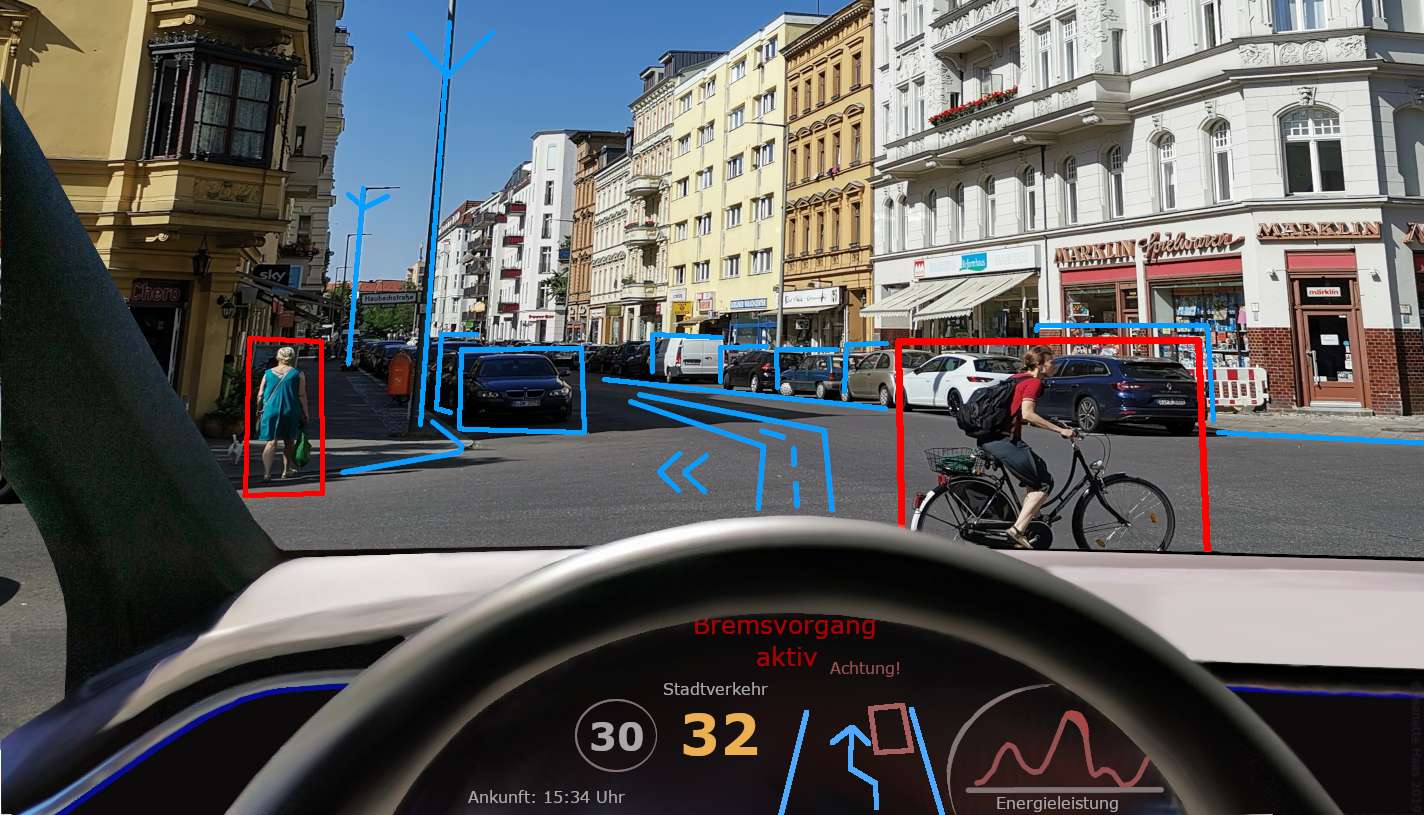
13.Chatbot
Een chatbot is als een computerprogramma dat met mensen kan praten op een manier die lijkt op een echt menselijk gesprek.
Het wordt vaak gebruikt in de online klantenservice om klanten te helpen en ze het gevoel te geven dat ze met een persoon praten, ook al is het eigenlijk een programma dat op een computer draait.
De chatbot kan berichten of vragen van klanten begrijpen en erop reageren, en nuttige informatie en hulp bieden, net zoals een menselijke klantenservicemedewerker dat zou doen.
14. Spraakherkenning
Spraakherkenning verwijst naar het vermogen van een computersysteem om menselijke spraak te begrijpen en te interpreteren. Het gaat om de technologie die een computer of apparaat in staat stelt om te "luisteren" naar gesproken woorden en deze om te zetten in tekst of commando's die het kan begrijpen.
met spraakherkenning, kunt u communiceren met apparaten of applicaties door simpelweg tegen ze te praten in plaats van te typen of andere invoermethoden te gebruiken.
Het systeem analyseert de gesproken woorden, herkent de patronen en geluiden en vertaalt deze vervolgens naar begrijpelijke tekst of handelingen. Het maakt handsfree en natuurlijke communicatie met technologie mogelijk, waardoor taken zoals spraakopdrachten, dicteren of spraakgestuurde interacties mogelijk worden. De meest voorkomende voorbeelden zijn de AI-assistenten zoals Siri en Google Assistant.
15. Sentimentanalyse
Sentiment analyse is een techniek die wordt gebruikt om de emoties, meningen en attitudes uitgedrukt in tekst of spraak te begrijpen en te interpreteren. Het omvat het analyseren van geschreven of gesproken taal om te bepalen of het uitgedrukte sentiment positief, negatief of neutraal is.
Met behulp van algoritmen voor machine learning kunnen algoritmen voor sentimentanalyse grote hoeveelheden tekstgegevens scannen en analyseren, zoals klantrecensies, berichten op sociale media of feedback van klanten, om het onderliggende sentiment achter de woorden te identificeren.
De algoritmen zoeken naar specifieke woorden, zinnen of patronen die emoties of meningen aangeven.
Deze analyse helpt bedrijven of individuen te begrijpen hoe mensen over een product, dienst of onderwerp denken en kan worden gebruikt om op gegevens gebaseerde beslissingen te nemen of inzicht te krijgen in de voorkeuren van klanten.
Een bedrijf kan bijvoorbeeld sentimentanalyse gebruiken om klanttevredenheid bij te houden, verbeterpunten te identificeren of de publieke opinie over hun merk te volgen.
16. Automatische vertaling
Machinevertaling, in de context van AI, verwijst naar het gebruik van computeralgoritmen en kunstmatige intelligentie om tekst of spraak automatisch van de ene taal naar de andere te vertalen.
Het omvat het leren van computers om menselijke talen te begrijpen en te verwerken om nauwkeurige vertalingen te leveren. Het meest voorkomende voorbeeld is Google Vertalen.
Met automatische vertaling kunt u tekst of spraak in één taal invoeren en het systeem analyseert de invoer en genereert een overeenkomstige vertaling in een andere taal. Dit is met name handig bij communicatie of toegang tot informatie in verschillende talen.
Machinevertalingssystemen vertrouwen op een combinatie van taalkundige regels, statistische modellen en algoritmen voor machine learning. Ze leren van enorme hoeveelheden taalgegevens om de vertaalnauwkeurigheid in de loop van de tijd te verbeteren. Sommige benaderingen van machinevertaling bevatten ook neurale netwerken om de kwaliteit van vertalingen te verbeteren.
17. Robotics
Robotica is de combinatie van kunstmatige intelligentie en werktuigbouw om intelligente machines te creëren die robots worden genoemd. Deze robots zijn ontworpen om taken autonoom of met minimale menselijke tussenkomst uit te voeren.
Robots zijn fysieke entiteiten die hun omgeving kunnen waarnemen, beslissingen kunnen nemen op basis van die sensorische input en specifieke acties of taken kunnen uitvoeren.
Ze zijn uitgerust met verschillende sensoren, zoals camera's, microfoons of aanraaksensoren, waarmee ze informatie uit de wereld om hen heen kunnen verzamelen. Met behulp van AI-algoritmen en programmering kunnen robots deze gegevens analyseren, interpreteren en intelligente beslissingen nemen om hun toegewezen taken uit te voeren.
AI speelt een cruciale rol in de robotica door robots in staat te stellen te leren van hun ervaringen en zich aan te passen aan verschillende situaties.
Machine learning-algoritmen kunnen worden gebruikt om robots te trainen om objecten te herkennen, door omgevingen te navigeren of zelfs met mensen om te gaan. Hierdoor kunnen robots veelzijdiger, flexibeler en beter in staat zijn om complexe taken uit te voeren.
18. drones
Drones zijn een soort robot die in de lucht kan vliegen of zweven zonder een menselijke piloot aan boord. Ze worden ook wel onbemande luchtvaartuigen (UAV's) genoemd. Drones zijn uitgerust met verschillende sensoren, zoals camera's, gps en gyroscopen, waarmee ze gegevens kunnen verzamelen en door hun omgeving kunnen navigeren.
Ze worden op afstand bestuurd door een menselijke operator of kunnen autonoom werken met behulp van voorgeprogrammeerde instructies.
Drones dienen een breed scala aan doeleinden, waaronder luchtfotografie en videografie, landmetingen en kaarten, bezorgdiensten, zoek- en reddingsmissies, landbouwmonitoring en zelfs recreatief gebruik. Ze hebben toegang tot afgelegen of gevaarlijke gebieden die moeilijk of gevaarlijk zijn voor mensen.
19. Augmented Reality (AR)
Augmented reality (AR) is een technologie die de echte wereld combineert met virtuele objecten of informatie om onze waarneming en interactie met de omgeving te verbeteren. Het plaatst door de computer gegenereerde afbeeldingen, geluiden of andere zintuiglijke inputs op de echte wereld, waardoor een meeslepende en interactieve ervaring ontstaat.
Simpel gezegd, stel je voor dat je een speciale bril draagt of je smartphone gebruikt om de wereld om je heen te zien, maar dan met toegevoegde virtuele elementen.
U kunt bijvoorbeeld uw smartphone op een straat in de stad richten en virtuele wegwijzers zien met routebeschrijvingen, beoordelingen en recensies voor restaurants in de buurt of zelfs virtuele personages die interactie hebben met de echte omgeving.
Deze virtuele elementen gaan naadloos over in de echte wereld, waardoor uw begrip en ervaring van de omgeving wordt verbeterd. Augmented reality kan op verschillende gebieden worden gebruikt, zoals gaming, onderwijs, architectuur en zelfs voor alledaagse taken zoals navigatie of het uitproberen van nieuwe meubels in uw huis voordat u ze koopt.
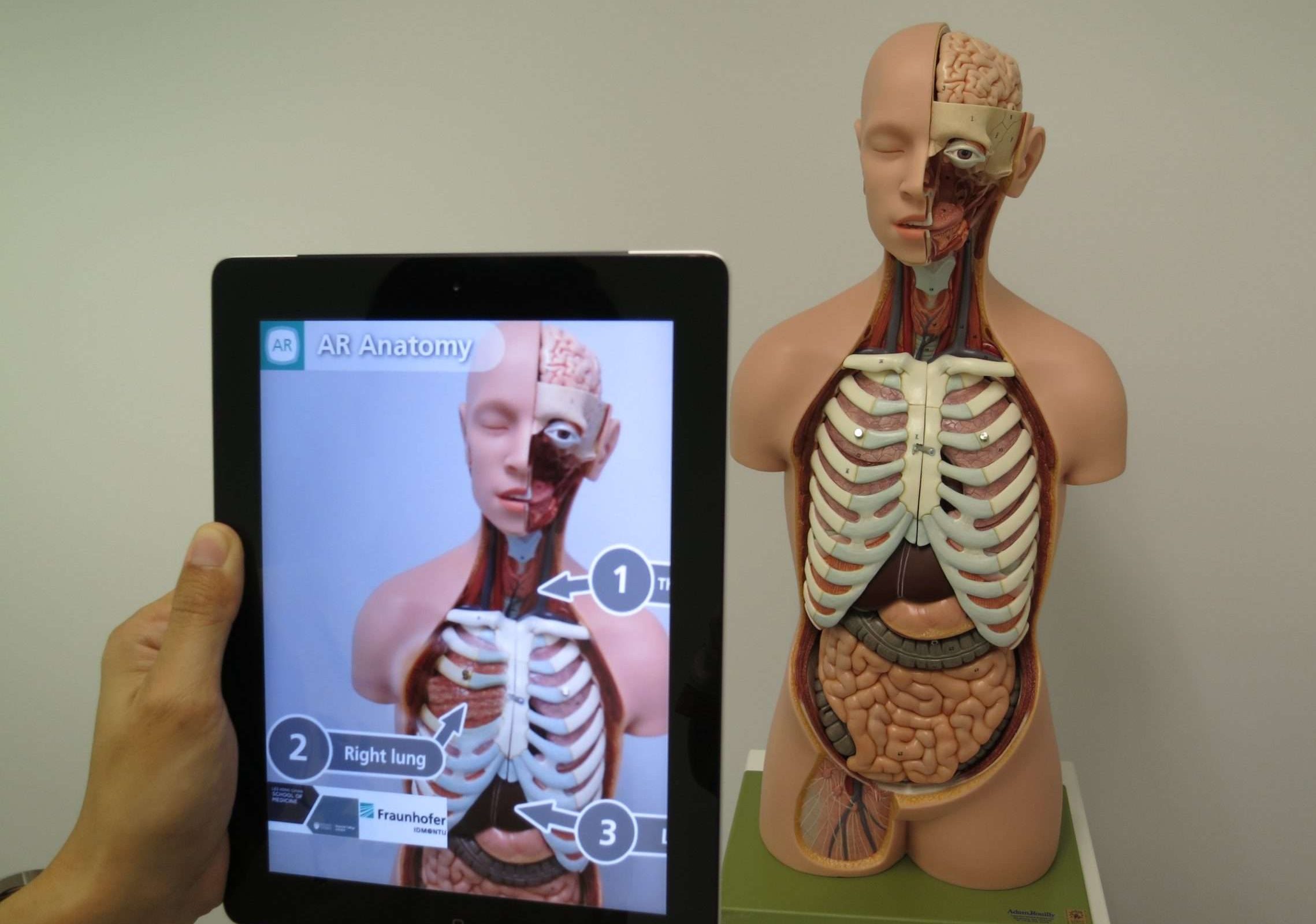
20. Virtuele Realiteit (VR)
Virtual reality (VR) is een technologie die computergegenereerde simulaties gebruikt om een kunstmatige omgeving te creëren die een persoon kan verkennen en waarmee hij kan communiceren. Het dompelt de gebruiker onder in een virtuele wereld, blokkeert de echte wereld en vervangt deze door een digitale wereld.
Simpel gezegd, stel je voor dat je een speciale headset opzet die je ogen en oren bedekt en je naar een heel andere plek brengt. In deze virtuele wereld voelt alles wat je ziet en hoort ongelooflijk echt, ook al wordt het allemaal gegenereerd door een computer.
Je kunt je verplaatsen, in elke richting kijken en interactie hebben met objecten of personages alsof ze fysiek aanwezig zijn.
In een virtual reality-game bevindt u zich bijvoorbeeld in een middeleeuws kasteel, waar u door de gangen kunt lopen, wapens kunt oppakken en zwaardgevechten kunt aangaan met virtuele tegenstanders. De virtual reality-omgeving reageert op uw bewegingen en acties, waardoor u zich volledig ondergedompeld en betrokken voelt bij de ervaring.
Virtual reality wordt niet alleen gebruikt voor gaming, maar ook voor verschillende andere toepassingen, zoals trainingssimulaties voor piloten, chirurgen of militair personeel, architecturale walkthroughs, virtueel toerisme en zelfs therapie voor bepaalde psychologische aandoeningen. Het creëert een gevoel van aanwezigheid en neemt gebruikers mee naar nieuwe en opwindende virtuele werelden, waardoor de ervaring zo dicht mogelijk bij de werkelijkheid komt te staan.
21. Gegevenswetenschap
Gegevenswetenschap is een vakgebied waarbij wetenschappelijke methoden, tools en algoritmen worden gebruikt om waardevolle kennis en inzichten uit gegevens te halen. Het combineert elementen van wiskunde, statistiek, programmeren en domeinexpertise om grote en complexe datasets te analyseren.
In eenvoudiger bewoordingen gaat datawetenschap over het vinden van zinvolle informatie en patronen die verborgen zijn in een hoop gegevens. Het omvat het verzamelen, opschonen en ordenen van gegevens en vervolgens het gebruik van verschillende technieken om deze te verkennen en te analyseren. Data wetenschappers gebruik statistische modellen en algoritmen om trends te ontdekken, voorspellingen te doen en problemen op te lossen.
Op het gebied van gezondheidszorg kan datawetenschap bijvoorbeeld worden gebruikt om patiëntendossiers en medische gegevens te analyseren om risicofactoren voor ziekten te identificeren, patiëntresultaten te voorspellen of behandelplannen te optimaliseren. In het bedrijfsleven kan datawetenschap worden toegepast op klantgegevens om hun voorkeuren te begrijpen, producten aan te bevelen of marketingstrategieën te verbeteren.
22. Gegevensruzie
Data wrangling, ook wel data munging genoemd, is het proces van het verzamelen, opschonen en transformeren van onbewerkte data in een formaat dat nuttiger en geschikter is voor analyse. Het omvat het verwerken en voorbereiden van gegevens om de kwaliteit, consistentie en compatibiliteit met analysetools of -modellen te waarborgen.
In eenvoudiger bewoordingen is het worstelen met gegevens als het bereiden van ingrediënten om te koken. Het omvat het verzamelen van gegevens uit verschillende bronnen, het sorteren en opschonen om eventuele fouten, inconsistenties of irrelevante informatie te verwijderen.
Bovendien moeten gegevens mogelijk worden getransformeerd, geherstructureerd of geaggregeerd om het gemakkelijker te maken om ermee te werken en er inzichten uit te halen.
Gegevensruzie kan bijvoorbeeld bestaan uit het verwijderen van dubbele vermeldingen, het corrigeren van spelfouten of opmaakproblemen, het verwerken van ontbrekende waarden en het converteren van gegevenstypen. Het kan ook gaan om het samenvoegen of samenvoegen van verschillende datasets, het splitsen van gegevens in subsets of het creëren van nieuwe variabelen op basis van bestaande gegevens.
23. Verhalen van gegevens
Verhalen van gegevens is de kunst van het presenteren van gegevens op een boeiende en boeiende manier om een verhaal of boodschap effectief over te brengen. Het gaat om het gebruiken datavisualisaties, verhalen en context om inzichten en bevindingen over te brengen op een manier die begrijpelijk en gedenkwaardig is voor het publiek.
In eenvoudiger bewoordingen gaat data storytelling over het gebruik van data om een verhaal te vertellen. Het gaat verder dan alleen het presenteren van cijfers en grafieken. Het omvat het maken van een verhaal rond de gegevens, waarbij visuele elementen en verteltechnieken worden gebruikt om de gegevens tot leven te brengen en herkenbaar te maken voor het publiek.
In plaats van simpelweg een tabel met verkoopcijfers te presenteren, kan data storytelling bijvoorbeeld het creëren van een interactief dashboard inhouden waarmee gebruikers de verkooptrends visueel kunnen verkennen.
Het kan een verhaal bevatten waarin de belangrijkste bevindingen worden belicht, de redenen achter de trends worden uitgelegd en bruikbare aanbevelingen worden gedaan op basis van de gegevens.
24. Gegevensgestuurde besluitvorming
Datagedreven besluitvorming is een proces van het maken van keuzes of het ondernemen van acties op basis van de analyse en interpretatie van relevante gegevens. Het gaat om het gebruik van gegevens als basis om besluitvormingsprocessen te begeleiden en te ondersteunen in plaats van uitsluitend te vertrouwen op intuïtie of persoonlijk oordeel.
In eenvoudiger bewoordingen betekent gegevensgestuurde besluitvorming het gebruik van feiten en bewijzen uit gegevens om de keuzes die we maken te onderbouwen en te sturen. Het omvat het verzamelen en analyseren van gegevens om patronen, trends en relaties te begrijpen en die kennis te gebruiken om weloverwogen beslissingen te nemen en problemen op te lossen.
In een zakelijke omgeving kan gegevensgestuurde besluitvorming bijvoorbeeld het analyseren van verkoopgegevens, feedback van klanten en markttrends inhouden om de meest effectieve prijsstrategie te bepalen of gebieden voor verbetering in productontwikkeling te identificeren.
In de gezondheidszorg kan het gaan om het analyseren van patiëntgegevens om behandelplannen te optimaliseren of ziekteresultaten te voorspellen.
25. Gegevensmeer
Een data lake is een gecentraliseerde en schaalbare datarepository die enorme hoeveelheden data opslaat in zijn onbewerkte en onverwerkte vorm. Het is ontworpen om een breed scala aan gegevenstypen, formaten en structuren te bevatten, zoals gestructureerde, semi-gestructureerde en ongestructureerde gegevens, zonder dat vooraf gedefinieerde schema's of gegevenstransformaties nodig zijn.
Een bedrijf kan bijvoorbeeld gegevens uit verschillende bronnen, zoals websitelogboeken, klanttransacties, feeds van sociale media en IoT-apparaten, verzamelen en opslaan in een datameer.
Deze gegevens kunnen vervolgens voor verschillende doeleinden worden gebruikt, zoals het uitvoeren van geavanceerde analyses, het uitvoeren van machine learning-algoritmen of het onderzoeken van patronen en trends in klantgedrag.
26. Datawarehouse
Een datawarehouse is een gespecialiseerd databasesysteem dat speciaal is ontworpen voor het opslaan, organiseren en analyseren van grote hoeveelheden gegevens uit verschillende bronnen. Het is zo gestructureerd dat het efficiënt ophalen van gegevens en complexe analytische vragen ondersteunt.
Het dient als een centrale opslagplaats die gegevens uit verschillende operationele systemen integreert, zoals transactiedatabases, CRM-systemen en andere gegevensbronnen binnen een organisatie.
De gegevens worden getransformeerd, opgeschoond en in het datawarehouse geladen in een gestructureerd formaat dat is geoptimaliseerd voor analytische doeleinden.
27. Bedrijfsintelligentie (BI)
Business intelligence verwijst naar het proces van het verzamelen, analyseren en presenteren van gegevens op een manier die bedrijven helpt weloverwogen beslissingen te nemen en waardevolle inzichten te verkrijgen. Het omvat het gebruik van verschillende tools, technologieën en technieken om onbewerkte gegevens om te zetten in zinvolle, bruikbare informatie.
Een business intelligence-systeem kan bijvoorbeeld verkoopgegevens analyseren om de meest winstgevende producten te identificeren, voorraadniveaus te bewaken en klantvoorkeuren te volgen.
Het kan real-time inzicht bieden in key performance indicators (KPI's) zoals omzet, klantacquisitie of productprestaties, waardoor bedrijven op gegevens gebaseerde beslissingen kunnen nemen en passende maatregelen kunnen nemen om hun activiteiten te verbeteren.
Tools voor bedrijfsinformatie bevatten vaak functies zoals gegevensvisualisatie, ad-hocquery's en mogelijkheden voor gegevensverkenning. Deze tools stellen gebruikers in staat, zoals bedrijfsanalisten of managers, om te interageren met de gegevens, deze te snijden en te dobbelen, en rapporten of visuele weergaven te genereren die belangrijke inzichten en trends benadrukken.
28. Voorspellende analyses
Voorspellende analyse is de praktijk van het gebruik van gegevens en statistische technieken om weloverwogen voorspellingen of voorspellingen te doen over toekomstige gebeurtenissen of resultaten. Het omvat het analyseren van historische gegevens, het identificeren van patronen en het bouwen van modellen om toekomstige trends, gedragingen of gebeurtenissen te extrapoleren en in te schatten.
Het heeft tot doel relaties tussen variabelen bloot te leggen en die informatie te gebruiken om voorspellingen te doen. Het gaat verder dan alleen het beschrijven van gebeurtenissen uit het verleden; in plaats daarvan maakt het gebruik van historische gegevens om te begrijpen en te anticiperen op wat er waarschijnlijk in de toekomst gaat gebeuren.
Op het gebied van financiën kan bijvoorbeeld voorspellende analyse worden gebruikt om te voorspellen voorraad prijzen op basis van historische marktgegevens, economische indicatoren en andere relevante factoren.
In marketing kan het worden gebruikt om het gedrag en de voorkeuren van klanten te voorspellen, waardoor gerichte advertenties en gepersonaliseerde marketingcampagnes mogelijk worden.
In de gezondheidszorg kan voorspellende analyse helpen bij het identificeren van patiënten met een hoog risico op bepaalde ziekten of het voorspellen van de waarschijnlijkheid van heropname op basis van medische geschiedenis en andere factoren.
29. Prescriptieve analyses
Prescriptieve analyse is de toepassing van gegevens en analyses om de best mogelijke acties te bepalen die in een bepaalde situatie of besluitvormingsscenario kunnen worden ondernomen.
Het gaat verder dan beschrijvend en predictive analytics door niet alleen inzicht te geven in wat er in de toekomst zou kunnen gebeuren, maar ook de meest optimale manier van handelen aan te bevelen om een gewenst resultaat te bereiken.
Het combineert historische gegevens, voorspellende modellen en optimalisatietechnieken om verschillende scenario's te simuleren en de mogelijke uitkomsten van verschillende beslissingen te evalueren. Het houdt rekening met meerdere beperkingen, doelstellingen en factoren om bruikbare aanbevelingen te genereren die de gewenste resultaten maximaliseren of risico's minimaliseren.
Bijvoorbeeld, in toeleveringsketen management, prescriptieve analyses kunnen gegevens over voorraadniveaus, productiecapaciteiten, transportkosten en klantvraag analyseren om het meest efficiënte distributieplan te bepalen.
Het kan de ideale toewijzing van middelen aanbevelen, zoals voorraadopslaglocaties of transportroutes, om kosten te minimaliseren en tijdige levering te garanderen.
30. Datagestuurde marketing
Datagestuurde marketing verwijst naar de praktijk van het gebruik van gegevens en analyses om marketingstrategieën, campagnes en besluitvormingsprocessen aan te sturen.
Het omvat het gebruik van verschillende gegevensbronnen om inzicht te krijgen in klantgedrag, voorkeuren en trends en die informatie te gebruiken om marketinginspanningen te optimaliseren.
Het richt zich op het verzamelen en analyseren van gegevens van meerdere contactpunten, zoals website-interacties, betrokkenheid bij sociale media, demografische gegevens van klanten, aankoopgeschiedenis en meer. Deze gegevens worden vervolgens gebruikt om een uitgebreid inzicht te krijgen in de doelgroep, hun voorkeuren en hun behoeften.
Door gegevens te benutten, kunnen marketeers weloverwogen beslissingen nemen met betrekking tot klantsegmentatie, targeting en personalisatie.
Ze kunnen specifieke klantsegmenten identificeren die eerder positief reageren op marketingcampagnes en hun berichten en aanbiedingen daarop afstemmen.
Daarnaast helpt datagedreven marketing bij het optimaliseren van marketingkanalen, het bepalen van de meest effectieve marketingmix en het meten van het succes van marketinginitiatieven.
Een datagestuurde marketingbenadering kan bijvoorbeeld het analyseren van klantgegevens inhouden om koopgedrag en voorkeurspatronen te identificeren. Op basis van deze inzichten kunnen marketeers gerichte campagnes opzetten met gepersonaliseerde content en aanbiedingen die aansluiten bij specifieke klantsegmenten.
Door continue analyse en optimalisatie kunnen ze de effectiviteit van hun marketinginspanningen meten en strategieën in de loop van de tijd verfijnen.
31. Gegevensbeheer
Data governance is het raamwerk en de reeks werkwijzen die organisaties toepassen om het juiste beheer, de bescherming en de integriteit van gegevens gedurende de gehele levenscyclus te waarborgen. Het omvat de processen, het beleid en de procedures die bepalen hoe gegevens worden verzameld, opgeslagen, geopend, gebruikt en gedeeld binnen een organisatie.
Het heeft tot doel verantwoording, verantwoordelijkheid en controle over gegevensactiva vast te stellen. Het zorgt ervoor dat gegevens nauwkeurig, volledig, consistent en betrouwbaar zijn, waardoor organisaties weloverwogen beslissingen kunnen nemen, de gegevenskwaliteit kunnen behouden en kunnen voldoen aan wettelijke vereisten.
Gegevensbeheer omvat het definiëren van rollen en verantwoordelijkheden voor gegevensbeheer, het vaststellen van gegevensstandaarden en -beleid, en het implementeren van processen om naleving te bewaken en af te dwingen. Het behandelt verschillende aspecten van gegevensbeheer, waaronder gegevensprivacy, gegevensbeveiliging, gegevenskwaliteit, gegevensclassificatie en gegevenslevenscyclusbeheer.
Data governance kan bijvoorbeeld het implementeren van procedures omvatten om ervoor te zorgen dat persoonlijke of gevoelige gegevens worden behandeld in overeenstemming met de toepasselijke privacyregelgeving, zoals de Algemene Verordening Gegevensbescherming (AVG).
Het kan ook het vaststellen van gegevenskwaliteitsnormen en het implementeren van gegevensvalidatieprocessen omvatten om ervoor te zorgen dat gegevens nauwkeurig en betrouwbaar zijn.
32. Gegevensbeveiliging
Gegevensbeveiliging gaat over het beschermen van onze waardevolle informatie tegen ongeoorloofde toegang of diefstal. Het gaat om het nemen van maatregelen om de vertrouwelijkheid, integriteit en beschikbaarheid van gegevens te beschermen.
In wezen betekent het ervoor te zorgen dat alleen de juiste mensen toegang hebben tot onze gegevens, dat deze nauwkeurig en ongewijzigd blijven en dat ze beschikbaar zijn wanneer dat nodig is.
Om gegevensbeveiliging te bereiken, worden verschillende strategieën en technologieën gebruikt. Zo helpen toegangscontroles en versleutelingsmethoden de toegang tot geautoriseerde personen of systemen te beperken, waardoor het voor buitenstaanders moeilijker wordt om toegang te krijgen tot onze gegevens.
Bewakingssystemen, firewalls en inbraakdetectiesystemen fungeren als bewakers, waarschuwen ons voor verdachte activiteiten en voorkomen ongeoorloofde toegang.
33. internet van dingen
Het Internet of Things (IoT) verwijst naar een netwerk van fysieke objecten of "dingen" die met internet zijn verbonden en met elkaar kunnen communiceren. Het is als een groot web van alledaagse voorwerpen, apparaten en machines die in staat zijn om informatie te delen en taken uit te voeren door middel van interactie via internet.
In eenvoudige bewoordingen houdt IoT in dat er "slimme" mogelijkheden worden gegeven aan verschillende objecten of apparaten die traditioneel niet met internet waren verbonden. Deze objecten kunnen huishoudelijke apparaten, draagbare apparaten, thermostaten, auto's en zelfs industriële machines zijn.
Door deze objecten met internet te verbinden, kunnen ze gegevens verzamelen en delen, instructies ontvangen en taken autonoom of in reactie op gebruikerscommando's uitvoeren.
Een slimme thermostaat kan bijvoorbeeld de temperatuur bewaken, instellingen aanpassen en energieverbruiksrapporten naar een smartphone-app sturen. Een draagbare fitnesstracker kan gegevens over uw fysieke activiteiten verzamelen en voor analyse synchroniseren met een cloudgebaseerd platform.
34. Beslisboom
Een beslissingsboom is een visuele weergave of diagram dat ons helpt beslissingen te nemen of een handelwijze te bepalen op basis van een reeks keuzes of voorwaarden.
Het is als een stroomschema dat ons door een besluitvormingsproces leidt door verschillende opties en hun mogelijke resultaten te overwegen.
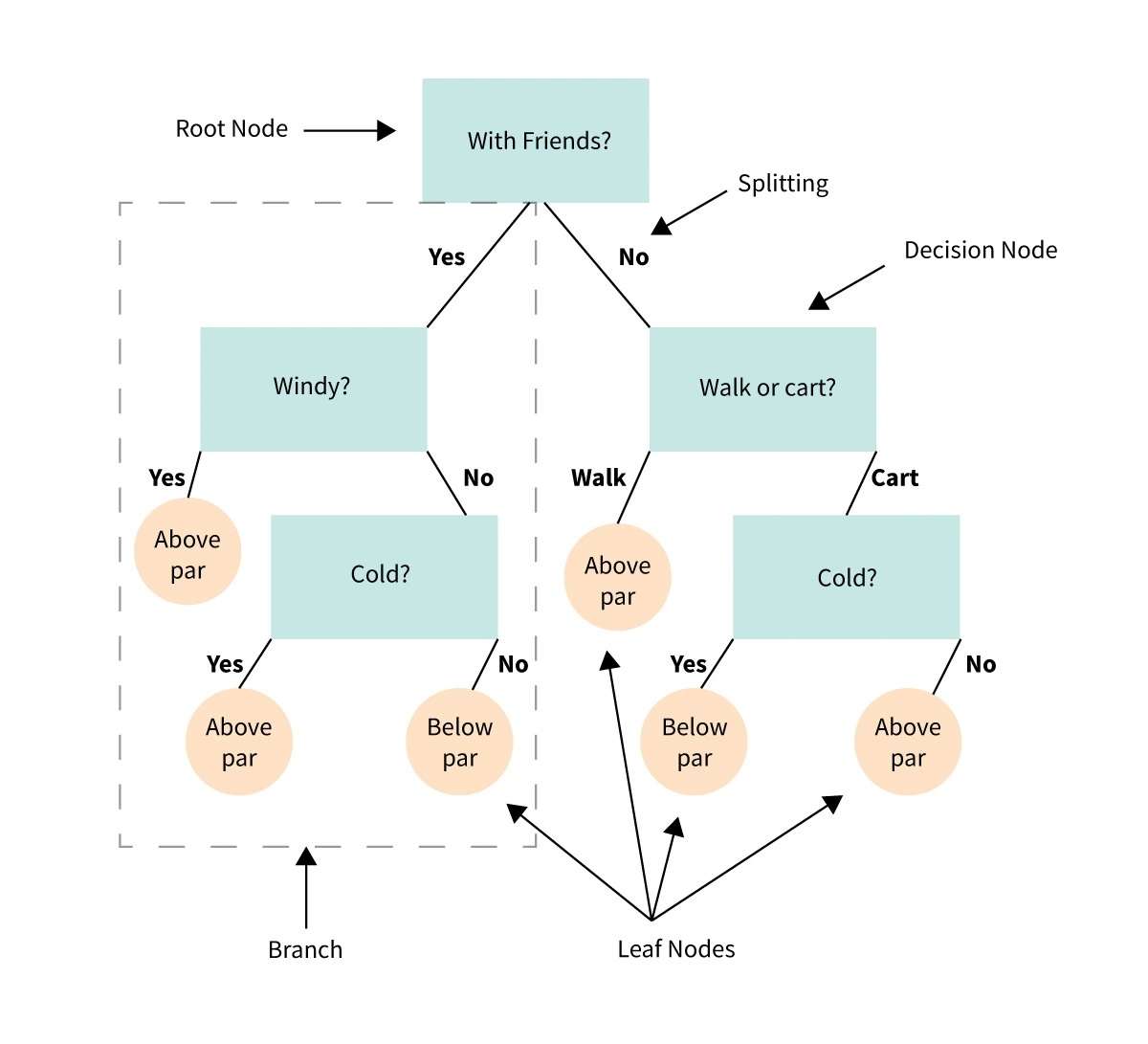
Stel je hebt een probleem of een vraag en je moet een keuze maken.
Een beslissingsboom splitst de beslissing op in kleinere stappen, beginnend met een initiële vraag en vertakkend in verschillende mogelijke antwoorden of acties op basis van de voorwaarden of criteria bij elke stap.
35. Cognitieve computers
Cognitief computergebruik verwijst in eenvoudige bewoordingen naar computersystemen of technologieën die menselijke cognitieve vaardigheden nabootsen, zoals leren, redeneren, begrijpen en probleemoplossing.
Het gaat om het creëren van computersystemen die informatie kunnen verwerken en interpreteren op een manier die lijkt op menselijk denken.
Cognitive computing heeft tot doel machines te ontwikkelen die mensen op een meer natuurlijke en intelligente manier kunnen begrijpen en ermee kunnen communiceren. Deze systemen zijn ontworpen om enorme hoeveelheden gegevens te analyseren, patronen te herkennen, voorspellingen te doen en zinvolle inzichten te bieden.
Beschouw cognitief computergebruik als een poging om computers meer als mensen te laten denken en handelen.
Het omvat het gebruik van technologieën zoals kunstmatige intelligentie, machine learning, natuurlijke taalverwerking en computervisie om computers in staat te stellen taken uit te voeren die traditioneel werden geassocieerd met menselijke intelligentie.
36. Computationele leertheorie
Computational Learning Theory is een gespecialiseerde tak binnen het domein van kunstmatige intelligentie die draait om de ontwikkeling en het onderzoek van algoritmen die speciaal zijn ontworpen om te leren van gegevens.
Dit veld onderzoekt verschillende technieken en methodologieën voor het construeren van algoritmen die hun prestaties autonoom kunnen verbeteren door grote hoeveelheden informatie te analyseren en te verwerken.
Door gebruik te maken van de kracht van data, probeert Computational Learning Theory patronen, relaties en inzichten bloot te leggen die machines in staat stellen hun besluitvormingsmogelijkheden te verbeteren en taken efficiënter uit te voeren.
Het uiteindelijke doel is om algoritmen te creëren die zich kunnen aanpassen, generaliseren en nauwkeurige voorspellingen kunnen doen op basis van de gegevens waaraan ze zijn blootgesteld, wat bijdraagt aan de vooruitgang van kunstmatige intelligentie en de praktische toepassingen ervan.
37. Turing-test
De Turing-test, oorspronkelijk voorgesteld door de briljante wiskundige en computerwetenschapper Alan Turing, is een boeiend concept dat wordt gebruikt om te beoordelen of een machine intelligent gedrag kan vertonen dat vergelijkbaar is met of praktisch niet te onderscheiden is van dat van een mens.
In de Turing-test voert een menselijke beoordelaar een gesprek in natuurlijke taal met zowel een machine als een andere menselijke deelnemer zonder te weten welke de machine is.
De rol van de beoordelaar is om te onderscheiden welke entiteit de machine is, uitsluitend op basis van hun antwoorden. Als de machine de beoordelaar ervan kan overtuigen dat hij de menselijke tegenhanger is, dan zou hij geslaagd zijn voor de Turing-test, waarmee hij blijk geeft van een intelligentieniveau dat de menselijke capaciteiten weerspiegelt.
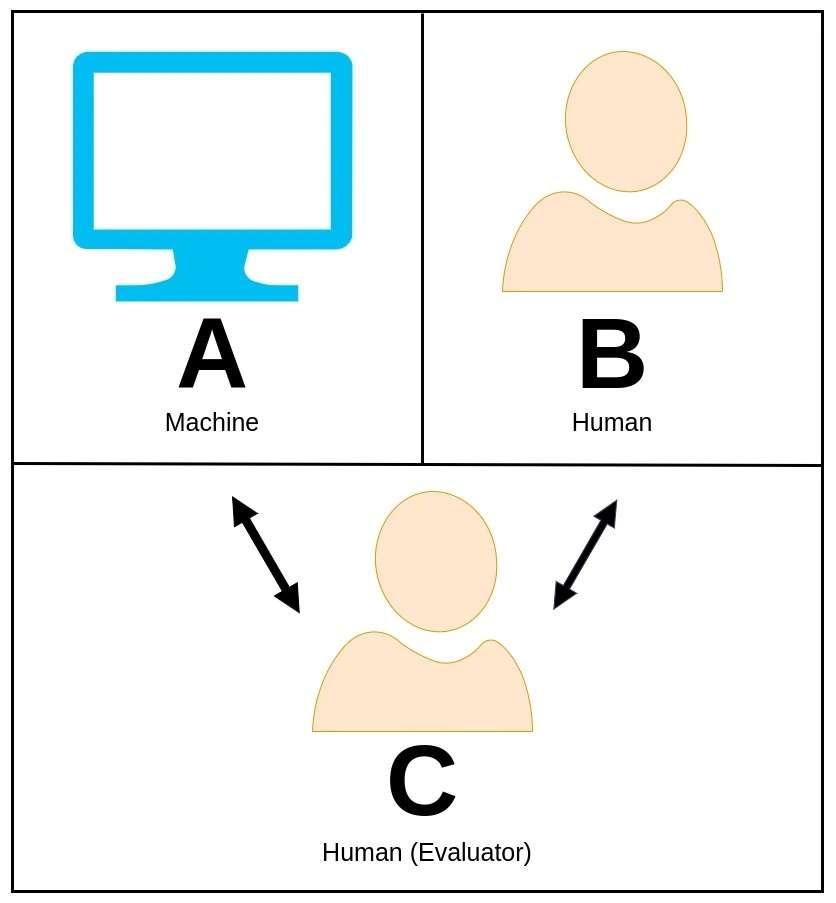
Alan Turing stelde deze test voor als een middel om het concept van machine-intelligentie te verkennen en om de vraag te stellen of machines cognitie op menselijk niveau kunnen bereiken.
Door de test te kaderen in termen van menselijke ononderscheidbaarheid, benadrukte Turing het potentieel van machines om gedrag te vertonen dat zo overtuigend intelligent is dat het een uitdaging wordt om ze van mensen te onderscheiden.
De Turing-test leidde tot uitgebreide discussies en onderzoek op het gebied van kunstmatige intelligentie en cognitieve wetenschap. Hoewel het slagen voor de Turing-test een belangrijke mijlpaal blijft, is het niet de enige maatstaf voor intelligentie.
Desalniettemin dient de test als een tot nadenken stemmende maatstaf, die voortdurende inspanningen stimuleert om machines te ontwikkelen die in staat zijn menselijke intelligentie en gedrag na te bootsen en bij te dragen aan de bredere verkenning van wat het betekent om intelligent te zijn.
38. Versterkend leren
Versterking leren is een vorm van leren die met vallen en opstaan plaatsvindt, waarbij een "agent" (dit kan een computerprogramma of een robot zijn) leert taken uit te voeren door beloningen te ontvangen voor goed gedrag en de consequenties of straffen voor slecht gedrag onder ogen te zien.
Stel je een scenario voor waarin de agent een specifieke taak probeert uit te voeren, zoals het navigeren door een doolhof. In eerste instantie weet de agent niet wat het juiste pad is, dus probeert hij verschillende acties en verkent hij verschillende routes.
Wanneer het een goede actie kiest die het dichter bij het doel brengt, ontvangt het een beloning, zoals een virtueel "schouderklopje". Als het echter een slechte beslissing neemt die tot een doodlopende weg leidt of het van het doel afleidt, krijgt het straf of negatieve feedback.
Door dit proces van vallen en opstaan leert de agent bepaalde acties te associëren met positieve of negatieve uitkomsten. Het zoekt geleidelijk de beste volgorde van acties uit om zijn beloningen te maximaliseren en straffen te minimaliseren, en wordt uiteindelijk vaardiger in de taak.
Versterkend leren haalt inspiratie uit hoe mensen en dieren leren door feedback van de omgeving te ontvangen.
Door dit concept toe te passen op machines, proberen onderzoekers intelligente systemen te ontwikkelen die kunnen leren en zich kunnen aanpassen aan verschillende situaties door autonoom het meest effectieve gedrag te ontdekken via een proces van positieve bekrachtiging en negatieve gevolgen.
39. Entiteitsextractie
Entiteitsextractie verwijst naar een proces waarbij we belangrijke stukjes informatie, ook wel entiteiten genoemd, uit een tekstblok identificeren en extraheren. Deze entiteiten kunnen verschillende dingen zijn, zoals de namen van mensen, namen van plaatsen, namen van organisaties, enzovoort.
Laten we ons voorstellen dat je een paragraaf hebt die een nieuwsartikel beschrijft.
Entiteitsextractie omvat het analyseren van de tekst en het uitkiezen van specifieke bits die verschillende entiteiten vertegenwoordigen. Als de tekst bijvoorbeeld de naam van een persoon vermeldt, zoals 'John Smith', de locatie 'New York City' of de organisatie 'OpenAI', zijn dit de entiteiten die we willen identificeren en extraheren.
Door entiteitsextractie uit te voeren, leren we een computerprogramma in wezen om belangrijke elementen uit de tekst te herkennen en te isoleren. Dit proces stelt ons in staat om informatie efficiënter te organiseren en te categoriseren, waardoor het gemakkelijker wordt om grote hoeveelheden tekstuele gegevens te doorzoeken, analyseren en inzichten te ontlenen.
Over het algemeen helpt entiteitsextractie ons bij het automatiseren van de taak van het lokaliseren van belangrijke entiteiten, zoals mensen, plaatsen en organisaties, in de tekst, het stroomlijnen van de extractie van waardevolle informatie en het verbeteren van ons vermogen om tekstuele gegevens te verwerken en te begrijpen.
40. Taalkundige annotatie
Taalkundige annotatie omvat het verrijken van tekst met aanvullende taalkundige informatie om ons begrip en analyse van de gebruikte taal te verbeteren. Het is als het toevoegen van handige labels of tags aan verschillende delen van een tekst.
Wanneer we taalkundige annotaties uitvoeren, gaan we verder dan de basiswoorden en -zinnen in een tekst en beginnen we met het labelen of taggen van specifieke elementen. We kunnen bijvoorbeeld part-of-speech-tags toevoegen, die de grammaticale categorie van elk woord aangeven (zoals zelfstandig naamwoord, werkwoord, bijvoeglijk naamwoord, enz.). Dit helpt ons de rol te begrijpen die elk woord in een zin speelt.
Een andere vorm van linguïstische annotatie is naamgevende entiteitsherkenning, waarbij we specifiek benoemde entiteiten identificeren en labelen, zoals namen van mensen, plaatsen, organisaties of datums. Hierdoor kunnen we snel belangrijke informatie uit de tekst lokaliseren en extraheren.
Door tekst op deze manieren te annoteren, creëren we een meer gestructureerde en georganiseerde weergave van de taal. Dit kan enorm handig zijn in een verscheidenheid aan toepassingen. Het helpt bijvoorbeeld de nauwkeurigheid van zoekmachines te verbeteren door de intentie achter zoekopdrachten van gebruikers te begrijpen. Het helpt ook bij machinevertaling, sentimentanalyse, informatie-extractie en vele andere natuurlijke taalverwerkingstaken.
Taalkundige annotatie is een essentieel hulpmiddel voor onderzoekers, taalkundigen en ontwikkelaars, waardoor ze taalpatronen kunnen bestuderen, taalmodellen kunnen bouwen en geavanceerde algoritmen kunnen ontwikkelen die de tekst beter kunnen analyseren en begrijpen.
41. Hyperparameter
In machine learning, is een hyperparameter als een speciale instelling of configuratie waarover we moeten beslissen voordat we een model trainen. Het is niet iets dat het model zelf uit de gegevens kan leren; in plaats daarvan moeten we het van tevoren bepalen.
Zie het als een knop of schakelaar die we kunnen aanpassen om nauwkeurig af te stemmen hoe het model leert en voorspellingen doet. Deze hyperparameters beheersen verschillende aspecten van het leerproces, zoals de complexiteit van het model, de snelheid van training en de wisselwerking tussen nauwkeurigheid en generalisatie.
Laten we bijvoorbeeld eens kijken naar een neuraal netwerk. Een belangrijke hyperparameter is het aantal lagen in het netwerk. We moeten kiezen hoe diep we het netwerk willen hebben, en deze beslissing beïnvloedt het vermogen om complexe patronen in de gegevens vast te leggen.
Andere veelvoorkomende hyperparameters zijn de leersnelheid, die bepaalt hoe snel het model zijn interne parameters aanpast op basis van de trainingsgegevens, en de regularisatiekracht, die bepaalt hoeveel het model complexe patronen bestraft om overfitting te voorkomen.
Het correct instellen van deze hyperparameters is cruciaal omdat ze de prestaties en het gedrag van het model aanzienlijk kunnen beïnvloeden. Het gaat vaak gepaard met een beetje vallen en opstaan, experimenteren met verschillende waarden en observeren hoe deze de prestaties van het model op een validatiedataset beïnvloeden.
42. Metagegevens
Metadata verwijst naar aanvullende informatie die details geeft over andere gegevens. Het is als een set tags of labels die ons meer context geven of de kenmerken van de belangrijkste gegevens beschrijven.
Wanneer we gegevens hebben, of het nu gaat om een document, een foto, een video of een ander type informatie, helpen metagegevens ons belangrijke aspecten van die gegevens te begrijpen.
In een document kunnen metagegevens bijvoorbeeld details bevatten zoals de naam van de auteur, de datum waarop het is gemaakt of de bestandsindeling. In het geval van een foto kunnen metadata ons vertellen over de locatie waar de foto is genomen, de gebruikte camera-instellingen of zelfs de datum en tijd waarop de foto is gemaakt.
Metadata helpt ons om gegevens effectiever te organiseren, te doorzoeken en te interpreteren. Door deze beschrijvende stukjes informatie toe te voegen, kunnen we snel specifieke bestanden vinden of hun oorsprong, doel of context begrijpen zonder de hele inhoud te hoeven doorzoeken.
43. Dimensionaliteitsreductie
Dimensionaliteitsreductie is een techniek die wordt gebruikt om een dataset te vereenvoudigen door het aantal kenmerken of variabelen die het bevat te verminderen. Het is als het condenseren of samenvatten van de informatie in een dataset om het beter beheersbaar en gemakkelijker te maken om mee te werken.
Stel je voor dat je een dataset hebt met talloze kolommen of attributen die verschillende kenmerken van de datapunten vertegenwoordigen. Elke kolom draagt bij aan de complexiteit en rekenkundige vereisten van algoritmen voor machine learning.
In sommige gevallen kan het hebben van een groot aantal dimensies het een uitdaging maken om betekenisvolle patronen of relaties in de gegevens te vinden.
Dimensionaliteitsreductie helpt dit probleem aan te pakken door de dataset om te zetten in een lager-dimensionale weergave terwijl zoveel mogelijk relevante informatie behouden blijft. Het is bedoeld om de belangrijkste aspecten of variaties in de gegevens vast te leggen en overbodige of minder informatieve dimensies te negeren.
44. Tekstclassificatie
Tekstclassificatie is een proces waarbij specifieke labels of categorieën worden toegewezen aan tekstblokken op basis van hun inhoud of betekenis. Het is als het sorteren of organiseren van tekstuele informatie in verschillende groepen of klassen om verdere analyse of besluitvorming te vergemakkelijken.
Laten we eens kijken naar een voorbeeld van e-mailclassificatie. In dit scenario willen we bepalen of een inkomende e-mail spam of niet-spam is (ook wel ham genoemd). Tekstclassificatie algoritmen analyseren de inhoud van de e-mail en kennen dienovereenkomstig een label toe.
Als het algoritme vaststelt dat de e-mail kenmerken vertoont die gewoonlijk worden geassocieerd met spam, kent het het label 'spam' toe. Omgekeerd, als de e-mail legitiem en niet-spamachtig lijkt, wordt het label "niet-spam" of "ham" toegewezen.
Tekstclassificatie vindt toepassingen in verschillende domeinen buiten het filteren van e-mail. Het wordt gebruikt in sentimentanalyse om het sentiment te bepalen dat wordt uitgedrukt in klantrecensies (positief, negatief of neutraal).
Nieuwsartikelen kunnen worden ingedeeld in verschillende onderwerpen of categorieën, zoals sport, politiek, entertainment en meer. Chatlogboeken voor klantenondersteuning kunnen worden gecategoriseerd op basis van de intentie of het probleem dat wordt aangepakt.
45. Zwakke AI
Zwakke AI, ook wel smalle AI genoemd, verwijst naar kunstmatige intelligentiesystemen die zijn ontworpen en geprogrammeerd om specifieke taken of functies uit te voeren. In tegenstelling tot menselijke intelligentie, die een breed scala aan cognitieve vaardigheden omvat, is zwakke AI beperkt tot een bepaald domein of een bepaalde taak.
Zie zwakke AI als gespecialiseerde software of machines die uitblinken in het uitvoeren van specifieke taken. Er kan bijvoorbeeld een schaak-AI-programma worden gemaakt om spelsituaties te analyseren, strategieën te bedenken en te strijden tegen menselijke spelers.
Een ander voorbeeld is een beeldherkenningssysteem dat objecten op foto's of video's kan identificeren.
Deze AI-systemen zijn getraind en geoptimaliseerd om uit te blinken in hun specifieke expertisegebieden. Ze vertrouwen op algoritmen, gegevens en vooraf gedefinieerde regels om hun taken effectief uit te voeren.
Ze beschikken echter niet over een algemene intelligentie waarmee ze taken buiten hun aangewezen domein kunnen begrijpen of uitvoeren.
46. Sterke AI
Sterke AI, ook bekend als algemene AI of kunstmatige algemene intelligentie (AGI), verwijst naar een vorm van kunstmatige intelligentie die het vermogen bezit om elke intellectuele taak te begrijpen, te leren en uit te voeren die een mens kan.
In tegenstelling tot zwakke AI, die is ontworpen voor specifieke taken, is sterke AI gericht op het repliceren van mensachtige intelligentie en cognitieve vaardigheden. Het streeft ernaar machines of software te creëren die niet alleen uitblinken in gespecialiseerde taken, maar ook een breder begrip en aanpassingsvermogen hebben om een breed scala aan intellectuele uitdagingen aan te pakken.
Het doel van sterke AI is het ontwikkelen van systemen die kunnen redeneren, complexe informatie begrijpen, leren van ervaringen, gesprekken voeren in natuurlijke taal, creativiteit tonen en andere kwaliteiten vertonen die verband houden met menselijke intelligentie.
In wezen streeft het ernaar AI-systemen te creëren die denken en probleemoplossing op menselijk niveau in meerdere domeinen kunnen simuleren of repliceren.
47. Vooruit ketenen
Forward chaining is een manier van redeneren of logica die begint met de beschikbare gegevens en deze gebruikt om gevolgtrekkingen te maken en nieuwe conclusies te trekken. Het is alsof je de punten met elkaar verbindt door de informatie die voorhanden is te gebruiken om verder te komen en tot aanvullende inzichten te komen.
Stel je voor dat je een reeks regels of feiten hebt en je wilt nieuwe informatie afleiden of op basis daarvan specifieke conclusies trekken. Forward chaining werkt door de initiële gegevens te onderzoeken en logische regels toe te passen om aanvullende feiten of conclusies te genereren.
Laten we ter vereenvoudiging een eenvoudig scenario bekijken om te bepalen wat we moeten dragen op basis van de weersomstandigheden. Je hebt een regel die zegt: "Als het regent, neem een paraplu mee", en een andere regel die zegt: "Als het koud is, draag dan een jas." Als je nu merkt dat het inderdaad regent, kun je forward chaining gebruiken om te concluderen dat je een paraplu moet meenemen.
48. Achterwaarts ketenen
Backward chaining is een redeneermethode die begint met een gewenste conclusie of doel en achteruit werkt om de noodzakelijke gegevens of feiten te bepalen die nodig zijn om die conclusie te ondersteunen. Het is als het volgen van uw stappen vanaf het gewenste resultaat tot de eerste informatie die nodig is om het te bereiken.
Laten we, om backward chaining te begrijpen, een eenvoudig voorbeeld bekijken. Stel, je wilt bepalen of het geschikt is om te gaan zwemmen. De gewenste conclusie is of zwemmen op basis van bepaalde voorwaarden gepast is.
In plaats van te beginnen met de voorwaarden, begint achterwaarts koppelen met de conclusie en werkt het achteruit om de ondersteunende gegevens te vinden.
In dit geval zou achterwaarts ketenen het stellen van vragen als "Is het warm weer?" Als het antwoord ja is, zou je vragen: "Is er een zwembad beschikbaar?" Als het antwoord weer ja is, zou je verdere vragen stellen, zoals: "Is er genoeg tijd om te gaan zwemmen?"
Door deze vragen iteratief te beantwoorden en terug te werken, kunt u de noodzakelijke voorwaarden bepalen waaraan moet worden voldaan om de conclusie om te gaan zwemmen te ondersteunen.
49. Heuristiek
Een heuristiek is, in eenvoudige bewoordingen, een praktische regel of strategie die ons helpt beslissingen te nemen of problemen op te lossen, meestal gebaseerd op onze ervaringen uit het verleden of intuïtie. Het is als een mentale kortere weg die ons in staat stelt om snel met een redelijke oplossing te komen zonder een langdurig of uitputtend proces te doorlopen.
Bij complexe situaties of taken dienen heuristieken als leidende principes of "vuistregels" die de besluitvorming vereenvoudigen. Ze bieden ons algemene richtlijnen of strategieën die vaak effectief zijn in bepaalde situaties, ook al garanderen ze misschien niet de optimale oplossing.
Laten we bijvoorbeeld eens kijken naar een heuristiek voor het vinden van een parkeerplaats in een druk gebied. In plaats van elke beschikbare plek nauwkeurig te analyseren, zou je kunnen vertrouwen op de heuristiek van het zoeken naar geparkeerde auto's met draaiende motor.
Deze heuristiek gaat ervan uit dat deze auto's op het punt staan te vertrekken, waardoor de kans op het vinden van een beschikbare plek groter wordt.
50. Modellering van natuurlijke taal
Modellering van natuurlijke taal, in eenvoudige bewoordingen, is het proces van het trainen van computermodellen om menselijke taal te begrijpen en te genereren op een manier die vergelijkbaar is met hoe mensen communiceren. Het gaat erom computers te leren tekst op een natuurlijke en betekenisvolle manier te verwerken, interpreteren en genereren.
Het doel van natuurlijke taalmodellering is om computers in staat te stellen menselijke taal te begrijpen en te genereren op een manier die vloeiend, coherent en contextueel relevant is.
Het omvat het trainen van modellen op grote hoeveelheden tekstuele gegevens, zoals boeken, artikelen of gesprekken, om de patronen, structuren en semantiek van taal te leren.
Eenmaal getraind, kunnen deze modellen verschillende taalgerelateerde taken uitvoeren, zoals taalvertaling, tekstsamenvatting, het beantwoorden van vragen, chatbot-interacties en meer.
Ze kunnen de betekenis en context van zinnen begrijpen, relevante informatie extraheren en tekst genereren die grammaticaal correct en samenhangend is.





Laat een reactie achter