AI जताततै छ, तर कहिलेकाहीँ यो शब्दावली र शब्दावली बुझ्न चुनौतीपूर्ण हुन सक्छ। यस ब्लग पोष्टमा, हामी 50 भन्दा बढी एआई सर्तहरू र परिभाषाहरू व्याख्या गर्छौं ताकि तपाईं यो द्रुत रूपमा बढ्दो टेक्नोलोजीलाई अझ बढी बुझ्न सक्नुहुन्छ।
चाहे तपाईं शुरुवात वा विशेषज्ञ हुनुहुन्छ, हामी शर्त गर्छौं कि यहाँ केही सर्तहरू छन् जुन तपाईंलाई थाहा छैन!
1। कृत्रिम खुफिया
कृत्रिम खुफिया (AI) ले कम्प्यूटर प्रणालीहरूको विकासलाई बुझाउँछ जुन स्वतन्त्र रूपमा सिक्ने र काम गर्ने क्षमता हुन्छ, प्रायः मानव बुद्धिको अनुकरण गरेर।
यी प्रणालीहरूले डेटा विश्लेषण गर्दछ, ढाँचाहरू पहिचान गर्दछ, निर्णयहरू लिन्छ, र अनुभवको आधारमा तिनीहरूको व्यवहार अनुकूलन गर्दछ। एल्गोरिदम र मोडेलहरू प्रयोग गरेर, AI ले आफ्नो वरपरको अवस्था बुझ्न र बुझ्न सक्षम बुद्धिमान मेसिनहरू सिर्जना गर्ने लक्ष्य राख्छ।
अन्तिम लक्ष्य भनेको मेसिनहरूलाई कुशलतापूर्वक कार्यहरू गर्न, डेटाबाट सिक्न, र मानवजस्तै संज्ञानात्मक क्षमताहरू प्रदर्शन गर्न सक्षम पार्नु हो।
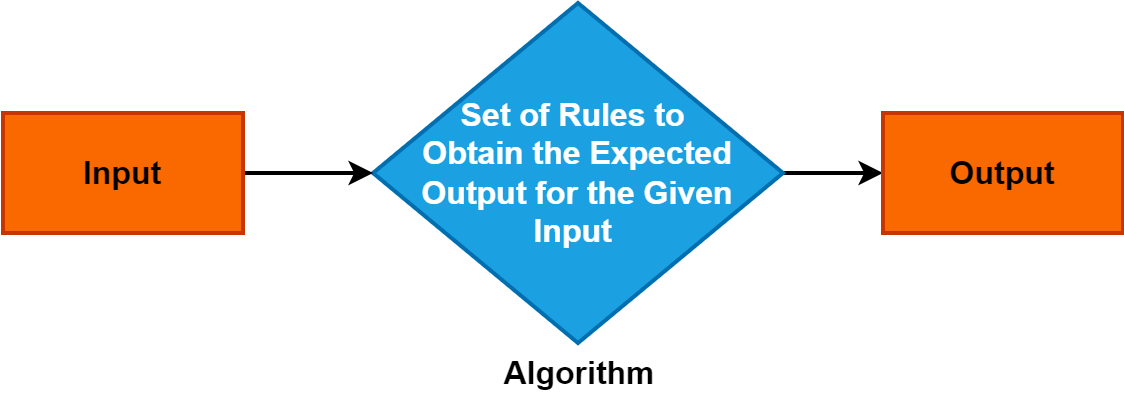
2। अल्गोरिदम
एल्गोरिदम भनेको समस्या समाधान गर्ने वा विशेष कार्य पूरा गर्ने प्रक्रियालाई मार्गदर्शन गर्ने निर्देशन वा नियमहरूको सटीक र व्यवस्थित सेट हो।
यसले विभिन्न डोमेनहरूमा आधारभूत अवधारणाको रूपमा कार्य गर्दछ र कम्प्युटर विज्ञान, गणित, र समस्या समाधान गर्ने विषयहरूमा निर्णायक भूमिका खेल्छ। एल्गोरिदमहरू बुझ्न महत्त्वपूर्ण छ किनकि तिनीहरूले कुशल र संरचित समस्या-समाधान दृष्टिकोणहरू सक्षम पार्छन्, प्रविधि र निर्णय प्रक्रियाहरूमा प्रगतिहरू चलाउँछन्।
१० बिग डाटा
बिग डाटाले अत्यन्त ठूला र जटिल डेटासेटहरूलाई बुझाउँछ जुन परम्परागत विश्लेषण विधिहरूको क्षमताहरू भन्दा बढी हुन्छ। यी डेटासेटहरू सामान्यतया तिनीहरूको भोल्युम, वेग र विविधताद्वारा विशेषता हुन्छन्।
भोल्युमले विभिन्न स्रोतहरूबाट उत्पन्न डेटाको विशाल मात्रालाई बुझाउँछ जस्तै सामाजिक संजाल, सेन्सर, र लेनदेन।
वेगले उच्च गतिलाई जनाउँछ जसमा डाटा उत्पन्न हुन्छ र वास्तविक समयमा वा वास्तविक समयमा प्रशोधन गर्न आवश्यक हुन्छ। विविधताले संरचित, असंरचित, र अर्ध-संरचित डेटा सहित डेटाको विविध प्रकार र ढाँचाहरूलाई जनाउँछ।
.4.१.१। डाटा खनन
डाटा खनन एक व्यापक प्रक्रिया हो जसको उद्देश्य विशाल डाटासेटहरूबाट मूल्यवान अन्तरदृष्टिहरू निकाल्ने हो।
यसले चार मुख्य चरणहरू समेट्छ: डाटा सङ्कलन, सान्दर्भिक डाटा सङ्कलन समावेश; डाटा तयारी, डाटा गुणस्तर र अनुकूलता सुनिश्चित; डाटा खनन, ढाँचा र सम्बन्धहरू पत्ता लगाउन एल्गोरिदमहरू प्रयोग गर्दै; र डेटा विश्लेषण र व्याख्या, जहाँ निकालिएको ज्ञान जाँच र बुझिन्छ।
5. न्यूरल नेटवर्क
कम्प्युटर प्रणाली जस्तै काम गर्न डिजाइन गरिएको छ मानव मस्तिष्क, अन्तरसम्बन्धित नोडहरू वा न्यूरोन्सहरूबाट बनेको। धेरै जसो AI मा आधारित भएकोले यसलाई अलि बढि बुझौं तंत्रिका सञ्जालहरू.
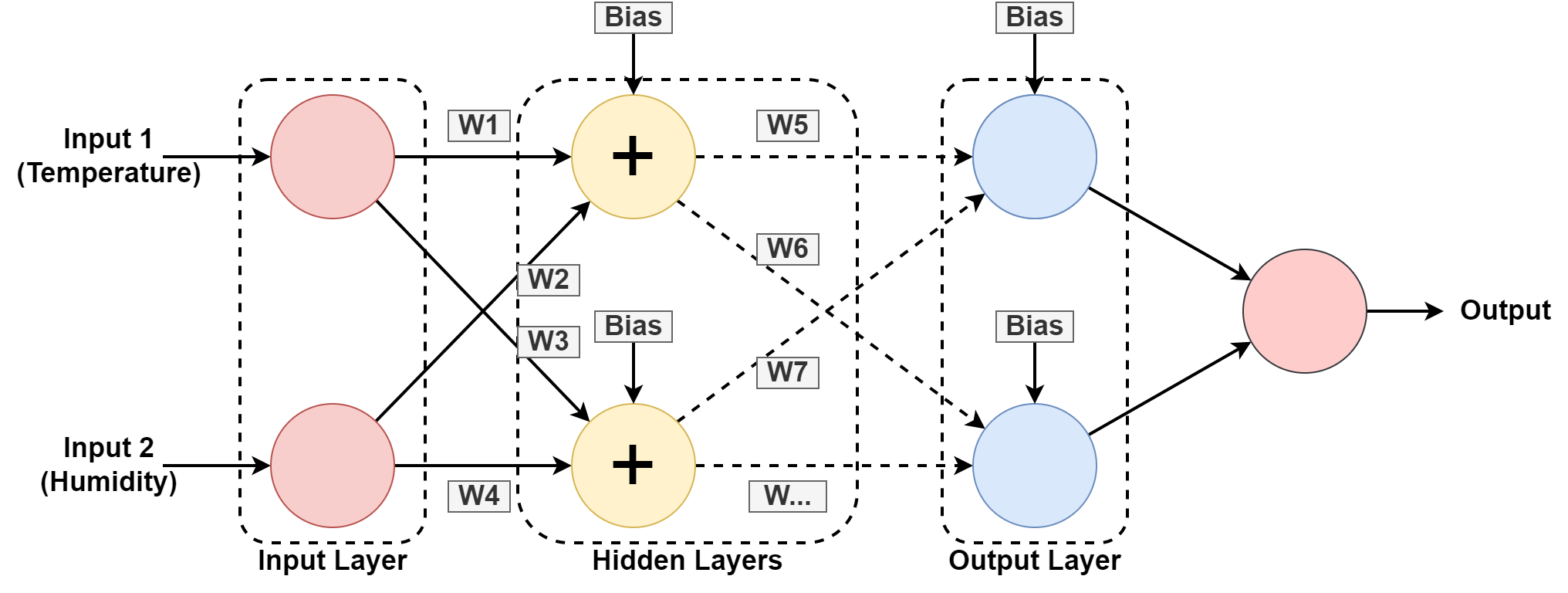
माथिको ग्राफिक्समा, हामीले विगतको ढाँचाबाट सिकेर भौगोलिक स्थानको आर्द्रता र तापक्रमको भविष्यवाणी गरिरहेका छौं। आगतहरू विगतको रेकर्डको लागि डेटासेट हुन्।
यो तंत्रिका नेटवर्क सिक्छ तौलसँग खेलेर र लुकेका तहहरूमा पूर्वाग्रह मानहरू लागू गरेर ढाँचा। W1, W2….W7 सम्बन्धित तौलहरू हुन्। यो प्रदान गरिएको डेटासेटमा आफैलाई तालिम दिन्छ र भविष्यवाणीको रूपमा आउटपुट दिन्छ।
तपाईं यो जटिल जानकारी द्वारा अभिभूत हुन सक्नुहुन्छ। यदि यो मामला हो भने, तपाइँ हाम्रो साधारण गाइड संग सुरु गर्न सक्नुहुन्छ यहाँ.
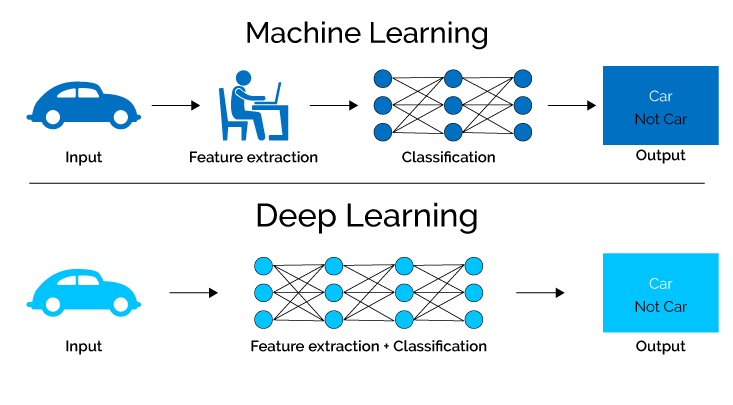
२. मेशिन लर्निंग
मेसिन लर्निङले डेटाबाट स्वचालित रूपमा सिक्ने र समयसँगै तिनीहरूको कार्यसम्पादनमा सुधार गर्न सक्षम एल्गोरिदम र मोडेलहरू विकास गर्नमा केन्द्रित हुन्छ।
यसले कम्प्युटरहरूलाई ढाँचाहरू पहिचान गर्न, भविष्यवाणीहरू गर्न, र स्पष्ट रूपमा प्रोग्राम नगरी डाटा-संचालित निर्णयहरू गर्न सक्षम पार्न सांख्यिकीय प्रविधिहरूको प्रयोग समावेश गर्दछ।
मेशिन शिक्षा एल्गोरिदम विश्लेषण गर्नुहोस् र ठूला डेटासेटहरूबाट सिक्नुहोस्, प्रणालीहरूलाई तिनीहरूले प्रक्रिया गर्ने जानकारीको आधारमा तिनीहरूको व्यवहारलाई अनुकूलन गर्न र सुधार गर्न अनुमति दिन्छ।
7. गहिरो शिक्षा
गहिरो शिक्षा, मेसिन लर्निङ र न्यूरल नेटवर्कहरूको उपक्षेत्र, मानव मस्तिष्कको जटिल प्रक्रियाहरूको नक्कल गरेर डेटाबाट ज्ञान प्राप्त गर्न परिष्कृत एल्गोरिदमहरू प्रयोग गर्दछ।
धेरै लुकेका तहहरूसँग तंत्रिका सञ्जालहरू प्रयोग गरेर, गहिरो सिकाइ मोडेलहरूले जटिल सुविधाहरू र ढाँचाहरूलाई स्वायत्त रूपमा निकाल्न सक्छन्, तिनीहरूलाई असाधारण सटीकता र दक्षताका साथ जटिल कार्यहरू गर्न सक्षम पार्दै।
8. ढाँचा पहिचान
ढाँचा पहिचान, एक डेटा विश्लेषण प्रविधि, मेसिन लर्निङ एल्गोरिदमको शक्तिलाई डेटासेटहरू भित्रको ढाँचा र नियमितताहरू स्वायत्त रूपमा पत्ता लगाउन र पत्ता लगाउन प्रयोग गर्दछ।
कम्प्युटेसनल मोडेलहरू र सांख्यिकीय विधिहरू प्रयोग गरेर, ढाँचा पहिचान एल्गोरिदमहरूले जटिल र विविध डेटामा अर्थपूर्ण संरचनाहरू, सहसंबंधहरू, र प्रवृत्तिहरू पहिचान गर्न सक्छन्।
यो प्रक्रियाले बहुमूल्य अन्तर्दृष्टिहरूको निकासी, डेटाको फरक वर्गहरूमा वर्गीकरण, र मान्यता प्राप्त ढाँचाहरूमा आधारित भविष्यका परिणामहरूको भविष्यवाणी गर्न सक्षम बनाउँछ। ढाँचा पहिचान विभिन्न डोमेनहरूमा एक महत्त्वपूर्ण उपकरण हो, निर्णय लिने सशक्तिकरण, विसंगति पत्ता लगाउने, र भविष्यवाणी मोडलिङ।
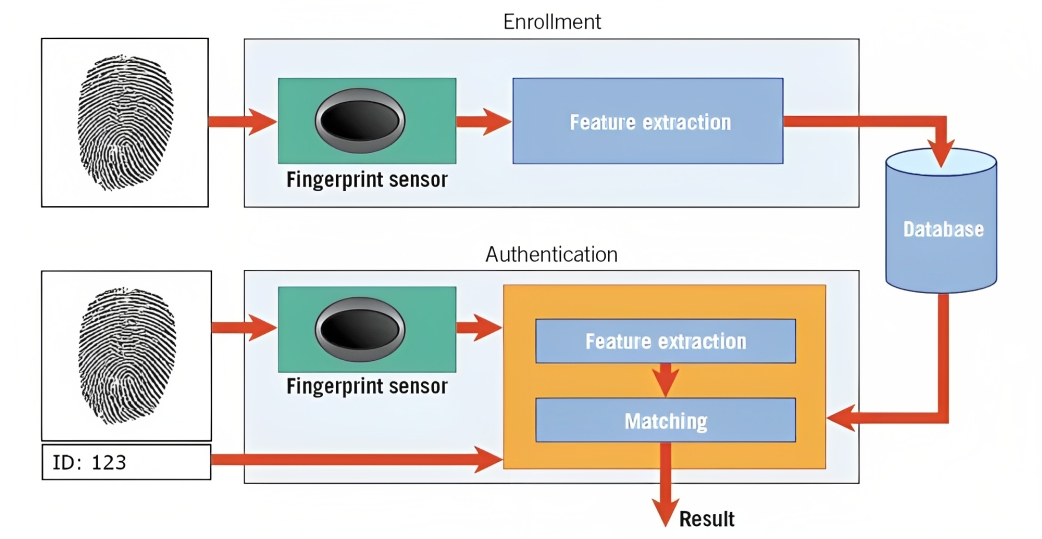
बायोमेट्रिक्स यसको एउटा उदाहरण हो। उदाहरणका लागि, फिंगरप्रिन्ट पहिचानमा, एल्गोरिदमले टेम्प्लेट भनिने डिजिटल प्रतिनिधित्व सिर्जना गर्न व्यक्तिको फिंगरप्रिन्टको रिज, कर्भ र अद्वितीय विशेषताहरूको विश्लेषण गर्छ।
जब तपाइँ आफ्नो स्मार्टफोन अनलक गर्न वा सुरक्षित सुविधामा पहुँच गर्ने प्रयास गर्नुहुन्छ, ढाँचा पहिचान प्रणालीले क्याप्चर गरिएको बायोमेट्रिक डाटा (जस्तै, फिंगरप्रिन्ट) लाई यसको डाटाबेसमा भण्डार गरिएका टेम्प्लेटहरूसँग तुलना गर्दछ।
ढाँचाहरू मिलाएर र समानताको स्तर मूल्याङ्कन गरेर, प्रणालीले प्रदान गरिएको बायोमेट्रिक डाटा भण्डार गरिएको टेम्प्लेटसँग मेल खान्छ कि भनेर निर्धारण गर्न सक्छ र तदनुसार पहुँच प्रदान गर्दछ।
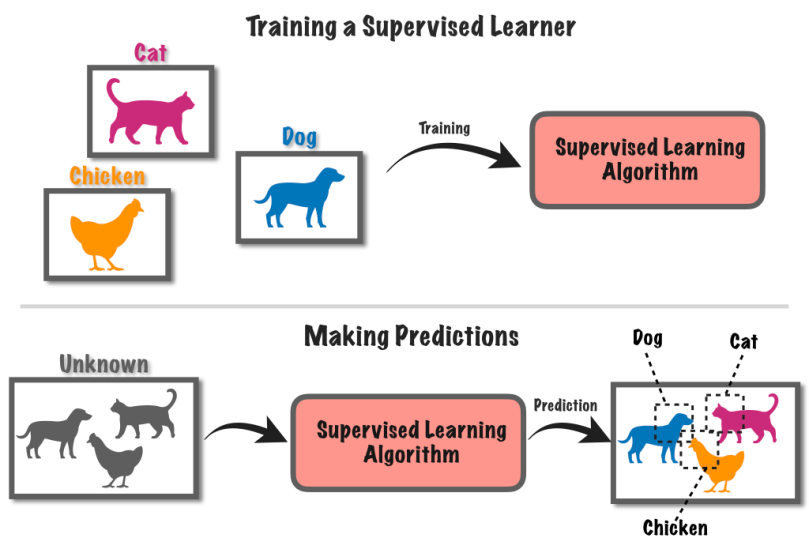
9. पर्यवेक्षित शिक्षा
सुपरभाइज्ड लर्निङ एउटा मेसिन लर्निङ दृष्टिकोण हो जसमा लेबल गरिएको डाटा प्रयोग गरेर कम्प्युटर प्रणालीलाई प्रशिक्षण दिइन्छ। यस विधिमा, कम्प्युटरलाई सम्बन्धित ज्ञात लेबल वा नतिजाहरू सहित इनपुट डेटाको सेट प्रदान गरिन्छ।
मानौं तपाईंसँग तस्विरहरूको गुच्छा छ, केही कुकुरहरूसँग र केही बिरालाहरूसँग।
तपाइँ कम्प्युटरलाई बताउनुहुन्छ कुन चित्रमा कुकुरहरू छन् र कुनमा बिरालाहरू छन्। त्यसपछि कम्प्युटरले चित्रहरूमा ढाँचाहरू फेला पारेर कुकुर र बिरालाहरू बीचको भिन्नता पहिचान गर्न सिक्छ।
यो सिकिसकेपछि, तपाइँ कम्प्युटरलाई नयाँ चित्रहरू दिन सक्नुहुन्छ, र यसले लेबल गरिएका उदाहरणहरूबाट सिकेको कुराको आधारमा तिनीहरूसँग कुकुर वा बिरालाहरू छन् कि छैनन् भनेर पत्ता लगाउने प्रयास गर्नेछ। यो ज्ञात जानकारी प्रयोग गरेर भविष्यवाणी गर्न कम्प्युटर प्रशिक्षण जस्तै हो।
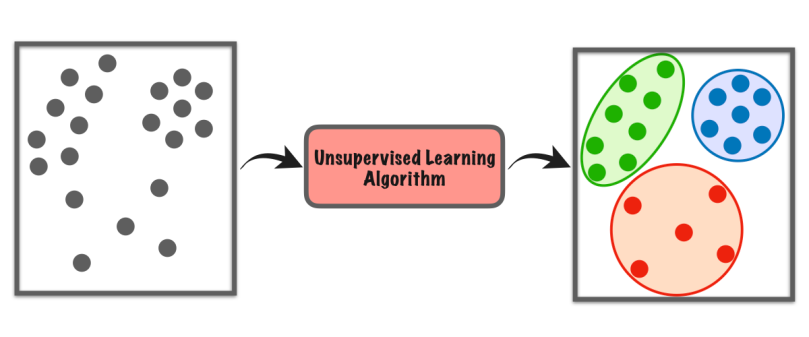
10. असुरक्षित शिक्षा
अनसुपरभाइज्ड लर्निङ एक प्रकारको मेसिन लर्निङ हो जहाँ कम्प्युटरले कुनै विशेष निर्देशन बिना ढाँचा वा समानताहरू फेला पार्न आफ्नै रूपमा डेटासेट अन्वेषण गर्दछ।
यो पर्यवेक्षित शिक्षामा जस्तै लेबल गरिएका उदाहरणहरूमा भर पर्दैन। यसको सट्टा, यसले डेटामा लुकेका संरचना वा समूहहरू खोज्छ। यो कम्प्यूटरले के खोज्ने भनेर शिक्षकले नभईकन आफैले चीजहरू खोजिरहेको जस्तो छ।
यस प्रकारको सिकाइले हामीलाई नयाँ अन्तर्दृष्टिहरू फेला पार्न, डेटा व्यवस्थित गर्न, वा पूर्व ज्ञान वा स्पष्ट मार्गदर्शनको आवश्यकता बिना असामान्य चीजहरू पहिचान गर्न मद्दत गर्दछ।
11. प्राकृतिक भाषा प्रशोधन (NLP)
प्राकृतिक भाषा प्रशोधनले कम्प्युटरहरूले मानव भाषालाई कसरी बुझ्छ र अन्तरक्रिया गर्छ भन्ने कुरामा केन्द्रित छ। यसले कम्प्यूटरहरूलाई मानव भाषालाई विश्लेषण गर्न, व्याख्या गर्न र प्रतिक्रिया दिन मद्दत गर्छ जुन हामीलाई अझ स्वाभाविक लाग्छ।
NLP ले हामीलाई भ्वाइस सहायकहरू, र च्याटबटहरूसँग कुराकानी गर्न र हाम्रा इमेलहरूलाई स्वचालित रूपमा फोल्डरहरूमा क्रमबद्ध गर्न सम्भव बनाउँछ।
यसले कम्प्यूटरहरूलाई शब्दहरू, वाक्यहरू, र सम्पूर्ण पाठहरू पछाडिको अर्थ बुझ्न सिकाउन समावेश गर्दछ, जसले गर्दा तिनीहरूले हामीलाई विभिन्न कार्यहरूमा मद्दत गर्न र प्रविधिसँगको हाम्रो अन्तरक्रियालाई अझ सहज बनाउन सक्छन्।
12. कम्प्युटर भिजन
कम्प्युटर दृष्टि एक आकर्षक प्रविधि हो जसले कम्प्यूटरहरूलाई छवि र भिडियोहरू हेर्न र बुझ्न अनुमति दिन्छ, जस्तै हामी मानिसहरूले हाम्रो आँखाले गर्छौं। यो कम्प्युटरहरूलाई भिजुअल जानकारीको विश्लेषण गर्न र उनीहरूले देखेका कुराहरूको अर्थ बनाउन सिकाउने बारे हो।
सरल शब्दहरूमा, कम्प्युटर दृष्टिले कम्प्युटरहरूलाई दृश्य संसारलाई चिन्न र व्याख्या गर्न मद्दत गर्दछ। यसले तिनीहरूलाई छविहरूमा विशिष्ट वस्तुहरू पहिचान गर्न, छविहरूलाई विभिन्न कोटीहरूमा वर्गीकरण गर्न, वा छविहरूलाई अर्थपूर्ण भागहरूमा विभाजन गर्न सिकाउने जस्ता कार्यहरू समावेश गर्दछ।
सडक र वरपरका सबै चीजहरू "हेर्न" कम्प्युटर दृष्टि प्रयोग गरेर सेल्फ-ड्राइभिङ कारको कल्पना गर्नुहोस्।
यसले पैदल यात्रीहरू, ट्राफिक संकेतहरू, र अन्य सवारीहरू पत्ता लगाउन र ट्र्याक गर्न सक्छ, तिनीहरूलाई सुरक्षित रूपमा नेभिगेट गर्न मद्दत गर्दछ। वा फेसियल रिकग्निसन टेक्नोलोजीले कसरी हाम्रा स्मार्टफोनहरू अनलक गर्न वा हाम्रो अनुहारको अद्वितीय विशेषताहरू पहिचान गरेर हाम्रो पहिचान प्रमाणित गर्न कम्प्युटर भिजन प्रयोग गर्छ भन्ने बारे सोच्नुहोस्।
यो भीडभाड स्थानहरू निगरानी गर्न र कुनै पनि संदिग्ध गतिविधिहरू स्पट गर्न निगरानी प्रणालीहरूमा पनि प्रयोग गरिन्छ।
कम्प्युटर दृष्टि एक शक्तिशाली प्रविधि हो जसले सम्भावनाहरूको संसार खोल्छ। कम्प्युटरहरूलाई भिजुअल जानकारी हेर्न र बुझ्न सक्षम बनाएर, हामीले हाम्रो जीवनलाई सजिलो, सुरक्षित र थप प्रभावकारी बनाउँदै हाम्रो वरपरको संसारलाई बुझ्न र व्याख्या गर्न सक्ने अनुप्रयोगहरू र प्रणालीहरू विकास गर्न सक्छौं।
२. च्याटबोट
च्याटबोट एउटा कम्प्युटर प्रोग्राम जस्तै हो जसले मानिसहरूसँग वास्तविक मानव कुराकानी जस्तो देखिन्छ।
यो प्रायः अनलाइन ग्राहक सेवामा ग्राहकहरूलाई मद्दत गर्न र उनीहरूलाई एक व्यक्तिसँग कुरा गरिरहेको महसुस गराउन प्रयोग गरिन्छ, यद्यपि यो वास्तवमा कम्प्युटरमा चलिरहेको प्रोग्राम हो।
च्याटबोटले ग्राहकहरूको सन्देश वा प्रश्नहरू बुझ्न र जवाफ दिन सक्छ, मानव ग्राहक सेवा प्रतिनिधिले जस्तै उपयोगी जानकारी र सहायता प्रदान गर्दछ।
14. आवाज पहिचान
आवाज पहिचानले मानव बोली बुझ्न र व्याख्या गर्न कम्प्युटर प्रणालीको क्षमतालाई बुझाउँछ। यसले कम्प्युटर वा यन्त्रलाई बोल्ने शब्दहरू "सुन्न" र तिनीहरूलाई बुझ्न सक्ने पाठ वा आदेशहरूमा रूपान्तरण गर्न सक्षम बनाउने प्रविधि समावेश गर्दछ।
संग आवाज मान्यता, तपाईँले टाइप गर्न वा अन्य इनपुट विधिहरू प्रयोग गर्नुको सट्टा केवल तिनीहरूसँग बोलेर उपकरणहरू वा अनुप्रयोगहरूसँग अन्तर्क्रिया गर्न सक्नुहुन्छ।
प्रणालीले बोलिएका शब्दहरूको विश्लेषण गर्छ, ढाँचा र ध्वनिहरू पहिचान गर्छ, र त्यसपछि तिनीहरूलाई बुझ्न सकिने पाठ वा कार्यहरूमा अनुवाद गर्छ। यसले भ्वाइस आदेशहरू, श्रुतलेखन, वा आवाज-नियन्त्रित अन्तरक्रियाहरू सम्भव बनाउँदै प्रविधिसँग ह्यान्ड्स-फ्री र प्राकृतिक सञ्चारको लागि अनुमति दिन्छ। सबैभन्दा सामान्य उदाहरणहरू सिरी र गुगल सहायक जस्ता AI सहायकहरू हुन्।
15. भावना विश्लेषण
सेन्मेन्ट विश्लेषण पाठ वा भाषणमा व्यक्त गरिएका भावना, विचार र मनोवृत्ति बुझ्न र व्याख्या गर्न प्रयोग गरिने प्रविधि हो। यसमा व्यक्त गरिएको भावना सकारात्मक, नकारात्मक वा तटस्थ छ कि छैन भनेर निर्धारण गर्न लिखित वा बोलिने भाषाको विश्लेषण समावेश छ।
मेसिन लर्निङ एल्गोरिदमहरू प्रयोग गरेर, भावना विश्लेषण एल्गोरिदमहरूले शब्दहरूको पछाडि अन्तर्निहित भावना पहिचान गर्न ग्राहक समीक्षाहरू, सोशल मिडिया पोस्टहरू, वा ग्राहक प्रतिक्रिया जस्ता पाठ डेटाको ठूलो मात्रा स्क्यान र विश्लेषण गर्न सक्छन्।
एल्गोरिदमहरूले विशिष्ट शब्दहरू, वाक्यांशहरू, वा ढाँचाहरू खोज्छन् जसले भावनाहरू वा विचारहरू संकेत गर्दछ।
यो विश्लेषणले व्यवसाय वा व्यक्तिहरूलाई उत्पादन, सेवा, वा विषयको बारेमा मानिसहरूलाई कस्तो लाग्छ भनेर बुझ्न मद्दत गर्दछ र डेटा-संचालित निर्णयहरू गर्न वा ग्राहक प्राथमिकताहरूमा अन्तरदृष्टि प्राप्त गर्न प्रयोग गर्न सकिन्छ।
उदाहरण को लागी, एक कम्पनीले ग्राहक सन्तुष्टि ट्र्याक गर्न, सुधार को लागी क्षेत्रहरु को पहिचान गर्न, वा आफ्नो ब्रान्ड को बारे मा सार्वजनिक राय को निगरानी को लागी भावना विश्लेषण को उपयोग गर्न सक्छ।
16. मेसिन अनुवाद
मेशिन अनुवाद, AI को सन्दर्भमा, कम्प्युटर एल्गोरिदम र कृत्रिम बुद्धिमत्ताको प्रयोगलाई स्वचालित रूपमा पाठ वा बोलीलाई एक भाषाबाट अर्को भाषामा अनुवाद गर्न बुझाउँछ।
यसले कम्प्युटरहरूलाई सही अनुवादहरू प्रदान गर्न मानव भाषाहरू बुझ्न र प्रशोधन गर्न सिकाउँछ। सबैभन्दा सामान्य उदाहरण हो गुगल अनुवाद्।
मेसिन अनुवादको साथ, तपाइँ एक भाषामा पाठ वा भाषण इनपुट गर्न सक्नुहुन्छ, र प्रणालीले इनपुटको विश्लेषण गर्नेछ र अर्को भाषामा सम्बन्धित अनुवाद उत्पन्न गर्नेछ। विभिन्न भाषाहरूमा सञ्चार वा जानकारी पहुँच गर्दा यो विशेष गरी उपयोगी छ।
मेसिन अनुवाद प्रणालीहरू भाषिक नियमहरू, सांख्यिकीय मोडेलहरू, र मेसिन लर्निङ एल्गोरिदमहरूको संयोजनमा निर्भर हुन्छन्। तिनीहरूले समयसँगै अनुवाद शुद्धता सुधार गर्न भाषा डेटाको विशाल मात्राबाट सिक्छन्। केही मेसिन अनुवाद दृष्टिकोणले अनुवादको गुणस्तर बढाउन न्यूरल नेटवर्कहरू पनि समावेश गर्दछ।
२ रोबोटिक्स
रोबोटिक्स भनेको रोबोट भनिने बौद्धिक मेसिनहरू सिर्जना गर्न कृत्रिम बुद्धिमत्ता र मेकानिकल इन्जिनियरिङको संयोजन हो। यी रोबोटहरू स्वायत्त रूपमा वा न्यूनतम मानव हस्तक्षेपको साथ कार्यहरू गर्न डिजाइन गरिएको हो।
रोबोटहरू भौतिक निकायहरू हुन् जसले आफ्नो वातावरणलाई बुझ्न सक्छ, त्यो संवेदी इनपुटको आधारमा निर्णयहरू लिन सक्छ, र विशिष्ट कार्य वा कार्यहरू गर्न सक्छ।
तिनीहरू विभिन्न सेन्सरहरूसँग सुसज्जित छन्, जस्तै क्यामेरा, माइक्रोफोन, वा टच सेन्सर, जसले तिनीहरूलाई वरपरको संसारबाट जानकारी सङ्कलन गर्न अनुमति दिन्छ। एआई एल्गोरिदम र प्रोग्रामिङको सहयोगमा, रोबोटहरूले यस डेटाको विश्लेषण गर्न, व्याख्या गर्न र आफ्नो तोकिएको कार्यहरू गर्न बुद्धिमानी निर्णयहरू गर्न सक्छन्।
रोबोटहरूलाई तिनीहरूको अनुभवबाट सिक्न र विभिन्न परिस्थितिहरूमा अनुकूलन गर्न सक्षम बनाएर एआईले रोबोटिक्समा महत्त्वपूर्ण भूमिका खेल्छ।
मेसिन लर्निङ एल्गोरिदमहरू रोबोटहरूलाई वस्तुहरू पहिचान गर्न, वातावरणमा नेभिगेट गर्न वा मानिसहरूसँग अन्तरक्रिया गर्न तालिम दिन प्रयोग गर्न सकिन्छ। यसले रोबोटहरूलाई धेरै बहुमुखी, लचिलो र जटिल कार्यहरू ह्यान्डल गर्न सक्षम बन्न अनुमति दिन्छ।
18 ड्रोन
ड्रोन एक प्रकारको रोबोट हो जुन मानव पाइलट बिना हावामा उड्न वा होभर गर्न सक्छ। तिनीहरूलाई मानवरहित हवाई सवारी (UAVs) पनि भनिन्छ। ड्रोनहरू क्यामेरा, जीपीएस, र जाइरोस्कोप जस्ता विभिन्न सेन्सरहरूसँग सुसज्जित छन्, जसले तिनीहरूलाई डेटा सङ्कलन गर्न र उनीहरूको वरपर नेभिगेट गर्न अनुमति दिन्छ।
तिनीहरू टाढाबाट मानव अपरेटरद्वारा नियन्त्रित हुन्छन् वा पूर्व-कार्यक्रमित निर्देशनहरू प्रयोग गरेर स्वायत्त रूपमा सञ्चालन गर्न सक्छन्।
ड्रोनहरूले एरियल फोटोग्राफी र भिडियोग्राफी, सर्वेक्षण र म्यापिङ, डेलिभरी सेवाहरू, खोज र उद्धार अभियानहरू, कृषि अनुगमन, र मनोरञ्जन प्रयोग सहित विभिन्न उद्देश्यहरूको सेवा गर्छन्। तिनीहरू दुर्गम वा खतरनाक क्षेत्रहरूमा पहुँच गर्न सक्छन् जुन मानिसहरूका लागि गाह्रो वा खतरनाक छन्।
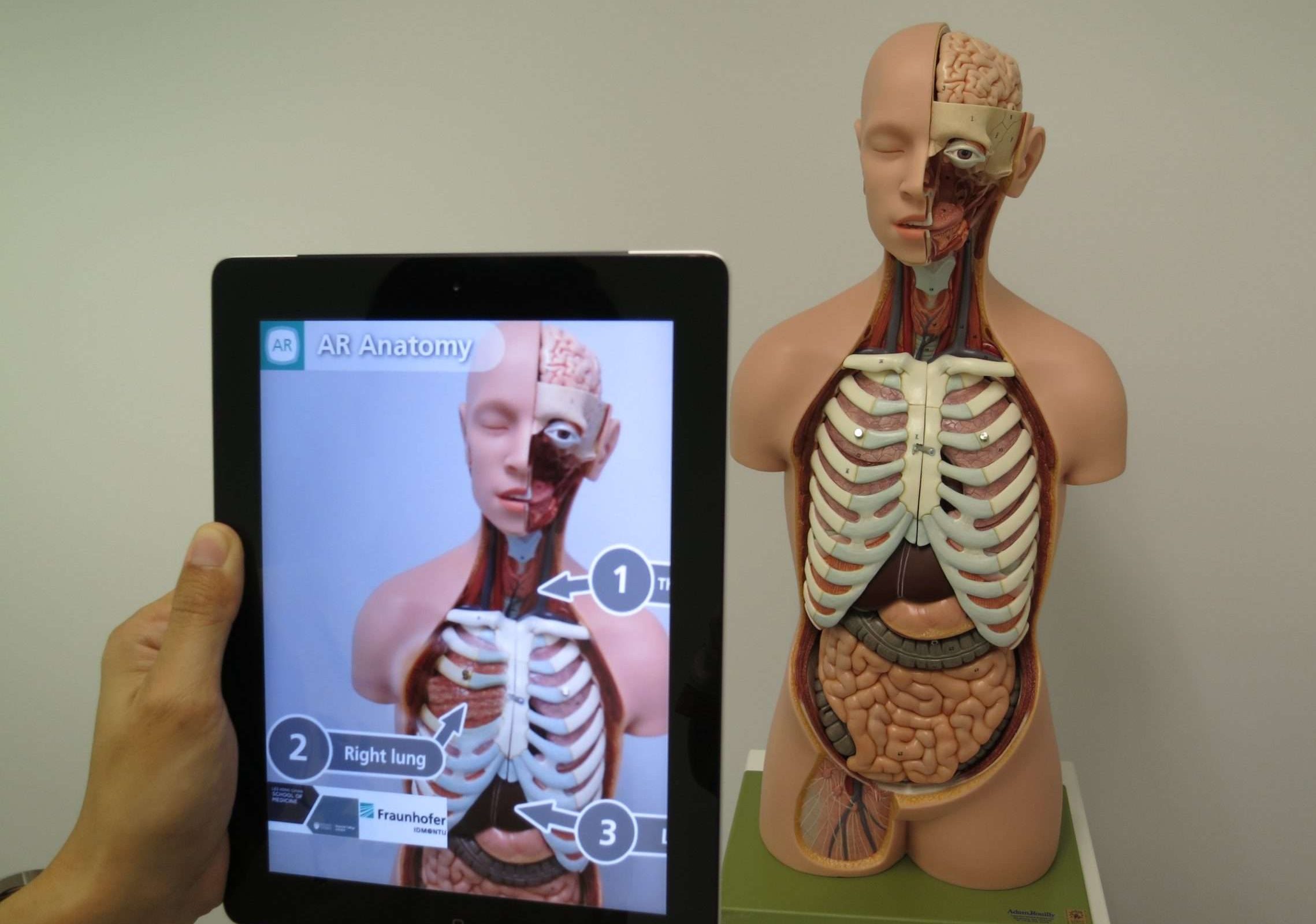
.19.२.२ संवर्धित वास्तविकता (एआर)
संवर्धित वास्तविकता (एआर) एक प्रविधि हो जसले वास्तविक संसारलाई भर्चुअल वस्तु वा जानकारीसँग जोड्दछ र वातावरणसँग हाम्रो धारणा र अन्तरक्रियालाई बढाउँछ। यसले कम्प्युटर-उत्पन्न छविहरू, ध्वनिहरू, वा अन्य संवेदी इनपुटहरूलाई वास्तविक संसारमा ओभरले गर्दछ, इमर्सिभ र अन्तरक्रियात्मक अनुभव सिर्जना गर्दछ।
सरल शब्दमा भन्नुपर्दा, विशेष चश्मा लगाएर वा आफ्नो वरपरको संसार हेर्नको लागि आफ्नो स्मार्टफोन प्रयोग गर्ने कल्पना गर्नुहोस्, तर थप भर्चुअल तत्वहरू थपिएको छ।
उदाहरणका लागि, तपाईंले आफ्नो स्मार्टफोनलाई सहरको सडकमा देखाउन सक्नुहुन्छ र नजिकैका रेस्टुरेन्टहरू वा वास्तविक वातावरणसँग अन्तर्क्रिया गर्ने भर्चुअल क्यारेक्टरहरूका लागि दिशा, मूल्याङ्कन, र समीक्षाहरू देखाउने भर्चुअल साइनपोस्टहरू देख्न सक्नुहुन्छ।
यी भर्चुअल तत्वहरूले वास्तविक संसारसँग निर्बाध मिश्रण गर्दछ, तपाईंको वरिपरिको बुझाइ र अनुभव बढाउँदै। संवर्धित वास्तविकता विभिन्न क्षेत्रहरूमा प्रयोग गर्न सकिन्छ जस्तै गेमिङ, शिक्षा, वास्तुकला, र दैनिक कार्यहरू जस्तै नेभिगेसन वा तपाईंको घरमा नयाँ फर्नीचर प्रयोग गरेर यसलाई किन्नु अघि प्रयोग गर्न सकिन्छ।
.20.२.१ भर्चुअल रियलिटी (VR)
भर्चुअल रियालिटी (VR) एउटा प्रविधि हो जसले कम्प्युटरद्वारा निर्मित सिमुलेशनहरू प्रयोग गरी एक व्यक्तिले अन्वेषण गर्न र अन्तरक्रिया गर्न सक्ने कृत्रिम वातावरण सिर्जना गर्दछ। यसले प्रयोगकर्तालाई भर्चुअल संसारमा डुबाउँछ, वास्तविक संसारलाई रोक्छ र यसलाई डिजिटल क्षेत्रसँग प्रतिस्थापन गर्दछ।
सरल शब्दमा भन्नुपर्दा, तपाईंको आँखा र कान छोप्ने र तपाईंलाई पूर्णतया फरक ठाउँमा पुर्याउने विशेष हेडसेट लगाउने कल्पना गर्नुहोस्। यस भर्चुअल संसारमा, तपाईंले देख्नु र सुन्नुभएको सबै कुरा अविश्वसनीय रूपमा वास्तविक महसुस हुन्छ, यद्यपि यो सबै कम्प्युटरद्वारा उत्पन्न हुन्छ।
तपाईं वरिपरि जान सक्नुहुन्छ, कुनै पनि दिशामा हेर्न सक्नुहुन्छ, र वस्तुहरू वा क्यारेक्टरहरूसँग अन्तर्क्रिया गर्न सक्नुहुन्छ मानौं तिनीहरू शारीरिक रूपमा उपस्थित थिए।
उदाहरणका लागि, भर्चुअल रियालिटी गेममा, तपाईंले आफूलाई मध्ययुगीन महल भित्र भेट्टाउन सक्नुहुन्छ, जहाँ तपाईं यसको करिडोरहरूबाट हिंड्न सक्नुहुन्छ, हतियार उठाउन सक्नुहुन्छ र भर्चुअल विरोधीहरूसँग तरवार लडाइँमा संलग्न हुन सक्नुहुन्छ। भर्चुअल वास्तविकता वातावरणले तपाईंको चाल र कार्यहरूमा प्रतिक्रिया दिन्छ, तपाईंलाई पूर्ण रूपमा डुबेको र अनुभवमा संलग्न भएको महसुस गराउँछ।
भर्चुअल रियालिटी गेमिङका लागि मात्र होइन, पाइलटहरू, सर्जनहरू, वा सैन्य कर्मचारीहरूका लागि प्रशिक्षण सिमुलेशनहरू, वास्तुकला वाकथ्रुहरू, भर्चुअल पर्यटन, र केही मनोवैज्ञानिक अवस्थाहरूको लागि पनि थेरापी जस्ता विभिन्न अन्य अनुप्रयोगहरूको लागि पनि प्रयोग गरिन्छ। यसले उपस्थितिको भावना सिर्जना गर्छ र प्रयोगकर्ताहरूलाई नयाँ र रोमाञ्चक भर्चुअल संसारहरूमा ढुवानी गर्छ, अनुभवलाई यथार्थको नजिक महसुस गराउँदछ।
21. डाटा विज्ञान
डेटा विज्ञान डेटाबाट बहुमूल्य ज्ञान र अन्तरदृष्टि निकाल्न वैज्ञानिक विधिहरू, उपकरणहरू र एल्गोरिदमहरू प्रयोग गर्ने क्षेत्र हो। यसले ठूला र जटिल डेटासेटहरू विश्लेषण गर्न गणित, तथ्याङ्क, प्रोग्रामिङ, र डोमेन विशेषज्ञताका तत्वहरूलाई संयोजन गर्दछ।
सरल शब्दहरूमा, डाटा विज्ञान भनेको डाटाको गुच्छा भित्र लुकेका अर्थपूर्ण जानकारी र ढाँचाहरू फेला पार्ने बारेमा हो। यसमा डेटा सङ्कलन, सफाई, र व्यवस्थित गर्ने, त्यसपछि विभिन्न प्रविधिहरू प्रयोग गरी यसलाई अन्वेषण र विश्लेषण समावेश गर्दछ। डाटा वैज्ञानिकहरू प्रचलनहरू उजागर गर्न, भविष्यवाणीहरू गर्न र समस्याहरू समाधान गर्न सांख्यिकीय मोडेलहरू र एल्गोरिदमहरू प्रयोग गर्नुहोस्।
उदाहरण को लागी, स्वास्थ्य सेवा को क्षेत्र मा, डाटा विज्ञान रोगहरु को लागी जोखिम कारकहरु को पहिचान गर्न को लागी रोगी रेकर्डहरु र चिकित्सा डेटा को विश्लेषण गर्न को लागी प्रयोग गर्न सकिन्छ, रोगी को नतिजाहरु को भविष्यवाणी गर्न, वा उपचार योजनाहरु लाई अनुकूलित गर्न को लागी। व्यवसायमा, डेटा विज्ञान ग्राहक डेटामा उनीहरूको प्राथमिकताहरू बुझ्न, उत्पादनहरू सिफारिस गर्न वा मार्केटिङ रणनीतिहरू सुधार गर्न लागू गर्न सकिन्छ।
22. डाटा झगडा
डाटा र्याङ्लिङ, जसलाई डाटा मुङ्गिङ पनि भनिन्छ, कच्चा डाटालाई सङ्कलन गर्ने, सफा गर्ने र विश्लेषणका लागि उपयुक्त र उपयुक्त ढाँचामा रूपान्तरण गर्ने प्रक्रिया हो। यसमा यसको गुणस्तर, स्थिरता, र विश्लेषण उपकरण वा मोडेलहरूसँग अनुकूलता सुनिश्चित गर्न डेटा ह्यान्डलिंग र तयारी समावेश छ।
सरल शब्दहरूमा, डेटा झगडा भनेको खाना पकाउने सामग्रीहरू तयार गर्नु जस्तै हो। यसमा विभिन्न स्रोतहरूबाट डाटा सङ्कलन, यसलाई क्रमबद्ध गर्ने, र कुनै त्रुटिहरू, असंगतिहरू, वा अप्रासंगिक जानकारीहरू हटाउन यसलाई सफा गर्ने समावेश छ।
थप रूपमा, डेटालाई रूपान्तरण गर्न, पुनर्संरचना गर्न, वा एकीकृत गर्नको लागि यसलाई सजिलोसँग काम गर्न र अन्तर्दृष्टि निकाल्न आवश्यक पर्दछ।
उदाहरणका लागि, डेटा झगडाले नक्कल प्रविष्टिहरू हटाउने, गलत हिज्जे वा ढाँचासम्बन्धी समस्याहरू सच्याउने, छुटेका मानहरू ह्यान्डल गर्ने, र डेटा प्रकारहरू रूपान्तरण गर्ने समावेश हुन सक्छ। यसमा विभिन्न डेटासेटहरू एकसाथ मर्ज गर्ने वा जोड्ने, डेटालाई सबसेटहरूमा विभाजन गर्ने वा अवस्थित डाटामा आधारित नयाँ चरहरू सिर्जना गर्ने कार्य पनि समावेश हुन सक्छ।
23. डाटा स्टोरीटेलिङ
डाटा कथा कथन कथा वा सन्देशलाई प्रभावकारी रूपमा सञ्चार गर्नको लागि आकर्षक र आकर्षक तरिकामा डाटा प्रस्तुत गर्ने कला हो। यसको प्रयोग समावेश छ डाटा दृश्यावलोकन, कथाहरू, र सन्दर्भहरू अन्तर्दृष्टि र निष्कर्षहरू व्यक्त गर्नका लागि दर्शकहरूलाई बुझ्न योग्य र सम्झनायोग्य तरिकामा।
सरल शब्दहरूमा, डेटा कथा कथन भनेको कथा बताउन डेटा प्रयोग गर्ने बारे हो। यो केवल संख्या र चार्ट प्रस्तुत गर्न बाहिर जान्छ। यसले डेटालाई जीवन्त बनाउन र यसलाई श्रोताहरूका लागि सान्दर्भिक बनाउन दृश्य तत्वहरू र कथा कथन प्रविधिहरू प्रयोग गरी डेटाको वरिपरि कथन सिर्जना गर्ने समावेश गर्दछ।
उदाहरणका लागि, केवल बिक्री तथ्याङ्कहरूको तालिका प्रस्तुत गर्नुको सट्टा, डेटा कथा कथनमा अन्तरक्रियात्मक ड्यासबोर्ड सिर्जना गर्न समावेश हुन सक्छ जसले प्रयोगकर्ताहरूलाई दृश्यात्मक रूपमा बिक्री प्रवृतिहरू अन्वेषण गर्न अनुमति दिन्छ।
यसमा मुख्य निष्कर्षहरू हाइलाइट गर्ने, प्रवृतिहरू पछाडिका कारणहरू बताउने, र डाटामा आधारित कार्ययोग्य सिफारिसहरू सुझाव दिने कथा समावेश हुन सक्छ।
24. डाटा-संचालित निर्णय लिने
डेटा-संचालित निर्णय-प्रक्रिया सान्दर्भिक डेटाको विश्लेषण र व्याख्याको आधारमा छनौट गर्ने वा कार्यहरू लिने प्रक्रिया हो। यसमा केवल अन्तर्ज्ञान वा व्यक्तिगत निर्णयमा भर पर्नुको सट्टा निर्णय लिने प्रक्रियाहरूलाई मार्गदर्शन र समर्थन गर्न आधारको रूपमा डेटा प्रयोग गर्न समावेश छ।
सरल शब्दहरूमा, डाटा-संचालित निर्णय-निर्धारण भनेको हामीले गर्ने छनौटहरूलाई सूचित गर्न र मार्गदर्शन गर्न तथ्याङ्क र प्रमाणहरू प्रयोग गर्नु हो। यसले ढाँचाहरू, प्रवृत्तिहरू, र सम्बन्धहरू बुझ्नको लागि डेटा सङ्कलन र विश्लेषण र सूचित निर्णयहरू गर्न र समस्याहरू समाधान गर्न त्यो ज्ञान प्रयोग गर्न समावेश गर्दछ।
उदाहरणका लागि, व्यापार सेटिङमा, डेटा-संचालित निर्णय-निर्धारणमा बिक्री डेटा, ग्राहक प्रतिक्रिया, र बजार प्रवृतिहरू विश्लेषण गर्न सबैभन्दा प्रभावकारी मूल्य निर्धारण रणनीति निर्धारण गर्न वा उत्पादन विकासमा सुधारका लागि क्षेत्रहरू पहिचान गर्न समावेश हुन सक्छ।
स्वास्थ्य सेवामा, यसले उपचार योजनाहरू अनुकूलन गर्न वा रोगको नतिजाहरू भविष्यवाणी गर्न बिरामी डेटाको विश्लेषण समावेश गर्न सक्छ।
25. डाटा लेक
डाटा लेक एक केन्द्रीकृत र स्केलेबल डाटा रिपोजिटरी हो जसले यसको कच्चा र अप्रशोधित रूपमा डाटाको ठूलो मात्रा भण्डार गर्दछ। यो पूर्व-परिभाषित स्कीमा वा डेटा रूपान्तरणको आवश्यकता बिना नै संरचित, अर्ध-संरचित, र असंरचित डेटा जस्ता विभिन्न प्रकारका डेटा प्रकारहरू, ढाँचाहरू र संरचनाहरू राख्न डिजाइन गरिएको हो।
उदाहरणका लागि, कम्पनीले विभिन्न स्रोतहरूबाट डेटा सङ्कलन र भण्डारण गर्न सक्छ, जस्तै वेबसाइट लगहरू, ग्राहक लेनदेनहरू, सामाजिक मिडिया फिडहरू, र IoT उपकरणहरू, डेटा तालमा।
यस डेटालाई विभिन्न उद्देश्यका लागि प्रयोग गर्न सकिन्छ, जस्तै उन्नत विश्लेषणहरू सञ्चालन गर्ने, मेसिन लर्निङ एल्गोरिदमहरू प्रदर्शन गर्ने, वा ग्राहकको व्यवहारमा ढाँचा र प्रवृत्तिहरू अन्वेषण गर्ने।
26. डाटा वेयरहाउस
डाटा गोदाम एक विशेष डाटाबेस प्रणाली हो जुन विशेष रूपमा विभिन्न स्रोतहरूबाट ठूलो मात्रामा डाटा भण्डारण गर्न, व्यवस्थित गर्न र विश्लेषण गर्न डिजाइन गरिएको हो। यो कुशल डेटा पुन: प्राप्ति र जटिल विश्लेषणात्मक प्रश्नहरूलाई समर्थन गर्ने तरिकामा संरचित गरिएको छ।
यसले केन्द्रीय भण्डारको रूपमा कार्य गर्दछ जसले विभिन्न परिचालन प्रणालीहरू, जस्तै लेनदेन डाटाबेसहरू, CRM प्रणालीहरू, र संगठन भित्रका अन्य डेटा स्रोतहरूबाट डाटा एकीकृत गर्दछ।
डेटा रूपान्तरित, सफा, र विश्लेषणात्मक उद्देश्यका लागि अनुकूलित संरचित ढाँचामा डाटा गोदाममा लोड हुन्छ।
27. व्यापार खुफिया (BI)
व्यापार बुद्धिमत्ताले व्यवसायहरूलाई सूचित निर्णयहरू गर्न र मूल्यवान अन्तर्दृष्टिहरू प्राप्त गर्न मद्दत गर्ने तरिकामा डेटा सङ्कलन, विश्लेषण र प्रस्तुत गर्ने प्रक्रियालाई बुझाउँछ। यसले कच्चा डाटालाई अर्थपूर्ण, कार्ययोग्य जानकारीमा रूपान्तरण गर्न विभिन्न उपकरणहरू, प्रविधिहरू र प्रविधिहरू प्रयोग गर्दछ।
उदाहरणका लागि, एक व्यापार खुफिया प्रणालीले सबैभन्दा लाभदायक उत्पादनहरू पहिचान गर्न, सूची स्तरहरू निगरानी गर्न, र ग्राहक प्राथमिकताहरू ट्र्याक गर्न बिक्री डेटा विश्लेषण गर्न सक्छ।
यसले प्रमुख कार्यसम्पादन सूचकहरू (KPIs) जस्तै राजस्व, ग्राहक अधिग्रहण, वा उत्पादन कार्यसम्पादनमा वास्तविक-समय अन्तर्दृष्टि प्रदान गर्न सक्छ, जसले व्यवसायहरूलाई डेटा-संचालित निर्णयहरू गर्न र तिनीहरूको सञ्चालन सुधार गर्न उपयुक्त कार्यहरू गर्न अनुमति दिन्छ।
व्यापारिक खुफिया उपकरणहरूले प्रायः डाटा भिजुअलाइजेशन, तदर्थ क्वेरी, र डाटा अन्वेषण क्षमताहरू जस्ता सुविधाहरू समावेश गर्दछ। यी उपकरणहरूले प्रयोगकर्ताहरूलाई सक्षम गर्दछ, जस्तै व्यापार विश्लेषकहरू वा प्रबन्धकहरू, डेटासँग अन्तरक्रिया गर्न, यसलाई टुक्रा र पासा गर्नुहोस्, र महत्त्वपूर्ण अन्तर्दृष्टि र प्रवृतिहरू हाइलाइट गर्ने रिपोर्टहरू वा भिजुअल प्रतिनिधित्वहरू उत्पन्न गर्नुहोस्।
P. भविष्यवाणी गर्ने एनालिटिक्स
भविष्यवाणी विश्लेषण भनेको भविष्यका घटनाहरू वा नतिजाहरूको बारेमा सूचित भविष्यवाणी वा पूर्वानुमानहरू गर्न डेटा र सांख्यिकीय प्रविधिहरू प्रयोग गर्ने अभ्यास हो। यसले ऐतिहासिक डेटाको विश्लेषण, ढाँचाहरू पहिचान गर्ने, र भविष्यका प्रचलनहरू, व्यवहारहरू, वा घटनाहरूलाई एक्स्ट्रपोलेट गर्न र अनुमान गर्न मोडेलहरू निर्माण गर्ने समावेश गर्दछ।
यसले चरहरू बीचको सम्बन्धलाई उजागर गर्ने र भविष्यवाणी गर्न त्यो जानकारी प्रयोग गर्ने लक्ष्य राख्छ। यो केवल विगतका घटनाहरू वर्णन गर्न बाहिर जान्छ; यसको सट्टा, यसले भविष्यमा के हुन सक्छ भनेर बुझ्न र अनुमान गर्न ऐतिहासिक डेटाको लाभ उठाउँछ।
उदाहरण को लागी, वित्त को क्षेत्र मा, भविष्यवाणी को विश्लेषण को लागी प्रयोग गर्न सकिन्छ शेयर ऐतिहासिक बजार डेटा, आर्थिक सूचकहरू र अन्य सान्दर्भिक कारकहरूमा आधारित मूल्यहरू।
मार्केटिङमा, यसलाई लक्षित विज्ञापन र व्यक्तिगत मार्केटिङ अभियानहरू सक्षम पार्दै, ग्राहकको व्यवहार र प्राथमिकताहरू भविष्यवाणी गर्न प्रयोग गर्न सकिन्छ।
स्वास्थ्य सेवामा, भविष्यवाणी विश्लेषणले निश्चित रोगहरूको लागि उच्च जोखिममा बिरामीहरूलाई पहिचान गर्न वा चिकित्सा इतिहास र अन्य कारकहरूको आधारमा पुन: भर्ना हुने सम्भावनाको भविष्यवाणी गर्न मद्दत गर्न सक्छ।
29. प्रिस्क्रिप्टिव एनालिटिक्स
प्रिस्क्रिप्टिभ एनालिटिक्स भनेको कुनै विशेष परिस्थिति वा निर्णय लिने परिदृश्यमा लिनको लागि उत्तम सम्भावित कार्यहरू निर्धारण गर्न डाटा र एनालिटिक्सको प्रयोग हो।
यो वर्णनात्मक भन्दा पर जान्छ र भविष्यवाणी एनालिटिक्स भविष्यमा के हुन सक्छ भन्ने बारे अन्तर्दृष्टि प्रदान गरेर मात्र नभई वांछित नतिजा प्राप्त गर्नको लागि सबैभन्दा इष्टतम कार्यको सिफारिस पनि गर्दछ।
यसले ऐतिहासिक डेटा, भविष्यवाणी मोडेलहरू, र अनुकूलन प्रविधिहरू संयोजन गर्दछ विभिन्न परिदृश्यहरू अनुकरण गर्न र विभिन्न निर्णयहरूको सम्भावित परिणामहरूको मूल्याङ्कन गर्न। यसले धेरै बाधाहरू, उद्देश्यहरू, र कारकहरूलाई कार्ययोग्य सिफारिसहरू उत्पन्न गर्न विचार गर्दछ जसले वांछित परिणामहरूलाई अधिकतम बनाउँछ वा जोखिमहरू कम गर्दछ।
उदाहरणका लागि, भित्र आपूर्ति श्रृंखला व्यवस्थापन, प्रिस्क्रिप्टिभ एनालिटिक्सले सूची स्तर, उत्पादन क्षमता, ढुवानी लागत, र ग्राहकको मागमा सबैभन्दा प्रभावकारी वितरण योजना निर्धारण गर्न डेटा विश्लेषण गर्न सक्छ।
यसले लागत कम गर्न र समयमै डेलिभरी सुनिश्चित गर्नका लागि सूची भण्डारण स्थानहरू वा यातायात मार्गहरू जस्ता स्रोतहरूको आदर्श आवंटन सिफारिस गर्न सक्छ।
30. डाटा-संचालित मार्केटिङ
डाटा-संचालित मार्केटिङले मार्केटिङ रणनीतिहरू, अभियानहरू, र निर्णय प्रक्रियाहरू चलाउन डेटा र विश्लेषणहरू प्रयोग गर्ने अभ्यासलाई बुझाउँछ।
यसले ग्राहकको व्यवहार, प्राथमिकताहरू, र प्रवृत्तिहरूमा अन्तर्दृष्टि प्राप्त गर्न डेटाका विभिन्न स्रोतहरू प्रयोग गर्ने र मार्केटिङ प्रयासहरूलाई अनुकूलन गर्न त्यो जानकारी प्रयोग गर्ने समावेश गर्दछ।
यसले वेबसाइट अन्तरक्रिया, सामाजिक सञ्जाल संलग्नता, ग्राहक जनसांख्यिकी, खरिद इतिहास, र थप जस्ता धेरै टचपोइन्टहरूबाट डेटा सङ्कलन र विश्लेषणमा केन्द्रित छ। यो डाटा त्यसपछि लक्षित दर्शक, तिनीहरूको प्राथमिकताहरू, र तिनीहरूको आवश्यकताहरूको व्यापक समझ सिर्जना गर्न प्रयोग गरिन्छ।
डेटा दोहन गरेर, मार्केटरहरूले ग्राहक विभाजन, लक्ष्यीकरण, र निजीकरण सम्बन्धी सूचित निर्णयहरू गर्न सक्छन्।
तिनीहरूले विशिष्ट ग्राहक खण्डहरू पहिचान गर्न सक्छन् जुन मार्केटिङ अभियानहरूमा सकारात्मक प्रतिक्रिया दिने सम्भावना बढी हुन्छ र तिनीहरूको सन्देशहरू र प्रस्तावहरू तदनुसार अनुरूप हुन्छन्।
थप रूपमा, डाटा-संचालित मार्केटिङले मार्केटिङ च्यानलहरू अनुकूलन गर्न, सबैभन्दा प्रभावकारी मार्केटिङ मिश्रण निर्धारण गर्न, र मार्केटिङ पहलहरूको सफलता मापन गर्न मद्दत गर्दछ।
उदाहरणका लागि, डेटा-संचालित मार्केटिङ दृष्टिकोणले खरिद व्यवहार र प्राथमिकता ढाँचाहरू पहिचान गर्न ग्राहक डेटाको विश्लेषण समावेश गर्न सक्छ। यी अन्तर्दृष्टिहरूको आधारमा, मार्केटरहरूले व्यक्तिगत सामग्री र विशेष ग्राहक खण्डहरूसँग प्रतिध्वनि गर्ने प्रस्तावहरूको साथ लक्षित अभियानहरू सिर्जना गर्न सक्छन्।
निरन्तर विश्लेषण र अप्टिमाइजेसनको माध्यमबाट, तिनीहरूले आफ्नो मार्केटिङ प्रयासहरूको प्रभावकारिता मापन गर्न र समयको साथमा रणनीतिहरू परिष्कृत गर्न सक्छन्।
31. डाटा शासन
डाटा गभर्नेन्स भनेको ढाँचा र अभ्यासहरूको सेट हो जुन संगठनहरूले आफ्नो जीवनचक्रमा डाटाको उचित व्यवस्थापन, संरक्षण र अखण्डता सुनिश्चित गर्न अपनाउने गर्दछ। यसले प्रक्रियाहरू, नीतिहरू, र प्रक्रियाहरू समावेश गर्दछ जसले कसरी डेटा सङ्कलन, भण्डारण, पहुँच, प्रयोग, र संगठन भित्र साझेदारी गरिन्छ।
यसले डेटा सम्पत्तिहरूमा जवाफदेहिता, जिम्मेवारी र नियन्त्रण स्थापना गर्ने लक्ष्य राख्छ। यसले तथ्याङ्कहरू सही, पूर्ण, सुसंगत र भरपर्दो छ भनी सुनिश्चित गर्दछ, संस्थाहरूलाई सूचित निर्णयहरू गर्न, डेटाको गुणस्तर कायम राख्न र नियामक आवश्यकताहरू पूरा गर्न सक्षम बनाउँछ।
डाटा गभर्नेन्समा डाटा व्यवस्थापनका लागि भूमिका र जिम्मेवारीहरू परिभाषित गर्ने, डाटा मापदण्ड र नीतिहरू स्थापना गर्ने, र अनुपालनको अनुगमन र लागू गर्न प्रक्रियाहरू लागू गर्ने समावेश छ। यसले डाटा गोपनीयता, डाटा सुरक्षा, डाटा गुणस्तर, डाटा वर्गीकरण, र डाटा जीवनचक्र व्यवस्थापन सहित डाटा व्यवस्थापनका विभिन्न पक्षहरूलाई सम्बोधन गर्दछ।
उदाहरणका लागि, डेटा प्रशासनले सामान्य डेटा संरक्षण नियमन (GDPR) जस्ता लागू गोपनीयता नियमहरूको अनुपालनमा व्यक्तिगत वा संवेदनशील डेटाहरू ह्यान्डल गरिएको छ भनी सुनिश्चित गर्न प्रक्रियाहरू लागू गर्न समावेश हुन सक्छ।
यसमा डाटा गुणस्तर मापदण्डहरू स्थापना गर्ने र डाटा सही र भरपर्दो छ भनी सुनिश्चित गर्न डाटा प्रमाणीकरण प्रक्रियाहरू लागू गर्ने समावेश हुन सक्छ।
१. डेटा सुरक्षा
डाटा सुरक्षा भनेको हाम्रो बहुमूल्य जानकारीलाई अनधिकृत पहुँच वा चोरीबाट सुरक्षित राख्नु हो। यसमा डेटाको गोपनीयता, अखण्डता र उपलब्धताको सुरक्षा गर्न उपायहरू लिनु समावेश छ।
अनिवार्य रूपमा, यसको मतलब यो सुनिश्चित गर्नु हो कि केवल सही व्यक्तिहरूले हाम्रो डेटा पहुँच गर्न सक्छन्, कि यो सही र अपरिवर्तित रहन्छ, र यो आवश्यक पर्दा उपलब्ध छ।
डाटा सुरक्षा प्राप्त गर्न, विभिन्न रणनीति र प्रविधिहरू प्रयोग गरिन्छ। उदाहरणका लागि, पहुँच नियन्त्रणहरू र इन्क्रिप्सन विधिहरूले आधिकारिक व्यक्ति वा प्रणालीहरूमा पहुँच सीमित गर्न मद्दत गर्दछ, जसले बाहिरका मानिसहरूलाई हाम्रो डेटा पहुँच गर्न गाह्रो बनाउँछ।
अनुगमन प्रणाली, फायरवालहरू, र घुसपैठ पत्ता लगाउने प्रणालीहरूले संदिग्ध गतिविधिहरूमा हामीलाई सचेत गराउँदै र अनाधिकृत पहुँचलाई रोक्न अभिभावकको रूपमा काम गर्छन्।
Th. कुराको इन्टरनेट
इन्टरनेट अफ थिंग्स (IoT) भन्नाले भौतिक वस्तुहरू वा "बस्तुहरू" को नेटवर्कलाई बुझाउँछ जुन इन्टरनेटमा जोडिएको छ र एकअर्कासँग सञ्चार गर्न सक्छ। यो इन्टरनेट मार्फत अन्तरक्रिया गरेर जानकारी साझा गर्न र कार्यहरू गर्न सक्षम हुने दैनिक वस्तुहरू, उपकरणहरू र मेसिनहरूको ठूलो वेब जस्तै हो।
सरल शब्दहरूमा, IoT ले परम्परागत रूपमा इन्टरनेटमा जडान नभएका विभिन्न वस्तु वा उपकरणहरूलाई "स्मार्ट" क्षमताहरू दिने समावेश गर्दछ। यी वस्तुहरूमा घरायसी उपकरणहरू, पहिरन मिल्ने यन्त्रहरू, थर्मोस्टेटहरू, कारहरू र औद्योगिक मेसिनरीहरू पनि समावेश हुन सक्छन्।
यी वस्तुहरूलाई इन्टरनेटमा जडान गरेर, तिनीहरूले डेटा सङ्कलन र साझेदारी गर्न सक्छन्, निर्देशनहरू प्राप्त गर्न सक्छन्, र स्वायत्त रूपमा वा प्रयोगकर्ता आदेशहरूको प्रतिक्रियामा कार्यहरू गर्न सक्छन्।
उदाहरणका लागि, स्मार्ट थर्मोस्ट्याटले तापक्रम निगरानी गर्न, सेटिङहरू समायोजन गर्न र स्मार्टफोन एपमा ऊर्जा उपयोग रिपोर्टहरू पठाउन सक्छ। एक पहिरन योग्य फिटनेस ट्रयाकरले तपाइँको शारीरिक गतिविधिहरूमा डेटा सङ्कलन गर्न सक्छ र विश्लेषणको लागि क्लाउड-आधारित प्लेटफर्ममा सिंक गर्न सक्छ।
34. निर्णय रूख
निर्णय रूख एक दृश्य प्रतिनिधित्व वा रेखाचित्र हो जसले हामीलाई निर्णय गर्न वा छनौट वा सर्तहरूको श्रृंखलामा आधारित कार्यको पाठ्यक्रम निर्धारण गर्न मद्दत गर्दछ।
यो एक फ्लोचार्ट जस्तै हो जसले हामीलाई विभिन्न विकल्पहरू र तिनीहरूको सम्भावित परिणामहरू विचार गरेर निर्णय प्रक्रिया मार्फत मार्गदर्शन गर्दछ।
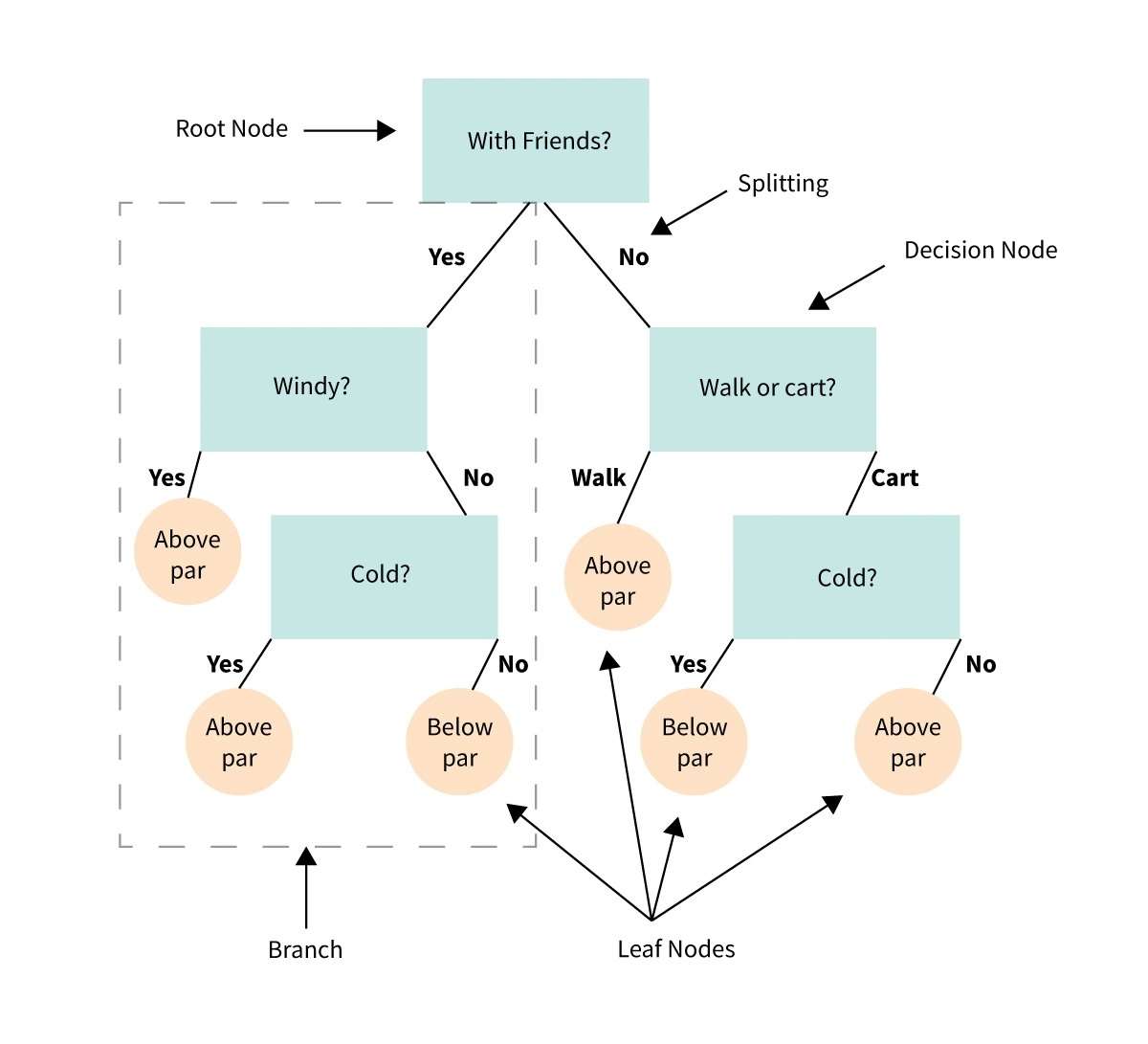
कल्पना गर्नुहोस् कि तपाईंसँग समस्या वा प्रश्न छ, र तपाईंले छनौट गर्न आवश्यक छ।
एउटा निर्णय रूखले निर्णयलाई साना चरणहरूमा विभाजन गर्दछ, प्रारम्भिक प्रश्नबाट सुरु गरेर र प्रत्येक चरणमा सर्त वा मापदण्डको आधारमा विभिन्न सम्भावित उत्तरहरू वा कार्यहरूमा शाखा बनाउँछ।
35. संज्ञानात्मक कम्प्युटिङ
संज्ञानात्मक कम्प्युटिङ, सरल शब्दहरूमा, कम्प्यूटर प्रणाली वा प्रविधिहरूलाई जनाउँछ जसले मानव संज्ञानात्मक क्षमताहरूको नक्कल गर्दछ, जस्तै सिक्ने, तर्क, बुझाइ, र समस्या समाधान।
यसले कम्प्यूटर प्रणालीहरू सिर्जना गर्न समावेश गर्दछ जसले जानकारीलाई प्रशोधन गर्न र मानव सोचसँग मिल्दोजुल्दो तरिकाले व्याख्या गर्न सक्छ।
संज्ञानात्मक कम्प्युटिङले मानवलाई अझ प्राकृतिक र बुद्धिमानी तरिकाले बुझ्न र अन्तरक्रिया गर्न सक्ने मेसिनहरू विकास गर्ने लक्ष्य राख्छ। यी प्रणालीहरू डेटाको विशाल मात्राको विश्लेषण गर्न, ढाँचाहरू पहिचान गर्न, भविष्यवाणीहरू गर्न, र अर्थपूर्ण अन्तर्दृष्टि प्रदान गर्न डिजाइन गरिएको हो।
संज्ञानात्मक कम्प्युटिङलाई कम्प्यूटरलाई मानिसजस्तै सोच्न र कार्य गर्ने प्रयासको रूपमा सोच्नुहोस्।
यसले कृत्रिम बुद्धिमत्ता, मेसिन लर्निङ, प्राकृतिक भाषा प्रशोधन, र कम्प्युटर भिजन जस्ता प्रविधिहरू समावेश गर्दछ जसले कम्प्युटरहरूलाई कार्यहरू गर्न सक्षम पार्छ जुन परम्परागत रूपमा मानव बुद्धिसँग सम्बन्धित थियो।
36. कम्प्यूटेशनल लर्निंग थ्योरी
कम्प्युटेसनल लर्निङ थ्योरी आर्टिफिसियल इन्टेलिजेन्सको दायरा भित्रको एउटा विशेष शाखा हो जुन डेटाबाट सिक्न विशेष गरी डिजाइन गरिएको एल्गोरिदमको विकास र परीक्षणको वरिपरि घुम्छ।
यस क्षेत्रले एल्गोरिदमहरू निर्माण गर्नका लागि विभिन्न प्रविधिहरू र विधिहरू अन्वेषण गर्दछ जसले ठूलो मात्रामा जानकारीको विश्लेषण र प्रशोधन गरेर आफ्नो कार्यसम्पादनलाई स्वायत्त रूपमा सुधार गर्न सक्छ।
डाटाको शक्ति प्रयोग गरेर, कम्प्युटेशनल लर्निङ थ्योरीले ढाँचाहरू, सम्बन्धहरू, र अन्तरदृष्टिहरू उजागर गर्ने लक्ष्य राख्छ जसले मेसिनहरूलाई उनीहरूको निर्णय गर्ने क्षमताहरू बढाउन र कार्यहरू अझ कुशलतापूर्वक गर्न सक्षम गर्दछ।
अन्तिम लक्ष्य एल्गोरिदमहरू सिर्जना गर्नु हो जसले उनीहरूलाई उजागर गरिएको डाटाको आधारमा अनुकूलन गर्न, सामान्यीकरण गर्न र सही भविष्यवाणीहरू गर्न सक्छ, कृत्रिम बुद्धिमत्ता र यसको व्यावहारिक अनुप्रयोगहरूको विकासमा योगदान पुर्याउँछ।
37. ट्युरिङ टेस्ट
ट्युरिङ परीक्षण, मूल रूपमा प्रतिभाशाली गणितज्ञ र कम्प्युटर वैज्ञानिक एलन ट्युरिङद्वारा प्रस्ताव गरिएको, एउटा मनमोहक अवधारणा हो जुन मेसिनले मानिसको तुलनामा बौद्धिक व्यवहार देखाउन सक्छ वा व्यावहारिक रूपमा फरक गर्न सक्दैन भनेर मूल्याङ्कन गर्न प्रयोग गरिन्छ।
ट्युरिङ परीक्षणमा, एक मानव मूल्याङ्कनकर्ताले मेसिन र अर्को मानव सहभागी दुवैसँग प्राकृतिक भाषा कुराकानीमा संलग्न हुन्छन् जुन मेसिन हो भनेर थाहा छैन।
मूल्याङ्कनकर्ताको भूमिका भनेको तिनीहरूको प्रतिक्रियाको आधारमा कुन निकाय मेसिन हो भनी पत्ता लगाउनु हो। यदि मेसिनले मूल्याङ्कनकर्तालाई यो मानव समकक्ष हो भनी विश्वास दिलाउन सक्षम छ भने, त्यसले ट्युरिङ परीक्षण पास गरेको भनिन्छ, जसले मानवजस्तै क्षमताहरू प्रतिबिम्बित गर्ने बुद्धिको स्तर प्रदर्शन गर्दछ।
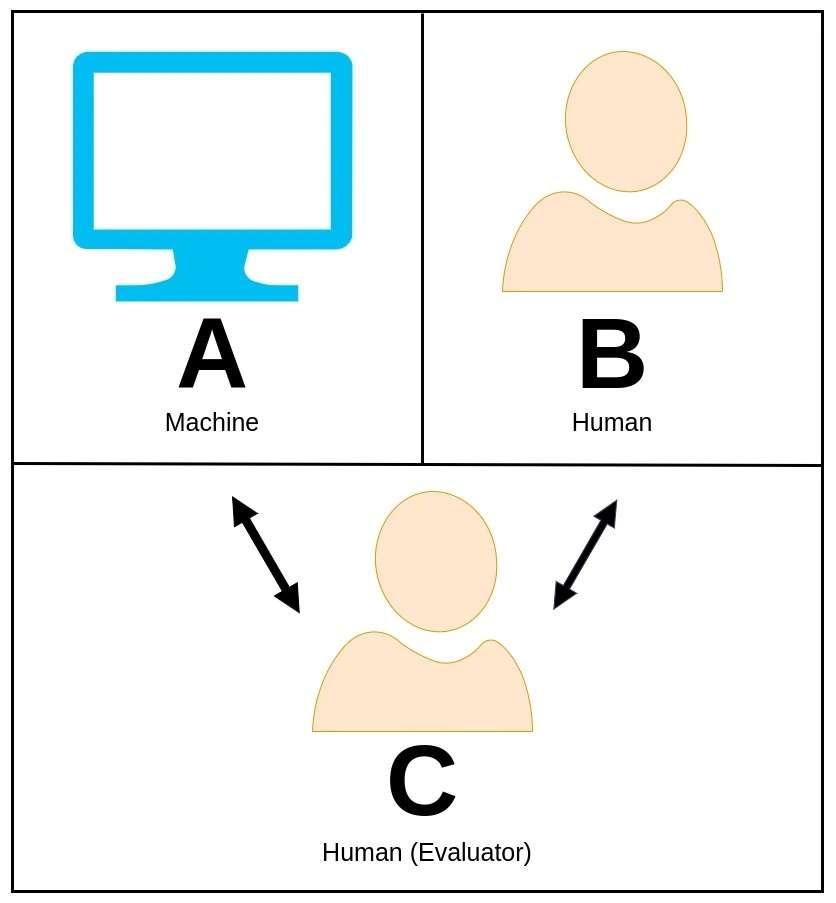
एलन ट्युरिङले मेसिन इन्टेलिजेन्सको अवधारणालाई अन्वेषण गर्न र मेसिनहरूले मानव-स्तरको अनुभूति हासिल गर्न सक्छन् कि छैनन् भन्ने प्रश्न खडा गर्ने माध्यमको रूपमा यो परीक्षण प्रस्ताव गरे।
मानव अविभाज्यताको सर्तमा परीक्षणको रूपरेखा बनाएर, ट्युरिङले मेसिनहरूको व्यवहार प्रदर्शन गर्न सक्ने क्षमतालाई हाइलाइट गरे जुन यति विश्वस्त रूपमा बुद्धिमानी छ कि तिनीहरूलाई मानिसहरूबाट छुट्याउन चुनौतीपूर्ण हुन्छ।
ट्युरिङ परीक्षणले आर्टिफिसियल इन्टेलिजेन्स र संज्ञानात्मक विज्ञानको क्षेत्रमा व्यापक छलफल र अनुसन्धानलाई जगायो। ट्युरिङ परीक्षण पास गर्नु महत्त्वपूर्ण कोसेढुङ्गा हो, यो बुद्धिको एकमात्र मापन होइन।
जे होस्, परीक्षणले सोच-उत्तेजक बेन्चमार्कको रूपमा कार्य गर्दछ, मानव-जस्तै बुद्धिमत्ता र व्यवहारको अनुकरण गर्न सक्षम मेसिनहरू विकास गर्न जारी प्रयासहरूलाई उत्तेजित गर्दछ र बौद्धिक हुनुको अर्थ के हो भन्ने फराकिलो अन्वेषणमा योगदान पुर्याउँछ।
38. सुदृढीकरण शिक्षा
सुदृढीकरण शिक्षण यो एक प्रकारको सिकाइ हो जुन परीक्षण र त्रुटि मार्फत हुन्छ, जहाँ "एजेन्ट" (जुन कम्प्युटर प्रोग्राम वा रोबोट हुन सक्छ) राम्रो व्यवहारको लागि पुरस्कार प्राप्त गरेर र नराम्रो व्यवहारको परिणाम वा सजायको सामना गरेर कार्यहरू गर्न सिक्छ।
एउटा परिदृश्यको कल्पना गर्नुहोस् जहाँ एजेन्टले एक विशेष कार्य पूरा गर्न प्रयास गरिरहेको छ, जस्तै भूलभुलैया नेभिगेट गर्ने। सुरुमा, एजेन्टलाई लिने सही मार्ग थाहा छैन, त्यसैले यसले विभिन्न कार्यहरू प्रयास गर्दछ र विभिन्न मार्गहरू अन्वेषण गर्दछ।
जब यसले लक्ष्यको नजिक पुग्ने राम्रो कार्य छनोट गर्छ, यसले भर्चुअल "पछाडि प्याट" जस्तै पुरस्कार प्राप्त गर्दछ। यद्यपि, यदि यसले खराब निर्णय गर्छ जसले डेड एन्डमा पुर्याउँछ वा लक्ष्यबाट टाढा लैजान्छ भने, यसले सजाय वा नकारात्मक प्रतिक्रिया प्राप्त गर्दछ।
परीक्षण र त्रुटिको यस प्रक्रिया मार्फत, एजेन्टले केहि कार्यहरूलाई सकारात्मक वा नकारात्मक परिणामहरूसँग सम्बद्ध गर्न सिक्छ। यसले बिस्तारै आफ्नो पुरस्कारलाई अधिकतम बनाउन र सजायहरू न्यूनीकरण गर्नका लागि कार्यहरूको उत्कृष्ट क्रम पत्ता लगाउँछ, अन्ततः कार्यमा अझ कुशल हुँदै जान्छ।
सुदृढीकरण सिकाइले वातावरणबाट प्रतिक्रिया प्राप्त गरेर मानिस र जनावरहरूले कसरी सिक्छन् त्यसबाट प्रेरणा लिन्छ।
मेसिनहरूमा यो अवधारणा लागू गरेर, अनुसन्धानकर्ताहरूले बौद्धिक प्रणालीहरू विकास गर्ने लक्ष्य राख्छन् जसले सकारात्मक सुदृढीकरण र नकारात्मक नतिजाहरूको प्रक्रिया मार्फत स्वायत्त रूपमा सबैभन्दा प्रभावकारी व्यवहारहरू पत्ता लगाएर विभिन्न परिस्थितिहरूमा सिक्न र अनुकूलन गर्न सक्छन्।
39. निकाय निकासी
संस्था निकासीले एउटा प्रक्रियालाई बुझाउँछ जसमा हामीले सूचनाको महत्त्वपूर्ण टुक्राहरू पहिचान गर्छौं, जसलाई संस्थाहरू भनेर चिनिन्छ, पाठको ब्लकबाट। यी संस्थाहरू विभिन्न चीजहरू हुन सक्छन् जस्तै व्यक्तिहरूको नाम, ठाउँहरूको नाम, संस्थाहरूको नाम, र यस्तै।
कल्पना गरौं तपाईंसँग एउटा समाचार लेख वर्णन गर्ने अनुच्छेद छ।
संस्था निकासीले पाठको विश्लेषण गर्ने र छुट्टै निकायहरूलाई प्रतिनिधित्व गर्ने विशिष्ट बिटहरू छान्ने समावेश गर्दछ। उदाहरणका लागि, यदि पाठले "John Smith," स्थान "New York City," वा संस्था "OpenAI" जस्ता व्यक्तिको नाम उल्लेख गरेको छ भने, यी हामीले पहिचान गर्ने र निकाल्ने लक्ष्य राखेका संस्थाहरू हुनेछन्।
संस्था निकासी प्रदर्शन गरेर, हामी अनिवार्य रूपमा पाठबाट महत्त्वपूर्ण तत्वहरू पहिचान गर्न र अलग गर्न कम्प्युटर प्रोग्रामलाई सिकाउँदैछौं। यो प्रक्रियाले हामीलाई थप कुशलतापूर्वक जानकारीलाई व्यवस्थित गर्न र वर्गीकरण गर्न सक्षम बनाउँछ, खोजी गर्न, विश्लेषण गर्न, र पाठ्य डेटाको ठूलो मात्राबाट अन्तर्दृष्टि प्राप्त गर्न सजिलो बनाउँछ।
समग्रमा, संस्था निकासीले हामीलाई महत्त्वपूर्ण संस्थाहरू, जस्तै व्यक्तिहरू, स्थानहरू, र संगठनहरू, पाठ भित्र, बहुमूल्य जानकारीको निकासीलाई सुव्यवस्थित बनाउने र पाठ्य डेटालाई प्रशोधन गर्ने र बुझ्ने क्षमता बढाउने कार्यलाई स्वचालित बनाउन मद्दत गर्छ।
40. भाषिक एनोटेशन
भाषिक एनोटेशनले प्रयोग गरिएको भाषाको हाम्रो बुझाइ र विश्लेषण बढाउनको लागि अतिरिक्त भाषिक जानकारीको साथ पाठलाई समृद्ध बनाउने समावेश गर्दछ। यो पाठको विभिन्न भागहरूमा उपयोगी लेबल वा ट्यागहरू थप्नु जस्तै हो।
जब हामी भाषिक एनोटेशन प्रदर्शन गर्छौं, हामी पाठमा आधारभूत शब्दहरू र वाक्यहरू भन्दा बाहिर जान्छौं र विशिष्ट तत्वहरूलाई लेबल वा ट्याग गर्न सुरु गर्छौं। उदाहरणका लागि, हामीले प्रत्येक शब्दको व्याकरणीय श्रेणी (जस्तै संज्ञा, क्रिया, विशेषण, इत्यादि) लाई संकेत गर्ने पार्ट-अफ-स्पीच ट्यागहरू थप्न सक्छौं। यसले हामीलाई प्रत्येक शब्दले वाक्यमा खेल्ने भूमिका बुझ्न मद्दत गर्छ।
भाषिक एनोटेसनको अर्को रूपलाई संस्था पहिचान भनिन्छ, जहाँ हामी व्यक्ति, स्थान, संस्था वा मितिहरू जस्ता विशिष्ट नाम गरिएका संस्थाहरूलाई पहिचान र लेबल गर्छौं। यसले हामीलाई द्रुत रूपमा पत्ता लगाउन र पाठबाट महत्त्वपूर्ण जानकारी निकाल्न अनुमति दिन्छ।
यी तरिकाहरूमा पाठ एनोटेट गरेर, हामी भाषाको थप संरचित र संगठित प्रतिनिधित्व सिर्जना गर्छौं। यो विभिन्न अनुप्रयोगहरूमा धेरै उपयोगी हुन सक्छ। उदाहरणका लागि, यसले प्रयोगकर्ताका प्रश्नहरूको पछाडिको उद्देश्य बुझेर खोज इन्जिनहरूको शुद्धता सुधार गर्न मद्दत गर्छ। यसले मेसिन अनुवाद, भावना विश्लेषण, जानकारी निकासी, र अन्य धेरै प्राकृतिक भाषा प्रशोधन कार्यहरूमा पनि मद्दत गर्दछ।
भाषिक एनोटेसनले अनुसन्धानकर्ताहरू, भाषाविद्हरू र विकासकर्ताहरूका लागि महत्त्वपूर्ण उपकरणको रूपमा कार्य गर्दछ, तिनीहरूलाई भाषा ढाँचाहरू अध्ययन गर्न, भाषा मोडेलहरू निर्माण गर्न, र पाठलाई राम्रोसँग विश्लेषण र बुझ्न सक्ने परिष्कृत एल्गोरिदमहरू विकास गर्न सक्षम पार्छ।
41. हाइपरपेरामिटर
In मेशिन सिकाइ, हाइपरपेरामिटर एक विशेष सेटिङ वा कन्फिगरेसन जस्तै हो जुन हामीले एक मोडेललाई प्रशिक्षण दिनु अघि निर्णय गर्न आवश्यक छ। यो मोडेलले डेटाबाट आफैं सिक्न सक्ने कुरा होइन; बरु, हामीले यसलाई पहिले नै निर्धारण गर्नुपर्छ।
यसलाई एउटा घुँडा वा स्विचको रूपमा सोच्नुहोस् जुन हामीले मोडेलले कसरी सिक्छ र भविष्यवाणी गर्छ भनेर राम्रोसँग समायोजन गर्न सक्छौं। यी हाइपरपेरामिटरहरूले सिकाइ प्रक्रियाका विभिन्न पक्षहरूलाई नियन्त्रण गर्छन्, जस्तै मोडेलको जटिलता, प्रशिक्षणको गति, र शुद्धता र सामान्यीकरण बीचको व्यापार।
उदाहरणका लागि, हामी एक तंत्रिका नेटवर्क विचार गरौं। एउटा महत्त्वपूर्ण हाइपरपेरामिटर नेटवर्कमा तहहरूको संख्या हो। हामीले नेटवर्कलाई कति गहिरो बनाउन चाहन्छौं भनेर हामीले छनोट गर्नुपर्छ, र यो निर्णयले डाटामा जटिल ढाँचाहरू खिच्ने क्षमतालाई असर गर्छ।
अन्य सामान्य हाइपरपेरामिटरहरूले सिकाइ दर समावेश गर्दछ, जसले प्रशिक्षण डेटाको आधारमा मोडेलले आफ्नो आन्तरिक मापदण्डहरूलाई कति चाँडो समायोजन गर्छ, र नियमितीकरण बल, जसले मोडेलले ओभरफिटिंग रोक्न जटिल ढाँचाहरूलाई कति दण्ड दिन्छ भनेर नियन्त्रण गर्दछ।
यी हाइपरपेरामिटरहरू सही रूपमा सेट गर्नु महत्त्वपूर्ण छ किनभने तिनीहरूले मोडेलको प्रदर्शन र व्यवहारलाई महत्त्वपूर्ण रूपमा असर गर्न सक्छन्। यसमा प्रायः थोरै परीक्षण र त्रुटि समावेश हुन्छ, विभिन्न मानहरू प्रयोग गरेर र तिनीहरूले प्रमाणीकरण डेटासेटमा मोडेलको कार्यसम्पादनलाई कसरी प्रभाव पार्छ भनेर अवलोकन गर्ने।
42. मेटाडेटा
मेटाडेटाले थप जानकारीलाई जनाउँछ जसले अन्य डेटाको बारेमा विवरणहरू प्रदान गर्दछ। यो ट्याग वा लेबलहरूको सेट जस्तै हो जसले हामीलाई थप सन्दर्भ दिन्छ वा मुख्य डेटाका विशेषताहरू वर्णन गर्दछ।
जब हामीसँग डाटा हुन्छ, चाहे त्यो कागजात होस्, फोटो होस्, भिडियो होस्, वा कुनै अन्य प्रकारको जानकारी होस्, मेटाडेटाले हामीलाई त्यो डाटाका महत्त्वपूर्ण पक्षहरू बुझ्न मद्दत गर्छ।
उदाहरणका लागि, कागजातमा, मेटाडेटाले लेखकको नाम, यो सिर्जना गरिएको मिति, वा फाइल ढाँचा जस्ता विवरणहरू समावेश गर्न सक्छ। फोटोको मामलामा, मेटाडेटाले हामीलाई यो लिइएको स्थान, प्रयोग गरिएको क्यामेरा सेटिङहरू, वा यसलाई खिचिएको मिति र समय पनि बताउन सक्छ।
मेटाडेटाले हामीलाई डेटालाई अझ प्रभावकारी रूपमा व्यवस्थित गर्न, खोज्न र व्याख्या गर्न मद्दत गर्छ। जानकारीका यी वर्णनात्मक टुक्राहरू थपेर, हामी सम्पूर्ण सामग्रीको खोजी नगरी नै विशेष फाइलहरू फेला पार्न वा तिनीहरूको उत्पत्ति, उद्देश्य, वा सन्दर्भ बुझ्न सक्छौं।
43. आयाम घटाउने
Dimensionality reduction भनेको यसमा रहेका सुविधाहरू वा चरहरूको संख्या घटाएर डेटासेटलाई सरल बनाउन प्रयोग गरिने प्रविधि हो। यो डेटासेटमा जानकारीलाई थप व्यवस्थित र काम गर्न सजिलो बनाउनको लागि संक्षेपण वा संक्षेपण गर्नु जस्तै हो।
कल्पना गर्नुहोस् कि तपाईंसँग डेटा बिन्दुहरूको विभिन्न विशेषताहरू प्रतिनिधित्व गर्ने धेरै स्तम्भहरू वा विशेषताहरू भएको डेटासेट छ। प्रत्येक स्तम्भले मेसिन लर्निङ एल्गोरिदमको जटिलता र कम्प्युटेसनल आवश्यकताहरू थप्छ।
केही अवस्थामा, आयामहरूको उच्च संख्या भएकोले डेटामा अर्थपूर्ण ढाँचा वा सम्बन्धहरू फेला पार्न चुनौतीपूर्ण बनाउन सक्छ।
डाइमेन्शनलिटी रिडक्सनले सकेसम्म धेरै सान्दर्भिक जानकारी राख्दै डाटासेटलाई तल्लो-आयामी प्रतिनिधित्वमा रूपान्तरण गरेर यस मुद्दालाई सम्बोधन गर्न मद्दत गर्दछ। यसले अनावश्यक वा कम जानकारीमूलक आयामहरूलाई खारेज गर्दा डेटामा सबैभन्दा महत्त्वपूर्ण पक्षहरू वा भिन्नताहरू क्याप्चर गर्ने लक्ष्य राख्छ।
44. पाठ वर्गीकरण
पाठ वर्गीकरण भनेको सामग्री वा अर्थको आधारमा पाठको ब्लकहरूमा विशिष्ट लेबल वा कोटीहरू तोक्ने प्रक्रिया हो। यो थप विश्लेषण वा निर्णय लिने सुविधाको लागि विभिन्न समूह वा वर्गहरूमा पाठ्य जानकारीहरू क्रमबद्ध वा व्यवस्थित गर्नु जस्तै हो।
इमेल वर्गीकरण को एक उदाहरण विचार गरौं। यस परिदृश्यमा, हामी आगमन इमेल स्प्याम वा गैर-स्प्याम (ह्याम पनि भनिन्छ) हो कि भनेर निर्धारण गर्न चाहन्छौं। पाठ वर्गीकरण एल्गोरिदमले इमेलको सामग्रीको विश्लेषण गर्छ र तदनुसार लेबल प्रदान गर्दछ।
यदि एल्गोरिदमले निर्धारण गर्छ कि इमेलले सामान्यतया स्प्यामसँग सम्बन्धित विशेषताहरू प्रदर्शन गर्दछ, यसले लेबल "स्प्याम" नियुक्त गर्दछ। यसको विपरित, यदि इमेल वैध र गैर-स्प्यामी देखिन्छ भने, यसले "गैर-स्प्याम" वा "ह्याम" लेबल प्रदान गर्दछ।
पाठ वर्गीकरणले इमेल फिल्टरिङभन्दा बाहिरका विभिन्न डोमेनहरूमा एपहरू फेला पार्छ। यो ग्राहक समीक्षा (सकारात्मक, नकारात्मक, वा तटस्थ) मा व्यक्त भावना निर्धारण गर्न भावना विश्लेषण मा प्रयोग गरिन्छ।
समाचार लेखहरूलाई खेलकुद, राजनीति, मनोरञ्जन, र थप जस्ता विभिन्न विषयहरू वा कोटीहरूमा वर्गीकृत गर्न सकिन्छ। ग्राहक समर्थन च्याट लगहरू अभिप्राय वा मुद्दालाई सम्बोधन गरिएको आधारमा वर्गीकृत गर्न सकिन्छ।
४५. कमजोर एआई
कमजोर एआई, संकीर्ण एआई पनि भनिन्छ, कृत्रिम बुद्धिमत्ता प्रणालीहरूलाई बुझाउँछ जुन विशेष कार्य वा कार्यहरू गर्न डिजाइन र प्रोग्राम गरिएको छ। मानव बुद्धिको विपरीत, जसले संज्ञानात्मक क्षमताहरूको विस्तृत दायरालाई समेट्छ, कमजोर एआई कुनै विशेष डोमेन वा कार्यमा सीमित हुन्छ।
कमजोर AI लाई विशेष सफ्टवेयर वा मेशिनहरूका रूपमा सोच्नुहोस् जुन विशिष्ट कार्यहरू गर्न उत्कृष्ट छ। उदाहरणका लागि, चेस खेल्ने एआई कार्यक्रम खेल परिस्थितिहरूको विश्लेषण गर्न, चालहरू रणनीति बनाउन, र मानव खेलाडीहरू विरुद्ध प्रतिस्पर्धा गर्न सिर्जना गर्न सकिन्छ।
अर्को उदाहरण छवि पहिचान प्रणाली हो जसले फोटो वा भिडियोहरूमा वस्तुहरू पहिचान गर्न सक्छ।
यी AI प्रणालीहरू प्रशिक्षित छन् र तिनीहरूको विशेषज्ञताको विशिष्ट क्षेत्रहरूमा उत्कृष्टता हासिल गर्न अनुकूलित छन्। तिनीहरू आफ्नो कार्यहरू प्रभावकारी रूपमा पूरा गर्न एल्गोरिदम, डेटा, र पूर्व-परिभाषित नियमहरूमा भर पर्छन्।
यद्यपि, तिनीहरूसँग सामान्य बुद्धि छैन जसले तिनीहरूलाई उनीहरूको तोकिएको डोमेन बाहिरका कार्यहरू बुझ्न वा प्रदर्शन गर्न अनुमति दिन्छ।
46. बलियो एआई
बलियो AI, सामान्य AI वा कृत्रिम सामान्य बुद्धिमत्ता (AGI) को रूपमा पनि चिनिन्छ, कृत्रिम बुद्धिमत्ताको एक रूपलाई बुझाउँछ जसमा मानिसले गर्न सक्ने कुनै पनि बौद्धिक कार्य बुझ्न, सिक्ने र प्रदर्शन गर्ने क्षमता हुन्छ।
कमजोर AI को विपरीत, जुन विशेष कार्यहरूको लागि डिजाइन गरिएको हो, बलियो AI ले मानवजस्तै बुद्धिमत्ता र संज्ञानात्मक क्षमताहरू प्रतिकृति गर्ने लक्ष्य राख्छ। यसले मेशिन वा सफ्टवेयर सिर्जना गर्ने प्रयास गर्दछ जुन विशेष कार्यहरूमा मात्र उत्कृष्ट नभई बौद्धिक चुनौतीहरूको विस्तृत दायरालाई सामना गर्न फराकिलो समझ र अनुकूलन क्षमता पनि हुन्छ।
बलियो AI को लक्ष्य तर्क गर्न, जटिल जानकारी बुझ्न, अनुभवबाट सिक्न, प्राकृतिक भाषा कुराकानीमा संलग्न हुन, रचनात्मकता प्रदर्शन गर्न र मानव बुद्धिसँग सम्बन्धित अन्य गुणहरू प्रदर्शन गर्न सक्ने प्रणालीहरू विकास गर्नु हो।
संक्षेपमा, यसले एआई प्रणालीहरू सिर्जना गर्ने आकांक्षा राख्छ जसले मानव-स्तरको सोच र बहुविध डोमेनहरूमा समस्या समाधान गर्न नक्कल गर्न वा नक्कल गर्न सक्छ।
47. अगाडि चेनिङ
फर्वार्ड चेनिङ तर्क वा तर्कको एक विधि हो जुन उपलब्ध डाटाबाट सुरु हुन्छ र यसलाई निष्कर्षहरू बनाउन र नयाँ निष्कर्षहरू निकाल्न प्रयोग गर्दछ। यो अगाडि बढ्न र थप अन्तर्दृष्टिमा पुग्न हातमा रहेको जानकारी प्रयोग गरेर थोप्लाहरू जडान गर्नु जस्तै हो।
कल्पना गर्नुहोस् कि तपाईंसँग नियम वा तथ्यहरूको सेट छ, र तपाईं नयाँ जानकारी प्राप्त गर्न चाहनुहुन्छ वा तिनीहरूमा आधारित विशिष्ट निष्कर्षमा पुग्न चाहनुहुन्छ। फर्वार्ड चेनिङले प्रारम्भिक डाटा जाँच गरेर र थप तथ्य वा निष्कर्षहरू उत्पन्न गर्न तार्किक नियमहरू लागू गरेर काम गर्दछ।
सरल बनाउन, मौसम अवस्थाको आधारमा के लगाउने भनेर निर्धारण गर्ने एउटा साधारण परिदृश्यलाई विचार गरौं। तपाइँसँग एउटा नियम छ "यदि पानी परिरहेको छ भने, छाता ल्याउ" र अर्को नियम "यदि चिसो छ भने, ज्याकेट लगाउनुहोस्।" अब, यदि तपाईंले यो वास्तवमै वर्षा भइरहेको देख्नुभयो भने, तपाईंले छाता ल्याउनु पर्छ भनेर अनुमान गर्न अगाडि चेनिंग प्रयोग गर्न सक्नुहुन्छ।
48. ब्याकवर्ड चेनिङ
ब्याकवर्ड चेनिङ एक तर्क विधि हो जुन चाहिएको निष्कर्ष वा लक्ष्यबाट सुरु हुन्छ र त्यस निष्कर्षलाई समर्थन गर्न आवश्यक डाटा वा तथ्यहरू निर्धारण गर्न पछाडि काम गर्दछ। यो प्राप्त गर्न आवश्यक प्रारम्भिक जानकारीमा इच्छित परिणामबाट तपाइँका चरणहरू ट्रेस गर्नु जस्तै हो।
ब्याकवर्ड चेनिङ बुझ्नको लागि, एउटा साधारण उदाहरण विचार गरौं। मान्नुहोस् कि तपाईं पौडी खेल्न जानु उपयुक्त छ कि भनेर निर्धारण गर्न चाहनुहुन्छ। वांछित निष्कर्ष भनेको निश्चित अवस्थाहरूमा आधारित पौडी खेल्नु उपयुक्त छ कि छैन भन्ने हो।
सर्तहरूबाट सुरु गर्नुको सट्टा, ब्याकवर्ड चेनिङ निष्कर्षबाट सुरु हुन्छ र समर्थन डेटा फेला पार्न पछाडि काम गर्दछ।
यस अवस्थामा, ब्याकवर्ड चेनिङमा "मौसम न्यानो छ?" जस्ता प्रश्नहरू सोध्नु समावेश हुन्छ। यदि जवाफ हो हो भने, तपाइँ सोध्नुहुनेछ, "के त्यहाँ पोखरी उपलब्ध छ?" यदि जवाफ फेरि हो हो भने, तपाईंले थप प्रश्नहरू सोध्नुहुनेछ जस्तै, "के त्यहाँ पौडी खेल्न पर्याप्त समय छ?"
पुनरावृत्तिपूर्वक यी प्रश्नहरूको जवाफ दिएर र पछाडि काम गरेर, तपाईंले पौडी खेल्न जाने निष्कर्षलाई समर्थन गर्न आवश्यक सर्तहरू निर्धारण गर्न सक्नुहुन्छ।
49. ह्युरिस्टिक
एक ह्युरिस्टिक, सरल शब्दहरूमा, एक व्यावहारिक नियम वा रणनीति हो जसले हामीलाई निर्णय गर्न वा समस्याहरू समाधान गर्न मद्दत गर्दछ, सामान्यतया हाम्रो विगतका अनुभवहरू वा अन्तर्ज्ञानमा आधारित। यो एक मानसिक सर्टकट जस्तै हो जसले हामीलाई लामो वा विस्तृत प्रक्रियाको माध्यमबाट नजाइकन तुरुन्तै उचित समाधानको साथ आउन अनुमति दिन्छ।
जटिल परिस्थिति वा कार्यहरूको सामना गर्दा, हेरिस्टिक्सले मार्गदर्शन सिद्धान्त वा "औठाको नियम" को रूपमा काम गर्दछ जसले निर्णय लिने प्रक्रियालाई सरल बनाउँछ। तिनीहरूले हामीलाई इष्टतम समाधानको ग्यारेन्टी नगरे पनि केही परिस्थितिहरूमा प्रभावकारी हुने सामान्य दिशानिर्देश वा रणनीतिहरू प्रदान गर्छन्।
उदाहरणका लागि, भीडभाड भएको ठाउँमा पार्किङ स्थल फेला पार्नको लागि हेराइस्टिकलाई विचार गरौं। प्रत्येक उपलब्ध स्थानलाई सावधानीपूर्वक विश्लेषण गर्नुको सट्टा, तपाईं पार्क गरिएका कारहरूको इन्जिनहरू चलिरहेको खोजीमा भर पर्न सक्नुहुन्छ।
यो ह्युरिस्टिकले मान्दछ कि यी कारहरू छोड्न लागेका छन्, उपलब्ध स्थान फेला पार्ने सम्भावनाहरू बढाउँदै।
50. प्राकृतिक भाषा मोडेलिङ
प्राकृतिक भाषा मोडलिङ, सरल शब्दहरूमा, मानव भाषालाई बुझ्न र उत्पन्न गर्नको लागि कम्प्युटर मोडेलहरूलाई प्रशिक्षण दिने प्रक्रिया हो जुन मानिसहरूले कसरी सञ्चार गर्छन्। यसले कम्प्युटरहरूलाई प्राकृतिक र अर्थपूर्ण तरिकाले प्रशोधन गर्न, व्याख्या गर्न र पाठ उत्पन्न गर्न सिकाउँछ।
प्राकृतिक भाषा मोडलिङको लक्ष्य कम्प्युटरहरूलाई मानव भाषालाई प्रवाहित, सुसंगत, र प्रासंगिक रूपमा सान्दर्भिक रूपमा बुझ्न र उत्पन्न गर्न सक्षम पार्नु हो।
यसले भाषाको ढाँचा, संरचना, र सिमान्टिक्स सिक्न पुस्तकहरू, लेखहरू, वा कुराकानीहरू जस्ता पाठ्य डेटाको विशाल मात्रामा प्रशिक्षण मोडेलहरू समावेश गर्दछ।
एक पटक प्रशिक्षित भएपछि, यी मोडेलहरूले विभिन्न भाषा-सम्बन्धित कार्यहरू गर्न सक्छन्, जस्तै भाषा अनुवाद, पाठ सारांश, प्रश्न उत्तर, च्याटबोट अन्तरक्रिया, र थप।
तिनीहरूले वाक्यको अर्थ र सन्दर्भ बुझ्न सक्छन्, सान्दर्भिक जानकारी निकाल्न सक्छन्, र व्याकरणको रूपमा सही र सुसंगत पाठ उत्पन्न गर्न सक्छन्।





जवाफ छाड्नुस्