Jadual Kandungan[Sembunyi][Tunjukkan]
Permainan video terus memberikan cabaran kepada berbilion pemain di seluruh dunia. Anda mungkin belum mengetahuinya, tetapi algoritma pembelajaran mesin telah mula menyahut cabaran itu juga.
Pada masa ini terdapat sejumlah besar penyelidikan dalam bidang AI untuk melihat sama ada kaedah pembelajaran mesin boleh digunakan pada permainan video. Kemajuan yang ketara dalam bidang ini menunjukkan bahawa pembelajaran mesin ejen boleh digunakan untuk meniru atau menggantikan pemain manusia.
Apakah ertinya ini untuk masa depan permainan video?
Adakah projek ini semata-mata untuk keseronokan, atau adakah terdapat sebab yang lebih mendalam mengapa begitu ramai penyelidik memberi tumpuan kepada permainan?
Artikel ini akan meneroka secara ringkas sejarah AI dalam permainan video. Selepas itu, kami akan memberi anda gambaran ringkas tentang beberapa teknik pembelajaran mesin yang boleh kami gunakan untuk mempelajari cara mengalahkan permainan. Kami kemudian akan melihat beberapa aplikasi yang berjaya jaring saraf untuk mempelajari dan menguasai permainan video tertentu.
Sejarah Ringkas AI dalam Permainan
Sebelum kita mengetahui sebab jaring saraf telah menjadi algoritma yang ideal untuk menyelesaikan permainan video, mari kita lihat secara ringkas bagaimana saintis komputer telah menggunakan permainan video untuk memajukan penyelidikan mereka dalam AI.
Anda boleh berhujah bahawa, sejak penubuhannya, permainan video telah menjadi bidang penyelidikan yang hangat untuk penyelidik yang berminat dengan AI.
Walaupun bukan asal permainan video semata-mata, catur telah menjadi tumpuan besar pada hari-hari awal AI. Pada tahun 1951, Dr. Dietrich Prinz menulis program permainan catur menggunakan komputer digital Ferranti Mark 1. Ini berlaku pada zaman ketika komputer besar ini terpaksa membaca program dari pita kertas.

Program itu sendiri bukanlah AI catur yang lengkap. Kerana keterbatasan komputer, Prinz hanya boleh mencipta program yang menyelesaikan masalah catur pasangan dalam dua. Secara purata, program ini mengambil masa 15-20 minit untuk mengira setiap langkah yang mungkin untuk pemain Putih dan Hitam.
Bekerja untuk meningkatkan catur dan dam AI telah bertambah baik secara berterusan sepanjang dekad. Kemajuan itu mencapai kemuncaknya pada tahun 1997 apabila Deep Blue IBM mengalahkan grandmaster catur Rusia Garry Kasparov dalam sepasang perlawanan enam perlawanan. Kini, enjin catur yang anda boleh temui pada telefon mudah alih anda boleh mengalahkan Deep Blue.
Lawan AI mula mendapat populariti semasa zaman kegemilangan permainan arked video. Space Invaders 1978 dan Pac-Man 1980-an ialah beberapa perintis industri dalam mencipta AI yang cukup mencabar walaupun pemain arked yang paling veteran.
Pac-Man, khususnya, adalah permainan popular untuk penyelidik AI untuk bereksperimen. Macam-macam pertandingan untuk Cik Pac-Man telah diatur untuk menentukan pasukan mana yang boleh menghasilkan AI terbaik untuk mengalahkan permainan.
AI permainan dan algoritma heuristik terus berkembang apabila keperluan untuk lawan yang lebih bijak timbul. Sebagai contoh, pertempuran AI meningkat dalam populariti kerana genre seperti penembak orang pertama menjadi lebih arus perdana.
Pembelajaran Mesin dalam Permainan Video
Memandangkan teknik pembelajaran mesin semakin popular, pelbagai projek penyelidikan cuba menggunakan teknik baharu ini untuk bermain permainan video.
Permainan seperti Dota 2, StarCraft dan Doom boleh bertindak sebagai masalah untuk ini algoritma pembelajaran mesin untuk menyelesaikan. Algoritma pembelajaran mendalam, khususnya, mampu mencapai dan bahkan mengatasi prestasi peringkat manusia.
. Persekitaran Pembelajaran Arked atau ALE memberikan penyelidik antara muka untuk lebih seratus permainan Atari 2600. Platform sumber terbuka membolehkan penyelidik menanda aras prestasi teknik pembelajaran mesin pada permainan video Atari klasik. Google juga menerbitkan mereka sendiri kertas menggunakan tujuh permainan daripada ALE

Sementara itu, projek seperti VizDoom memberi peluang kepada penyelidik AI untuk melatih algoritma pembelajaran mesin untuk memainkan penembak orang pertama 3D.

Bagaimana Ia Berfungsi: Beberapa Konsep Utama
Rangkaian Neural
Kebanyakan pendekatan untuk menyelesaikan permainan video dengan pembelajaran mesin melibatkan sejenis algoritma yang dikenali sebagai rangkaian saraf.
Anda boleh menganggap jaring saraf sebagai program yang cuba meniru cara otak berfungsi. Sama seperti bagaimana otak kita terdiri daripada neuron yang menghantar isyarat, jaring saraf juga mengandungi neuron tiruan.
Neuron tiruan ini juga memindahkan isyarat antara satu sama lain, dengan setiap isyarat adalah nombor sebenar. Jaringan saraf mengandungi berbilang lapisan antara lapisan input dan output, dipanggil rangkaian saraf dalam.
Pembelajaran pengukuhan
Satu lagi teknik pembelajaran mesin biasa yang berkaitan dengan pembelajaran permainan video ialah idea pembelajaran pengukuhan.
Teknik ini ialah proses melatih ejen menggunakan ganjaran atau hukuman. Dengan pendekatan ini, ejen sepatutnya dapat menghasilkan penyelesaian kepada masalah melalui percubaan dan kesilapan.
Katakan kita mahukan AI untuk mengetahui cara bermain permainan Ular. Objektif permainan ini adalah mudah: dapatkan mata sebanyak mungkin dengan memakan item dan mengelakkan ekor anda yang semakin membesar.
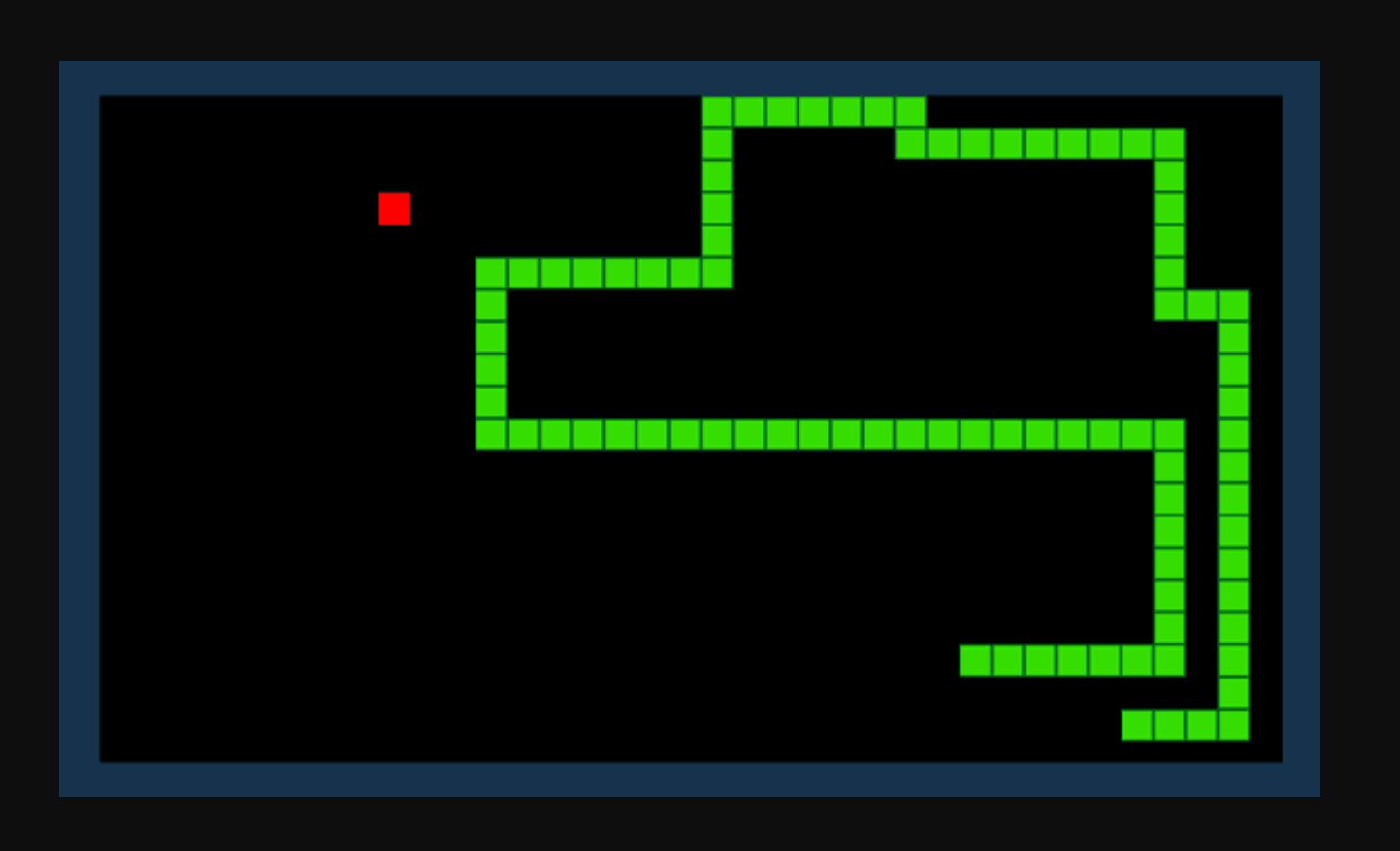
Dengan pembelajaran pengukuhan, kita boleh mentakrifkan fungsi ganjaran R. Fungsi menambah mata apabila Ular menggunakan item dan menolak mata apabila Ular melanggar halangan. Memandangkan persekitaran semasa dan satu set tindakan yang mungkin, model pembelajaran pengukuhan kami akan cuba mengira 'dasar' optimum yang memaksimumkan fungsi ganjaran kami.
Neuroevolusi
Mengekalkan tema dengan diilhamkan oleh alam semula jadi, penyelidik juga telah menemui kejayaan dalam menerapkan ML pada permainan video melalui teknik yang dikenali sebagai neuroevolution.
Daripada menggunakan keturunan kecerunan untuk mengemas kini neuron dalam rangkaian, kita boleh menggunakan algoritma evolusi untuk mencapai hasil yang lebih baik.
Algoritma evolusi biasanya bermula dengan menjana populasi awal individu rawak. Kami kemudian menilai individu ini menggunakan kriteria tertentu. Individu terbaik dipilih sebagai "ibu bapa" dan dibiakkan bersama untuk membentuk individu generasi baharu. Individu ini kemudiannya akan menggantikan individu yang paling kurang cergas dalam populasi.
Algoritma ini juga biasanya memperkenalkan beberapa bentuk operasi mutasi semasa langkah silang atau "pembiakan" untuk mengekalkan kepelbagaian genetik.
Contoh Penyelidikan tentang Pembelajaran Mesin dalam Permainan Video
OpenAI Five

OpenAI Five ialah program komputer oleh OpenAI yang bertujuan untuk bermain DOTA 2, permainan arena pertempuran mudah alih berbilang pemain (MOBA) yang popular.
Program ini memanfaatkan teknik pembelajaran pengukuhan sedia ada, berskala untuk belajar daripada berjuta-juta bingkai sesaat. Terima kasih kepada sistem latihan yang diedarkan, OpenAI dapat bermain permainan bernilai 180 tahun setiap hari.
Selepas tempoh latihan, OpenAI Five dapat mencapai prestasi peringkat pakar dan menunjukkan kerjasama dengan pemain manusia. Pada 2019, OpenAI five dapat mengalahkan 99.4% pemain dalam perlawanan awam.
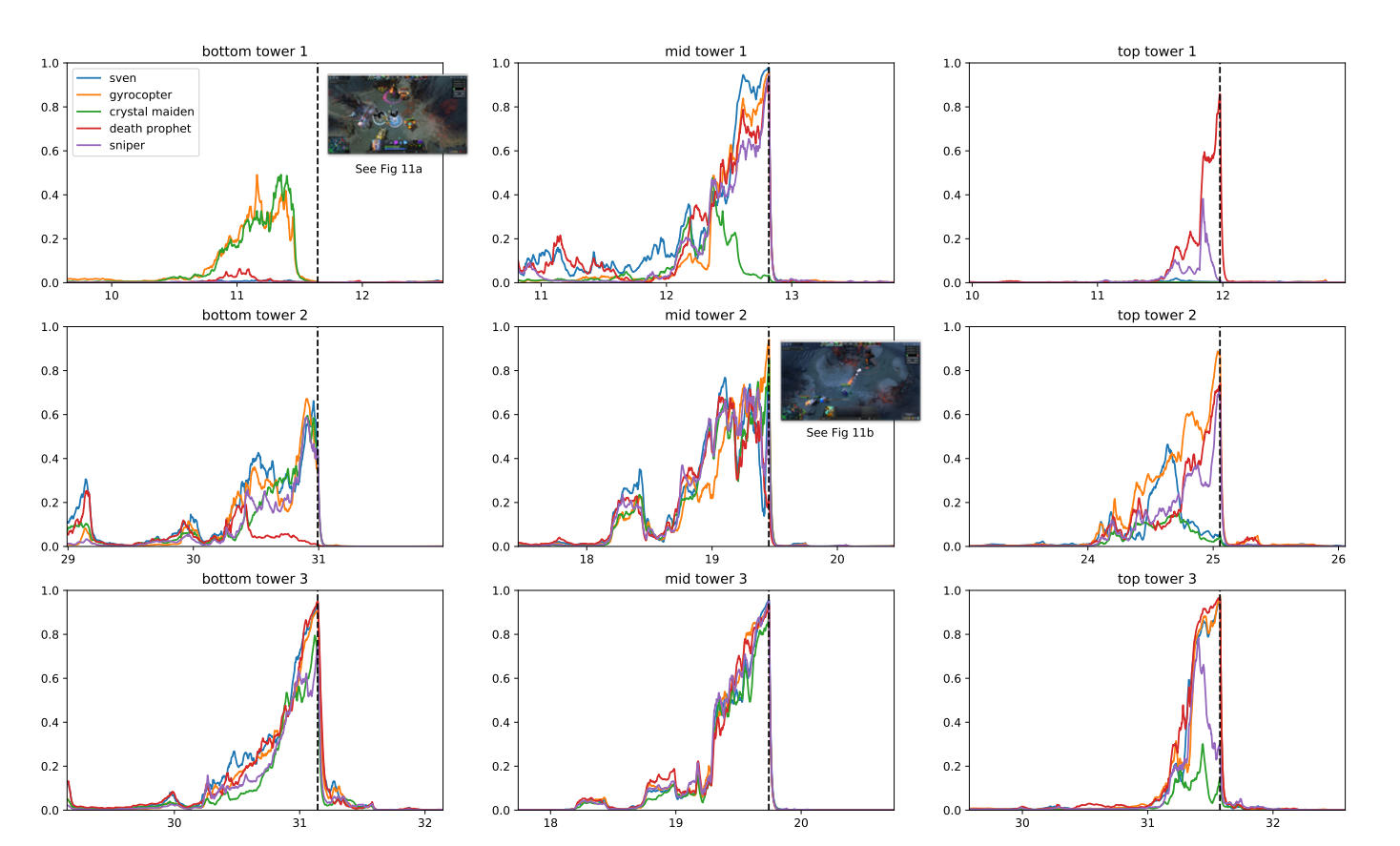
Mengapa OpenAI memutuskan permainan ini? Menurut penyelidik, DOTA 2 mempunyai mekanik kompleks yang berada di luar jangkauan dalam yang sedia ada pembelajaran tetulang algoritma.
Super Mario Bros
Satu lagi aplikasi jaring saraf yang menarik dalam permainan video ialah penggunaan neuroevolution untuk bermain platformer seperti Super Mario Bros.
Contohnya, ini kemasukan hackathon bermula dengan tidak mempunyai pengetahuan tentang permainan dan perlahan-lahan membina asas tentang apa yang diperlukan untuk maju melalui tahap.
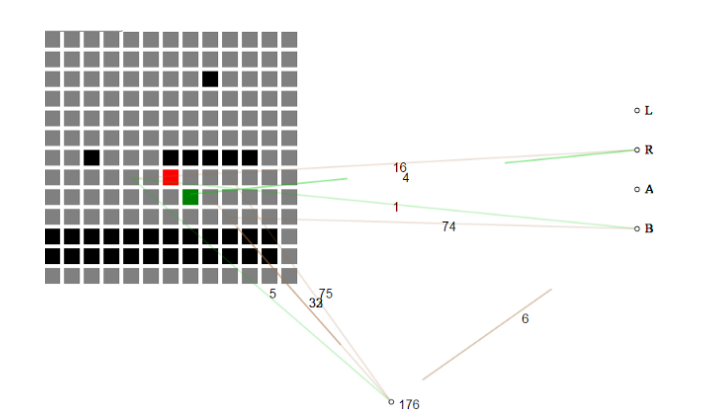
Jaringan saraf yang berkembang sendiri mengambil keadaan semasa permainan sebagai grid jubin. Pada mulanya, jaring saraf tidak memahami maksud setiap jubin, cuma jubin "udara" berbeza daripada "jubin tanah" dan "jubin musuh."
Pelaksanaan neuroevolusi projek hackathon menggunakan algoritma genetik NEAT untuk membiak jaring saraf yang berbeza secara selektif.
kepentingan
Memandangkan anda telah melihat beberapa contoh jaring saraf bermain permainan video, anda mungkin tertanya-tanya apa gunanya semua ini.
Memandangkan permainan video melibatkan interaksi yang kompleks antara ejen dan persekitaran mereka, ia merupakan tempat ujian yang sempurna untuk membuat AI. Persekitaran maya adalah selamat dan boleh dikawal serta menyediakan bekalan data yang tidak terhingga.
Penyelidikan yang dibuat dalam bidang ini telah memberikan para penyelidik gambaran tentang cara jaring saraf boleh dioptimumkan untuk mempelajari cara menyelesaikan masalah di dunia nyata.
Rangkaian saraf diilhamkan oleh cara otak berfungsi di dunia semula jadi. Dengan mengkaji cara neuron tiruan berkelakuan apabila mempelajari cara bermain permainan video, kita juga boleh mendapat gambaran tentang bagaimana otak manusia kerja.
Kesimpulan
Persamaan antara rangkaian saraf dan otak telah membawa kepada pandangan dalam kedua-dua bidang. Penyelidikan berterusan tentang bagaimana jaring saraf boleh menyelesaikan masalah suatu hari nanti boleh membawa kepada bentuk yang lebih maju kecerdasan buatan.
Bayangkan menggunakan AI yang disesuaikan dengan spesifikasi anda yang boleh memainkan keseluruhan permainan video sebelum anda membelinya untuk memberitahu anda sama ada ia berbaloi dengan masa anda. Adakah syarikat permainan video akan menggunakan jaring saraf untuk meningkatkan reka bentuk permainan, tahap tweak dan kesukaran lawan?
Apa yang anda fikir akan berlaku apabila jaring saraf menjadi pemain utama?





Sila tinggalkan balasan anda