Jadual Kandungan[Sembunyi][Tunjukkan]
Model teks-ke-imej yang besar membuat kemajuan yang ketara dalam pembangunan AI dengan menghasilkan sintesis gambar yang berkualiti tinggi dan pelbagai daripada gesaan teks yang diberikan.
Model ini tidak dapat mensintesis perwakilan unik subjek dalam pelbagai tetapan atau untuk meniru penampilan subjek dalam set rujukan yang diberikan.
Teknologi yang baru dikeluarkan seperti DALL.E2 OpenAI atau StabilityAI Resapan Stabil dan Midjourney sudah pun menggunakan internet. Kini tiba masanya untuk menyesuaikan keputusan. Namun bagaimana?
Google DreamBooth AI telah tiba.
DreamBooth mempunyai keupayaan untuk mengenali topik gambar, menyahbina daripada konteks asalnya, dan kemudian mensintesiskannya dengan tepat ke dalam konteks baharu yang dikehendaki. Selain itu, ia boleh digunakan dengan penjana gambar AI semasa.
Dalam artikel ini, kita akan melihat dengan mendalam tentang DreamBooth, penggunaannya, tutorialnya, hadnya dan banyak lagi.
Apa itu Dreambooth?
dreambooth, model penyebaran teks-ke-imej yang serba baharu, telah dipersembahkan oleh Google. Gesaan bertulis boleh digunakan sebagai panduan oleh Google DreamBooth AI untuk menjana pelbagai jenis foto subjek pilihan pengguna dalam tetapan yang berbeza.
Kumpulan penyelidikan dari Universiti Boston dan Google membangunkan DreamBooth, teknik canggih untuk mengubah model teks kepada imej yang telah menjalani pra-latihan yang meluas.
Konsep keseluruhannya agak mudah: mereka mahu meningkatkan kamus penglihatan bahasa supaya ID token yang tidak biasa dikaitkan dengan topik tersuai yang boleh ditentukan oleh pengguna.
Matlamat utama model adalah untuk menghubungkan pengguna ke model penyebaran teks ke imej dengan memberi mereka sumber yang mereka perlukan untuk menghasilkan perwakilan fotorealistik bagi contoh perkara subjek pilihan mereka.
Akibatnya, teknik ini nampaknya berfungsi dengan baik untuk meringkaskan cabaran dalam pelbagai situasi.
DreamBooth Google berbeza daripada alatan teks-ke-imej sebelumnya, seperti DALL-E2, Resapan Stabil, dan Pertengahan perjalanan, kerana ia memberi pengguna lebih kawalan ke atas imej topik sebelum membenarkan mereka memanipulasi model resapan menggunakan input berasaskan teks.
Ciri-ciri
- DreamBooth AI mungkin menambah baik model teks ke imej dengan 3-5 imej.
- Foto fotorealistik asal boleh dibuat dengan DreamBooth AI.
- Selain itu, DreamBooth AI boleh mencipta foto topik dari pelbagai sudut.
Kesesuaian
Persembahan Seni
Tugas ini berbeza secara khusus daripada pemindahan gaya, yang mengekalkan semantik adegan sumber sambil menggabungkan gaya imej lain ke dalam adegan asal.

Berdasarkan pendekatan kreatif, AI boleh mencapai perubahan adegan yang ketara sambil mengekalkan pengenalan dan spesifik contoh topik.
Pengubahsuaian Harta
Ciri-ciri contoh subjek boleh diubah suai oleh DreamBooth AI.

Aksesori
Komposisi yang kukuh sebelum model penjanaan inilah yang menjadikan keupayaan DreamBooth AI untuk menghiasi objek begitu menarik.

Kontekstualisasi semula
DreamBooth AI boleh menghasilkan imej tersendiri untuk contoh subjek tertentu dengan memberikan model terlatih ayat yang merangkumi pengecam unik dan kata nama kelas.

Ia boleh menjana subjek dalam postur, artikulasi dan struktur pemandangan yang unik dan tidak pernah didengari sebelum ini daripada mengubah persekitaran. Pantulan dan bayang yang realistik, serta interaksi antara subjek dan objek sekeliling.
Tutorial Dreambooth
Dalam tutorial ini, kami akan mengikuti Buku nota Google Collab, dan saya akan membimbing anda melaluinya, yang akan membuat anda memahami dan menggunakannya sendiri.
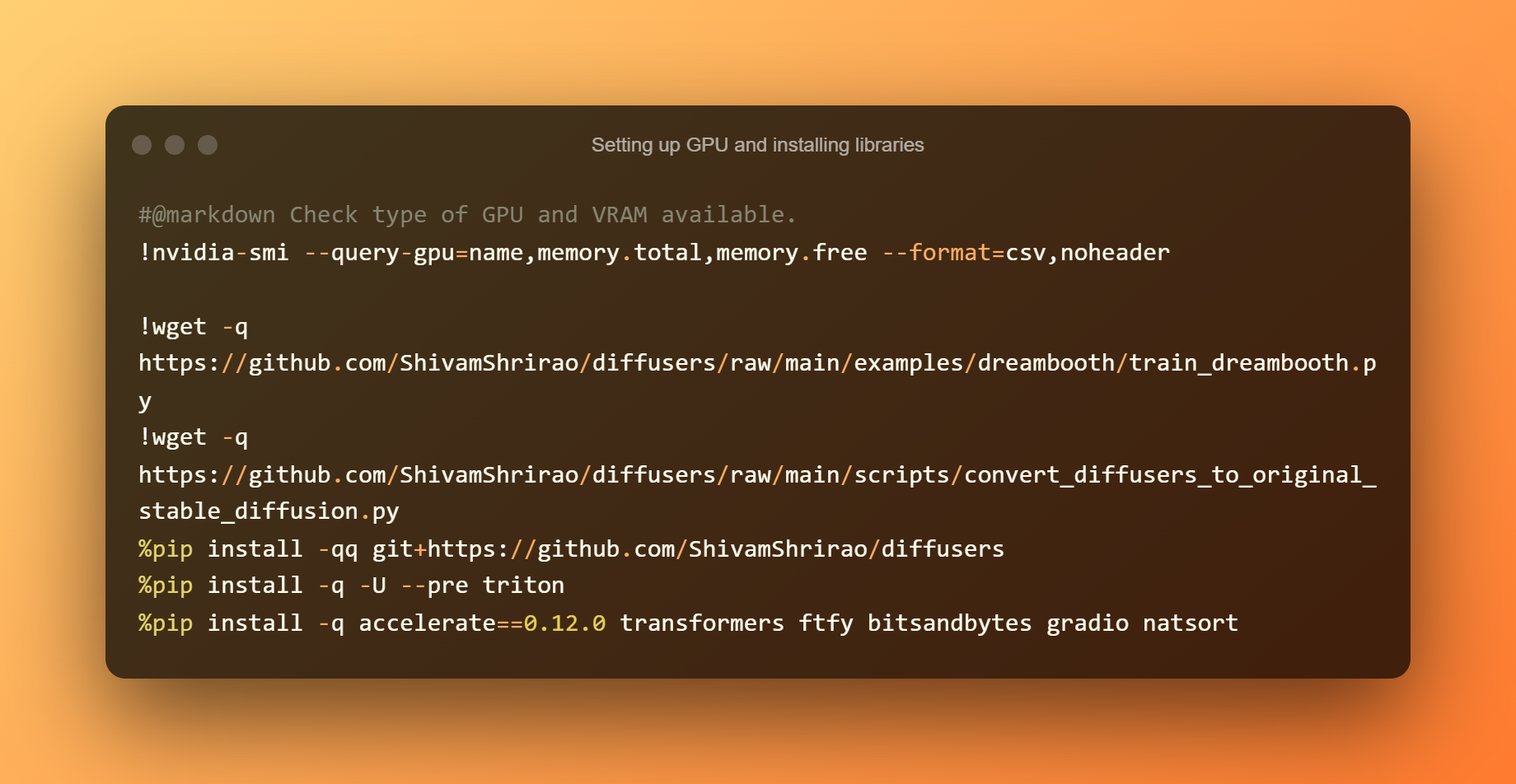
Menyediakan GPU dan memasang perpustakaan
Mengetahui jenis GPU dan VRAM yang tersedia ialah langkah pertama. Memasang beberapa keperluan dan kebergantungan juga perlu. Hanya tekan butang main, kemudian tunggu sehingga ia selesai.
Buat akaun di Huggingface dan jana token
Langkah seterusnya ialah mendaftar untuk akaun Huggingface. Apabila anda selesai, klik tetapan di penjuru kanan sebelah atas. Anda akan tiba di halaman seterusnya.
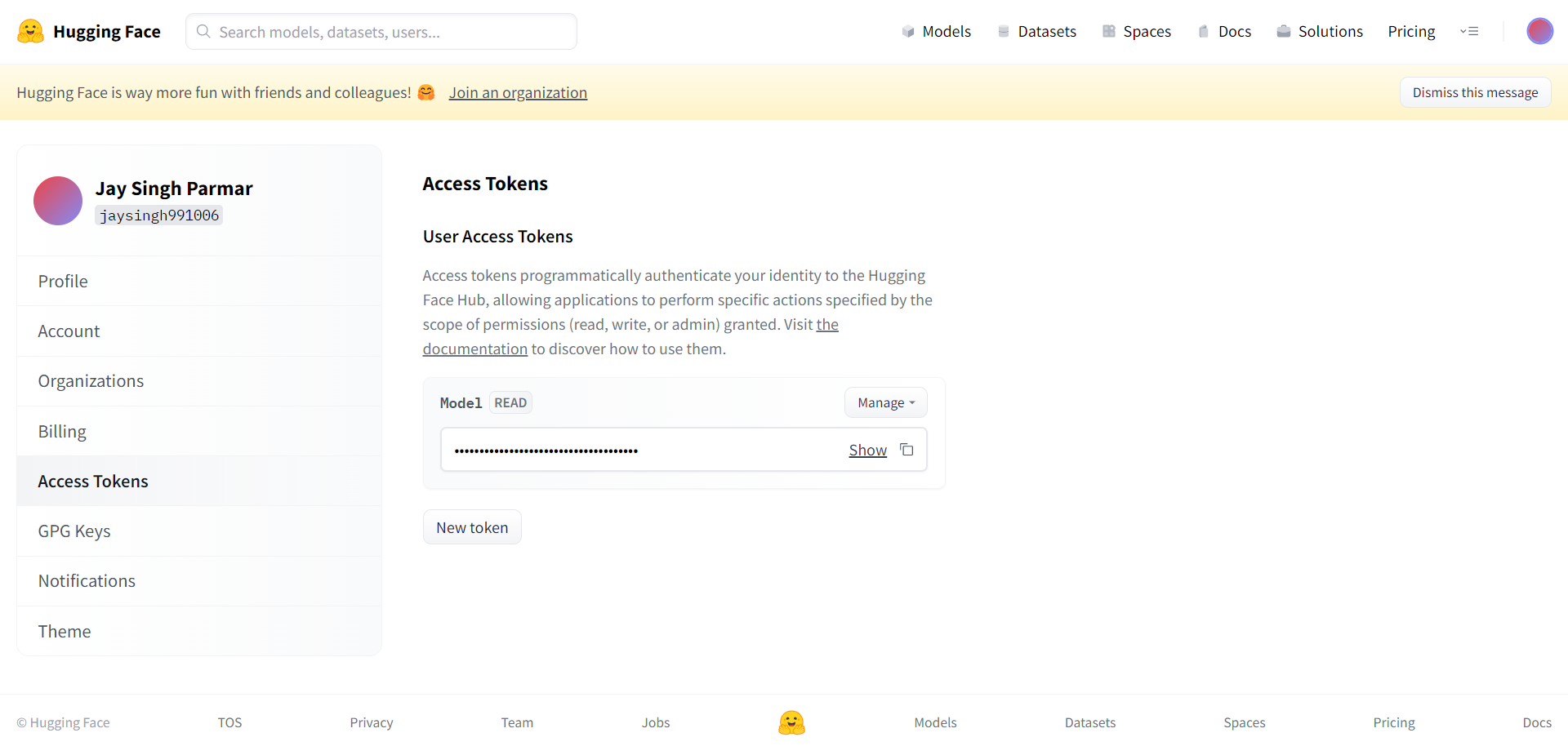
Cipta token dan nama seperti yang diminta dari sini. Token hendaklah disalin dan ditampal ke dalam kolaborasi Google dalam sel di bawah.

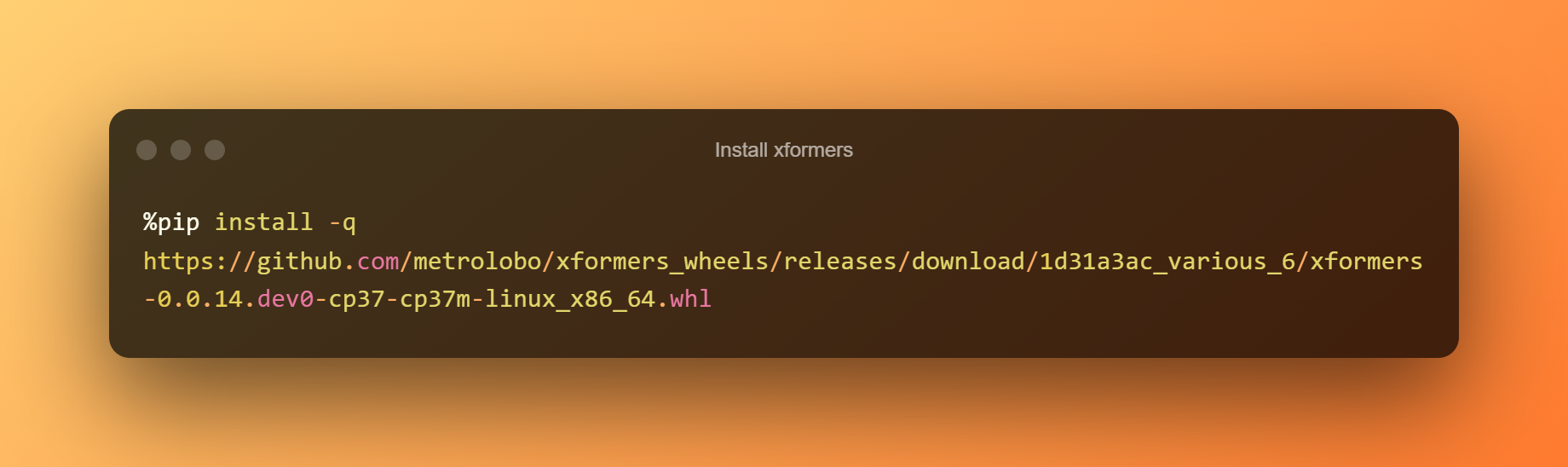
Pasang xformers
Pada peringkat ini, anda hanya boleh menekan butang main untuk memasang xformers dengan mengklik pada masa jalan.
Sambung ke Drive
Sekarang, anda hanya perlu menjalankan sel ini untuk menyambung ke pemacu google.
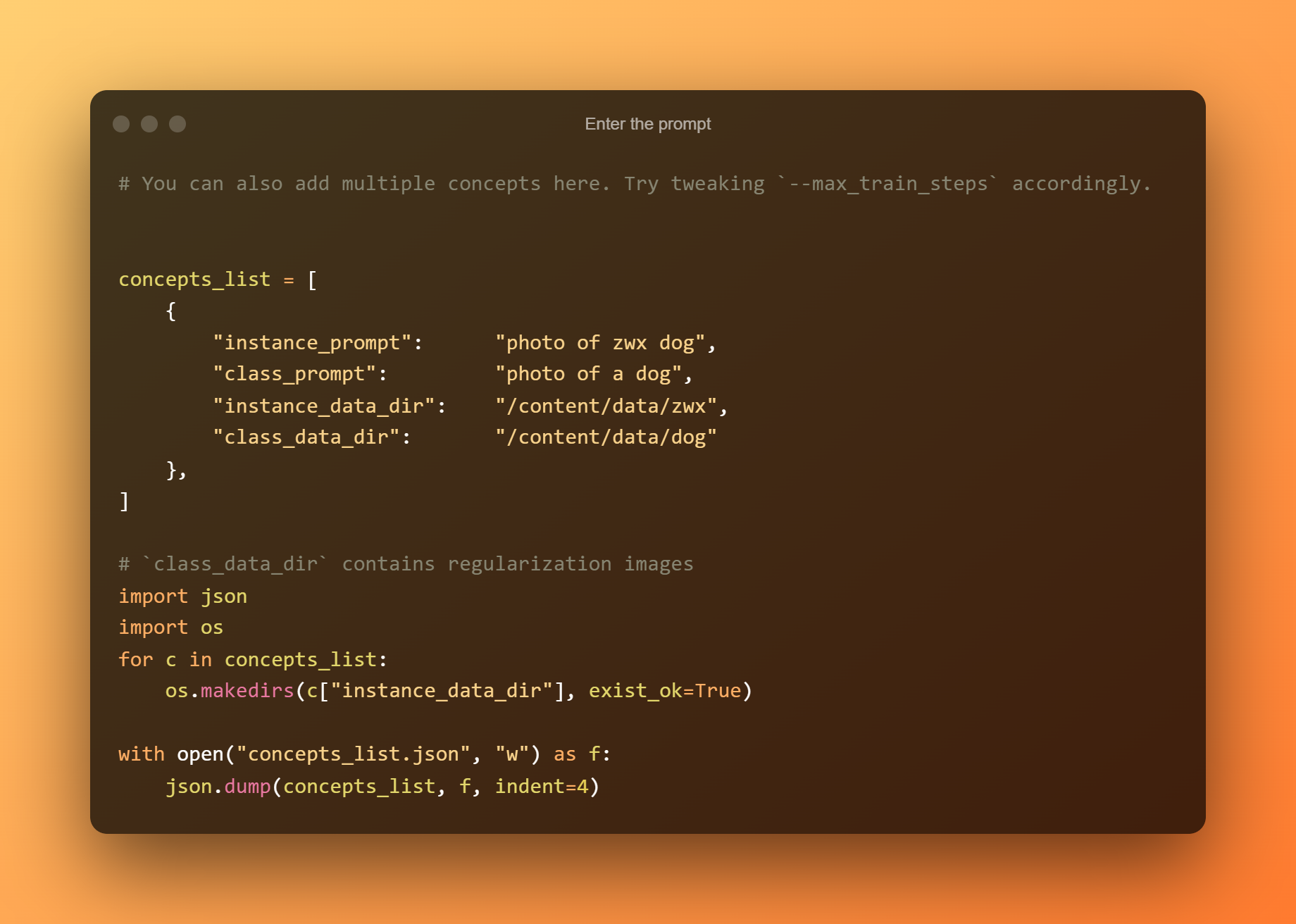
Masukkan gesaan
Dalam sel berikut, anda hanya perlu memasukkan gesaan.
Memuat naik gambar
Dalam langkah ini, anda hanya perlu memuat naik gambar yang anda ingin latih.

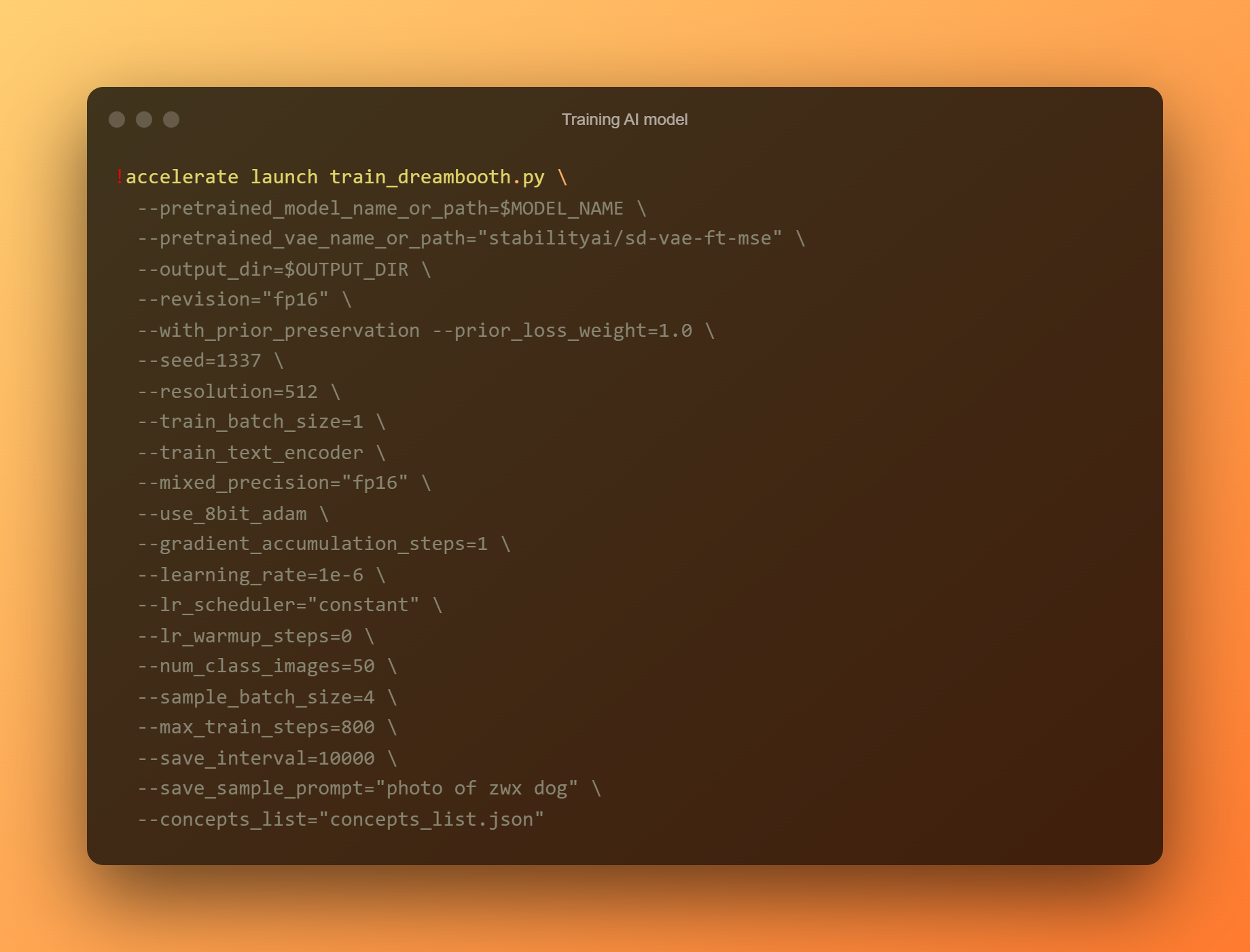
Latih model AI
Ini adalah fasa yang paling penting, kerana anda akan menggunakan DreamBooth untuk melatih model AI baharu berdasarkan semua gambar rujukan anda yang diserahkan. Anda mesti mengehadkan perhatian anda kepada dua medan input. “—instance prompt” ialah parameter pertama. Anda mesti memberikan nama yang sangat berbeza di sini.
Argumen '–senarai konsep' ialah medan input kritikal kedua. Ia mesti dinamakan semula supaya sepadan dengan yang digunakan dalam bahagian 'Tukar gesaan'.
Hasilkan imej AI
Gambar AI akan dibuat pada peringkat ini, di mana anda boleh memasukkan arahan teks.

Had Dreambooth
- Gesaan arahan menjadi penghalang untuk membuat lelaran dalam topik dengan tahap perincian yang tinggi. DreamBooth boleh menukar konteks subjek, tetapi jika model ingin menukar subjek itu sendiri, terdapat masalah dengan bingkai.
- Isu lain ialah overfitting gambar output kepada imej input. Jika tidak ada gambar yang mencukupi yang dibekalkan, subjek mungkin tidak dipertimbangkan atau mungkin digabungkan dengan konteks imej yang diserahkan. Apabila konteks untuk generasi ganjil ditanya, perkara yang sama berlaku.
Kesimpulan
Untuk menghasilkan output daripada satu input teks, sebahagian besar model teks-ke-imej memerlukan berjuta-juta parameter dan perpustakaan.
DreamBooth memudahkan pemerolehan dan penggunaan kandungan untuk pengguna dengan hanya memerlukan input tiga hingga lima gambar topik berserta latar belakang teks.





Sila tinggalkan balasan anda