Jadual Kandungan[Sembunyi][Tunjukkan]
Masa depan di sini. Dan, pada masa hadapan mesin ini memahami dunia di sekeliling mereka dengan cara yang sama seperti yang dilakukan oleh orang ramai. Komputer boleh memandu kereta, mendiagnosis penyakit dan meramal masa depan dengan tepat.
Ini mungkin kelihatan seperti fiksyen sains, tetapi model pembelajaran mendalam menjadikannya realiti.
Algoritma canggih ini mendedahkan rahsia kecerdasan buatan, membolehkan komputer belajar sendiri dan berkembang. Dalam siaran ini, kita akan mendalami bidang model pembelajaran mendalam.
Dan, kita akan menyiasat potensi besar yang mereka ada untuk merevolusikan kehidupan kita. Bersedia untuk belajar tentang teknologi canggih yang mengubah masa depan manusia.

Apakah Sebenarnya Model Pembelajaran Dalam?
Pernahkah anda bermain permainan di mana anda perlu mengenal pasti perbezaan antara dua imej?
Ia menyeronokkan namun, ia juga boleh menjadi sukar, bukan? Bayangkan anda boleh mengajar komputer bermain permainan itu dan menang setiap kali. Model pembelajaran mendalam mencapai perkara itu!
Model pembelajaran mendalam adalah serupa dengan mesin super pintar yang boleh memeriksa sejumlah besar imej dan menentukan persamaan mereka. Mereka mencapai ini dengan membuka imej dan mengkaji setiap satu secara individu.
Mereka kemudian menggunakan apa yang mereka pelajari untuk mengenal pasti corak dan membuat ramalan tentang imej baharu yang tidak pernah mereka lihat sebelum ini.

Model pembelajaran mendalam ialah rangkaian saraf tiruan yang boleh mempelajari dan mengekstrak corak dan ciri rumit daripada set data besar-besaran. Model ini terdiri daripada beberapa lapisan nod terpaut, atau neuron, yang menganalisis dan mengubah data masuk untuk menjana output.
Model pembelajaran mendalam amat sesuai untuk pekerjaan yang memerlukan ketepatan dan ketepatan yang tinggi, seperti pengenalan imej, pengecaman pertuturan, pemprosesan bahasa semula jadi dan robotik.
Mereka telah digunakan dalam segala-galanya daripada kereta pandu sendiri kepada diagnostik perubatan, sistem pengesyor dan analisis ramalan.
Berikut ialah versi ringkas visualisasi untuk menggambarkan aliran data dalam model pembelajaran mendalam.
Data input mengalir ke lapisan input model, yang kemudiannya menghantar data melalui beberapa lapisan tersembunyi sebelum memberikan ramalan output.
Setiap lapisan tersembunyi melakukan satu siri operasi matematik pada data input sebelum menghantarnya ke lapisan seterusnya, yang menyediakan ramalan akhir.
Sekarang, mari kita lihat apakah model pembelajaran mendalam dan bagaimana kita boleh menggunakannya dalam kehidupan kita.
1. Rangkaian Neural Konvolusi (CNN)
CNN ialah model pembelajaran mendalam yang telah mengubah bidang penglihatan komputer. CNN digunakan untuk mengklasifikasikan imej, mengecam objek dan membahagikan imej. Struktur dan fungsi korteks visual manusia memaklumkan reka bentuk CNN.
Bagaimana Mereka Bekerja?
CNN terdiri daripada beberapa lapisan konvolusi, lapisan pengumpulan dan lapisan terpaut sepenuhnya. Input adalah imej, dan output adalah ramalan label kelas imej.
Lapisan konvolusi CNN membina peta ciri dengan melakukan produk titik antara gambar input dan satu set penapis. Lapisan penggabungan mengurangkan saiz peta ciri dengan mengurangkan pensampelannya.
Akhir sekali, peta ciri digunakan oleh lapisan yang disambungkan sepenuhnya untuk meramalkan label kelas imej.

Mengapa CNN Penting?
CNN adalah penting kerana mereka boleh belajar untuk mengesan corak dan ciri dalam imej yang sukar dilihat oleh orang ramai. CNN boleh diajar untuk mengenali ciri seperti tepi, bucu dan tekstur menggunakan set data yang besar. Selepas mempelajari sifat ini, CNN boleh menggunakannya untuk mengenal pasti objek dalam foto baharu. CNN telah menunjukkan prestasi canggih pada pelbagai aplikasi pengenalan imej.
Di mana Kami Menggunakan CNN
Penjagaan kesihatan, industri auto dan runcit hanyalah beberapa sektor yang menggunakan CNN. Dalam industri penjagaan kesihatan, mereka boleh memberi manfaat untuk diagnosis penyakit, pembangunan ubat, dan analisis imej perubatan.
Dalam sektor automobil, mereka membantu pengesanan lorong, pengesanan objek, dan pemanduan autonomi. Ia juga banyak digunakan dalam runcit untuk carian visual, pengesyoran produk berasaskan imej dan kawalan inventori.
Sebagai contoh; Google menggunakan CNN dalam pelbagai aplikasi, termasuk Lensa Google, alat pengenalan imej yang disukai ramai. Program ini menggunakan CNN untuk menilai gambar dan memberi maklumat kepada pengguna.
Google Lens, contohnya, boleh mengecam sesuatu dalam imej dan menawarkan butiran tentangnya, seperti jenis bunga.

Ia juga boleh menterjemah teks yang diekstrak daripada gambar ke dalam pelbagai bahasa. Google Lens dapat memberi pengguna maklumat berguna kerana bantuan CNN dalam mengenal pasti item dengan tepat dan mengekstrak ciri daripada foto.
2. Rangkaian Memori Jangka Pendek Panjang (LSTM).
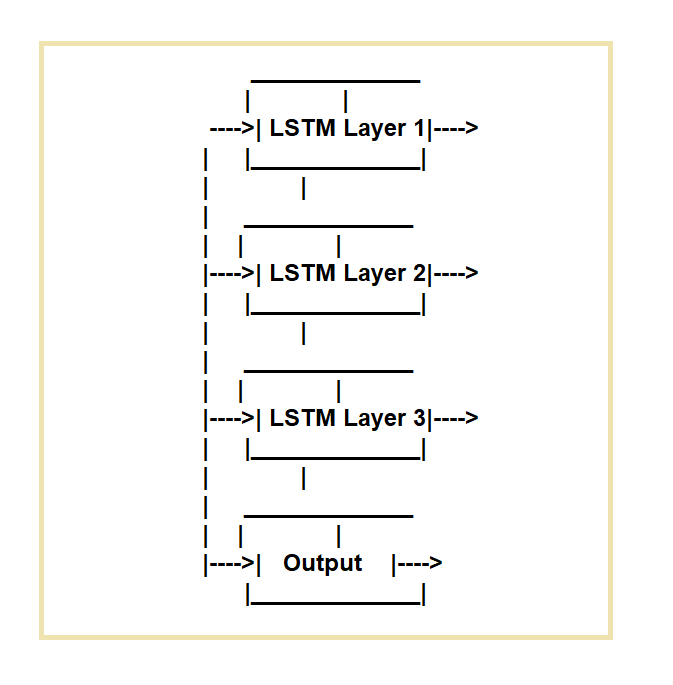
Rangkaian Memori Jangka Pendek Panjang (LSTM) dicipta untuk menangani kelemahan rangkaian saraf berulang biasa (RNN). Rangkaian LSTM sesuai untuk tugasan yang menuntut pemprosesan jujukan data merentas masa.
Mereka berfungsi dengan menggunakan sel memori tertentu dan tiga mekanisme gating.
Mereka mengawal aliran maklumat masuk dan keluar dari sel. Gerbang input, get lupa dan get keluaran adalah tiga get.
Gerbang input mengawal aliran data ke dalam sel memori, get lupa mengawal pemadaman data daripada sel, dan get keluaran mengawal aliran data keluar dari sel.
Apakah Kepentingan mereka?
Rangkaian LSTM berguna kerana ia boleh berjaya mewakili dan meramalkan jujukan data dengan perhubungan jangka panjang. Mereka boleh merekod dan menyimpan maklumat tentang input terdahulu, membolehkan mereka membuat ramalan yang lebih tepat tentang input masa hadapan.
Pengecaman pertuturan, pengecaman tulisan tangan, pemprosesan bahasa semula jadi dan kapsyen gambar hanyalah beberapa daripada aplikasi yang telah menggunakan rangkaian LSTM.
Di Mana Kami Menggunakan Rangkaian LSTM?
Banyak aplikasi perisian dan teknologi menggunakan rangkaian LSTM, termasuk sistem pengecaman pertuturan, alat pemprosesan bahasa semula jadi seperti analisis sentimen, sistem terjemahan mesin, dan sistem penjanaan teks dan gambar.
Mereka juga telah digunakan dalam penciptaan kereta pandu sendiri dan robot, serta dalam industri kewangan untuk mengesan penipuan dan menjangka pasaran saham pergerakan.
3. Rangkaian Musuh Generatif (GAN)
GAN ialah a pembelajaran mendalam teknik yang digunakan untuk menjana sampel data baharu yang serupa dengan set data yang diberikan. GAN terdiri daripada dua rangkaian saraf: satu yang belajar menghasilkan sampel baharu dan satu yang belajar membezakan antara sampel tulen dan terjana.
Dalam pendekatan yang sama, kedua-dua rangkaian ini dilatih bersama sehingga penjana boleh menghasilkan sampel yang tidak dapat dibezakan daripada yang sebenar.
Mengapa Kami Menggunakan GAN
GAN adalah penting kerana kapasiti mereka untuk menghasilkan kualiti tinggi data sintetik yang boleh digunakan untuk pelbagai aplikasi, termasuk pengeluaran gambar dan video, penjanaan teks, dan juga penjanaan muzik.
GAN juga telah digunakan untuk penambahan data, yang merupakan penjanaan data sintetik untuk menambah data dunia sebenar dan meningkatkan prestasi model pembelajaran mesin.
Tambahan pula, dengan mencipta data sintetik yang boleh digunakan untuk melatih model dan meniru percubaan, GAN mempunyai potensi untuk mengubah sektor seperti perubatan dan pembangunan ubat.

Aplikasi GAN
GAN boleh menambah set data, mencipta gambar atau filem baharu, dan juga menjana data sintetik untuk simulasi saintifik. Tambahan pula, GAN mempunyai potensi untuk digunakan dalam pelbagai aplikasi daripada hiburan kepada perubatan.
umur dan video. NVIDIA's StyleGAN2, sebagai contoh, telah digunakan untuk mencipta gambar-gambar selebriti dan karya seni yang berkualiti tinggi.
4. Rangkaian Kepercayaan Dalam (DBN)
Rangkaian Kepercayaan Dalam (DBN) ialah kecerdasan buatan sistem yang boleh belajar mengesan corak dalam data. Mereka mencapai ini dengan membahagikan data kepada bahagian yang lebih kecil dan lebih kecil, memperoleh pemahaman yang lebih teliti mengenainya pada setiap peringkat.
DBN mungkin belajar daripada data tanpa dimaklumkan apa itu (ini dirujuk sebagai "pembelajaran tanpa pengawasan"). Ini menjadikan mereka amat berharga untuk mengesan corak dalam data yang sukar atau mustahil untuk dilihat oleh seseorang.
Apa yang Menjadikan DBN Penting?
DBN adalah penting kerana keupayaan mereka untuk mempelajari perwakilan data hierarki. Perwakilan ini boleh digunakan untuk pelbagai aplikasi seperti pengelasan, pengesanan anomali dan pengurangan dimensi.
Keupayaan DBN untuk menjalankan pra-latihan tanpa pengawasan, yang boleh meningkatkan prestasi model pembelajaran mendalam dengan data berlabel minimum, adalah manfaat yang ketara.

Apakah Aplikasi DBN?
Salah satu aplikasi yang paling penting ialah pengesanan objek, di mana DBN digunakan untuk mengenali jenis perkara tertentu seperti kapal terbang, burung dan manusia. Ia juga digunakan untuk penjanaan dan pengelasan imej, pengesanan gerakan dalam filem, dan pemahaman bahasa semula jadi untuk pemprosesan suara.
Tambahan pula, DBN biasanya digunakan dalam set data untuk menilai postur manusia. DBN ialah alat yang hebat untuk pelbagai industri, termasuk penjagaan kesihatan dan perbankan serta teknologi.
5. Rangkaian Pembelajaran Pengukuhan Dalam (DRL)
Deep Pembelajaran Pengukuhan Rangkaian (DRL) mengintegrasikan rangkaian saraf dalam dengan teknik pembelajaran pengukuhan untuk membolehkan ejen belajar dalam persekitaran yang rumit melalui percubaan dan kesilapan.
DRL digunakan untuk mengajar ejen cara mengoptimumkan isyarat ganjaran dengan berinteraksi dengan persekitaran mereka dan belajar daripada kesilapan mereka.
Apa yang Membuatkan Mereka Luar Biasa?
Ia telah digunakan dengan berkesan dalam pelbagai aplikasi, termasuk permainan, robotik dan pemanduan autonomi. DRL adalah penting kerana mereka boleh belajar secara langsung daripada input deria mentah, membolehkan ejen membuat keputusan berdasarkan interaksi mereka dengan persekitaran.
Aplikasi Penting
DRL digunakan dalam keadaan dunia sebenar kerana mereka boleh menangani isu yang sukar.
DRL telah disertakan dalam beberapa perisian dan platform teknologi terkemuka, termasuk Gim OpenAI, Ejen ML Unity, dan Makmal DeepMind Google. AlphaGo, dibina oleh Google Deepmind, sebagai contoh, menggunakan DRL untuk bermain permainan papan Go di peringkat juara dunia.

Satu lagi kegunaan DRL ialah dalam robotik, di mana ia digunakan untuk mengawal pergerakan lengan robot untuk melaksanakan tugas seperti mencengkam benda atau menyusun blok. DRL mempunyai banyak kegunaan dan merupakan alat yang berguna untuk melatih ejen untuk belajar dan membuat keputusan dalam tetapan yang rumit.
6. Pengekod automatik
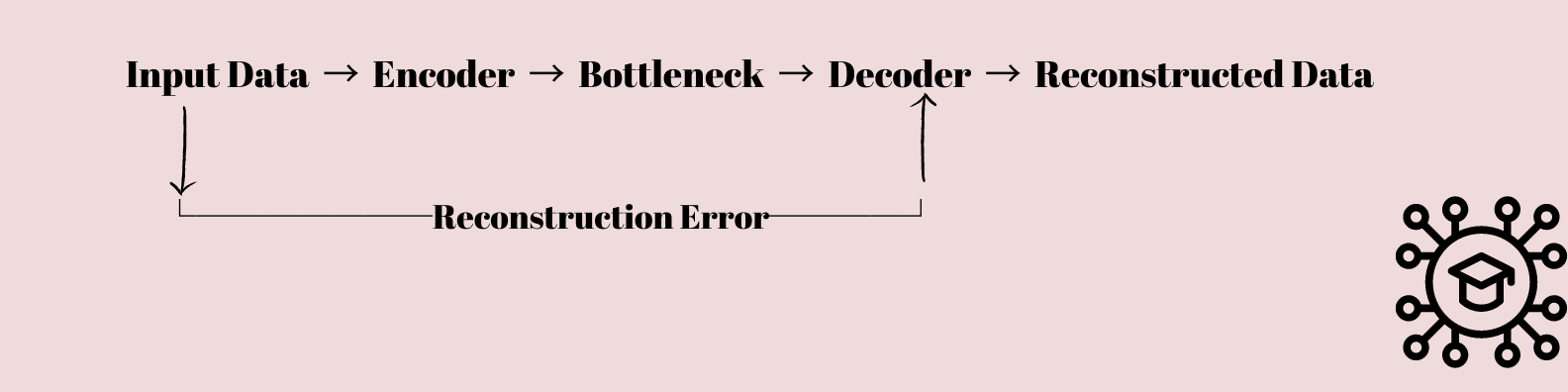
Autoencoders ialah jenis yang menarik rangkaian neural yang telah menarik minat kedua-dua sarjana dan saintis data. Mereka pada asasnya direka untuk mempelajari cara memampatkan dan memulihkan data.
Data input disalurkan melalui penggantian lapisan yang menurunkan dimensi data secara beransur-ansur sehingga ia dimampatkan ke dalam lapisan bottleneck dengan nod yang lebih sedikit daripada lapisan input dan output.
Perwakilan termampat ini kemudiannya digunakan untuk mencipta semula data input asal menggunakan urutan lapisan yang secara beransur-ansur meningkatkan dimensi data kembali kepada bentuk asalnya.
Mengapa Penting?
Pengekod auto ialah komponen penting bagi pembelajaran mendalam kerana mereka memungkinkan pengekstrakan ciri dan pengurangan data.
Mereka dapat mengenal pasti elemen utama data masuk dan menterjemahkannya ke dalam bentuk termampat yang kemudiannya boleh digunakan pada tugas lain seperti pengelasan, pengumpulan atau penciptaan data baharu.
Di Mana Kami Menggunakan Autoencoders?
Pengesanan anomali, pemprosesan bahasa semula jadi, dan penglihatan komputer hanyalah beberapa disiplin di mana pengekod auto digunakan. Autoencoders, misalnya, boleh digunakan untuk pemampatan imej, penyahnosian imej dan sintesis gambar dalam penglihatan komputer.
Kami boleh menggunakan Pengekod Auto dalam tugas seperti penciptaan teks, pengkategorian teks dan ringkasan teks dalam pemprosesan bahasa semula jadi. Ia boleh mengenal pasti aktiviti anomali dalam data yang menyimpang daripada norma dalam pengenalpastian anomali.
7. Rangkaian Kapsul
Capsule Networks ialah seni bina pembelajaran mendalam baharu yang dibangunkan sebagai pengganti Rangkaian Neural Konvolusi (CNN).
Rangkaian Kapsul adalah berdasarkan tanggapan mengelompokkan unit otak yang dipanggil kapsul yang bertanggungjawab untuk mengiktiraf kewujudan item tertentu dalam imej dan mengekodkan atributnya, seperti orientasi dan kedudukan, ke dalam vektor keluarannya. Oleh itu, Rangkaian Kapsul boleh mengurus interaksi spatial dan turun naik perspektif dengan lebih baik daripada CNN.
Mengapa Kami Memilih Rangkaian Kapsul berbanding CNN?
Rangkaian Kapsul berguna kerana ia mengatasi kesukaran CNN dalam menangkap hubungan hierarki antara item dalam gambar. CNN boleh mengenali pelbagai saiz tetapi sukar untuk memahami cara item ini bersambung antara satu sama lain.
Rangkaian Kapsul, sebaliknya, boleh belajar mengenali sesuatu dan kepingannya, serta cara ia diletakkan secara spatial dalam imej, menjadikannya pesaing yang berdaya maju untuk aplikasi penglihatan komputer.
Bidang Permohonan
Rangkaian Kapsul telah pun menunjukkan hasil yang menjanjikan dalam pelbagai aplikasi, termasuk klasifikasi imej, pengenalan objek dan pembahagian gambar.
Mereka telah digunakan untuk membezakan perkara dalam foto perubatan, mengenali orang dalam filem, dan juga mencipta model 3D daripada imej 2D.
Untuk meningkatkan prestasi mereka, Rangkaian Kapsul telah digabungkan dengan seni bina pembelajaran mendalam yang lain seperti Generative Adversarial Networks (GAN) dan Variational Autoencoders (VAEs). Rangkaian Kapsul dijangka memainkan peranan yang semakin penting dalam meningkatkan teknologi penglihatan komputer apabila sains pembelajaran mendalam berkembang.
Sebagai contoh; Nibabel ialah alat Python yang terkenal untuk membaca dan menulis jenis fail neuroimaging. Untuk pembahagian imej, ia menggunakan Capsule Networks.
8. Model berasaskan perhatian
Model pembelajaran mendalam yang dikenali sebagai model berasaskan perhatian, juga dikenali sebagai mekanisme perhatian, berusaha untuk meningkatkan ketepatan model pembelajaran mesin. Model ini berfungsi dengan menumpukan pada ciri tertentu data masuk, menghasilkan pemprosesan yang lebih cekap dan berkesan.
Dalam tugas pemprosesan bahasa semula jadi seperti terjemahan mesin dan analisis sentimen, kaedah perhatian telah terbukti agak berjaya.
Apa Kepentingan Mereka?
Model berasaskan perhatian berguna kerana ia membolehkan pemprosesan data rumit yang lebih berkesan dan cekap.
Rangkaian saraf tradisional menilai semua data input sebagai sama penting, menyebabkan pemprosesan yang lebih perlahan dan ketepatan yang berkurangan. Proses perhatian menumpukan pada aspek penting data input, membolehkan ramalan yang lebih cepat dan lebih tepat.

Bidang Penggunaan
Dalam bidang kecerdasan buatan, mekanisme perhatian mempunyai pelbagai aplikasi, termasuk pemprosesan bahasa semula jadi, pengecaman gambar dan audio, dan juga kenderaan tanpa pemandu.
Kaedah perhatian, sebagai contoh, boleh digunakan untuk menambah baik terjemahan mesin dalam pemprosesan bahasa semula jadi dengan membenarkan sistem memfokus pada perkataan atau frasa tertentu yang penting untuk konteks.
Kaedah perhatian dalam kereta autonomi boleh digunakan untuk membantu sistem memfokuskan pada item atau cabaran tertentu dalam persekitarannya.
9. Rangkaian Transformer
Rangkaian Transformer ialah model pembelajaran mendalam yang meneliti dan menghasilkan jujukan data. Mereka berfungsi dengan memproses jujukan input satu elemen pada satu masa dan menghasilkan jujukan output dengan panjang yang sama atau berbeza.
Rangkaian pengubah, tidak seperti model jujukan-ke-jujukan standard, tidak memproses jujukan menggunakan rangkaian saraf berulang (RNN). Sebaliknya, mereka menggunakan proses perhatian diri untuk mempelajari hubungan antara kepingan urutan.
Apakah Kepentingan Rangkaian Transformer?
Rangkaian transformer telah berkembang popular dalam beberapa tahun kebelakangan ini hasil daripada prestasi mereka yang lebih baik dalam pekerjaan pemprosesan bahasa semula jadi.
Mereka amat sesuai untuk tugas penciptaan teks seperti terjemahan bahasa, ringkasan teks dan penghasilan perbualan.
Rangkaian pengubah adalah jauh lebih cekap dari segi pengiraan daripada model berasaskan RNN, menjadikannya pilihan pilihan untuk aplikasi berskala besar.

Di Mana Anda Boleh Cari Rangkaian Transformer?
Rangkaian pengubah digunakan secara meluas dalam pelbagai aplikasi, terutamanya pemprosesan bahasa semula jadi.
Siri GPT (Generative Pre-trained Transformer) ialah model berasaskan transformer terkemuka yang telah digunakan untuk tugasan seperti terjemahan bahasa, ringkasan teks dan penjanaan chatbot.
BERT (Perwakilan Pengekod Dua Arah daripada Transformers) ialah satu lagi model berasaskan pengubah biasa yang telah digunakan untuk aplikasi pemahaman bahasa semula jadi seperti menjawab soalan dan analisis sentimen.
Kedua-dua GPT dan BERT dicipta dengan PyTorch, rangka kerja pembelajaran dalam sumber terbuka yang telah popular untuk membangunkan model berasaskan transformer.
10. Mesin Boltzmann Terhad( RBM)
Mesin Boltzmann Terhad (RBM) ialah sejenis rangkaian saraf tanpa pengawasan yang belajar secara generatif. Oleh kerana keupayaan mereka untuk mempelajari dan mengekstrak ciri penting daripada data berdimensi tinggi, mereka telah digunakan secara meluas dalam bidang pembelajaran mesin dan pembelajaran mendalam.
RBM terdiri daripada dua lapisan, kelihatan dan tersembunyi, dengan setiap lapisan terdiri daripada sekumpulan neuron yang disambungkan oleh tepi berwajaran. RBM direka bentuk untuk mempelajari taburan kebarangkalian yang menerangkan data input.
Apakah Mesin Boltzmann Terhad?
RBM menggunakan strategi pembelajaran generatif. Dalam RBM, lapisan kelihatan mencerminkan data input, manakala lapisan terkubur mengekodkan ciri data input. Berat lapisan yang kelihatan dan tersembunyi menunjukkan kekuatan pautannya.
RBM melaraskan berat dan berat sebelah antara lapisan semasa latihan menggunakan teknik yang dikenali sebagai perbezaan kontrastif. Contrastive divergence ialah strategi pembelajaran tanpa pengawasan yang memaksimumkan kemungkinan ramalan model.
Apakah kepentingan Mesin Boltzmann Terhad?
RBM adalah penting dalam pembelajaran mesin dan pembelajaran mendalam kerana mereka boleh mempelajari dan mengekstrak ciri-ciri yang berkaitan daripada sejumlah besar data.
Ia sangat berkesan untuk pengecaman gambar dan pertuturan, dan ia telah digunakan dalam pelbagai aplikasi seperti sistem pengesyor, pengesanan anomali dan pengurangan dimensi. RBM boleh mencari corak dalam set data yang luas, menghasilkan ramalan dan cerapan yang unggul.

Di manakah Mesin Boltzmann Terhad boleh digunakan?
Aplikasi untuk RBM termasuk pengurangan dimensi, pengesanan anomali dan sistem pengesyoran. RBM amat membantu untuk analisis sentimen dan pemodelan topik dalam konteks pemprosesan bahasa semula jadi.
Rangkaian kepercayaan mendalam, sejenis rangkaian saraf yang digunakan untuk pengecaman suara dan gambar, juga menggunakan RBM. Kotak Alat Rangkaian Deep Belief, TensorFlow, dan Theano ialah beberapa contoh perisian atau teknologi tertentu yang menggunakan RBM.
Wrap Up
Model Pembelajaran Dalam menjadi semakin penting dalam pelbagai industri, termasuk pengecaman pertuturan, pemprosesan bahasa semula jadi dan penglihatan komputer.
Rangkaian Neural Konvolusi (CNN) dan Rangkaian Neural Berulang (RNN) telah menunjukkan yang paling menjanjikan dan digunakan secara meluas dalam banyak aplikasi, namun, semua model Pembelajaran Dalam mempunyai kelebihan dan kekurangannya.
Walau bagaimanapun, penyelidik masih meneliti Mesin Boltzmann Terhad (RBM) dan jenis model Pembelajaran Dalam yang lain kerana ia juga mempunyai kelebihan istimewa.
Model baharu dan kreatif dijangka akan dicipta memandangkan bidang pembelajaran mendalam terus maju untuk menangani masalah yang lebih sukar





Sila tinggalkan balasan anda