अनुक्रमणिका[लपवा][दाखवा]
- 1. पायथन स्क्रिप्टिंग म्हणजे काय आणि ते पायथन प्रोग्रामिंगपेक्षा वेगळे कसे आहे?
- 2. पायथनचे कचरा संकलन कसे कार्य करते?
- 3. सूची आणि ट्यूपलमधील फरक स्पष्ट करा
- 4. यादीचे आकलन काय आहे आणि त्यांच्या वापराचे उदाहरण द्या?
- 5. डीपकॉपी आणि कॉपीमधील फरक सांगा?
- 6. पायथनमध्ये मल्टीथ्रेडिंग कसे साध्य केले जाते आणि ते मल्टीप्रोसेसिंगपेक्षा वेगळे कसे आहे?
- 7. डेकोरेटर म्हणजे काय आणि ते पायथनमध्ये कसे वापरले जातात?
- 8. *args आणि **kwargs मधील फरक स्पष्ट करा?
- 9. डेकोरेटर वापरून फंक्शन एकदाच कॉल केले जाऊ शकते याची तुम्ही खात्री कशी कराल?
- 10. पायथनमध्ये वारसा कसा कार्य करतो?
- 11. मेथड ओव्हरलोडिंग आणि ओव्हरराइडिंग म्हणजे काय?
- 12. उदाहरणासह बहुरूपी संकल्पनेचे वर्णन करा.
- 13. उदाहरण, वर्ग आणि स्थिर पद्धतींमधील फरक स्पष्ट करा.
- 14. पायथन संच अंतर्गत कसे कार्य करते याचे वर्णन करा.
- 15. पायथनमध्ये शब्दकोश कसा लागू केला जातो?
- 16. नामांकित ट्युपल्स वापरण्याचे फायदे स्पष्ट करा.
- 17. प्रयत्न-वगळता ब्लॉक कसे कार्य करते?
- 18. raise आणि assert स्टेटमेंटमध्ये काय फरक आहे?
- 19. तुम्ही पायथनमधील बायनरी फाईलमधून डेटा कसा वाचता आणि लिहिता?
- 20. I/O फाईलसह कार्य करताना विधानासह आणि त्याचे फायदे स्पष्ट करा.
- २१. तुम्ही पायथनमध्ये सिंगलटन मॉड्यूल कसे तयार कराल?
- 22. Python स्क्रिप्टमध्ये मेमरी वापर ऑप्टिमाइझ करण्याचे काही मार्ग सांगा.
- 23. तुम्ही regex वापरून दिलेल्या स्ट्रिंगमधून सर्व ईमेल पत्ते कसे काढाल?
- 24. फॅक्टरी डिझाईन पॅटर्न आणि पायथनमधील त्याचा वापर स्पष्ट करा
- 25. इटरेटर आणि जनरेटरमध्ये काय फरक आहे?
- 26. @property डेकोरेटर कसे काम करते?
- 27. तुम्ही पायथनमध्ये मूलभूत REST API कसे तयार कराल?
- 28. HTTP POST विनंती करण्यासाठी विनंती लायब्ररी कशी वापरायची याचे वर्णन करा.
- 29. Python वापरून तुम्ही PostgreSQL डेटाबेसशी कसे कनेक्ट कराल?
- 30. Python मध्ये ORM ची भूमिका काय आहे आणि एक लोकप्रिय नाव काय आहे?
- 31. तुम्ही पायथन स्क्रिप्टची प्रोफाइल कशी कराल?
- 32. CPython मधील GIL (ग्लोबल इंटरप्रीटर लॉक) स्पष्ट करा
- 33. Python चे async/await स्पष्ट करा. हे पारंपारिक थ्रेडिंगपेक्षा वेगळे कसे आहे?
- 34. तुम्ही Python चे concurrent.futures कसे वापराल याचे वर्णन करा.
- 35. जॅंगो आणि फ्लास्कची वापर केस आणि स्केलेबिलिटीच्या बाबतीत तुलना करा.
- निष्कर्ष
आपल्या जीवनाच्या प्रत्येक पैलूमध्ये तंत्रज्ञान अस्तित्वात असताना, python ला स्क्रिप्टिंग हे प्रचंड आणि गुंतागुंतीच्या IT पायाभूत सुविधांचा एक प्रमुख घटक म्हणून उदयास आले आहे, जे वापरण्यास सुलभतेचे आणि उपयुक्ततेचे उदाहरण देते.
पायथनची ताकद केवळ त्याच्या सिंटॅक्टिकल साधेपणा आणि वाचनीयतेमध्येच नाही तर त्याच्या अनुकूलतेमध्ये देखील आहे, ज्यामुळे ते कमी-जोखीम, नवशिक्या-स्तरीय स्क्रिप्टिंग आणि उच्च-स्टेक्स, एंटरप्राइझ-स्तरीय सॉफ्टवेअर डेव्हलपमेंटमधील अंतर सहजतेने भरून काढू देते.
Python च्या विस्तृत लायब्ररी आणि फ्रेमवर्क एक प्रवाही, कल्पनारम्य तांत्रिक साहसासाठी मार्ग मोकळा करतात, मग ते डेटा विश्लेषण, वेब विकास, कृत्रिम बुद्धिमत्ता किंवा नेटवर्क सर्व्हरच्या क्षेत्रातील असो.
समस्या सोडवण्याचे साधन असण्यासोबतच, Python एक असे वातावरण देखील वाढवते जिथे नावीन्य केवळ स्वीकारले जात नाही तर त्याच्या प्रचंड लायब्ररी आणि फ्रेमवर्क्स, जसे की वेब डेव्हलपमेंटसाठी Django किंवा डेटा विश्लेषणासाठी Pandas यांच्यामुळे नैसर्गिकरित्या अंतर्भूत केले जाते.
डेटा किंग असलेल्या जगात, पायथन हाताळणी, विश्लेषण आणि डेटा दृश्यमान करणे, परिणामी कृती करण्यायोग्य अंतर्दृष्टी आणि मार्गदर्शक धोरणात्मक निवडी.
पायथन ही केवळ प्रोग्रामिंग भाषा नाही; हा एक भरभराट करणारा समुदाय देखील आहे, एक केंद्र जिथे विकासक, डेटा वैज्ञानिक आणि तंत्रज्ञान उत्साही आयटी उद्योगाचा शोध, निर्मिती आणि पुढील स्तरावर नेण्यासाठी एकत्र येतात.
नवोन्मेष, प्रक्रिया सुधारणा आणि सुधारित ग्राहक सेवेसाठी उत्प्रेरक म्हणून, नवीन स्टार्टअप्सपासून ते सुस्थापित संस्थांपर्यंत सर्व आकारांच्या व्यवसायांद्वारे पायथन विकासकांचा शोध घेतला जातो.
याव्यतिरिक्त, हे मुक्त-स्रोत निसर्ग सामायिक शिक्षण आणि सहयोगी वाढीची संस्कृती वाढवते, याची हमी देते की ते वेगाने बदलत असलेल्या तंत्रज्ञानाच्या जगाशी पुढे जात राहील.
2023 मध्ये पायथन शिकणे ही एका भाषेत केलेली गुंतवणूक आहे जी चालू, लवचिक आणि तंत्रज्ञानाच्या प्रवाहाचे व्यवस्थापन करण्यासाठी आवश्यक राहण्याचे वचन देते.
च्या फील्डमध्ये प्रवेश देते मशीन शिक्षण, डेटा विश्लेषण, सायबरसुरक्षा आणि बरेच काही, जे सर्व डिजिटल युगाला आकार देण्यासाठी महत्त्वपूर्ण आहेत.
म्हणून, आम्ही तुमच्यासाठी सर्वोत्कृष्ट पायथन स्क्रिप्टिंग मुलाखतीच्या प्रश्नांची एक सूची तयार केली आहे, जी तुम्हाला विकासक म्हणून चमकण्यास आणि मुलाखतीचा दर्जा प्राप्त करण्यास सक्षम करेल.
1. पायथन स्क्रिप्टिंग म्हणजे काय आणि ते पायथन प्रोग्रामिंगपेक्षा वेगळे कसे आहे?
Python त्याच्या अनुकूलतेसाठी ओळखले जाते आणि स्क्रिप्टिंग आणि प्रोग्रामिंग दोन्ही कौशल्ये प्रदान करते, प्रत्येक विशिष्ट नोकरी आणि उद्दिष्टांसाठी अनुकूल आहे.
पायथन स्क्रिप्टिंग ही मूलभूतपणे लहान, अधिक कार्यक्षम स्क्रिप्ट लिहिण्याची प्रक्रिया आहे ज्याचा उद्देश फायली व्यवस्थापित करणे, पुनरावृत्ती प्रक्रिया स्वयंचलित करणे किंवा त्वरीत प्रोटोटाइप कल्पना आहे.
या स्क्रिप्ट, ज्या वारंवार एकट्या असतात, कार्यक्षमतेने क्रमाने क्रियांची सूची पार पाडतात.
पायथन प्रोग्रामिंग, दुसरीकडे, लायब्ररी, फ्रेमवर्क आणि सर्वोत्तम पद्धती वापरून संरचित कोडसह मोठे, अधिक क्लिष्ट प्रोग्राम तयार करण्यावर जोर देऊन पुढे जाते.
ते दोघे एकाच भाषेतून आलेले असताना, स्क्रिप्टिंग सुलभ करते आणि स्वयंचलित करते जेव्हा प्रोग्रामिंग तयार करते आणि शोध लावते. हा फरक प्रत्येक शाखेच्या व्याप्ती आणि उद्दिष्टांमध्ये दिसून येतो.
2. पायथनचे कचरा संकलन कसे कार्य करते?
प्रभावी मेमरी व्यवस्थापन सुनिश्चित करण्यासाठी मुख्य घटक म्हणजे पायथनची कचरा संकलन प्रणाली.
मेमरी लीक होण्यापासून सिस्टम संसाधनांचे संरक्षण करण्यासाठी ते पार्श्वभूमीत अथकपणे कार्य करते. हा स्वयंचलित दृष्टीकोन मुख्यतः संदर्भ मोजणी पद्धतीवर आधारित आहे, जेथे प्रत्येक ऑब्जेक्ट इतर किती वस्तूंचा संदर्भ घेत आहेत याचा मागोवा ठेवतो.
जेव्हा ही संख्या 0 वर येते तेव्हा हा ऑब्जेक्ट मेमरी रिक्लेमेशनसाठी उमेदवार बनतो, जे सूचित करते की आयटमची यापुढे आवश्यकता नाही.
याव्यतिरिक्त, पायथन एक चक्रीय कचरा संग्राहक वापरतो, जो संदर्भ चक्र शोधण्यासाठी आणि साफ करण्यासाठी साध्या संदर्भ गणना दृष्टिकोनातून चुकू शकतो.
अशा प्रकारे, संदर्भ मोजणी आणि चक्रीय कचरा संकलन दुहेरी-स्तरित रणनीती मेमरीचा काळजीपूर्वक आणि प्रभावी वापर प्रदान करते, पायथनची कार्यक्षमता मजबूत करते, विशेषत: मेमरी-केंद्रित अनुप्रयोगांमध्ये.
पायथनच्या कचरा संकलन प्रणालीशी इंटरफेस कसा करायचा हे दर्शविणारा एक साधा कोड नमुना खाली प्रदान केला आहे:
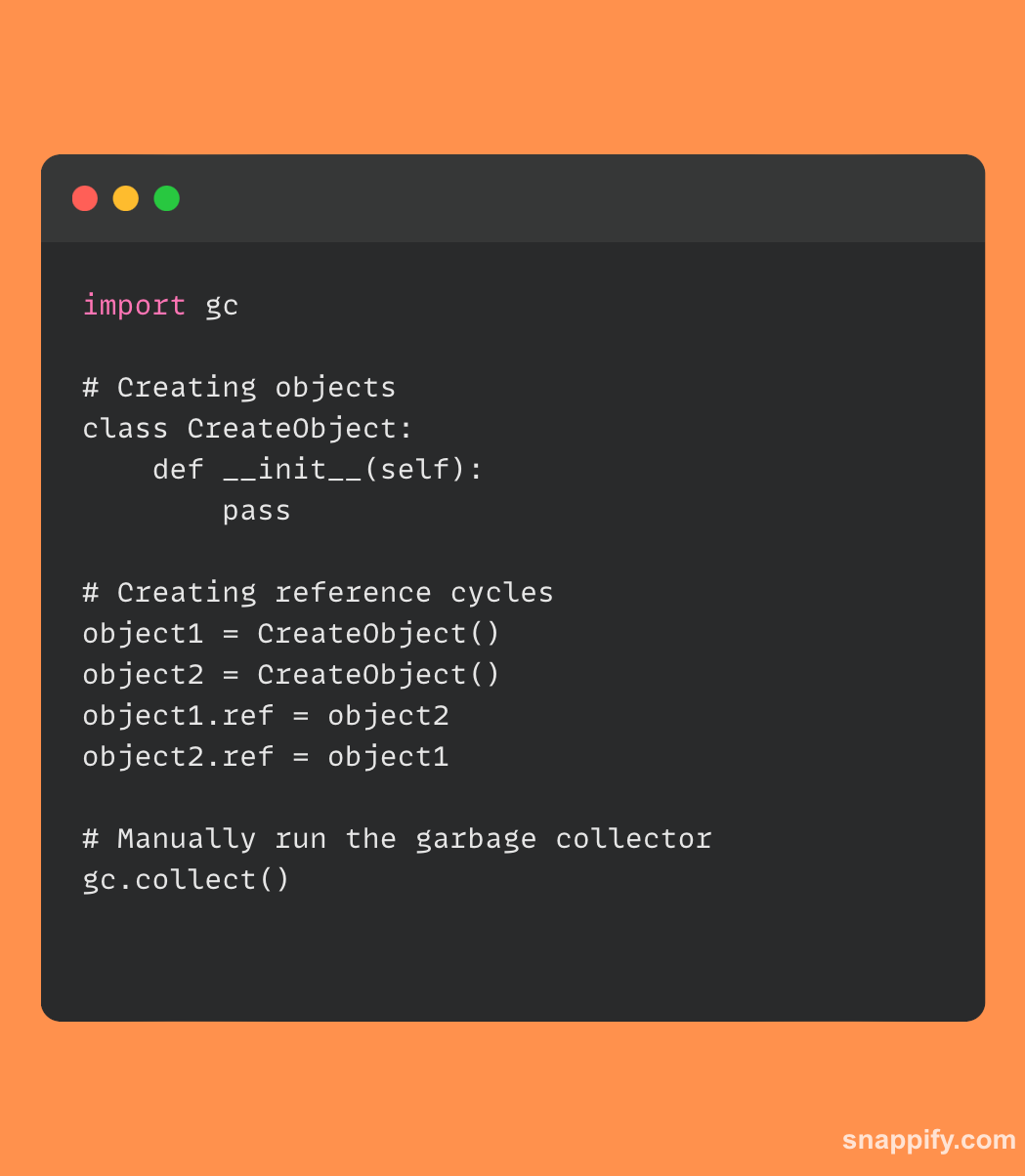
या उतार्यात दोन ऑब्जेक्ट्स व्युत्पन्न केल्या आहेत आणि एक चक्र स्थापित करण्यासाठी क्रॉस-रेफरन्स केले आहेत. नंतर कचरा गोळा करणारा gc.collect() वापरून मॅन्युअली ट्रिगर केला जातो, प्रोग्रामर पायथनच्या मेमरी मॅनेजमेंट मेकॅनिझममध्ये आवश्यकतेनुसार कसे व्यस्त राहू शकतात हे दर्शविते.
3. सूची आणि ट्यूपलमधील फरक स्पष्ट करा
याद्या आणि ट्यूपल्स हे Python जगात डेटासाठी प्रभावी कंटेनर आहेत, परंतु त्यांच्याकडे भिन्न गुणधर्म आहेत जे भिन्न प्रोग्रामिंग उद्देश पूर्ण करतात.
चौरस कंसाने दर्शविलेली यादी, त्यातील घटकांच्या बदलत्या आणि डायनॅमिक आकारमानास अनुमती देऊन लवचिकता सक्षम करते.
दुसरीकडे कंसात बंद केलेले ट्युपल अपरिवर्तनीय असते आणि फंक्शन कार्यान्वित होत असताना त्याची प्रारंभिक स्थिती कायम ठेवते.
ट्यूपल्स एक घन, अपरिवर्तनीय अनुक्रम देतात तर याद्या लवचिकता देतात, ज्यामुळे डेटा प्रोसेसिंग आणि बदलामध्ये विविध उपयोगांची परवानगी मिळते.
येथे थोडे आहे पायथन कोड याद्या आणि ट्यूपल्स दोन्ही कसे वापरायचे हे दर्शविणारा नमुना:

4. यादीचे आकलन काय आहे आणि त्यांच्या वापराचे उदाहरण द्या?
सूची आकलन हा Python मध्ये याद्या तयार करण्याचा एक कार्यक्षम आणि अर्थपूर्ण मार्ग आहे ज्यात कंडिशनल लॉजिकची शक्ती आणि लूप कोडच्या एकल, समजण्यायोग्य लाइनमध्ये एकत्र केले जातात.
ते आमचे हेतू एका सूचीमध्ये रूपांतरित करण्यासाठी एक सरलीकृत वाक्यरचना प्रदान करतात, पुनरावृत्ती आणि सशर्तता एकाच, परिष्कृत संरचनेत एकत्र करतात.
सूचीचे आकलन मूलत: प्रोग्रामरना प्रत्येक सदस्यावर ऑपरेशन्स करून सूची तयार करण्याची क्षमता देते आणि कदाचित नीटनेटका कोडबेस ठेवून काही विशिष्ट निकषांवर अवलंबून ते फिल्टर करतात.
हे अभिव्यक्त वैशिष्ट्य वाचनीयता सुधारून पायथन प्रोग्रामिंगमधील स्पष्टतेसह कार्यक्षमतेची जोड देते आणि काही परिस्थितींमध्ये संगणकीय लाभ देखील प्रदान करते.
पायथन सूची आकलनाचे उदाहरण खाली दर्शविले आहे:
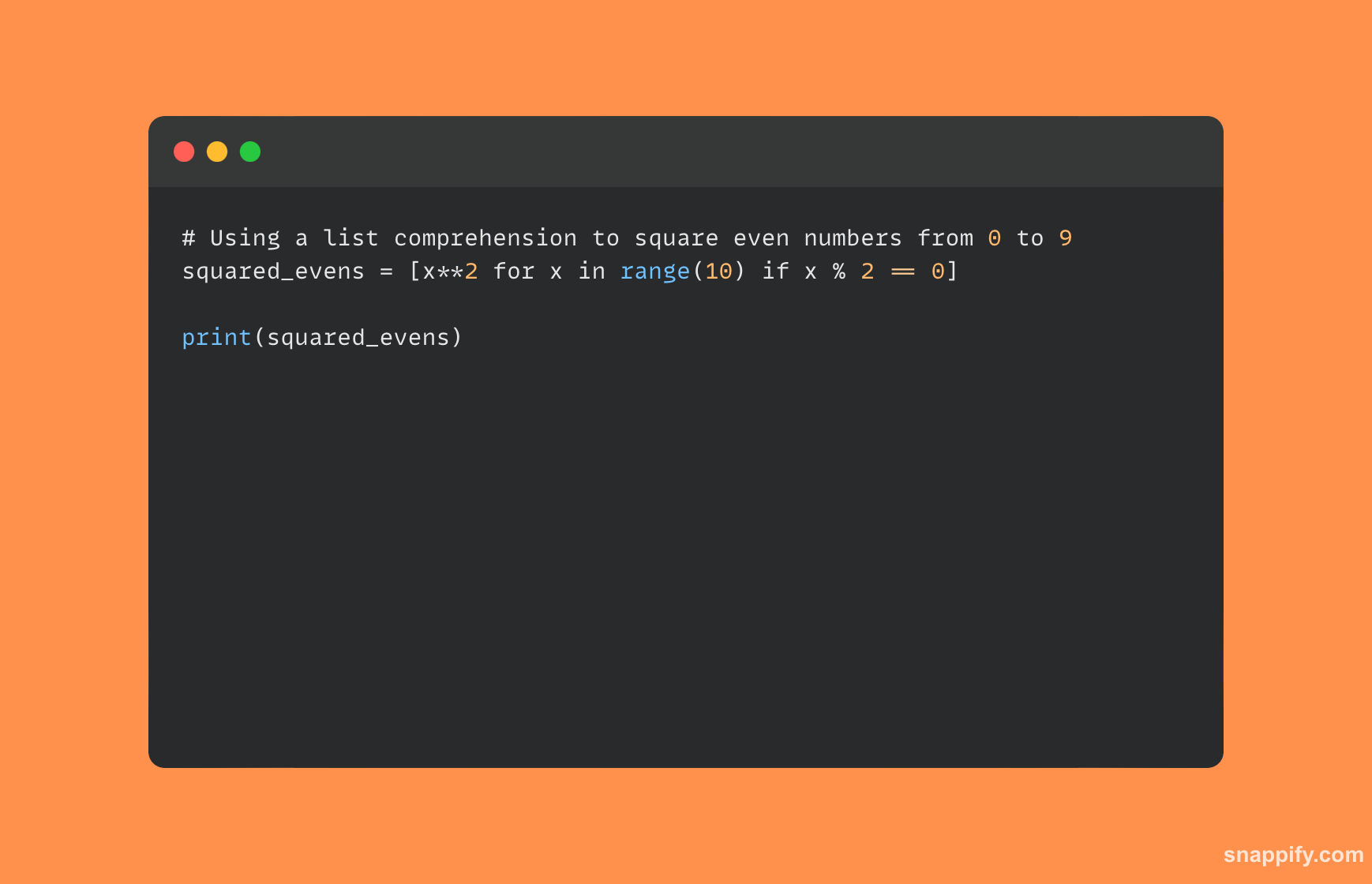
5. डीपकॉपी आणि कॉपीमधील फरक सांगा?
डुप्लिकेट केलेल्या वस्तूंची खोली आणि अखंडता यामधील फरक निर्धारित करते deepcopy आणि copy Python मध्ये.
मूळ नेस्टेड ऑब्जेक्ट्सचे संदर्भ ठेवून नवीन आयटम तयार करून, अ copy एक उथळ प्रतिकृती तयार करते जी त्यांचे भाग्य एकमेकांवर अवलंबून असलेल्या जाळ्यात एकत्र विणते.
Deepcopy मूळ ऑब्जेक्ट आणि त्याच्या सर्व श्रेणीबद्ध घटकांची पुनरावृत्ती करून, सर्व कनेक्शन कापून आणि बदलांमध्ये स्वायत्तता राखून पूर्णपणे स्वायत्त क्लोन तयार करते.
म्हणून, ऑब्जेक्ट स्वतंत्रतेच्या आवश्यक स्तरावर अवलंबून, deepcopy सर्वसमावेशक पुनरुत्पादनाची खात्री देते तर कॉपी फक्त पृष्ठभाग-स्तरीय डुप्लिकेशन देते.
कसे ते दाखवण्यासाठी येथे काही कोड आहे copy आणि deepcopy एकमेकांपासून भिन्न:
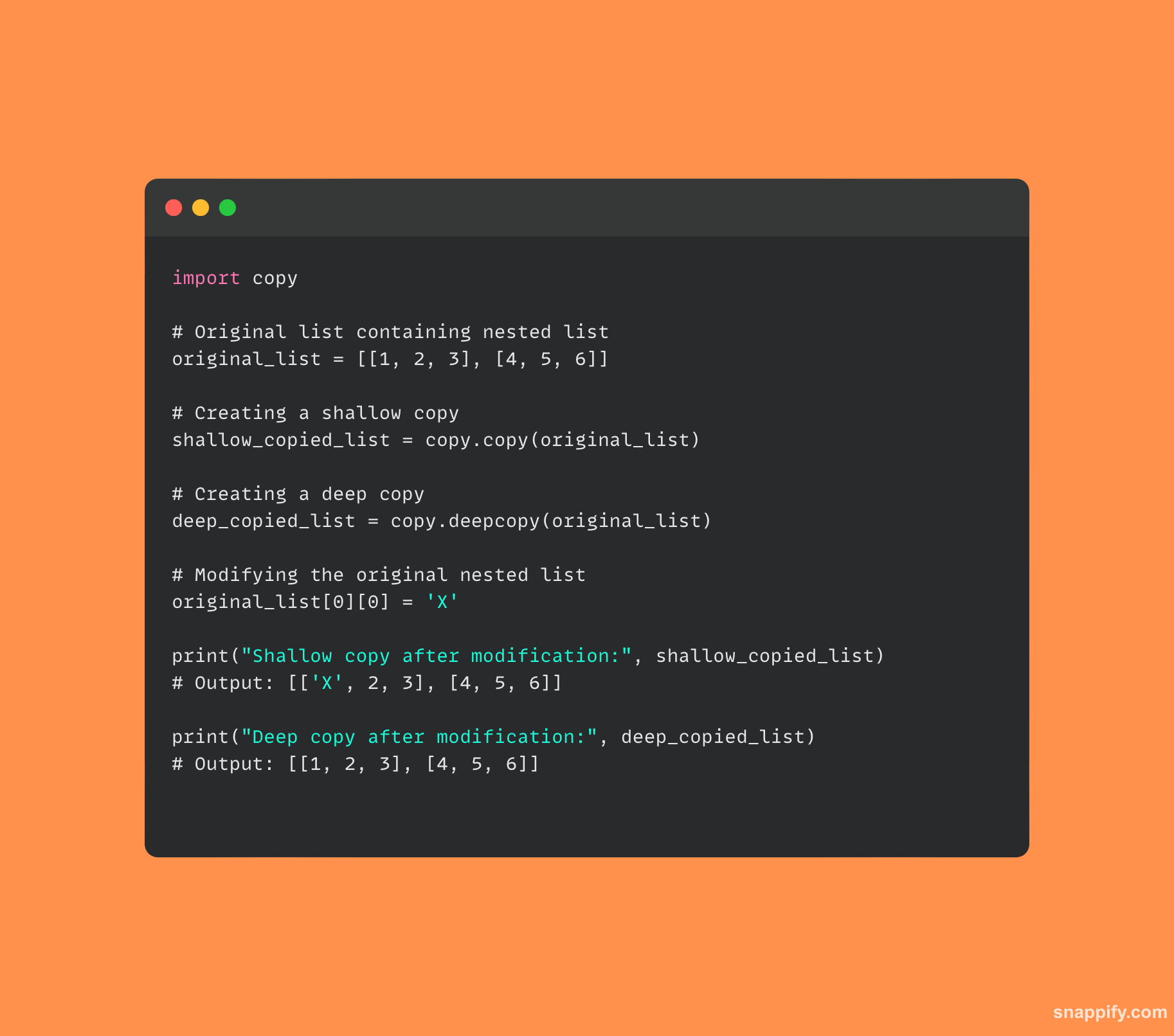
6. पायथनमध्ये मल्टीथ्रेडिंग कसे साध्य केले जाते आणि ते मल्टीप्रोसेसिंगपेक्षा वेगळे कसे आहे?
पायथनचे मल्टिप्रोसेसिंग आणि मल्टीथ्रेडिंग दोन्ही संबोधित समवर्ती अंमलबजावणी, परंतु भिन्न प्रतिमान वापरून.
एकाच प्रक्रियेत अनेक थ्रेड्स वापरून, मल्टीथ्रेडिंग सामायिक मेमरी स्पेसमध्ये समवर्ती कार्य अंमलबजावणी सक्षम करते.
तथापि, Python's Global Interpreter Lock (GIL) मुळे वास्तविक समांतर थ्रेड एक्झिक्युशन प्राप्त करणे कठीण होऊ शकते.
दुसरीकडे, मल्टीप्रोसेसिंग अनेक प्रक्रियांचा वापर करते, प्रत्येक स्वतंत्र पायथन इंटरप्रिटर आणि मेमरी स्पेससह, खरी समांतरता सुनिश्चित करते.
I/O-बाउंड क्रियाकलापांसाठी, मल्टीथ्रेडिंग अधिक हलके आणि व्यावहारिक आहे, परंतु CPU-बाउंड परिस्थितींमध्ये मल्टीप्रोसेसिंग उत्कृष्ट आहे जेथे वास्तविक समांतर अंमलबजावणी महत्त्वपूर्ण आहे.
येथे एक संक्षिप्त कोड नमुना आहे जो मल्टीप्रोसेसिंग विरुद्ध मल्टीथ्रेडिंगचा विरोधाभास करतो:
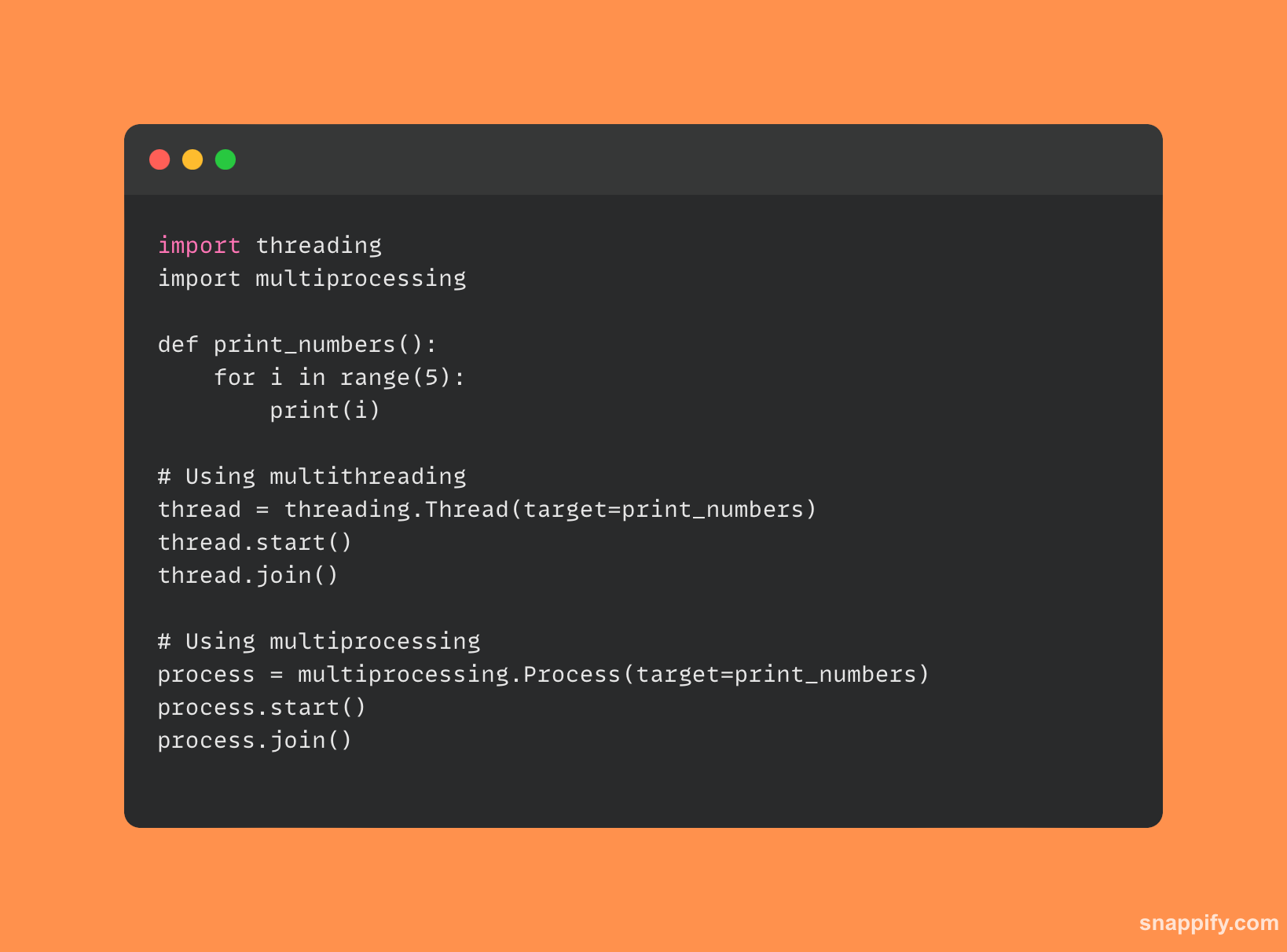
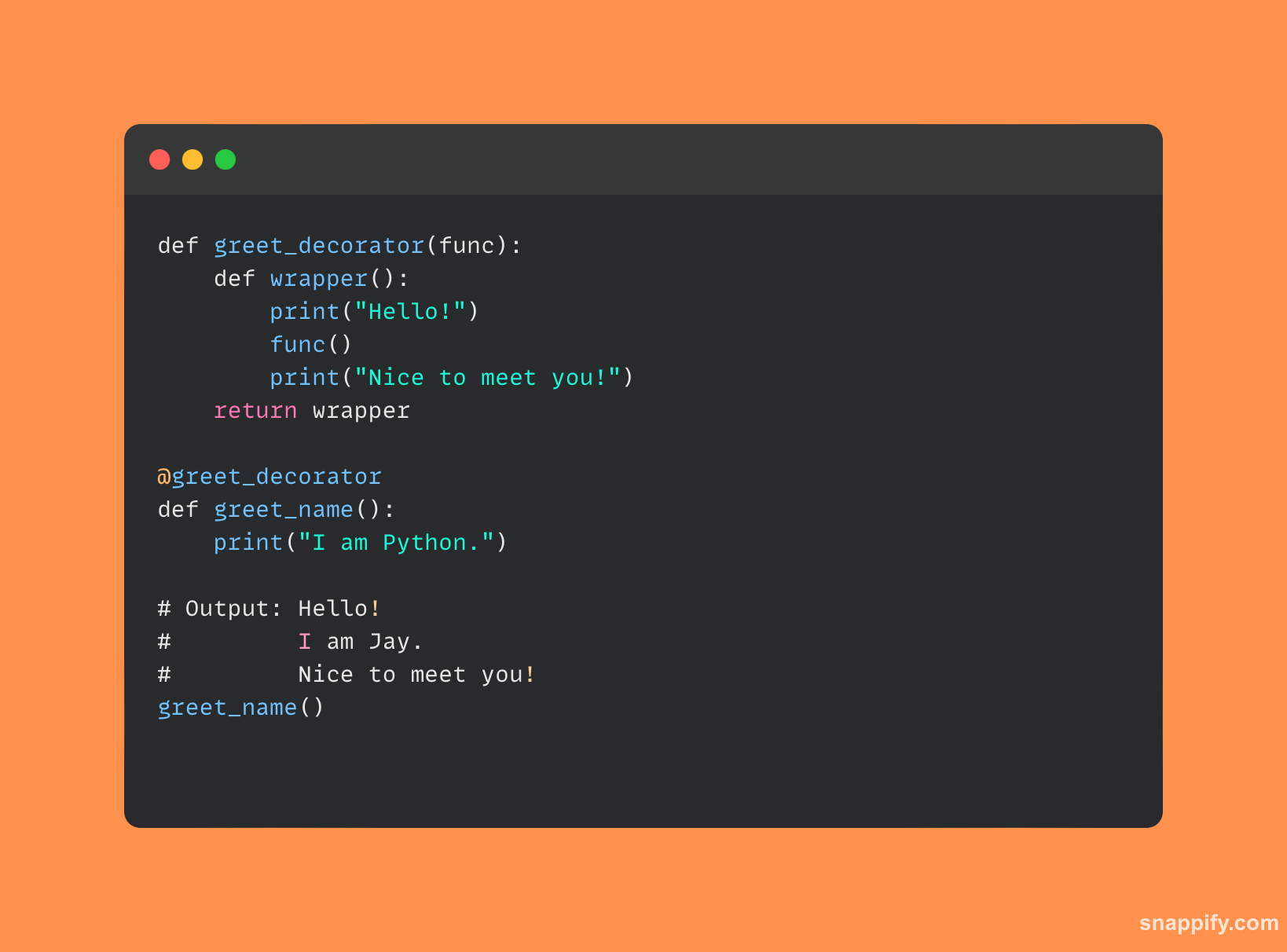
7. डेकोरेटर म्हणजे काय आणि ते पायथनमध्ये कसे वापरले जातात?
पायथनमध्ये, सजावट करणारे सुरेखपणे कार्ये वाढवताना किंवा बदलताना उपयुक्तता आणि साधेपणा एकत्र करतात.
डेकोरेटर्सचा एक बुरखा म्हणून विचार करा जो फंक्शनला सुंदरपणे व्यापतो, त्याचे आवश्यक स्वरूप न बदलता त्याच्या क्षमतांमध्ये भर घालतो.
या संस्था, चिन्हाद्वारे दर्शविल्या जातात @, इनपुट म्हणून फंक्शन स्वीकारा आणि संपूर्ण नवीन फंक्शन आउटपुट करा, फंक्शन वर्तन सुधारण्याचे अखंड साधन ऑफर करा.
डेकोरेटर्स लॉगिंगपासून ऍक्सेस कंट्रोलपर्यंत, स्पष्ट, समजण्यायोग्य वाक्यरचना राखून कोड नवीन स्तरांसह वाढवण्यापर्यंत विस्तृत वैशिष्ट्ये प्रदान करतात.
डेकोरेटर कसे वापरले जातात हे दर्शविणारे एक साधे पायथन कोड उदाहरण येथे आहे:
8. *args आणि **kwargs मधील फरक स्पष्ट करा?
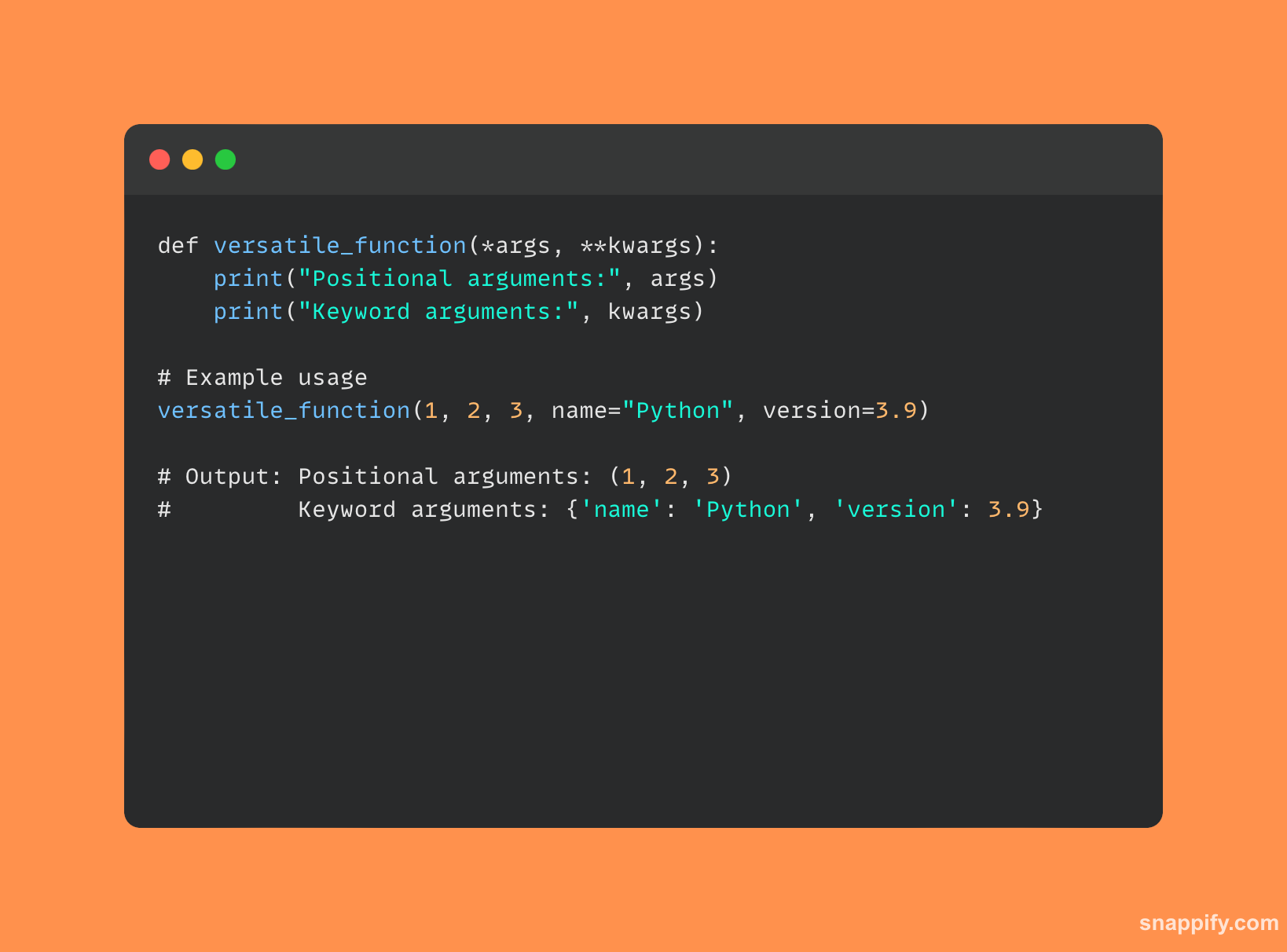
पायथनचे लवचिक पॅरामीटर्स *args आणि **kwargs फंक्शन्सना वितर्कांची श्रेणी योग्यरित्या घेण्यास अनुमती देते.
फंक्शन वापरून कितीही पोझिशनल आर्ग्युमेंट स्वीकारू शकते *args पॅरामीटर, जे त्यांना टपलमध्ये गटबद्ध करते.
याउलट, फंक्शन वापरून कितीही कीवर्ड वितर्क स्वीकारू शकते **kwargs पॅरामीटर, जे त्यांना शब्दकोशात गटबद्ध करते.
दोन्ही फंक्शन कन्स्ट्रक्शन आणि कॉलिंगमध्ये गतिशीलता आणि लवचिकता यासाठी चॅनेल म्हणून कार्य करतात, **kwargs कीवर्ड इनपुट्सची अनियंत्रित रक्कम हाताळण्यासाठी एक संरचित पद्धत ऑफर करत आहे *args अपरिभाषित पोझिशनल इनपुट्स सुंदरपणे हाताळते.
एकत्रितपणे, ते विस्तृत अनुप्रयोग परिस्थिती कुशलतेने आणि स्पष्टपणे हाताळून पायथन फंक्शन्सची लवचिकता आणि टिकाऊपणा सुधारतात.
पायथन कोडचे उदाहरण जे वापरते *args आणि **kwargs खाली दिले आहे:
9. डेकोरेटर वापरून फंक्शन एकदाच कॉल केले जाऊ शकते याची तुम्ही खात्री कशी कराल?
पायथन डेकोरेटर्स उपयुक्तता आणि अभिजातता एकत्र करण्यात पटाईत आहेत, जे कार्याच्या अंमलबजावणीमध्ये एकलता सुनिश्चित करण्यासाठी आवश्यक आहे.
फंक्शन संलग्न करण्यासाठी डेकोरेटर डिझाइन करणे शक्य आहे आणि अंतर्गत स्थिती ठेवून या माहितीचा मागोवा ठेवणे शक्य आहे.
एन्कॅप्स्युलेटेड फंक्शन एकदा कॉल केले जाते, आणि अंमलात आणले जाते आणि डेकोरेटर कॉल रेकॉर्ड करतो. त्यानंतरचे कॉल अवरोधित केले जातात, फंक्शनला त्रास होणार नाही याची खात्री करून वारंवार अंमलबजावणीपासून संरक्षण करते.
डेकोरेटर्सच्या या ऍप्लिकेशनच्या मदतीने, फंक्शन कॉल्स सूक्ष्म परंतु प्रभावी पद्धतीने नियंत्रित केले जाऊ शकतात, सुंदर आणि बिनधास्त अशा दोन्ही प्रकारे विशिष्टतेची हमी देतात.
फंक्शन किती वेळा कॉल केले जाऊ शकते ते मर्यादित करण्यासाठी डेकोरेटर कसे वापरले जाऊ शकतात हे दर्शविण्यासाठी येथे एक कोड नमुना आहे:

10. पायथनमध्ये वारसा कसा कार्य करतो?
पायथनची वारसा प्रणाली वर्गांमधील श्रेणीबद्ध दुव्यांचे जाळे तयार करते, ज्यामुळे पालक वर्गातील वैशिष्ट्ये आणि कार्ये त्याच्या संततीसह सामायिक केली जाऊ शकतात.
हे एक वंश व्यवस्थापित करते जे व्युत्पन्न (बाल) वर्गांना त्यांच्या मूळ (पालक) वर्गांमधून वारसा, पुनर्स्थित किंवा कार्यक्षमता जोडण्याची परवानगी देते, कोड पुनर्वापर आणि तार्किक, श्रेणीबद्ध डिझाइनला प्रोत्साहन देते.
बाल वर्ग त्याच्या पालकांच्या क्षमता आत्मसात करण्याव्यतिरिक्त, एक मजबूत, बहु-स्तरीय ऑब्जेक्ट मॉडेल तयार करण्याव्यतिरिक्त त्याच्या अद्वितीय वैशिष्ट्यांचा आणि वर्तनाचा परिचय देऊ शकतो.
या दृष्टिकोनामध्ये, वारसा कुशलतेने संपूर्ण वर्ग पदानुक्रमाच्या धमन्यांमध्ये कार्यक्षमतेचे वितरण करते, एक एकीकृत, सुव्यवस्थित ऑब्जेक्ट-ओरिएंटेड आर्किटेक्चर तयार करते.
खालील सरलीकृत पायथन कोड वारसा दर्शवतो:

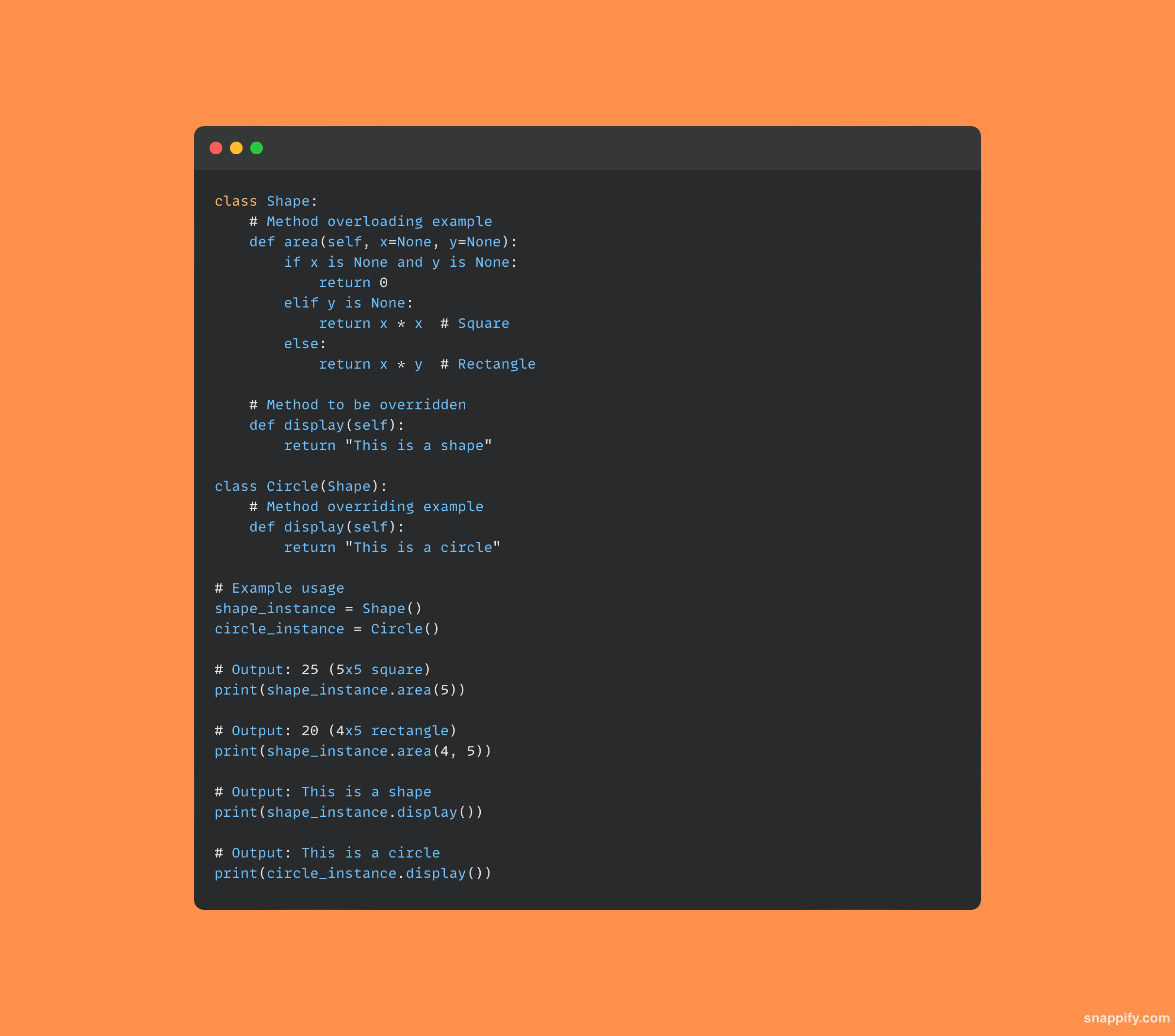
11. मेथड ओव्हरलोडिंग आणि ओव्हरराइडिंग म्हणजे काय?
चे दोन कोनशिले ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग, मेथड ओव्हरलोडिंग आणि मेथड ओव्हरराइडिंग, डेव्हलपरला अनेक उद्देशांसाठी समान पद्धतीचे नाव वापरण्यास सक्षम करते.
पद्धत ओव्हरलोडिंगमुळे अनेक स्वाक्षरी करून एकाच पद्धतीमध्ये विविध डेटा प्रकार आणि युक्तिवाद संख्या सामावून घेता येते.
दुसरीकडे, मेथड ओव्हरराइडिंग उपवर्गाला त्याच्या पालक वर्गामध्ये आधीच परिभाषित केलेल्या पद्धतीमध्ये स्वतःची विशेष अंमलबजावणी जोडण्याची परवानगी देते, मुलाची आवृत्ती कॉल केली जाईल याची हमी देते.
एकत्रितपणे, या धोरणे संदर्भ आणि अनुप्रयोगाच्या विशिष्ट आवश्यकतांवर अवलंबून असलेल्या पद्धती वर्तन सक्षम करून अनुकूलता सुधारतात.
येथे कोडचा एक नमुना आहे जो दोन्ही संकल्पनांचे उदाहरण देतो:
12. उदाहरणासह बहुरूपी संकल्पनेचे वर्णन करा.
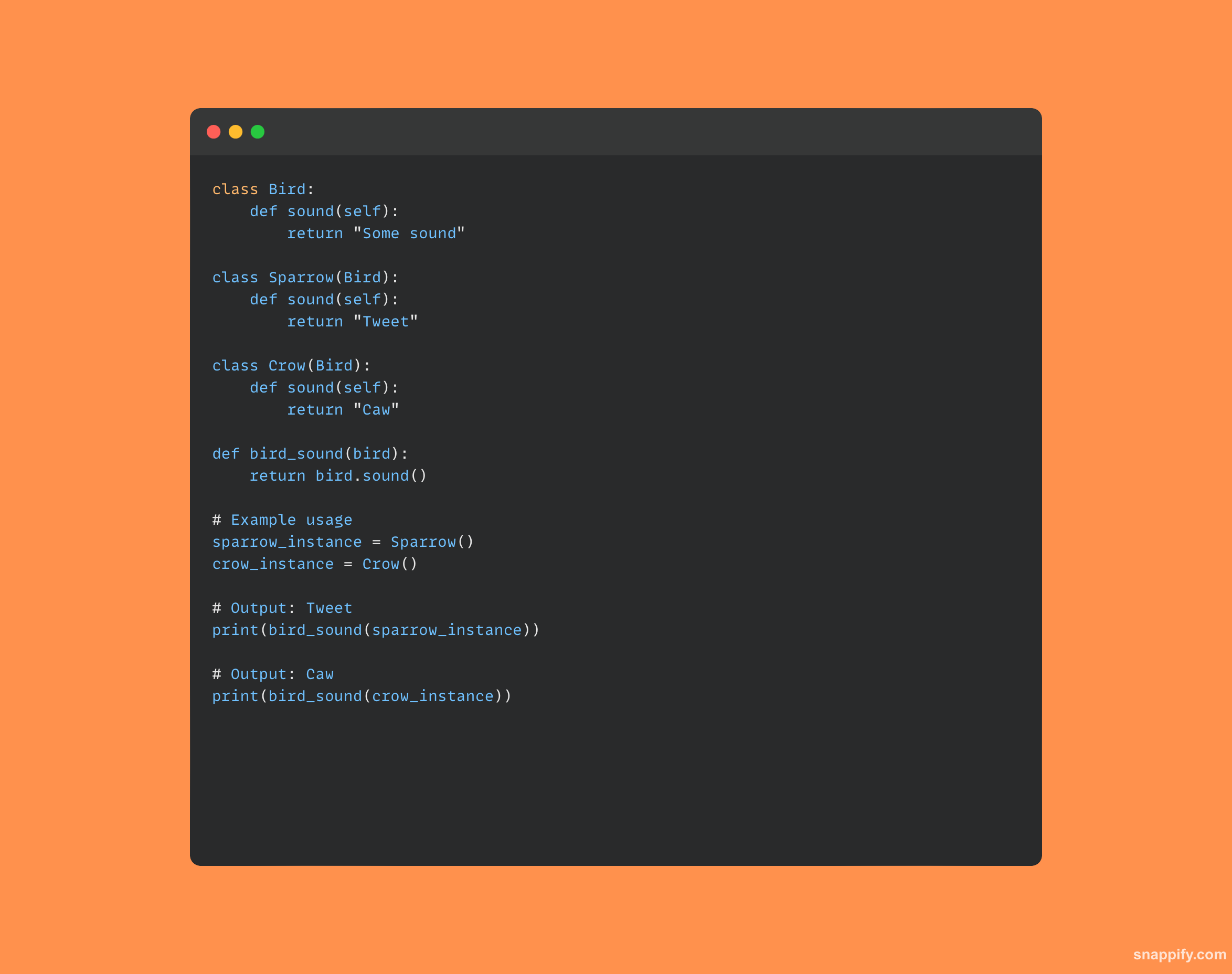
पॉलिमॉर्फिझम म्हणजे विविध डेटा प्रकारांसाठी एकच इंटरफेस वापरण्याची प्रथा.
ही कल्पना पद्धतींना त्यांच्या अंतर्गत प्रकार किंवा वर्गावर अवलंबून अनेक मार्गांनी वस्तूंवर प्रक्रिया करण्याचे स्वातंत्र्य देऊन डिझाइनमध्ये अनुकूलता आणि स्केलेबिलिटी सुनिश्चित करते.
थोडक्यात, पोलिमॉर्फिझम विविध वर्गांच्या वस्तूंना वारशाद्वारे समान वर्गाची उदाहरणे म्हणून विचारात घेण्यास अनुमती देऊन भिन्न वर्तन ठेवताना एकत्रित परस्परसंवाद सक्षम करते.
हे डायनॅमिक वैशिष्ट्य एकल फंक्शन किंवा ऑपरेटरला कोणत्याही समस्यांशिवाय विविध प्रकारच्या ऑब्जेक्टशी संवाद साधण्याची परवानगी देऊन कोड साधेपणाला प्रोत्साहन देते.
येथे एक स्पष्ट कोड नमुना आहे जो बहुरूपता दर्शवतो:
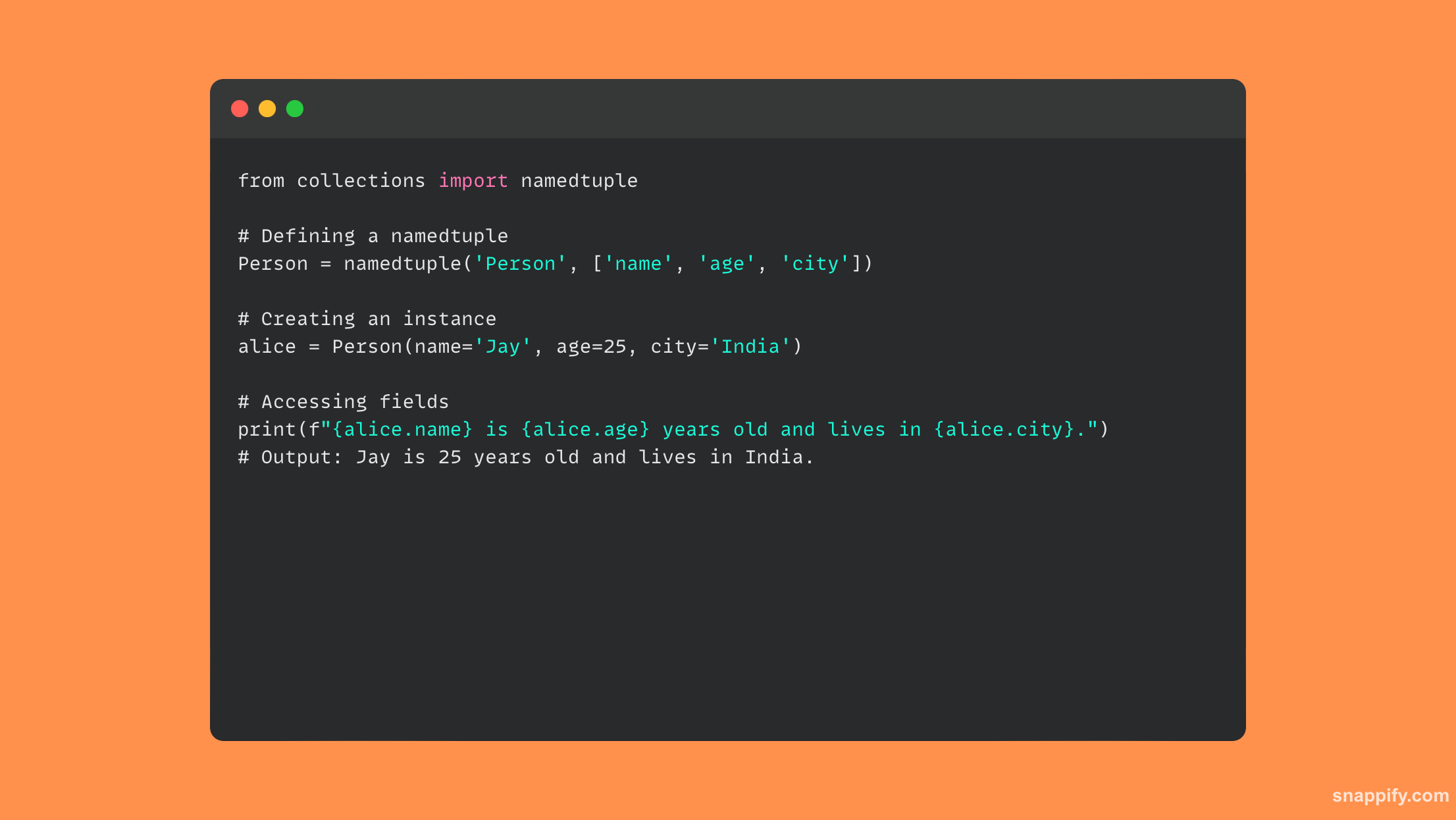
13. उदाहरण, वर्ग आणि स्थिर पद्धतींमधील फरक स्पष्ट करा.
उदाहरण, वर्ग आणि स्थिर पद्धती या सर्वांचे पायथनमधील ऑब्जेक्ट आणि क्लास डेटाशी संवाद साधण्याचे त्यांचे स्वतःचे वेगळे मार्ग आहेत.
सर्वात प्रचलित प्रकार, उदाहरण पद्धती, वर्ग उदाहरण डेटावर कार्य करतात आणि वर्गाचे एक उदाहरण इनपुट म्हणून घेतात, सामान्यत: सेल्फ म्हणतात.
वर्ग स्वतःच (अनेकदा cls म्हणून ओळखला जातो) वर्ग पद्धतींद्वारे एक युक्तिवाद म्हणून स्वीकारला जातो, ज्याला @classmethod ने सूचित केले जाते आणि ते वर्ग-स्तरीय डेटा हाताळतात.
@staticmethod या हॅश चिन्हाने दर्शविल्या जाणार्या स्टॅटिक पद्धती, क्लास किंवा इन्स्टन्स स्टेटस प्रभावित करत नाहीत कारण ते क्लासमधील फ्रीस्टँडिंग फंक्शन्स आहेत आणि सेल्फ किंवा cls ला प्रथम पॅरामीटर म्हणून घेत नाहीत.
कारण प्रत्येक पद्धतीचा प्रकार भिन्न प्रवेश आणि उपयुक्तता प्रदान करतो, ऑब्जेक्ट-ओरिएंटेड आर्किटेक्चर लवचिक आणि अचूक असतात.
कोडमधील या पद्धतींपैकी एकाचे उदाहरण म्हणून:
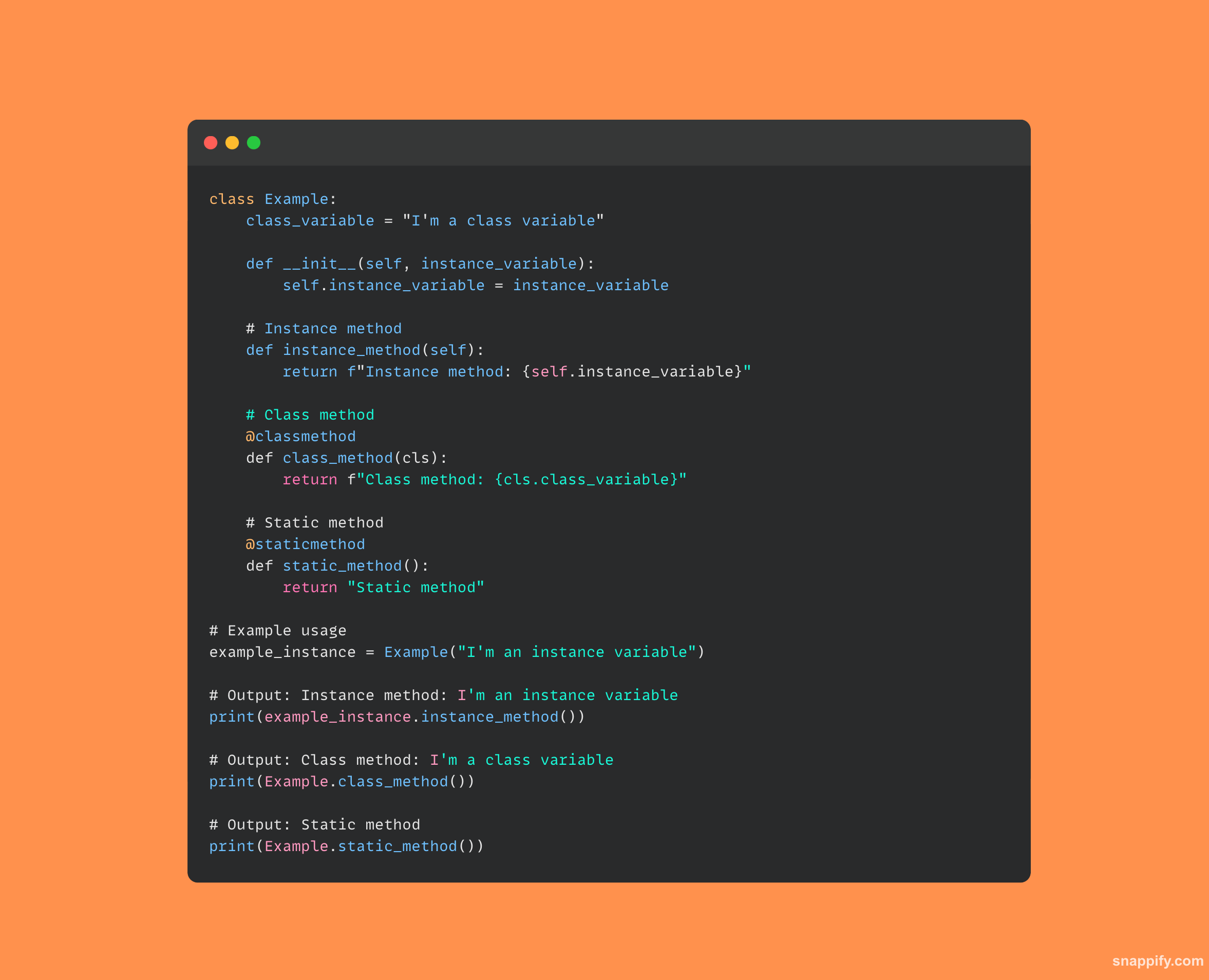
14. पायथन संच अंतर्गत कसे कार्य करते याचे वर्णन करा.
एक अंतर्गत डेटा रचना हॅशटेबल नावाचा पायथन संच वापरला जातो, जो विशिष्ट घटकांचा अक्रमित संग्रह आहे, शक्तिशाली आणि प्रभावी ऑपरेशन्स करण्यासाठी.
जेव्हा एखादा घटक सेटमध्ये जोडला जातो तेव्हा त्वरीत डेटा व्यवस्थापित करण्यासाठी आणि पुनर्प्राप्त करण्यासाठी Python हॅश फंक्शन वापरते, घटकाला हॅश व्हॅल्यूमध्ये बदलते जे नंतर त्याचे स्थान मेमरीमध्ये परिभाषित करते.
त्वरीत सदस्यत्व तपासणे सुलभ करून आणि डुप्लिकेट नोंदी काढून, हे तंत्र सुनिश्चित करते की सेटमधील प्रत्येक घटक अद्वितीय आणि सहज उपलब्ध आहे.
त्यामुळे, संचाची मूळ रचना युनियन, क्रॉसिंग आणि फरक यांसारख्या ऑपरेशन्सला अनुकूल बनवते, परिणामी एक लहान, प्रभावी डेटा संरचना बनते.
येथे कोडचा एक तुकडा आहे जो पायथन सेटशी साधा संवाद कसा साधायचा हे दाखवतो:
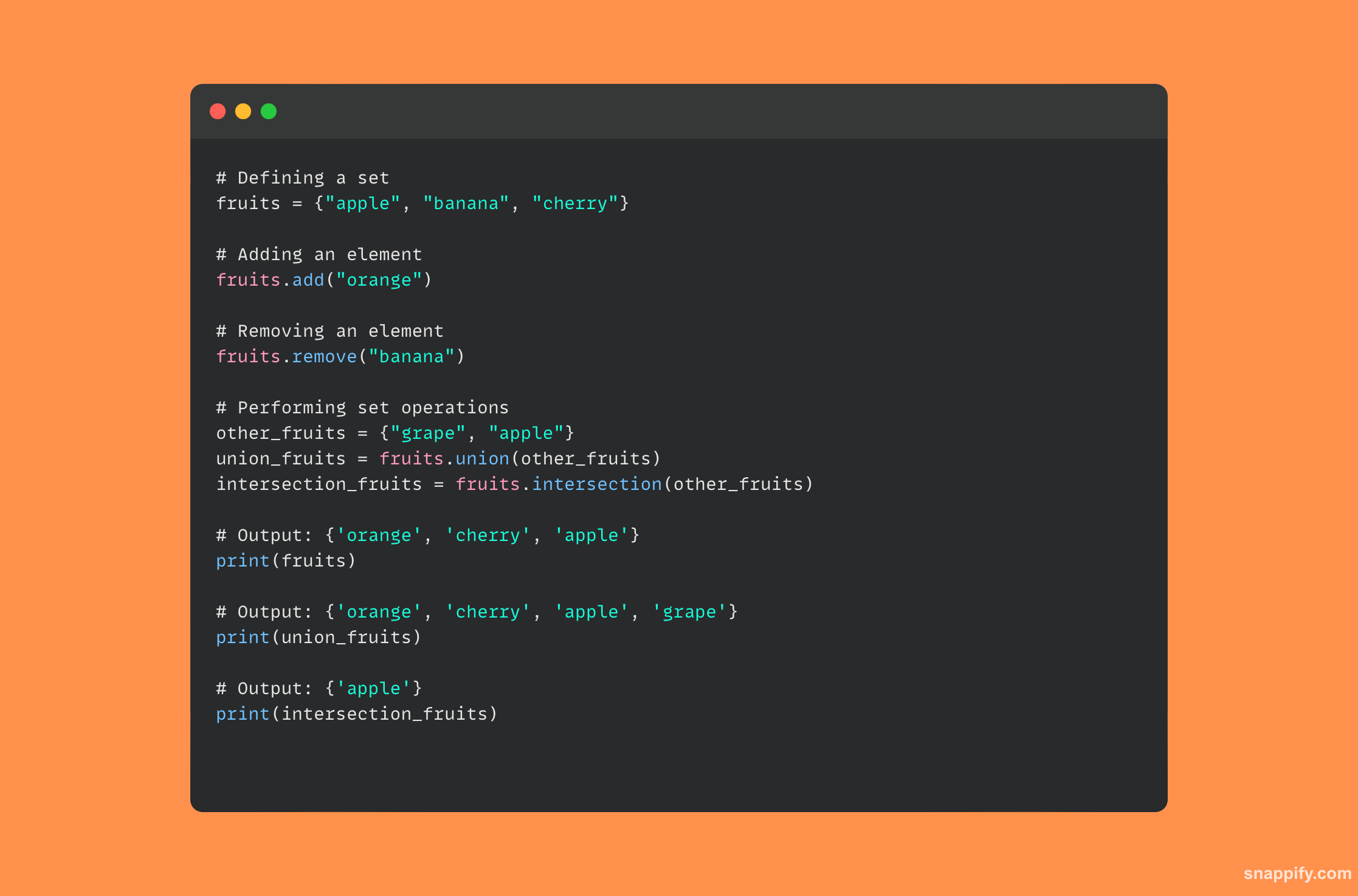
15. पायथनमध्ये शब्दकोश कसा लागू केला जातो?
हॅशटेबल पायथनमधील शब्दकोशाचा पाया म्हणून काम करते आणि द्रुत डेटा पुनर्प्राप्ती आणि हाताळणीसाठी परवानगी देते. शब्दकोश हे की-व्हॅल्यू जोड्यांचे डायनॅमिक, अक्रमित संग्रह आहेत.
जेव्हा की-व्हॅल्यू जोडी जारी केली जाते तेव्हा कीच्या हॅशची गणना करण्यासाठी Python हॅश फंक्शन वापरते, मेमरीमध्ये मूल्याच्या स्टोरेज पत्त्याचे स्थान शोधते.
हॅश फंक्शन इंटरप्रिटरला मेमरी अॅड्रेसवर ताबडतोब पॉइंट करत असल्याने, हे डिझाईन कीजवर आधारित डेटामध्ये द्रुत प्रवेश देते आणि पुनर्प्राप्ती, समाविष्ट करणे आणि हटविण्याच्या ऑपरेशनमध्ये आश्चर्यकारकपणे कार्यक्षम आहे.
Python शब्दकोशांद्वारे प्रदान केलेल्या गती आणि लवचिकतेच्या मोहक संयोजनामुळे Devs डेटा सहज आणि प्रभावीपणे व्यवस्थापित करू शकतात.
पायथन शब्दकोश कसा वापरायचा हे दर्शविणारा एक कोड नमुना खाली सूचीबद्ध आहे:
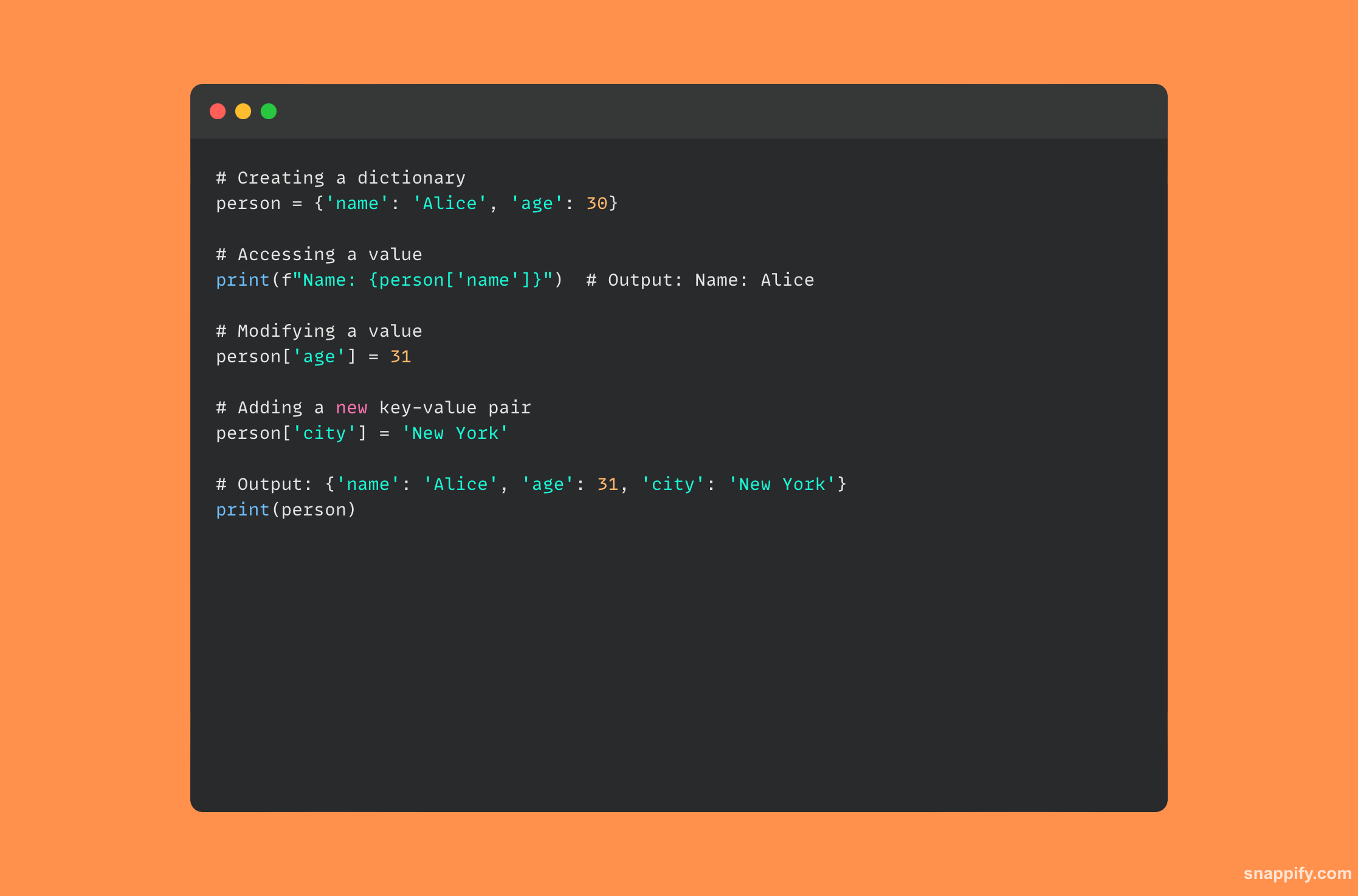
16. नामांकित ट्युपल्स वापरण्याचे फायदे स्पष्ट करा.
Python मधील नामांकित ट्युपल्सचा वापर कुशलतेने वर्गांच्या अभिव्यक्तीला ट्युपल्सच्या साधेपणासह एकत्रित करतो, परिणामी एक लहान, स्वयं-स्पष्टीकरणात्मक डेटा संरचना तयार होते.
पारंपारिक ट्यूपल नामांकित ट्यूपल्सद्वारे वाढविले जाते, जे कोड वाचनीयता आणि स्व-वर्णन सुधारण्यासाठी नामित फील्ड जोडताना ट्युपल्सची अपरिवर्तनीयता आणि मेमरी कार्यक्षमता ठेवते.
नामांकित ट्युपल्स कोणत्याही पद्धतीशिवाय सरळ, हलक्या वजनाच्या वस्तू स्थापित करून, विकसकाचा अनुभव आणि संगणकीय कामगिरी दोन्ही सुधारून स्पष्ट, समजण्यायोग्य आणि कार्यक्षम कोडला प्रोत्साहन देतात.
परिणामी, नामांकित ट्युपल्स एका शक्तिशाली साधनात विकसित होतात जे गतीशी तडजोड न करता डेटा संरचना आणि वाचनीयता सुधारतात.
नामांकित ट्युपल्सचा वापर स्पष्ट करणारा कोड नमुना खाली दर्शविला आहे:
17. प्रयत्न-वगळता ब्लॉक कसे कार्य करते?
प्रयत्न-वगळता ब्लॉक पायथन अभिव्यक्ती वाक्यरचना मध्ये एक संरक्षक म्हणून कार्य करतो, रनटाइम अनियमिततेपासून सावधपणे संरक्षण करतो आणि संभाव्य समस्या असूनही अंमलबजावणीचा सुरळीत प्रवाह राखतो.
जेव्हा ट्राय ब्लॉकमध्ये एरर आढळते, तेव्हा नियंत्रण आपोआप ब्लॉक वगळता योग्य ठिकाणी हस्तांतरित केले जाते, जिथे समस्या अहवाल देऊन, निराकरण करून किंवा कदाचित अपवाद पुन्हा थ्रो करून सोडवली जाते.
हेतूपूर्ण, नियंत्रित मार्गाने अपवाद हाताळून, ही प्रणाली केवळ विघटनकारी क्रॅशपासूनच संरक्षण करत नाही तर सुधारते वापरकर्ता अनुभव आणि डेटा अखंडता.
परिणामी, प्रयत्न-वगळता ब्लॉक प्रोग्रामच्या अंमलबजावणीसह त्रुटी व्यवस्थापन कुशलतेने मिश्रित करतो, अनुप्रयोग मजबूती आणि स्थिरतेची हमी देतो.
येथे कोडचा एक छोटासा नमुना आहे जो प्रयत्न-वगळता ब्लॉक वापरतो:
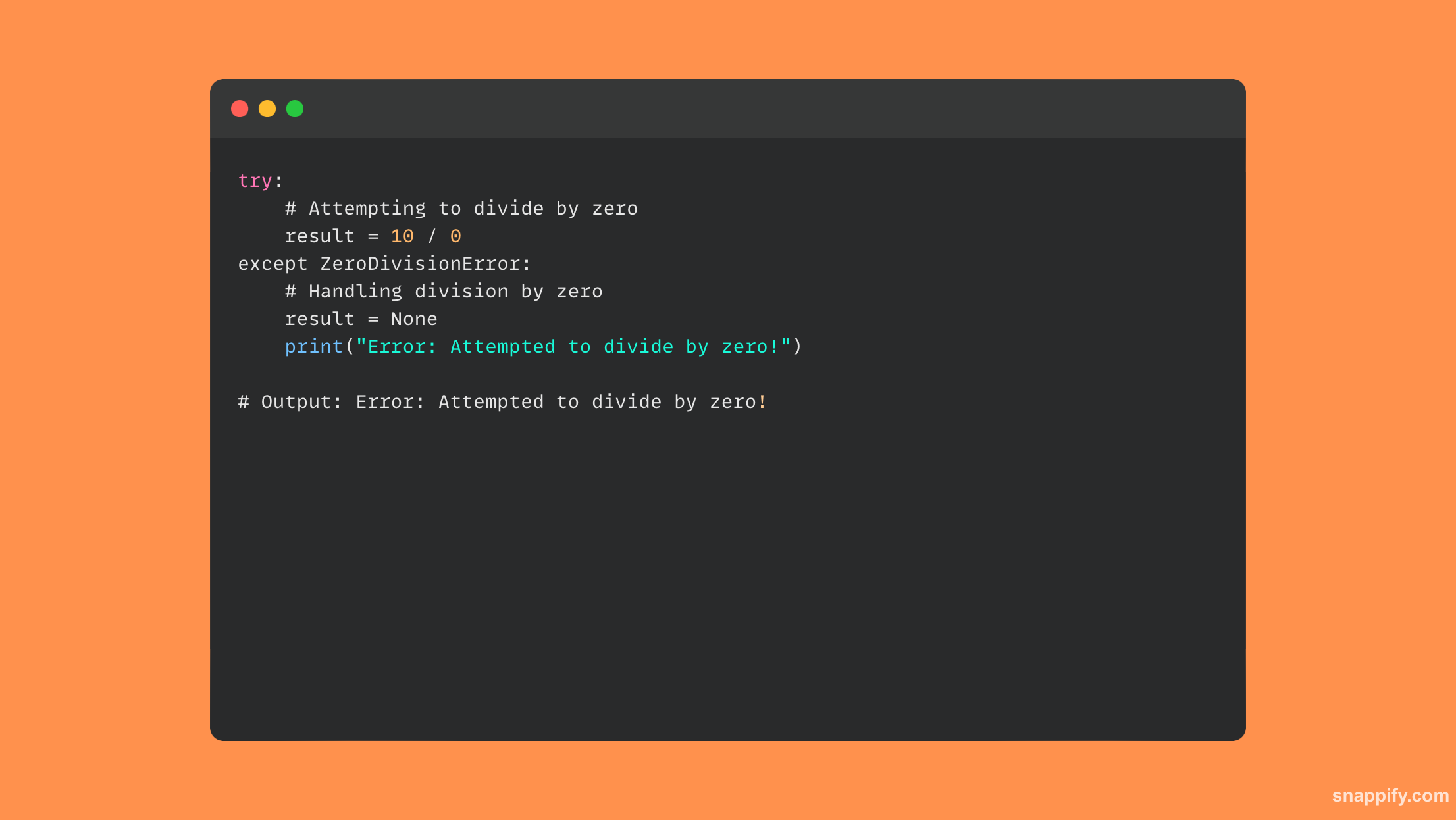
18. raise आणि assert स्टेटमेंटमध्ये काय फरक आहे?
Python च्या एरर हँडलिंगमधील raise आणि assert स्टेटमेंट्स अपवाद व्यवस्थापनाच्या दोन वेगळ्या पण संबंधित अभिव्यक्ती दर्शवतात.
अगोदर निर्देश केलेल्या बाबीसंबंधी बोलताना raise स्टेटमेंट प्रोग्रामरला त्रुटी संदेशांवर स्पष्ट नियंत्रण देते आणि त्यांना स्पष्टपणे निर्दिष्ट अपवाद आणण्याची परवानगी देऊन प्रवाह.
Assert, दुसरीकडे, स्वयंचलितपणे व्युत्पन्न करून डीबगिंग साधन म्हणून कार्य करते AssertionError जर त्याची संबंधित स्थिती समाधानी नसेल तर, विकासादरम्यान कार्यक्रम इच्छित कामगिरी करतो याची हमी देतो.
Assert फक्त परिस्थिती तपासते, डीबगिंग आणि प्रमाणीकरण सुधारते, तर raise व्यापक, अधिक स्पष्ट नियंत्रण सक्षम करते. दोन्ही वाढवतात आणि परमिट नियंत्रित अपवाद उत्पादनाचा दावा करतात.
कसे वापरायचे ते येथे काही नमुना कोड आहे raise आणि assert:
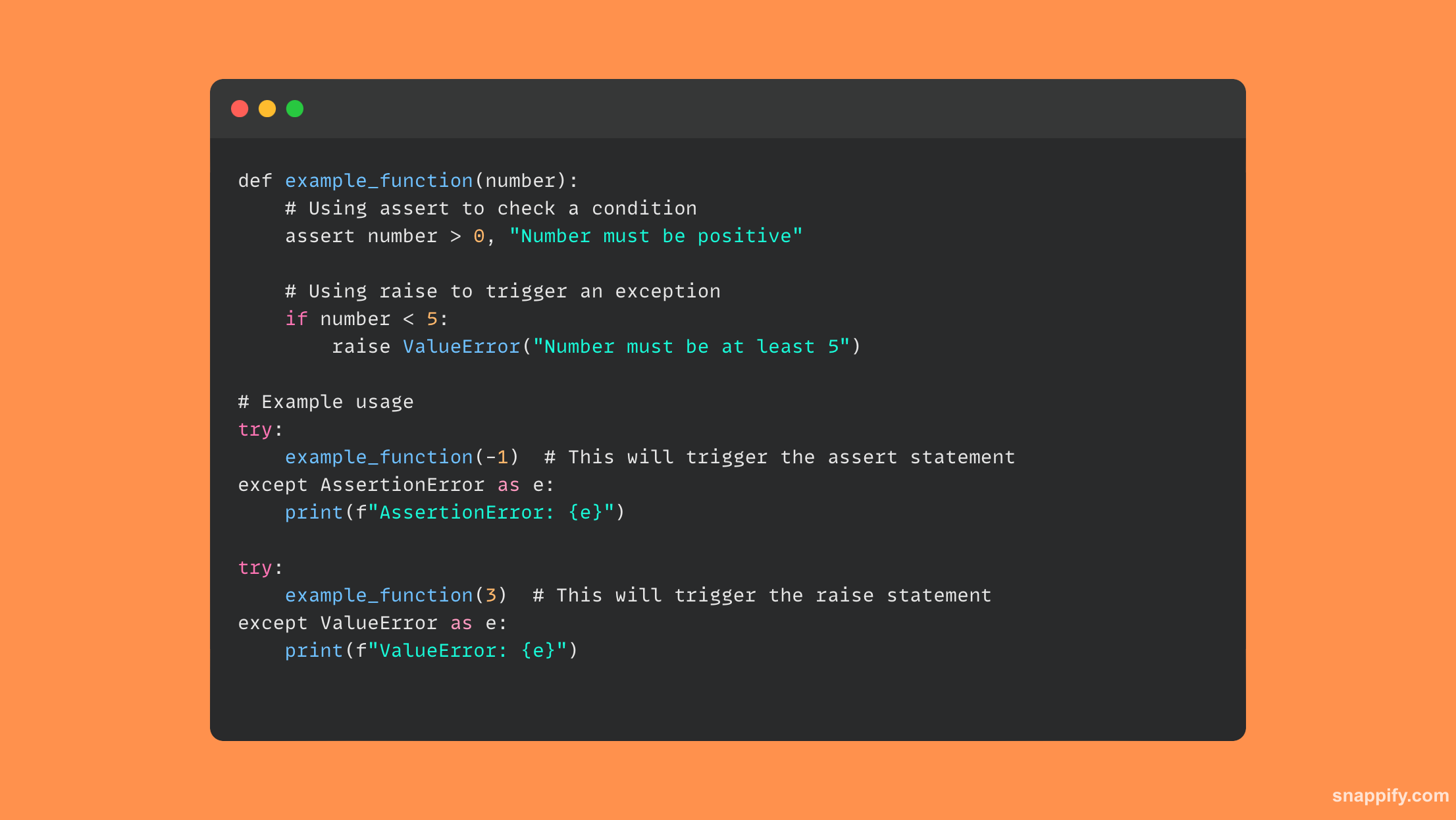
19. तुम्ही पायथनमधील बायनरी फाईलमधून डेटा कसा वाचता आणि लिहिता?
बायनरी मोड स्पेसिफायरसह बिल्ट-इन ओपन फंक्शन वापरणे, पायथनमधील बायनरी फाइल्ससह इंटरफेस करणे अचूकता आणि साधेपणाचे संतुलन आवश्यक आहे.
वापरून rb or wb बायनरी फाइल उघडताना मोड्स हे सुनिश्चित करतील की बायनरी डेटा वाचताना किंवा लिहिताना डेटा त्याच्या अनकोड केलेल्या, कच्च्या स्वरूपात हाताळला जाईल.
या मोड्सचा वापर करून, पायथन नॉन-टेक्स्ट डेटाचे व्यवस्थापन सुलभ करते, जसे की चित्रे किंवा एक्झिक्युटेबल फाइल्स, प्रोग्रामरना बायनरी डेटा तंतोतंत आणि सहजपणे हाताळण्यास आणि त्याचे विश्लेषण करण्यास सक्षम करते.
त्यामुळे, Python मधील बायनरी फाइल ऑपरेशन्स डेटा सीरियलायझेशन, इमेज प्रोसेसिंग आणि बायनरी विश्लेषणासह, अनुप्रयोगांच्या विस्तृत श्रेणीसाठी दरवाजे उघडतात, काही उल्लेख करण्यासाठी.
बायनरी फाइल वापरून, कोडचे हे उदाहरण डेटा कसे वाचायचे आणि कसे लिहायचे ते दाखवते:
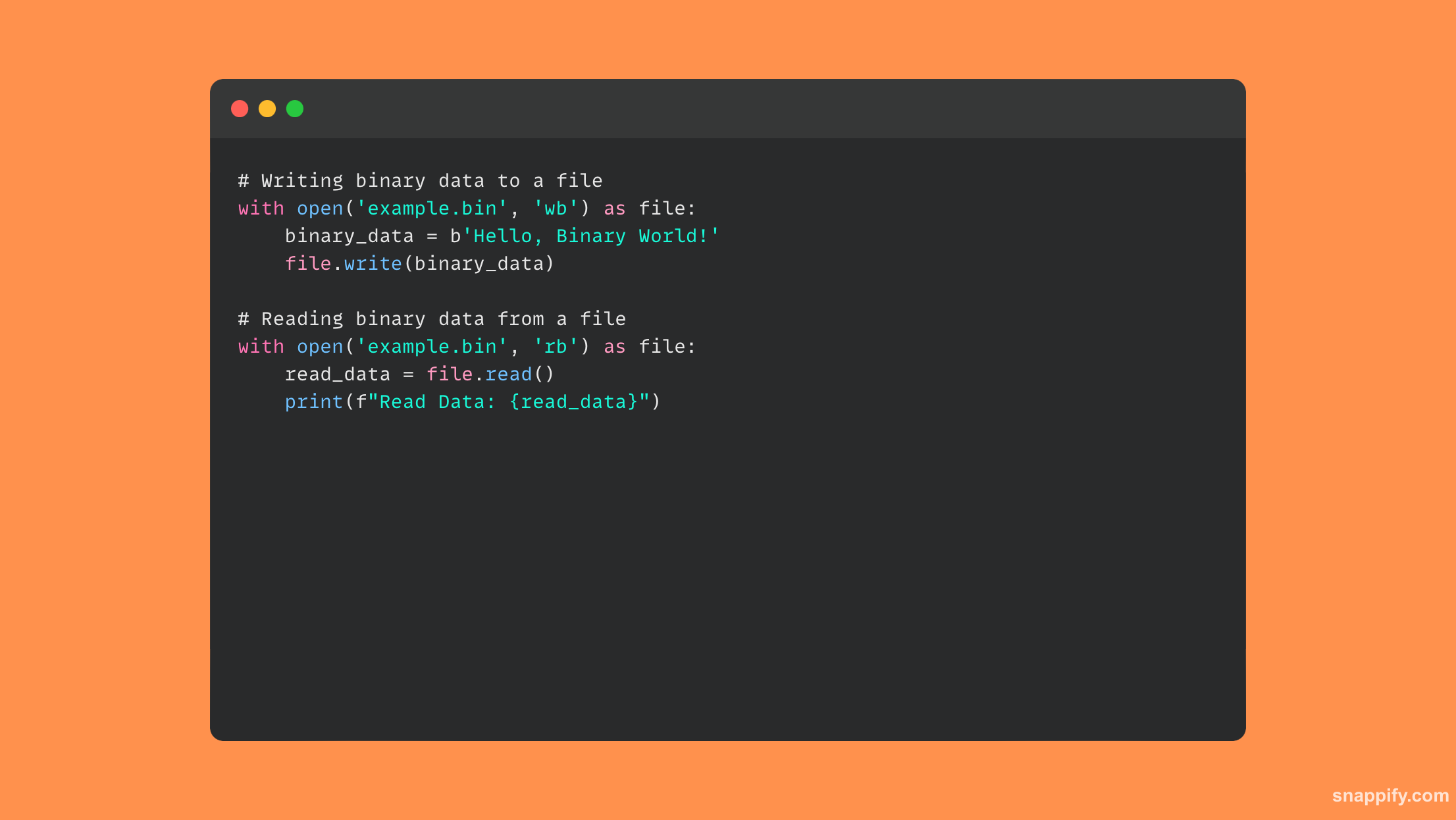
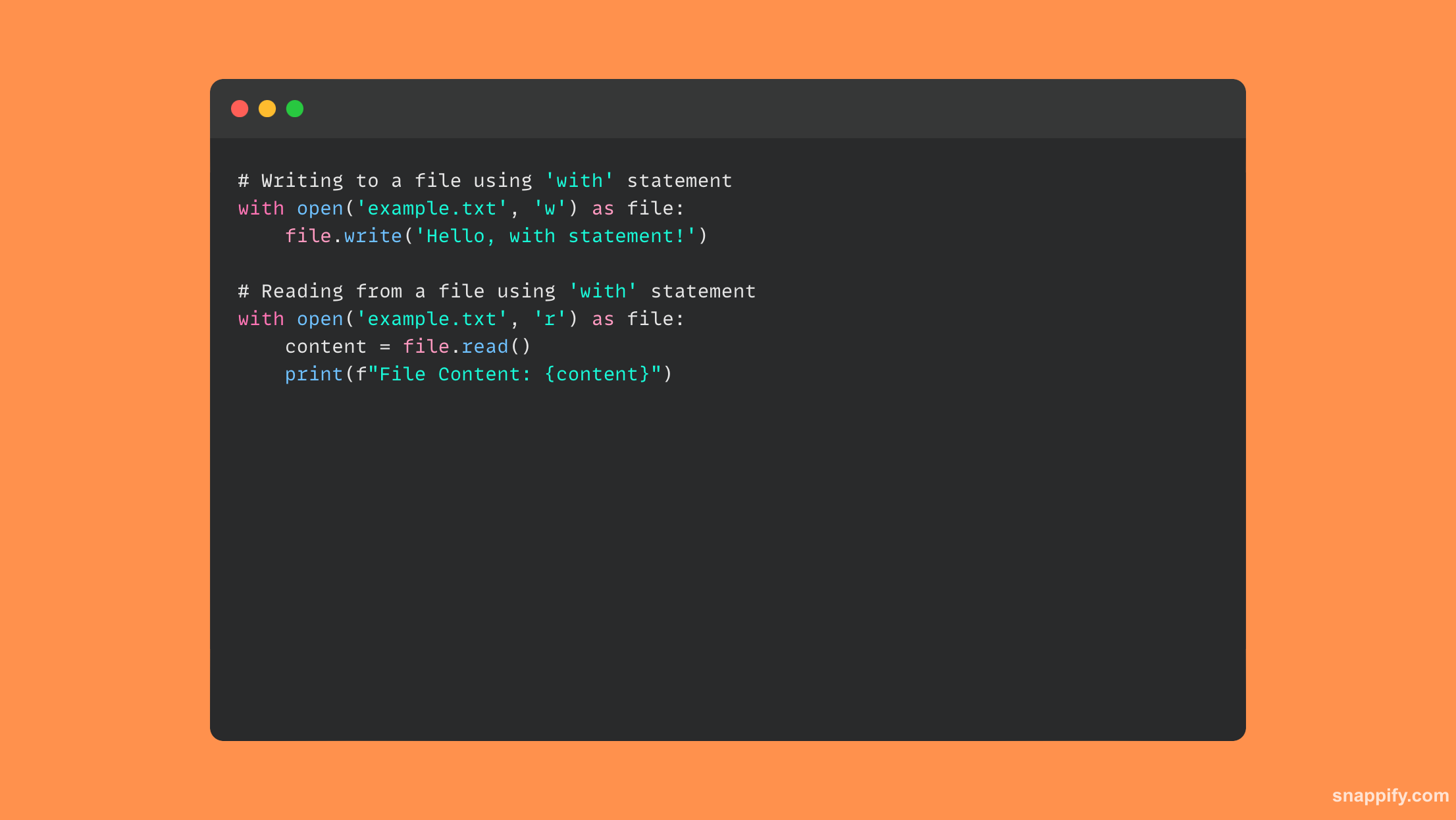
20. स्पष्ट करा with फाइल I/O सह कार्य करताना विधान आणि त्याचे फायदे.
Python's with Statement, ज्याचा वापर I/O फाईलसह वारंवार केला जातो, संदर्भ व्यवस्थापनाच्या कल्पनेमुळे संसाधने प्रभावीपणे हाताळली गेली आहेत याची सुरेखपणे खात्री करते.
फाइल्स हाताळताना, withस्टेटमेंट वापरल्यानंतर फाईल ताबडतोब बंद करते, जरी क्रिया केली जात असताना अपवाद आला तरीही, संसाधन लीकपासून संरक्षण करणे आणि स्वच्छ समाप्तीची हमी देणे.
बॉयलरप्लेट कोड काढून टाकून, ही सिंटॅक्टिक साखर कोड वाचनीयता सुधारते. हे संसाधन व्यवस्थापन आणि अपवाद हाताळणी एकत्रित करून विश्वासार्हता आणि साधेपणा देखील वाढवते.
परिणामी, तुमची फाइल ऑपरेशन्स विश्वासार्ह आणि स्वच्छ आहेत याची खात्री करण्यासाठी, अनपेक्षित समस्यांपासून संरक्षण करण्यासाठी आणि कोड स्पष्टता सुधारण्यासाठी विथ स्टेटमेंट आवश्यक बनते.
येथे कोडचे एक उदाहरण आहे जे वापरते with फाइल ऑपरेशन्समधील विधानः
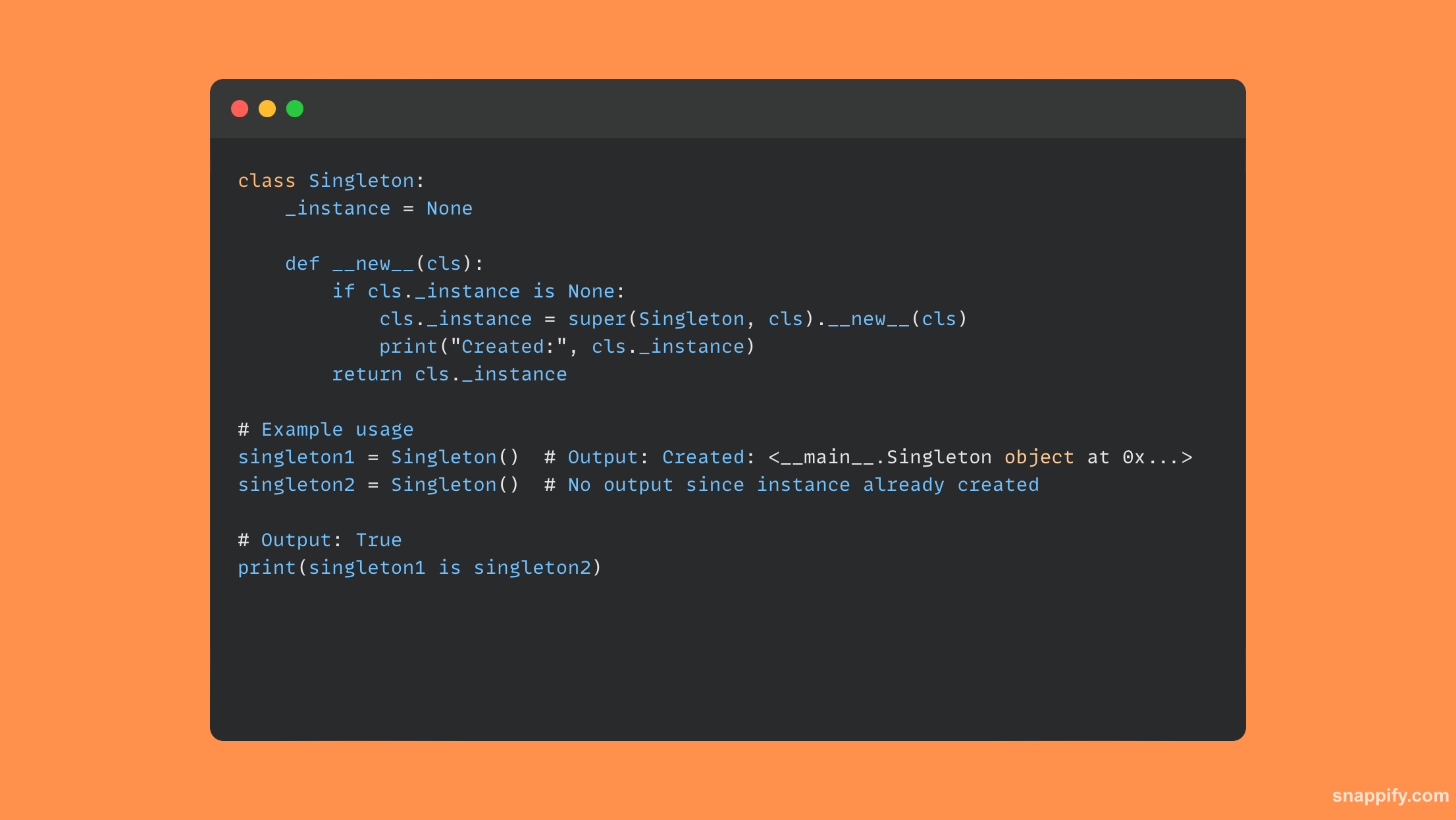
२१. तुम्ही पायथनमध्ये सिंगलटन मॉड्यूल कसे तयार कराल?
पायथनमध्ये सिंगलटन मॉड्यूल तयार करण्यासाठी क्लास पद्धती आणि अंतर्गत तपासण्यांचे संयोजन वापरले जाते, एक डिझाइन पॅटर्न जो केवळ वर्गाचा एकच प्रसंग तयार करण्यास परवानगी देतो.
त्याच्या स्वतःच्या उदाहरणाचा मागोवा ठेवून आणि ते जनरेट करण्यासाठी किंवा परत करण्यासाठी एक पद्धत प्रदान करून, त्यानंतरच्या घटना पहिल्या उदाहरणाची प्रतिकृती बनवतात याची खात्री करण्यासाठी वर्ग हा पॅटर्न फॉलो करतो.
एकल पॉइंट ऑफ कंट्रोल, रिसोर्सेसमध्ये युनिफाइड ऍक्सेस आणि स्पर्धक हाताळणीपासून संरक्षण, सिंगलटन एका पॉइंट ऑफ कंट्रोलची खात्री देते.
परिणामी, सामायिक संसाधने समाविष्ट करण्यासाठी, संपूर्ण प्रोग्राममध्ये सातत्यपूर्ण प्रवेश आणि सुधारणांची हमी देण्यासाठी हे एक प्रभावी साधन म्हणून विकसित होते.
सिंगलटन क्लास दर्शविणारा एक छोटा पायथन कोड नमुना येथे आहे:
22. Python स्क्रिप्टमध्ये मेमरी वापर ऑप्टिमाइझ करण्याचे काही मार्ग सांगा.
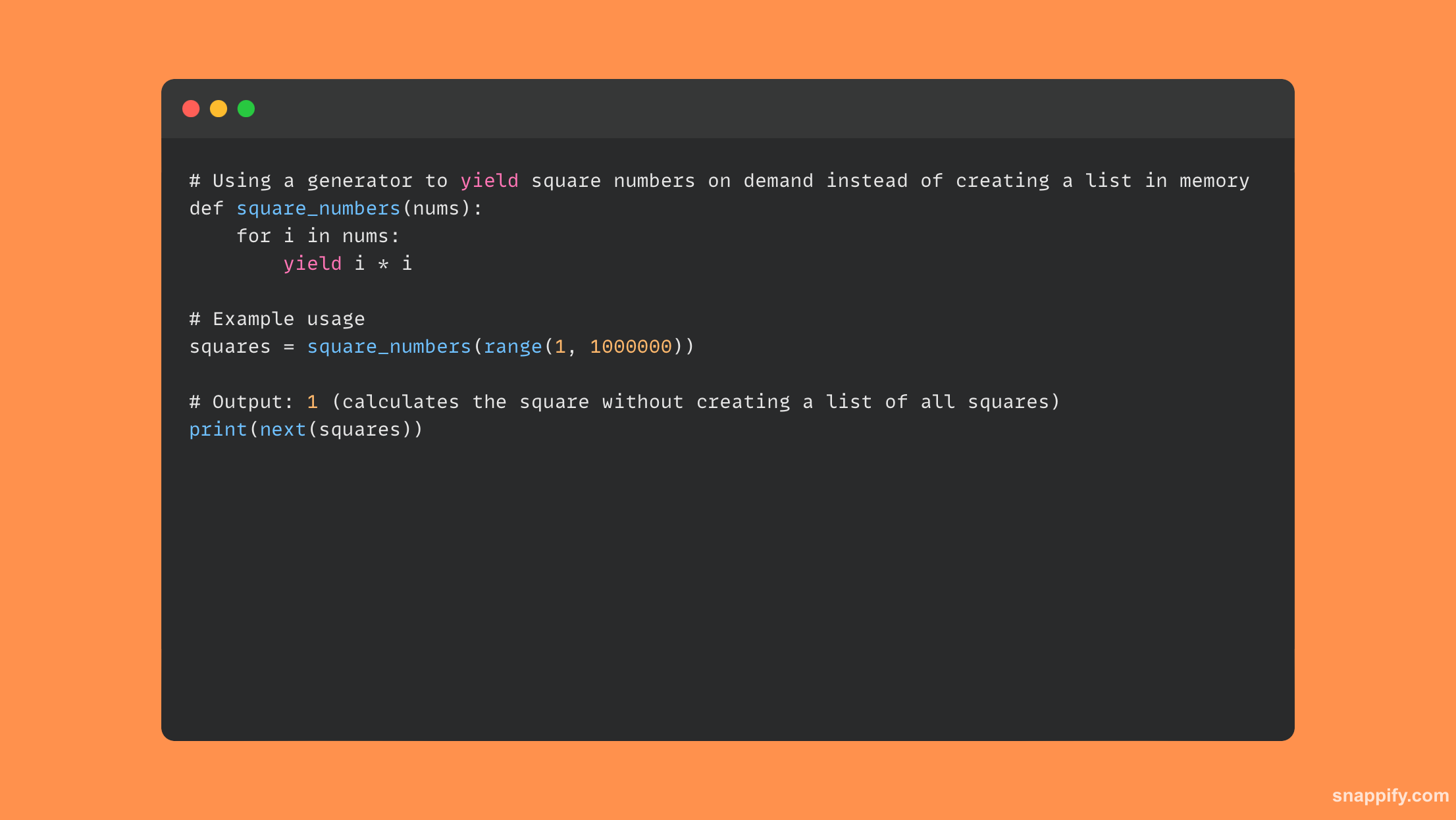
Python स्क्रिप्ट मेमरी वापर ऑप्टिमायझेशनमध्ये डेटा स्ट्रक्चर निवड, अल्गोरिदम सुधारणा आणि संसाधन व्यवस्थापन यांच्यातील काळजीपूर्वक संतुलन साधणे आवश्यक आहे.
मोठ्या डेटासेटसह काम करताना, उदाहरणार्थ, याद्यांऐवजी जनरेटर वापरणे, मेमरीमध्ये ठेवण्याऐवजी फ्लायवरील वस्तूंचे आळशी मूल्यांकन करून मेमरी वापर लक्षणीयरीत्या कमी करू शकते.
सूचीऐवजी अॅरे डेटा स्ट्रक्चर्ससह संख्यात्मक डेटा हाताळून आणि कमी प्रमाणात वापरून मेमरी वापर कमी करणे शक्य आहे. __slots__ डायनॅमिक विशेषतांच्या निर्मितीवर नियंत्रण ठेवण्यासाठी वर्गातील घोषणा.
अशाप्रकारे, कार्यप्रदर्शन आणि संसाधनांचा वापर संतुलित करून, आपण हे सुनिश्चित करू शकता की पायथन प्रोग्राम केवळ प्रभावीच नाहीत तर ते किती मेमरी वापरतात याबद्दल देखील विचारशील आहेत.
वापरलेल्या मेमरीचे प्रमाण कमी करण्यासाठी जनरेटर वापरणारे कोडचे एक लहान उदाहरण येथे आहे:
23. तुम्ही regex वापरून दिलेल्या स्ट्रिंगमधून सर्व ईमेल पत्ते कसे काढाल?
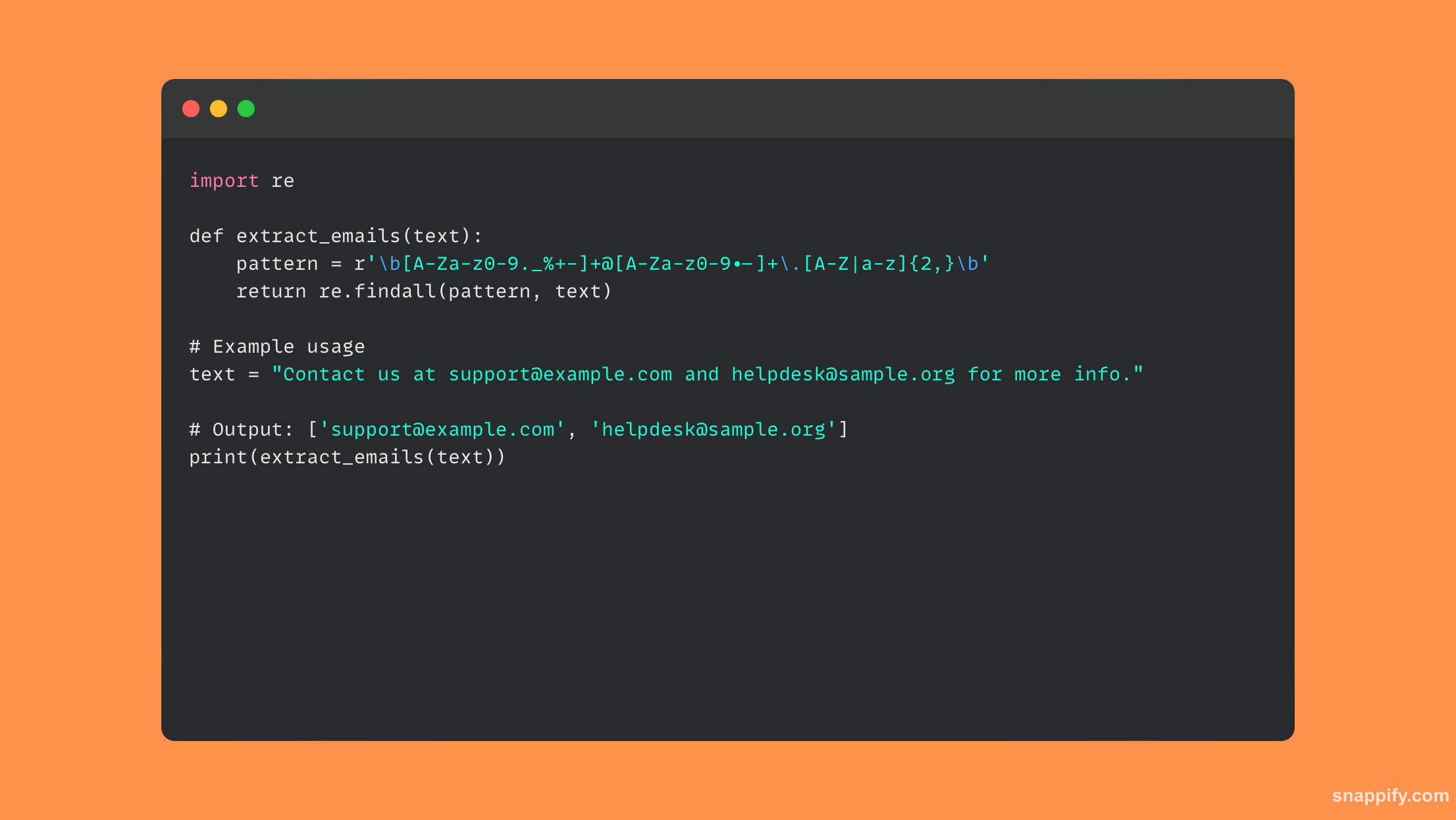
पायथनमधील रेग्युलर एक्स्प्रेशन्स (रेजेक्स) स्ट्रिंगमधून ईमेल पत्ते काढण्यासाठी अचूकता आणि अष्टपैलुत्व एकत्र करतात, ज्यामुळे विकासकाला मजकूर सामग्रीद्वारे चपळपणे फिल्टर करता येते आणि इच्छित नमुने ओळखता येतात.
ईमेल पत्त्याची रचना स्थापित करण्यासाठी, एक री-मॉड्यूल वापरून एक regex नमुना तयार करतो. मग, आपण वापरू शकता findall लक्ष्य स्ट्रिंगमधून सर्व घटना प्राप्त करण्यासाठी.
ही पद्धत सर्व लपविलेले ईमेल पत्ते मिळविण्यासाठी मजकूर चक्रव्यूहात कुशलतेने नेव्हिगेट करते, जे केवळ काढण्याच्या प्रक्रियेला गती देत नाही तर अचूकतेची खात्री देखील देते.
पायथन स्क्रिप्ट्सची डेटा प्रोसेसिंग आणि विश्लेषण वाढवून, स्ट्रिंगमधून काही डेटा प्रभावीपणे काढण्यासाठी Regex चा कुशलतेने वापर केला जाऊ शकतो.
येथे कोडचा एक भाग आहे जो ईमेल काढण्यासाठी regex वापरतो:
24. फॅक्टरी डिझाईन पॅटर्न आणि पायथनमधील त्याचा वापर स्पष्ट करा
ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंगचा मूलभूत सिद्धांत, फॅक्टरी डिझाइन पॅटर्न, व्युत्पन्न करायच्या ऑब्जेक्ट्सचा अचूक वर्ग ओळखल्याशिवाय ऑब्जेक्ट्सची निर्मिती आहे.
फॅक्टरी पॅटर्न पद्धत इनपुट किंवा कॉन्फिगरेशनवर अवलंबून अनेक वर्गांची उदाहरणे देणारी पद्धत तयार करून पायथनमध्ये सुंदरपणे लागू केली जाऊ शकते.
ही प्रक्रिया, ज्याला काहीवेळा "फॅक्टरी" म्हणून संबोधले जाते, अनेक वर्ग उदाहरणे विणण्यासाठी केंद्र म्हणून कार्य करते, कॉलरला हाताने वर्ग सुरू न करता वस्तू तयार केल्या जातात याची हमी देते.
अशाप्रकारे, फॅक्टरी पॅटर्न कोड मॉड्युलॅरिटी आणि सुसंगतता सुधारताना डिकपल्ड, स्केलेबल आर्किटेक्चर राखतो. हे ऑब्जेक्ट्स तयार करण्यासाठी एक सरलीकृत तंत्र देखील देते.
25. इटरेटर आणि जनरेटरमध्ये काय फरक आहे?
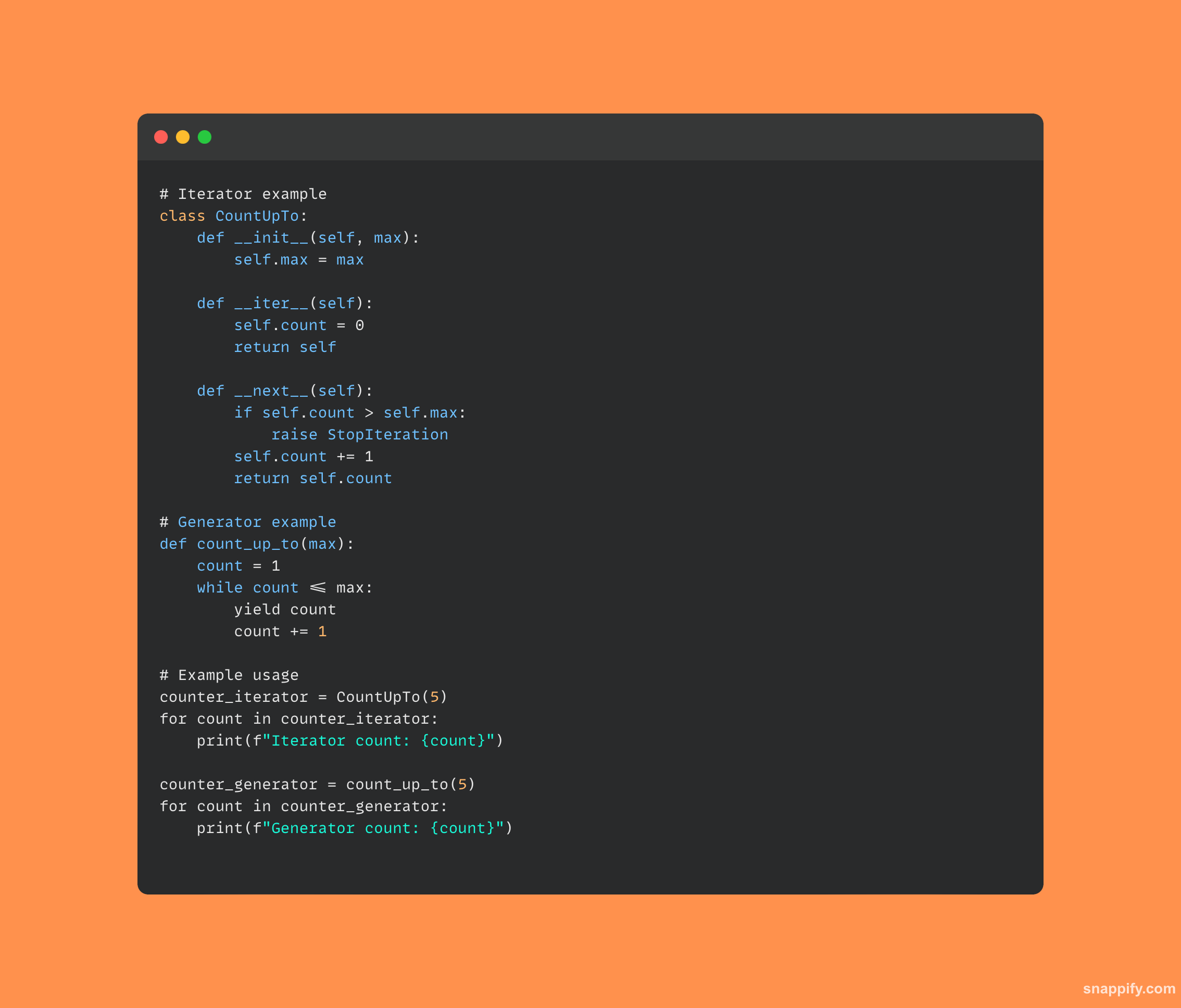
पायथनच्या पुनरावृत्ती आणि जनरेटरवरून हे स्पष्ट आहे की दोन्ही बांधकाम मूल्यांमधून लूप करणे शक्य करतात, तथापि, ते कसे अंमलात आणले जातात आणि कसे वापरले जातात यात सूक्ष्म फरक आहेत.
जनरेटर, जो वारंवार त्याच्या उत्पन्नाच्या वापराद्वारे ओळखला जातो, तो आपोआप त्याची स्थिती राखतो आणि कार्यासह कार्यान्वित केला जातो, फ्लायवर मूल्ये निर्माण करण्यासाठी एक संक्षिप्त आणि स्मृती-कार्यक्षम मार्ग प्रदान करतो.
इटरेटर, जो सामान्यत: वर्ग म्हणून लागू केला जातो, यासारख्या पद्धती वापरतो __iter__ आणि __next__ त्याची पुनरावृत्ती स्थिती व्यवस्थापित करण्यासाठी आणि मूल्ये निर्माण करण्यासाठी.
परिणामी, विशिष्ट वापराच्या केसवर आधारित प्रत्येकाचे स्वतःचे गुण आहेत, पुनरावर्तक डेटावर मार्गक्रमण करण्यासाठी संपूर्ण, ऑब्जेक्ट-देणारं मार्ग ऑफर करतात तर जनरेटर हलके, आळशी मूल्यमापन तंत्र ऑफर करतात.
दोन्ही तंत्रे विकसकाच्या शस्त्रागारात भर घालतात आणि विविध परिस्थितींमध्ये जलद आणि प्रभावीपणे डेटा एक्सप्लोर करणे शक्य करतात.
पायथनमध्ये इटरेटर आणि जनरेटरच्या कोडचा एक भाग येथे आहे:
How. कसे @property डेकोरेटरचे काम?
Python मधील '@property' डेकोरेटर एक सुंदर गाणे वाजवतो जे मेथड कॉल्सला विशेषता-सारख्या ऍक्सेसमध्ये रूपांतरित करते, ऑब्जेक्टची उपयोगिता आणि अभिव्यक्ती सुधारते.
@प्रॉपर्टी वापरून कंस न वापरता पद्धत कॉल केली जाऊ शकते, जी विशेषता ऍक्सेस करण्यासारखीच आहे. हे ऑब्जेक्ट परस्परसंवादासाठी एक स्पष्ट आणि वापरण्यास सुलभ इंटरफेस तयार करते.
याव्यतिरिक्त, ते कार्यक्षमता आणि एन्कॅप्स्युलेशनचे कुशल संतुलन देते, अंतर्ज्ञानी इंटरफेस वितरीत करताना ऑब्जेक्ट स्टेटसचे संरक्षण करते, विकासकांना गेटर आणि सेटर पद्धती वापरून सहजतेने विशेषता निर्दिष्ट करण्यास सक्षम करते.
विशेषता प्रवेशयोग्यतेसह पद्धत कार्यक्षमता एकत्रित करून, द @property डेकोरेटर एक महत्त्वपूर्ण साधन म्हणून उदयास आले आहे आणि एक सरळ परंतु प्रभावी ऑब्जेक्ट परस्पर संवाद नमुना देते.
पायथनचे उदाहरण @property डेकोरेटर खाली दर्शविले आहे:
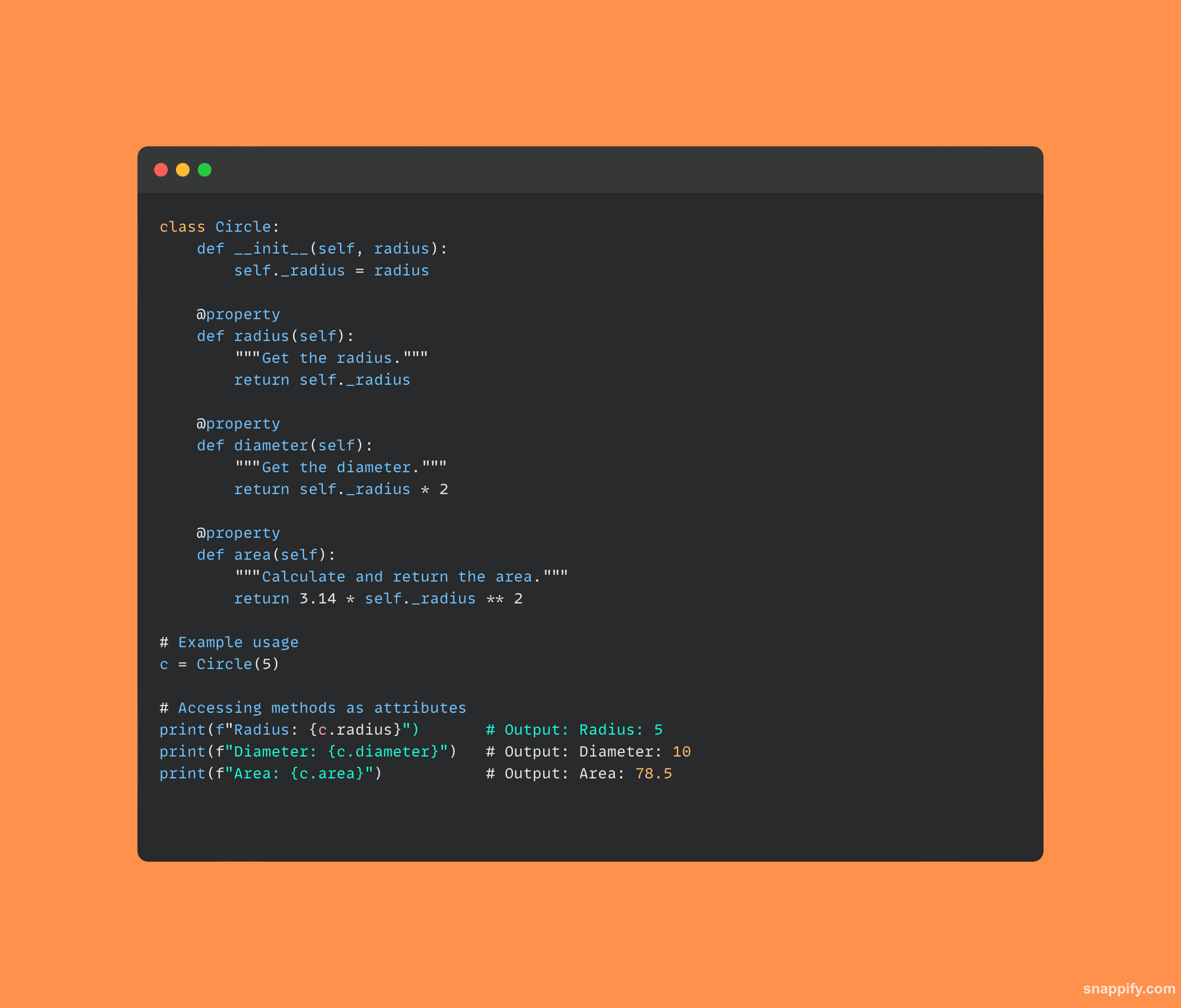
27. तुम्ही पायथनमध्ये मूलभूत REST API कसे तयार कराल?
एचटीटीपी विनंत्यांद्वारे संवाद साधणाऱ्या वेब सेवा तयार करण्यासाठी, डेव्हलपर वारंवार फ्लास्क सारख्या फ्रेमवर्कच्या अभिव्यक्त क्षमतेचा वापर करतात. आरईएसटी API Python मध्ये.
त्याच्या सोप्या आणि समजण्याजोग्या वाक्यरचनासह, फ्लास्क विकासकांना मूळ अनुप्रयोगाशी संवाद साधण्यासाठी GET आणि POST सह अनेक HTTP पद्धतींद्वारे प्रवेश करता येणारे मार्ग तयार करण्यास सक्षम करते.
फ्लास्क वापरून तयार केलेला REST API HTTP विनंत्या सहजपणे स्वीकारू शकतो, समाविष्ट डेटावर प्रक्रिया करू शकतो आणि विविध कार्यक्षमतेशी जोडलेले अद्वितीय एंडपॉइंट्स निर्दिष्ट करून प्रतिसादात संबंधित माहिती प्रदान करू शकतो.
नेटवर्क केलेल्या वातावरणात विविध सॉफ्टवेअर घटकांमधील अखंड संवाद सुनिश्चित करण्यासाठी, विकसक Python आणि Flask चे संयोजन वापरून शक्तिशाली REST API वापरू शकतात.
येथे कोडचा एक छोटा तुकडा आहे जो REST API तयार करण्यासाठी फ्लास्क वापरतो:
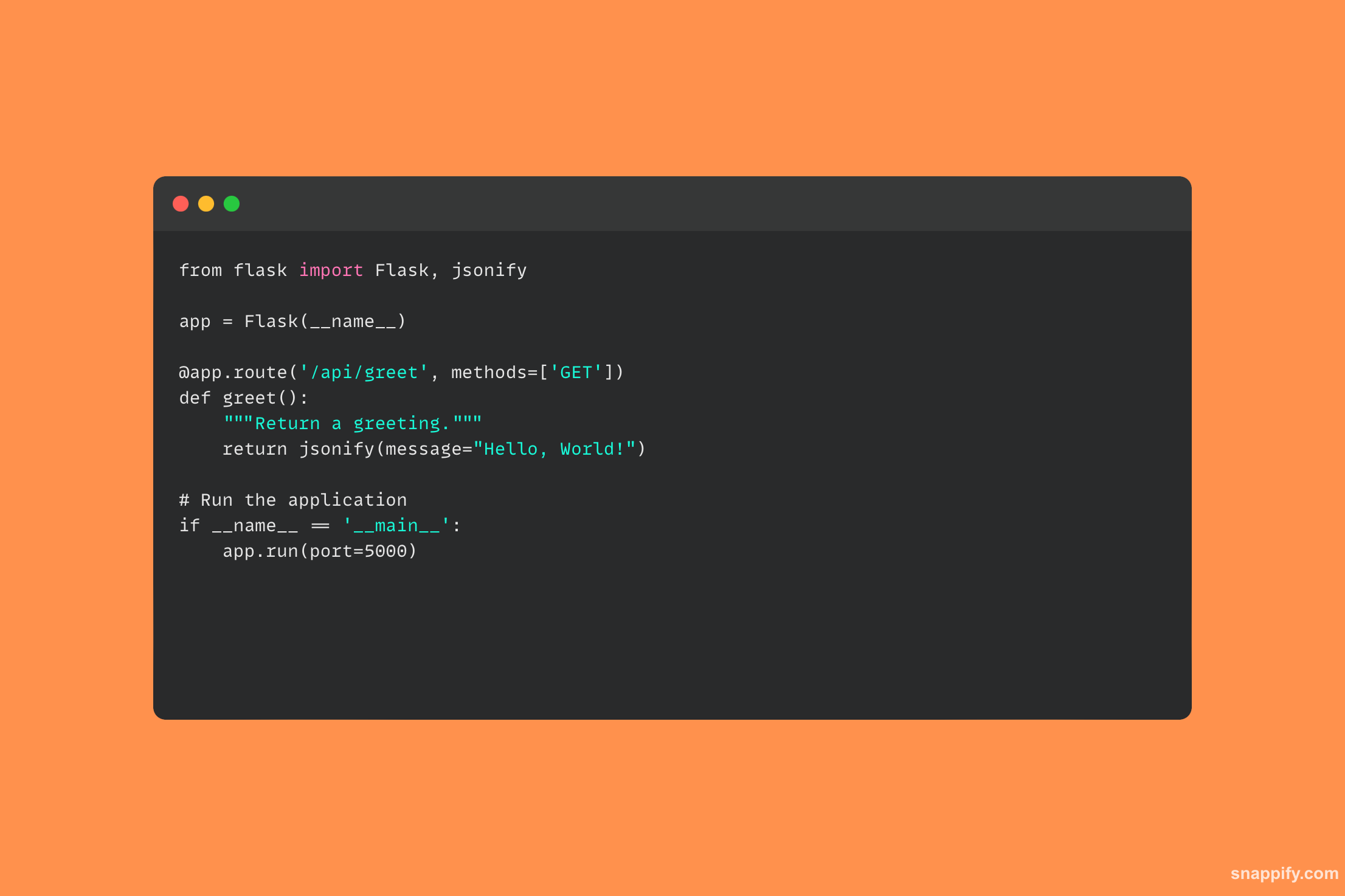
28. HTTP POST विनंती करण्यासाठी विनंती लायब्ररी कशी वापरायची याचे वर्णन करा.
पायथनची रिक्वेस्ट लायब्ररी हे एक शक्तिशाली साधन आहे जे HTTP कम्युनिकेशनच्या अडचणींचे स्वागत API मध्ये रूपांतरित करते आणि HTTP POST विनंत्या वापरून ऑनलाइन सेवांशी संवाद साधणे सोपे आणि नैसर्गिक बनवते.
पोस्ट पद्धत वापरून, गंतव्य URL देऊन आणि पाठवायची सामग्री संलग्न करून POST विनंती केली जाते, ज्यामध्ये फॉर्म डेटा, JSON, फाइल्स आणि बरेच काही असू शकते.
विनंत्या लायब्ररी नंतर अंतर्निहित HTTP कनेक्शन व्यवस्थापित करते, नियुक्त URL वर डेटा पाठवते आणि द्रव वेब परस्परसंवाद सक्षम करण्यासाठी सर्व्हरचा प्रतिसाद गोळा करते.
विकसक ऑनलाइन सेवांसह सहजपणे व्यस्त राहू शकतात, फॉर्म डेटा सबमिट करू शकतात आणि विनंत्यांद्वारे वेब API सह इंटरफेस करू शकतात, स्थानिक अॅप्स आणि जागतिक वेबमधील अंतर कमी करू शकतात.
विनंत्या लायब्ररी वापरून, खालील कोड नमुना HTTP POST विनंती कशी पाठवायची ते दाखवते:
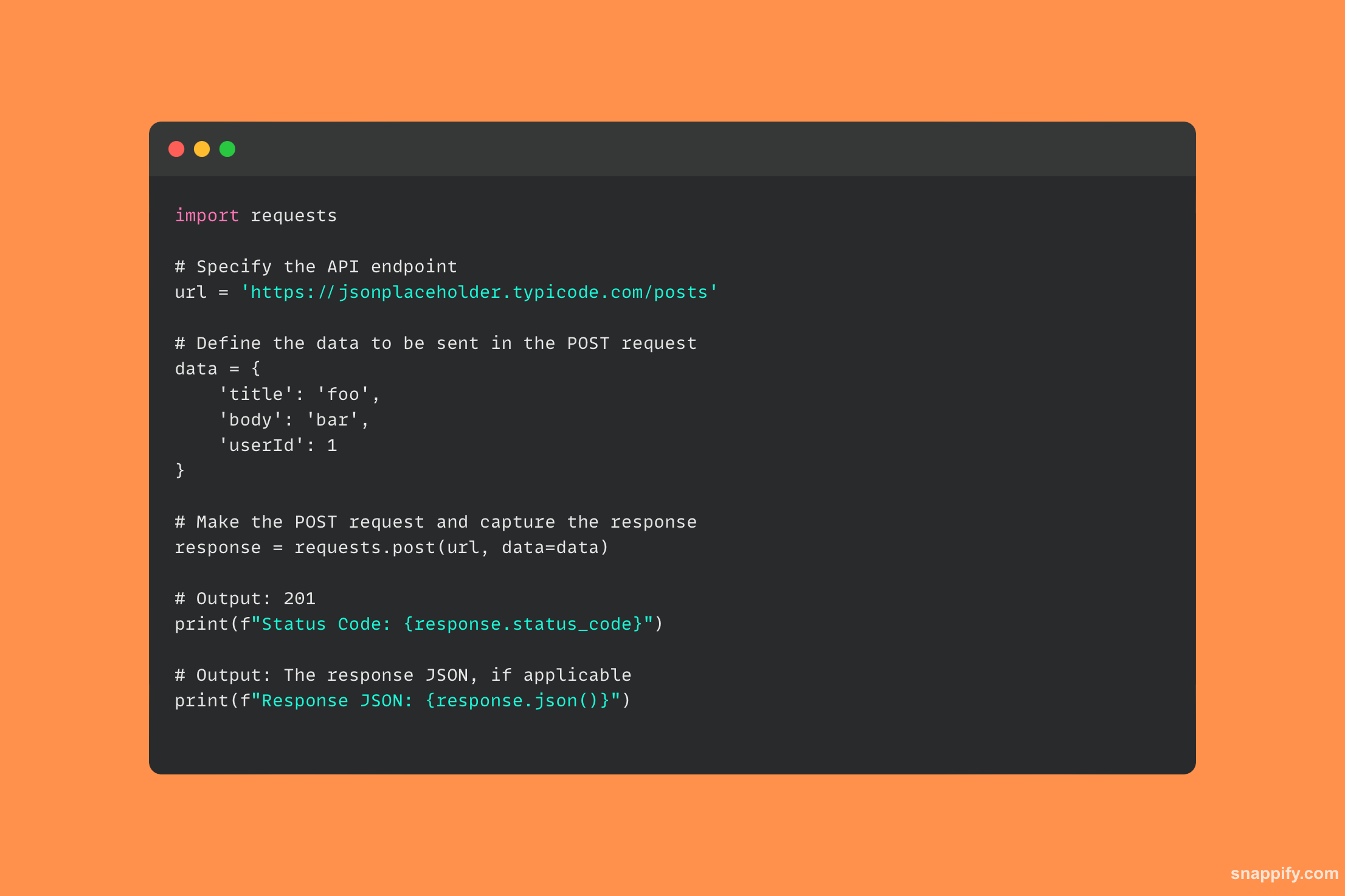
29. Python वापरून तुम्ही PostgreSQL डेटाबेसशी कसे कनेक्ट कराल?
Python वातावरणातील PostgreSQL डेटाबेससह गुंतणे psycopg2 पॅकेजद्वारे सुरेखपणे हाताळले जाते, जो एक शक्तिशाली ब्रिज आहे जो अखंड डेटाबेस परस्परसंवादासाठी परवानगी देतो.
वापरुन psycopg2, प्रोग्रामर सहजपणे कनेक्शन तयार करू शकतात, SQL क्वेरी चालवू शकतात आणि परिणाम मिळवू शकतात, थेट पायथन प्रोग्राममध्ये PostgreSQL ची क्षमता समाकलित करू शकतात.
आपण कोडच्या काही ओळींसह जटिल डेटाबेस फंक्शन्स अनलॉक करू शकता, याची हमी देतो की डेटा ऍक्सेस केला जाईल, सुधारला जाईल आणि अचूकता आणि कार्यक्षमतेसह जतन केला जाईल.
हे मॉड्यूल विकसकांना त्यांच्या ऍप्लिकेशन्समध्ये Python आणि PostgreSQL यांच्यातील समन्वयाची सुरेखपणे जाणीव करून रिलेशनल डेटाबेसेसचा पूर्णपणे वापर करण्यास अनुमती देते.
येथे नमुना कोड आहे जो कसा वापरायचा हे दर्शवितो psycopg2 PostgreSQL डेटाबेसशी कनेक्शन स्थापित करण्यासाठी लायब्ररी:
30. Python मध्ये ORM ची भूमिका काय आहे आणि एक लोकप्रिय नाव काय आहे?
Python मधील ऑब्जेक्ट-रिलेशनल मॅपिंग (ORM) विकसकांना Python वर्ग आणि ऑब्जेक्ट पॅराडाइम्स वापरून डेटाबेसशी कनेक्ट करण्यास सक्षम करते.
हे ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग आणि रिलेशनल डेटाबेस अॅडमिनिस्ट्रेशन दरम्यान एक हार्मोनिक मध्यस्थ म्हणून कार्य करते.
SQLAlchemy, Python वातावरणातील सर्वात सुप्रसिद्ध ORM पैकी एक, उच्च-स्तरीय, ऑब्जेक्ट-ओरिएंटेड सिंटॅक्स वापरून एकाधिक SQL डेटाबेससह संवाद साधण्यासाठी संपूर्ण साधनांचा संच प्रदान करते.
SQLAlchemy च्या मदतीने, डेटाबेस घटकांना Python वर्ग म्हणून प्रस्तुत केले जाऊ शकते, या वर्गांच्या उदाहरणांसह डेटाबेस टेबलमध्ये पंक्ती म्हणून काम केले जाते.
हे प्रोग्रामरना कोणत्याही कच्च्या SQL क्वेरी न लिहिता डेटाबेससह ऑपरेट करण्यास अनुमती देते.
SQL आणि डेटाबेस कनेक्टिव्हिटीच्या जटिलतेमुळे, SQLAlchemy सारखे ORM अधिक वापरकर्ता-अनुकूल, सुरक्षित आणि देखभाल करण्यायोग्य डेटाबेस परस्परसंवाद शक्य करतात.
SQLAlchemy कसे कार्य करते हे दर्शविणारे एक साधे उदाहरण येथे आहे:
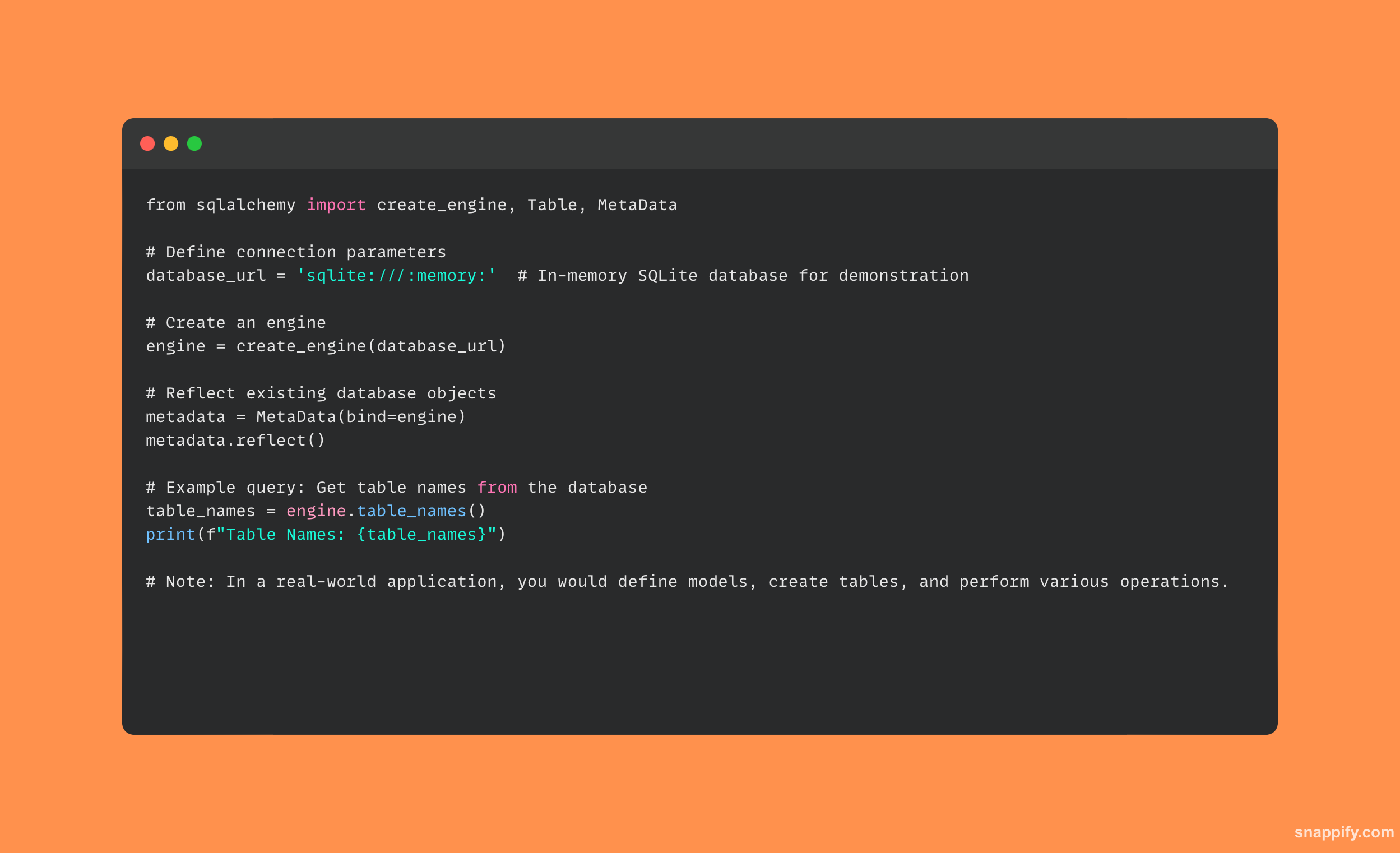
31. तुम्ही पायथन स्क्रिप्टची प्रोफाइल कशी कराल?
कोणत्याही संभाव्य कार्यक्षमतेतील अडथळे शोधण्यासाठी आणि कार्यक्षमतेत सुधारणा करण्यासाठी पायथन स्क्रिप्टची संगणकीय रचना आणि त्याच्या अंमलबजावणीची वेळ आणि जागा तपशीलांचे विश्लेषण करून प्रोफाइल केले जाते.
बिल्ट-इन वापरून विकासक रनटाइम दरम्यान त्यांच्या कोडच्या वर्तनाचे काळजीपूर्वक विश्लेषण करू शकतात cProfile मॉड्यूल
असे केल्याने, ते फंक्शन कॉल, एक्झिक्यूशन वेळा आणि कॉल रिलेशनशिप्सवर संपूर्ण डेटा मिळवू शकतात, ज्यामुळे त्यांना कार्यप्रदर्शनातील अडथळे ओळखता येतात आणि त्यांचे निराकरण करता येते.
आपण हमी देऊ शकता की कोड केवळ योग्यरित्या कार्य करत नाही तर कार्यक्षमतेने देखील, संगणकीय संसाधनांमध्ये संतुलन साधते आणि संपूर्ण अनुप्रयोग कार्यप्रदर्शन सुधारते, विकास जीवनचक्रामध्ये प्रोफाइलिंग समाविष्ट करून.
त्यामुळे डेव्हलपर अकार्यक्षमतेपासून प्रोग्रॅम्सचे काळजीपूर्वक प्रोफाइलिंग करून संरक्षण करू शकतात, हे सुनिश्चित करून की ते संगणकीय मागण्यांच्या श्रेणीमध्ये विश्वसनीयरित्या ट्यून केलेले आणि कार्यक्षम आहेत.
वापरून पायथन स्क्रिप्ट प्रोफाइलिंगचे एक साधे उदाहरण येथे आहे cProfile मॉड्यूल:
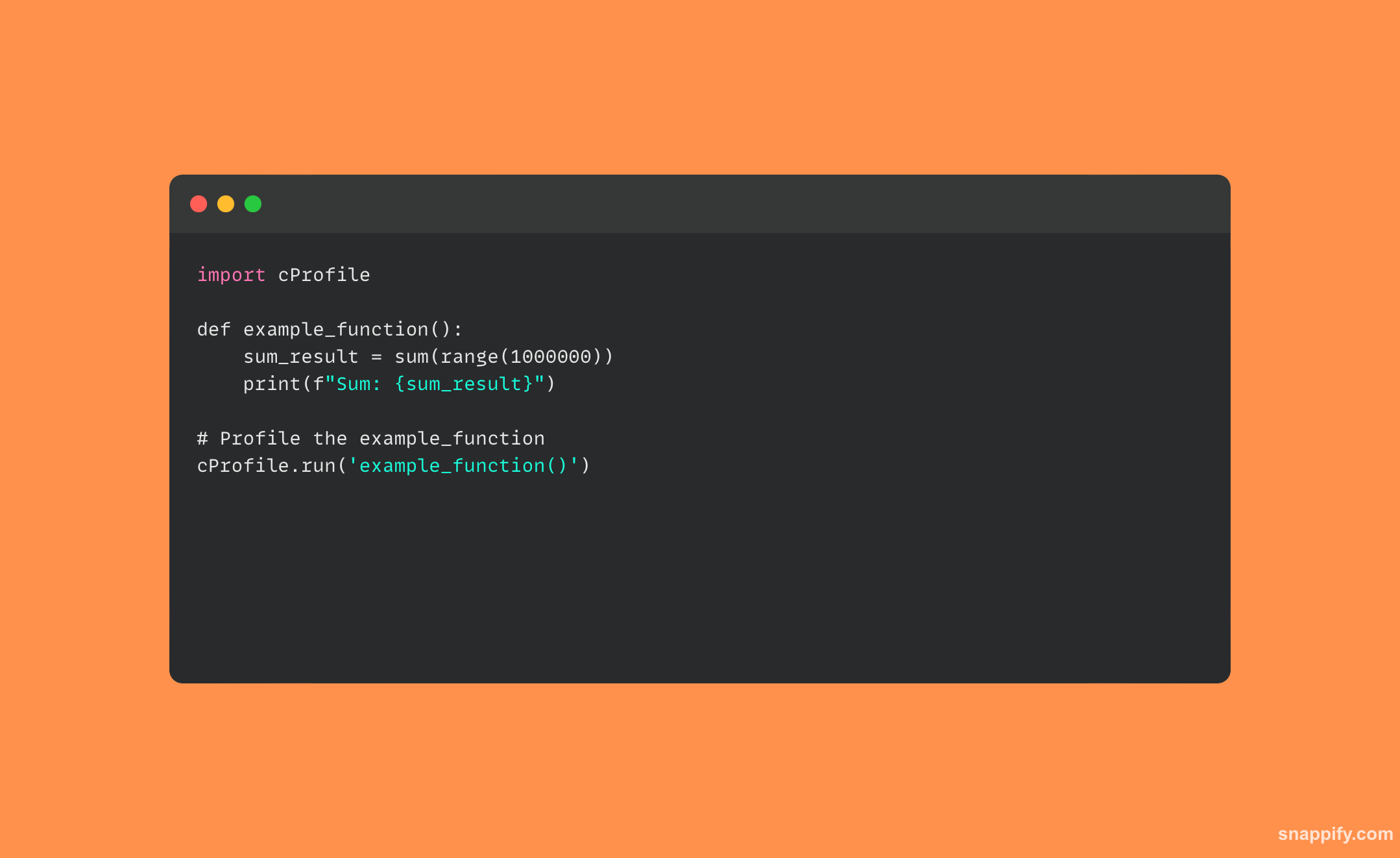
32. CPython मधील GIL (ग्लोबल इंटरप्रीटर लॉक) स्पष्ट करा
CPython मधील ग्लोबल इंटरप्रिटर लॉक (GIL) सेंटिनेल म्हणून कार्य करते, याची हमी देते की एकाच प्रक्रियेत एकाच वेळी फक्त एक थ्रेड पायथन बायकोड चालवतो, अगदी मल्टी-थ्रेडेड ऍप्लिकेशन्समध्येही.
जरी ते अडथळे असल्याचे दिसून येत असले तरी, CPython च्या मेमरी व्यवस्थापन आणि अंतर्गत डेटा संरचनांना समवर्ती प्रवेशापासून संरक्षण करण्यासाठी आणि सिस्टम अखंडतेचे संरक्षण करण्यासाठी GIL महत्त्वपूर्ण आहे.
I/O-बाउंड क्रियाकलापांमध्ये मल्टीथ्रेडिंगची गरज, जिथे थ्रेड्सने डेटा वितरित किंवा प्राप्त होण्याची प्रतीक्षा केली पाहिजे, तरीही, GIL ही गरज दूर करत नसल्यामुळे, लक्षात ठेवले पाहिजे.
अशाप्रकारे, जरी GIL ला CPU-बद्ध क्रियाकलापांसाठी अडचणी येत असल्या तरी, त्याच्या वर्तनाचे आकलन आणि तंत्रांचे अनुकूलन, जसे की मल्टीप्रोसेसिंग किंवा समवर्ती प्रोग्रामिंग वापरणे, विकासकांना प्रभावी, समवर्ती पायथन प्रोग्राम तयार करण्यास अनुमती देते.
येथे पायथन कोडचे एक उदाहरण आहे जे थ्रेड्स वापरते आणि दाखवते की GIL चा CPU-बद्ध कार्यांवर कसा परिणाम होऊ शकतो:
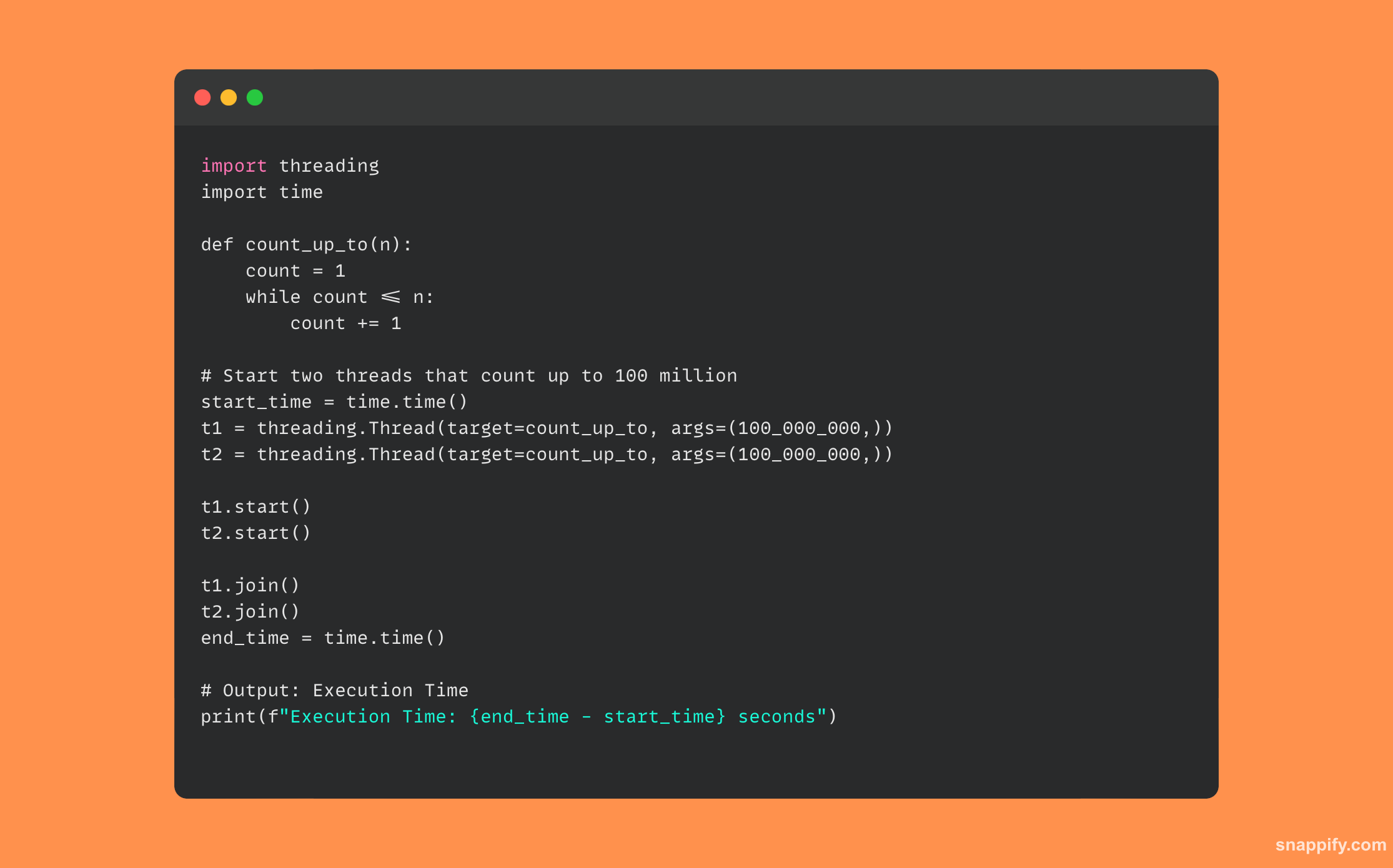
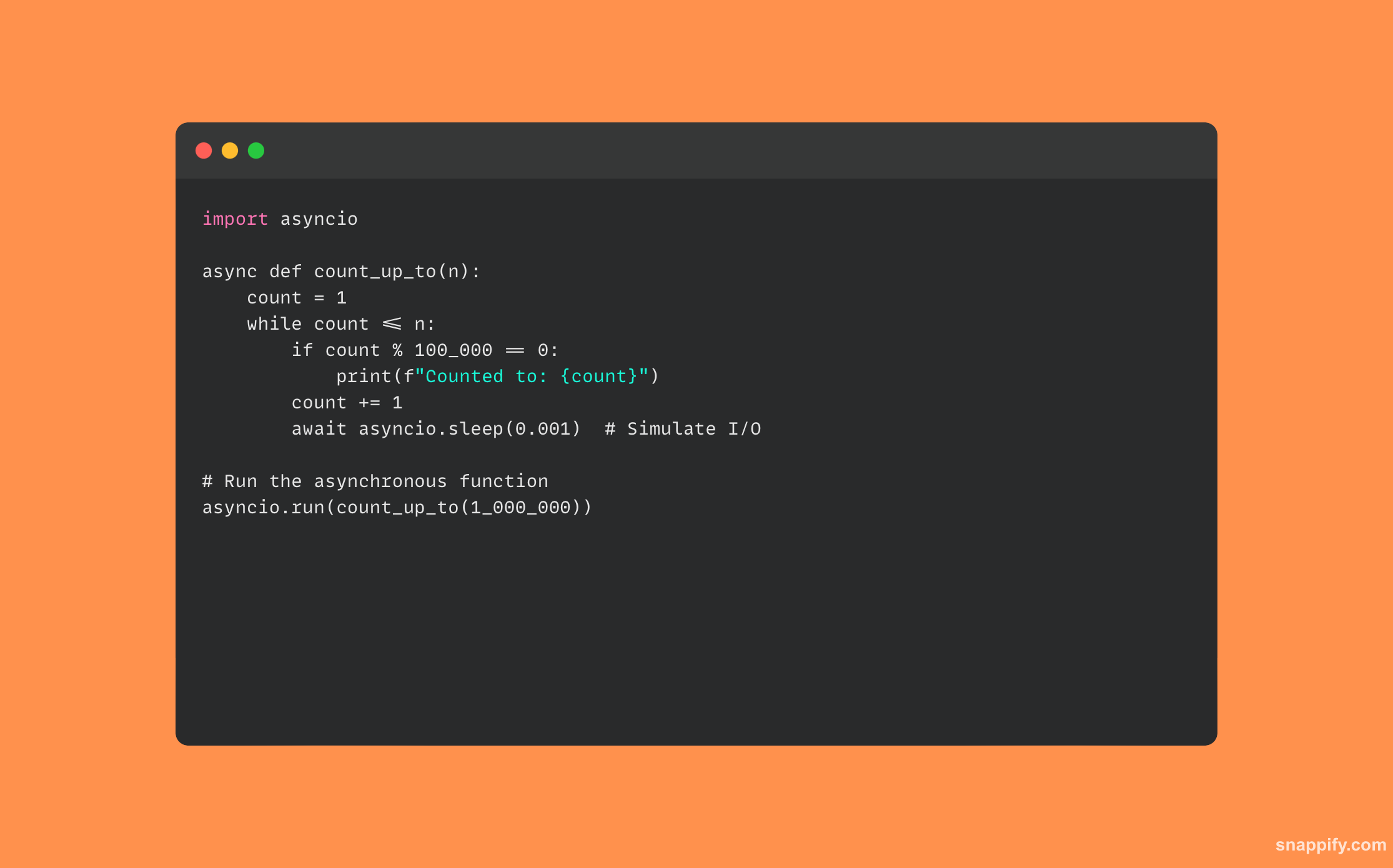
33. Python चे async/await स्पष्ट करा. हे पारंपारिक थ्रेडिंगपेक्षा वेगळे कसे आहे?
Python मधील async/await सिंटॅक्स असिंक्रोनस प्रोग्रामिंगचे जग उघडते, एक नमुना जो काही कार्ये रनटाइम वातावरणावर नियंत्रण ठेवू देतो जेणेकरून इतर क्रियाकलाप या दरम्यान कार्यक्षमतेत सुधारणा करू शकतील.
Async/await एकाच थ्रेडमध्ये अॅक्टिव्हिटी ठेवते परंतु थ्रेड व्यवस्थापनाच्या जटिलतेशिवाय नॉन-ब्लॉकिंग वर्तनाची खात्री देऊन, कार्यांदरम्यान उडी मारण्यासाठी अंमलबजावणी सक्षम करते.
हे शास्त्रीय थ्रेडिंगच्या विरुद्ध आहे, जेथे थ्रेड्स समांतरपणे कार्यान्वित होतात आणि वारंवार क्लिष्ट व्यवस्थापन आणि सिंक्रोनाइझेशनची आवश्यकता असते.
परिणामी, विकासक समवर्ती I/O-बाउंड क्रियाकलाप प्रभावीपणे हाताळू शकतात आणि समवर्ती नियंत्रित करण्यासाठी अधिक सरळ दृष्टिकोनासह.
हे सहकारी मल्टीटास्किंग मॉडेलला प्रोत्साहन देते ज्यामध्ये प्रक्रिया स्वेच्छेने नियंत्रण मिळवतात.
परिणामी, async/await समवर्ती ऍप्लिकेशन्स डिझाइन करण्याचा एक विशिष्ट, सोपा मार्ग ऑफर करते, विशेषत: जेथे I/O ऑपरेशन्स सामान्य आहेत, कार्यप्रदर्शन आणि जटिलता यांच्यातील समतोल शोधणे.
async/await वापरणाऱ्या Python कोडचे उदाहरण खाली दिले आहे:
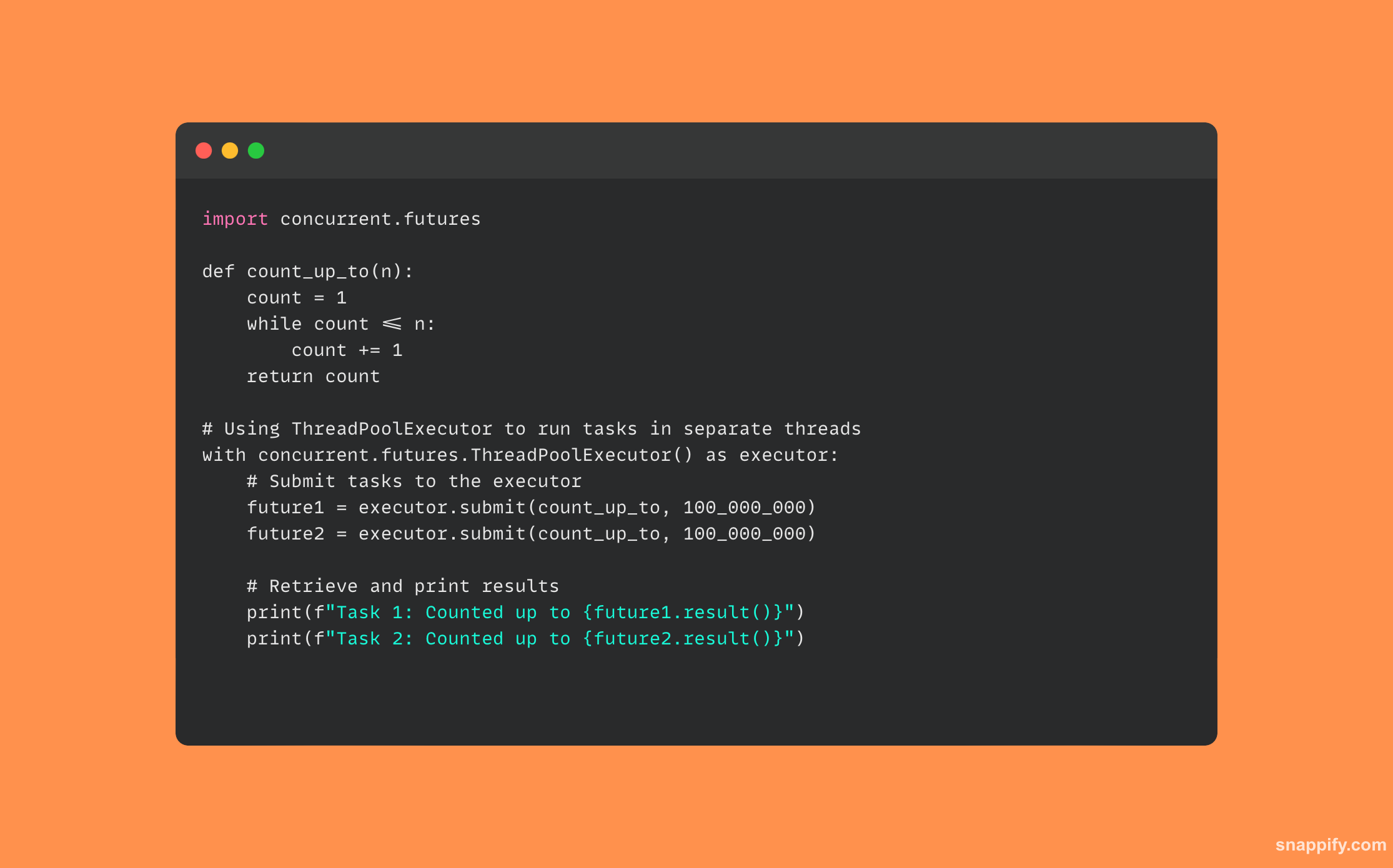
34. तुम्ही Python चा वापर कसा कराल याचे वर्णन करा concurrent.futures.
थ्रेड्स किंवा प्रक्रियांद्वारे असिंक्रोनसपणे कॉलेबल कार्यान्वित करण्यासाठी इंटरफेस, विकासक एसिंक्रोनस आणि समांतर ऑपरेशन्स सुंदरपणे व्यवस्थापित करू शकतात.
हे मॉड्यूल एक्झिक्युटर्स (ThreadPoolExecutor आणि ProcessPoolExecutor) द्वारे थ्रेडिंग आणि मल्टीप्रोसेसिंगच्या नाजूक पैलूंचा अंतर्भाव करताना कॉलबल्सचे संसाधन वाटप आणि अंमलबजावणी व्यवस्थापित करते.
डेव्हलपर CPU-बद्ध क्रियाकलापांसाठी मल्टी-कोर प्रोसेसर प्रभावीपणे वापरू शकतात आणि एक्झिक्युटरला कार्ये पाठवून नॉन-ब्लॉकिंग I/O ऑपरेशन्स प्रदान करू शकतात, जे नंतर त्यांना एकाच वेळी करू शकतात आणि त्यांचे परिणाम एकत्रित करू शकतात.
अनुप्रयोग प्रतिसादात्मक आणि कार्यक्षम आहेत याची खात्री करण्यासाठी, concurrent.futures एक जागा तयार करते जिथे जटिल गणना आणि I/O क्रियाकलाप सहजतेने विलीन होऊ शकतात.
येथे वापरणाऱ्या कोडचा नमुना आहे concurrent.futures:
35. जॅंगो आणि फ्लास्कची वापर केस आणि स्केलेबिलिटीच्या बाबतीत तुलना करा.
Python च्या वेब फ्रेमवर्क्समधील दोन तारे, Django आणि Flask, प्रत्येक डेव्हलपरच्या विविध गरजा पूर्ण करताना चमकदारपणे चमकतात.
मोठ्या प्रमाणावर, डेटाबेस-चालित ऍप्लिकेशन्स तयार करणाऱ्या प्रोग्रामरसाठी, Django हे निवडीचे साधन आहे कारण ते ORM आणि अंगभूत ऍडमिन इंटरफेससह येते.
तथापि, फ्लास्कची साधी आणि मॉड्यूलर रचना विकासकांना त्यांचे स्वतःचे घटक निवडण्याचे स्वातंत्र्य देते, ज्यामुळे ते लहान प्रकल्पांसाठी किंवा परिस्थितींसाठी योग्य पर्याय बनते जेथे हलके, जुळवून घेणारे समाधान आवश्यक आहे.
जेव्हा स्केलेबिलिटीचा विचार केला जातो तेव्हा दोन्ही फ्रेमवर्क मोठ्या मागण्यांसाठी मोजले जाऊ शकतात.
तथापि, फ्लास्कच्या दुबळ्या स्वभावामुळे सानुकूलित स्केलिंग डावपेचांना अनुमती मिळते जी विशिष्ट गरजांनुसार तयार केली जातात, तर जॅंगोच्या अंगभूत क्षमता मोठ्या, अधिक क्लिष्ट प्रकल्पांमध्ये जलद विकासासाठी एक छोटासा फायदा देऊ शकतात.
निष्कर्ष
पायथन स्क्रिप्टिंग मुलाखतींना भाषेच्या क्षमता, गुंतागुंत आणि अनुप्रयोगांचे सखोल ज्ञान आवश्यक आहे.
कसून तयारी केल्याने केवळ तांत्रिक क्षमता मजबूत होत नाही तर आत्मविश्वास देखील वाढतो, अर्जदारांना प्रश्नांच्या कठीण चक्रव्यूहातून जलद आणि अचूकपणे पुढे जाण्यास मदत होते.
इच्छुकांना खात्री करून घेता येईल की ते मुलभूत आणि लागू दोन्ही पायथन समस्या हाताळण्यासाठी तयार आहेत जसे की एकरूपता, OOP तत्त्वे आणि डेटा स्ट्रक्चर्स, तसेच वेब प्रोग्रामिंग आणि डेटा मॅनिप्युलेशन सारख्या व्यावहारिक अनुप्रयोगांमध्ये प्रवेश करून.
परिणामी, यशस्वी होण्यासाठी चांगले गोलाकार शिक्षण आवश्यक बनते आणि अशा परिस्थिती उद्भवू शकतात जिथे एखाद्याची पायथन प्रोग्रामिंग क्षमता उत्कृष्ट आणि सर्जनशील होऊ शकते. पहा हॅशडॉर्कची मुलाखत मालिका मुलाखतीच्या तयारीसाठी मदतीसाठी.





प्रत्युत्तर द्या