Клучна и пожелна задача во компјутерската визија и графиката е да се продуцираат креативни портрети филмови од највисок калибар.
Иако се предложени неколку ефективни модели за тонификација на портретни слики врз основа на моќниот StyleGAN, овие техники ориентирани кон слика имаат јасни недостатоци кога се користат со видеа, како што се фиксната големина на рамката, барањето за усогласување на лицето, отсуството на детали што не се на лицето. , и временска недоследност.
Револуционерната рамка VToonify се користи за справување со тешко контролираниот пренос на видео стил на портрет со висока резолуција.
Ќе ја испитаме најновата студија за VToonify во оваа статија, вклучувајќи ја неговата функционалност, недостатоци и други фактори.
Што е Vtoonify?
Рамката VToonify овозможува приспособлив пренос на видео во стил на портрет со висока резолуција.
VToonify ги користи слоевите со средна и висока резолуција на StyleGAN за да создаде висококвалитетни уметнички портрети засновани на карактеристики на содржина во повеќе размери, преземени од енкодер за задржување на деталите на рамката.
Резултантната целосно конволуционална архитектура зема неусогласени лица во филмовите со променлива големина како влез, што резултира со региони на целото лице со реални движења на излезот.

Оваа рамка е компатибилна со тековните модели за тонификација на слики базирани на StyleGAN, овозможувајќи им да се прошират на видео тонификација и наследуваат атрактивни карактеристики како што се прилагодливи прилагодувања на бојата и интензитетот.
Оваа студија воведува две инстанции на VToonify базирани на Toonify и DualStyleGAN за пренос на видео стил на портрет базиран на колекција и примерок, соодветно.
Опсежните експериментални наоди покажуваат дека предложената рамка VToonify ги надминува постоечките пристапи во правењето висококвалитетни, временски кохерентни уметнички портрети филмови со променливи стилски параметри.
Истражувачите обезбедуваат тетратка Google Colab, за да можете да ги извалкате рацете на неа.
Како работи?
За да се постигне прилагодлив пренос на видео стил на портрет со висока резолуција, VToonify ги комбинира предностите на рамката за преведување слики со рамката базирана на StyleGAN.
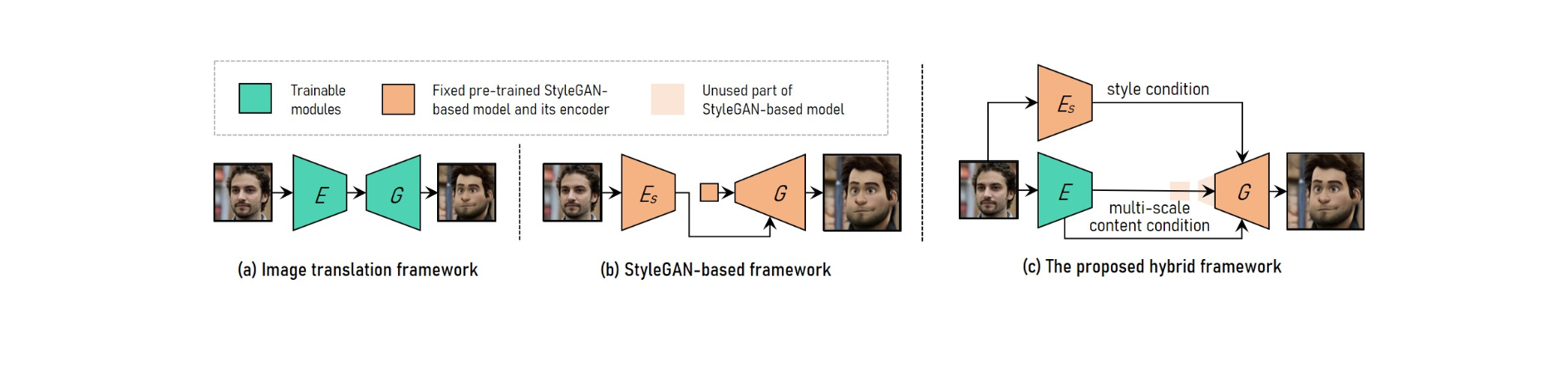
За да се приспособат на различни големини на внесување, системот за преведување слики користи целосно конволуциони мрежи. Тренингот од нула, од друга страна, го прави невозможно преносот со висока резолуција и контролиран стил.
Претходно обучениот StyleGAN модел се користи во рамката заснована на StyleGAN за пренос со висока резолуција и контролиран стил, иако е ограничен на фиксна големина на сликата и загуби на детали.
StyleGAN е изменет во хибридната рамка со бришење на неговата влезна карактеристика со фиксна големина и слоеви со ниска резолуција, што резултира со целосно конволуционална архитектура на енкодер-генератор слична на онаа на рамката за преведување слики.
За да ги одржувате деталите за рамката, обучете го енкодерот да ги извлече карактеристиките на содржината во повеќе размери на влезната рамка како дополнителен услов за содржина на генераторот. Vtoonify ја наследува флексибилноста на стилската контрола на моделот StyleGAN со тоа што го става во генераторот за да ги дестилира податоците и моделот.
Ограничувања на StyleGAN и предложениот Vtoonify
Уметничките портрети се вообичаени во нашиот секојдневен живот, како и во креативните бизниси како што е уметноста, социјални медиуми аватари, филмови, рекламирање за забава и така натаму.
Со развојот на длабоко учење технологија, сега е возможно да се создаваат висококвалитетни уметнички портрети од фотографии од реални лица со користење на автоматизиран пренос на стил на портрет.
Постојат различни успешни начини создадени за пренос на стил базиран на слики, од кои многу се лесно достапни за почетните корисници во форма на мобилни апликации. Видео материјалот брзо стана главен столб на нашите доводи на социјалните мрежи во последните неколку години.
Подемот на социјалните медиуми и ефемерните филмови ја зголемија побарувачката за иновативно видео монтажа, како што е пренос на стил на видео портрет, за да се генерираат успешни и интересни видеа.
Постојните техники ориентирани кон слики имаат значителни недостатоци кога се применуваат на филмови, ограничувајќи ја нивната корисност при автоматизирана стилизација на видео портрет.
StyleGAN е вообичаена основа за развој на модел за пренос во стил на слика на портрет поради неговиот капацитет да создава висококвалитетни лица со прилагодливо управување со стилови.
Систем базиран на StyleGAN (исто така познат како тонификација на слики) шифрира вистинско лице во латентниот простор StyleGAN и потоа го применува добиениот стилски код на друг StyleGAN фино подесен на базата на податоци за уметнички портрети за да создаде стилизирана верзија.
StyleGAN создава слики со подредени лица и со фиксна големина, што не ги фаворизира динамичните лица во реалните снимки. Сечењето на лицето и усогласувањето во видеото понекогаш резултира со делумно лице и непријатни гестови. Истражувачите го нарекуваат ова прашање „ограничување на фиксна култура“ на StyleGAN.
За неусогласени лица, предложен е StyleGAN3; сепак, поддржува само поставена големина на слика.
Понатаму, една неодамнешна студија откри дека кодирањето неусогласени лица е поголем предизвик од порамнетите лица. Неправилното кодирање на лицето е штетно за преносот на стилот на портрет, што резултира со проблеми како што се промена на идентитетот и недостасуваат компоненти во реконструираните и стилизираните рамки.
Како што беше дискутирано, ефикасна техника за пренос на видео стил на портрет мора да се справи со следниве прашања:
- За да се зачуваат реалистични движења, пристапот мора да може да се справи со неусогласени лица и различни големини на видео. Големата големина на видеото или широк агол на гледање може да сними повеќе информации додека лицето не се движи надвор од рамката.
- За да се натпреварува со денешните најчесто користени HD гаџети, неопходно е видео со висока резолуција.
- Треба да се понуди флексибилна контрола на стилот за корисниците да го променат и да го изберат својот избор кога развиваат реален систем за интеракција со корисниците.
За таа цел, истражувачите предлагаат VToonify, нова хибридна рамка за видео тонификација. За да се надмине фиксното ограничување на културите, истражувачите прво ја проучуваат еквиваријантноста на преводот во StyleGAN.
VToonify ги комбинира придобивките од архитектурата базирана на StyleGAN и рамката за преведување на слики за да постигне прилагодлив пренос на видео стил на портрет со висока резолуција.
Следниве се главните придонеси:
- Истражувачите го истражуваат ограничувањето на фиксната култура на StyleGAN и предлагаат решение засновано на еквиваријантност во преводот.
- Истражувачите презентираат уникатна целосно конволуциона VToonify рамка за контролиран пренос на видео стил на портрет со висока резолуција што поддржува неусогласени лица и различни големини на видео.
- Истражувачите го конструираат VToonify на столбовите на Toonify и DualStyleGAN и ги кондензираат столбовите во однос и на податоците и на моделот за да овозможат пренос на видео стил на портрет базиран на колекција и на пример.
Споредување на Vtoonify со други најсовремени модели
Тонизирај
Служи како основа за пренос на стил базиран на колекција на подредени лица со помош на StyleGAN. За да ги вратат стилските кодови, истражувачите мора да ги усогласат лицата и да исечат 256256 фотографии за PSP. Toonify се користи за генерирање стилизиран исход со кодови за стилови 1024*1024.
Конечно, тие повторно го усогласуваат резултатот во видеото на неговата оригинална локација. Нестилизираната област е поставена на црна.

DualStyleGAN
Тоа е основа за трансфер на стил базиран на примери, базиран на StyleGAN. Тие ги користат истите техники пред и пост-обработка на податоци како Toonify.
Pix2pixHD
Тоа е модел на превод од слика во слика кој вообичаено се користи за кондензирање на претходно обучени модели за уредување со висока резолуција. Се тренира со користење на спарени податоци.
Истражувачите користат pix2pixHD како негови дополнителни влезови за мапи на пример, бидејќи користи извлечена карта за парсирање.
Движење од прв ред
FOM е типичен модел за анимација на слики. Обучен е на 256256 слики и слабо функционира со други големини на слики. Како последица на тоа, истражувачите прво ги размеруваат видео кадрите на 256*256 за FOM до анимација, а потоа ја менуваат големината на резултатите до нивната оригинална големина.
За правична споредба, ФОМ ја користи првата стилизирана рамка од својот пристап како референтна слика во стилот.
ДаГАН
Тоа е 3D модел за анимација на лице. Тие ги користат истите методи за подготовка и постобработка на податоци како FOM.

Предности
- Може да се користи во уметноста, аватарите на социјалните мрежи, филмовите, рекламирањето за забава и така натаму.
- Vtoonify може да се користи и во метаверзумот.
Ограничувања
- Оваа методологија ги извлекува и податоците и моделот од столбовите засновани на StyleGAN, што резултира со пристрасност на податоци и модел.
- Артефактите се предизвикани најмногу од разликите во големината помеѓу стилизираниот регион на лицето и другите делови.
- Оваа стратегија е помалку успешна кога се занимаваме со нешта во регионот на лицето.
Заклучок
Конечно, VToonify е рамка за тонификација на видео со висока резолуција контролирана од стил.
Оваа рамка постигнува одлични перформанси во ракувањето со видеата и овозможува широка контрола врз структурниот стил, стилот на бојата и степенот на стил со кондензирање на моделите за тонификација на слики базирани на StyleGAN во однос на нивните синтетички податоци и мрежни структури.





Оставете Одговор