Видео игрите продолжуваат да претставуваат предизвик за милијарди играчи ширум светот. Можеби сè уште не го знаете, но алгоритмите за машинско учење почнаа да се справуваат и со предизвикот.
Во моментов има значителен број на истражувања во областа на вештачката интелигенција за да се види дали методите за машинско учење можат да се применат на видео игрите. Тоа го покажува значителниот напредок на ова поле машинско учење агентите може да се користат за емулирање или дури и замена на човечкиот играч.
Што значи ова за иднината на видео игри?
Дали овие проекти се едноставно за забава или има подлабоки причини зошто толку многу истражувачи се фокусираат на игрите?
Оваа статија накратко ќе ја истражи историјата на вештачката интелигенција во видео игрите. Потоа, ќе ви дадеме брз преглед на некои техники за машинско учење што можеме да ги користиме за да научиме како да ги победиме игрите. Потоа ќе разгледаме некои успешни апликации на нервни мрежи да учат и совладаат специфични видео игри.
Кратка историја на вештачката интелигенција во игри
Пред да навлеземе во тоа зошто нервните мрежи станаа идеален алгоритам за решавање на видео игрите, ајде накратко да погледнеме како компјутерските научници користеле видео игри за да ги унапредат своите истражувања во вештачката интелигенција.
Може да тврдите дека, од своето основање, видео игрите биле жешка област на истражување за истражувачите заинтересирани за вештачка интелигенција.
Иако не е строго видео игра по потекло, шахот беше голем фокус во раните денови на вештачката интелигенција. Во 1951 година, д-р Дитрих Принц напиша програма за играње шах користејќи го дигиталниот компјутер Ferranti Mark 1. Ова беше многу назад во ерата кога овие гломазни компјутери мораа да читаат програми од хартиена лента.

Самата програма не беше целосна шаховска вештачка интелигенција. Поради ограничувањата на компјутерот, Принц можел да создаде само програма која решавала шаховски проблеми мате-во-два. Во просек, на програмата беа потребни 15-20 минути за да се пресмета секој можен потег на бело-црните играчи.
Работата на подобрување на вештачката интелигенција на шахот и дама постојано се подобруваше низ децениите. Напредокот го достигна својот врв во 1997 година кога Deep Blue од IBM го победи рускиот шаховски велемајстор Гари Каспаров во пар од шест натпревари. Во денешно време, шаховските мотори што можете да ги најдете на вашиот мобилен телефон можат да го победат Deep Blue.
Противниците на вештачката интелигенција почнаа да се здобиваат со популарност за време на златното доба на видео аркадните игри. Space Invaders од 1978 година и Pac-Man од 1980-тите се некои од пионерите во индустријата во создавањето вештачка интелигенција што може доволно да ги предизвика дури и најветераните од аркадни гејмери.
Конкретно, Pac-Man беше популарна игра на која истражувачите на вештачката интелигенција можеа да експериментираат. Различни натпревари за г-ѓа Pac-Man се организирани за да се одреди кој тим би можел да ја најде најдобрата ВИ за да ја победи играта.
Вештачката интелигенција на играта и хеуристичките алгоритми продолжија да се развиваат како што се појави потребата за попаметни противници. На пример, борбената вештачка интелигенција се зголеми во популарност бидејќи жанровите како што се стрелците во прво лице станаа поглавни.
Машинско учење во видео игри
Бидејќи техниките за машинско учење брзо се зголемија во популарност, различни истражувачки проекти се обидоа да ги искористат овие нови техники за играње видео игри.
Игри како што се Dota 2, StarCraft и Doom може да делуваат како проблем за нив алгоритми за машинско учење да се реши. Алгоритми за длабоко учење, особено, беа во можност да постигнат, па дури и да ги надминат перформансите на човечко ниво.
на Аркадна средина за учење или ALE им даде на истражувачите интерфејс за повеќе од сто Atari 2600 игри. Платформата со отворен код им овозможи на истражувачите да ги мери перформансите на техниките за машинско учење на класичните видео игри на Atari. Google дури и објави свои хартија користејќи седум игри од ALE

Во меѓувреме, проекти како VizDoom им даде можност на истражувачите на вештачката интелигенција да ги обучуваат алгоритмите за машинско учење за да играат 3D стрелци во прво лице.

Како функционира: Некои клучни концепти
Нервни мрежи
Повеќето пристапи за решавање видео игри со машинско учење вклучуваат тип на алгоритам познат како невронска мрежа.
Невралната мрежа може да ја замислите како програма која се обидува да имитира како може да функционира мозокот. Слично на тоа како нашиот мозок е составен од неврони кои пренесуваат сигнал, нервната мрежа содржи и вештачки неврони.
Овие вештачки неврони, исто така, пренесуваат сигнали еден на друг, при што секој сигнал е вистински број. Невралната мрежа содржи повеќе слоеви помеѓу влезните и излезните слоеви, наречени длабока невронска мрежа.
Засилување на учењето
Друга вообичаена техника за машинско учење релевантна за учење видео игри е идејата за засилено учење.
Оваа техника е процес на обука на агент користејќи награди или казни. Со овој пристап, агентот треба да може да дојде до решение за проблемот преку обиди и грешки.
Да речеме дека сакаме вештачка интелигенција да открие како да ја игра играта Змија. Целта на играта е едноставна: да добиете што е можно повеќе поени со конзумирање на предмети и избегнување на вашата растечка опашка.
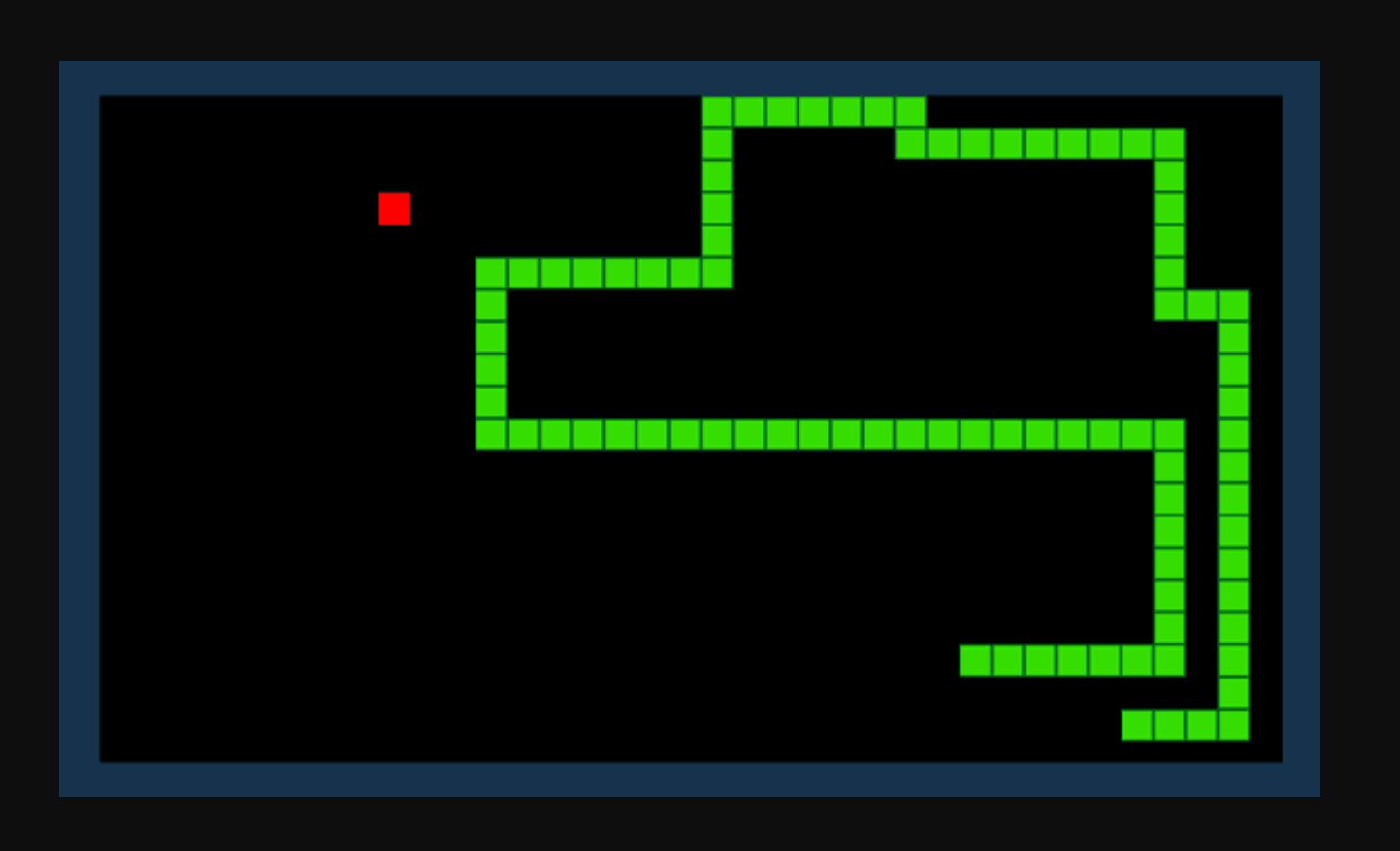
Со засилено учење, можеме да дефинираме функција за наградување R. Функцијата додава поени кога змија троши ставка и одзема поени кога змијата ќе удри во пречка. Со оглед на тековното опкружување и збир на можни дејства, нашиот модел за зајакнување на учење ќе се обиде да ја пресмета оптималната „политика“ што ја максимизира нашата функција за наградување.
Невроеволуција
Со оглед на тоа дека се инспирирани од природата, истражувачите откриле успех и во примената на ML во видео игрите преку техника позната како невроеволуција.
Наместо да користите спуштање на градиент за да ги ажурираме невроните во мрежата, можеме да користиме еволутивни алгоритми за да постигнеме подобри резултати.
Еволутивните алгоритми обично започнуваат со генерирање на почетна популација од случајни поединци. Потоа ги оценуваме овие лица користејќи одредени критериуми. Најдобрите поединци се избираат како „родители“ и се одгледуваат заедно за да формираат нова генерација на поединци. Овие индивидуи потоа ќе ги заменат најмалку погодните поединци во популацијата.
Овие алгоритми, исто така, обично воведуваат некоја форма на операција на мутација за време на чекорот на вкрстување или „размножување“ за одржување на генетската разновидност.
Примерок за истражување за машинско учење во видео игри
OpenAI Five

OpenAI Five е компјутерска програма на OpenAI која има за цел да ја игра DOTA 2, популарна игра за мобилна битка арена (MOBA) со повеќе играчи.
Програмата ги искористи постоечките техники за учење за зајакнување, намалени за учење од милиони слики во секунда. Благодарение на дистрибуираниот систем за обука, OpenAI можеше да игра игри во вредност од 180 години секој ден.
По периодот на обука, OpenAI Five можеше да постигне перформанси на ниво на експерти и да демонстрира соработка со човечки играчи. Во 2019 година, OpenAI Five можеше пораз 99.4% од играчите на јавни натпревари.
Зошто OpenAI се одлучи за оваа игра? Според истражувачите, DOTA 2 имала сложена механика која била надвор од дофатот на постојните длабоки зајакнување на учење алгоритми.
Супер Марио Брос
Друга интересна примена на нервните мрежи во видео игрите е употребата на невроеволуција за играње платформери како што е Super Mario Bros.
На пример, ова влез во хакатон започнува со тоа што нема познавање на играта и полека ја гради основата на она што е потребно за да напредува низ ниво.
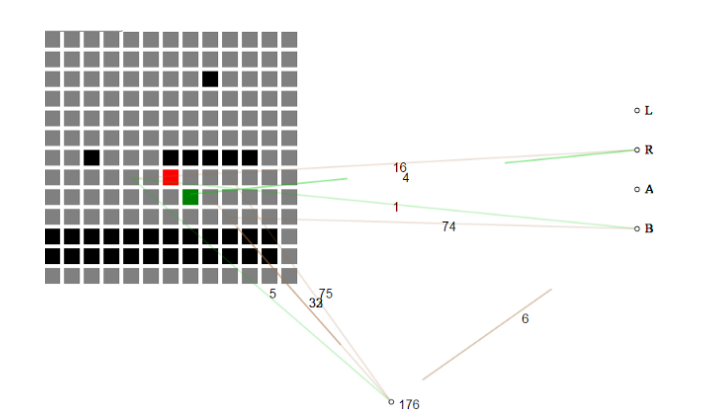
Саморазвивачката нервна мрежа ја прифаќа моменталната состојба на играта како решетка од плочки. Отпрвин, нервната мрежа нема разбирање за тоа што значи секоја плочка, само дека плочките „воздух“ се разликуваат од „земните плочки“ и „непријателските плочки“.
Имплементацијата на невроеволуцијата на проектот хакатон го користеше генетскиот алгоритам NEAT за селективно одгледување на различни нервни мрежи.
Важност
Сега кога видовте неколку примери на невронски мрежи кои играат видео игри, можеби се прашувате која е поентата на сето ова.
Бидејќи видео игрите вклучуваат сложени интеракции помеѓу агентите и нивните опкружувања, тие се совршено полигон за тестирање за создавање вештачка интелигенција. Виртуелните средини се безбедни и контролирани и обезбедуваат бесконечна понуда на податоци.
Истражувањето направено на ова поле им даде на истражувачите увид во тоа како нервните мрежи може да се оптимизираат за да научат како да решаваат проблеми во реалниот свет.
Невронски мрежи се инспирирани од тоа како функционира мозокот во природниот свет. Проучувајќи како вештачките неврони се однесуваат кога учиме како да играме видео игра, може да добиеме и увид во тоа како човечки мозок работи.
Заклучок
Сличностите помеѓу невронските мрежи и мозокот доведоа до сознанија во двете полиња. Континуираното истражување за тоа како нервните мрежи можат да решаваат проблеми еден ден може да доведат до понапредни форми на вештачка интелигенција.
Замислете да користите вештачка интелигенција прилагодена на вашите спецификации што може да игра цела видео игра пред да ја купите за да ве извести дали вреди да одвоите време. Дали компаниите за видео игри би користеле нервни мрежи за да го подобрат дизајнот на играта, нивото на дотерување и тешкотијата на противникот?
Што мислите дека ќе се случи кога нервните мрежи ќе станат врвни гејмери?





Оставете Одговор