Содржина[Крие][Прикажи]
Големите модели од текст во слика направија значителен напредок во развојот на вештачката интелигенција со производство на висококвалитетна и разновидна синтеза на слики од дадена текстуална порака.
Овие модели не се во можност да синтетизираат уникатни претстави на субјекти во различни поставки или да го реплицираат изгледот на предметите во дадено референтно множество.
Новообјавените технологии како OpenAI's DALL.E2 или StabilityAI's Стабилна дифузија и Midjourney веќе го зафаќаат интернетот. Сега е време да се прилагодат резултатите. Сепак како?
Google DreamBooth AI пристигна.
DreamBooth има способност да ја препознае темата на сликата, да ја деконструира од нејзиниот оригинален контекст и потоа прецизно да ја синтетизира во нов посакуван контекст. Дополнително, може да се користи со сегашните генератори на слики со вештачка интелигенција.
Во оваа статија, ќе разгледаме длабоко DreamBooth, неговата употреба, неговото упатство, неговите ограничувања и многу повеќе.
Што е Dreambooth?
штанд за соништа, сосема нов модел на дифузија од текст во слика, беше претставен од Google. Писменото известување може да се користи како упатство од Google DreamBooth AI за генерирање на широк опсег на фотографии од избраниот предмет на корисникот во различни поставки.
Истражувачка група од Универзитетот во Бостон и Google разви DreamBooth, најсовремена техника за менување на моделите од текст во слика кои поминале низ обемна претобука.
Целокупниот концепт е прилично јасен: тие сакаат да го зголемат речникот за јазична визија така што невообичаените идентификатори на токени се поврзуваат со сопствени теми што корисниците можат да ги дефинираат.
Главната цел на моделот е да ги поврзе корисниците со модел на дифузија од текст во слика со тоа што ќе им ги дадат ресурсите што им се потребни за да произведат фотореалистични прикази на примероците од нивната избрана тема.
Како последица на тоа, се чини дека оваа техника добро функционира за сумирање на предизвиците во низа ситуации.
DreamBooth на Google се разликува од претходните алатки за текст во слика, како на пр ДАЛ-Е2, Стабилна дифузија, и Средно патување, со тоа што им дава на корисниците поголема контрола врз сликата на темата пред да им дозволи да манипулираат со моделот на дифузија користејќи внесувања базирани на текст.
Карактеристики
- DreamBooth AI може да го подобри моделот текст-во-слика со 3-5 слики.
- Оригиналните фотореалистични фотографии може да се креираат со DreamBooth AI.
- Покрај тоа, DreamBooth AI може да креира фотографии од тема од повеќе агли.
апликација
Уметнички изведби
Оваа задача конкретно се разликува од трансферот на стилови, што ја задржува семантиката на изворната сцена додека го инкорпорира стилот на друга слика во оригиналната сцена.

Врз основа на креативниот пристап, вештачката интелигенција може да постигне значајни промени на сцената додека ги одржува спецификите за идентификација и пример на тема.
Измена на имот
Карактеристиките на предметниот пример може да се изменат со DreamBooth AI.

Аксесоризација
Силната композиција пред генерацискиот модел е она што ја прави способноста на DreamBooth AI да украсува предмети толку интересна.

Реконтекстуализација
DreamBooth AI може да произведе карактеристични слики за одреден предмет на пример, давајќи му на обучениот модел реченица што ги вклучува единствениот идентификатор и именката од класата.

Може да го генерира предметот во уникатни, досега нечуени пози, артикулации и структура на сцената наместо да ја менува околината. Реални рефлексии и сенки, како и интеракции помеѓу субјектот и околните објекти.
Упатство за Dreambooth
Во овој туторијал, ќе го следиме тетратка Google Collab, и ќе те прошетам низ него, што ќе те натера да го разбереш и да го искористиш самостојно.
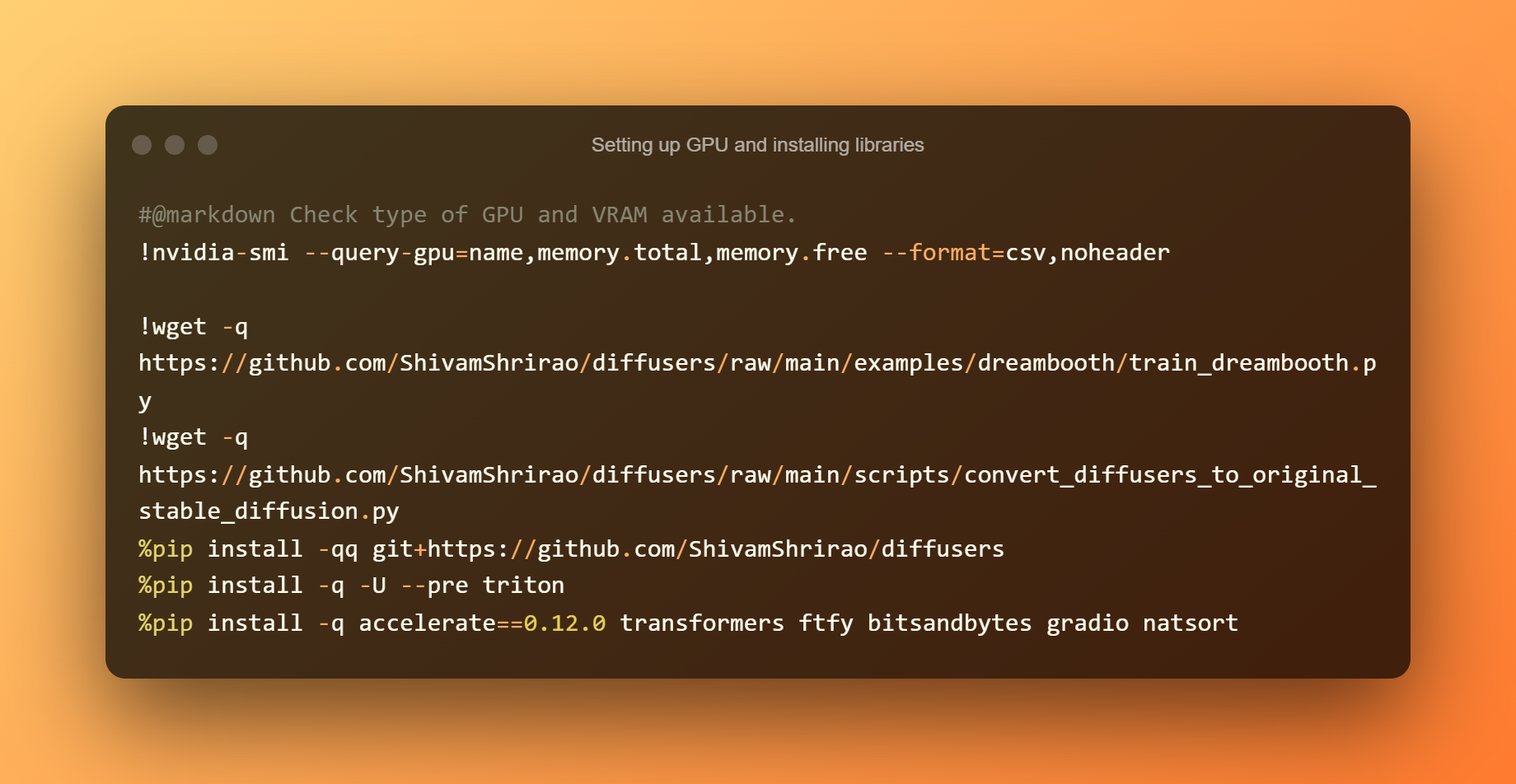
Поставување графички процесор и инсталирање библиотеки
Откривањето на достапните GPU и VRAM видови е првиот чекор. Неопходно е и инсталирање на неколку барања и зависности. Едноставно притиснете го копчето за репродукција, а потоа почекајте да заврши.
Направете сметка на Huggingface и генерирајте токен
Следниот чекор е да се регистрирате за сметка на Huggingface. Кога ќе завршите, кликнете на поставките во горниот десен агол. Ќе пристигнете на следната страница.
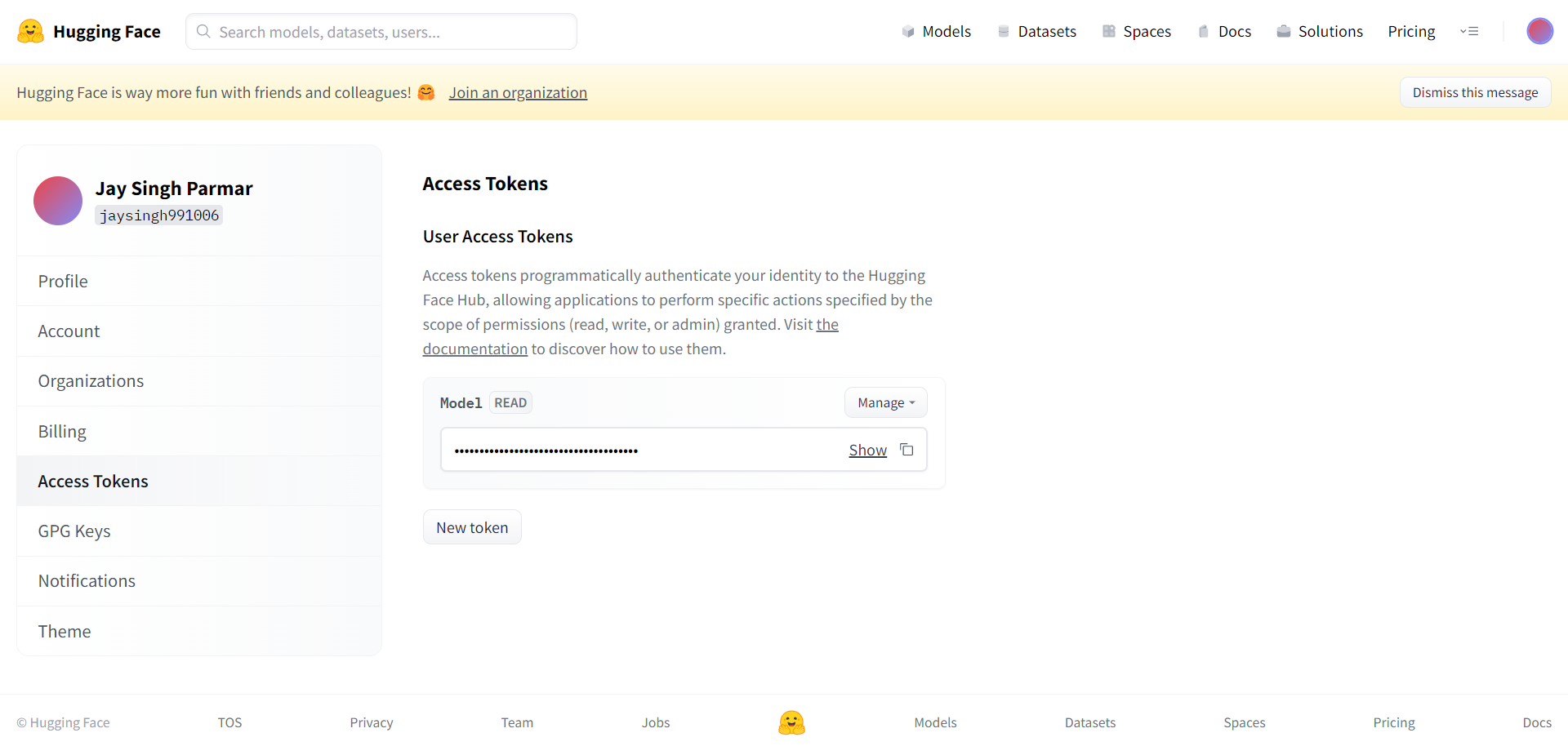
Направете го токенот и името како што се бара од овде. Токенот треба да се копира и залепи во Google collab во ќелијата подолу.

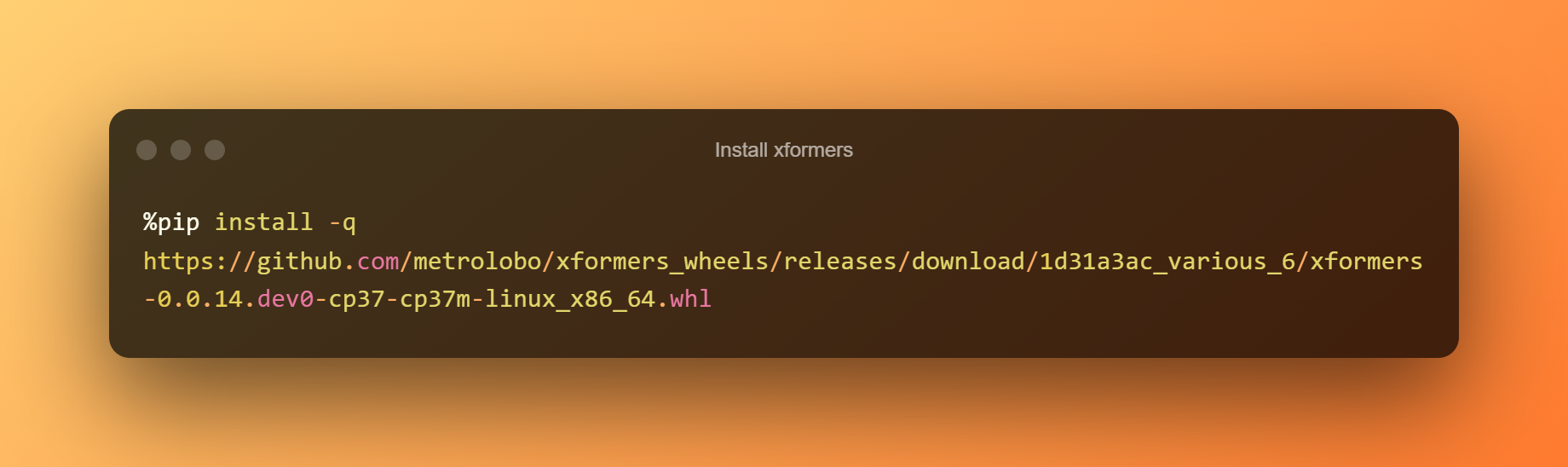
Инсталирајте xformers
Во оваа фаза, можете едноставно да го притиснете копчето за репродукција за да инсталирате xformers со кликнување на времетраењето.
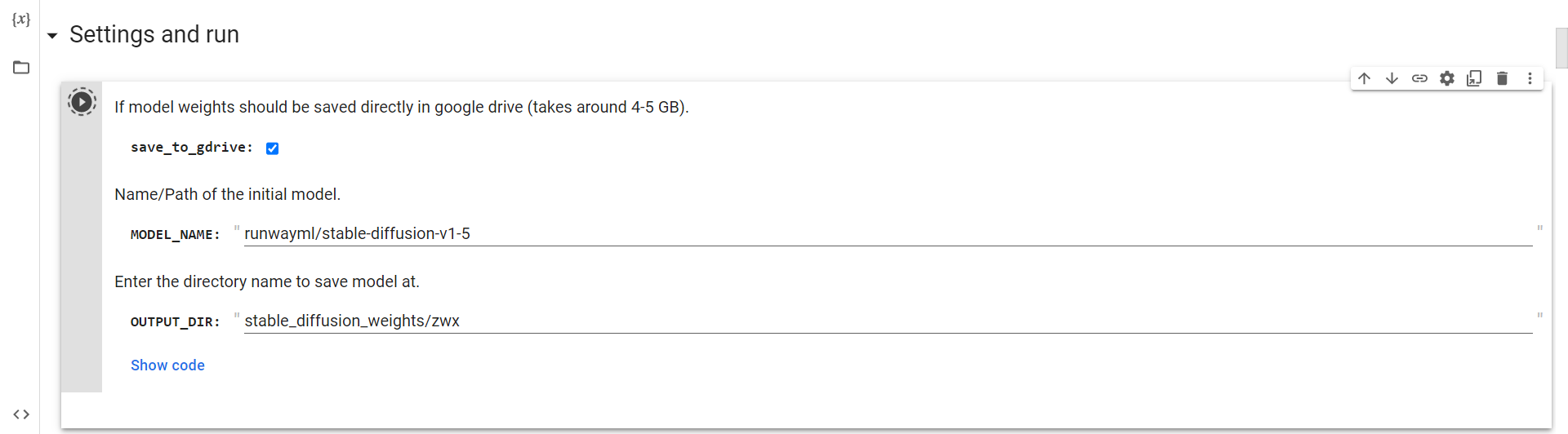
Поврзете се на Drive
Сега, само треба да ја стартувате оваа ќелија за да се поврзете со Google Drive.
Внесете го промптот
Во следната ќелија, само треба да го внесете промптот.
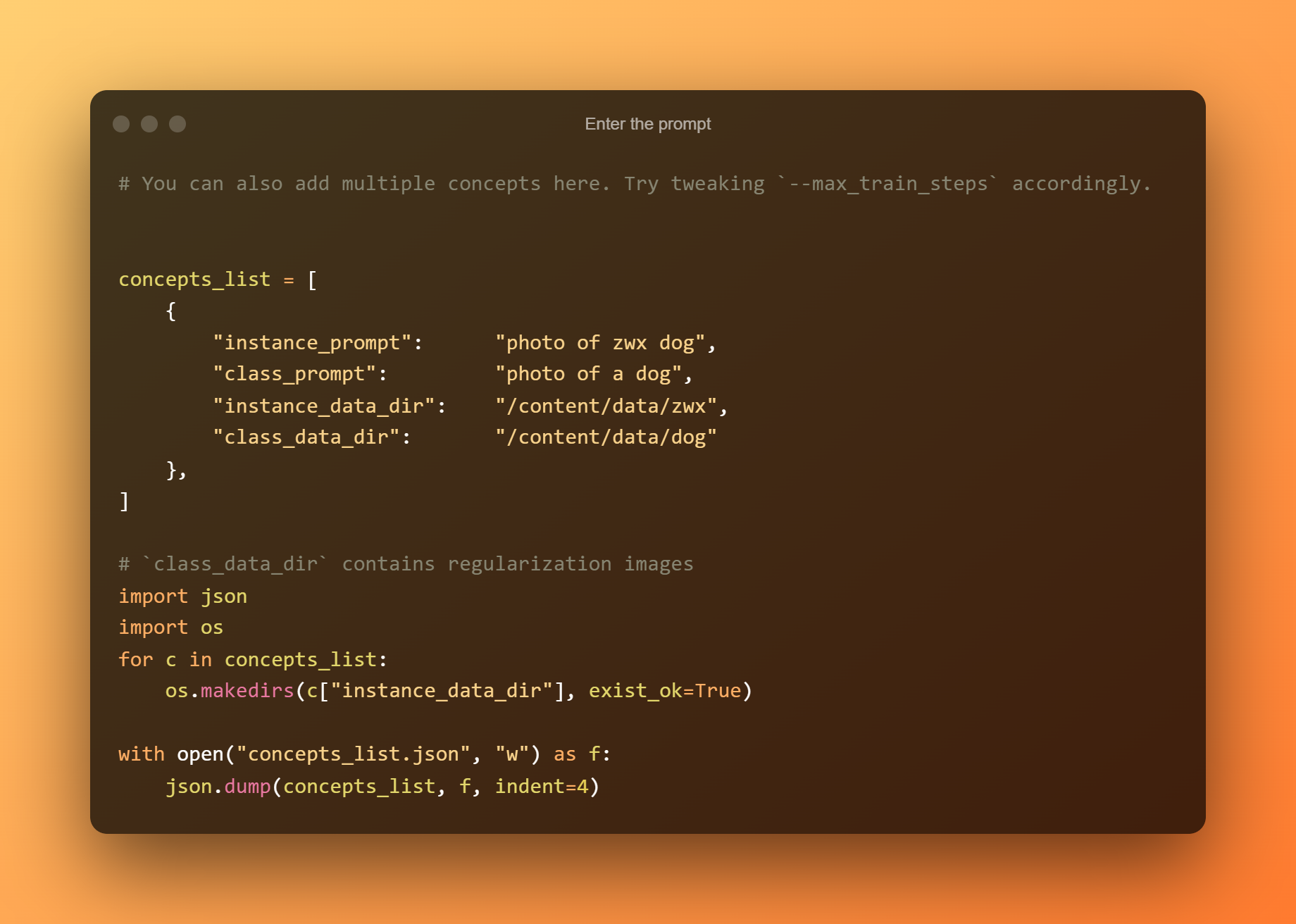
Поставување слики
Во овој чекор, само треба да ги прикачите сликите што сакате да ги обучите.

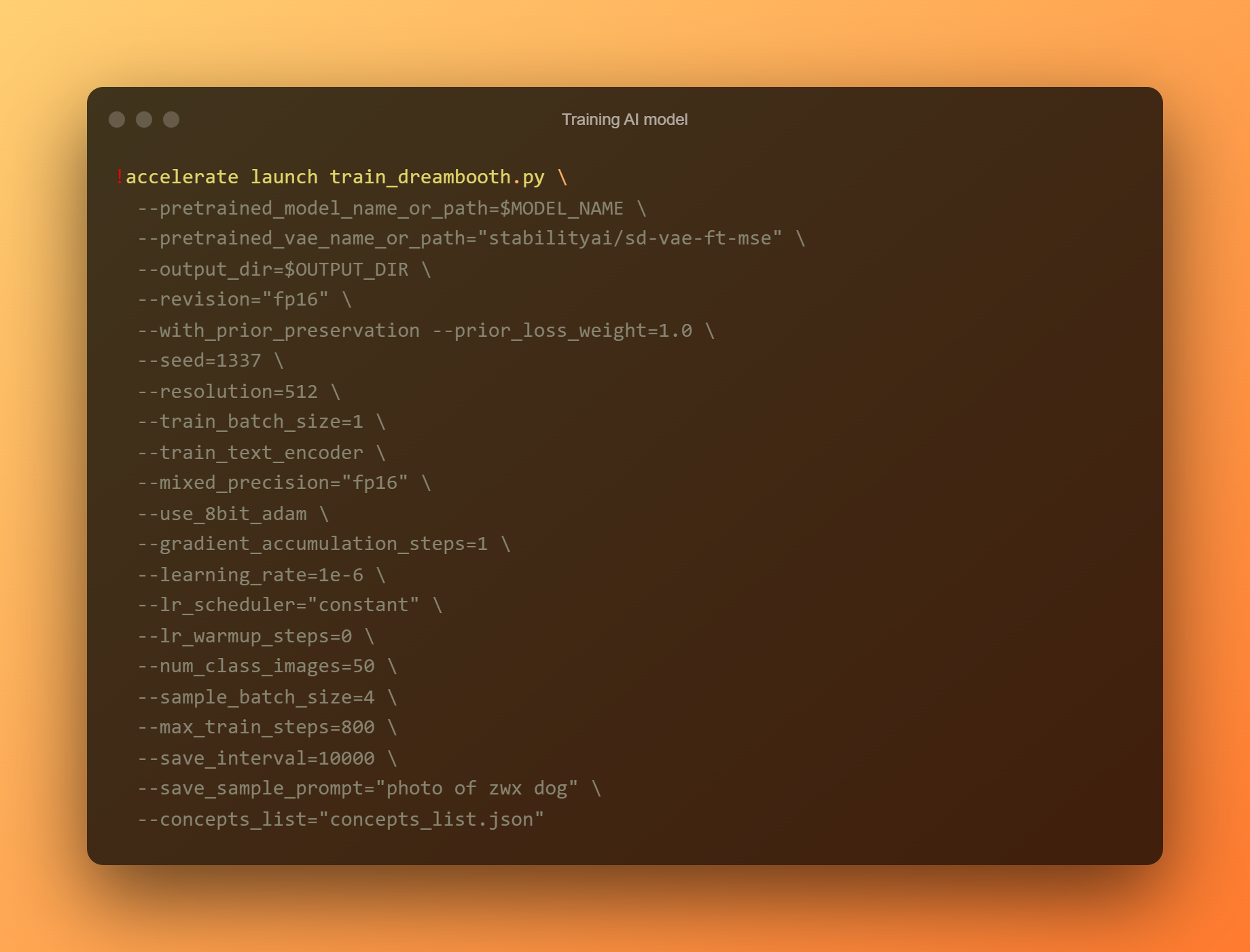
Воз модел на вештачка интелигенција
Ова е најважната фаза, бидејќи ќе го користите DreamBooth за да обучите нов модел со вештачка интелигенција врз основа на сите ваши поднесени референтни фотографии. Мора да го ограничите вашето внимание на две полиња за внесување. „—instance prompt“ е првиот параметар. Мора да наведете многу различно име овде.
Аргументот „–список на концепти“ е второто критично поле за внесување. Мора да се преименува за да одговара на она што се користи во делот „Промени го потсетникот“.
Генерирајте слики со вештачка интелигенција
Сликите со вештачка интелигенција ќе се креираат во оваа фаза, каде што можете да ги внесете текстуалните инструкции.

Ограничувања на Dreambooth
- Командната линија станува пречка за повторување на темата со високи степени на детали. DreamBooth може да го промени контекстот на темата, но ако моделот сака да го промени самиот предмет, има проблеми со рамката.
- Друг проблем е преоптоварувањето на излезната слика на влезната слика. Ако нема доволно доставени слики, предметот може да не се разгледува или да се помеша со контекстот на поднесените слики. Кога се прашува контекст за непарна генерација, се случува истото.
Заклучок
За да се произведат излези од еден внес на текст, најголемиот дел од моделите текст-на-слика бараат милиони параметри и библиотеки.
DreamBooth го поедноставува стекнувањето и користењето содржини за потрошувачите со тоа што бара само внесување од три до пет тематски фотографии заедно со текстуална позадина.





Оставете Одговор