Didėjant duomenų analizės ir duomenų valdymo svarbai įmonėms, šiandienos rinkai būtinas duomenų platformų Snowflake ir Databricks palyginimas.
Organizacijoms reikia mechanizmo, leidžiančio surinkti visus duomenis, kuriuos joms reikia įvertinti, vienoje vietoje, kur jos galėtų būti paruoštos duomenų gavybai, nes tiriamų duomenų kiekis palaipsniui auga.
Be jokios abejonės, pripažintos debesų duomenų sistemos „Snowflake“ ir „Databricks“ yra pramonės lyderės. Tačiau kuri duomenų platforma yra ideali jūsų įmonei?
„Snowflake“ ir „Databricks“ teikia verslo žvalgybos programoms reikalingą kiekį, greitį ir kokybę.
Nors yra skirtumų, yra ir daug paralelių. Jie turi skirtingą orientaciją, kuri yra akivaizdi atidžiai apžiūrėjus.
„Apache Spark“ įkūrėjai įkūrė įmonės programinės įrangos verslą „Databricks“.
Jis garsėja tuo, kad sujungia didžiausius duomenų ežerų aspektus ir duomenų saugyklas į ežero architektūrą.
Duomenų saugyklos verslas „Snowflake“ siūlo debesyje pagrįstas saugojimo ir prieigos paslaugas su minimaliu vargo. Tai patvirtina savo poziciją kaip sprendimą, kuris siūlo saugią prieigą prie jūsų duomenų ir reikalauja beveik mažai priežiūros.
Šiame straipsnyje pateikiamas išsamus „Snowflake Vs“ palyginimas. Duomenų blokai ir paaiškinami kiekvieno produkto pranašumai, kad galėtumėte nuspręsti, kuris jūsų verslui yra geriausias. Pradėkime nuo jų įžangos.
Kas yra Snieguolė?
„Snowflake“ yra visiškai valdoma paslauga, kuri klientams siūlo beveik neribotą lygiagrečių darbo krūvių mastelį, kad būtų galima paprastai integruoti, įkelti, analizuoti ir bendrinti duomenis.
Duomenų ežerai, duomenų inžinerija, duomenų taikomųjų programų kūrimas, duomenų mokslas ir saugus bendrinamų duomenų naudojimas yra keletas tipiškų jo naudojimo būdų.

Skaičiavimas ir saugojimas natūraliai atskirti išskirtiniu „Snowflake“ dizainu.
Naudodami šią architektūrą galite praktiškai suteikti visiems savo vartotojams ir duomenų darbo krūviams prieigą prie vienos duomenų kopijos nepatirdami neigiamo našumo poveikio.
Kad naudotojų patirtis būtų nuosekli, „Snowflake“ suteikia galimybę nepastebimai vykdyti duomenų sprendimą įvairiose vietose ir debesyse.
Panaikinus pagrindinių debesų infrastruktūrų sudėtingumą, „Snowflake“ tai įmanoma.
„Snowflake Data Marketplace“, kuri siūlo daugybę galimybių bendrauti su tūkstančiais „Snowflake“ klientų, taip pat leidžia pasiekti bendrinamus duomenų rinkinius ir duomenų paslaugas.
Savybės
- Veiksmingesnis duomenimis pagrįstas sprendimų priėmimas: Naudodami „Snowflake“ galite pašalinti duomenų kaupiklius ir suteikti visiems verslo atstovams prieigą prie naudingų įžvalgų. Tai yra esminis pradinis žingsnis stiprinant partnerių santykius, optimizuojant kainodarą, mažinant su veikla susijusias išlaidas, didinant pardavimo efektyvumą ir daug kitų dalykų.
- Pagerinkite „Analytics“ greitį ir kokybę: galite sustiprinti analizės dujotiekį naudodami „Snowflake“, perjungdami nuo naktinių paketų įkėlimų prie duomenų srautų realiuoju laiku. Suteikdami visiems savo verslo darbuotojams saugią, lygiagrečią ir kontroliuojamą prieigą prie jūsų duomenų saugyklos, galite pagerinti darbo analizės kokybę. Tai sumažina išlaidas ir rankų darbą, todėl įmonės gali optimaliai paskirstyti išteklius, kad padidintų pajamas.
- Keitimasis duomenimis su pritaikymu: Galite sukurti savo duomenų mainus su Snowflake, kad galėtumėte saugiai perduoti tiesioginius, reguliuojamus duomenis. Be to, tai yra motyvacija plėtoti stipresnius duomenų ryšius su partneriais, klientais ir kitais verslo padaliniais. Tai pasiekiama gaudama 360 laipsnių jūsų vartotojo perspektyvą, kurioje pateikiama informacija apie svarbias kliento savybes, įskaitant interesus, profesiją ir daug daugiau.
- Didesnė gaminio ir naudotojų patirtis: Galite geriau suprasti naudotojo elgesį ir produkto naudojimą, kai įdiegta „Snowflake“. Be to, galite naudoti visą duomenų rinkinį, kad patenkintumėte klientų poreikius, gerokai patobulintumėte savo produktų liniją ir skatintumėte duomenų mokslo naujoves.
- Stiprus saugumas: Visi atitikties ir kibernetinio saugumo duomenys gali būti centralizuoti saugiame duomenų ežere. Greitą incidentų reakciją garantuoja snaigių duomenų ežerai. Sujungus didžiulius žurnalų duomenų kiekius vienoje vietoje ir greitai įvertinus metų žurnalo duomenis, galite susidaryti visą įvykio vaizdą. Pusiau struktūrizuoti žurnalai ir struktūrizuoti įmonės duomenys dabar gali būti sujungti į vieną duomenų ežerą. Be jokio indeksavimo, „Snowflake“ leidžia įkišti koją į duris, o importuotus duomenis lengva redaguoti ir keisti.
Kas yra Duomenų plytos?
Databricks yra debesies pagrindu sukurta duomenų platforma, kurią valdo Apache Spark. Jame daugiausia dėmesio skiriama didelių duomenų analizei ir bendradarbiavimui.
Galite pateikti visą duomenų mokslo darbo sritį Verslo analitikai, duomenų mokslininkai ir duomenų inžinieriai sąveikauja naudodami „Databricks“ mašininio mokymosi vykdymo laiką, valdomą ML srautą ir bendradarbiavimo bloknotus.

Duomenų rėmeliai ir Spark SQL bibliotekos, leidžiančios tvarkyti struktūrinius duomenis, yra saugomos Databricks.
Be to, kad padeda kurti Dirbtinis intelektas sprendimus, Databricks leidžia lengvai padaryti išvadas iš dabartinių duomenų.
Be to, Databricks siūlo įvairias bibliotekas mašininis mokymasis, įskaitant Tensorflow, Pytorch ir kitus, skirtus mašininio mokymosi modeliams kurti ir mokyti.
Įvairūs verslo klientai naudoja Databricks, kad vykdytų didžiulius gamybos procesus įvairiuose naudojimo atvejuose ir sektoriuose, įskaitant sveikatos priežiūrą, žiniasklaidą ir pramogas, finansines paslaugas, mažmeninę prekybą ir dar daugiau.
Savybės
- Delta ežeras: Databricks turi operacijų saugojimo sluoksnį, kuris yra atvirojo kodo ir sukurtas naudoti per visą duomenų gyvavimo ciklą. Šis sluoksnis gali būti naudojamas siekiant užtikrinti duomenų mastelį ir patikimumą jūsų dabartiniam duomenų ežerui.
- Interaktyvūs užrašų knygelės: galite greitai pasiekti savo duomenis, juos analizuoti, kurti modelius su kitais ir dalytis naujomis naudingomis įžvalgomis, kai turite tinkamus įrankius ir kalbą. Scala, R, SQL ir Python yra tik keletas kalbų, kurias palaiko Databricks.
- Mašininis mokymasis: Naudodama pažangiausias sistemas, tokias kaip „Tensorflow“, „Scikit-Learn“ ir „Pytorch“, „Databricks“ suteikia prieigą prie iš anksto sukonfigūruotų mašininio mokymosi aplinkų vienu spustelėjimu. Galite bendrinti ir stebėti eksperimentus, kartu tvarkyti modelius ir kartoti vykdymus vienoje centrinėje saugykloje.
- Patobulintas Spark Engine: Naujausias „Apache Spark“ versijas galite gauti naudodami „Databricks“. Įvairios atvirojo kodo bibliotekos taip pat gali būti sklandžiai integruotos su Databricks. Galite greitai nustatyti grupes ir sukurti visiškai valdomą Apache Spark aplinką, jei turite prieigą prie kelių debesies paslaugų teikėjų pasiekiamumo ir mastelio. Klasteriai gali būti konfigūruojami, nustatomi ir tiksliai suderinami naudojant „Databricks“, nereikalaujant nuolatinio stebėjimo, kad būtų išlaikytas optimalus našumas ir patikimumas.
Pagrindiniai skirtumai tarp Snowflake ir Databricks
architektūra
„Snowflake“ yra ANSI SQL pagrįsta sistema be serverio, turinti visiškai skirtingus saugojimo ir skaičiavimo apdorojimo sluoksnius.
Kiekvienas virtualus sandėlis (ty skaičiavimo klasteris) „Snowflake“ saugo viso duomenų rinkinio poaibį vietoje, o užklausoms atlikti naudoja masiškai lygiagretų apdorojimą (MPP).
Vidiniam duomenų tvarkymui ir optimizavimui į suglaudintą stulpelių formatą, kuris gali būti saugomas debesyje, Snowflake naudoja mikro skaidinius.
Tai, kad „Snowflake“ palaiko visus duomenų valdymo aspektus, įskaitant failo dydį, glaudinimą, struktūrą, metaduomenis, statistiką ir kitus duomenų elementus, kurie nėra iš karto matomi vartotojams ir kuriuos galima pasiekti tik naudojant SQL užklausas, leidžia visa tai padaryti. automatiškai.
Virtualūs sandėliai, kurie yra skaičiuojami klasteriai, sudaryti iš daugelio MPP mazgų, naudojami visam apdorojimui „Snowflake“ atlikti.
„Snowflake“ ir „Databricks“ yra „SaaS“ sprendimai, tačiau „Databricks“ architektūra labai skiriasi, nes ji sukurta „Spark“.
Daugiakalbis variklis, vadinamas Spark, gali būti įdiegtas debesyje ir yra pagrįstas atskirais mazgais arba klasteriais. Šiuo metu „Databricks“ naudoja AWS, GCP ir „Azure“, kaip ir „Snowflake“.
Valdymo plokštuma ir duomenų plokštuma sudaro jos struktūrą. Visi apdoroti duomenys yra duomenų plokštumoje, o visos užpakalinės paslaugos, valdomos Databricks Serverless kompiuterijos, yra valdymo plokštumoje.
Kompiuterija be serverio leidžia administratoriams sukurti be serverio SQL galinius taškus, kuriuos visiškai valdo Databricks ir kurie siūlo tiesioginį skaičiavimą.
Nors daugumos kitų Databricks skaičiavimų skaičiavimo ištekliai bendrinami debesies paskyroje arba tradicinėje duomenų plokštumoje, šie ištekliai bendrinami duomenų plokštumoje be serverio.
Databricks architektūra susideda iš kelių svarbių dalių:
- Databricks Delta ežeras
- Databricks Delta variklis
- MLFlow
Duomenų struktūra
Tiek pusiau struktūrinius, tiek struktūrinius failus galima išsaugoti ir įkelti naudojant „Snowflake“, nereikalaujant ETL įrankio, kad būtų galima sutvarkyti duomenis prieš importuojant juos į EDW.
Pateikus duomenis „Snowflake“ akimirksniu konvertuoja duomenis į savo vidinį, organizuotą formatą. Priešingai nei duomenų ežere, Snowflake nereikia pateikti struktūros nestruktūriniams duomenims, kad galėtumėte juos įkelti ir su jais sąveikauti.
Visi duomenų tipai gali būti naudojami su Databricks pradiniu formatu. Norėdami sukurti nestruktūruotą duomenų struktūrą, kad ją galėtų naudoti kiti įrankiai, pvz., „Snowflake“, netgi galite naudoti Databricks kaip ETL įrankį..
„Databricks“ ir „Snowflake“ diskusijose „Databricks“ viršija „Snowflake“ pagal duomenų struktūrą.
Duomenų nuosavybės teisė
Apdorojimo ir saugojimo sluoksniai yra atskirti Snowflake, todėl jie gali augti savarankiškai debesyje. Tai rodo, kad jie visi gali savarankiškai keisti mastelį debesyje pagal jūsų poreikius.
Tai turės naudos jūsų finansams. Be to, išlaikoma abiejų sluoksnių nuosavybės teisė. „Snowflake“ užtikrina prieigą prie duomenų ir mašinos išteklių naudodama vaidmenimis pagrįstą prieigos kontrolės (RBAC) techniką.
„Databricks“ duomenų apdorojimo ir saugojimo sluoksniai yra visiškai atsieti, priešingai nei „Snowflake“ atsieti sluoksniai.
Vartotojai gali įdėti savo duomenis bet kur ir bet kokiu formatu, o Databricks juos tvarkys efektyviai, nes pagrindinis jos tikslas yra duomenų taikymas.
„Databricks“ yra aiškus „Databricks“ ir „Snowflake“ diskusijų nugalėtojas, nes galite tiesiog jį naudoti duomenims apdoroti.
Duomenų apsauga
Kelionės laiku ir saugus nuo nesėkmių yra dvi ypatingos „Snowflake“ savybės. „Snowflake“ kelionės laiku funkcija saugo duomenis prieš atnaujinant.
Nors įmonės klientai gali pasirinkti iki 90 dienų laikotarpį, kelionės laiku dažnai apsiriboja viena diena. Duomenų bazės, schemos ir lentelės gali naudoti šią galimybę.
Pasibaigus kelionės laiku saugojimo terminui, prasideda 7 dienų saugaus gedimo laikotarpis, skirtas ankstesniems duomenims apsaugoti ir atkurti.
Duomenų blokai Panašiai kaip veikia „Snowflake“ kelionių laiku funkcija, „Delta Lake“ taip pat veikia. Delta Lake saugomi duomenys yra automatiškai versijuojami, todėl vartotojai gali gauti ankstesnes duomenų versijas, kad būtų galima naudoti ateityje.
„Databricks“ veikia „Spark“, o kadangi „Spark“ yra sukurta objekto lygio saugykloje, „Databricks“ niekada nesaugo jokių duomenų.
Tai vienas iš pagrindinių jos privalumų. Tai taip pat reiškia, kad Databricks gali tvarkyti vietinių sistemų naudojimo atvejus.
saugumas
Visi duomenys ramybės būsenoje automatiškai užšifruojami „Snowflake“.
Visi ryšiai tarp valdymo plokštumos ir duomenų plokštumos vyksta privačiame debesų paslaugų teikėjo tinkle, o visi duomenys, išsaugoti Databricks, yra apsaugoti.
Abi parinktys siūlo RBAC (vaidmenimis pagrįstą prieigos kontrolę). Snowflake ir Databricks laikosi kelių įstatymų ir sertifikatų, įskaitant SOC 2 Type II, ISO 27001, HIPAA ir GDPR.
Tačiau, kadangi Databricks veikia virš objekto lygio saugyklos, tokios kaip AWS S3, Azure Blob Storage, "Google Cloud Sandėliavimas ir pan., priešingai nei Snowflake, jai trūksta saugojimo sluoksnio.
spektaklis
Kalbant apie našumą, „Snowflake“ ir „Databricks“ yra tokie radikaliai skirtingi sprendimai, kad juos palyginti yra gana sudėtinga.
Kiekvieną etaloną galima modifikuoti, kad būtų pateikta šiek tiek kitokia istorija. Puikus to pavyzdys yra Neseniai atliktas tyrimas atliko Databricks apie TPC-DS etaloną.
Kalbant apie tiesioginį palyginimą, „Snowflake“ ir „Databricks“ palaiko šiek tiek skirtingus naudojimo atvejus, ir nė vienas iš jų nėra pranašesnis už kitą.
Tačiau snaigė gali būti tinkamiausia interaktyvių užklausų parinktis, nes ji optimizuoja visą saugyklą, kad būtų galima pasiekti duomenis.
Naudokite atvejį
BI ir SQL naudojimo atvejus gerai palaiko Databricks ir Snowflake.
„Snowflake“ teikia JDBC ir ODBC tvarkykles, kurias paprasta integruoti su kita programine įranga.
Atsižvelgiant į tai, kad klientams nereikia administruoti programos, ji dažniausiai garsėja BI naudojimo atvejais ir įmonėms, kurios renkasi paprastą analitinę platformą.
Tuo tarpu „Databricks“ išleistas atvirojo kodo „Delta Lake“ prideda papildomą stabilumo sluoksnį „Data Lake“. Klientai gali siųsti SQL užklausas į Delta Lake su puikiu našumu.
Atsižvelgiant į jų įvairovę ir puikią technologiją, „Databricks“ yra gerai žinomas dėl naudojimo atvejų, kurie sumažina pardavėjo blokavimą, yra geriau pritaikyti ML darbo krūviams ir padeda technologijų milžinams.
Kainos
Klientai turi prieigą prie keturių įmonės lygio rodinių naudodami „Snowflake“. Yra keturios galimos versijos: „Standard“, „Enterprise“, „Business Critical“ ir „Virtual Private Snowflake“. Yra visa informacija apie kainas čia.
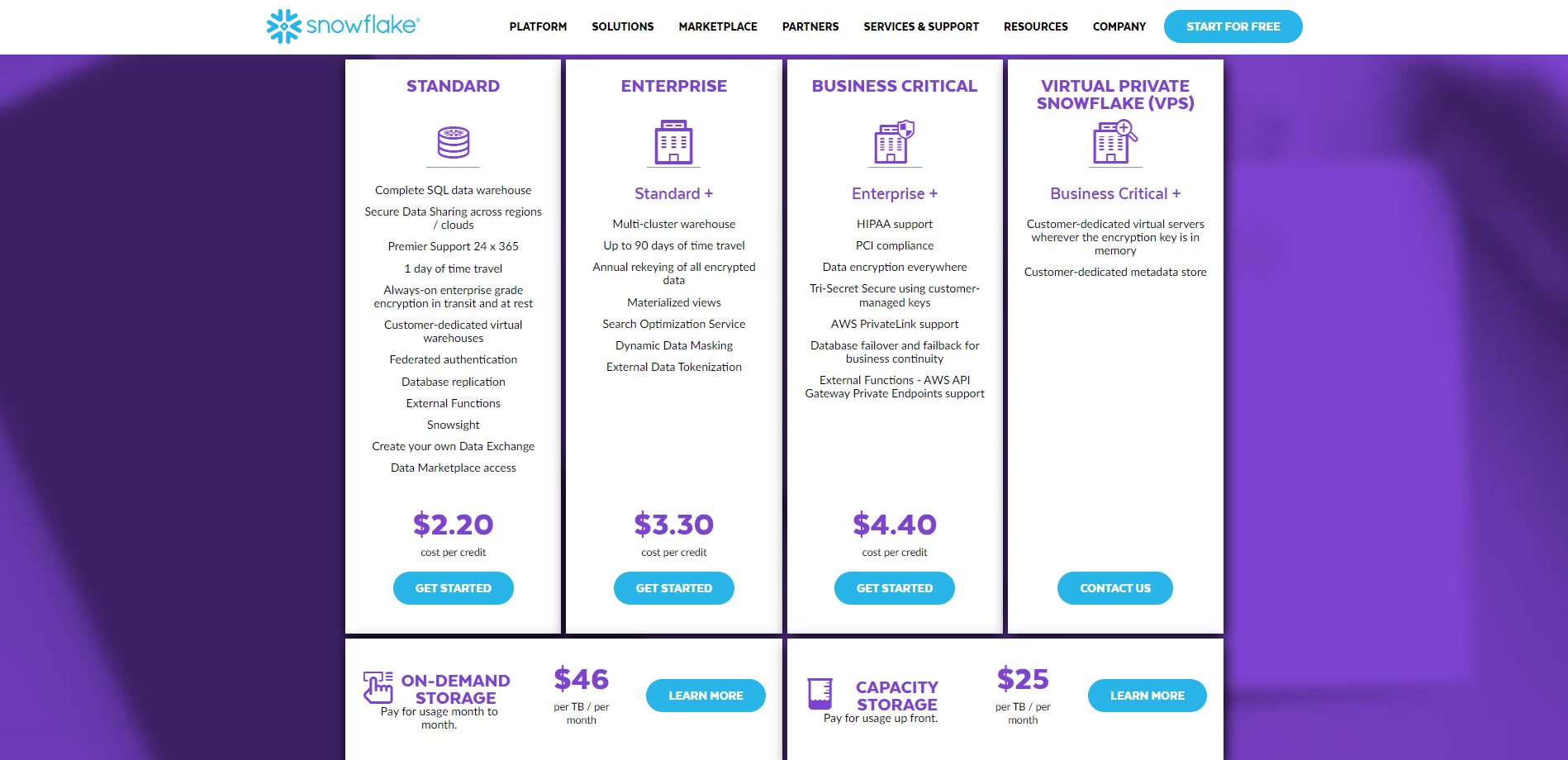
Kita vertus, trys „Databricks“ siūlomos komercinių kainų pakopos yra pagrindinės, aukščiausios kokybės ir įmonės. Galite peržiūrėti visą kainoraštį dešinėje čia.

Išvada
Puikūs duomenų analizės įrankiai yra „Snowflake“ ir „Databricks“.
Kiekvienam yra privalumų ir trūkumų. Naudojimo modeliai, duomenų apimtys, darbo krūviai ir duomenų strategija – visa tai atsiliepia sprendžiant, kuri platforma idealiai tinka jūsų verslui.
„Snowflake“ labiau tinka tiems, kurie yra patyrę su SQL ir įprastai duomenų transformacijai bei analizei.
Srautinio perdavimo, ML, AI ir duomenų mokslo darbo krūviai labiau tinka „Databricks“ dėl „Spark“ variklio, kuris palaiko daugelio kalbų naudojimą.
Siekdama pasivyti kitas kalbas, Snowflake pristatė Python, Java ir Scala palaikymą.
Kai kurie teigia, kad „Snowflake“ sumažina saugojimą priėmimo metu, todėl yra pranašesnis už interaktyvias užklausas.
Be to, jis puikiai tinka kurti ataskaitas ir prietaisų skydelius bei valdyti BI darbo krūvius. Kalbant apie duomenų saugyklą, ji veikia gerai.
Tačiau kai kurie vartotojai pastebėjo, kad jis kenčia nuo didelio duomenų kiekio, pvz., matomo srautinio perdavimo programose. Snaigė triumfuoja tiesioginėse varžybose, paremtose duomenų saugojimo įgūdžiais.
Tačiau Databricks iš tikrųjų nėra duomenų saugykla. Jo duomenų platforma yra išsamesnė ir turi pranašesnes ELT, duomenų mokslo ir mašininio mokymosi galimybes nei Snowflake.
Vartotojai nekontroliuoja valdomų objektų saugojimo, kuriame saugo savo duomenis, išlaidų. Duomenų ežeras ir duomenų apdorojimas yra pagrindinės temos.
Tačiau jis yra specialiai skirtas duomenų mokslininkams ir ypač kvalifikuotiems analitikams.
Apibendrinant, Databricks triumfuoja techninei auditorijai. Tiek techniškai išprusę, tiek netechniškai išmanantys vartotojai gali lengvai panaudoti „Snowflake“.
Beveik visos „Snowflake“ siūlomos duomenų tvarkymo funkcijos pasiekiamos „Databricks“ ir daug daugiau. Tačiau ją valdyti sunkiau, reikia daug mokytis ir ją reikia daugiau prižiūrėti.
Tačiau jis gali apdoroti daug didesnį duomenų darbo krūvių ir kalbų spektrą. O tie, kurie yra susipažinę su Apache Spark, links į Databricks.
„Snowflake“ labiau tinka klientams, norintiems greitai įdiegti gerą duomenų saugyklą ir analizės platformą, neįsigilinant į sąranką, duomenų mokslo detales ar rankinį nustatymą.
Tai taip pat nereiškia, kad Snowflake yra paprastas įrankis ar skirtas naujiems vartotojams. Visai ne.
Tai nėra tokia aukštos klasės kaip Databricks; ši platforma labiau tinka sudėtingoms duomenų inžinerijos, ETL, duomenų mokslo ir srautinio perdavimo programoms.
„Snowflake“ yra analizės duomenų saugykla, kurioje saugomi gamybos duomenys. Be to, tai naudinga asmenims, norintiems pradėti nuo mažo ir palaipsniui augti, taip pat pradedantiesiems.





Palikti atsakymą