Turinys[Slėpti][Rodyti]
Įmonės fiksuoja daugiau duomenų nei bet kada anksčiau, nes vis labiau jais remiasi priimdamos svarbius verslo sprendimus, patobulindamos produktų pasiūlą ir teikdamos geresnį klientų aptarnavimą.
Duomenų kiekis sukuriamas eksponentiniu greičiu, todėl debesyje yra keletas duomenų apdorojimo ir analizės pranašumų, įskaitant mastelio keitimą, patikimumą ir prieinamumą.
Debesų ekosistemoje taip pat yra keletas įrankių ir technologijų duomenų apdorojimui ir analizei. Dviejų tipų didžiųjų duomenų saugojimo struktūros, kurios dažniausiai naudojamos, yra duomenų saugyklos ir duomenų ežerai.
Nors duomenų ežero naudojimas yra mažiau patrauklus, nes negalite pateikti užklausos dėl modelio ir duomenų, kol jie vis dar svarbūs, naudoti duomenų saugyklą srautiniam duomenų saugojimui yra švaistoma.

Wkokį debesų architektūros tipą renkamės?
Ar turėtume apsvarstyti naujesnes duomenų ežero sąvokas, ar turėtume pasitenkinti saugyklos suvaržymais ar ežero apribojimais?
Nauja duomenų saugojimo architektūra, vadinama „duomenų ežerų namais“, sujungia duomenų ežerų pritaikomumą su duomenų saugyklų duomenų valdymu.
Norint sukurti patikimą duomenų saugojimo vamzdyną verslo žvalgybai (BI), duomenų analizei ir mašininis mokymasis (ML) darbo krūviai, atsižvelgiant į jūsų įmonės poreikius.
Šiame įraše atidžiai apžvelgsime „Data Warehouse“, „Data Lake“ ir „Data Lakehouse“ su jų pranašumais, apribojimais, taip pat privalumais ir trūkumais. Pradėkime.
Kas yra duomenų saugykla?
Duomenų saugykla yra centralizuota duomenų saugykla, kurią naudoja organizacija, kad būtų galima laikyti didžiulius duomenų kiekius iš daugelio šaltinių. Duomenų saugykla veikia kaip vienintelis organizacijos „duomenų tiesos“ šaltinis ir yra būtinas ataskaitoms ir verslo analizei.
Paprastai duomenų saugyklos sujungia reliacinius duomenų rinkinius iš kelių šaltinių, pvz., taikomųjų programų, verslo ir operacijų duomenų, kad saugotų istorinius duomenis. Prieš įkeliant į sandėliavimo sistemą, duomenys yra transformuojami ir išvalomi duomenų saugyklose, kad juos būtų galima naudoti kaip vieną duomenų tiesos šaltinį.
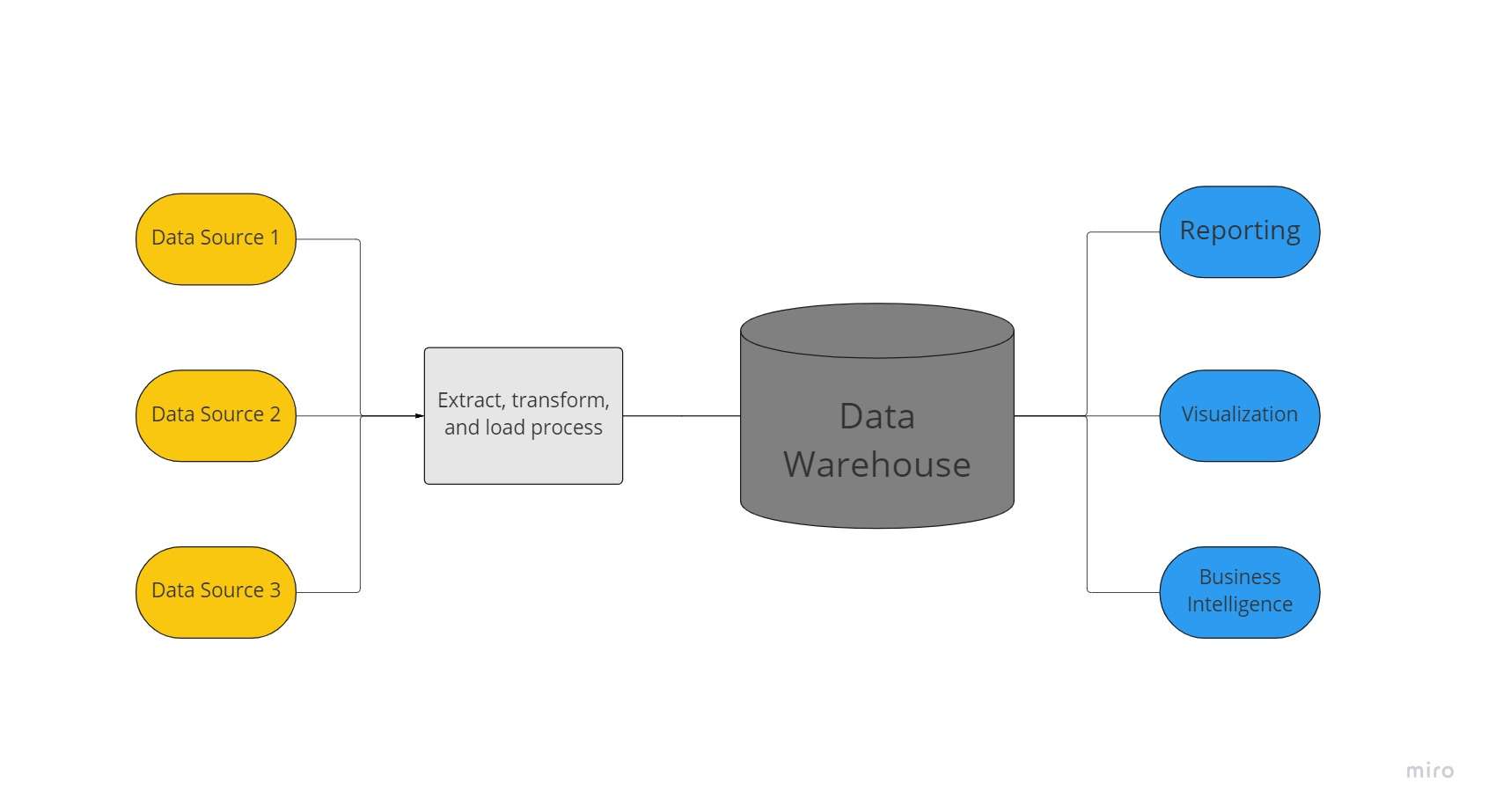
Dėl savo gebėjimo greitai pasiūlyti verslo įžvalgas iš visų įmonės sričių, įmonės investuoja į duomenų saugyklas. Naudojant BI įrankius, SQL klientus ir kitus mažiau sudėtingus (ty ne duomenų mokslo) analizės sprendimus, verslo analitikai, duomenų inžinieriai ir sprendimus priimantys asmenys gali pasiekti duomenis iš duomenų saugyklų.
Brangu išlaikyti sandėlį su vis didėjančiu duomenų kiekiu, o duomenų saugykla negali tvarkyti neapdorotų ar nestruktūruotų duomenų. Be to, tai nėra idealus pasirinkimas sudėtingiems duomenų analizės metodams, pvz., mašininiam mokymuisi ar nuspėjamajam modeliavimui.
Todėl duomenų saugykla suteikia greitesnius atsakymus į užklausas ir aukštesnės kokybės duomenis. „Google Big Query“, „Amazon Redshift“, „Azure SQL Data warehouse“ ir „Snowflake“ yra debesies paslaugos, kurias galima naudoti duomenų saugyklose.
Duomenų saugyklos privalumai
- Verslo žvalgybos ir duomenų analizės darbo krūvių efektyvumo ir greičio didinimas: Duomenų saugyklos sutrumpina duomenų paruošimo ir analizės laiką. Jie gali lengvai susieti su duomenų analizės ir verslo žvalgybos įrankiais, nes duomenys iš duomenų saugyklos yra patikimi ir nuoseklūs. Be to, duomenų saugyklos sutaupo laiko, reikalingo duomenims rinkti, ir suteikia komandoms galimybę naudoti duomenis ataskaitoms, prietaisų skydeliams ir kitiems analizės reikalavimams.
- Duomenų nuoseklumo, kokybės ir standartizavimo didinimas: organizacijos renka duomenis iš įvairių šaltinių, įskaitant naudotojų, pardavimo ir operacijų duomenis. Įmonė gali pasitikėti duomenimis verslo poreikiams tenkinti, nes duomenų saugykla kaupia įmonės duomenis į vienodą standartizuotą formatą, kuris gali veikti kaip vienas duomenų tiesos šaltinis.
- Sprendimų priėmimo gerinimas apskritai: Duomenų saugykla palengvina geresnių sprendimų priėmimą, nes siūlo centralizuotą tiek naujausių, tiek senų duomenų parduotuvę. Apdorojant duomenis duomenų saugyklose, kad gautų tikslias įžvalgas, sprendimus priimantys asmenys gali įvertinti riziką, suprasti klientų norus ir tobulinti prekes bei paslaugas.
- Geresnės verslo informacijos suteikimas: Duomenų saugykla užpildo atotrūkį tarp didžiulių neapdorotų duomenų, kurie dažnai renkami įprastai, ir kuruojamų duomenų, kurie suteikia įžvalgų. Jie veikia kaip organizacijos duomenų saugojimo pagrindas, leidžiantys atsakyti į sudėtingus klausimus apie savo duomenis ir panaudoti atsakymus priimant pagrįstus verslo sprendimus.
Duomenų saugyklos apribojimai
- Duomenų lankstumo trūkumas: Nors duomenų saugyklos puikiai tvarko struktūrinius duomenis, pusiau struktūrizuoti ir nestruktūrizuoti duomenų formatai, pvz., žurnalų analizė, srautinis perdavimas ir socialinės žiniasklaidos duomenys, jiems gali būti sudėtingi. Tai leidžia rekomenduoti duomenų saugyklas naudojimo atvejams, susijusiems su mašininiu mokymusi ir dirbtinis intelektas sunku.
- Brangus įrengimas ir priežiūra: Duomenų saugyklas įrengti ir prižiūrėti gali būti brangu. Be to, duomenų saugykla dažnai nėra statiška; jis sensta ir jį reikia dažnai prižiūrėti, o tai brangu.
Argumentai "už"
- Duomenis lengva rasti, gauti ir pateikti užklausas.
- Kol duomenys jau švarūs, SQL duomenų paruošimas yra paprastas.
Trūkumai
- Esate priversti naudoti tik vieną analizės tiekėją.
- Nestruktūruotų arba tekančių duomenų analizavimas ir saugojimas yra gana brangus.
Kas yra Data Lake?
Duomenų ežerai žada ir įgalina bet kokio tipo duomenis. Naudinga, kad duomenys būtų prieinami centralizuotai ir juos būtų galima skaityti.
Duomenų ežeras yra centralizuota, itin pritaikoma saugykla, kurioje saugomi didžiuliai organizuotų ir nestruktūruotų duomenų kiekiai neapdorotomis, nepakeistomis ir nesuformatuotomis formomis.
Duomenų ežere duomenims saugoti naudojama plokščia architektūra ir objektai, saugomi neapdoroti, o ne duomenų saugyklos, kuriose išsaugomi anksčiau „išvalyti“ reliaciniai duomenys.
Duomenų ežerai, priešingai nei duomenų saugyklos, kurioms sunku tvarkyti tokio formato duomenis, yra pritaikomi, patikimi ir prieinami, todėl įmonėms suteikiama galimybė gauti geresnę įžvalgą iš nestruktūrizuotų duomenų.
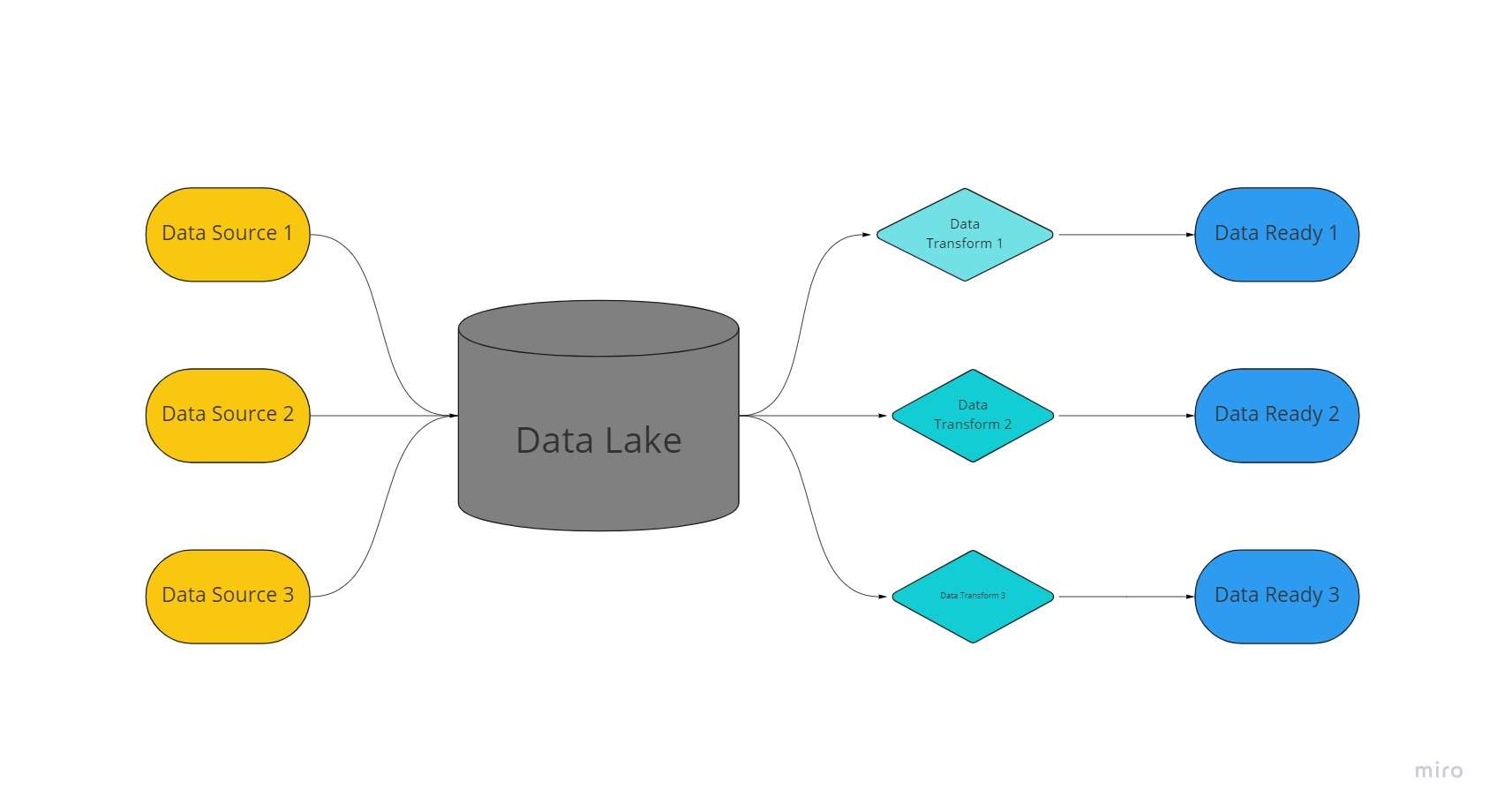
Duomenų ežeruose duomenys išgaunami, įkeliami ir transformuojami (ELT) analitiniais tikslais, o ne duomenų rinkimo metu nustatyti schemą ar duomenis.
Technologijų naudojimas daugeliui duomenų rūšių iš daiktų interneto įrenginių, socialinės žiniasklaidosir srautinio duomenų perdavimo, duomenų ežerai įgalina mašininį mokymąsi ir nuspėjamąją analizę.
Be to, duomenų mokslininkas, galintis apdoroti neapdorotus duomenis, gali naudoti duomenų ežerą. Kita vertus, duomenų saugykla įmonėms lengviau naudotis. Puikiai tinka vartotojų profiliavimui, nuspėjamoji analizė, mašininis mokymasis ir kitos užduotys.
Nors duomenų ežerai sprendžia keletą problemų, susijusių su duomenų saugyklomis, jų duomenų kokybė yra prasta, o užklausos greitis yra nepakankamas. Be to, norint atlikti SQL užklausas, verslo vartotojams reikia papildomų įrankių. Prastai struktūrizuotame duomenų ežere gali kilti problemų dėl duomenų stagnacijos.
„Data Lake“ pranašumai
- Įvairių mašininio mokymosi ir duomenų mokslo taikymo atvejų palaikymas Duomenims tvarkyti duomenų ežeruose yra paprasčiau naudoti skirtingus mašininius ir gilaus mokymosi algoritmus, nes duomenys saugomi atvirai, neapdorotai.
- Duomenų ežerų universalumas, leidžiantis saugoti duomenis bet kokiame formate ar laikmenoje, nereikalaujant iš anksto nustatytos schemos, yra didelis privalumas. Gali būti palaikomi būsimi duomenų naudojimo atvejai ir galima išanalizuoti daugiau duomenų, jei duomenys paliekami pradinėje būsenoje.
- Kad nereikėtų saugoti abiejų tipų duomenų įvairiuose kontekstuose, duomenų rinkiniuose gali būti ir struktūrinių, ir nestruktūruotų duomenų. Įvairių rūšių organizacijos duomenims saugoti jie siūlo vieną vietą.
- Palyginti su tradicinėmis duomenų saugyklomis, duomenų rinkiniai yra pigesni, nes jie sukurti taip, kad juos būtų galima laikyti naudojant nebrangią prekinę aparatinę įrangą, pvz., objektų saugyklą, kuri dažnai yra skirta mažesnei saugomo gigabaito kainai.
„Data Lake“ apribojimai
- Duomenų analizės ir verslo žvalgybos naudojimo atvejų rezultatai yra prasti: duomenų ežerai gali tapti netvarkingi, jei jie nėra tinkamai prižiūrimi, todėl sunku juos susieti su verslo žvalgybos ir analizės įrankiais. Be to, kai reikia ataskaitų teikimo ir analizės naudojimo atvejų, trūksta nuoseklumo duomenų struktūros ir ACID (atomiškumas, nuoseklumas, izoliacija ir ilgaamžiškumas) operacijų palaikymas gali lemti neoptimalų užklausos našumą.
- Dėl duomenų ežerų nenuoseklumo neįmanoma užtikrinti duomenų patikimumo ir saugumo, todėl trūksta abiejų. Gali būti sunku sukurti tinkamus duomenų saugumo ir valdymo standartus, kad būtų patenkinti jautrių duomenų tipai, nes duomenų ežerai gali apdoroti bet kokią duomenų formą.
Argumentai "už"
- Įperkami sprendimai visų tipų duomenims.
- Geba tvarkyti ir organizuotus, ir pusiau struktūrinius duomenis.
- Idealiai tinka sudėtingam duomenų apdorojimui ir srautiniam perdavimui.
Trūkumai
- Reikia nutiesti sudėtingą vamzdyną.
- Duokite duomenims šiek tiek laiko, kad būtų galima užklausti.
- Reikia laiko, kad būtų užtikrintas duomenų patikimumas ir kokybė.
Kas yra Data Lakehouse?
Nauja didelių duomenų saugojimo architektūra, vadinama „duomenų ežerų namais“, sujungia didžiausius duomenų ežerų ir duomenų saugyklų aspektus. Visi jūsų duomenys, nesvarbu, ar jie struktūrizuoti, pusiau struktūrizuoti ar nestruktūrizuoti, gali būti saugomi vienoje vietoje, naudojant geriausias mašininio mokymosi, verslo žvalgybos ir srautinio perdavimo galimybes dėl duomenų ežero.
Visų rūšių duomenų ežerai dažnai yra duomenų ežerų atspirties taškas; po to duomenys transformuojami į Delta Lake formatą (atvirojo kodo saugojimo sluoksnį, kuris užtikrina duomenų ežerų patikimumą).
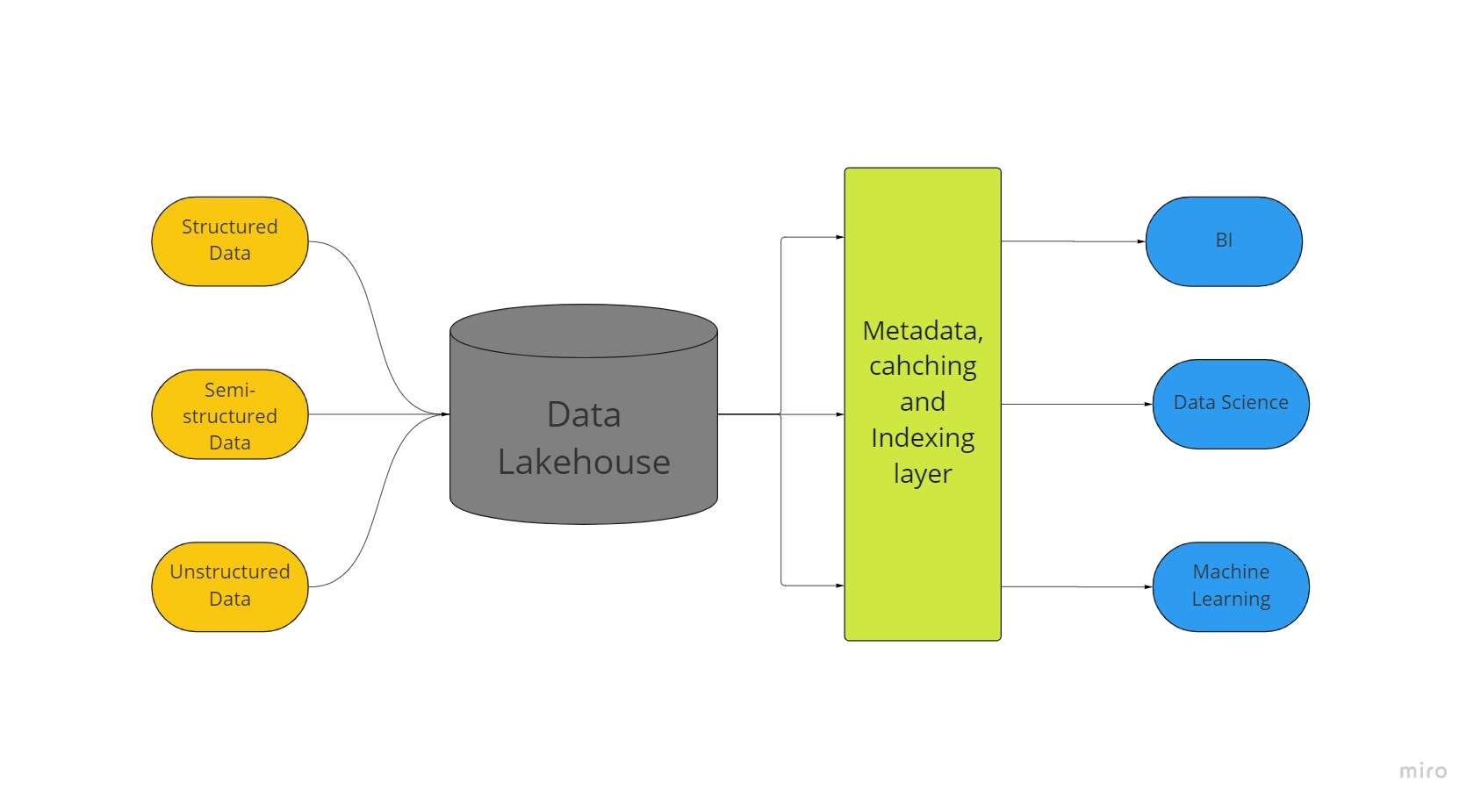
Duomenų ežerai su delta ežerais leidžia atlikti ACID operacijų procedūras iš įprastų duomenų saugyklų. Iš esmės Lakehouse sistema naudoja nebrangią saugyklą, kad išlaikytų didžiulius duomenų kiekius originaliomis formomis, panašiai kaip duomenų ežeruose.
Pridėjus metaduomenų sluoksnį parduotuvės viršuje taip pat suteikiama duomenų struktūra ir suteikiami duomenų valdymo įrankiai, pvz., esantys duomenų saugyklose.
Tai leidžia daugeliui komandų pasiekti visus įmonės duomenis per vieną sistemą įvairioms iniciatyvoms, tokioms kaip duomenų mokslas, mašinų mokymasis ir verslo žvalgyba.
„Data Lakehouse“ pranašumai
- Didesnio darbo krūvio palaikymas: siekiant palengvinti sudėtingą analizę, duomenų bazės suteikia vartotojams tiesioginę prieigą prie kai kurių populiariausių verslo žvalgybos įrankių (Tableau, PowerBI). Be to, duomenų mokslininkai ir mašininio mokymosi inžinieriai gali lengvai naudoti duomenis, nes duomenų bazėse naudojami atvirųjų duomenų formatai (pvz., „Parquet“) kartu su API ir mašininio mokymosi sistemomis, tokiomis kaip Python/R.
- Ekonomiškumas: Data Lakehouses naudoja nebrangius objektų saugojimo sprendimus, kad įgyvendintų rentabilių duomenų ežerų saugojimo charakteristikas. Siūlydami vieną sprendimą, duomenų bazės taip pat sumažina išlaidas ir laiką, susijusį su įvairių duomenų saugojimo sistemų valdymu.
- „Data Lakehouse“ dizainas užtikrina schemų ir duomenų vientisumą, todėl lengviau sukurti veiksmingas duomenų saugos ir valdymo sistemas. Lengvumas duomenų versijų nustatymas, valdymas ir saugumas.
- „Data Lakehouses“ siūlo vieną daugiafunkcę duomenų saugojimo platformą, kuri gali patenkinti visus įmonės duomenų poreikius, o tai sumažina duomenų dubliavimą. Dauguma įmonių renkasi hibridinį sprendimą dėl duomenų saugyklos ir duomenų ežero pranašumų. Tuo tarpu ši strategija gali sukelti brangų duomenų dubliavimą.
- Atvirų formatų palaikymas. Atvirieji formatai yra failų tipai, kuriuos gali naudoti daugelis programinės įrangos ir kurių specifikacijos yra viešai prieinamos. Remiantis ataskaitomis, „Lakehouses“ gali saugoti duomenis įprastais failų formatais, tokiais kaip Apache Parquet ir ORC (Optimized Row Columnar).
„Data Lakehouse“ apribojimai
Didžiausias „Data Lakehouse“ trūkumas yra tai, kad tai vis dar jauna ir besivystanti technologija. Neaišku, ar ji įvykdys savo įsipareigojimus. Kol duomenų bazės galės konkuruoti su nusistovėjusiomis didelių duomenų saugojimo sistemomis, gali praeiti ne vieneri metai.
Tačiau, atsižvelgiant į šiuolaikinių naujovių atsiradimo greitį, sunku pasakyti, ar jos nepakeis kita duomenų saugojimo sistema.
Argumentai "už"
- Vienoje platformoje yra visi duomenys, o tai reiškia, kad reikia mažiau prieglobos pavadinimų.
- Atomiškumas, konsistencija, izoliacija ir kietumas neturi įtakos.
- Tai žymiai pigiau.
- Vienoje platformoje yra visi duomenys, o tai reiškia, kad reikia mažiau prieglobos pavadinimų.
- Paprasta valdyti ir greitai išspręsti visas problemas
- Paprasčiau statyti dujotiekį
Trūkumai
- Sąranka gali užtrukti.
- Ji per jauna ir per toli, kad būtų laikoma nusistovėjusia saugojimo sistema.
Data Warehouse vs Data Lake vs Data Lakehouse
Duomenų saugykla turi ilgą įmonės žvalgybos, ataskaitų teikimo ir analizės programų istoriją ir yra pirmoji didelių duomenų saugojimo technologija.
Kita vertus, duomenų saugyklos yra brangios ir turi problemų tvarkant įvairius ir nestruktūrizuotus duomenis, pvz., srautinius duomenis. Mašininio mokymosi ir duomenų mokslo darbo krūviams buvo sukurti duomenų ežerai, skirti tvarkyti neapdorotus duomenis įvairiomis formomis prieinamoje saugykloje.
Nors duomenų ežerai yra veiksmingi naudojant nestruktūruotus duomenis, jiems trūksta duomenų saugyklų ACID operacijų galimybių, todėl sunku užtikrinti duomenų nuoseklumą ir patikimumą.
Naujausia duomenų saugojimo architektūra, žinoma kaip „duomenų ežerų namai“, sujungia duomenų saugyklų patikimumą ir nuoseklumą su duomenų ežerų prieinamumu ir pritaikomumu.
Išvada
Apibendrinant, gali būti sunku sukurti duomenų ežero namus nuo nulio. Be to, beveik neabejotinai naudosite platformą, skirtą atvirų duomenų ežero architektūrai įgalinti.
Todėl prieš pirkdami atidžiai ištirkite daugybę kiekvienos platformos funkcijų ir įdiegimų. Įmonės, ieškančios brandaus, struktūrizuoto duomenų sprendimo, daugiausia dėmesio skirdamos verslo žvalgybai ir duomenų analizės naudojimo atvejams, gali apsvarstyti galimybę sukurti duomenų saugyklą.
Tačiau įmonės, ieškančios keičiamo dydžio, įperkamo didelių duomenų sprendimo, skirto duomenų mokslo ir mašininio mokymosi, naudojant nestruktūrizuotus duomenis, darbo krūvius, turėtų apsvarstyti duomenų ežerus.
Apsvarstykite, kad jūsų verslui reikia daugiau duomenų, nei gali suteikti duomenų saugykla ir duomenų ežero technologijos, arba kad ieškote sprendimo, kaip integruoti sudėtingas analizės ir mašininio mokymosi operacijas į savo duomenis. A duomenų ežero namas yra protingas pasirinkimas šioje situacijoje.





Palikti atsakymą