ສາລະບານ[ເຊື່ອງ][ສະແດງ]
ອິນເຕີເນັດໄດ້ມີການປ່ຽນແປງອັນໃຫຍ່ຫຼວງນັບຕັ້ງແຕ່ການເລີ່ມຕົ້ນ. ມັນໄດ້ກາຍເປັນອົງປະກອບພື້ນຖານຂອງການເຊື່ອມຕໍ່ຂອງມະນຸດແລະມັນຍັງສືບຕໍ່ພັດທະນາຈາກອິນເຕີເນັດ Relay Chat (IRC) ໄປສູ່ສື່ສັງຄົມທີ່ທັນສະໄຫມ. ມັນ ກຳ ລັງພັດທະນາໄປສູ່ມົນທົນຕົວເມືອງຂອງຊຸມຊົນທົ່ວໂລກໃນອະນາຄົດ.
ເຈົ້າຄົງເຄີຍໄດ້ຍິນປະໂຫຍກທີ່ວ່າ “Web 3.0” ດັງໄປທົ່ວອິນເຕີເນັດ. ທ່ານອາດຈະໄດ້ເຫັນ infographic ທີ່ອະທິບາຍວິທີການເຮັດວຽກຂອງ Web 3.0 ແລະການພັດທະນາທີ່ຫນ້າປະຫລາດໃຈຂອງມັນ. ຢ່າງຫນ້ອຍ, ທ່ານຄວນໄດ້ເຫັນຮູບເງົາສັ້ນທີ່ອະທິບາຍວິທີການ Web 3.0 ຈະປ່ຽນແປງໃບຫນ້າຂອງໂລກຢ່າງຖາວອນ.
ຖ້າທ່ານບໍ່ໄດ້ເຮັດສິ່ງຂ້າງເທິງນີ້ແລະບໍ່ຮູ້ວ່າ Web 3.0 ແມ່ນຫຍັງ, ນີ້ແມ່ນບົດຄວາມສໍາລັບທ່ານ. ກ່ອນທີ່ພວກເຮົາຈະໄປຂ້າງຫນ້າເພື່ອເຂົ້າໄປເບິ່ງສິ່ງທີ່ອະນາຄົດມີຢູ່ໃນຮ້ານຂອງພວກເຮົາ, ໃຫ້ພວກເຮົາເບິ່ງທາງຫລັງຂອງພວກເຮົາກັບຍຸກທໍາອິດຂອງອິນເຕີເນັດ.
ວິວັດທະນາການຂອງເວັບໄຊຕ໌
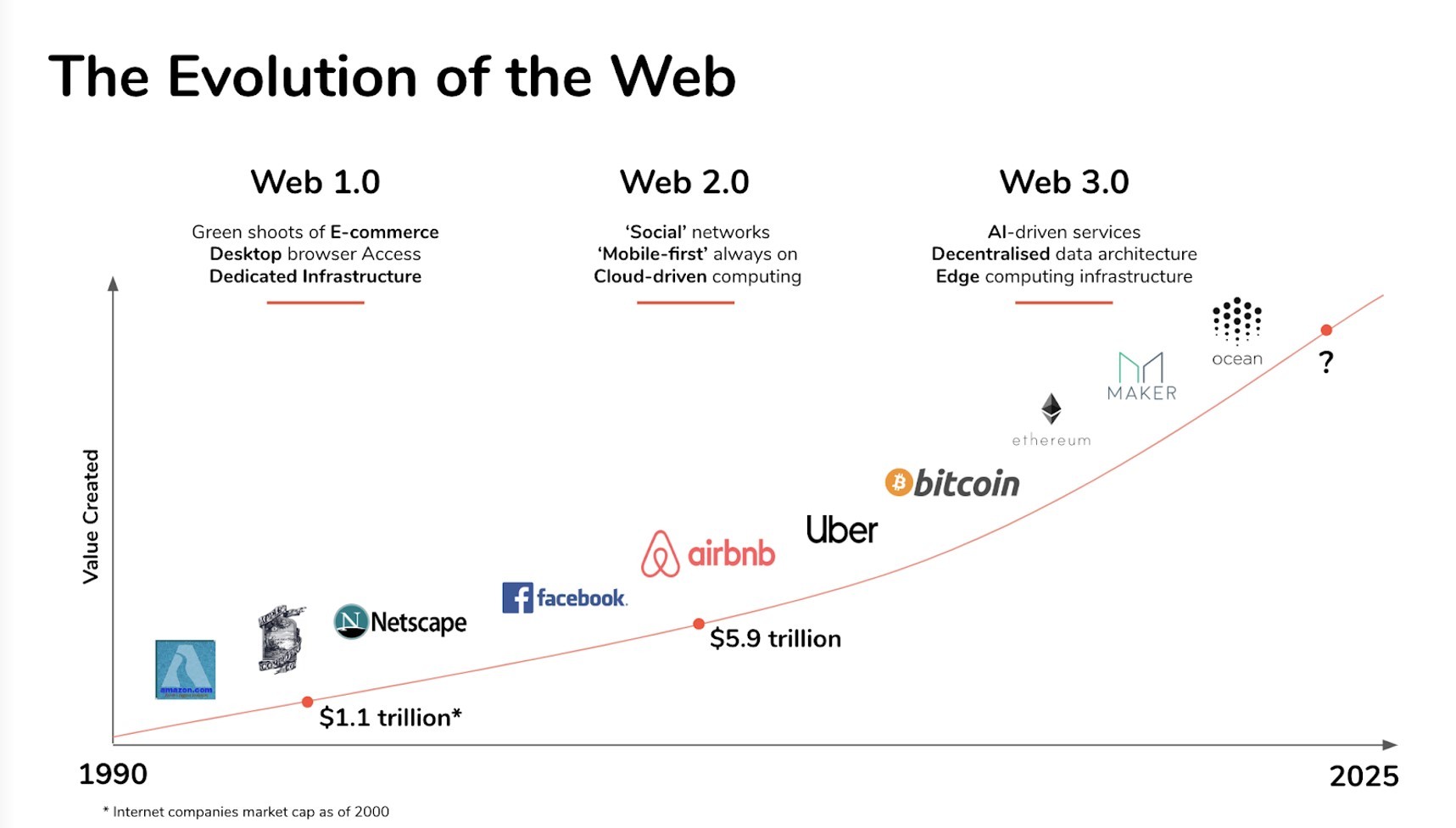
ເວັບໄຊຕ໌ໄດ້ຂະຫຍາຍຕົວຢ່າງຫຼວງຫຼາຍໃນໄລຍະປີ, ແລະຄໍາຮ້ອງສະຫມັກຂອງຕົນໃນມື້ນີ້ແມ່ນເກືອບບໍ່ສາມາດຮັບຮູ້ໄດ້ຈາກມື້ທໍາອິດຂອງຕົນ. ບາງຄັ້ງການວິວັດທະນາການຂອງເວັບແມ່ນແບ່ງອອກເປັນສາມຂັ້ນຕອນຄື: Web 1.0, Web 2.0, ແລະ Web 3.0.
Web 1.0
ມັນເປັນໄປບໍ່ໄດ້ສໍາລັບໄວຫນຸ່ມໃນມື້ນີ້ທີ່ຈະຈິນຕະນາການອິນເຕີເນັດໂດຍບໍ່ມີ Google, Facebook, ຫຼື Instagram Stories. ຢ່າງໃດກໍ່ຕາມ, ມີຍຸກຄລາສສິກຂອງອິນເຕີເນັດທີ່ແລ່ນຈາກກາງຊຸມປີ 1990 ຫາຕົ້ນປີ 2000. Web 1.0 ເປັນ incarnation ເບື້ອງຕົ້ນຂອງອິນເຕີເນັດ. ຜູ້ເຂົ້າຮ່ວມສ່ວນຫຼາຍແມ່ນຜູ້ບໍລິໂພກເນື້ອຫາ, ໃນຂະນະທີ່ຜູ້ສ້າງສ່ວນໃຫຍ່ແມ່ນຜູ້ພັດທະນາທີ່ສ້າງເວັບໄຊທ໌ທີ່ສົ່ງເນື້ອຫາສ່ວນໃຫຍ່ໃນຮູບແບບຂໍ້ຄວາມຫຼືຮູບພາບ.
ແທນທີ່ຈະເປັນ HTML ແບບເຄື່ອນໄຫວ, ເວັບໄຊທ໌ 1.0 ໃຫ້ບໍລິການອຸປະກອນສະຖິດ. ຂໍ້ມູນແລະເນື້ອຫາໄດ້ຖືກສະຫນອງໃຫ້ໂດຍຜ່ານລະບົບໄຟລ໌ຄົງທີ່ແທນທີ່ຈະເປັນຖານຂໍ້ມູນ, ແລະຫນ້າເວັບຂາດການໂຕ້ຕອບ. ແນວຄິດຂອງການຖ່າຍທອດວິດີໂອບໍ່ມີຢູ່. ປະຊາຊົນຈະເຂົ້າໄປໃນຫ້ອງສົນທະນາ AOL ເພື່ອ "ເວົ້າອອນໄລນ໌."
ມັນໃຊ້ເວລາໝົດມື້ເພື່ອດາວໂຫລດເພງດຽວ. ເມື່ອເຊື່ອມຕໍ່ອິນເຕີເນັດຜ່ານທາງໂທ-ອັບ, ເຈົ້າຕ້ອງເອົາໂທລະສັບຕັ້ງໂຕະຂອງເຈົ້າອອກ. ບໍ່, ໂທລະສັບມືຖືບໍ່ມີ. ທ່ານຕ້ອງຕິດຕໍ່ສື່ສານກັບບຸກຄົນໃນບຸກຄົນ, ໂດຍບໍ່ຕ້ອງໃຊ້ emojis. ມັນເປັນຕາຢ້ານ, ຂ້ອຍບອກເຈົ້າ!
Web 2.0
ອິນເຕີເນັດຢູ່ໃນປະຫວັດສາດຂອງຕົນໃນຕົ້ນຊຸມປີ 2000. ມັນອາດຈະຢູ່ໃນຫ້ອງສະໝຸດທາງດຽວ, ຈືດໆ, ຫຼືມັນອາດຈະກາຍເປັນນະວັດຕະກໍາທີ່ມະຫັດສະຈັນທີ່ເຊື່ອມຕໍ່ຄົນຈາກທົ່ວໂລກ. ໂຊກດີ, ມັນເລືອກທາງເລືອກທີສອງ. ທ່ານບໍ່ຈໍາເປັນຕ້ອງເປັນນັກພັດທະນາເພື່ອເຂົ້າຮ່ວມຂະບວນການສ້າງສັນໃນ Web2 ຈັກກະວານ. ຄໍາຮ້ອງສະຫມັກຈໍານວນຫຼາຍໄດ້ຖືກອອກແບບໃນລັກສະນະທີ່ໃຜພຽງແຕ່ອາດຈະກາຍເປັນຜູ້ຜະລິດ.
ກັບການພັດທະນາຂອງ ສື່ມວນຊົນສັງຄົມໃນທີ່ສຸດຜູ້ໃຊ້ສາມາດເພີດເພີນກັບປະສົບການທີ່ເລິກເຊິ່ງຢູ່ໃນ "ສຸດທິ." ດຽວນີ້ທ່ານສາມາດເຜີຍແຜ່ ແລະອອກອາກາດເນື້ອຫາວິດີໂອໄປໃສ່ YouTube ໄດ້, ແລະ Google ກາຍເປັນເວັບໄຊສຳລັບທຸກຢ່າງ. Web2 ແມ່ນງ່າຍດາຍຢ່າງບໍ່ຫນ້າເຊື່ອ, ແລະດ້ວຍເຫດນັ້ນ, ບຸກຄົນຫຼາຍກວ່າແລະຫຼາຍໃນທົ່ວໂລກໄດ້ກາຍເປັນຜູ້ສ້າງ.
Web2 ແມ່ນກ່ຽວກັບການມີສ່ວນຮ່ວມແທນທີ່ຈະເປັນການສັງເກດການ. ໃນກາງຊຸມປີ 2000, ເວັບໄຊທ໌ສ່ວນໃຫຍ່ໄດ້ປ່ຽນໄປເປັນ Web2 (Web 2.0). ການຫຼິ້ນເກມອອນໄລນ໌ເຮັດໃຫ້ການໂຕ້ຕອບຜູ້ຫຼິ້ນຫຼາຍຄົນລະຫວ່າງຜູ້ຫຼິ້ນທົ່ວໂລກ. ທ່ານສາມາດຕິດຕາມທີ່ຮັກຂອງທ່ານໃນເຟສບຸກແລະແບ່ງປັນຮູບພາບທີ່ເຮັດໃຫ້ຫົວຂອງສັດລ້ຽງຂອງທ່ານກ່ຽວກັບ Instagram, ແຕ່ວ່າພຽງແຕ່ຈາກໂທລະສັບສະຫຼາດຂອງທ່ານ.
ດັ່ງນັ້ນ, Web 3.0 ແມ່ນຫຍັງ?
Web 3.0 ແມ່ນໄລຍະຕໍ່ໄປໃນການຂະຫຍາຍຕົວຂອງອິນເຕີເນັດທີ່ເຮັດໃຫ້ແຜ່ນຄວບຄຸມຂອງເວັບກັບຄືນໄປບ່ອນຢູ່ໃນມືຂອງຜູ້ບໍລິໂພກ. ຄວາມແຕກຕ່າງແມ່ນສ້າງຂື້ນໂດຍເຕັກໂນໂລຢີທີ່ພົ້ນເດັ່ນຂື້ນເຊັ່ນ blockchain, ເຊິ່ງເຮັດໃຫ້ອິນເຕີເນັດສາມາດເຮັດວຽກເປັນລະບົບ peer-to-peer (P2P), ລະບົບທີ່ເຊື່ອຖືໄດ້.
ມີຄວາມແຕກຕ່າງທີ່ສໍາຄັນຈໍານວນຫນຶ່ງລະຫວ່າງ web2 ແລະ web3, ແຕ່ການກະຈາຍອໍານາດແມ່ນຢູ່ໃນຫົວໃຈຂອງທັງສອງ. ແອັບພລິເຄຊັນ Web3, ຫຼື Dapps, ແມ່ນສ້າງຂຶ້ນໃນເຄືອຂ່າຍ peer-to-peer ທີ່ມີການແບ່ງຂັ້ນຄຸ້ມຄອງເຊັ່ນ Ethereum ແລະ IPFS. ເຄືອຂ່າຍເຫຼົ່ານີ້ແມ່ນໄດ້ຮັບການສ້າງ, ດໍາເນີນການ, ແລະຮັກສາໂດຍຜູ້ໃຊ້ຂອງເຂົາເຈົ້າແທນທີ່ຈະເປັນບໍລິສັດ. ພວກເຂົາເຈົ້າຈັດຕັ້ງຕົນເອງແລະບໍ່ມີຈຸດດຽວຂອງຄວາມລົ້ມເຫຼວ.
ມັນເປັນຂັ້ນຕອນທີສາມຂອງການເຕີບໂຕຂອງເວັບໄຊຕ໌, ມັກຈະເອີ້ນວ່າຂັ້ນຕອນການອ່ານ - ຂຽນ - ປະຕິບັດ, ແລະມັນກ່ຽວຂ້ອງກັບອະນາຄົດຂອງເວັບ. Artificial Intelligence (AI) ແລະ ການຮຽນຮູ້ເຄື່ອງ (ML) ອະນຸຍາດໃຫ້ຄອມພິວເຕີສາມາດເຂົ້າໃຈຂໍ້ມູນໃນລັກສະນະດຽວກັນກັບທີ່ມະນຸດເຮັດ. ເປົ້າໝາຍຂອງ Web 3.0 ແມ່ນເພື່ອເປີດ ແລະ ກະຈາຍສັນຍານອິນເຕີເນັດ.
ຜູ້ໃຊ້ຕ້ອງອີງໃສ່ເຄືອຂ່າຍແລະໂທລະສັບມືຖືເພື່ອຮັກສາການຕິດຕາມຂອງຂໍ້ມູນທີ່ຜ່ານລະບົບຂອງເຂົາເຈົ້າໃນປັດຈຸບັນ. ດ້ວຍການປະກົດຕົວຂອງເທກໂນໂລຍີບັນຊີລາຍການທີ່ແຈກຢາຍ, ຜູ້ໃຊ້ຈະສາມາດຖອນຄືນການຄວບຄຸມຂໍ້ມູນຂອງພວກເຂົາໃນອະນາຄົດອັນໃກ້ນີ້. ບໍລິສັດຂໍ້ມູນໃຫຍ່ແລະບໍລິສັດທົ່ວໂລກບໍ່ຄວນແບ່ງປັນຂໍ້ມູນສ່ວນຕົວຫຼືມີການຜູກຂາດກ່ຽວກັບອໍານາດແລະຂໍ້ມູນ.
ເປັນຫຍັງພວກເຮົາຕ້ອງການ Web 3.0?
ເມື່ອພວກເຮົາຕິດຕໍ່ສື່ສານຜ່ານອິນເຕີເນັດ, ສຳເນົາຂໍ້ມູນຂອງພວກເຮົາຖືກສ້າງ ແລະເກັບຮັກສາໄວ້ໃນເຊີບເວີຂອງບໍລິສັດເຊັ່ນ Google ຫຼື Facebook, ແລະພວກເຮົາສູນເສຍການຄວບຄຸມຂໍ້ມູນຂອງພວກເຮົາ. ຄວາມຈິງທີ່ວ່າຂໍ້ມູນຂອງພວກເຮົາຖືກຖືໂດຍພາກສ່ວນທີສາມບໍ່ແມ່ນປະກົດຂຶ້ນເປັນສິ່ງລົບ; ຢ່າງໃດກໍຕາມ, ເມື່ອບໍລິສັດດຽວໄກ່ເກ່ຍຂະບວນການທັງຫມົດ, ສິ່ງຕ່າງໆອາດຈະຜິດພາດ.
ພວກເຮົາຕ້ອງການສັງຄົມທີ່ຂໍ້ມູນທີ່ທ່ານສະເຫນີອາດຈະຖືກນໍາໃຊ້ໃນທາງທີ່ຜິດຍ້ອນຄວາມໂລບຫຼືຄວາມຊົ່ວຮ້າຍ? ນີ້ໄປໄດ້ດີນອກເຫນືອຄວາມເປັນສ່ວນຕົວ; ຮາກຂອງບັນຫາຂອງພວກເຮົາແມ່ນຫນຶ່ງໃນການຄວບຄຸມ. ພວກເຮົາຖ່າຍທອດຄວາມເປັນເຈົ້າຂອງ petabytes ຂອງຂໍ້ມູນໃຫ້ກັບບໍລິສັດ ແລະບຸກຄົນເປັນປະຈໍາໂດຍບໍ່ມີທາງເລືອກທີ່ຊັດເຈນ.
- ຄວາມປອດໄພ & ຄວາມເປັນສ່ວນຕົວ — ການສ້າງເວັບທີ່ດີກວ່າໂດຍການນໍາໃຊ້ເຕັກໂນໂລຊີການເຂົ້າລະຫັດທີ່ທັນສະໄຫມຈະເຮັດໃຫ້ແນ່ໃຈວ່າຜູ້ໃຊ້ອິນເຕີເນັດສາມາດຮັກສາຂໍ້ມູນສ່ວນບຸກຄົນຂອງເຂົາເຈົ້າເປັນສ່ວນຕົວ, ຫ່າງໄກຈາກຕາ prying ຂອງບໍລິສັດຫຼືແຮກເກີ.
- ການຄຸ້ມຄອງການເກັບຮັກສາແບບແບ່ງປັນ - ໄຟລ໌ຂະຫນາດໃຫຍ່ອາດຈະຖືກແບ່ງອອກເປັນສ່ວນນ້ອຍທີ່ສາມາດເຂົ້າລະຫັດສ່ວນບຸກຄົນແລະເກັບໄວ້ໃນຫຼາຍບ່ອນ. ເຄືອຂ່າຍ IPFS ແລະໂປໂຕຄອນທີ່ສົມທຽບໄດ້ມີໂຄງສ້າງໃນລັກສະນະທີ່ການລະເມີດພວກມັນຈະຕ້ອງຖືກ hack ເຂົ້າໄປໃນເຄື່ອງຈັກຫຼາຍແຫ່ງທົ່ວໂລກໃນເວລາດຽວກັນ, ແຕ່ລະຄົນມີການປົກປ້ອງຂອງຕົນເອງ.
- ເອກະລັກ ແລະຊື່ສຽງ — ເຈົ້າບໍ່ໄດ້ຢູ່ຄົນດຽວຫາກເຈົ້າກັງວົນວ່າພວກເຮົາຈະຮັບມືກັບຄວາມໄວ້ວາງໃຈ ແລະຊື່ສຽງອອນລາຍແນວໃດ. ໃນຄວາມເປັນຈິງ, ພວກເຮົາມີຕົວຕົນດິຈິຕອນອອນໄລນ໌ທີ່ປະກອບດ້ວຍຂໍ້ມູນທີ່ເຜີຍແຜ່ໃນສື່ສັງຄົມແລະເວັບໄຊທ໌ອື່ນໆ. ບັນຫາຕົ້ນຕໍແມ່ນພວກເຮົາບໍ່ໄດ້ເປັນເຈົ້າຂອງຫຼືຈັດການຂໍ້ມູນນັ້ນ, ເຊິ່ງມີການປ່ຽນແປງກັບເວັບໃຫມ່.
ຜົນປະໂຫຍດ
ນີ້ແມ່ນຄໍເລັກຊັນຂອງຄຸນນະພາບທີ່ໂດດເດັ່ນຂອງ Web 3.0 ເພື່ອຊ່ວຍໃຫ້ທ່ານເຂົ້າໃຈວ່າມັນຈະດໍາເນີນການແນວໃດ ແລະທ່ານຈະໄດ້ຮັບຜົນປະໂຫຍດຈາກມັນແນວໃດ!

1 Artificial Intelligence
Artificial Intelligence (AI) ບໍ່ແມ່ນແນວຄິດໃຫມ່ທີ່ຈະປາກົດຢູ່ໃນ Web 3.0. ພວກເຮົາໄດ້ສັງເກດເຫັນມັນຢູ່ໃນແອັບພລິເຄຊັນ Web 2.0 ແລ້ວ. ຢ່າງໃດກໍ່ຕາມ, ໂດຍ Web 3.0, AI ຈະມີກົນໄກການຮຽນຮູ້ໄວທີ່ມັນຍາກທີ່ຈະປະຕິເສດການມີຢູ່ຂອງມັນ. AI ຈະຈໍາແນກຢ່າງໄວວາລະຫວ່າງຂໍ້ມູນທີ່ດີແລະບໍ່ດີ, ລະຫວ່າງບຸກຄົນທີ່ແທ້ຈິງແລະ bots, ແລະ, ສໍາຄັນທີ່ສຸດ, ລະຫວ່າງຂ່າວປອມແລະການລາຍງານຄວາມຈິງ.
2. 3D Virtual Identities
Web 3.0 ຈະນໍາເອົາເສັ້ນທາງໃຫມ່ຂອງການສື່ສານແລະການເຊື່ອມຕໍ່ virtual. ການສົນທະນາ, ອີເມວ, ແລະການໂທວິດີໂອອາດຈະຍັງເປັນໄປໄດ້. ຢ່າງໃດກໍຕາມ, ຜູ້ໃຊ້ອາດຈະເຂົ້າເຖິງຕົວຕົນ 3D ທີ່ເປັນຕົວແທນໃຫ້ພວກເຂົາຢູ່ໃນເວັບ. ຮູບແທນຕົວສະເໝືອນເຫຼົ່ານີ້, ຄ້າຍກັບຕົວລະຄອນເກມອອນໄລນ໌, ຈະເປັນຕົວແທນຂອງພວກເຮົາໃນທຸລະກຳຂອງບໍລິສັດ, ການຮ່ວມມືໃນການເຮັດວຽກ ແລະແອັບພລິເຄຊັນນັດພົບ.
3. ບໍລິການທີ່ບໍ່ຕິດຂັດ
ຂໍ້ມູນຈະໄດ້ຮັບການເກັບຮັກສາໄວ້ໃນຫຼາຍຂໍ້ກະແຈກກະຈາຍໃນ Web 3.0. ວິທີການນີ້ຮັບປະກັນວ່າມີໂນດສໍາຮອງພຽງພໍສະເຫມີເພື່ອສະຫນອງລະບົບຕ່ອງໂສ້ແລະຮັກສາເຄື່ອງແມ່ຂ່າຍຈາກການຢຸດຫຼືລົ້ມເຫລວ. ເວົ້າງ່າຍໆ, ອິນເຕີເນັດຈະບໍ່ສາມາດໃຊ້ໄດ້ຍ້ອນຄວາມລົ້ມເຫຼວຂອງເຊີບເວີ.
4. ຄວາມເປັນເຈົ້າຂອງຂໍ້ມູນ
ເມື່ອ Web 3.0 ກາຍເປັນຄວາມເປັນຈິງແລ້ວ, ບໍລິສັດຂະຫນາດໃຫຍ່ເຊັ່ນ Amazon, Facebook, ແລະ Google ຈະບໍ່ຕ້ອງການເຄື່ອງແມ່ຂ່າຍຂະຫນາດໂຮງງານຂອງພວກເຂົາເພື່ອເກັບຂໍ້ມູນຂອງລູກຄ້າຂອງພວກເຂົາ. ແທນທີ່ຈະ, ຜູ້ໃຊ້ອິນເຕີເນັດຈະມີການຄວບຄຸມຂໍ້ມູນທັງຫມົດຂອງເຂົາເຈົ້າ, ລວມທັງຂໍ້ມູນທາງດ້ານການເງິນ, ຂໍ້ມູນການເຂົ້າສູ່ລະບົບ, ແລະອື່ນໆ.
5. Semantic Metadata
Semantic metadata ແມ່ນຂໍ້ມູນທີ່ອະທິບາຍ "ຄວາມຫມາຍ" ຂອງຂໍ້ມູນ. ມີມູນຄ່າທີ່ສະທ້ອນໃຫ້ເຫັນແນວຄວາມຄິດບາງຢ່າງໃນສະພາບແວດລ້ອມທີ່ມີຂໍ້ມູນ. Semantic metadata ຈະເປັນອົງປະກອບທີ່ສໍາຄັນຂອງ Web 3.0. ວິທີການນີ້ຈະຊ່ວຍໃຫ້ເວັບສາມາດເຂົ້າໃຈຄວາມຫມາຍຂອງສັນຍາລັກ, ຄໍາສໍາຄັນ, ແລະຂໍ້ຄວາມ. ສໍາລັບຕົວຢ່າງ, ເຄືອຂ່າຍຈະກວດພົບ emoji "smiley" ຄລາສສິກ, ເຊິ່ງເຮັດໂດຍສອງຈຸດຕາມດ້ວຍ arc. ຢ່າງໃດກໍຕາມ, ມັນຈະຮັບຮູ້ວ່າມັນເປັນຕົວແທນຂອງຮອຍຍິ້ມຂອງມະນຸດ, ທ່າທາງຂອງຄວາມສຸກແລະການຍອມຮັບ.
ທ້າທາຍ
Web 3.0, ຄືກັບເທັກໂນໂລຍີໃໝ່ໆ, ແມ່ນຍາກທີ່ຈະນຳໃຊ້ໃນສະພາບປັດຈຸບັນຂອງມັນ, ຢ່າງໜ້ອຍໃນຕອນທຳອິດ. ບັນຫາ ແລະ ຂໍ້ບົກຜ່ອງຂອງ Web 3.0 ລວມມີສິ່ງຕໍ່ໄປນີ້:
1. ການມາຊ້າ
ສຸດທ້າຍ, Web 3.0 ຈະບໍ່ເປັນສິ່ງມະຫັດສະຈັນສໍາລັບທຸກຄົນ. ຜູ້ໃຊ້ອິນເຕີເນັດທີ່ມີລະດູການຫຼາຍອາດຈະຈື່ໄດ້ວ່າ Web 1.0 ໃຊ້ເວລາເກືອບຫນຶ່ງທົດສະວັດທີ່ຈະໄດ້ຮັບແຮງດຶງດູດທົ່ວໂລກ. ເມື່ອ Web 2.0 ມາຮອດ, ມັນໄດ້ນໍາເອົາເຕັກໂນໂລຢີທີ່ສະຫລາດແລະສື່ສັງຄົມ, ແຕ່ປະຊາຊົນຍັງຊອກຫາວິທີການສົນທະນາແລະອີເມວເຮັດວຽກ. ທຸລະກິດຈໍານວນຫຼາຍຈະໃຊ້ເວລາຂອງພວກເຂົາຫັນປ່ຽນຈາກເຄືອຂ່າຍສູນກາງໄປສູ່ລະບົບຕ່ອງໂສ້ທີ່ບໍ່ຫນ້າເຊື່ອຖື.
ແກດເຈັດຫຼາຍອັນຈະລ້າສະໄໝແລ້ວ, ແຕ່ຜູ້ໃຊ້ຂອງພວກມັນຈະບໍ່ສາມາດປ່ຽນໄປໃຊ້ Web 3.0 ໄດ້ທັນທີ. ດັ່ງນັ້ນ, Web 2.0 ແລະ Web 3.0 ຈະຢູ່ຮ່ວມກັນສໍາລັບອະນາຄົດທີ່ຄາດໄວ້.
2. ການປະພຶດທີ່ບໍ່ດີຂອງມະນຸດ
Web 3.0 ເບິ່ງຄືວ່າເປັນບາດກ້າວທີ່ປ່ຽນແປງເກມໄປສູ່ຄວາມກ້າວຫນ້າທາງດ້ານເຕັກໂນໂລຢີ. ແຫຼ່ງທີ່ມາຂອງມັນຈະສະແດງເຖິງຈຸດ “ກ່ອນ ແລະ ຫຼັງ” ໃນການໂຕ້ຕອບຂອງພວກເຮົາກັບອິນເຕີເນັດ. ແນວໃດກໍ່ຕາມ, ພວກເຮົາບໍ່ຄວນລືມວ່າຜູ້ທີ່ມີແຮງຈູງໃຈທີ່ບໍ່ດີຈະຍັງຄົງຢູ່.
ຜູ້ໃຊ້ທີ່ບໍ່ດີອາດມີເຈດຕະນາໃຫ້ເວັບໄຊທ໌ມີເນື້ອໃນທີ່ບໍ່ຖືກຕ້ອງຫຼືເຮັດໃຫ້ເຂົ້າໃຈຜິດ, ສ້າງສະພາບແວດລ້ອມທີ່ເຫມາະສົມສໍາລັບອາຊະຍາກໍາອອນໄລນ໌. ເພື່ອຫຼຸດຜ່ອນຄວາມຖີ່ຂອງການໂຈມຕີ hack, cryptography, ແລະ ປັນຍາປະດິດ ວິທີການຮຽນຮູ້ຈະຕ້ອງປັບປຸງແລະປັບປຸງຢ່າງໄວວາ.
ສະຫຼຸບ
ອິນເຕີເນັດໄດ້ຮັບການຜັນຂະຫຍາຍຢ່າງຍາວນານ, ແລະມັນຈະສືບຕໍ່ເຮັດແນວນັ້ນຢ່າງແນ່ນອນໃນອະນາຄົດ. ເນື່ອງຈາກການຂະຫຍາຍຂະຫນາດໃຫຍ່ຂອງຂໍ້ມູນທີ່ບໍ່ສາມາດເຂົ້າເຖິງໄດ້, ເວັບໄຊທ໌ແລະແອັບຯອາດຈະປ່ຽນໄປຫາເວັບທີ່ສະຫນອງປະສົບການທີ່ດີກວ່າໃຫ້ກັບຈໍານວນຄົນທີ່ເພີ່ມຂຶ້ນໃນທົ່ວໂລກ. ໃນຂະນະທີ່ບໍ່ມີຄໍານິຍາມທີ່ຊັດເຈນສໍາລັບ Web3 (Web 3.0) ໃນເວລານີ້, ມັນໄດ້ຖືກກະຕຸ້ນໂດຍຄວາມກ້າວຫນ້າທາງດ້ານເຕັກໂນໂລຢີໃນຂະແຫນງການອື່ນໆ.
ໃນຂະນະທີ່ພວກເຮົາກ້າວໄປສູ່ອິນເຕີເນັດທີ່ມີການກະຈາຍອໍານາດຫຼາຍຂຶ້ນ, ດ້ວຍ ຄວາມເປັນຈິງ (AR) ແລະ Artificial Intelligence (AI) ມີບົດບາດສໍາຄັນໃນການກໍານົດສະຖານະການການນໍາໃຊ້ຂອງພວກເຮົາ, ພວກເຮົາອາດຈະຄາດວ່າຈະມີຄື້ນໃຫມ່ຂອງການປະຕິວັດອິນເຕີເນັດທົ່ວໂລກ.
Web 3.0 ສະຫນອງຄວາມຍືດຫຍຸ່ນທີ່ຕ້ອງການຫຼາຍສໍາລັບຄວາມຄິດສ້າງສັນໃຫ້ກັບນັກພັດທະນາ. ໃນທາງກົງກັນຂ້າມ, ຜູ້ໃຊ້ອາດຈະຄາດວ່າຈະມີການປັບປຸງ ປະສົບການດິຈິຕອນ ເຊັ່ນດຽວກັນກັບອິນເຕີເນັດທີ່ປັບປຸງ ແລະປັບປຸງດີຂຶ້ນໂດຍລວມ. ຖ້າເຮັດຢ່າງຖືກຕ້ອງ, Web 3.0 ມີທ່າແຮງທີ່ຈະປະຫຍັດເວລາ, ແລະເພີ່ມຜົນຜະລິດດ້ວຍຄ່າໃຊ້ຈ່າຍຕ່ໍາ. ພວກເຮົາອາດຈະຄາດຫວັງວ່າອິນເຕີເນັດທີ່ສະຫລາດກວ່າເພາະວ່າ, ເຊື່ອຫຼືບໍ່, ມັນຢູ່ທີ່ນີ້ເພື່ອຢູ່.





ອອກຈາກ Reply ເປັນ