ວິດີໂອເກມສືບຕໍ່ສ້າງຄວາມທ້າທາຍໃຫ້ກັບຜູ້ຫຼິ້ນຫຼາຍຕື້ຄົນໃນທົ່ວໂລກ. ທ່ານອາດຈະບໍ່ຮູ້ມັນເທື່ອ, ແຕ່ລະບົບການຮຽນຮູ້ເຄື່ອງຈັກກໍ່ເລີ່ມມີຄວາມທ້າທາຍເຊັ່ນກັນ.
ປະຈຸບັນມີການຄົ້ນຄວ້າຈໍານວນຫຼວງຫຼາຍໃນຂົງເຂດ AI ເພື່ອເບິ່ງວ່າວິທີການຮຽນຮູ້ຂອງເຄື່ອງຈັກສາມາດຖືກນໍາໃຊ້ກັບວິດີໂອເກມ. ຄວາມຄືບຫນ້າຢ່າງຫຼວງຫຼາຍໃນຂົງເຂດນີ້ສະແດງໃຫ້ເຫັນວ່າ ການຮຽນຮູ້ເຄື່ອງຈັກ ຕົວແທນສາມາດຖືກນໍາໃຊ້ເພື່ອເຮັດຕາມແບບຢ່າງຫຼືແມ້ກະທັ້ງການທົດແທນຜູ້ນຂອງມະນຸດ.
ນີ້ຫມາຍຄວາມວ່າແນວໃດສໍາລັບອະນາຄົດຂອງ ວິດິໂອເກມ?
ໂຄງການເຫຼົ່ານີ້ແມ່ນພຽງແຕ່ເພື່ອຄວາມມ່ວນຊື່ນ, ຫຼືມີເຫດຜົນເລິກເຊິ່ງກວ່າວ່າເປັນຫຍັງນັກຄົ້ນຄວ້າຈໍານວນຫຼາຍກໍາລັງສຸມໃສ່ເກມ?
ບົດຄວາມນີ້ຈະສໍາຫຼວດໂດຍຫຍໍ້ກ່ຽວກັບປະຫວັດສາດຂອງ AI ໃນວິດີໂອເກມ. ຫຼັງຈາກນັ້ນ, ພວກເຮົາຈະບອກທ່ານກ່ຽວກັບສະພາບລວມຂອງເຕັກນິກການຮຽນຮູ້ເຄື່ອງຈັກບາງຢ່າງທີ່ພວກເຮົາສາມາດໃຊ້ເພື່ອຮຽນຮູ້ວິທີການຕີເກມ. ຫຼັງຈາກນັ້ນພວກເຮົາຈະເບິ່ງບາງຄໍາຮ້ອງສະຫມັກສົບຜົນສໍາເລັດຂອງ ຕາຫນ່າງ neural ເພື່ອຮຽນຮູ້ແລະຕົ້ນສະບັບວິດີໂອເກມສະເພາະ.
ປະຫວັດຫຍໍ້ຂອງ AI ໃນເກມ
ກ່ອນທີ່ພວກເຮົາຈະເຂົ້າໃຈວ່າເປັນຫຍັງຕາຫນ່າງ neural ໄດ້ກາຍເປັນສູດການຄິດໄລ່ທີ່ເຫມາະສົມໃນການແກ້ໄຂວິດີໂອເກມ, ໃຫ້ພວກເຮົາເບິ່ງສັ້ນໆກ່ຽວກັບວິທີການວິທະຍາສາດຄອມພິວເຕີໄດ້ນໍາໃຊ້ວິດີໂອເກມເພື່ອກ້າວຫນ້າການຄົ້ນຄວ້າຂອງເຂົາເຈົ້າໃນ AI.
ທ່ານສາມາດໂຕ້ຖຽງວ່າ, ຕັ້ງແຕ່ເລີ່ມຕົ້ນ, ເກມວີດີໂອໄດ້ເປັນພື້ນທີ່ຮ້ອນຂອງການຄົ້ນຄວ້າສໍາລັບນັກຄົ້ນຄວ້າທີ່ມີຄວາມສົນໃຈໃນ AI.
ໃນຂະນະທີ່ບໍ່ເປັນວິດີໂອເກມໃນຕົ້ນກຳເນີດຢ່າງເຂັ້ມງວດ, ໝາກຮຸກເປັນຈຸດສຳຄັນຫຼາຍໃນຍຸກທຳອິດຂອງ AI. ໃນປີ 1951, ທ່ານດຣ Dietrich Prinz ຂຽນໂຄງການຫຼິ້ນໝາກຮຸກໂດຍໃຊ້ຄອມພິວເຕີດິຈິຕອລ Ferranti Mark 1. ນີ້ແມ່ນວິທີການກັບຄືນໄປບ່ອນໃນຍຸກທີ່ຄອມພິວເຕີຂະຫນາດໃຫຍ່ເຫຼົ່ານີ້ຕ້ອງອ່ານໂຄງການອອກຈາກ tape ເຈ້ຍ.

ໂຄງການຕົວມັນເອງບໍ່ແມ່ນ AI chess ທີ່ສົມບູນ. ເນື່ອງຈາກຂໍ້ຈໍາກັດຂອງຄອມພິວເຕີ, Prinz ພຽງແຕ່ສາມາດສ້າງໂຄງການທີ່ແກ້ໄຂບັນຫາ chess ຄູ່ໃນສອງ. ໂດຍສະເລ່ຍ, ໂຄງການໃຊ້ເວລາ 15-20 ນາທີເພື່ອຄິດໄລ່ທຸກໆການເຄື່ອນໄຫວທີ່ເປັນໄປໄດ້ສໍາລັບຜູ້ຫຼິ້ນສີຂາວແລະສີດໍາ.
ເຮັດວຽກກ່ຽວກັບການປັບປຸງ chess ແລະ checkers AI ໄດ້ປັບປຸງຢ່າງຕໍ່ເນື່ອງຕະຫຼອດທົດສະວັດ. ຄວາມຄືບໜ້າໄດ້ບັນລຸຈຸດສູງສຸດໃນປີ 1997 ເມື່ອບໍລິສັດ Deep Blue ຂອງ IBM ໄດ້ເອົາຊະນະນາຍໃຫຍ່ໝາກຮຸກລັດເຊຍ Garry Kasparov ໃນການແຂ່ງຂັນ XNUMX ເກມຄູ່. ໃນປັດຈຸບັນ, ເຄື່ອງຈັກຫມາກຮຸກທີ່ທ່ານສາມາດຊອກຫາຢູ່ໃນໂທລະສັບມືຖືຂອງທ່ານສາມາດທໍາລາຍ Deep Blue.
ຄູ່ແຂ່ງ AI ເລີ່ມໄດ້ຮັບຄວາມນິຍົມໃນຊ່ວງຍຸກທອງຂອງວິດີໂອເກມອາເຄດ. Space Invaders ໃນປີ 1978 ແລະ Pac-Man ໃນຊຸມປີ 1980 ແມ່ນບາງບຸກເບີກຂອງອຸດສາຫະກໍາໃນການສ້າງ AI ທີ່ສາມາດທ້າທາຍໄດ້ຢ່າງພຽງພໍເຖິງແມ່ນວ່ານັກຫຼິ້ນເກມອາເຄດທີ່ມີປະສົບການຫຼາຍທີ່ສຸດ.
Pac-Man, ໂດຍສະເພາະ, ເປັນເກມທີ່ນິຍົມສໍາລັບນັກຄົ້ນຄວ້າ AI ເພື່ອທົດລອງ. ຕ່າງໆ ການແຂ່ງຂັນ ສໍາລັບນາງ Pac-Man ໄດ້ຖືກຈັດຕັ້ງເພື່ອກໍານົດວ່າທີມໃດສາມາດມີ AI ທີ່ດີທີ່ສຸດເພື່ອເອົາຊະນະເກມ.
ເກມ AI ແລະສູດການຄິດໄລ່ heuristic ສືບຕໍ່ພັດທະນາຍ້ອນວ່າຄວາມຕ້ອງການສໍາລັບ opponents smarter ເກີດຂຶ້ນ. ສໍາລັບຕົວຢ່າງ, ການຕໍ່ສູ້ AI ເພີ່ມຂຶ້ນໃນຄວາມນິຍົມເປັນປະເພດເຊັ່ນ: ຍິງຄົນທໍາອິດໄດ້ກາຍເປັນເລື່ອງຕົ້ນຕໍ.
ການຮຽນຮູ້ເຄື່ອງຈັກໃນວິດີໂອເກມ
ໃນຂະນະທີ່ເຕັກນິກການຮຽນຮູ້ເຄື່ອງຈັກເພີ່ມຂຶ້ນຢ່າງໄວວາໃນຄວາມນິຍົມ, ໂຄງການຄົ້ນຄ້ວາຕ່າງໆໄດ້ພະຍາຍາມໃຊ້ເຕັກນິກໃຫມ່ເຫຼົ່ານີ້ເພື່ອຫຼິ້ນເກມວີດີໂອ.
ເກມເຊັ່ນ Dota 2, StarCraft, ແລະ Doom ສາມາດເຮັດໜ້າທີ່ເປັນບັນຫາເຫຼົ່ານີ້ໄດ້ ສູດການຮຽນຮູ້ເຄື່ອງຈັກ ການແກ້ໄຂ. ສູດການຄິດໄລ່ການຮຽນຮູ້ເລິກໂດຍສະເພາະ, ສາມາດບັນລຸໄດ້ແລະເກີນກວ່າການປະຕິບັດລະດັບມະນຸດ.
ໄດ້ ສະພາບແວດລ້ອມການຮຽນຮູ້ອາເຄດ ຫຼື ALE ໃຫ້ນັກຄົ້ນຄວ້າມີການໂຕ້ຕອບສໍາລັບຫຼາຍກວ່າຮ້ອຍ Atari 2600 ເກມ. ແພລະຕະຟອມເປີດແຫຼ່ງອະນຸຍາດໃຫ້ນັກຄົ້ນຄວ້າສາມາດປະເມີນປະສິດທິພາບຂອງເຕັກນິກການຮຽນຮູ້ເຄື່ອງຈັກໃນວິດີໂອເກມຄລາສສິກ Atari. Google ຍັງໄດ້ເຜີຍແຜ່ຂອງຕົນເອງ ເຈ້ຍ ໃຊ້ເຈັດເກມຈາກ ALE

ໃນຂະນະດຽວກັນ, ໂຄງການເຊັ່ນ VizDoom ໄດ້ໃຫ້ໂອກາດນັກວິໄຈ AI ຝຶກອົບຮົມລະບົບການຮຽນຮູ້ເຄື່ອງຈັກເພື່ອຫຼິ້ນນັກຍິງຄົນທຳອິດແບບ 3 ມິຕິ.

ມັນເຮັດວຽກແນວໃດ: ບາງແນວຄວາມຄິດທີ່ສໍາຄັນ
Neural Networks
ວິທີການສ່ວນໃຫຍ່ໃນການແກ້ໄຂວິດີໂອເກມທີ່ມີການຮຽນຮູ້ເຄື່ອງຈັກກ່ຽວຂ້ອງກັບປະເພດຂອງລະບົບປະສາດທີ່ເອີ້ນວ່າເຄືອຂ່າຍ neural.
ທ່ານສາມາດຄິດວ່າ neural net ເປັນໂຄງການທີ່ພະຍາຍາມທີ່ຈະເຮັດໃຫ້ການເຮັດວຽກຂອງສະຫມອງ. ຄ້າຍຄືກັນກັບວິທີການສະຫມອງຂອງພວກເຮົາປະກອບດ້ວຍ neurons ທີ່ສົ່ງສັນຍານ, ຕາຫນ່າງ neural ຍັງມີ neurons ປອມ.
neurons ປອມເຫຼົ່ານີ້ຍັງໂອນສັນຍານໃຫ້ກັນແລະກັນ, ໂດຍແຕ່ລະສັນຍານເປັນຕົວເລກຕົວຈິງ. ຕາຫນ່າງ neural ປະກອບດ້ວຍຫຼາຍຊັ້ນລະຫວ່າງຊັ້ນ input ແລະ output, ເອີ້ນວ່າເຄືອຂ່າຍ neural ເລິກ.
ການຮຽນຮູ້ການເສີມສ້າງ
ອີກເຕັກນິກການຮຽນຮູ້ເຄື່ອງຈັກທົ່ວໄປທີ່ກ່ຽວຂ້ອງກັບການຮຽນຮູ້ວີດີໂອເກມແມ່ນແນວຄວາມຄິດຂອງການຮຽນຮູ້ເສີມ.
ເຕັກນິກນີ້ແມ່ນຂະບວນການຂອງການຝຶກອົບຮົມຕົວແທນໂດຍນໍາໃຊ້ລາງວັນຫຼືການລົງໂທດ. ດ້ວຍວິທີການນີ້, ຕົວແທນຄວນຈະສາມາດແກ້ໄຂບັນຫາໄດ້ໂດຍຜ່ານການທົດລອງແລະຄວາມຜິດພາດ.
ສົມມຸດວ່າພວກເຮົາຕ້ອງການ AI ເພື່ອຄົ້ນຫາວິທີການຫລິ້ນເກມ Snake. ຈຸດປະສົງຂອງເກມແມ່ນງ່າຍດາຍ: ໄດ້ຮັບຈຸດຫຼາຍເທົ່າທີ່ເປັນໄປໄດ້ໂດຍການບໍລິໂພກລາຍການແລະຫຼີກເວັ້ນການຫາງການຂະຫຍາຍຕົວຂອງທ່ານ.
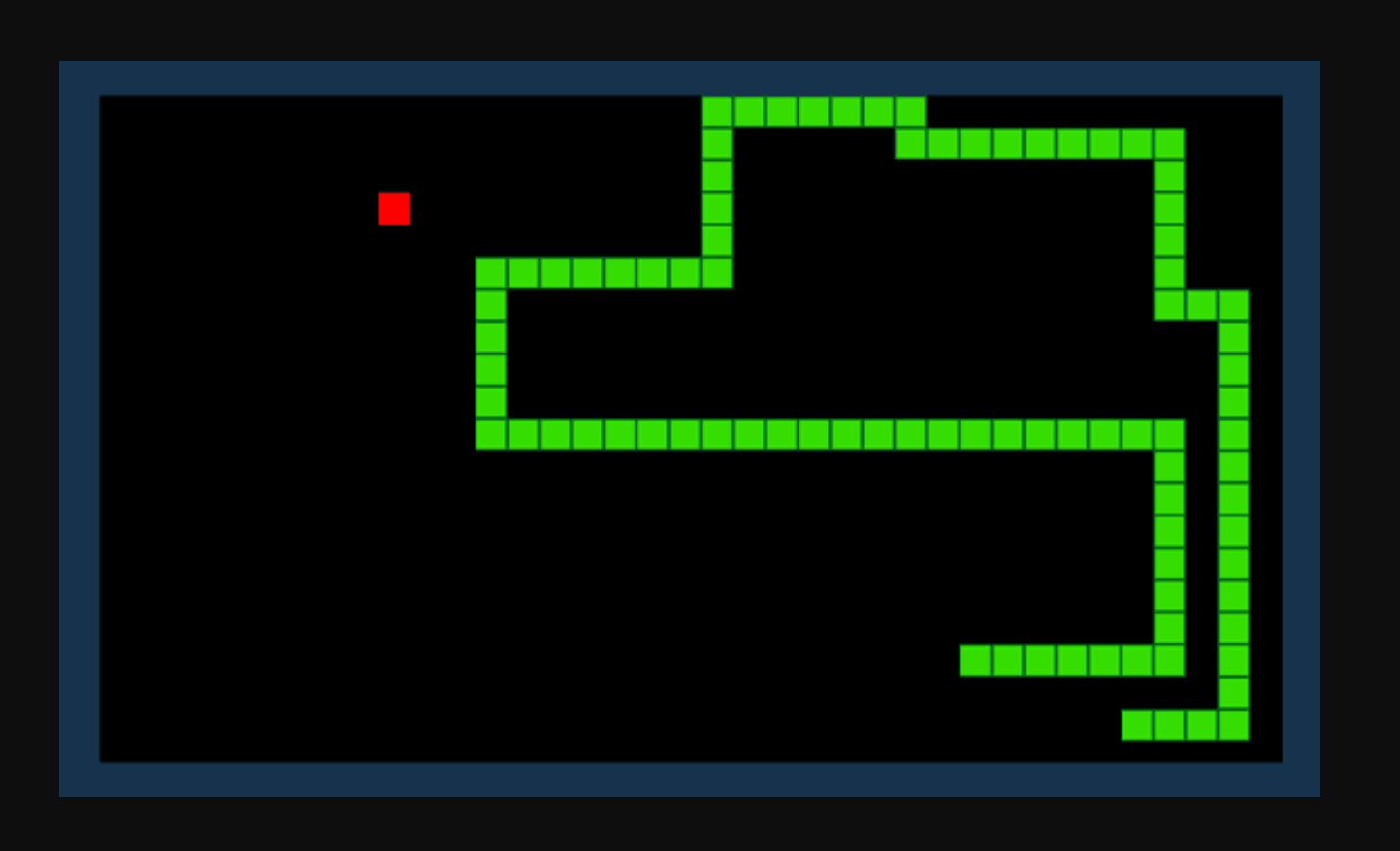
ດ້ວຍການຮຽນຮູ້ເສີມ, ພວກເຮົາສາມາດກຳນົດຟັງຊັນລາງວັນ R. ຟັງຊັນເພີ່ມຈຸດເມື່ອງູກິນລາຍການໃດໜຶ່ງ ແລະ ຫັກຄະແນນເມື່ອງູຕີອຸປະສັກ. ເນື່ອງຈາກສະພາບແວດລ້ອມໃນປະຈຸບັນແລະຊຸດຂອງການປະຕິບັດທີ່ເປັນໄປໄດ້, ຮູບແບບການຮຽນຮູ້ການເສີມຂອງພວກເຮົາຈະພະຍາຍາມຄິດໄລ່ 'ນະໂຍບາຍ' ທີ່ດີທີ່ສຸດທີ່ເຮັດໃຫ້ຫນ້າທີ່ລາງວັນຂອງພວກເຮົາສູງສຸດ.
ນິເວດວິທະຍາ
ຮັກສາຢູ່ໃນຫົວຂໍ້ທີ່ມີການດົນໃຈຈາກທໍາມະຊາດ, ນັກຄົ້ນຄວ້າຍັງໄດ້ພົບເຫັນຜົນສໍາເລັດໃນການນໍາໃຊ້ ML ກັບເກມວີດີໂອໂດຍຜ່ານເຕັກນິກທີ່ເອີ້ນວ່າ neuroevolution.
ແທນທີ່ຈະໃຊ້ ການສືບເຊື້ອສາຍ gradient ເພື່ອປັບປຸງ neurons ໃນເຄືອຂ່າຍ, ພວກເຮົາສາມາດນໍາໃຊ້ algorithms evolutionary ເພື່ອບັນລຸຜົນໄດ້ຮັບທີ່ດີກວ່າ.
ໂດຍປົກກະຕິແລ້ວ ສູດການວິວັດທະນາການເລີ່ມຕົ້ນໂດຍການສ້າງປະຊາກອນເບື້ອງຕົ້ນຂອງບຸກຄົນແບບສຸ່ມ. ຈາກນັ້ນພວກເຮົາປະເມີນບຸກຄົນເຫຼົ່ານີ້ໂດຍໃຊ້ເງື່ອນໄຂທີ່ແນ່ນອນ. ບຸກຄົນທີ່ດີທີ່ສຸດແມ່ນໄດ້ຖືກເລືອກເປັນ "ພໍ່ແມ່" ແລະໄດ້ຖືກອົບຣົມມາຮ່ວມກັນເພື່ອສ້າງບຸກຄົນຮຸ່ນໃຫມ່. ບຸກຄົນເຫຼົ່ານີ້ຫຼັງຈາກນັ້ນຈະທົດແທນບຸກຄົນທີ່ເຫມາະຫນ້ອຍທີ່ສຸດໃນປະຊາກອນ.
ສູດການຄິດໄລ່ເຫຼົ່ານີ້ປົກກະຕິແລ້ວຍັງແນະນໍາບາງຮູບແບບຂອງການປະຕິບັດການກາຍພັນໃນລະຫວ່າງການຂ້າມຜ່ານຫຼືຂັ້ນຕອນ "ການປັບປຸງພັນ" ເພື່ອຮັກສາຄວາມຫຼາກຫຼາຍທາງພັນທຸກໍາ.
ຕົວຢ່າງການຄົ້ນຄວ້າກ່ຽວກັບການຮຽນຮູ້ເຄື່ອງຈັກໃນວິດີໂອເກມ
OpenAI ຫ້າ

OpenAI ຫ້າ ເປັນໂຄງການຄອມພິວເຕີຂອງ OpenAI ທີ່ມີຈຸດປະສົງເພື່ອຫຼິ້ນເກມ DOTA 2, ເປັນເກມສະຫນາມຮົບມືຖືທີ່ມີຜູ້ຫຼິ້ນຫຼາຍຄົນ (MOBA).
ໂຄງການດັ່ງກ່າວໄດ້ນໍາໃຊ້ເຕັກນິກການຮຽນຮູ້ເສີມທີ່ມີຢູ່ແລ້ວ, ຂະຫນາດເພື່ອຮຽນຮູ້ຈາກລ້ານເຟຣມຕໍ່ວິນາທີ. ຂໍຂອບໃຈກັບລະບົບການຝຶກອົບຮົມທີ່ແຈກຢາຍ, OpenAI ສາມາດຫຼິ້ນເກມທີ່ມີມູນຄ່າ 180 ປີໃນແຕ່ລະມື້.
ຫຼັງຈາກໄລຍະເວລາການຝຶກອົບຮົມ, OpenAI Five ສາມາດບັນລຸການປະຕິບັດລະດັບຜູ້ຊ່ຽວຊານແລະສະແດງໃຫ້ເຫັນການຮ່ວມມືກັບຜູ້ນຂອງມະນຸດ. ໃນປີ 2019, OpenAI ຫ້າສາມາດ ເອົາຊະນະ 99.4% ຂອງຜູ້ນໃນການແຂ່ງຂັນສາທາລະນະ.
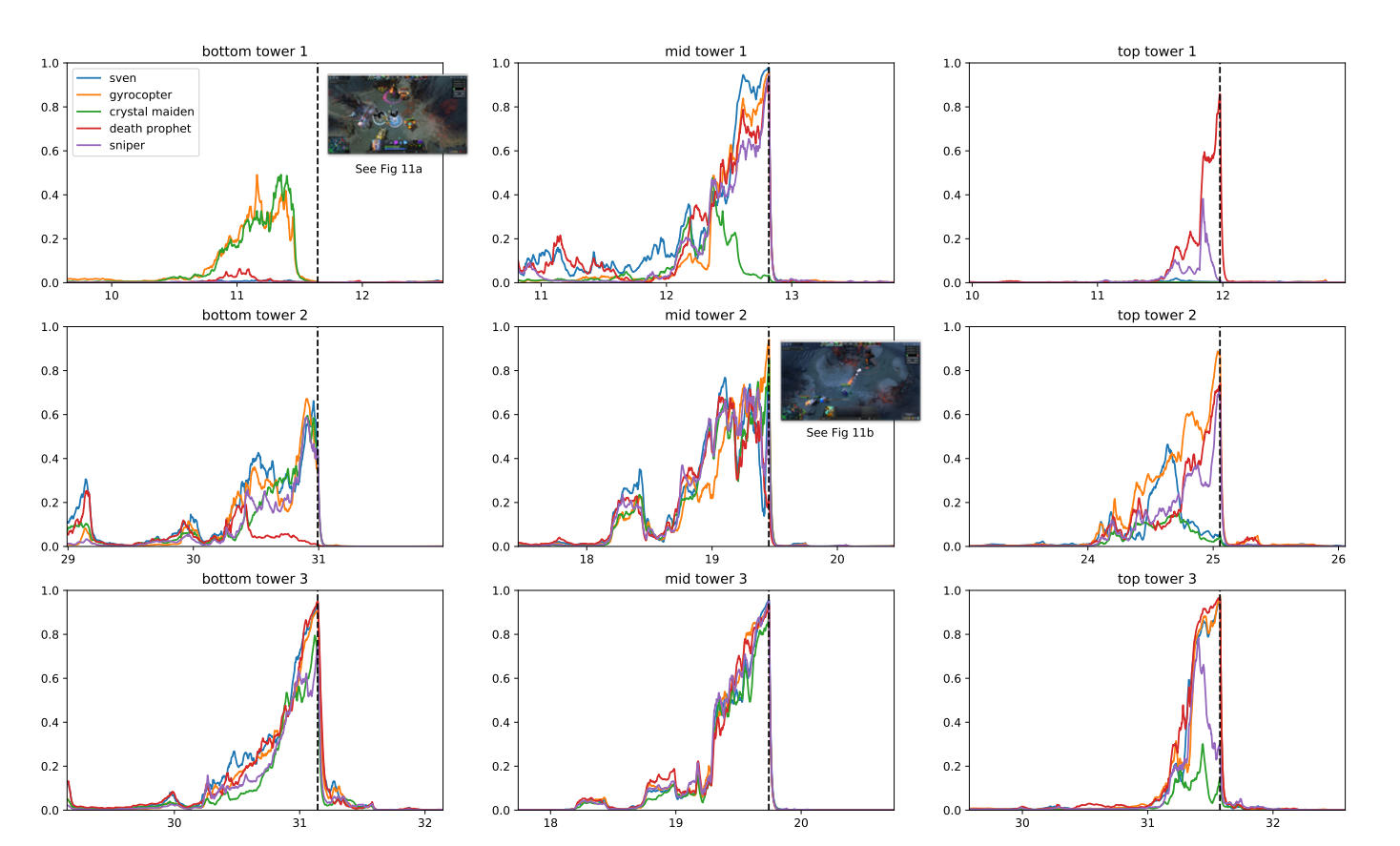
ເປັນຫຍັງ OpenAI ຈຶ່ງຕັດສິນໃຈກ່ຽວກັບເກມນີ້? ອີງຕາມນັກຄົ້ນຄວ້າ, DOTA 2 ມີກົນໄກສະລັບສັບຊ້ອນທີ່ຢູ່ນອກຂອບເຂດຂອງຄວາມເລິກທີ່ມີຢູ່ແລ້ວ ການຮຽນຮູ້ການເສີມສ້າງ ສູດການຄິດໄລ່.
Super Mario Bros
ຄໍາຮ້ອງສະຫມັກທີ່ຫນ້າສົນໃຈອີກອັນຫນຶ່ງຂອງຕາຫນ່າງ neural ໃນເກມວີດີໂອແມ່ນການນໍາໃຊ້ neuroevolution ເພື່ອຫຼິ້ນເວທີເຊັ່ນ Super Mario Bros.
ຍົກຕົວຢ່າງ, ນີ້ ການເຂົ້າ hackathon ເລີ່ມຕົ້ນດ້ວຍການບໍ່ມີຄວາມຮູ້ກ່ຽວກັບເກມແລະຄ່ອຍໆສ້າງພື້ນຖານຂອງສິ່ງທີ່ຈໍາເປັນເພື່ອກ້າວໄປສູ່ລະດັບໃດຫນຶ່ງ.
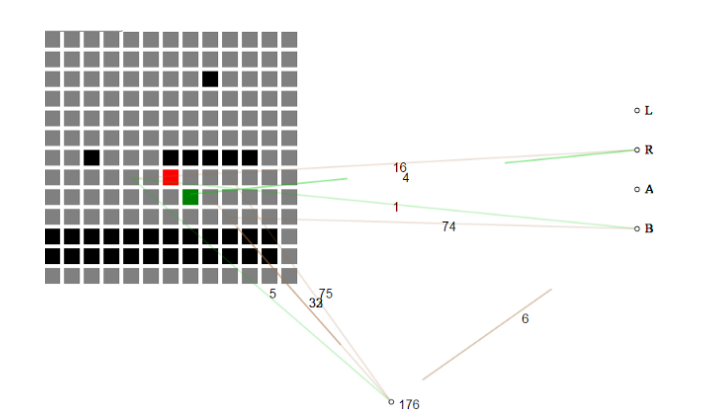
ຕາໜ່າງຂອງລະບົບປະສາດທີ່ພັດທະນາຕົນເອງໃຊ້ເວລາໃນສະຖານະປັດຈຸບັນຂອງເກມເປັນຕາໜ່າງຂອງກະເບື້ອງ. ໃນຕອນທໍາອິດ, ຕາຫນ່າງ neural ບໍ່ເຂົ້າໃຈວ່າແຕ່ລະກະເບື້ອງຫມາຍຄວາມວ່າແນວໃດ, ພຽງແຕ່ວ່າກະເບື້ອງ "ອາກາດ" ແຕກຕ່າງຈາກ "ກະເບື້ອງດິນ" ແລະ "ກະເບື້ອງສັດຕູ."
ການປະຕິບັດໂຄງການ hackathon ຂອງ neuroevolution ໄດ້ນໍາໃຊ້ NEAT ສູດການຄິດໄລ່ທາງພັນທຸກໍາເພື່ອສາຍພັນ neural nets ທີ່ແຕກຕ່າງກັນເລືອກ.
ຄວາມສໍາຄັນ
ໃນປັດຈຸບັນທີ່ທ່ານໄດ້ເຫັນບາງຕົວຢ່າງຂອງຕາຫນ່າງ neural ມັກຫຼີ້ນເກມວີດີໂອ, ທ່ານອາດຈະສົງໄສວ່າຈຸດຂອງສິ່ງທັງຫມົດນີ້ແມ່ນຫຍັງ.
ນັບຕັ້ງແຕ່ເກມວີດີໂອກ່ຽວຂ້ອງກັບການໂຕ້ຕອບທີ່ສັບສົນລະຫວ່າງຕົວແທນແລະສະພາບແວດລ້ອມຂອງພວກເຂົາ, ມັນເປັນພື້ນທີ່ທົດສອບທີ່ສົມບູນແບບສໍາລັບການສ້າງ AI. ສະພາບແວດລ້ອມສະເໝືອນມີຄວາມປອດໄພ ແລະສາມາດຄວບຄຸມໄດ້ ແລະສະໜອງຂໍ້ມູນທີ່ບໍ່ມີຂອບເຂດ.
ການຄົ້ນຄວ້າທີ່ເຮັດໃນຂົງເຂດນີ້ໄດ້ໃຫ້ຄວາມເຂົ້າໃຈກັບນັກຄົ້ນຄວ້າກ່ຽວກັບວິທີການຕາຫນ່າງ neural ສາມາດເພີ່ມປະສິດທິພາບເພື່ອຮຽນຮູ້ວິທີການແກ້ໄຂບັນຫາໃນໂລກທີ່ແທ້ຈິງ.
ເຄືອຂ່າຍ Neural ໄດ້ຮັບການດົນໃຈຈາກວິທີການເຮັດວຽກຂອງສະຫມອງໃນໂລກທໍາມະຊາດ. ໂດຍການສຶກສາວິທີການ neurons ທຽມປະຕິບັດຕົວໃນເວລາທີ່ຮຽນຮູ້ວິທີການຫຼິ້ນເກມວິດີໂອ, ພວກເຮົາຍັງອາດຈະໄດ້ຮັບຄວາມເຂົ້າໃຈກ່ຽວກັບວິທີການ ສະຫມອງຂອງມະນຸດ ວຽກງານ.
ສະຫຼຸບ
ຄວາມຄ້າຍຄືກັນລະຫວ່າງເຄືອຂ່າຍ neural ແລະສະຫມອງໄດ້ເຮັດໃຫ້ຄວາມເຂົ້າໃຈໃນທັງສອງດ້ານ. ການຄົ້ນຄວ້າຢ່າງຕໍ່ເນື່ອງກ່ຽວກັບວິທີການຕາຫນ່າງ neural ສາມາດແກ້ໄຂບັນຫາໃນມື້ຫນຶ່ງອາດຈະນໍາໄປສູ່ຮູບແບບທີ່ກ້າວຫນ້າທາງດ້ານຫຼາຍ ປັນຍາປະດິດ.
ຈິນຕະນາການໃຊ້ AI ທີ່ປັບແຕ່ງຕາມສະເພາະຂອງເຈົ້າທີ່ສາມາດຫຼິ້ນເກມໄດ້ທັງໝົດກ່ອນທີ່ທ່ານຈະຊື້ມັນເພື່ອແຈ້ງໃຫ້ເຈົ້າຮູ້ວ່າມັນຄຸ້ມຄ່າເວລາຂອງເຈົ້າຫຼືບໍ່. ບໍລິສັດວິດີໂອເກມຈະໃຊ້ຕາຫນ່າງ neural ເພື່ອປັບປຸງການອອກແບບເກມ, ລະດັບ tweak, ແລະຄວາມຫຍຸ້ງຍາກ opponent?
ເຈົ້າຄິດວ່າຈະເກີດຫຍັງຂຶ້ນເມື່ອຕາໜ່າງ neural ກາຍເປັນນັກຫຼິ້ນເກມສູງສຸດ?





ອອກຈາກ Reply ເປັນ