ການຂູດເວັບໄດ້ກາຍເປັນວິທີທີ່ສໍາຄັນສໍາລັບການໄດ້ຮັບຂໍ້ມູນຄວາມເຂົ້າໃຈຈາກເວທີອິນເຕີເນັດໃນສັງຄົມທີ່ຂັບເຄື່ອນດ້ວຍຂໍ້ມູນໃນປະຈຸບັນ.
ໃນຖານະເປັນເວັບໄຊສື່ມວນຊົນສັງຄົມທີ່ນິຍົມທີ່ສຸດ, Instagram ສະຫນອງຫຼາຍຂອງອຸປະກອນການສ້າງໂດຍຜູ້ໃຊ້. ແລະ, ຂໍ້ມູນທີ່ສ້າງຂຶ້ນເຫຼົ່ານີ້ສາມາດຖືກນໍາໃຊ້ສໍາລັບການຕະຫຼາດ, ການຄົ້ນຄວ້າ, ແລະເຫດຜົນອື່ນໆ.
ຜູ້ໃຊ້ສາມາດສະກັດຂໍ້ມູນຈາກ Instagram ໄດ້ງ່າຍແລະມີປະສິດທິພາບຍ້ອນການຂູດຂໍ້ມູນ Instagram ທີ່ອຸດົມສົມບູນຂອງ Bright Data, ເປັນຜູ້ນໍາຫນ້າ. ການຂູດເວັບ ເຄື່ອງມື. ໃນບົດຂຽນນີ້, ພວກເຮົາຈະໃຫ້ຂັ້ນຕອນຢ່າງລະອຽດ, ຂັ້ນຕອນຂອງຂະບວນການຂູດ Instagram.
ດັ່ງນັ້ນ, ໃຫ້ເບິ່ງຂັ້ນຕອນສໍາລັບວິທີທີ່ພວກເຮົາສາມາດຂູດຂໍ້ມູນຈາກ Instagram.
ເຂົ້າໃຈ Instagram Scrapers ຈາກ Bright Data
ດ້ວຍການຊ່ວຍເຫຼືອຂອງສອງເຄື່ອງຂູດເວັບທີ່ມີຈຸດປະສົງທັງຫມົດແລະຊຸດຂໍ້ມູນທີ່ລວບລວມໄວ້ກ່ອນ, Bright Data ສະຫນອງການບໍລິການຂູດຂໍ້ມູນ Instagram ຕ່າງໆ. ເທັກໂນໂລຍີເຫຼົ່ານີ້ໃຫ້ຄວາມຄ່ອງແຄ້ວໃນການສະກັດເອົາຂໍ້ມູນ ແລະປັບຕົວເຂົ້າກັບຄວາມຕ້ອງການຕ່າງໆ.
ໃຫ້ກວດເບິ່ງແຕ່ລະທາງເລືອກເຫຼົ່ານີ້ໂດຍລາຍລະອຽດເພີ່ມເຕີມ:
a. ຕົວທ່ອງເວັບຂູດ
ເຕັກໂນໂລຍີນະວັດຕະກໍາທີ່ເອີ້ນວ່າ Scraping Browser ໄດ້ຖືກສ້າງຂື້ນເພື່ອຕອບສະຫນອງຄວາມຕ້ອງການຂອງໂຄງການຂູດຂໍ້ມູນ. ມັນສະຫນອງທຸກສິ່ງທຸກຢ່າງທີ່ຕ້ອງການສໍາລັບການຂູດຂະຫນາດພາຍໃນຂອງຕົວທ່ອງເວັບດຽວ. ມັນໂດດເດັ່ນຍ້ອນເວັບໄຊທ໌ທີ່ປະສົມປະສານຂອງມັນ unblocking ອັດຕະໂນມັດ, ເຊິ່ງເຮັດໃຫ້ມັນເປັນຕົວທ່ອງເວັບດຽວຂອງການຈັດລຽງຂອງມັນໃນທົ່ວໂລກ.
Scraping Browser ໃຫ້ຜູ້ໃຊ້ເຂົ້າເຖິງຄຸນນະສົມບັດທີ່ເຂັ້ມແຂງທີ່ເກີນກວ່າຕົວທ່ອງເວັບອັດຕະໂນມັດແລະບໍ່ມີຫົວ, ໃຫ້ພວກເຂົາໄດ້ຮັບຫຼາຍກວ່າສະຄິບທີ່ຍາກທີ່ສຸດແລະອຸປະສັກຂອງເວັບໄຊທ໌ສໍາລັບການກວດພົບ bot.
ການຂູດຂໍ້ມູນແມ່ນມີປະສິດຕິຜົນຫຼາຍຂຶ້ນແລະບໍ່ຫຍຸ້ງຍາກເນື່ອງຈາກຄຸນສົມບັດການປັບອັດຕະໂນມັດຂອງມັນ, ເຊິ່ງສາມາດຈັດການບລັອກສົດໆ, ການແກ້ໄຂ CAPTCHA, ລາຍນິ້ວມື, ແລະການພະຍາຍາມອີກຄັ້ງ, ແລະປະກົດວ່າເປັນຜູ້ໃຊ້ທີ່ແທ້ຈິງ.
ການນໍາໃຊ້ AI ເພື່ອ outsmart ລະບົບການກວດສອບ bot
ໂດຍການນໍາໃຊ້ເຕັກໂນໂລຊີ AI ທີ່ທັນສະໄຫມ, Scraping Browser ສາມາດ outwit ລະບົບ bot-detection ແລະສືບຕໍ່ປັບປ່ຽນຍຸດທະສາດຂອງເຂົາເຈົ້າ. ເພື່ອປົດລັອກຫນ້າເວັບທີ່ດີກວ່າ, Scraping Browser ຮຽນຮູ້ຈາກຄວາມພະຍາຍາມຂອງລະບົບເຫຼົ່ານີ້ໃນການກວດສອບ ແລະສະກັດກັ້ນຄວາມພະຍາຍາມຂູດ ແລະດັດແປງພຶດຕິກໍາຂອງມັນໃຫ້ເໝາະສົມ.
ມັນດີກວ່າປະສິດທິພາບຂອງຕົວແທນທົ່ວໄປໂດຍການຮຽນແບບພຶດຕິກໍາຂອງຕົວທ່ອງເວັບທີ່ໃຊ້ໂດຍຜູ້ໃຊ້ທີ່ແທ້ຈິງ. ດັ່ງນັ້ນ, ລູກຄ້າອາດຈະສຸມໃສ່ເປົ້າຫມາຍຂອງພວກເຂົາສໍາລັບການຂູດຂໍ້ມູນໂດຍບໍ່ຈໍາເປັນຕ້ອງຈັດການກັບຄວາມຫຍຸ້ງຍາກແລະຄ່າໃຊ້ຈ່າຍຂອງຂັ້ນຕອນການກວດສອບ bot ຢ່າງຕໍ່ເນື່ອງ.
b. Web Scraper IDE
ເຄື່ອງມືຂູດເວັບທີ່ເຂັ້ມແຂງທີ່ສ້າງຂຶ້ນສໍາລັບນັກພັດທະນາ, Web Scraper IDE ສາມາດຈັດການກັບວຽກງານການຂູດທີ່ສັບສົນ. ມັນຫຼຸດລົງເວລາການພັດທະນາຢ່າງຫຼວງຫຼາຍໃນຂະນະທີ່ສະຫນອງການຂະຫຍາຍທີ່ບໍ່ມີຂອບເຂດຍ້ອນການແກ້ໄຂທີ່ເປັນເຈົ້າພາບຢ່າງສົມບູນແລະລັກສະນະການຂູດທີ່ສ້າງຂຶ້ນກ່ອນ. ແອັບພລິເຄຊັນຊ່ວຍໃຫ້ການສ້າງເຄື່ອງຂູດອອນໄລນ໌ຢ່າງໄວວາແລະສາມາດຂະຫຍາຍໄດ້ໂດຍການສະຫນອງແມ່ແບບລະຫັດແລະຟັງຊັນ JavaScript ທີ່ກຽມພ້ອມຈາກເວັບໄຊທ໌ທີ່ນິຍົມ.
ທຸກສິ່ງທຸກຢ່າງທີ່ຕ້ອງການສໍາລັບການຂູດເວັບທີ່ປະສົບຜົນສໍາເລັດແມ່ນສະຫນອງໃຫ້ໂດຍ Web Scraper IDE. ມັນເປັນການແກ້ໄຂທີ່ສົມບູນແບບສໍາລັບການສະກັດເອົາຂໍ້ມູນອອນໄລນ໌ນັບຕັ້ງແຕ່ທາງເລືອກການເຊື່ອມໂຍງຊ່ວຍໃຫ້ລູກຄ້າສາມາດວາງແຜນການລວບລວມຂໍ້ມູນຫຼືເປີດຕົວຜ່ານ API ແລະເຊື່ອມຕໍ່ກັບລະບົບການເກັບຮັກສາຕົ້ນຕໍ.
ໃຊ້ມັນແນວໃດ? - ຄູສອນ
ທໍາອິດ, ໄປຫາ dashboard ຜູ້ໃຊ້ຢູ່ໃນເວັບໄຊທ໌.

ໃຫ້ເລີ່ມຕົ້ນດ້ວຍຂັ້ນຕອນຂອງພວກເຮົາທີ່ຈະຂູດ Instagram.
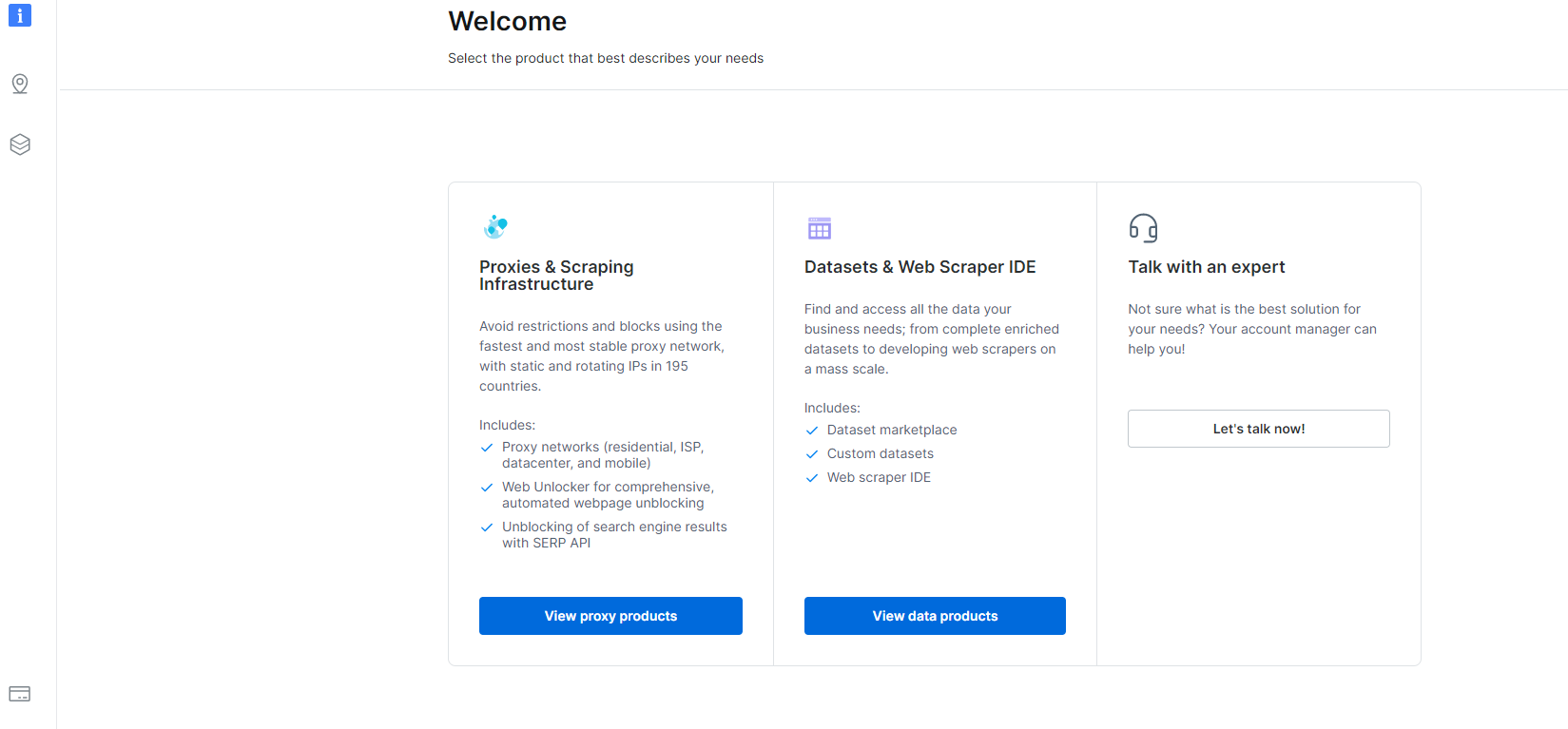
1- ທ່ອງໄປຫາ Dashboard ແລະຄລິກໃສ່ຊຸດຂໍ້ມູນ & Web Scraper IDE ພາກ.
2- ເມື່ອ, ເຈົ້າຢູ່ທີ່ນັ້ນ, ໃຫ້ຄລິກໃສ່ My Scrapers.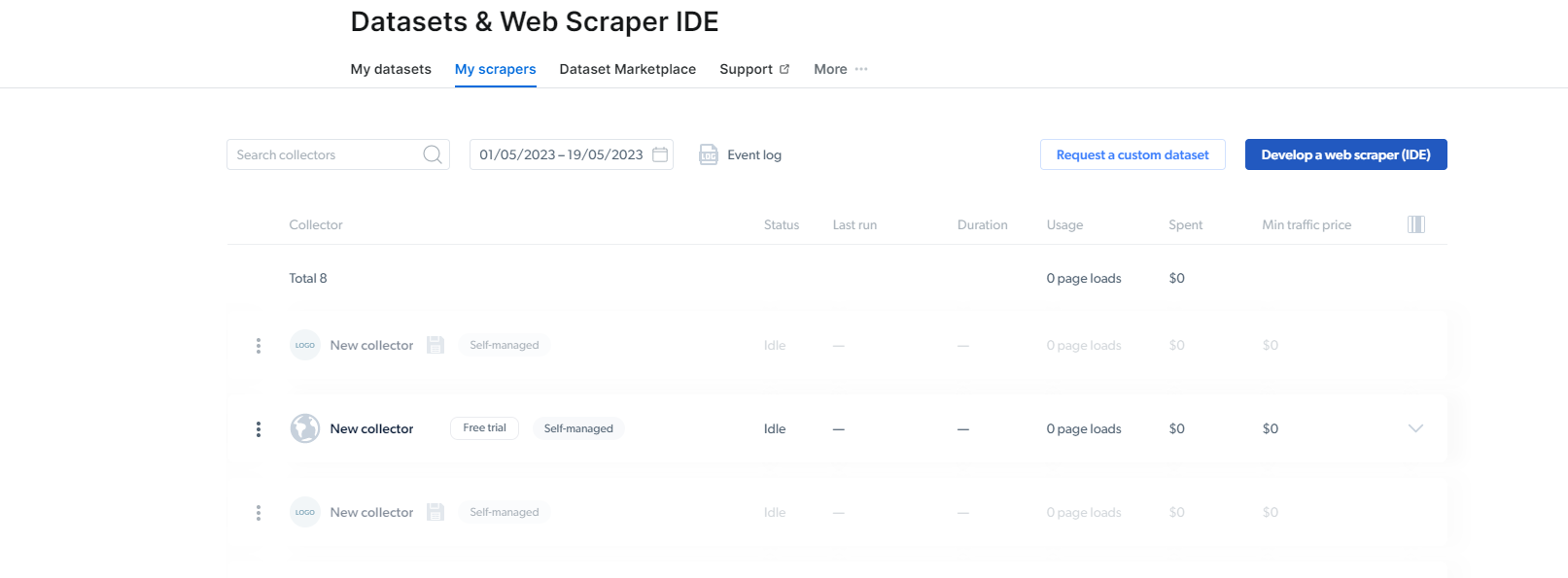
ທີ່ນີ້, ທ່ານຈໍາເປັນຕ້ອງຄລິກໃສ່ "ພັດທະນາເວັບ scraper (IDE)". ທີ່ນີ້ພວກເຮົາຈະສ້າງ scraper ຂອງພວກເຮົາສໍາລັບ Instagram.
3- ຕອນນີ້, ພວກເຮົາຈໍາເປັນຕ້ອງໄດ້ພັດທະນາເວັບ scraper ໃຫມ່. ພຽງແຕ່ສໍາລັບຕົວຢ່າງນີ້, ຂ້ອຍເລືອກທີ່ຈະຂູດບັນຊີ "NASA". ນີ້ແມ່ນພຽງແຕ່ສໍາລັບ sake ຂອງຕົວຢ່າງນີ້.
ດັ່ງນັ້ນ, ລະຫັດຂອງຂ້ອຍຈະມີລັກສະນະນີ້:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
ທ່ານຈໍາເປັນຕ້ອງຄລິກໃສ່ປຸ່ມ 'ຫຼິ້ນ' ໃນດ້ານຂວາເທິງເພື່ອແລ່ນລະຫັດນີ້.
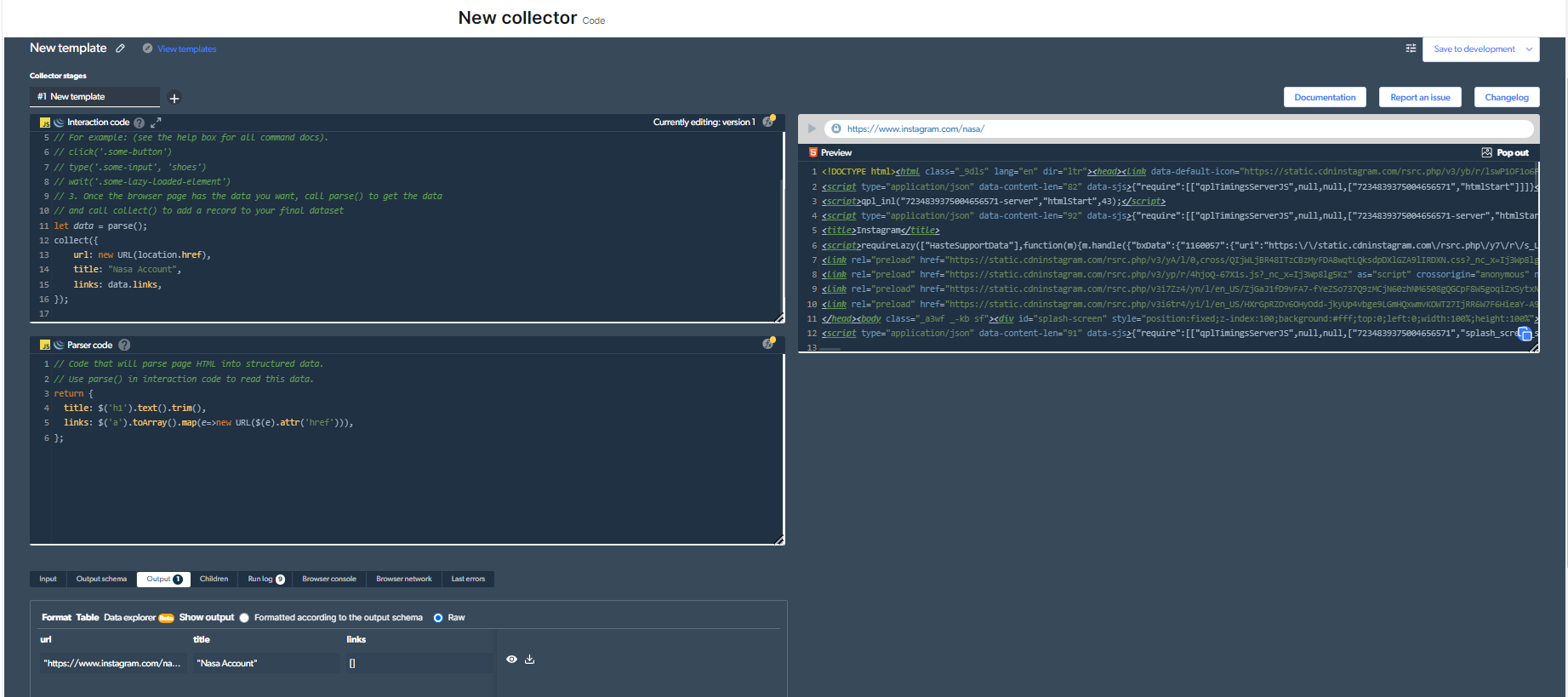
4- ໃນປັດຈຸບັນ, ພວກເຮົາຈະມີຜົນຜະລິດ.
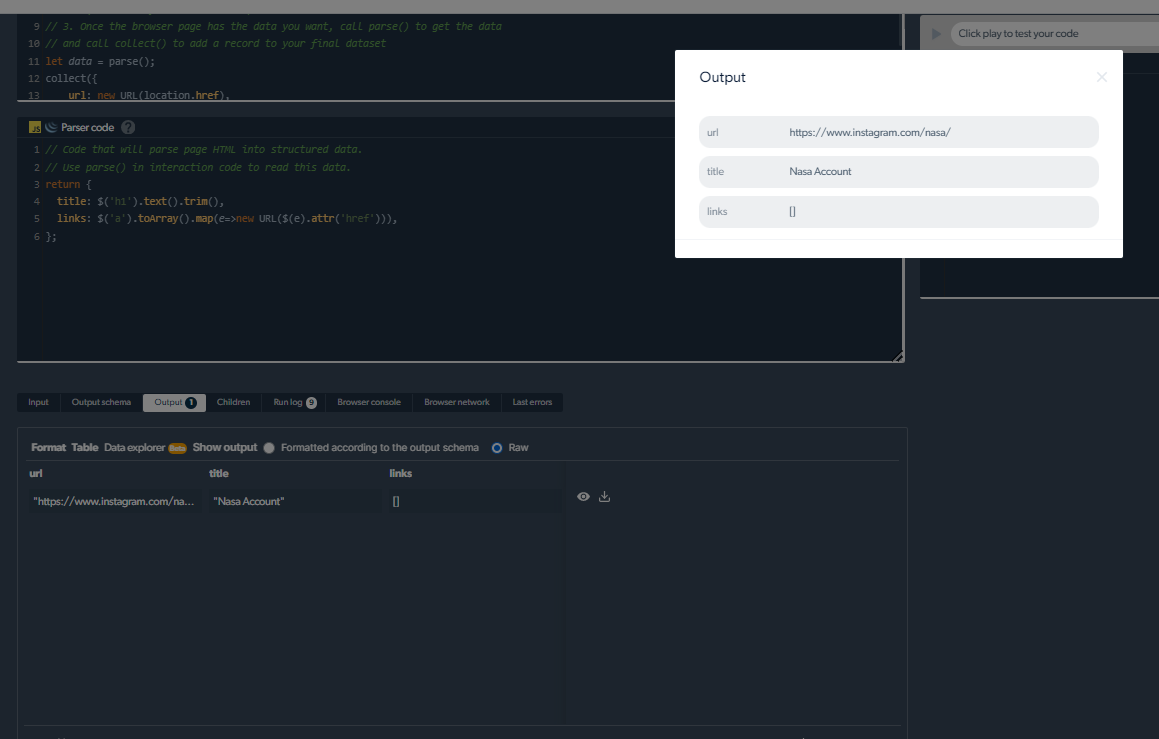
ການຈັດການບັນຫາການຂູດ
ຂໍ້ຄວາມ Instagram ທີ່ມີ "ປຸ່ມສະແດງເພີ່ມເຕີມ" ອາດຈະເປັນການຍາກສໍາລັບນັກຂູດຈັບພາບ. ຢ່າງໃດກໍຕາມ, ເຄື່ອງຂູດ Instagram ຈາກ Bright Data ແມ່ນເຮັດເພື່ອຈັດການກັບຄວາມສັບສົນດັ່ງກ່າວຢ່າງສໍາເລັດຜົນ. ເຄື່ອງຂູດເຫຼົ່ານີ້ມີທັກສະທີ່ທັນສະ ໄໝ ເພື່ອຂ້າມຜ່ານ pagination ແລະການໂຫຼດປຸ່ມເພີ່ມເຕີມ.
ເຄື່ອງຂູດຂໍ້ມູນ Instagram ຂອງ Bright Data ຈັດການຄວາມຫຍຸ້ງຍາກເຫຼົ່ານີ້ຢ່າງມີປະສິດທິພາບເພື່ອເຮັດໃຫ້ການຂຸດຄົ້ນຂໍ້ມູນຢ່າງລະອຽດ, ຊ່ວຍໃຫ້ທ່ານສາມາດລວບລວມຂໍ້ມູນທັງຫມົດທີ່ຕ້ອງການສໍາລັບການວິເຄາະຫຼືການສຶກສາຂອງທ່ານ.
ທ່ານສາມາດໄດ້ຮັບປະມານສິ່ງທ້າທາຍທີ່ນໍາສະເຫນີໂດຍລັກສະນະແບບເຄື່ອນໄຫວຂອງຂໍ້ຄວາມ Instagram ໂດຍການນໍາໃຊ້ເຄື່ອງມືຂູດເຫຼົ່ານີ້.
c. ຊຸດຂໍ້ມູນທີ່ເກັບໄວ້ລ່ວງໜ້າ
Bright Data ເຂົ້າໃຈວ່າບໍ່ແມ່ນທຸກຄົນຕ້ອງການທີ່ຈະດໍາເນີນການ scraper ຂອງເຂົາເຈົ້າ. ພວກເຂົາເຈົ້າສະຫນອງຊຸດຂໍ້ມູນທີ່ເກັບກໍາໄວ້ລ່ວງຫນ້າສໍາລັບ Instagram ເພື່ອດຶງດູດຜູ້ບໍລິໂພກດັ່ງກ່າວ.
ຊຸດຂໍ້ມູນນີ້ໃຫ້ຂໍ້ມູນທີ່ເປັນປະໂຫຍດຫຼາຍຢ່າງເຊັ່ນ: ຜູ້ຕິດຕາມ, ໂປຣໄຟລ໌, ໂພສ ແລະອື່ນໆອີກ.
Bright Data ສະເໜີທາງເລືອກການປັບແຕ່ງເພື່ອປັບແຕ່ງຊຸດຂໍ້ມູນໃຫ້ເປັນສ່ວນຕົວຕາມຄວາມຕ້ອງການຂອງທ່ານ, ບໍ່ວ່າທ່ານຕ້ອງການຊຸດຂໍ້ມູນທັງໝົດ ຫຼືຊຸດຍ່ອຍຂອງຂໍ້ມູນສະເພາະ. ວິທີການນີ້ຫຼີກເວັ້ນການກໍ່ສ້າງແລະການຄຸ້ມຄອງເຄື່ອງຂູດ, ໃຫ້ທ່ານມີຂໍ້ມູນທີ່ພ້ອມທີ່ຈະໃຊ້ສໍາລັບການວິເຄາະແລະຄວາມເຂົ້າໃຈ.
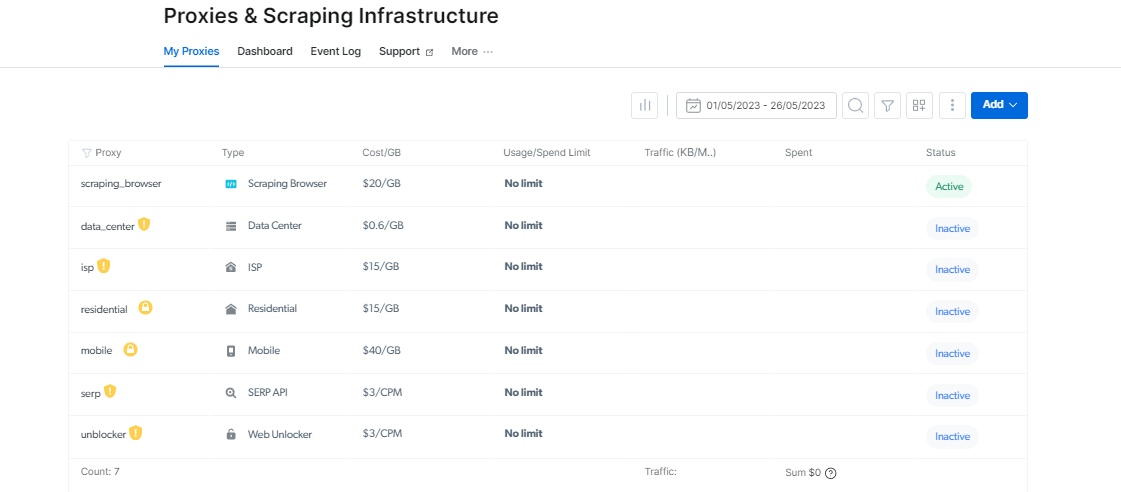
ຕອນນີ້, ໃຫ້ກວດເບິ່ງໂຄງສ້າງພື້ນຖານທີ່ເຮັດໃຫ້ເຄື່ອງມືເຫຼົ່ານີ້ມີປະສິດທິພາບຫຼາຍ: ໂຄງລ່າງພື້ນຖານຂອງຕົວແທນແລະ Web Unlocker.
ປົດປ່ອຍພະລັງຂອງຕົວແທນ
ການນໍາໃຊ້ proxies ມັນເປັນສິ່ງ ສຳ ຄັນໃນລະຫວ່າງການຂູດເວັບເພື່ອຮັບປະກັນວ່າການກະ ທຳ ຂອງທ່ານບໍ່ຖືກສັງເກດເຫັນ.
ຂໍ້ມູນສົດໃສສະຫນອງການຄັດເລືອກກ້ວາງຂອງ ບໍລິການຕົວແທນ ທີ່ປັບແຕ່ງຕາມຄວາມຕ້ອງການຂອງທ່ານ. ທ່ານສາມາດເລືອກເອົາຈາກ ຕົວແທນທີ່ຢູ່ອາໄສ, ເຊິ່ງສະເຫນີຫຼາຍກວ່າ 72 ລ້ານ IP ໝູນວຽນຈາກອຸປະກອນຕົວຈິງໃນ 195 ປະເທດ.
ທ່ານສາມາດເລືອກ ISP Proxies, ເຊິ່ງສະເຫນີ 700,000+ IP ເຮືອນທີ່ແທ້ຈິງໃນທົ່ວໂລກສໍາລັບການນໍາໃຊ້ໃນໄລຍະຍາວ; Datacenter Proxies, ເຊິ່ງມີ 770,000+ IPs ທີ່ແບ່ງປັນຈາກສະຖານທີ່ຕັ້ງພູມສາດໃດໜຶ່ງ; ແລະ Mobile Proxies, ເຊິ່ງເປັນເຄືອຂ່າຍມືຖື 3G/4G ແທ້ຈິງທີ່ໃຫຍ່ທີ່ສຸດທີ່ມີ 7,000,000+ IPs.
ດ້ວຍການໃຊ້ຕົວແທນເຫຼົ່ານີ້, ຄົນເຮົາສາມາດເກັບກຳຂໍ້ມູນໄດ້ຢ່າງງ່າຍດາຍໃນຂະນະທີ່ຕັ້ງຕົວເປັນຜູ້ໃຊ້ທີ່ໄດ້ຮັບອະນຸຍາດໃນຫຼາຍໆບ່ອນ.

ຕົວຈັດການພຣັອກຊີ: ເຮັດໃຫ້ການຈັດການພຣັອກຊີງ່າຍຂຶ້ນ
ການຄຸ້ມຄອງຕົວແທນຈໍານວນຫນຶ່ງອາດຈະເປັນການຍາກ, ແຕ່ Proxy Manager ເຮັດໃຫ້ມັນງ່າຍດາຍ.
ການໂຕ້ຕອບ open-source ນີ້ຊ່ວຍໃຫ້ທ່ານສາມາດຈັດການຕົວແທນທັງຫມົດຂອງທ່ານຈາກເວທີດຽວ. ບອກລາກັບການຕັ້ງຄ່າ ແລະສະຫຼັບຕົວແທນດ້ວຍຕົນເອງ. ຕົວຈັດການພຣັອກຊີເຮັດໃຫ້ຂັ້ນຕອນງ່າຍ ແລະປະຫຍັດເວລາ ແລະຄວາມພະຍາຍາມ.
ຕົວຂະຫຍາຍຂອງຕົວທ່ອງເວັບ Proxy: ປ່ຽນສະຖານທີ່ຂອງທ່ານໄດ້ຢ່າງງ່າຍດາຍ
ທ່ານຈໍາເປັນຕ້ອງເກັບກໍາຂໍ້ມູນເວັບໄຊຕ໌ຈາກຫຼາຍຂົງເຂດບໍ? ທ່ານຖືກຄຸ້ມຄອງໂດຍສ່ວນຂະຫຍາຍຂອງຕົວທ່ອງເວັບພຣັອກຊີຂອງພວກເຮົາ. ທ່ານສາມາດປ່ຽນສະຖານທີ່ການຊອກຫາຂອງທ່ານດ້ວຍການຄລິກດຽວເພື່ອໄດ້ຮັບຂໍ້ມູນຂ່າວສານພາກພື້ນສະເພາະ.
ໃຊ້ປະໂຫຍດຈາກຄວາມຍືດຫຍຸ່ນແລະຄວາມງ່າຍດາຍຂອງການເກັບກໍາຂໍ້ມູນຈາກຫຼາຍຂົງເຂດໂດຍບໍ່ມີຄວາມສັບສົນທາງດ້ານເຕັກໂນໂລຢີ.
ມັນເຮັດວຽກແນວໃດ? - ຄູສອນ
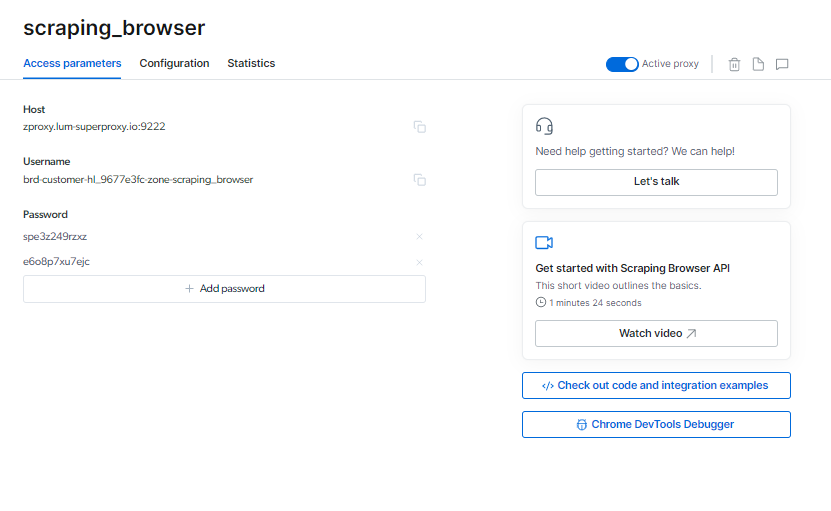
ທ່ານສາມາດຊອກຫາສະຖານທີ່ຂອງທ່ານ ຕົວທ່ອງເວັບຂູດ ຂໍ້ມູນການເຂົ້າສູ່ລະບົບຢູ່ໃນຫນ້າພາລາມິເຕີການເຂົ້າເຖິງ, ເຊິ່ງຈະຖືກນໍາໃຊ້ໃນເວລາທີ່ທ່ານເລີ່ມຕົ້ນເຊດຊັນຂອງຕົວທ່ອງເວັບໃຫມ່.
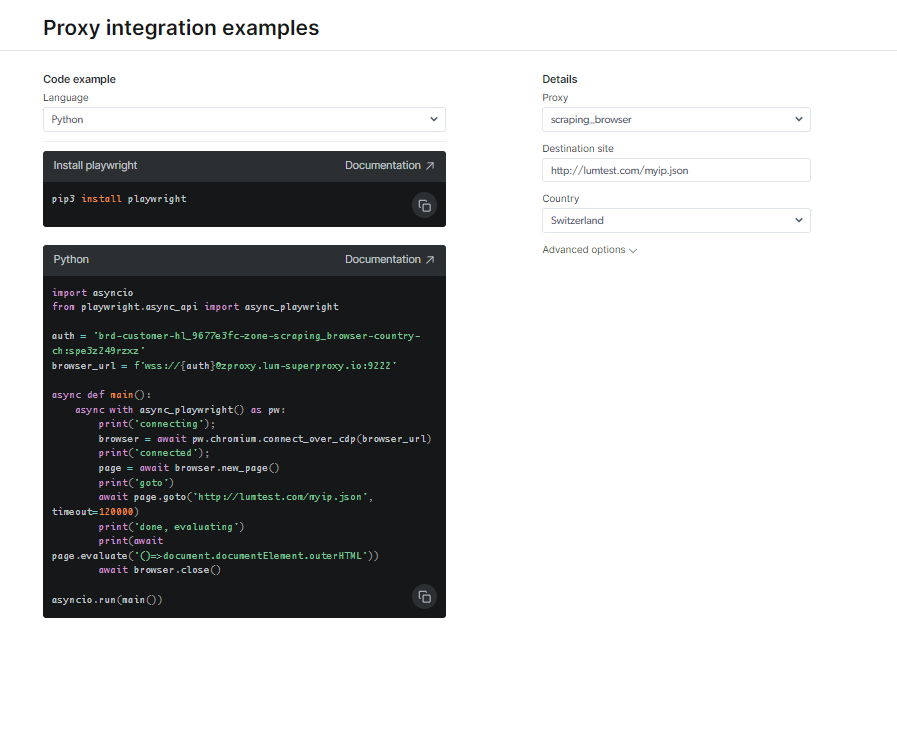
ກວດເບິ່ງເອກະສານແລະຕົວຢ່າງລະຫັດ, ລວມທັງສະຄິບຕົວຢ່າງທີ່ມີປະໂຫຍດຢ່າງເຕັມທີ່ທີ່ພ້ອມທີ່ຈະໃຊ້, ຫຼືເບິ່ງວິດີໂອຄໍາແນະນໍາການເລີ່ມຕົ້ນໂດຍຫຍໍ້. ຍົກຕົວຢ່າງ; ນີ້ແມ່ນ a ລະຫັດ Python ຕົວຢ່າງສໍາລັບການເຊື່ອມໂຍງ:
ຕ້ອງການຄວາມຊ່ວຍເຫຼືອບໍ? ສໍາລັບການສົນທະນາກັບຫນຶ່ງໃນຜູ້ຊ່ຽວຊານ, ທ່ານສາມາດຄລິກໃສ່ໄອຄອນສົນທະນາ.
ຈົ່ງຈື່ໄວ້ວ່າທ່ານມີການຄວບຄຸມທີ່ສົມບູນໃນກອງປະຊຸມຂອງຕົວທ່ອງເວັບໃນຂະນະທີ່ໃຊ້ Scraping Browser ແລະສາມາດດໍາເນີນການໃດໆທີ່ສະຫນັບສະຫນູນໂດຍ Puppeteer, Playwright, ຫຼືການນໍາໃຊ້ Chrome DevTools Protocol ໂດຍກົງ.
ການປົດລັອກເວັບໄຊທ໌ໂດຍບໍ່ມີການບລັອກ
Scraping Browser ຖືກສ້າງຂື້ນເພື່ອປະຕິບັດງານໃນລະດັບແລະຕາມຄວາມຕ້ອງການ. ທ່ານບໍ່ຈໍາເປັນຕ້ອງກັງວົນກ່ຽວກັບການຖືກຫ້າມ; ທ່ານສາມາດເລີ່ມຕົ້ນຂຶ້ນຂອງຕົວທ່ອງເວັບຫຼາຍເທົ່າທີ່ທ່ານຕ້ອງການ.
ຄວາມສາມາດນີ້, ເມື່ອຈັບຄູ່ກັບຄວາມເຂັ້ມແຂງຂອງຕົວແທນ, ຮັບປະກັນການລວບລວມຂໍ້ມູນຢ່າງຕໍ່ເນື່ອງ, ຊ່ວຍໃຫ້ທ່ານໄດ້ຮັບຂໍ້ມູນທີ່ທ່ານຕ້ອງການຢ່າງມີປະສິດທິພາບ.
ທັກສະການປົດລັອກໃນຕົວຂອງຕົວທ່ອງເວັບ Scraping ແລະເຄືອຂ່າຍຕົວແທນທີ່ເຂັ້ມແຂງຊ່ວຍໃຫ້ທ່ານປະຫຍັດເວລາ, ເພີ່ມປະສິດທິພາບການຜະລິດ, ແລະຄົ້ນພົບໂອກາດໃຫມ່.
ທ່ານຍັງສາມາດກວດເບິ່ງສະຖິຕິຈາກຫນ້າດຽວກັນໂດຍກົງ.
ລາຄາຂອງ Scraping Browser
Bright Data ສະໜອງທາງເລືອກລາຄາທີ່ສາມາດປັບແຕ່ງໄດ້ເພື່ອຕອບສະໜອງຈຸດປະສົງທີ່ຫຼາກຫຼາຍ. ທ່ານສາມາດເລືອກເອົາບໍ່ວ່າຈະເປັນໄລຍະການເກັບເງິນປະຈໍາເດືອນຫຼືປະຈໍາປີ.
ທາງເລືອກ Pay as You Go ອະນຸຍາດໃຫ້ທ່ານຈ່າຍພຽງແຕ່ສໍາລັບສິ່ງທີ່ທ່ານໃຊ້, ໂດຍບໍ່ມີຄໍາຫມັ້ນສັນຍາທີ່ຈໍາເປັນ, ເລີ່ມຕົ້ນທີ່ $ 20.00 / GB ແລະ $ 0.1 / ຊົ່ວໂມງ.
ແຜນການເຕີບໂຕ 500 ໂດລາ ເໝາະສຳລັບທຸລະກິດທີ່ກຳລັງເຕີບໃຫຍ່, ໂດຍມີການຫຼຸດຄ່າທຳນຽມ $15.30/GB ແລະ $0.1/ຊົ່ວໂມງ.
ໄດ້ ຊຸດທຸລະກິດ, ເຊິ່ງມີລາຄາ 1000 ໂດລາ, ເປັນທາງເລືອກທີ່ນິຍົມທີ່ສຸດ, ໂດຍ Scraping Browser API ມີມູນຄ່າ $13.50/GB ແລະ $0.1/ຊົ່ວໂມງ.
ໂດຍການຕິດຕໍ່ກັບທີມງານ Bright Data ໂດຍກົງ, ຜູ້ໃຊ້ວິສາຫະກິດສາມາດເພີດເພີນກັບການປັບຂະຫນາດທີ່ບໍ່ມີຂອບເຂດ ແລະລາຄາສ່ວນບຸກຄົນ. ເລີ່ມການທົດລອງໃຊ້ຟຣີໃນມື້ນີ້ເພື່ອຄົ້ນພົບທ່າແຮງຂອງຕົວທ່ອງເວັບຂູດຂໍ້ມູນ Bright Data ແລະປ່ຽນຄວາມພະຍາຍາມຂູດອອນໄລນ໌ຂອງທ່ານ.
ເວັບໄຊທ໌ Unlocker
Web Unlocker ເປັນເຄື່ອງມືທີ່ມີທ່າແຮງທີ່ສ້າງຂື້ນເພື່ອໃຫ້ໄດ້ເກີນຂອບເຂດຈໍາກັດຂອງເວັບໄຊທ໌ແລະສະຫນອງການຂຸດຄົ້ນຂໍ້ມູນໄດ້ງ່າຍ. ມັນເອົາຊະນະສິ່ງທ້າທາຍຫຼາຍຢ່າງ, ລວມທັງ cookies, ຕົວແທນຜູ້ໃຊ້ຂອງຕົວທ່ອງເວັບສະເພາະເວັບໄຊທ໌, ແລະການແກ້ໄຂ captcha, ໂດຍການນໍາໃຊ້ຂັ້ນຕອນອັດຕະໂນມັດ.
ໂດຍການນໍາໃຊ້ການຫມຸນທີ່ຢູ່ IP ອັດຕະໂນມັດ, ຜູ້ໃຊ້ Web Unlocker ອາດຈະສືບຕໍ່ຂູດເວັບໄຊທ໌ເປົ້າຫມາຍ, ຮັບປະກັນການເຂົ້າເຖິງຂໍ້ມູນທີ່ສໍາຄັນຢ່າງຕໍ່ເນື່ອງ.
ປັບປຸງການເດີນທາງການຮ້ອງຂໍຂອງຜູ້ພັດທະນາ
ຄຸນສົມບັດຫຼາຍຢ່າງເຮັດໃຫ້ Web Unlocker ເປັນທີ່ນິຍົມໃນບັນດານັກພັດທະນາ. ໂຄງການປັບປຸງຂະບວນການເກັບກໍາຂໍ້ມູນໂດຍການກໍານົດຕົວແທນຜູ້ໃຊ້ທີ່ຕ້ອງການສໍາລັບແຕ່ລະເວັບໄຊທ໌, ປະຫຍັດເວລາແລະຊັບພະຍາກອນທີ່ມີຄຸນຄ່າ.
Web Unlocker ປັບຕົວໃນເວລາທີ່ແທ້ຈິງເພື່ອຫຼີກເວັ້ນການກວດພົບໃນການຕອບສະຫນອງຕໍ່ກົນລະຍຸດທີ່ປ່ຽນແປງຢ່າງຕໍ່ເນື່ອງທີ່ໃຊ້ໂດຍການບລັອກ bots, ຮັບປະກັນການເຂົ້າເຖິງເວັບໄຊທ໌ທີ່ມີຄວາມສົນໃຈຢ່າງຕໍ່ເນື່ອງ. ສູດການຄິດໄລ່ການຮຽນຮູ້ເຄື່ອງຈັກຂອງເວທີສາມາດແກ້ໄຂ captchas ໄດ້ຢ່າງວ່ອງໄວ, ເປັນອຸປະສັກເລື້ອຍໆຕໍ່ການລິເລີ່ມການເກັບຂໍ້ມູນ.

ລາຄາຂອງ Web Unlocker
ເລີ່ມຕົ້ນຢູ່ທີ່ປະມານ $ 2.03 ຕໍ່ພັນຄໍາຮ້ອງຂໍ (CPM), Web Unlocker ສະເຫນີລາຄາຫຼາຍທາງເລືອກເພື່ອຕອບສະຫນອງຄວາມຕ້ອງການຕ່າງໆ. ການທົດລອງໃຊ້ຟຣີ 7 ມື້ແມ່ນມີໃຫ້ຜູ້ໃຊ້ເພື່ອເລີ່ມຕົ້ນ ແລະໃຫ້ພວກເຂົາທົດສອບຄຸນສົມບັດຂອງ Web Unlocker ກ່ອນທີ່ຈະດໍາເນີນການ.
Web Unlocker ມີຄວາມສາມາດໃນການປັບຕົວເພື່ອສະຫນັບສະຫນູນຮູບແບບການນໍາໃຊ້ຕ່າງໆ, ໂດຍບໍ່ຄໍານຶງເຖິງວ່າຜູ້ບໍລິໂພກຕ້ອງການວິທີການຈ່າຍຕາມທີ່ທ່ານໄປຫຼືຕ້ອງການແຜນການທີ່ກໍາຫນົດເອງທີ່ເຫມາະສົມກັບຄວາມຕ້ອງການສະເພາະຂອງພວກເຂົາ. ນອກຈາກນັ້ນ, ຜູ້ທີ່ເລືອກແຜນການລາຄາໃນໄລຍະຍາວສາມາດປະຫຍັດໄດ້ 32%.
ການປຽບທຽບລະຫວ່າງ Web Unlocker ກັບ Proxies ທີ່ຈັດການດ້ວຍຕົນເອງ
Web Unlocker ສະຫນອງຜົນປະໂຫຍດທັນທີຈໍານວນຫລາຍຫຼາຍກວ່າຕົວແທນທີ່ຈັດການດ້ວຍຕົນເອງ. ສໍາລັບການປະຕິບັດທີ່ລຽບງ່າຍ, ມັນສະຫນອງເຕັກນິກການເຊື່ອມໂຍງຢ່າງກວ້າງຂວາງທີ່ປະສົມປະສານຫນ້າທີ່ super proxy ແລະ Proxy Manager. ຜູ້ໃຊ້ອາດຈະຂະຫຍາຍການປະຕິບັດການເກັບກໍາຂໍ້ມູນຂອງເຂົາເຈົ້າຢ່າງມີປະສິດທິຜົນທີ່ມີຈໍານວນບໍ່ຈໍາກັດຂອງການເຊື່ອມຕໍ່ພ້ອມກັນ.
Web Unlocker ສະໜອງການປົດບລັອກອັດຕະໂນມັດ, ແກ້ໄຂ CAPTCHAs, ແລະຈັດການການດັດແກ້ markup ຢູ່ໃນເວັບໄຊທ໌ເປົ້າຫມາຍຢ່າງສໍາເລັດຜົນ.
ແພລະຕະຟອມຮັບປະກັນການສະກັດຂໍ້ມູນຢ່າງຕໍ່ເນື່ອງແລະເຊື່ອຖືໄດ້ໂດຍການປະຕິບັດລະບົບການພະຍາຍາມຄືນໃຫມ່ອັດຕະໂນມັດແລະເຮັດໃຫ້ການໂທ asynchronous ສໍາລັບບາງໂດເມນ. ນອກຈາກນັ້ນ, ການເກັບກໍາຂໍ້ມູນ HTTP header ທີ່ມີການຂະຫຍາຍຕົວຂອງ Unlocker, cookies ຂອງຕົວທ່ອງເວັບສະເພາະເວັບໄຊທ໌, ແລະ simulated gadgets ອະນຸຍາດໃຫ້ຜູ້ໃຊ້ຍັງບໍ່ໄດ້ຮັບການກວດພົບໃນຂະນະທີ່ເຮັດໃຫ້ພວກເຂົາໄດ້ຮັບຂໍ້ມູນອອນໄລນ໌ໃນເວລາຈິງ.
ຄວາມຄິດສຸດທ້າຍແລະສິ່ງທີ່ສໍາຄັນທີ່ຕ້ອງຈື່
ສຸດທ້າຍ, ໃນຂະນະທີ່ໃຊ້ Bright Data ສໍາລັບການຂູດຂໍ້ມູນ Instagram, ມັນເປັນສິ່ງສໍາຄັນທີ່ຈະຮັກສາຈຸດສໍາຄັນຈໍານວນຫນຶ່ງຢູ່ໃນໃຈ.
ກະລຸນາຮັບຊາບວ່າຄວາມສາມາດໃນການຂູດຂອງພວກມັນຖືກຈໍາກັດຢູ່ໃນຂໍ້ມູນສາທາລະນະ, ໂດຍການປະຕິບັດດ້ານຈັນຍາບັນ.
ທ່ານຄວນປະຕິບັດຕາມເງື່ອນໄຂການບໍລິການແລະນະໂຍບາຍຄວາມເປັນສ່ວນຕົວຂອງ Instagram ສະເຫມີ. ການຂູດຂີ້ເຫຍື້ອຄວນເຮັດຢ່າງມີຈັນຍາບັນແລະຄວາມຮັບຜິດຊອບ, ໂດຍບໍ່ມີການລ່ວງລະເມີດສິດທິຂອງຜູ້ໃຊ້ຫຼືລະເມີດກົດຫມາຍໃດໆ.
ອັນທີສອງ, ປັບປຸງແລະປັບຕົວກໍານົດການຂູດຂອງທ່ານຢ່າງເປັນປົກກະຕິເພື່ອຮັບປະກັນຄວາມຖືກຕ້ອງແລະຄວາມກ່ຽວຂ້ອງຂອງຂໍ້ມູນທີ່ດຶງມາ. ເວທີແລະສູດການຄິດໄລ່ຂອງ Instagram ແມ່ນມີການປ່ຽນແປງ, ດັ່ງນັ້ນທ່ານຈຶ່ງຕ້ອງປ່ຽນແປງກົນລະຍຸດການຂູດຂອງທ່ານຕາມຄວາມເຫມາະສົມ.
ສຸດທ້າຍ, ໃຊ້ການຊ່ວຍເຫຼືອແລະຊັບພະຍາກອນຂອງແພລະຕະຟອມ Bright Data ເພື່ອເພີ່ມປະສິດທິພາບຄວາມສໍາເລັດຂອງຄວາມພະຍາຍາມຂູດ Instagram ຂອງທ່ານ. ມີສ່ວນຮ່ວມກັບເອກະສານ, ບົດສອນ, ແລະການບໍລິການລູກຄ້າຂອງເຂົາເຈົ້າເພື່ອປັບປຸງຄວາມຮູ້ຂອງທ່ານກ່ຽວກັບເຄື່ອງມືຂູດຂອງເຂົາເຈົ້າ.
ທ່ານສາມາດໄດ້ຮັບຄວາມເຂົ້າໃຈທີ່ເປັນປະໂຫຍດ, ມີອິດທິພົນຕໍ່ການຕັດສິນໃຈທີ່ສະຫລາດ, ແລະປະສົບຜົນສໍາເລັດໃນການລິເລີ່ມທີ່ຂັບເຄື່ອນຂໍ້ມູນຂອງທ່ານໃນເວທີ Instagram ໂດຍປະຕິບັດຕາມການປະຕິບັດທີ່ດີທີ່ສຸດເຫຼົ່ານີ້ແລະນໍາໃຊ້ຄວາມເຂັ້ມແຂງຂອງຄວາມສາມາດໃນການຂູດຂໍ້ມູນ Instagram ຂອງ Bright Data.





ອອກຈາກ Reply ເປັນ