ສາລະບານ[ເຊື່ອງ][ສະແດງ]
ບໍລິສັດກໍາລັງເກັບກໍາຂໍ້ມູນຫຼາຍກວ່າທີ່ເຄີຍເປັນຍ້ອນວ່າເຂົາເຈົ້າອີງໃສ່ມັນຫຼາຍຂຶ້ນເພື່ອແຈ້ງການຕັດສິນໃຈທາງທຸລະກິດທີ່ສໍາຄັນ, ປັບປຸງການສະເຫນີຜະລິດຕະພັນ, ແລະໃຫ້ບໍລິການລູກຄ້າທີ່ດີກວ່າ.
ດ້ວຍປະລິມານຂໍ້ມູນທີ່ຖືກສ້າງຂື້ນໃນອັດຕາຕົວເລກ, ຟັງໄດ້ໃຫ້ຂໍ້ໄດ້ປຽບຫຼາຍຢ່າງສໍາລັບການປະມວນຜົນຂໍ້ມູນແລະການວິເຄາະ, ລວມທັງການຂະຫຍາຍ, ຄວາມຫນ້າເຊື່ອຖື, ແລະຄວາມພ້ອມ.
ໃນລະບົບນິເວດເມຄ, ຍັງມີເຄື່ອງມືແລະເຕັກໂນໂລຢີຫຼາຍຢ່າງສໍາລັບການປະມວນຜົນຂໍ້ມູນແລະການວິເຄາະ. ສອງປະເພດຂອງໂຄງສ້າງການເກັບຮັກສາຂໍ້ມູນໃຫຍ່ທີ່ຖືກນໍາໃຊ້ຫຼາຍທີ່ສຸດແມ່ນຄັງຂໍ້ມູນແລະຖານຂໍ້ມູນ.
ເຖິງແມ່ນວ່າການໃຊ້ Data lake ແມ່ນມີຄວາມດຶງດູດຫນ້ອຍເພາະວ່າທ່ານບໍ່ສາມາດສອບຖາມຕົວແບບແລະຂໍ້ມູນໄດ້ໃນຂະນະທີ່ມັນຍັງມີຄວາມກ່ຽວຂ້ອງ, ການຈ້າງຫ້ອງເກັບຂໍ້ມູນສໍາລັບການຖ່າຍທອດການເກັບຮັກສາຂໍ້ມູນແມ່ນສິ່ງເສດເຫຼືອ.

Wພວກເຮົາເລືອກສະຖາປັດຕະຍະກຳຄລາວປະເພດໃດ?
ພວກເຮົາຄວນພິຈາລະນາແນວຄວາມຄິດໃຫມ່ສໍາລັບ lakehouse ຂໍ້ມູນ, ຫຼືພວກເຮົາຄວນຈະພໍໃຈກັບຂໍ້ຈໍາກັດຂອງຄັງສິນຄ້າຫຼືຂໍ້ຈໍາກັດຂອງທະເລສາບ?
ສະຖາປັດຕະຍະກຳການເກັບຮັກສາຂໍ້ມູນແບບໃໝ່ທີ່ເອີ້ນວ່າ "ຖານຂໍ້ມູນ lakehouse" ປະສົມປະສານການປັບຕົວຂອງຂໍ້ມູນຂໍ້ມູນກັບການຈັດການຂໍ້ມູນຂອງຄັງຂໍ້ມູນ.
ການເຂົ້າໃຈວິທີການເກັບຮັກສາຂໍ້ມູນໃຫຍ່ຕ່າງໆແມ່ນມີຄວາມຈໍາເປັນສໍາລັບການສ້າງທໍ່ເກັບຮັກສາຂໍ້ມູນທີ່ເຊື່ອຖືໄດ້ສໍາລັບທຸລະກິດປັນຍາ (BI), ການວິເຄາະຂໍ້ມູນ, ແລະ. ການຮຽນຮູ້ເຄື່ອງຈັກ (ML) ປະລິມານວຽກ, ຂຶ້ນກັບຄວາມຕ້ອງການຂອງບໍລິສັດຂອງທ່ານ.
ໃນບົດຂຽນນີ້, ພວກເຮົາຈະເບິ່ງຢ່າງໃກ້ຊິດກ່ຽວກັບ Data Warehouse, Data Lake, ແລະ Data Lakehouse, ດ້ວຍຜົນປະໂຫຍດ, ຂໍ້ຈໍາກັດເຊັ່ນດຽວກັນກັບຂໍ້ດີແລະຂໍ້ເສຍຂອງມັນ. ໃຫ້ເລີ່ມຕົ້ນ.
Data Warehouse ແມ່ນຫຍັງ?
ຄັງເກັບຂໍ້ມູນເປັນບ່ອນເກັບຂໍ້ມູນສູນກາງທີ່ໃຊ້ໂດຍອົງການຈັດຕັ້ງເພື່ອເກັບຂໍ້ມູນປະລິມານອັນໃຫຍ່ຫຼວງຈາກຫຼາຍແຫຼ່ງ. ຄັງຂໍ້ມູນເຮັດຫນ້າທີ່ເປັນແຫຼ່ງດຽວຂອງອົງການຂອງ "ຄວາມຈິງຂໍ້ມູນ" ແລະເປັນສິ່ງຈໍາເປັນຕໍ່ການລາຍງານແລະການວິເຄາະທຸລະກິດ.
ໂດຍປົກກະຕິ, ຄັງຂໍ້ມູນລວມຊຸດຂໍ້ມູນທີ່ກ່ຽວຂ້ອງຈາກຫຼາຍແຫຼ່ງ, ເຊັ່ນ: ຄໍາຮ້ອງສະຫມັກ, ທຸລະກິດ, ແລະຂໍ້ມູນທຸລະກໍາ, ເພື່ອເກັບຮັກສາຂໍ້ມູນປະຫວັດສາດ. ກ່ອນທີ່ຈະຖືກໂຫລດເຂົ້າໄປໃນລະບົບສາງ, ຂໍ້ມູນຖືກປ່ຽນແລະເຮັດຄວາມສະອາດໃນຄັງຂໍ້ມູນເພື່ອໃຫ້ມັນສາມາດຖືກນໍາໃຊ້ເປັນຄວາມຈິງຂອງຂໍ້ມູນດຽວ.
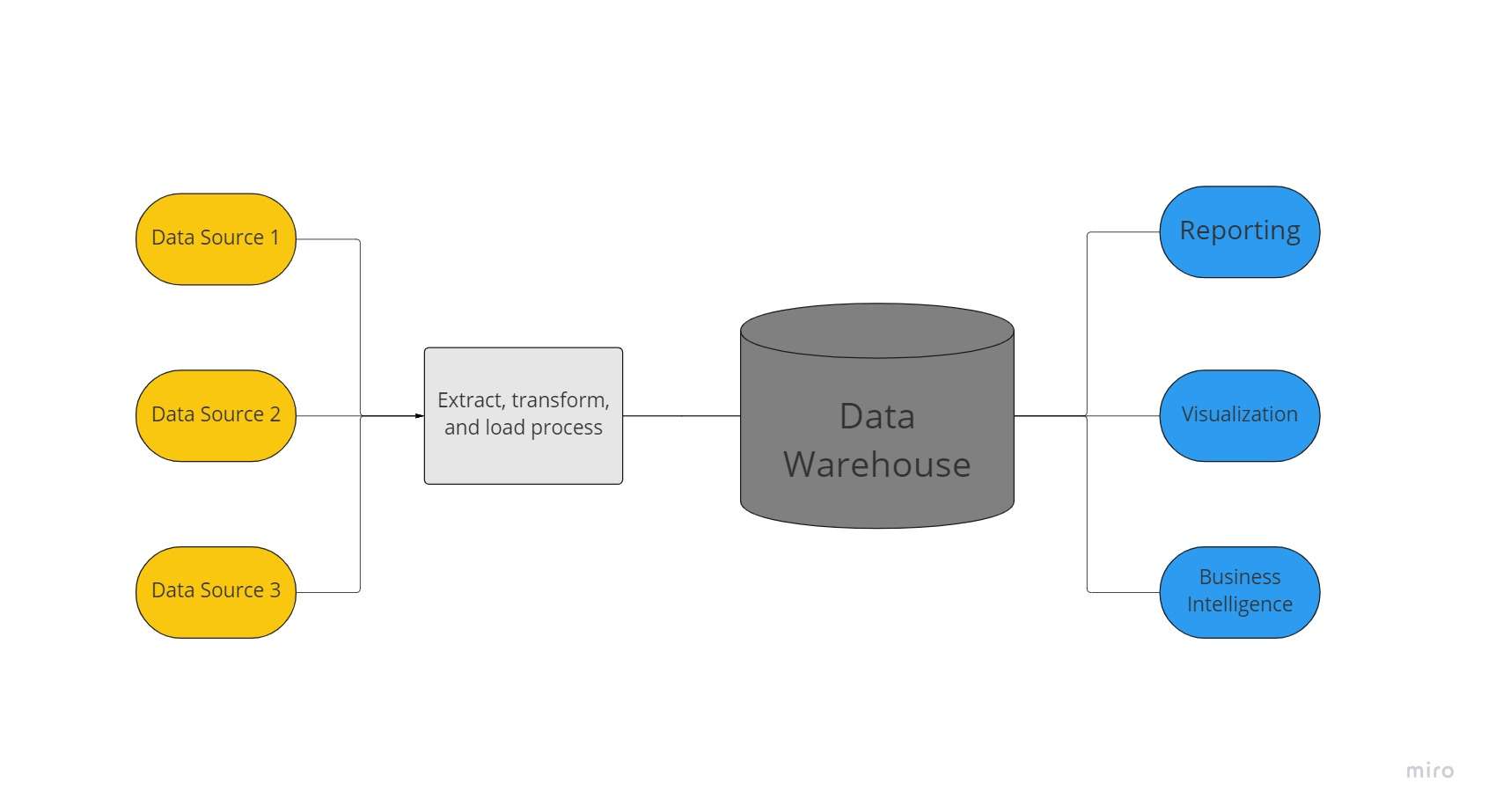
ເນື່ອງຈາກຄວາມສາມາດໃນການສະເຫນີຄວາມເຂົ້າໃຈທາງທຸລະກິດຢ່າງໄວວາຈາກທຸກຂົງເຂດຂອງບໍລິສັດ, ທຸລະກິດລົງທຶນໃນຄັງຂໍ້ມູນ. ດ້ວຍການນໍາໃຊ້ເຄື່ອງມື BI, ລູກຄ້າ SQL, ແລະອື່ນໆທີ່ບໍ່ທັນສະໄຫມ (ie, ວິທະຍາສາດທີ່ບໍ່ແມ່ນຂໍ້ມູນ) ວິທີແກ້ໄຂການວິເຄາະ, ນັກວິເຄາະທຸລະກິດ, ວິສະວະກອນຂໍ້ມູນ, ແລະຜູ້ຕັດສິນໃຈສາມາດເຂົ້າເຖິງຂໍ້ມູນຈາກຄັງຂໍ້ມູນ.
ມັນເປັນລາຄາແພງທີ່ຈະຮັກສາສາງທີ່ມີປະລິມານຂໍ້ມູນເພີ່ມຂຶ້ນເລື້ອຍໆ, ແລະຄັງຂໍ້ມູນບໍ່ສາມາດຈັດການກັບຂໍ້ມູນດິບຫຼືບໍ່ມີໂຄງສ້າງ. ນອກຈາກນັ້ນ, ມັນບໍ່ແມ່ນທາງເລືອກທີ່ເຫມາະສົມສໍາລັບເຕັກນິກການວິເຄາະຂໍ້ມູນທີ່ມີຄວາມຊັບຊ້ອນເຊັ່ນການຮຽນຮູ້ເຄື່ອງຈັກຫຼືການສ້າງແບບຈໍາລອງການຄາດເດົາ.
ດັ່ງນັ້ນ, ຄັງເກັບຂໍ້ມູນ, ສະຫນອງການຕອບຄໍາຖາມທີ່ໄວຂຶ້ນແລະຂໍ້ມູນທີ່ມີຄຸນນະພາບສູງກວ່າ. Google Big Query, Amazon Redshift, Azure SQL Data warehouse, ແລະ Snowflake ແມ່ນການບໍລິການຄລາວທີ່ມີສໍາລັບຄັງຂໍ້ມູນ.
ຜົນປະໂຫຍດຂອງສາງຂໍ້ມູນ
- ເພີ່ມທະວີປະສິດທິພາບ ແລະຄວາມໄວຂອງທຸລະກິດອັດສະລິຍະ ແລະວຽກງານການວິເຄາະຂໍ້ມູນ: ຄັງເກັບຂໍ້ມູນຫຼຸດເວລາທີ່ຈໍາເປັນສໍາລັບການກະກຽມຂໍ້ມູນແລະການວິເຄາະ. ພວກເຂົາສາມາດເຊື່ອມໂຍງກັບການວິເຄາະຂໍ້ມູນແລະເຄື່ອງມືທາງທຸລະກິດໄດ້ຢ່າງງ່າຍດາຍນັບຕັ້ງແຕ່ຂໍ້ມູນຈາກຄັງຂໍ້ມູນແມ່ນມີຄວາມຫນ້າເຊື່ອຖືແລະສອດຄ່ອງ. ນອກຈາກນັ້ນ, ຄັງຂໍ້ມູນຍັງປະຫຍັດເວລາທີ່ຈໍາເປັນສໍາລັບການລວບລວມຂໍ້ມູນແລະໃຫ້ທີມງານສາມາດນໍາໃຊ້ຂໍ້ມູນສໍາລັບບົດລາຍງານ, dashboards ແລະຄວາມຕ້ອງການການວິເຄາະອື່ນໆ.
- ເພີ່ມທະວີຄວາມສອດຄ່ອງ, ຄຸນນະພາບ, ແລະມາດຕະຖານຂອງຂໍ້ມູນ: ອົງການຈັດຕັ້ງເກັບກໍາຂໍ້ມູນຈາກແຫຼ່ງຕ່າງໆ, ລວມທັງຂໍ້ມູນຜູ້ໃຊ້, ການຂາຍ, ແລະຂໍ້ມູນທຸລະກໍາ. ບໍລິສັດສາມາດໄວ້ວາງໃຈຂໍ້ມູນສໍາລັບຄວາມຕ້ອງການຂອງທຸລະກິດເພາະວ່າຄັງຂໍ້ມູນລວບລວມຂໍ້ມູນຂອງບໍລິສັດເຂົ້າໄປໃນຮູບແບບທີ່ເປັນເອກະພາບ, ມາດຕະຖານທີ່ສາມາດປະຕິບັດເປັນແຫລ່ງຂໍ້ມູນດຽວຂອງຄວາມຈິງ.
- ເສີມຂະຫຍາຍການຕັດສິນໃຈໂດຍທົ່ວໄປ: ການເກັບຮັກສາຂໍ້ມູນສ້າງຄວາມສະດວກໃນການຕັດສິນໃຈທີ່ດີກວ່າໂດຍສະເຫນີໃຫ້ຮ້ານເປັນສູນກາງສໍາລັບຂໍ້ມູນທັງທີ່ຜ່ານມາແລະເກົ່າ. ໂດຍການປະມວນຜົນຂໍ້ມູນໃນຄັງຂໍ້ມູນສໍາລັບຄວາມເຂົ້າໃຈທີ່ຊັດເຈນ, ຜູ້ຕັດສິນໃຈສາມາດປະເມີນຄວາມສ່ຽງ, ເຂົ້າໃຈຄວາມຕ້ອງການຂອງລູກຄ້າ, ແລະເສີມຂະຫຍາຍສິນຄ້າແລະການບໍລິການ.
- ການສະຫນອງຄວາມສະຫລາດທາງທຸລະກິດທີ່ດີກວ່າ: ການເກັບຂໍ້ມູນເປັນຂົວຕໍ່ຊ່ອງຫວ່າງລະຫວ່າງຂໍ້ມູນດິບຂະໜາດໃຫຍ່, ເຊິ່ງຖືກເກັບກຳເປັນປະຈຳເປັນປະຈຳ, ແລະຂໍ້ມູນທີ່ຄັດສັນມາໃຫ້ຄວາມເຂົ້າໃຈ. ພວກເຂົາເຮັດຫນ້າທີ່ເປັນພື້ນຖານສໍາລັບການເກັບຮັກສາຂໍ້ມູນຂອງອົງການຈັດຕັ້ງ, ເຮັດໃຫ້ມັນສາມາດຕອບຄໍາຖາມທີ່ສັບສົນກ່ຽວກັບຂໍ້ມູນຂອງມັນແລະນໍາໃຊ້ຄໍາຕອບເພື່ອເຮັດການຕັດສິນໃຈທາງທຸລະກິດທີ່ມີການປ້ອງກັນ.
ຂໍ້ຈໍາກັດຂອງຄັງຂໍ້ມູນ
- ຂາດຄວາມຍືດຫຍຸ່ນຂອງຂໍ້ມູນ: ໃນຂະນະທີ່ຄັງຂໍ້ມູນດີເລີດໃນການຈັດການຂໍ້ມູນທີ່ມີໂຄງສ້າງ, ຮູບແບບຂໍ້ມູນເຄິ່ງໂຄງສ້າງແລະບໍ່ມີໂຄງສ້າງເຊັ່ນການວິເຄາະບັນທຶກ, ການຖ່າຍທອດແລະຂໍ້ມູນສື່ສັງຄົມສາມາດເປັນສິ່ງທ້າທາຍສໍາລັບພວກເຂົາ. ນີ້ເຮັດໃຫ້ການແນະນໍາຄັງຂໍ້ມູນສໍາລັບກໍລະນີການນໍາໃຊ້ທີ່ກ່ຽວຂ້ອງກັບການຮຽນຮູ້ເຄື່ອງຈັກແລະ ປັນຍາປະດິດ ຫຍຸ້ງຍາກ.
- ຄ່າໃຊ້ຈ່າຍໃນການຕິດຕັ້ງແລະຮັກສາ: ຄັງເກັບຂໍ້ມູນສາມາດມີລາຄາແພງໃນການຕິດຕັ້ງແລະຮັກສາ. ຍິ່ງໄປກວ່ານັ້ນ, ຄັງຂໍ້ມູນມັກຈະບໍ່ສະຖິດ; ມັນມີອາຍຸແລະຕ້ອງການການດູແລເລື້ອຍໆ, ເຊິ່ງລາຄາແພງ.
pros
- ຂໍ້ມູນແມ່ນງ່າຍດາຍເພື່ອຊອກຫາ, ດຶງຂໍ້ມູນ, ແລະການສອບຖາມ.
- ຕາບໃດທີ່ຂໍ້ມູນສະອາດແລ້ວ, ການກະກຽມຂໍ້ມູນ SQL ແມ່ນງ່າຍດາຍ.
cons
- ເຈົ້າຖືກບັງຄັບໃຫ້ໃຊ້ພຽງແຕ່ຫນຶ່ງຜູ້ຂາຍການວິເຄາະ.
- ການວິເຄາະແລະການເກັບຮັກສາຂໍ້ມູນທີ່ບໍ່ມີໂຄງສ້າງຫຼືໄຫຼແມ່ນຂ້ອນຂ້າງຄ່າໃຊ້ຈ່າຍ.
Data Lake ແມ່ນຫຍັງ?
ທຸກໆປະເພດຂອງຂໍ້ມູນຖືກສັນຍາໄວ້ແລະສ້າງຄວາມເປັນໄປໄດ້ໂດຍການເກັບຂໍ້ມູນ. ມັນເປັນປະໂຫຍດທີ່ຈະມີຂໍ້ມູນໃນລັກສະນະທີ່ສາມາດເຂົ້າເຖິງໄດ້ຢູ່ໃຈກາງແລະສາມາດໃຊ້ໄດ້ສໍາລັບການອ່ານ.
ອ່າງເກັບຂໍ້ມູນເປັນພື້ນທີ່ຈັດເກັບຂໍ້ມູນແບບລວມສູນ, ທີ່ສາມາດປັບຕົວໄດ້ສູງສຸດ ບ່ອນທີ່ມີປະລິມານຂໍ້ມູນທີ່ມີການຈັດຕັ້ງ ແລະບໍ່ມີໂຄງສ້າງຫຼາຍອັນຖືກເກັບໄວ້ໃນຮູບແບບທີ່ບໍ່ໄດ້ປະມວນຜົນ, ບໍ່ປ່ຽນແປງ ແລະບໍ່ມີຮູບແບບ.
ທະເລສາບຂໍ້ມູນໃຊ້ສະຖາປັດຕະຍະກໍາຮາບພຽງແລະວັດຖຸທີ່ເກັບໄວ້ໃນສະພາບທີ່ຍັງບໍ່ໄດ້ປຸງແຕ່ງເພື່ອເກັບຂໍ້ມູນ, ກົງກັນຂ້າມກັບຄັງຂໍ້ມູນ, ເຊິ່ງຊ່ວຍປະຢັດຂໍ້ມູນທີ່ກ່ຽວຂ້ອງທີ່ໄດ້ຖືກ "ອະນາໄມ."
Data lakes, ກົງກັນຂ້າມກັບສາງຂໍ້ມູນ, ເຊິ່ງມີຄວາມຫຍຸ້ງຍາກໃນການຈັດການຂໍ້ມູນໃນຮູບແບບນີ້, ສາມາດປັບຕົວໄດ້, ເຊື່ອຖືໄດ້, ແລະລາຄາບໍ່ແພງແລະອະນຸຍາດໃຫ້ວິສາຫະກິດສາມາດໄດ້ຮັບຄວາມເຂົ້າໃຈທີ່ເພີ່ມຂຶ້ນຈາກຂໍ້ມູນທີ່ບໍ່ມີໂຄງສ້າງ.
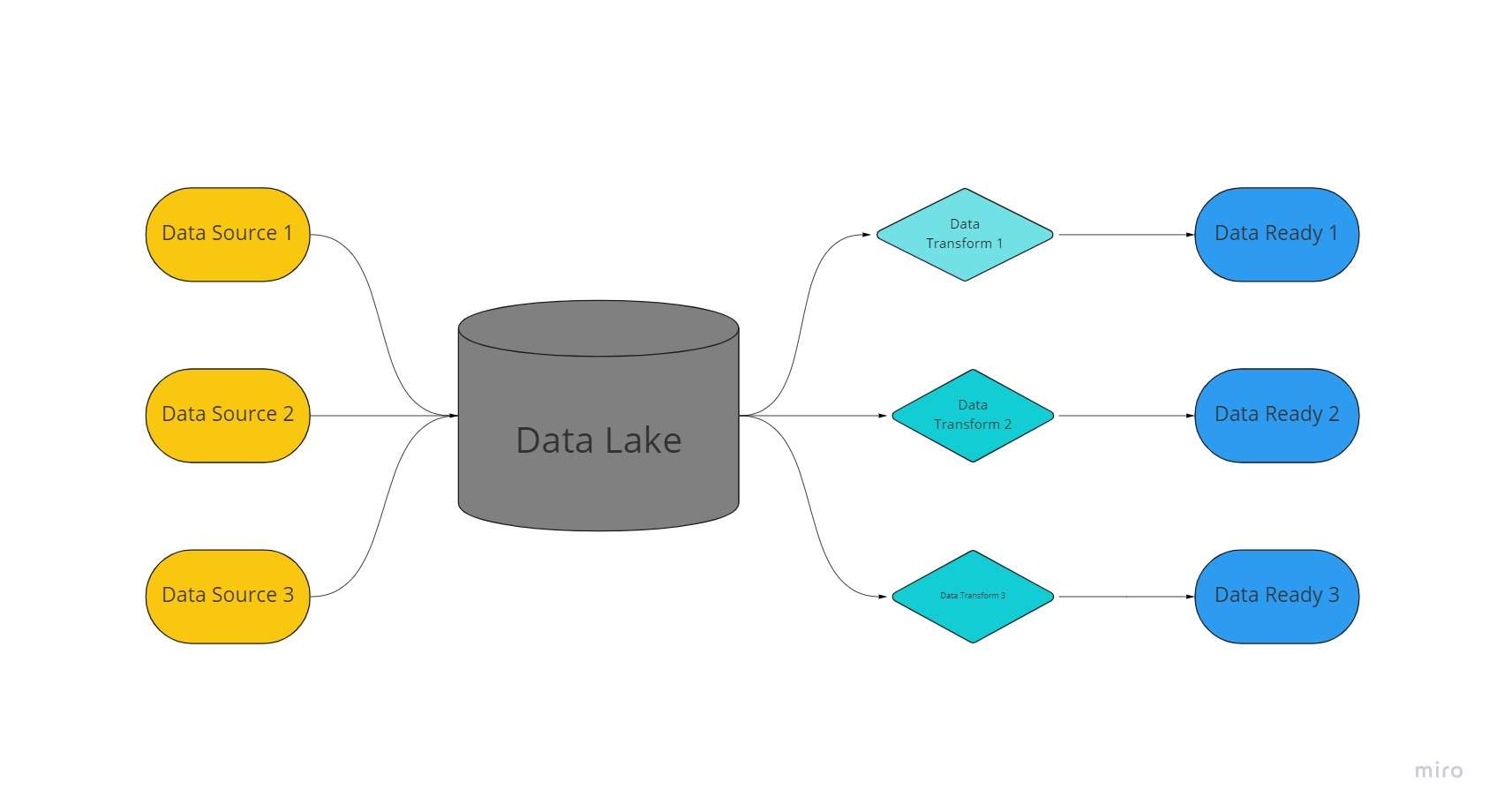
ໃນຂໍ້ມູນ lakes, ຂໍ້ມູນຖືກສະກັດ, ໂຫຼດ, ແລະຫັນປ່ຽນ (ELT) ສໍາລັບຈຸດປະສົງການວິເຄາະແທນທີ່ຈະມີ schema ຫຼືຂໍ້ມູນທີ່ຖືກສ້າງຕັ້ງຂຶ້ນໃນເວລາທີ່ເກັບກໍາຂໍ້ມູນ.
ການນໍາໃຊ້ເຕັກໂນໂລຊີສໍາລັບຫຼາຍປະເພດຂໍ້ມູນຈາກອຸປະກອນ IoT, ສື່ມວນຊົນສັງຄົມ, ແລະ streaming ຂໍ້ມູນ, lakes ຂໍ້ມູນເຮັດໃຫ້ການຮຽນຮູ້ເຄື່ອງຈັກແລະການວິເຄາະຄາດຄະເນ.
ນອກຈາກນັ້ນ, ນັກວິທະຍາສາດຂໍ້ມູນທີ່ສາມາດປຸງແຕ່ງຂໍ້ມູນດິບສາມາດນໍາໃຊ້ຂໍ້ມູນທະເລສາບ. ໃນທາງກົງກັນຂ້າມ, ຄັງເກັບຂໍ້ມູນແມ່ນງ່າຍກວ່າສໍາລັບທຸລະກິດທີ່ຈະໃຊ້. ມັນເປັນທີ່ດີເລີດສໍາລັບການ profile ຜູ້ໃຊ້, ການວິເຄາະການຄາດຄະເນ, ການຮຽນຮູ້ເຄື່ອງຈັກ, ແລະວຽກງານອື່ນໆ.
ເຖິງແມ່ນວ່າ Data lakes ແກ້ໄຂບັນຫາຫຼາຍຢ່າງກັບຄັງຂໍ້ມູນ, ຄຸນນະພາບຂໍ້ມູນຂອງພວກເຂົາບໍ່ດີແລະຄວາມໄວການສອບຖາມຂອງພວກເຂົາບໍ່ພຽງພໍ. ນອກຈາກນັ້ນ, ມັນໃຊ້ເຄື່ອງມືພິເສດສໍາລັບຜູ້ໃຊ້ທຸລະກິດເພື່ອດໍາເນີນການສອບຖາມ SQL. ຂໍ້ມູນທີ່ມີໂຄງສ້າງບໍ່ດີອາດຈະປະສົບກັບບັນຫາກັບຂໍ້ມູນຢຸດເຊົາການ.
ຜົນປະໂຫຍດຂອງ Data Lake
- ສະຫນັບສະຫນູນສໍາລັບລະດັບຄວາມກ້ວາງຂອງການຮຽນຮູ້ເຄື່ອງຈັກແລະກໍລະນີການນໍາໃຊ້ວິທະຍາສາດຂໍ້ມູນ ມັນເປັນເລື່ອງງ່າຍກວ່າທີ່ຈະນໍາໃຊ້ເຄື່ອງຈັກທີ່ແຕກຕ່າງກັນແລະການຮຽນຮູ້ເລິກ algorithms ເພື່ອຈັດການຂໍ້ມູນໃນ Data lakes ເນື່ອງຈາກວ່າຂໍ້ມູນຖືກເກັບຮັກສາໄວ້ໃນລັກສະນະທີ່ເປີດເຜີຍ, ດິບ.
- ຄວາມຫຼາກຫຼາຍຂອງ Data lakes, ເຊິ່ງຊ່ວຍໃຫ້ທ່ານສາມາດເກັບຂໍ້ມູນໃນຮູບແບບຕ່າງໆຫຼືສື່ຕ່າງໆໄດ້ໂດຍບໍ່ຕ້ອງການສໍາລັບ schema preset, ແມ່ນປະໂຫຍດອັນໃຫຍ່ຫຼວງ. ກໍລະນີການນໍາໃຊ້ຂໍ້ມູນໃນອະນາຄົດສາມາດໄດ້ຮັບການສະຫນັບສະຫນູນ, ແລະຂໍ້ມູນເພີ່ມເຕີມສາມາດວິເຄາະຖ້າຫາກວ່າຂໍ້ມູນຖືກປະໄວ້ຢູ່ໃນສະພາບເດີມຂອງມັນ.
- ເພື່ອຫຼີກເວັ້ນການເກັບຮັກສາຂໍ້ມູນທັງສອງປະເພດໃນສະພາບການຕ່າງໆ, ຂໍ້ມູນຂໍ້ມູນສາມາດມີທັງຂໍ້ມູນທີ່ມີໂຄງສ້າງແລະບໍ່ມີໂຄງສ້າງ. ສໍາລັບການເກັບຮັກສາຂໍ້ມູນອົງການຈັດຕັ້ງປະເພດຕ່າງໆ, ພວກເຂົາສະເຫນີສະຖານທີ່ດຽວ.
- ເມື່ອປຽບທຽບກັບຄັງເກັບຂໍ້ມູນແບບດັ້ງເດີມ, ຄັງຂໍ້ມູນແມ່ນລາຄາແພງຫນ້ອຍເພາະວ່າພວກມັນຖືກສ້າງຂື້ນເພື່ອເກັບຮັກສາໄວ້ໃນຮາດແວສິນຄ້າທີ່ມີລາຄາຖືກ, ເຊັ່ນ: ການເກັບຮັກສາວັດຖຸ, ເຊິ່ງມັກຈະຖືກໃຊ້ສໍາລັບຄ່າໃຊ້ຈ່າຍຕ່ໍາຕໍ່ gigabyte ເກັບຮັກສາໄວ້.
ຂໍ້ຈໍາກັດຂອງ Data Lake
- ການວິເຄາະຂໍ້ມູນແລະຄວາມສະຫລາດທາງດ້ານທຸລະກິດໃຊ້ກໍລະນີຄະແນນບໍ່ດີ: ຂໍ້ມູນລັບສາມາດກາຍເປັນການຈັດລຽງບໍ່ໄດ້ຖ້າພວກເຂົາບໍ່ໄດ້ຮັບການຮັກສາຢ່າງພຽງພໍ, ເຊິ່ງເຮັດໃຫ້ມັນຍາກທີ່ຈະເຊື່ອມໂຍງພວກເຂົາກັບທຸລະກິດປັນຍາແລະເຄື່ອງມືການວິເຄາະ. ນອກຈາກນັ້ນ, ໃນເວລາທີ່ມີຄວາມຈໍາເປັນສໍາລັບການລາຍງານແລະການວິເຄາະການນໍາໃຊ້ກໍລະນີ, ການຂາດຄວາມສອດຄ່ອງ ໂຄງສ້າງຂໍ້ມູນ ແລະ ACID (ປະລໍາມະນູ, ຄວາມສອດຄ່ອງ, ການໂດດດ່ຽວ, ແລະຄວາມທົນທານ) ການສະຫນັບສະຫນູນການເຮັດທຸລະກໍາສາມາດນໍາໄປສູ່ການປະຕິບັດການສອບຖາມທີ່ດີທີ່ສຸດ.
- ຄວາມບໍ່ສອດຄ່ອງຂອງ Data lakes ເຮັດໃຫ້ມັນເປັນໄປບໍ່ໄດ້ທີ່ຈະບັງຄັບໃຊ້ຄວາມຫນ້າເຊື່ອຖືແລະຄວາມປອດໄພຂອງຂໍ້ມູນ, ເຊິ່ງເຮັດໃຫ້ທັງສອງຂາດ. ມັນອາດຈະເປັນການຍາກທີ່ຈະພັດທະນາຄວາມປອດໄພຂອງຂໍ້ມູນ ແລະມາດຕະຖານການປົກຄອງທີ່ເໝາະສົມເພື່ອຕອບສະໜອງກັບປະເພດຂໍ້ມູນທີ່ອ່ອນໄຫວ, ເນື່ອງຈາກຂໍ້ມູນຂໍ້ມູນສາມາດຈັດການຮູບແບບຂໍ້ມູນຕ່າງໆໄດ້.
pros
- ການແກ້ໄຂທີ່ມີລາຄາບໍ່ແພງສໍາລັບທຸກປະເພດຂອງຂໍ້ມູນ.
- ສາມາດຈັດການກັບຂໍ້ມູນທີ່ມີທັງການຈັດຕັ້ງແລະເຄິ່ງໂຄງສ້າງ.
- ເໝາະສຳລັບການປະມວນຜົນຂໍ້ມູນທີ່ສັບສົນ ແລະສະຕີມ.
cons
- ຕ້ອງການສ້າງທໍ່ທີ່ທັນສະໄໝ.
- ໃຫ້ຂໍ້ມູນບາງເວລາເພື່ອໃຫ້ສາມາດສອບຖາມໄດ້.
- ໃຊ້ເວລາໃນການຮັບປະກັນຄວາມເຊື່ອຖືຂອງຂໍ້ມູນ ແລະຄຸນນະພາບ.
Data Lakehouse ແມ່ນຫຍັງ?
ສະຖາປັດຕະຍະກຳການເກັບຂໍ້ມູນຂະໜາດໃຫຍ່ອັນໃໝ່ທີ່ເອີ້ນວ່າ "ຄັງເກັບຂໍ້ມູນ" ລວມເອົາລັກສະນະອັນຍິ່ງໃຫຍ່ທີ່ສຸດຂອງການເກັບຂໍ້ມູນ ແລະຄັງເກັບຂໍ້ມູນ. ຂໍ້ມູນຂອງທ່ານທັງຫມົດ, ບໍ່ວ່າຈະເປັນໂຄງສ້າງ, ເຄິ່ງໂຄງສ້າງ, ຫຼືບໍ່ມີໂຄງສ້າງ, ສາມາດຖືກເກັບໄວ້ໃນສະຖານທີ່ດຽວກັບການຮຽນຮູ້ເຄື່ອງຈັກທີ່ດີທີ່ສຸດ, ຄວາມສະຫລາດທາງທຸລະກິດ, ແລະຄວາມສາມາດການຖ່າຍທອດທີ່ເປັນໄປໄດ້ຍ້ອນການເກັບຮັກສາຂໍ້ມູນ.
ທະເລສາບຂໍ້ມູນຂອງທຸກປະເພດມັກຈະເປັນຈຸດເລີ່ມຕົ້ນສໍາລັບ lakehouses ຂໍ້ມູນ; ຫຼັງຈາກນັ້ນ, ຂໍ້ມູນຈະຖືກປ່ຽນເປັນຮູບແບບ Delta Lake (ຊັ້ນເກັບຮັກສາແຫຼ່ງເປີດທີ່ນໍາເອົາຄວາມຫນ້າເຊື່ອຖືໃຫ້ກັບຂໍ້ມູນ Lakes).
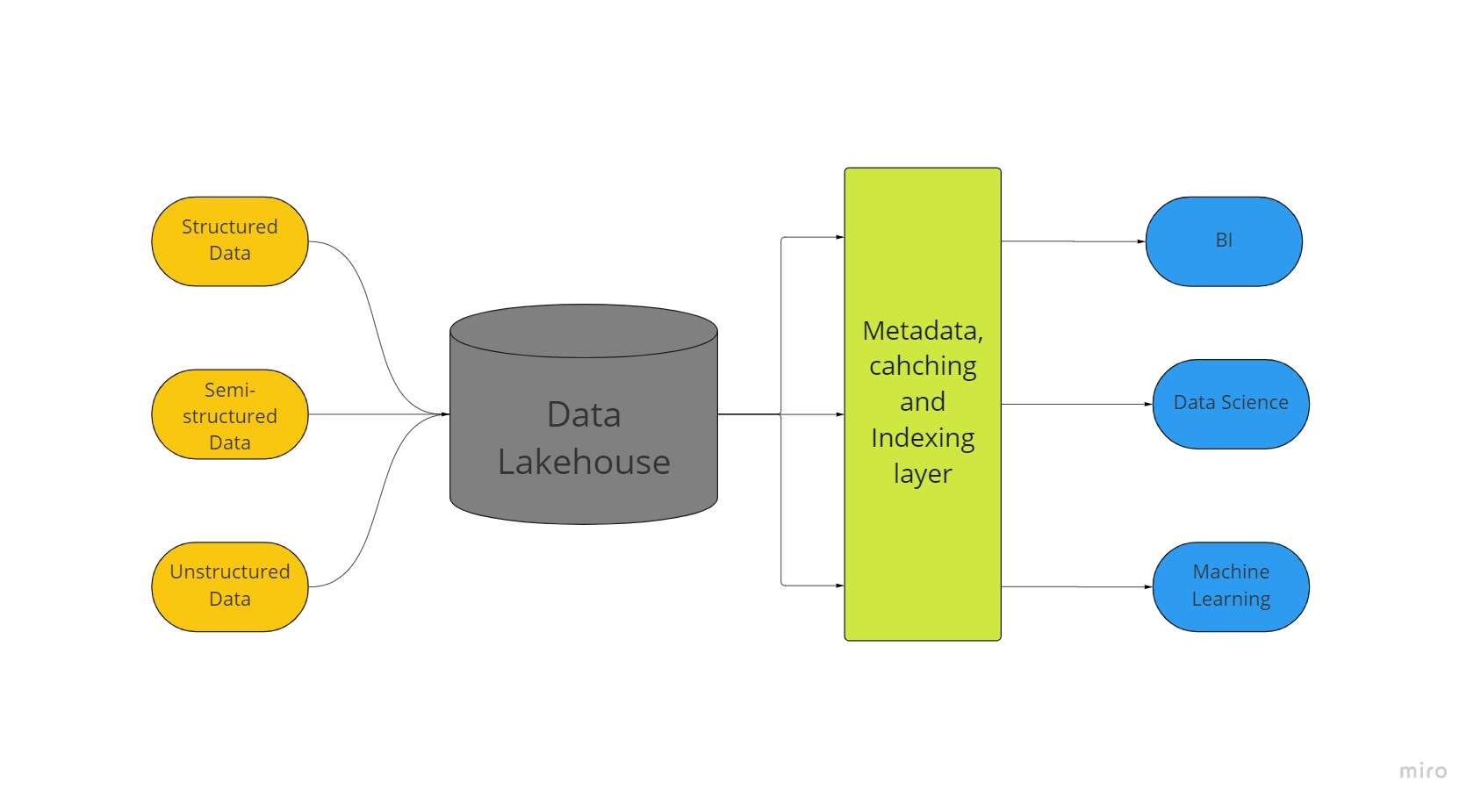
ທະເລສາບຂໍ້ມູນທີ່ມີ delta lakes ເຮັດໃຫ້ຂັ້ນຕອນການເຮັດທຸລະກໍາ ACID ຈາກຄັງຂໍ້ມູນທໍາມະດາ. ໂດຍເນື້ອແທ້ແລ້ວ, ລະບົບ lakehouse ໃຊ້ການເກັບຮັກສາລາຄາບໍ່ແພງເພື່ອຮັກສາຂໍ້ມູນຈໍານວນຫຼວງຫຼາຍໃນຮູບແບບຕົ້ນສະບັບຂອງພວກເຂົາ, ຄືກັບຂໍ້ມູນທະເລສາບ.
ການເພີ່ມຊັ້ນຂໍ້ມູນເມຕາເດຕາຢູ່ເທິງສຸດຂອງຮ້ານຍັງໃຫ້ໂຄງສ້າງຂໍ້ມູນ ແລະສ້າງຄວາມເຂັ້ມແຂງໃຫ້ເຄື່ອງມືການຈັດການຂໍ້ມູນຄືກັບທີ່ພົບເຫັນຢູ່ໃນຄັງຂໍ້ມູນ.
ນີ້ເຮັດໃຫ້ມັນເປັນໄປໄດ້ສໍາລັບທີມງານຈໍານວນຫຼາຍທີ່ຈະເຂົ້າເຖິງຂໍ້ມູນຂອງບໍລິສັດທັງຫມົດໂດຍຜ່ານລະບົບດຽວສໍາລັບການລິເລີ່ມທີ່ຫລາກຫລາຍ, ເຊັ່ນ: ວິທະຍາສາດຂໍ້ມູນ, ການຮຽນຮູ້ເຄື່ອງຈັກ, ແລະຄວາມສະຫລາດທາງທຸລະກິດ.
ຜົນປະໂຫຍດຂອງ Data Lakehouse
- ສະຫນັບສະຫນູນຂອບເຂດຂອງວຽກທີ່ໃຫຍ່ກວ່າ: ເພື່ອອໍານວຍຄວາມສະດວກໃນການວິເຄາະທີ່ຊັບຊ້ອນ, lakehouses ຂໍ້ມູນໃຫ້ຜູ້ໃຊ້ເຂົ້າເຖິງບາງເຄື່ອງມືທາງທຸລະກິດທີ່ນິຍົມຫຼາຍທີ່ສຸດ (Tableau, PowerBI). ນອກຈາກນັ້ນ, ນັກວິທະຍາສາດຂໍ້ມູນ ແລະວິສະວະກອນການຮຽນຮູ້ເຄື່ອງຈັກສາມາດນຳໃຊ້ຂໍ້ມູນໄດ້ງ່າຍ ເນື່ອງຈາກລະບົບຂໍ້ມູນຖານຂໍ້ມູນນຳໃຊ້ຮູບແບບຂໍ້ມູນເປີດ (ເຊັ່ນ: Parquet) ຮ່ວມກັບ APIs ແລະໂຄງຮ່າງການຮຽນຮູ້ຂອງເຄື່ອງຈັກ ເຊັ່ນ: Python/R.
- ປະສິດທິພາບຄ່າໃຊ້ຈ່າຍ: Data lakehouses ໃຊ້ວິທີແກ້ໄຂການເກັບຮັກສາວັດຖຸທີ່ມີລາຄາຖືກເພື່ອປະຕິບັດຄຸນລັກສະນະການເກັບຮັກສາຂໍ້ມູນຄ່າໃຊ້ຈ່າຍທີ່ມີປະສິດທິພາບ. ໂດຍການສະເຫນີການແກ້ໄຂດຽວ, ຄັງຂໍ້ມູນຍັງເຮັດໃຫ້ຄ່າໃຊ້ຈ່າຍແລະເວລາທີ່ກ່ຽວຂ້ອງກັບການຄຸ້ມຄອງລະບົບການເກັບຮັກສາຂໍ້ມູນຕ່າງໆ.
- ການອອກແບບ lakehouse ຂໍ້ມູນຮັບປະກັນ schema ແລະຄວາມສົມບູນຂອງຂໍ້ມູນ, ເຮັດໃຫ້ມັນງ່າຍກວ່າໃນການສ້າງຄວາມປອດໄພຂໍ້ມູນແລະລະບົບການປົກຄອງ. ຄວາມງ່າຍຂອງ ການອອກແບບຂໍ້ມູນ, ການປົກຄອງ, ແລະຄວາມປອດໄພ.
- Data lakehouses ສະເຫນີແພລະຕະຟອມການເກັບຂໍ້ມູນອະເນກປະສົງອັນດຽວທີ່ສາມາດຮອງຮັບຄວາມຕ້ອງການຂໍ້ມູນຂອງບໍລິສັດທັງຫມົດ, ເຊິ່ງຊ່ວຍຫຼຸດຜ່ອນການຊ້ໍາກັນຂອງຂໍ້ມູນ. ທຸລະກິດສ່ວນໃຫຍ່ເລືອກການແກ້ໄຂແບບປະສົມອັນເນື່ອງມາຈາກຜົນປະໂຫຍດຂອງທັງຄັງຂໍ້ມູນແລະຖານຂໍ້ມູນ. ຍຸດທະສາດນີ້, ໃນຂະນະດຽວກັນ, ອາດຈະເຮັດໃຫ້ຂໍ້ມູນຊ້ໍາກັນຄ່າໃຊ້ຈ່າຍ.
- ສະຫນັບສະຫນູນຮູບແບບເປີດ. ຮູບແບບເປີດແມ່ນປະເພດໄຟລ໌ທີ່ສາມາດນໍາໃຊ້ໄດ້ໂດຍຄໍາຮ້ອງສະຫມັກຊອບແວຈໍານວນຫຼາຍແລະຂໍ້ມູນຈໍາເພາະຂອງມັນມີໃຫ້ສາທາລະນະ. ອີງຕາມບົດລາຍງານ, Lakehouses ມີຄວາມສາມາດເກັບຮັກສາຂໍ້ມູນໃນຮູບແບບໄຟລ໌ທົ່ວໄປເຊັ່ນ Apache Parquet ແລະ ORC (Optimized Row Columnar).
ຂໍ້ຈໍາກັດຂອງ Data Lakehouse
ຂໍ້ບົກຜ່ອງທີ່ໃຫຍ່ທີ່ສຸດຂອງ Data lakehouse ແມ່ນວ່າມັນຍັງເປັນເຕັກໂນໂລຢີທີ່ຍັງອ່ອນແລະພັດທະນາ. ມັນບໍ່ແນ່ນອນວ່າມັນຈະປະຕິບັດຄໍາຫມັ້ນສັນຍາຂອງຕົນເປັນຜົນໄດ້ຮັບ. ກ່ອນທີ່ Data lakehouses ສາມາດແຂ່ງຂັນກັບລະບົບການເກັບຮັກສາຂໍ້ມູນໃຫຍ່, ມັນອາດຈະໃຊ້ເວລາຫຼາຍປີ.
ຢ່າງໃດກໍຕາມ, ເນື່ອງຈາກອັດຕາການປະດິດສ້າງທີ່ທັນສະໄຫມເກີດຂຶ້ນ, ມັນເປັນການຍາກທີ່ຈະເວົ້າວ່າຖ້າຫາກວ່າລະບົບການເກັບຮັກສາຂໍ້ມູນທີ່ແຕກຕ່າງກັນຈະບໍ່ທົດແທນມັນໃນທີ່ສຸດ.
pros
- ເວທີຫນຶ່ງມີຂໍ້ມູນທັງຫມົດ, ຊຶ່ງຫມາຍຄວາມວ່າມີ hostnames ຫນ້ອຍທີ່ຈະຮັກສາ.
- ປະລໍາມະນູ, ຄວາມສອດຄ່ອງ, ຄວາມໂດດດ່ຽວ, ແລະຄວາມເຄັ່ງຄັດແມ່ນບໍ່ໄດ້ຮັບຜົນກະທົບ.
- ມັນມີລາຄາຖືກກວ່າຢ່າງຫຼວງຫຼາຍ.
- ເວທີຫນຶ່ງມີຂໍ້ມູນທັງຫມົດ, ຊຶ່ງຫມາຍຄວາມວ່າມີ hostnames ຫນ້ອຍທີ່ຈະຮັກສາ.
- ງ່າຍໃນການຄຸ້ມຄອງ, ແລະໄວໃນການແກ້ໄຂບັນຫາໃດຫນຶ່ງ
- ເຮັດໃຫ້ມັນງ່າຍກວ່າໃນການກໍ່ສ້າງທໍ່
cons
- ການຕັ້ງຄ່າອາດຈະໃຊ້ເວລາເລັກນ້ອຍ.
- ມັນຍັງອ່ອນເກີນໄປ ແລະຢູ່ໄກເກີນໄປທີ່ຈະມີຄຸນສົມບັດເປັນລະບົບການເກັບຮັກສາທີ່ສ້າງຕັ້ງຂຶ້ນ.
Data Warehouse Vs Data Lake Vs Data Lakehouse
ຄັງເກັບຂໍ້ມູນມີປະຫວັດສາດອັນຍາວນານໃນບໍລິສັດ, ການລາຍງານ, ແລະການວິເຄາະຄໍາຮ້ອງສະຫມັກແລະເປັນເຕັກໂນໂລຢີການເກັບຮັກສາຂໍ້ມູນໃຫຍ່ຄັ້ງທໍາອິດ.
ໃນທາງກົງກັນຂ້າມ, ຄັງເກັບຂໍ້ມູນແມ່ນມີລາຄາແພງແລະມີບັນຫາໃນການຈັດການຂໍ້ມູນທີ່ຫຼາກຫຼາຍແລະບໍ່ມີໂຄງສ້າງ, ເຊັ່ນ: ການຖ່າຍທອດຂໍ້ມູນ. ສຳລັບການຮຽນຮູ້ຂອງເຄື່ອງຈັກ ແລະວຽກງານວິທະຍາສາດຂໍ້ມູນ, ການເກັບຂໍ້ມູນໄດ້ຖືກພັດທະນາເພື່ອຄຸ້ມຄອງຂໍ້ມູນດິບໃນຮູບແບບທີ່ຫຼາກຫຼາຍໃນການເກັບຮັກສາທີ່ເໝາະສົມ.
ເຖິງແມ່ນວ່າການເກັບຂໍ້ມູນມີປະສິດທິພາບກັບຂໍ້ມູນທີ່ບໍ່ມີໂຄງສ້າງ, ພວກມັນຂາດຄວາມສາມາດໃນການເຮັດທຸລະກໍາ ACID ຂອງຄັງຂໍ້ມູນ, ເຮັດໃຫ້ມັນທ້າທາຍໃນການຮັບປະກັນຄວາມສອດຄ່ອງຂອງຂໍ້ມູນແລະຄວາມຫນ້າເຊື່ອຖື.
ສະຖາປັດຕະຍະກຳການເກັບຮັກສາຂໍ້ມູນໃໝ່ລ່າສຸດ, ທີ່ຮູ້ຈັກກັນໃນນາມ "ຫໍເກັບຂໍ້ມູນ", ຮວມເອົາຄວາມໜ້າເຊື່ອຖື ແລະ ຄວາມສອດຄ່ອງຂອງຄັງເກັບຂໍ້ມູນເຂົ້າກັບຄວາມສາມາດໃນການປັບຕົວຂອງຂໍ້ມູນໄດ້.
ສະຫຼຸບ
ສະຫຼຸບແລ້ວ, ການສ້າງ lakehouse ຂໍ້ມູນຈາກ scratch ອາດຈະມີຄວາມຫຍຸ້ງຍາກ. ຍິ່ງໄປກວ່ານັ້ນ, ທ່ານເກືອບແນ່ນອນຈະໃຊ້ແພລະຕະຟອມທີ່ອອກແບບມາເພື່ອເປີດໃຊ້ງານສະຖາປັດຕະຍະກໍາ lakehouse ຂໍ້ມູນເປີດ.
ດັ່ງນັ້ນ, ຈົ່ງລະມັດລະວັງໃນການສືບສວນລັກສະນະຫຼາຍຢ່າງແລະການຈັດຕັ້ງປະຕິບັດແຕ່ລະແພລະຕະຟອມກ່ອນທີ່ຈະເຮັດການຊື້. ບໍລິສັດທີ່ຊອກຫາການແກ້ໄຂຂໍ້ມູນທີ່ມີໂຄງສ້າງທີ່ໃຫຍ່ເຕັມຕົວໂດຍເນັ້ນໃສ່ຄວາມສະຫລາດທາງທຸລະກິດແລະກໍລະນີການນໍາໃຊ້ການວິເຄາະຂໍ້ມູນສາມາດພິຈາລະນາຄັງຂໍ້ມູນ.
ເຖິງຢ່າງໃດກໍ່ຕາມ, ວິສາຫະກິດທີ່ຊອກຫາວິທີແກ້ໄຂຂໍ້ມູນໃຫຍ່ທີ່ສາມາດປັບຂະ ໜາດ ໄດ້, ລາຄາບໍ່ແພງເພື່ອການໂຫຼດພະລັງງານ ສຳ ລັບວິທະຍາສາດຂໍ້ມູນແລະການຮຽນຮູ້ເຄື່ອງຈັກໃນຂໍ້ມູນທີ່ບໍ່ມີໂຄງສ້າງຄວນພິຈາລະນາການເກັບຂໍ້ມູນ.
ພິຈາລະນາວ່າທຸລະກິດຂອງທ່ານຕ້ອງການຂໍ້ມູນຫຼາຍກວ່າທີ່ສາງຂໍ້ມູນ ແລະເຕັກໂນໂລຊີຂໍ້ມູນທະເລສາບສາມາດສະໜອງໄດ້, ຫຼືວ່າທ່ານກຳລັງຊອກຫາວິທີແກ້ໄຂບັນຫາເພື່ອລວມເອົາການວິເຄາະທີ່ຊັບຊ້ອນ ແລະການປະຕິບັດການຮຽນຮູ້ຂອງເຄື່ອງຈັກໃນຂໍ້ມູນຂອງທ່ານ. ກ lakehouse ຂໍ້ມູນ ເປັນທາງເລືອກທີ່ສົມເຫດສົມຜົນໃນສະຖານະການ.





ອອກຈາກ Reply ເປັນ