სარჩევი[დამალვა][ჩვენება]
კომპანიები იღებენ უფრო მეტ მონაცემს, ვიდრე ოდესმე, რადგან ისინი სულ უფრო მეტად ეყრდნობიან მასზე მნიშვნელოვანი ბიზნეს გადაწყვეტილებების ინფორმირებისთვის, პროდუქტის შეთავაზების გასაუმჯობესებლად და მომხმარებლის უკეთესი მომსახურების უზრუნველსაყოფად.
იმის გამო, რომ მონაცემთა რაოდენობა იქმნება ექსპონენციალური სიჩქარით, ღრუბელი გთავაზობთ რამდენიმე უპირატესობას მონაცემთა დამუშავებისა და ანალიტიკისთვის, მათ შორის მასშტაბურობა, საიმედოობა და ხელმისაწვდომობა.
ღრუბლოვან ეკოსისტემაში ასევე არსებობს რამდენიმე ინსტრუმენტი და ტექნოლოგია მონაცემთა დამუშავებისა და ანალიტიკისთვის. დიდი მონაცემთა შენახვის სტრუქტურების ორი ტიპი, რომლებიც ყველაზე ხშირად გამოიყენება, არის მონაცემთა საწყობები და მონაცემთა ტბები.
მიუხედავად იმისა, რომ მონაცემთა ტბის გამოყენება ნაკლებად მიმზიდველია, რადგან მოდელისა და მონაცემების მოთხოვნა ჯერ კიდევ აქტუალურია, მონაცემთა საწყობის გამოყენება ფუჭია.

Wრა ტიპის ღრუბლის არქიტექტურა ვირჩევთ?
უნდა გავითვალისწინოთ მონაცემთა ტბის უფრო ახალი ცნებები, თუ უნდა დავკმაყოფილდეთ საწყობის შეზღუდვებით თუ ტბის შეზღუდვებით?
მონაცემთა შენახვის ახალი არქიტექტურა, სახელწოდებით "მონაცემთა ტბის სახლი" აერთიანებს მონაცემთა ტბების ადაპტირებას მონაცემთა საწყობების მონაცემთა მართვასთან.
დიდი მონაცემების შენახვის სხვადასხვა მეთოდების გაგება აუცილებელია ბიზნეს დაზვერვისთვის (BI), მონაცემთა ანალიტიკისთვის და მონაცემთა შენახვის საიმედო მილსადენის შესაქმნელად. მანქანა სწავლის (ML) დატვირთვა, თქვენი კომპანიის მოთხოვნებიდან გამომდინარე.
ამ პოსტში ჩვენ ყურადღებით დავაკვირდებით Data Warehouse-ს, Data Lake-ს და Data Lakehouse-ს, მათი უპირატესობებით, შეზღუდვებით, ასევე დადებითი და უარყოფითი მხარეებით. Მოდით დავიწყოთ.
რა არის მონაცემთა საწყობი?
მონაცემთა საწყობი არის მონაცემთა ცენტრალიზებული საცავი, რომელსაც იყენებს ორგანიზაცია მრავალი წყაროდან მონაცემთა უზარმაზარი მოცულობის შესანახად. მონაცემთა საწყობი მოქმედებს როგორც ორგანიზაციის „მონაცემთა სიმართლის“ ერთადერთი წყარო და აუცილებელია ანგარიშგებისა და ბიზნეს ანალიტიკისთვის.
როგორც წესი, მონაცემთა საწყობები აერთიანებს რელაციურ მონაცემთა ნაკრებებს რამდენიმე წყაროდან, როგორიცაა აპლიკაციები, ბიზნესი და ტრანზაქციების მონაცემები, ისტორიული მონაცემების შესანახად. სასაწყობო სისტემაში ჩატვირთვამდე, მონაცემები ტრანსფორმირდება და იწმინდება მონაცემთა საწყობებში, რათა მათი გამოყენება შესაძლებელი იყოს მონაცემთა სიმართლის ერთ წყაროდ.
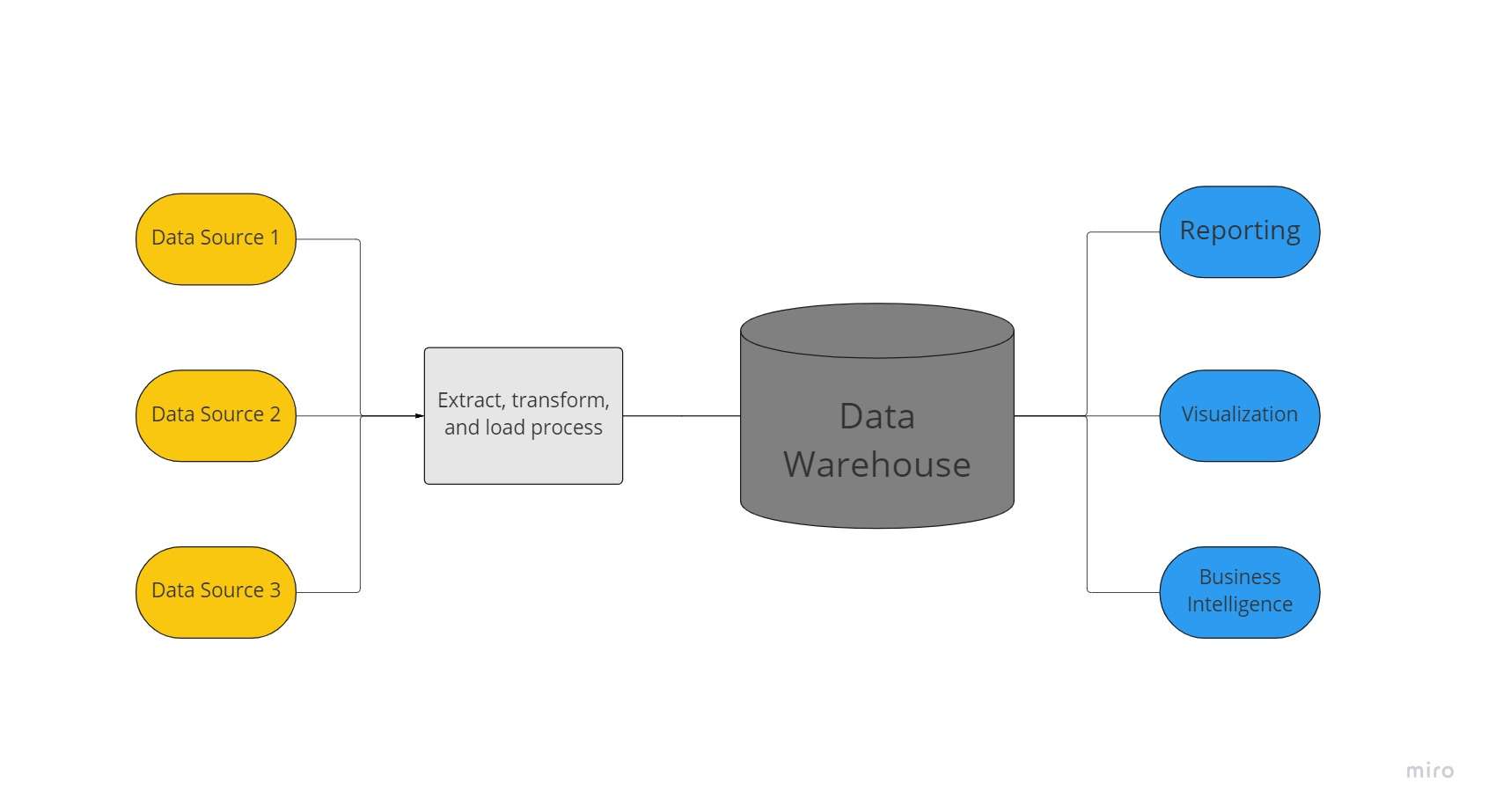
მათი შესაძლებლობების გამო, რომ სწრაფად შესთავაზონ ბიზნეს იდეები კომპანიის ყველა სფეროდან, ბიზნესი ინვესტირებას ახდენს მონაცემთა საწყობებში. BI ინსტრუმენტების, SQL კლიენტების და სხვა ნაკლებად დახვეწილი (ანუ მონაცემთა მეცნიერების გარეშე) ანალიტიკური გადაწყვეტილებების გამოყენებით, ბიზნესის ანალიტიკოსები, მონაცემთა ინჟინრებს და გადაწყვეტილების მიმღებებს შეუძლიათ წვდომა მონაცემთა საწყობებიდან.
ძვირია საწყობის შენარჩუნება მონაცემთა მუდმივად მზარდი მოცულობით და მონაცემთა საწყობი ვერ უმკლავდება ნედლეულ ან არასტრუქტურირებულ მონაცემებს. გარდა ამისა, ეს არ არის იდეალური ვარიანტი მონაცემთა ანალიზის დახვეწილი ტექნიკისთვის, როგორიცაა მანქანათმცოდნეობა ან პროგნოზირებადი მოდელირება.
ამრიგად, მონაცემთა საწყობი უზრუნველყოფს უფრო სწრაფ პასუხებს შეკითხვებზე და უფრო მაღალი ხარისხის მონაცემებს. Google Big Query, Amazon Redshift, Azure SQL Data warehouse და Snowflake არის ღრუბლოვანი სერვისები, რომლებიც ხელმისაწვდომია მონაცემთა საწყობებისთვის.
მონაცემთა საწყობის უპირატესობები
- ბიზნეს ინტელექტისა და მონაცემთა ანალიტიკის დატვირთვის ეფექტურობისა და სიჩქარის გაზრდა: მონაცემთა საწყობები ამცირებს მონაცემთა მომზადებისა და ანალიზისთვის საჭირო დროს. მათ შეუძლიათ ადვილად დაუკავშირონ მონაცემთა ანალიტიკას და ბიზნეს დაზვერვის ინსტრუმენტებს, რადგან მონაცემთა საწყობიდან მიღებული მონაცემები საიმედო და თანმიმდევრულია. გარდა ამისა, მონაცემთა საწყობები ზოგავს დროს საჭირო მონაცემთა შეგროვებისთვის და აძლევს გუნდებს შესაძლებლობას გამოიყენონ მონაცემები ანგარიშებისთვის, დაფებისთვის და სხვა ანალიტიკური მოთხოვნებისთვის.
- მონაცემთა თანმიმდევრულობის, ხარისხისა და სტანდარტიზაციის გაზრდა: ორგანიზაციები აგროვებენ მონაცემებს სხვადასხვა წყაროდან, მათ შორის მომხმარებლის, გაყიდვებისა და ტრანზაქციების მონაცემებიდან. ფირმას შეუძლია ენდოს მონაცემებს ბიზნესის მოთხოვნებისთვის, რადგან მონაცემთა საწყობი აგროვებს კორპორატიულ მონაცემებს ერთგვაროვან, სტანდარტიზებულ ფორმატში, რომელიც შეიძლება იყოს მონაცემთა სიმართლის ერთი წყარო.
- ზოგადად გადაწყვეტილების მიღების გაძლიერება: მონაცემთა საწყობი ხელს უწყობს უკეთესი გადაწყვეტილების მიღებას, ცენტრალიზებული მაღაზიის შეთავაზებით, როგორც ბოლო, ისე ძველი მონაცემებისთვის. მონაცემთა საწყობებში მონაცემების დამუშავებით ზუსტი ინფორმაციის მისაღებად, გადაწყვეტილების მიმღებებს შეუძლიათ შეაფასონ რისკები, გაიგონ კლიენტის სურვილები და გააუმჯობესონ საქონელი და მომსახურება.
- უკეთესი ბიზნეს ინტელექტის უზრუნველყოფა: მონაცემთა საწყობი ახდენს უფსკრული მასიურ ნედლეულ მონაცემებს შორის, რომლებიც ხშირად გროვდება, როგორც წესი, და კურირებულ მონაცემებს შორის, რომლებიც გვაწვდიან ინფორმაციას. ისინი მოქმედებენ როგორც ორგანიზაციის მონაცემთა შენახვის საფუძველი, რაც საშუალებას აძლევს მას უპასუხოს რთულ კითხვებს მისი მონაცემების შესახებ და გამოიყენოს პასუხები დაცვითი ბიზნეს გადაწყვეტილებების მისაღებად.
მონაცემთა საწყობის შეზღუდვები
- მონაცემთა მოქნილობის ნაკლებობა: მიუხედავად იმისა, რომ მონაცემთა საწყობები გამოირჩევიან სტრუქტურირებული მონაცემების დამუშავებით, ნახევრად სტრუქტურირებული და არასტრუქტურირებული მონაცემთა ფორმატები, როგორიცაა ჟურნალის ანალიტიკა, სტრიმინგი და სოციალური მედიის მონაცემები, შეიძლება მათთვის რთული იყოს. ეს იძლევა რეკომენდაციას მონაცემთა საწყობების გამოყენების შემთხვევებისთვის, რომლებიც მოიცავს მანქანურ სწავლებას და ხელოვნური ინტელექტი სირთულის.
- ძვირია ინსტალაცია და შენარჩუნება: მონაცემთა საწყობების ინსტალაცია და შენარჩუნება შეიძლება ძვირი იყოს. გარდა ამისა, მონაცემთა საწყობი ხშირად არ არის სტატიკური; ის ბერდება და საჭიროებს ხშირი მოვლას, რაც ძვირია.
დადებითი
- მონაცემთა მოძიება, მოძიება და მოთხოვნა მარტივია.
- სანამ მონაცემები უკვე სუფთაა, SQL მონაცემთა მომზადება მარტივია.
Cons
- თქვენ იძულებული ხართ გამოიყენოთ მხოლოდ ერთი ანალიტიკის გამყიდველი.
- არასტრუქტურირებული ან მიმდინარე მონაცემების ანალიზი და შენახვა საკმაოდ ძვირია.
რა არის დათა ტბა?
ყველა ტიპის მონაცემი დაპირებულია და შესაძლებელი ხდება მონაცემთა ტბებით. სასარგებლოა მონაცემების ხელმისაწვდომობა ცენტრალურად განლაგებული და ხელმისაწვდომი წასაკითხად.
მონაცემთა ტბა არის ცენტრალიზებული, უკიდურესად ადაპტირებადი შესანახი სივრცე, სადაც ორგანიზებული და არასტრუქტურირებული მონაცემების უზარმაზარი მოცულობები ინახება მათი დაუმუშავებელი, უცვლელი და არაფორმატირებული ფორმით.
მონაცემთა ტბა იყენებს ბრტყელ არქიტექტურას და მის დაუმუშავებელ მდგომარეობაში შენახულ ობიექტებს მონაცემების შესანახად, საპირისპიროდ მონაცემთა საწყობებისგან, რომლებიც ინახავენ ადრე „გაწმენდილ“ რელაციურ მონაცემებს.
მონაცემთა ტბები, განსხვავებით მონაცემთა საწყობებისგან, რომლებსაც უჭირთ მონაცემთა დამუშავება ამ ფორმატში, არის ადაპტირებადი, საიმედო და ხელმისაწვდომი და საშუალებას აძლევს საწარმოებს მიიღონ გაძლიერებული ინფორმაცია არასტრუქტურირებული მონაცემებისგან.
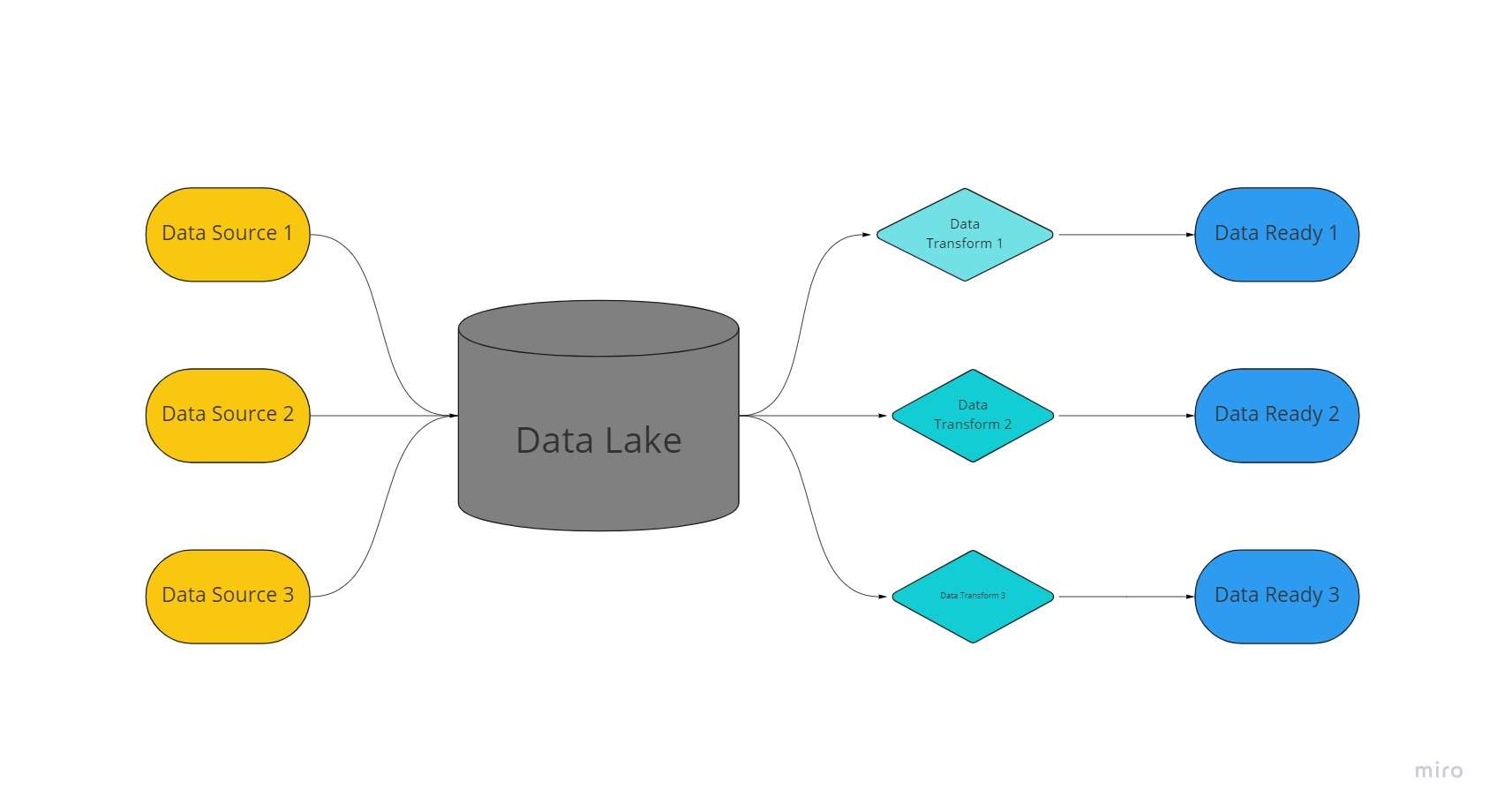
მონაცემთა ტბებში მონაცემები ამოღებულია, იტვირთება და გარდაიქმნება (ELT) ანალიტიკური მიზნებისთვის, ვიდრე სქემის ან მონაცემების დადგენისას მონაცემთა შეგროვების დროს.
ტექნოლოგიების გამოყენება მონაცემთა მრავალი ტიპისთვის IoT მოწყობილობებიდან, სოციალური მედიადა მონაცემთა ნაკადი, მონაცემთა ტბები საშუალებას იძლევა მანქანური სწავლა და პროგნოზირებადი ანალიტიკა.
გარდა ამისა, მონაცემთა მეცნიერს, რომელსაც შეუძლია დაუმუშავებელი მონაცემების დამუშავება, შეუძლია გამოიყენოს მონაცემთა ტბა. მეორეს მხრივ, მონაცემთა საწყობი უფრო ადვილია ბიზნესისთვის გამოსაყენებლად. იდეალურია მომხმარებლის პროფილისთვის, პროგნოზირებადი ანალიტიკა, მანქანათმცოდნეობა და სხვა ამოცანები.
მიუხედავად იმისა, რომ მონაცემთა ტბები აგვარებენ მონაცემთა საწყობების რამდენიმე საკითხს, მათი მონაცემთა ხარისხი დაბალია და მათი მოთხოვნის სიჩქარე არასაკმარისი. გარდა ამისა, ბიზნეს მომხმარებლებს სჭირდება დამატებითი ინსტრუმენტები SQL მოთხოვნების ჩასატარებლად. მონაცემთა ტბა, რომელიც ცუდად სტრუქტურირებულია, შეიძლება განიცდიდეს მონაცემთა სტაგნაციის პრობლემას.
დათა ტბის სარგებელი
- მანქანური სწავლებისა და მონაცემთა მეცნიერების გამოყენების შემთხვევების ფართო სპექტრის მხარდაჭერა. უფრო მარტივია გამოიყენოთ სხვა მანქანური და ღრმა სწავლის ალგორითმები მონაცემთა ტბებში მონაცემების დასამუშავებლად, რადგან მონაცემები ინახება ღია, დაუმუშავებელ რეჟიმში.
- მონაცემთა ტბების მრავალფეროვნება, რომელიც საშუალებას გაძლევთ შეინახოთ მონაცემები ნებისმიერ ფორმატში ან მედიაში წინასწარ დაყენებული სქემის მოთხოვნის გარეშე, დიდი უპირატესობაა. მონაცემთა გამოყენების შემდგომი შემთხვევები შეიძლება იყოს მხარდაჭერილი და მეტი მონაცემების გაანალიზება შესაძლებელია, თუ მონაცემები დარჩება თავდაპირველ მდგომარეობაში.
- ორივე ტიპის მონაცემების სხვადასხვა კონტექსტში შენახვის თავიდან ასაცილებლად, მონაცემთა ტბები შეიძლება შეიცავდეს როგორც სტრუქტურირებულ, ისე არასტრუქტურირებულ მონაცემებს. სხვადასხვა სახის ორგანიზაციული მონაცემების შესანახად, ისინი გვთავაზობენ ერთ ადგილს.
- მონაცემთა ტრადიციულ საწყობებთან შედარებით, მონაცემთა ტბები ნაკლებად ძვირია, რადგან ისინი აშენებულია იაფფასიანი საქონლის აპარატურაზე შესანახად, როგორიცაა ობიექტების შენახვა, რომელიც ხშირად განკუთვნილია შენახული გიგაბაიტის დაბალ ფასად.
მონაცემთა ტბის შეზღუდვები
- მონაცემთა ანალიტიკისა და ბიზნეს ინტელექტის გამოყენების შემთხვევებს ცუდი ქულა აქვს: მონაცემთა ტბები შეიძლება გახდეს არაორგანიზებული, თუ ისინი სათანადოდ არ არის დაცული, რაც ართულებს მათ ბიზნეს დაზვერვასა და ანალიტიკურ ინსტრუმენტებთან დაკავშირებას. გარდა ამისა, როდესაც საჭიროა ანგარიშგების და ანალიტიკის გამოყენების შემთხვევები, თანმიმდევრულობის ნაკლებობა მონაცემთა სტრუქტურები და ACID (ატომურობა, თანმიმდევრულობა, იზოლაცია და გამძლეობა) ტრანზაქციის მხარდაჭერამ შეიძლება გამოიწვიოს არაოპტიმალური შეკითხვის შესრულება.
- მონაცემთა ტბების შეუსაბამობა შეუძლებელს ხდის მონაცემთა საიმედოობისა და უსაფრთხოების დაცვას, რაც იწვევს ორივეს ნაკლებობას. შეიძლება ძნელი იყოს მონაცემთა უსაფრთხოებისა და მართვის შესაბამისი სტანდარტების შემუშავება მონაცემთა მგრძნობიარე ტიპებისთვის, რადგან მონაცემთა ტბებს შეუძლიათ მონაცემთა ნებისმიერი ფორმის დამუშავება.
დადებითი
- გადაწყვეტილებები, რომლებიც ხელმისაწვდომია ყველა ტიპის მონაცემისთვის.
- შეუძლია ორგანიზებული და ნახევრად სტრუქტურირებული მონაცემების დამუშავება.
- იდეალურია მონაცემთა რთული დამუშავებისა და სტრიმინგისთვის.
Cons
- საჭიროებს დახვეწილი მილსადენის ასაშენებლად.
- მიეცით მონაცემებს გარკვეული დრო, რომ გახდეს მოთხოვნადი.
- დრო სჭირდება მონაცემთა საიმედოობისა და ხარისხის გარანტიას.
რა არის Data Lakehouse?
დიდი მონაცემთა შენახვის ახალი არქიტექტურა, სახელწოდებით "მონაცემთა ტბის სახლი" აერთიანებს მონაცემთა ტბებისა და მონაცემთა საწყობების უდიდეს ასპექტებს. თქვენი ყველა მონაცემი, იქნება ეს სტრუქტურირებული, ნახევრად სტრუქტურირებული თუ არასტრუქტურირებული, შეიძლება ინახებოდეს ერთ ადგილას საუკეთესო მანქანათმცოდნეობის, ბიზნეს ინტელექტისა და სტრიმინგის შესაძლებლობებით, რაც შესაძლებელია მონაცემთა lakehouse-ის წყალობით.
მონაცემთა ყველა სახის ტბები ხშირად ამოსავალი წერტილია მონაცემთა ტბებისთვის; ამის შემდეგ, მონაცემები გარდაიქმნება დელტა ტბის ფორმატში (ღია კოდის შენახვის ფენა, რომელიც საიმედოობას ანიჭებს მონაცემთა ტბებს).
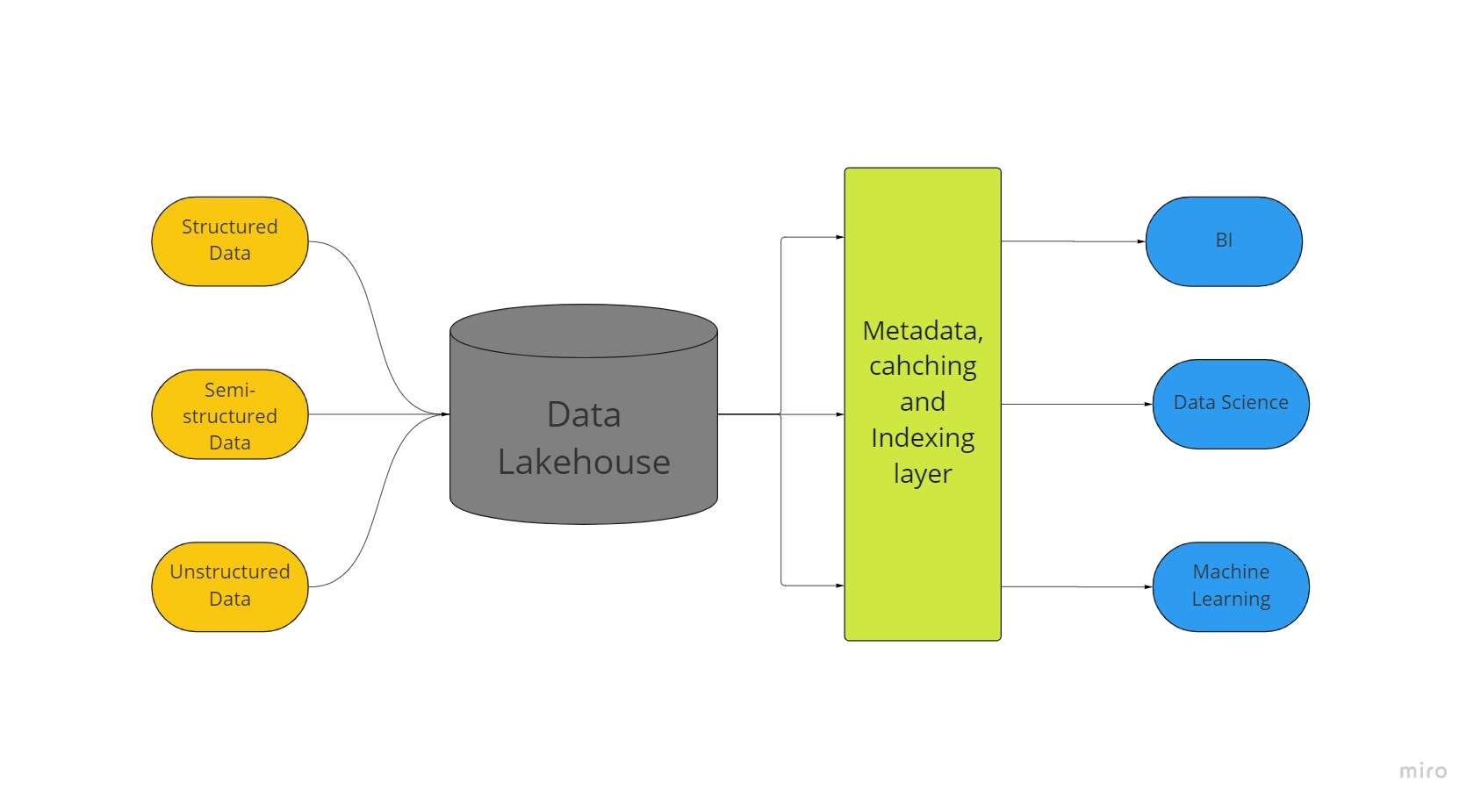
მონაცემთა ტბები დელტა ტბებით იძლევიან ACID ტრანზაქციის პროცედურებს ჩვეულებრივი მონაცემთა საწყობებიდან. არსებითად, Lakehouse სისტემა იყენებს იაფ საცავს, რათა შეინარჩუნოს მასიური რაოდენობის მონაცემები თავდაპირველ ფორმებში, ისევე როგორც მონაცემთა ტბებს.
მაღაზიის თავზე მეტამონაცემების ფენის დამატება ასევე იძლევა მონაცემთა სტრუქტურას და აძლიერებს მონაცემთა მართვის ინსტრუმენტებს, როგორიცაა მონაცემთა საწყობებში ნაპოვნი.
ეს საშუალებას აძლევს ბევრ გუნდს წვდომა ჰქონდეს კომპანიის ყველა მონაცემზე ერთი სისტემის მეშვეობით სხვადასხვა ინიციატივისთვის, როგორიცაა მონაცემთა მეცნიერება, მანქანათმცოდნეობა და ბიზნეს დაზვერვა.
Data Lakehouse-ის უპირატესობები
- სამუშაო დატვირთვის უფრო დიდი დიაპაზონის მხარდაჭერა: დახვეწილი ანალიზის გასაადვილებლად, მონაცემთა ტბა ჰაუსები მომხმარებლებს პირდაპირ წვდომას ანიჭებენ ბიზნეს დაზვერვის ზოგიერთ ყველაზე პოპულარულ ინსტრუმენტზე (Tableau, PowerBI). გარდა ამისა, მონაცემთა მეცნიერებს და მანქანათმცოდნეობის ინჟინერებს შეუძლიათ მარტივად გამოიყენონ მონაცემები, რადგან მონაცემთა ტბა ჰაუსები იყენებენ ღია მონაცემთა ფორმატებს (როგორიცაა პარკეტი) API-ებთან და მანქანათმცოდნეობის ჩარჩოებთან ერთად, როგორიცაა Python/R.
- ხარჯების ეფექტურობა: მონაცემთა ტბების სახლები იყენებენ ობიექტების შენახვის იაფ გადაწყვეტილებებს მონაცემთა ტბების შენახვის ეფექტურობის მახასიათებლების განსახორციელებლად. ერთი გადაწყვეტის შეთავაზებით, მონაცემთა ტბაჰაუსები ასევე აცილებენ ხარჯებს და დროს, რომლებიც დაკავშირებულია მონაცემთა შენახვის სხვადასხვა სისტემების მართვასთან.
- მონაცემთა lakehouse-ის დიზაინი უზრუნველყოფს სქემისა და მონაცემთა მთლიანობას, რაც ამარტივებს მონაცემთა უსაფრთხოების და მართვის ეფექტური სისტემების შექმნას. სიმარტივე მონაცემთა ვერსიირება, მმართველობა და უსაფრთხოება.
- მონაცემთა ტბა ჰაუსები გვთავაზობენ მონაცემთა შენახვის ერთ, მრავალ დანიშნულების პლატფორმას, რომელსაც შეუძლია დააკმაყოფილოს კომპანიის მონაცემების ყველა მოთხოვნა, რაც ამცირებს მონაცემთა დუბლირებას. ბიზნესის უმრავლესობა ირჩევს ჰიბრიდულ გადაწყვეტას როგორც მონაცემთა საწყობის, ასევე მონაცემთა ტბის უპირატესობების გამო. ამ სტრატეგიამ, იმავდროულად, შეიძლება გამოიწვიოს მონაცემთა ძვირადღირებული დუბლირება.
- ღია ფორმატების მხარდაჭერა. ღია ფორმატები არის ფაილის ტიპები, რომლებიც შეიძლება გამოყენებულ იქნას მრავალი პროგრამული აპლიკაციისთვის და რომელთა სპეციფიკაციები საჯაროა. გავრცელებული ინფორმაციით, Lakehouses-ს შეუძლია მონაცემთა შენახვა საერთო ფაილის ფორმატებში, როგორიცაა Apache Parquet და ORC (Optimized Row Columnar).
Data Lakehouse-ის შეზღუდვები
მონაცემთა lakehouse-ის ყველაზე დიდი ნაკლი ის არის, რომ ის ჯერ კიდევ ახალგაზრდა და განვითარებადი ტექნოლოგიაა. გაურკვეველია, შეასრულებს თუ არა დაკისრებულ ვალდებულებებს შედეგად. სანამ მონაცემთა ტბის სახლი კონკურენციას გაუწევს დამკვიდრებულ დიდი მონაცემთა შენახვის სისტემებს, ამას შეიძლება წლები დასჭირდეს.
თუმცა, იმის გათვალისწინებით, თუ რა ტემპით ხდება თანამედროვე ინოვაციები, ძნელი სათქმელია, არ ჩაანაცვლებს თუ არა მას მონაცემთა შენახვის სხვა სისტემა.
დადებითი
- ერთ პლატფორმას აქვს ყველა მონაცემი, რაც ნიშნავს, რომ ნაკლები ჰოსტის სახელია შესანარჩუნებლად.
- ატომურობა, თანმიმდევრულობა, იზოლაცია და სიმტკიცე არ იმოქმედებს.
- ეს მნიშვნელოვნად უფრო ხელმისაწვდომია.
- ერთ პლატფორმას აქვს ყველა მონაცემი, რაც ნიშნავს, რომ ნაკლები ჰოსტის სახელია შესანარჩუნებლად.
- მარტივი სამართავი და სწრაფი გამოსასწორებელი ნებისმიერი პრობლემა
- გაადვილეთ მილსადენის მშენებლობა
Cons
- დაყენებას შეიძლება გარკვეული დრო დასჭირდეს.
- ის ძალიან ახალგაზრდაა და ძალიან შორს არის დამკვიდრებული შენახვის სისტემის კვალიფიკაცია.
მონაცემთა საწყობი Vs მონაცემთა ტბა Vs მონაცემთა Lakehouse
მონაცემთა საწყობს აქვს ხანგრძლივი ისტორია კორპორატიული დაზვერვის, ანგარიშგების და ანალიტიკის აპლიკაციებში და არის დიდი მონაცემთა შენახვის პირველი ტექნოლოგია.
მეორეს მხრივ, მონაცემთა საწყობები ძვირია და უჭირთ სხვადასხვა და არასტრუქტურირებული მონაცემების მართვა, როგორიცაა მონაცემთა ნაკადი. მანქანათმცოდნეობისა და მონაცემთა მეცნიერების დატვირთვისთვის, მონაცემთა ტბები შეიქმნა, რათა მართონ ნედლეული მონაცემები სხვადასხვა ფორმით ხელმისაწვდომ შესანახად.
მიუხედავად იმისა, რომ მონაცემთა ტბები ეფექტურია არასტრუქტურირებული მონაცემებით, მათ არ გააჩნიათ მონაცემთა საწყობების ACID ტრანზაქციის შესაძლებლობები, რაც რთულს ხდის მონაცემთა თანმიმდევრულობისა და საიმედოობის გარანტიას.
მონაცემთა შენახვის უახლესი არქიტექტურა, რომელიც ცნობილია როგორც „მონაცემთა ტბის სახლი“, აერთიანებს მონაცემთა საწყობების საიმედოობასა და თანმიმდევრულობას მონაცემთა ტბების ხელმისაწვდომობასა და ადაპტირებასთან.
დასკვნა
დასასრულს, მონაცემთა ტბის სახლის აშენება ნულიდან შეიძლება რთული იყოს. გარდა ამისა, თქვენ თითქმის აუცილებლად იყენებთ პლატფორმას, რომელიც შექმნილია ღია მონაცემთა ტბის არქიტექტურის გასააქტიურებლად.
ამიტომ, ფრთხილად იყავით, გამოიკვლიოთ თითოეული პლატფორმის მრავალი მახასიათებელი და დანერგვა შესყიდვის დაწყებამდე. კომპანიებს, რომლებიც ეძებენ სექსუალურ, სტრუქტურირებულ მონაცემთა გადაწყვეტას ბიზნეს ინტელექტისა და მონაცემთა ანალიტიკის გამოყენების შემთხვევებზე ფოკუსირებული, შეუძლიათ განიხილონ მონაცემთა საწყობი.
თუმცა, საწარმოებმა, რომლებიც ეძებენ მასშტაბურ, ხელმისაწვდომ დიდ მონაცემთა გადაწყვეტას მონაცემთა მეცნიერების და მანქანური სწავლისთვის არასტრუქტურირებულ მონაცემებზე სამუშაო დატვირთვისთვის, უნდა განიხილონ მონაცემთა ტბები.
ჩათვალეთ, რომ თქვენს ბიზნესს უფრო მეტი მონაცემი სჭირდება, ვიდრე მონაცემთა საწყობი და მონაცემთა ტბის ტექნოლოგიები უზრუნველყოფენ, ან რომ თქვენ ეძებთ გამოსავალს თქვენს მონაცემებზე დახვეწილი ანალიტიკისა და მანქანათმცოდნეობის ოპერაციების ინტეგრირებისთვის. ა მონაცემთა ტბის სახლი გონივრული ვარიანტია სიტუაციაში.





დატოვე პასუხი