მონაცემთა გადაადგილება და შენახვა მნიშვნელოვანი გახდა IT ინდუსტრიის მუდმივი გაფართოებისა და მილიონობით მონაცემთა წერტილის შედეგად, რომლებიც ყოველ წამში იწარმოება.
გარდა ამისა, ეს მონაცემები უნდა იყოს მკაფიო და მარტივი გასაგებად, რათა ხელი შეუწყოს ზუსტი გადაწყვეტილების მიღებას.
კონკურენტუნარიანობის შესანარჩუნებლად და გრძელვადიანი წარმატების მისაღწევად, თქვენმა კომპანიამ უნდა შეინახოს და გადაიტანოს მონაცემები ხელმისაწვდომი ყველაზე ეფექტური გადაწყვეტილებების გამოყენებით.
ამის გამო, მეტი ბიზნესი იყენებს მონაცემთა ქსოვილებს. დროის, ფულისა და რესურსების დაზოგვის ერთ-ერთი საუკეთესო გზაა მონაცემთა ქსოვილის გამოყენება მონაცემთა დასამუშავებლად და AI მანქანური სწავლის გასააქტიურებლად.
ამ სტატიაში ჩვენ ღრმად განვიხილავთ Data Fabric-ს, მის გამოყენებას, ძირითად კომპონენტებს, უპირატესობებს და სხვა სასიცოცხლო დეტალებს.
მაშ, რა არის Data Fabric?
მიუხედავად იმისა, თუ სად მდებარეობს ისინი, მართეთ და დააკვირდით თქვენს მონაცემებსა და აპებს. თავის არსში, მონაცემთა ქსოვილი არის მონაცემთა ინტეგრირებული არქიტექტურა, რომელიც არის უსაფრთხო, მრავალმხრივი და ადაპტირებადი.
მონაცემთა ქსოვილი, რომელიც აერთიანებს ღრუბლის, ბირთვისა და კიდეების საუკეთესოს, მრავალი თვალსაზრისით არის ახალი სტრატეგიული მიდგომა თქვენი ბიზნესის შენახვის ოპერაციებისთვის.
ცენტრალიზებული კონტროლის დროს, მას შეუძლია მიაღწიოს ყველგან, მათ შორის შიდა შენობაში, საჯარო და კერძო ღრუბლებში, ასევე edge და IoT მოწყობილობებს.
ცათამბჯენების ზომის მონაცემთა სილოები და მრავალფეროვანი, დაუკავშირებელი ინფრასტრუქტურა წარსულის საგანია. მონაცემთა ქსოვილი დაფუძნებულია მონაცემთა მართვის ინსტრუმენტების ყოვლისმომცველ კოლექციაზე, რომელიც უზრუნველყოფს თანმიმდევრულობას თქვენს დაკავშირებულ გარემოში.
ავტომატიზაციის საშუალებით, აუმჯობესებს შრომატევად მენეჯმენტს, აჩქარებს განვითარებას, ტესტირებას და დანერგვას და იცავს თქვენს აქტივებს მთელი საათის განმავლობაში.
არ აქვს მნიშვნელობა სად მდებარეობს თქვენი მონაცემები და აპები, შეგიძლიათ თვალყური ადევნოთ შენახვის ხარჯებს, შესრულებას და ეფექტურობას ერთი პლატფორმიდან.
თქვენ შეგიძლიათ სწრაფად (და, ზოგიერთ შემთხვევაში, ავტომატურად) ცვლილებები შეიტანოთ თქვენს ჰიბრიდულ ღრუბლოვან ინფრასტრუქტურაში, მას შემდეგ რაც გექნებათ შესაბამისი ცოდნა ამის შესახებ, როგორიცაა შეცდომების გამოსწორება, უსაფრთხოებისა და შესაბამისობის საკითხების მოგვარება და გამოთვლების გაზრდა და შემცირება.
მოკლედ, Data Fabric აუმჯობესებს ინფრასტრუქტურის განლაგებას და შენარჩუნების ეფექტურობას, ამცირებს ხარჯებს და ზრდის შესრულებას.
რატომ უნდა გამოიყენოთ მონაცემთა ქსოვილი?
ნებისმიერ მონაცემებზე ორიენტირებულ ფირმას სჭირდება ყოვლისმომცველი სტრატეგია, რომელიც გადალახავს დაბრკოლებებს, როგორიცაა დრო, სივრცე, სხვადასხვა სახის პროგრამული უზრუნველყოფა და მონაცემთა მდებარეობა. მონაცემები არ უნდა იყოს დამალული ფეიერვოლების მიღმა ან გაფანტული რამდენიმე ადგილას, არამედ ხელმისაწვდომი უნდა იყოს მათთვის, ვისაც ეს სჭირდება.
წარმატების მისაღწევად, ბიზნესს ესაჭიროება მომავლის საიმედო გადაწყვეტა და უსაფრთხო, ეფექტური, ერთიანი გარემო. ეს შეიძლება გაკეთდეს მონაცემთა ქსოვილით.
თანამედროვე ბიზნესის მოთხოვნილებები რეალურ დროში კავშირის, თვითმომსახურების, ავტომატიზაციისა და უნივერსალური ცვლილებების შესახებ არ შეიძლება დაკმაყოფილდეს მონაცემთა ტრადიციული ინტეგრაციით.
მიუხედავად იმისა, რომ მრავალი წყაროდან მონაცემების შეგროვება ხშირად არ არის პრობლემა, ბევრი ბიზნესი იბრძვის სხვა წყაროებიდან მონაცემების ინტეგრირებაზე, დამუშავებაზე, კურირებასა და გარდაქმნაზე.
მომხმარებელთა, პარტნიორებისა და საქონლის სიღრმისეულად გასაგებად, მონაცემთა მართვის პროცესში ეს კრიტიკული ნაბიჯი უნდა განხორციელდეს. იმის გამო, რომ მათ შეუძლიათ განაახლონ თავიანთი სისტემები, უკეთ მოემსახურონ მომხმარებლებს და გამოიყენონ ისინი Cloud Computingშედეგად, ფირმები იძენენ კონკურენტულ უპირატესობას.
სადაც არ უნდა იყვნენ ორგანიზაციის მომხმარებლები, მონაცემთა ქსოვილი შეიძლება წარმოვიდგინოთ, როგორც ქსოვილი, რომელიც გლობალურად არის გავრცელებული. ამ ქსელში მომხმარებელს შეუძლია ნებისმიერ ადგილას იყოს და მაინც ჰქონდეს შეუზღუდავი, რეალურ დროში წვდომა მონაცემებზე ნებისმიერ სხვა ადგილას.
მონაცემთა ქსოვილის ძირითადი კომპონენტები
ძირითადი კომპონენტები, რომლებიც ქმნიან მონაცემთა ქსოვილს, შეიძლება შეირჩეს და შეგროვდეს სხვადასხვა გზით. ამრიგად, მონაცემთა ქსოვილი შეიძლება განხორციელდეს სხვადასხვა გზით. მოდით შევხედოთ მონაცემთა ქსოვილის ძირითად ელემენტებს.
- გაძლიერებული მონაცემთა კატალოგი
- მდგრადობის ფენა
- ცოდნა Graph
- Insights და Recommendations Engine
- მონაცემთა მომზადებისა და მონაცემთა მიწოდების ფენა
- ორკესტრირება და მონაცემთა ოპერაციები
შეგიძლიათ გადახედოთ Data Fabric არქიტექტურის ძირითად საყრდენებს, შესაბამისად Gartner.
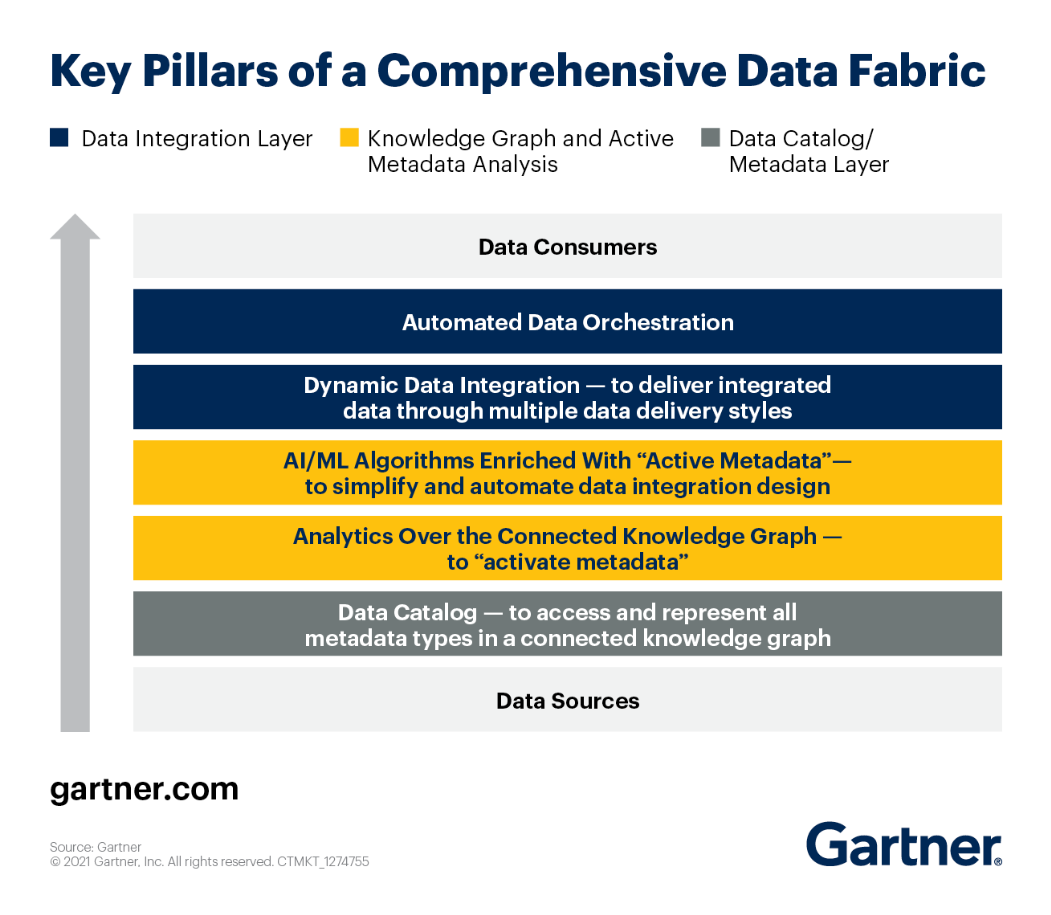
მოდით შევხედოთ თითოეულ მათგანს ყურადღებით.
- გაძლიერებული მონაცემთა კატალოგი – მომხმარებლებს აძლევს წვდომას ყველა სახის მეტამონაცემებზე ძლიერი ცოდნის გრაფიკის საშუალებით. გარდა ამისა, ის ავითარებს განმასხვავებელ ასოციაციებს არსებულ ინფორმაციას შორის და ვიზუალურად აჩვენებს მას გასაგებად. Გამოყენებით მანქანა სწავლის მონაცემთა აქტივების ორგანიზაციულ ტერმინოლოგიასთან დასაკავშირებლად, მონაცემთა გაუმჯობესებული კატალოგები ქმნიან ბიზნეს სემანტიკურ ფენას მონაცემთა ქსოვილისთვის.
- მდგრადობის ფენა – გამოყენების შემთხვევიდან გამომდინარე, სხვადასხვა რელაციური და არარელაციური მოდელების გამოყენება შესაძლებელია მონაცემთა დინამიურად შესანახად.
- აქტიური მეტამონაცემები – მონაცემთა ქსოვილის გამორჩეული ნაწილი. აძლევს მონაცემთა ქსოვილს მრავალი სახის მეტამონაცემების შეგროვების, გაზიარებისა და ანალიზის უნარს. პასიური მეტამონაცემებისგან განსხვავებით, აქტიური მეტამონაცემები აკონტროლებს მონაცემთა მუდმივ გამოყენებას სისტემებისა და ადამიანების მიერ (დიზაიზე დაფუძნებული და გაშვების დროს მეტამონაცემები).
- ცოდნა Graph - კიდევ ერთი ფუნდამენტური ერთეული მონაცემთა ქსოვილებისთვის. ისინი იყენებენ სტანდარტულ ID-ებს, ადაპტირებად სქემებს და ა.შ. დაკავშირებული მონაცემთა გარემოს საჩვენებლად. ცოდნის გრაფიკები ხდის მონაცემთა ქსოვილს ძიებას და ეხმარება მის გაგებაში.
- Insights და რეკომენდაციების ძრავა – აშენებს საიმედო, ძლიერ მონაცემთა მილსადენებს როგორც ოპერატიული, ასევე ანალიტიკური გამოყენების შემთხვევებისთვის.
- მონაცემთა მომზადებისა და მონაცემთა მიწოდების ფენა – მონაცემების მოძიება შესაძლებელია ნებისმიერი წყაროდან და გაგზავნილი ნებისმიერ სამიზნეზე ნებისმიერი მექანიზმის გამოყენებით, მათ შორის ETL (ნაყარი), შეტყობინებები, CDC, ვირტუალიზაცია და API.
- ორკესტრირება და მონაცემთა ოპერაციები – ეს კომპონენტი იყენებს მონაცემებს, რათა კოორდინაცია გაუწიოს ყველა ამოცანებს სამუშაო ნაკადის ბოლოდან ბოლომდე. ეს საშუალებას გაძლევთ აირჩიოთ როდის და რამდენად ხშირად გაუშვათ მილსადენები, ასევე როგორ მართოთ ამ მილსადენების წარმოებული მონაცემები.
უპირატესობები
ჯანსაღი მონაცემები განაწილებულ კონტექსტში არის ხელმისაწვდომი, დატვირთული, ინტეგრირებული და გაზიარებული მონაცემთა ქსოვილზე. ამით, ბიზნესს შეუძლია დააჩქაროს ციფრული გადასვლა და მაქსიმალურად გაზარდოს მათი მონაცემების ღირებულება.
ქვემოთ მოცემულია მონაცემთა ქსოვილის მოდელის ძირითადი უპირატესობები.
ეფექტურობა:
მონაცემთა ქსოვილს შეუძლია შეადგინოს შედეგები ადრინდელი შეკითხვებიდან, რაც საშუალებას აძლევს სისტემას სკანირება მოახდინოს აგრეგირებული ცხრილის ნაცვლად, ნედლეული მონაცემების ფონზე.
ინდივიდუალური მოთხოვნების უფრო სწრაფი რეაგირების დროის გამო, მოთხოვნებს საშუალებას აძლევს წვდომა უფრო მცირე მონაცემთა ნაკრებებზე, ვიდრე მაღაზიის სრული ნედლეული მონაცემების სკანირება, ასევე აგვარებს რამდენიმე ერთდროული მოთხოვნის საკითხს.
საწარმოებს შეუძლიათ სწრაფად უპასუხონ აქტუალურ შეკითხვებს მონაცემთა ქსოვილის უნარის გამო, მნიშვნელოვნად შეამციროს შეკითხვის პასუხების დრო.
ჭკვიანი ინტეგრაცია
მონაცემთა სხვადასხვა ტიპებსა და საბოლოო წერტილებში მონაცემთა ინტეგრირებისთვის, მონაცემთა ქსოვილები იყენებენ სემანტიკური ცოდნის გრაფიკებს, მეტამონაცემების მართვას და მანქანურ სწავლებას.
ეს ეხმარება მონაცემთა მენეჯმენტის გუნდებს დააჯგუფონ შესაბამისი მონაცემთა ნაკრები და ჩართონ მონაცემთა სრულიად ახალი წყაროები კომპანიის მონაცემთა ეკოსისტემაში.
ეს ფუნქცია ავტომატიზირებს მონაცემთა ამოცანების მენეჯმენტის ნაწილებს, რაც იწვევს პროდუქტიულობის დაზოგვას ზემოთ მითითებულ, მაგრამ ის ასევე ხელს უწყობს მონაცემთა სისტემის სილოების დაშლას, მონაცემთა მართვის პროცედურების ცენტრალიზებას და მონაცემთა საერთო ხარისხის ამაღლებას.
მონაცემთა უფრო ეფექტური უსაფრთხოება
ეს ასევე არ გულისხმობს მონაცემთა უსაფრთხოებისა და კონფიდენციალურობის დაცვის მსხვერპლს მონაცემთა წვდომის გაფართოების მიზნით.
ფაქტობრივად, ეს მოითხოვს წვდომის კონტროლის ღობეების გამკაცრებას და მონაცემთა მართვის უფრო მეტი ზომების განხორციელებას, რათა გარანტირებული იყოს, რომ გარკვეული როლები ერთადერთია, ვისაც აქვს წვდომა მოცემულ მონაცემებზე.
გარდა ამისა, მონაცემთა ქსოვილის არქიტექტურა იძლევა ტექნიკურ და უსაფრთხოების გუნდები მონაცემთა ნიღბის განსახორციელებლად და დაშიფვრა კონფიდენციალური და მგრძნობიარე ინფორმაციის ირგვლივ, რაც ამცირებს მონაცემთა გაზიარების და სისტემის ჰაკერების ალბათობას.
მონაცემთა დემოკრატიზაცია
თვითმომსახურების აპლიკაციებს ხელს უწყობს მონაცემთა ქსოვილის დიზაინი, რაც აფართოებს მონაცემთა წვდომას უფრო ტექნიკური პერსონალის მიღმა, როგორიცაა მონაცემთა ინჟინრები, დეველოპერები და მონაცემთა ანალიტიკის გუნდები.
ბიზნეს მომხმარებლებს უფრო სწრაფი არჩევანის გაკეთების ნებას რთავს და ტექნიკურ მომხმარებლებს პრიორიტეტულად აძლევენ აქტივობებს, რომლებიც საუკეთესოდ გამოიყენებენ მათ უნარების კომპლექტს, მონაცემთა შეფერხებების აღმოფხვრა იწვევს პროდუქტიულობის ზრდას.
გამოყენების შემთხვევაში
მონაცემთა ქსოვილის არქიტექტურა მიზნად ისახავს შესთავაზოს ყოვლისმომცველი სტრუქტურა შენახული ინფორმაციის ყველა ფორმის დასამუშავებლად, რათა საჭიროების შემთხვევაში მათი გამოყენება შესაძლებელი გახდეს.
ამ სახის მონაცემების გამოყენება შესაძლებელია ნებისმიერი რამისთვის, გაყიდვების პროგნოზიდან დაწყებული, ორგანიზაციის IT ინფრასტრუქტურის მდგომარეობის ან მომხმარებლის ბოლო წერტილების მდგომარეობის შესახებ მოხსენებამდე.
მონაცემთა ქსოვილის არქიტექტურის გამოყენების შემთხვევები იდენტურია ბიზნესში ნებისმიერი სხვა სახის მონაცემების გამოყენების შემთხვევაში, მათ შორის გაყიდვები, მარკეტინგი, IT, კიბერუსაფრთხოება და სხვა.
თუმცა, ორგანიზაციაში მონაცემები ხშირად არის ორგანიზებული, ნახევრად სტრუქტურირებული ან არასტრუქტურირებული თითქმის ყველა გამოყენების შემთხვევაში. რელაციურ მონაცემთა ბაზაში შეიძლება შეინახოს სტრუქტურირებული მონაცემები და დროულად იქნას გამოყენებული, როგორიცაა მონაცემთა ბაზის ჩანაწერები.
მონაცემები, რომლებიც არ არის გასუფთავებული ან კატეგორიზებული, მოიხსენიება, როგორც არასტრუქტურირებული მონაცემები და უნდა მომზადდეს გამოსაყენებლად საჭიროების შემთხვევაში.
არასტრუქტურირებული მონაცემების რამდენიმე ფორმას, რომლებიც ბევრ ფირმას შეუძლია შეიძინოს და შეინახოს მომავალი გამოყენებისთვის, მოიცავს მანქანა სწავლის, ანალიტიკა, სენსორის მონაცემები, ღრუბლოვანი გამოთვლები და პროდუქტიულობის აპები.
ნახევრად სტრუქტურირებულ მონაცემებში, რომელიც მოიცავს აღიარებული ტიპის მონაცემებს, რომლებიც შენახულია არასტრუქტურირებული მონაცემებით (როგორიცაა zip ფაილები, ვებ გვერდები და ელფოსტა), ორივე ასპექტი არსებობს.
მრავალი შესაძლო გამოყენების შემთხვევა, რომელიც დაფუძნებულია მონაცემთა ქსოვილის შესაძლებლობებზე, დაეხმაროს კომპანიებს მათი მონაცემების უფრო სწრაფად და ეფექტურად წვდომაში და გამოყენებაში, შეიძლება მოიძებნოს მისი გამოყენების შესწავლით.
ტიპიური მაგალითები მოიცავს:
- თაღლითობის გამოვლენა
- IoT ანალიტიკა
- მიწოდების ჯაჭვის ლოჯისტიკა
- რეალურ დროში მონაცემთა ანალიტიკა
- მომხმარებლის დაზვერვა
- ზრდის საოპერაციო ეფექტურობას
- პრევენციული შენარჩუნების ანალიზი
- გარდა ამისა, სამსახურში დაბრუნების რისკის მოდელები
- ტრანზაქციის უზრუნველყოფა საკრედიტო ბარათებით
- Churn პროგნოზირება, თაღლითობის გამოვლენა და საკრედიტო ქულები
დასკვნა
დასასრულს, მონაცემთა სილოები თანდათან უნდა დაიშალა, რადგან ჩვენი მონაცემების გამოყენების დონე იზრდება, რათა ადგილი გაუჩნდეს დაკავშირებულ კომპანიებს.
მონაცემთა ქსოვილების განლაგება წარმოადგენს მნიშვნელოვან წინსვლას ამ გზაზე, რაც 1970-იან წლებში რელაციური მონაცემთა ბაზების შემუშავების შემდეგ ყველაზე რევოლუციურ აღმოჩენებს შორისაა.
ეს იმიტომ ხდება, რომ მონაცემთა ქსოვილი უფრო მეტია, ვიდრე ტექნოლოგია ან ერთი ელემენტი.
მონაცემები და ბიზნეს ოპერაციები რთულად არის გადაჯაჭვული არქიტექტურის დიზაინის, სისტემური პროცედურისა და მენტალიტეტის ცვლილების გზით.
Data Fabric ამცირებს ხარჯებს, ზრდის შესრულებას და ხელს უწყობს ინფრასტრუქტურის უფრო ეფექტურ განლაგებას და შენარჩუნებას. ეს შეიძლება იყოს მთავარი კომპონენტი იმის უზრუნველსაყოფად, რომ თითოეული პროცესი, განაცხადი და ბიზნეს გადაწყვეტილება არის მონაცემების საფუძველზე.





დატოვე პასუხი