インターネットは、その誕生以来、大きな変化を遂げてきました。 それは人間のつながりの基本的な構成要素になり、インターネットリレーチャット(IRC)から現代のソーシャルメディアへと発展し続けています。 それは未来のグローバルコミュニティの町の広場に進化しています。
「Web3.0」というフレーズがインターネット上でバウンドしているのを聞いたことがあるでしょう。 Web3.0の動作とその驚異的な開発を説明するインフォグラフィックを見たことがあるかもしれません。 少なくとも、Web3.0が世界の顔を恒久的に変える方法を説明する短編映画を見たはずです。
上記のいずれも実行しておらず、Web 3.0が何であるかわからない場合は、ここに記事があります。 将来がどうなるかを見極める前に、インターネットの黎明期を振り返ってみましょう。
ウェブの進化
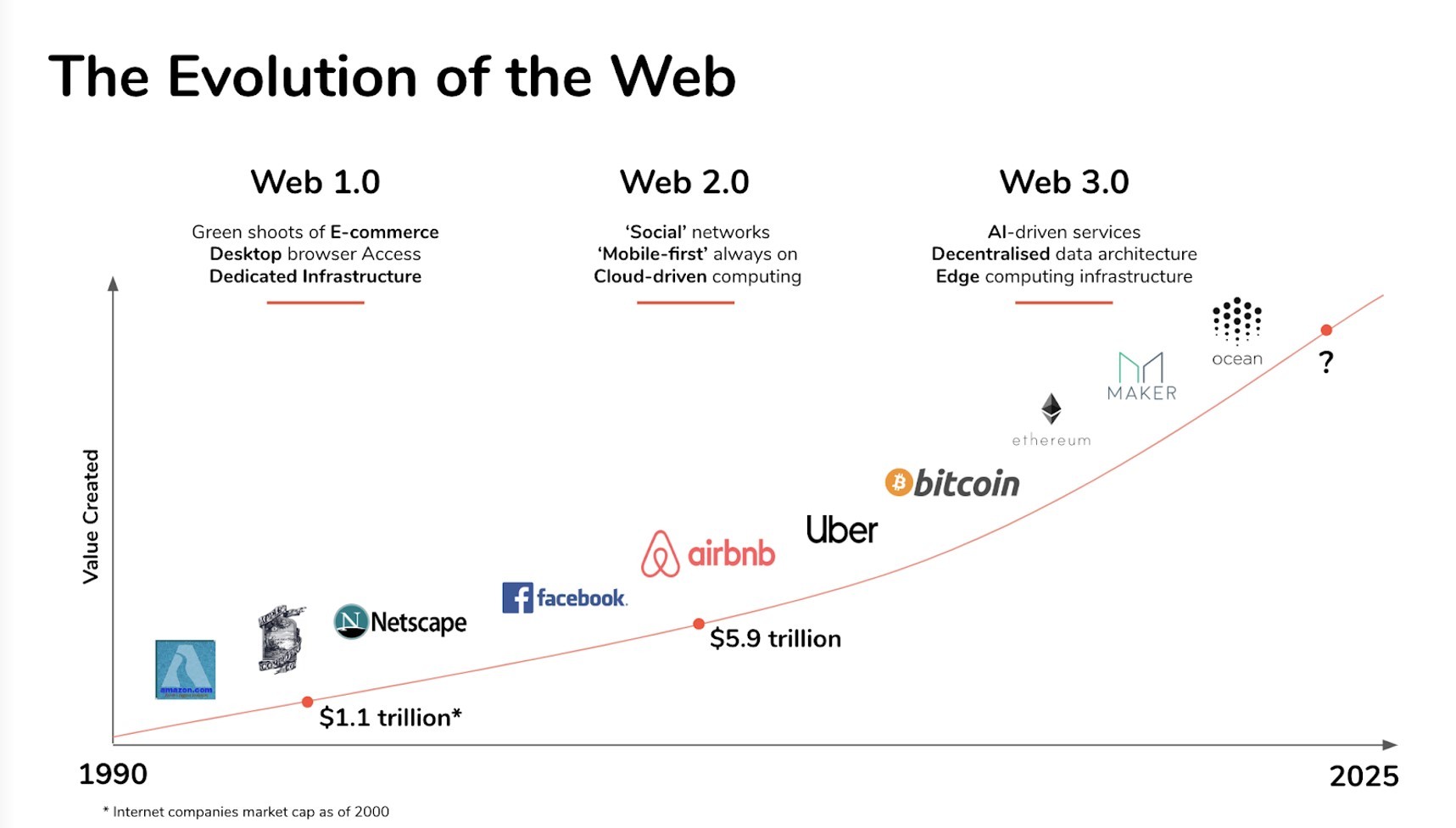
Webは何年にもわたって大幅に成長しており、今日のそのアプリケーションは、その初期の頃からほとんど認識できません。 Webの進化は、Web 1.0、Web 2.0、およびWeb3.0のXNUMXつの段階に分けられることがあります。
ウェブ1.0
今日の若者がGoogle、Facebook、またはInstagramストーリーなしでインターネットを想像することは不可能です。 しかし、1990年代半ばから2000年代初頭にかけて、インターネットの古典的な時代がありました。 Web 1.0は、インターネットの最初の化身でした。 参加者の大多数はコンテンツの消費者でしたが、作成者は主にテキストまたは画像形式で資料を配信するWebサイトを構築した開発者でした。
ダイナミックHTMLの代わりに、Web1.0サイトは静的な素材を提供していました。 データとコンテンツはデータベースではなく静的ファイルシステムを介して提供され、Webページには双方向性がありませんでした。 ビデオストリーミングの概念は存在しませんでした。 人々は「オンラインで話す」ためにAOLのチャットルームに群がります。
XNUMX曲をダウンロードするのに丸一日かかりました。 ダイヤルアップでインターネットに接続するときは、固定電話を外さなければなりませんでした。 いいえ、携帯電話は存在しませんでした。 絵文字を使用せずに、個人と直接コミュニケーションをとる必要がありました。 それはひどいものでした、私はあなたに言います!
ウェブ2.0
インターネットは、2000年代初頭の歴史の転換点にありました。 それは一方向の退屈な図書館のままであるかもしれません、あるいはそれは世界中からの人々をつなぐ驚くべき革新になるかもしれません。 幸い、2番目のオプションを選択しました。 WebXNUMXユニバースのクリエイティブなプロセスに参加するために、開発者である必要はありません。 多くのアプリケーションは、誰もが単にメーカーになることができるように設計されています。
の開発で ソーシャルメディア、ユーザーはついに「ネット」で没入型の体験を楽しむことができました。 これで、ビデオコンテンツをYouTubeに公開してブロードキャストできるようになり、Googleはあらゆるものの頼れるサイトになりました。 Web2は信じられないほどシンプルであり、そのため、世界中でますます多くの個人がクリエーターになりつつあります。
Web2は、観察ではなく参加に関するものでした。 2000年代半ばまでに、ほとんどのWebサイトはすでにWeb2(Web 2.0)に移行していました。 オンラインゲームは、世界中のプレイヤー間のマルチプレイヤーインタラクションを可能にしました。 Facebookで恋人をストーカーし、Instagramでペットの面白い写真を共有することができますが、それはスマートフォンからのみです。
では、Web 3.0とは何ですか?
Web 3.0は、インターネットの成長における次の段階であり、Webのコントロールパッドを消費者の手に戻します。 この違いは、インターネットがピアツーピア(P2P)の信頼できないシステムとして機能することを可能にするブロックチェーンなどの新しいテクノロジーによって生み出されています。
web2とweb3の間にはいくつかの本質的な違いがありますが、分散化は両方の中心にあります。 Web3アプリケーション(Dapps)は、次のような分散型ピアツーピアネットワーク上に構築されています。 Ethereum & IPFS。 これらのネットワークは、企業ではなくユーザーによって構築、実行、および保守されます。 それらは自己組織化し、単一障害点はありません。
これは、Webの成長の第XNUMX段階であり、多くの場合、読み取り-書き込み-実行段階として知られ、Webの将来に関連しています。 人工知能(AI)と 機械学習 (ML)コンピューターが人間と同じ方法でデータを理解できるようにします。 Web 3.0の目標は、インターネットを開放して分散化することです。
ユーザーは、現時点でシステムを通過するデータを追跡するために、ネットワークおよび携帯電話会社に依存する必要があります。 分散型台帳テクノロジーの出現により、ユーザーは近い将来、データの制御を取り戻すことができるようになります。 ビッグデータ企業やグローバル企業は、もはや個人情報を共有したり、権力や情報を独占したりするべきではありません。
なぜWeb3.0が必要なのですか?
インターネットを介して通信する場合、データのコピーが作成され、GoogleやFacebookなどの企業のサーバーに保持されるため、結果としてデータを制御できなくなります。 私たちの情報が第三者によって保持されているという事実は、本質的に否定的なことではありません。 それでも、XNUMXつの会社がプロセス全体を仲介する場合、問題が発生する可能性があります。
あなたが提供する情報が貪欲や悪意のために悪用される可能性のある社会が必要ですか? これはプライバシーをはるかに超えています。 私たちの問題の根本はコントロールのXNUMXつです。 ペタバイトのデータの所有権を定期的に企業や個人に譲渡しますが、明確な選択肢はありません。
- セキュリティ&プライバシー —最先端の暗号化技術を利用してより優れたWebを構築することで、インターネットユーザーは、企業やハッカーの詮索好きな目から離れて、個人情報を非公開に保つことができます。
- 分散型ストレージ管理 –大きなファイルは小さな部分に分割され、個別に暗号化して複数の場所に保存できます。 IPFSネットワークと同等のプロトコルは、それらを侵害すると、それぞれが独自の保護を備えた世界中の複数のマシンに同時にハッキングする必要があるように構成されています。
- アイデンティティと評判 —オンラインでの信頼と評判にどのように対処するかを心配しているのはあなただけではありません。 実際には、ソーシャルメディアや他のWebサイトで公開されたデータで構成されるオンラインデジタルIDがすでにあります。 主な問題は、新しいWebで変化するデータを、私たちが所有または管理していないことです。
福利厚生
これは、Web 3.0の革新的な品質のコレクションであり、Web XNUMXがどのように動作し、どのように利益を得るかを理解するのに役立ちます。

1。 人工知能
人工知能(AI)は、Web3.0に登場する新しい概念ではありません。 Web2.0アプリケーションではすでに気づいています。 ただし、Web 3.0までに、AIは非常に高速な学習メカニズムを備えているため、AIの存在を否定することは困難です。 AIは、良いデータと悪いデータ、実際の個人とボット、そして最も重要なこととして、偽のニュースと真のレポートをすばやく区別します。
2D仮想ID
Web 3.0は、コミュニケーションと仮想接続の新しい手段をもたらします。 チャット、電子メール、およびビデオ通話は引き続き可能です。 ただし、ユーザーはWeb上で自分を表す3DIDにアクセスできる場合があります。 これらの仮想アバターは、オンラインゲームのキャラクターと同様に、企業の取引、仕事のパートナーシップ、およびデートアプリケーションでの私たちの表現になります。
3.中断のないサービス
データは、Web3.0のいくつかの分散ノードに保存されます。 このアプローチにより、チェーンに供給し、サーバーのストールや障害を防ぐのに十分なバックアップノードが常に存在するようになります。 簡単に言えば、壊滅的なサーバー障害の結果としてインターネットが利用できなくなることはありません。
4。 データ所有権
Web 3.0が実現すると、Amazon、Facebook、Googleなどの大企業は、顧客のデータを保持するために工場規模のサーバーを必要としなくなります。 代わりに、インターネットユーザーは、財務情報、ログイン情報などを含むデータを完全に制御できます。
5.セマンティックメタデータ
セマンティックメタデータは、データの「意味」を説明するデータです。 データが存在するあらゆる環境で特定のアイデアを反映する値があります。 セマンティックメタデータは、Web3.0の重要なコンポーネントになります。 この方法により、Webは記号、キーワード、およびメッセージの意味を理解できるようになります。 たとえば、ネットワークは、XNUMXつのドットとそれに続く円弧で構成される古典的な「スマイリー」絵文字を検出します。 それでも、それは人間の笑顔、喜びと受容のジェスチャーを表していることを認識します。
課題
Web 3.0は、他の新しいテクノロジと同様に、少なくとも最初は、現在の状態で展開するのは困難です。 Web3.0の問題と欠点は次のとおりです。
1.取得が遅い
最後に、Web3.0は誰にとっても一発屋ではありません。 より経験豊富なインターネットユーザーは、Web1.0が世界的な注目を集めるのに2.0年近くかかったことを思い出すかもしれません。 Web XNUMXが登場したとき、それはそのスマートテクノロジーとソーシャルメディアをもたらしましたが、人々はまだチャットルームと電子メールがどのように機能するかを理解していました。 多くの企業は、集中型ネットワークから信頼できないチェーンへの移行に時間をかけます。
多くのガジェットは古くなりますが、ユーザーはWeb3.0にすぐに移行できなくなります。 その結果、Web2.0とWeb3.0は当面共存します。
2.人間による不正行為
Web 3.0は、技術の進歩において画期的な一歩であるように思われます。 その出版物は、インターネットとの相互作用における「前後」のポイントを表す可能性が最も高いでしょう。 しかし、動機の悪い人が存在し続けることを忘れてはなりません。
悪意のあるユーザーは、意図的に虚偽または誤解を招くような素材でWebを氾濫させ、オンライン犯罪に理想的な環境を作り出す可能性があります。 ハッキング攻撃、暗号化、および Artificial Intelligence 学習方法は、迅速に改善および更新する必要があります。
まとめ
インターネットは長い間進化してきましたが、今後も確実に進化し続けるでしょう。 アクセスできないデータが大幅に拡大しているため、ウェブサイトやアプリは、世界中でますます多くの人々にはるかに優れたエクスペリエンスを提供するウェブに移行する可能性があります。 現時点では、Web3(Web 3.0)の明確な定義はありませんが、他のセクターでの技術的な進歩によってすでに促進されています。
より分散化されたインターネットに向かって進むにつれて、 拡張現実 (AR)と人工知能(AI)がユースケースのシナリオを定義する上で重要な役割を果たしているため、世界的なインターネット革命の新たな波が予想されるかもしれません。
Web 3.0は、開発者に創造性のために切望されていた柔軟性を提供します。 一方、ユーザーは改善を期待するかもしれません デジタル体験 全体的に、よりアップグレードされ洗練されたインターネットもあります。 正しく実行されれば、Web 3.0は時間を節約し、低コストで生産性を向上させる可能性があります。 信じられないかもしれませんが、インターネットはここにとどまるため、よりスマートなインターネットが期待できます。





コメントを残す