短期集中コースの XNUMX 回目の講義へようこそ。
この講義では、Python で文字列を扱う方法を学びます。 ポップコーンを準備して、しっかりと座ってください。
弦
まず、引用符について説明し、Python で引用符が引き起こす可能性のある混乱を解消しましょう。
前に述べたように、Python では関数の後に一重引用符と二重引用符の両方を使用できます。 これには特別な有用性があります。 このようなものを印刷したいとします。
print('This is Shahbaz's computer')
上記の式では、Python は XNUMX 番目の引用符を文字列の終わりとして受け取るため、「Shahbaz's」のように XNUMX 番目の引用符以降はすべて Python インタプリタによって識別されません。 その場合、二重引用符を使用して次のように文字列を宣言します。
print("This is Shahbaz's computer")
これは逆にも適用でき、文字列内に二重引用符がある場合は一重引用符を使用できます。 例えば
print('This "computer" belongs to Shahbaz')
複数行にまたがる文字列を出力したい場合は、三重引用符を使用して文字列を囲む必要があります。 これらの引用符は、文字列の内容に応じて単一引用符または二重引用符にすることもできます。 例えば:
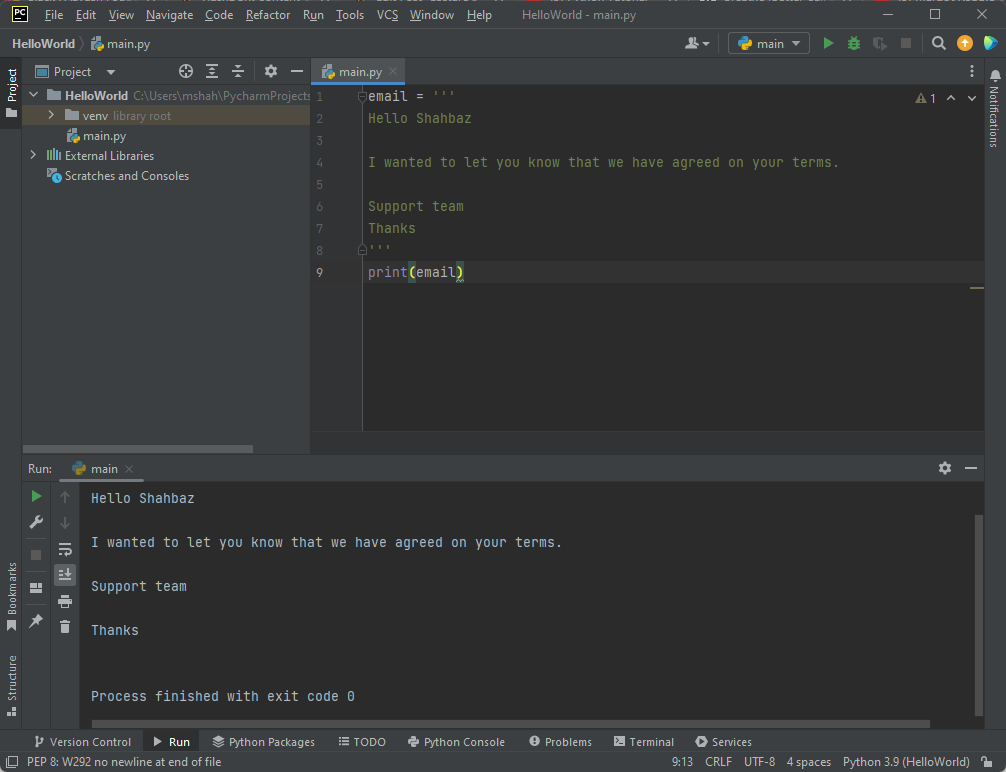
ここで、文字列から特定の文字を出力したいとします。 どうすればそうなりますか?
Python インタープリターは、次のように文字列内の文字にインデックスを付けます。
ターミナルでわかるように、「h」のみが出力されています。 これは、変数の後に角括弧内に 3 を書き込むことで、端末に表示する文字列の 1 番目の文字だけを選択しているためです。 Python インタープリターは、大きな文字列を簡素化するために、文字に負のインデックスを付けます。 つまり、「-21」が文字列の最後の数値になる、ということになります。 スペースにはインデックスが付けられていないことに注意してください。つまり、上記の文字列にはインデックス付きスペースが XNUMX 個しか含まれていません。
文字列から一連の文字を選択することもできます。 例えば
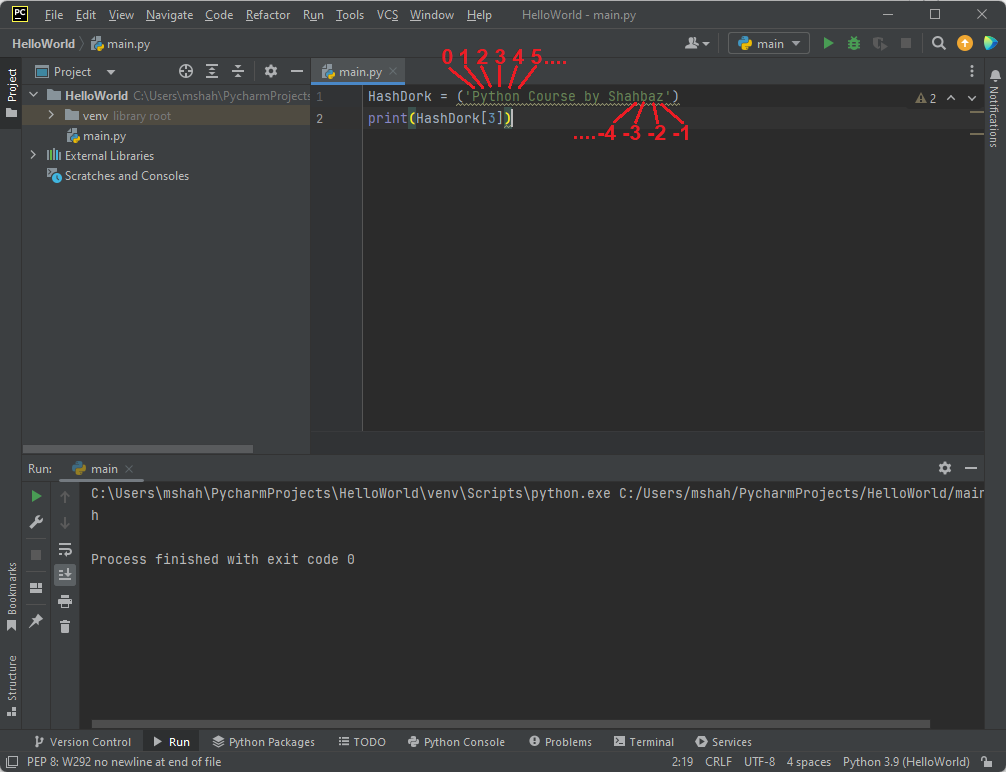
HashDork = ('Python Course by Shahbaz')
print(HashDork[0:3])
このプログラムは端末に「Pyt」と表示します。 インデックス 3 はここから除外されます。
HashDork = ('Python Course by Shahbaz')
print(HashDork[2:])
同様に、終了インデックスを指定しない場合、Python は最初のインデックスの後の文字列全体を出力します。 このプログラムの出力は「thon Course by Shahbaz」になります。 これは逆も同様です。 つまり、最初のインデックスを見逃した場合は、先頭から最後に定義されたインデックスまでの文字列全体が出力されます。
インデックス括弧内にコロンのみを含むプログラムでは、端末上に完全な文字列が表示されます。
エクササイズ
ここに興味深い練習があります
[1:-1] のインデックス間隔を定義するプログラムを作成します。 出力は何になると思いますか。 自分で試してみてください。
フォーマットされた文字列
フォーマットされた文字列は、変数を使用してテキストを動的に生成する状況で特に役立ちます。 披露させて。
名と姓という XNUMX つの変数があるとします。
first_name = 'Shahbaz'
last_name = 'Bhatti'
ここで、端末に「Shahbaz [Bhatti] is a coder」と出力したいと思います。 どうすればいいでしょうか? 次のような XNUMX 番目の変数を導入します。
message = 'first_name + ' [' + last_name + '] is a coder'
このプログラムを印刷して実行すると、端末上に「Shahbaz [Bhatti] is a coder」というメッセージが表示されます。
このアプローチは完全に機能しますが、テキストが複雑になるにつれて出力を視覚化するのが難しくなるため、理想的ではありません。 ここではフォーマットされた文字列を使用します。これにより、出力を視覚化しやすくなります。
XNUMX 番目の変数「message」を変更し、フォーマットされた文字列を導入しましょう。 書式設定された文字列を定義するには、文字列の前に「 f 」を付け、中括弧を使用して値を文字列に動的に挿入します。 私たちのプログラムは次のようになります。
first_name = 'Shahbaz'
last_name = 'Bhatti'
message = f'{first_name} [{last_name}] is a coder'
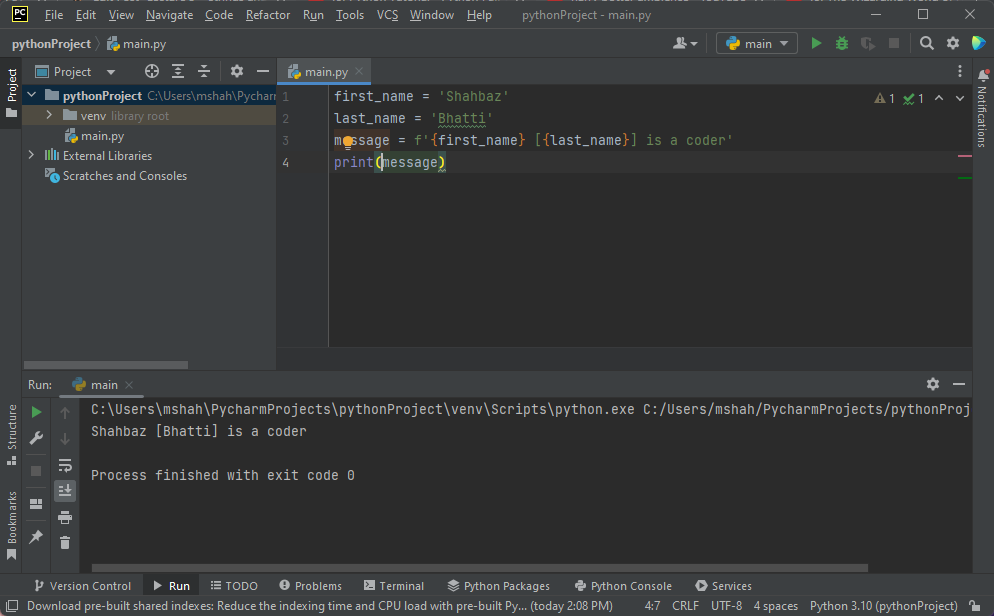
書式設定された文字列を定義するには、文字列の先頭に F を付け、中括弧を使用して値を文字列に動的に挿入します。
Python 文字列でできる素晴らしいこと
Python 文字列を使ってできる本当に素晴らしいことをいくつか紹介します。
1. 文字列内の文字数
それでは、変数を定義することから始めましょう。
message = 'Shahbaz Bhatti is a Coder '
ここで、上記の文字列の文字数を調べたい場合、Python には組み込み関数 ” len ” があります。 この関数で変数を次のように出力するだけです
print(len(message))
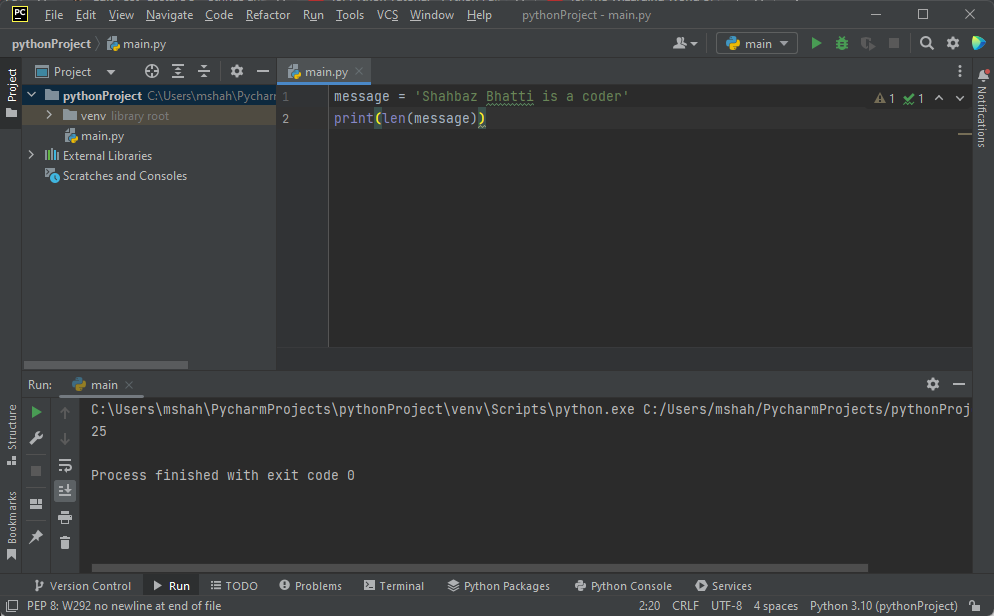
これは、ユーザーから入力を受け取る場合に特に便利です。 たとえば、オンラインでフォームに記入する場合、各入力フィールドには制限があることがよくあります。 たとえば、名前が 50 文字である場合、この「len」関数を使用して、入力フィールドの文字数に制限を適用できます。
2. 文字列内の文字を大文字または小文字に変換する
ドット演算子を介して文字列関連の関数にアクセスできます。 変数名を入力し、その前にドットを置くと、そのようなすべての関数のリストが表示されます。
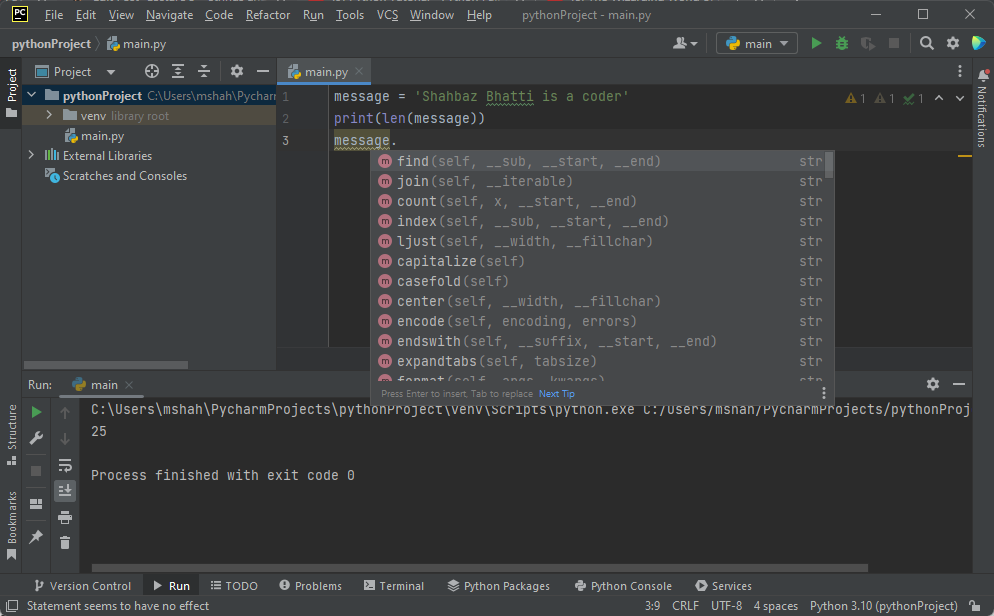
より正確に言うと、これらの関数をメソッドと呼びます。これはオブジェクト指向プログラミングの用語であり、今後検討していきたいと考えていますが、現時点では理解していただきたいのは、関数が他のものに属している場合、またはある種のオブジェクトに固有である場合、その関数をメソッドと呼ぶということです。 この場合、文字列を大文字に変換するメソッド「upper」を使用します。
この関数は文字列に固有であるため、これをメソッドと呼びます。 対照的に、「len」と「print」は汎用関数であり、文字列、数値、その他の種類のオブジェクトには属しません。 これが関数とメソッドの基本的な違いです。
では、これを印刷してみましょう。
message = 'Shahbaz Bhatti is a coder'
print(message.upper())
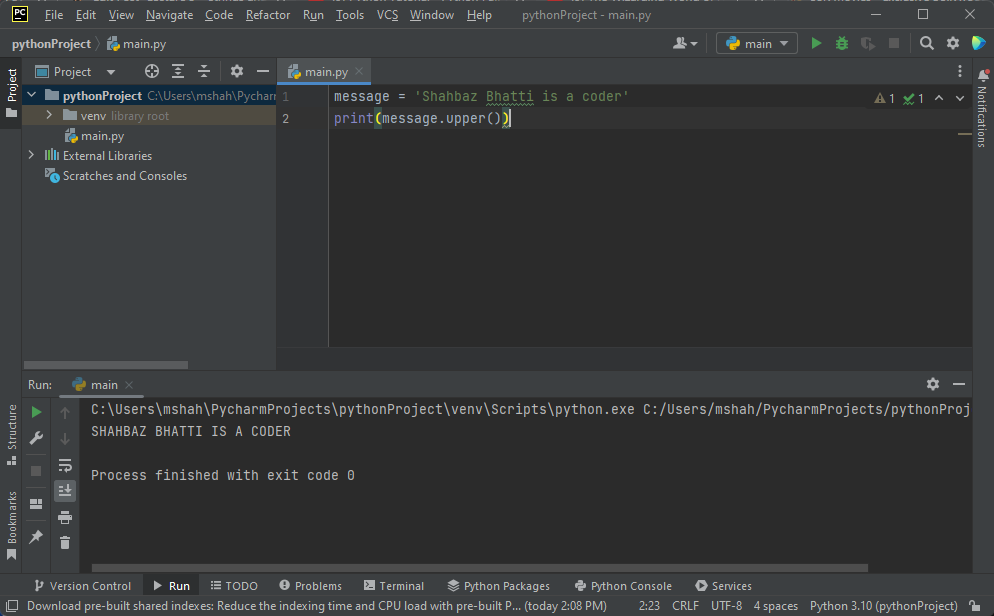
そして、文字列が大文字になっていることがわかります。 同様に、文字列を小文字に変換するメソッド「 lower 」があります。 「title」メソッドを使用して、文字列の各単語を大文字にすることもできます。
このメソッドは元の文字列を変更したり修正したりしないことに注意してください。 実際には、新しい文字列を作成して返します。
3. 文字列内の文字のシーケンスを見つける
別の方法を試して、文字列内の特定の文字のインデックスを見つけてみましょう。
タイプ:
message.find('b')
同じ変数の後に続けて出力します。 文字列内で最初に出現する文字「b」のインデックス (この場合は 4) が出力されます。
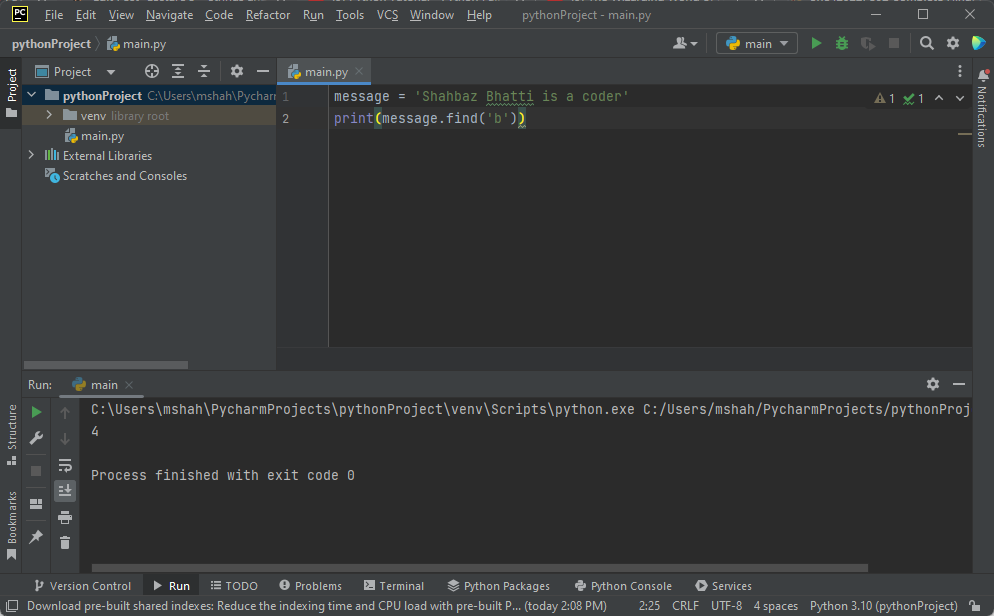
このメソッドでは大文字と小文字が区別され、文字列内に文字が見つからない場合は -1 が返されることに注意してください。 一連の文字にも使用できます。
たとえば、次のようなプログラムです。
message = 'Shahbaz Bhatti is a coder'
print(message.find('coder'))
シーケンス「coder」はインデックス 20 から始まるため、値「20」を返します。
4. 文字列内の文字を置換する
「replace」メソッドを使用すると、文字列内の XNUMX 文字または一連の文字を置換できます。 これを実際に見てみましょう。
message = 'Shahbaz Bhatti is a coder'
print(message.replace('coder', 'programmer'))
このプログラムは、「コーダー」という単語を「プログラマー」に置き換えて端末に表示します。

5. 文字列内の文字の存在を確認する
文字列内の文字または文字のシーケンスの存在を確認したい場合があります。 そのような状況では、次のように式の形式を使用できます。
message = 'Shahbaz Bhatti is a coder'
print(メッセージ内の「Python」)
これでブール関数が返されます。 つまり、「真」または「偽」です。 このような;
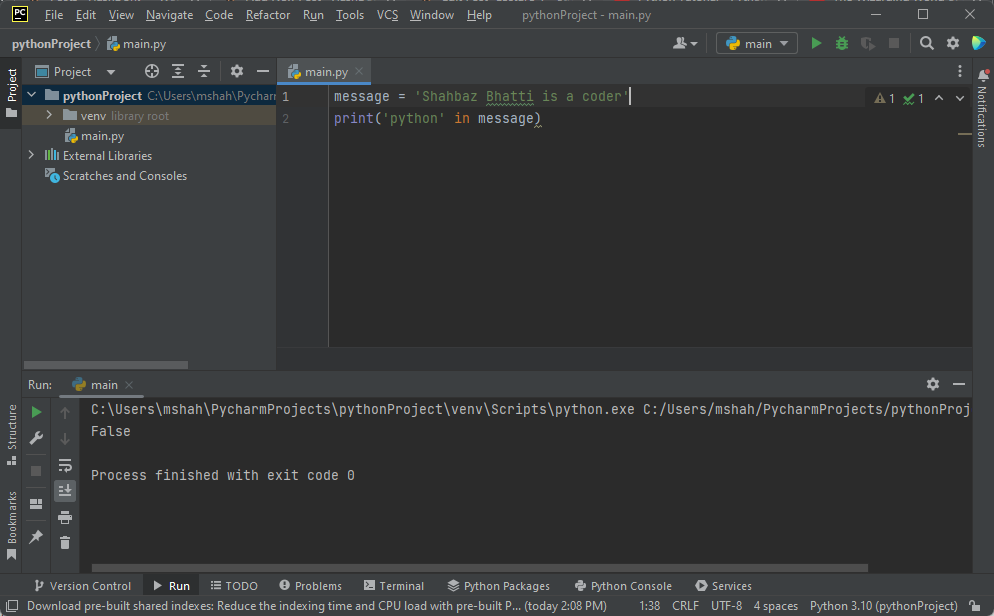
これらのメソッドと関数はすべて大文字と小文字が区別されることに注意してください。
要約!
文字列には他にもたくさんの機能があり、先に進むにつれて徐々に学習していきます。 次に、Python で算術演算を実行する方法を学習します。




コメントを残す