コンピューターのおかげで、空間の広がりと素粒子の微細な複雑さを計算できるようになりました。
電子がその回路を介して光速で移動するおかげで、コンピューターは、カウントと計算、および論理的なyes / noプロセスに従うことに関して、人間を打ち負かします。
しかし、過去には、コンピューターは人間に教えられ(プログラムされ)なければ何も実行できなかったため、それらを「インテリジェント」と見なすことはあまりありません。
深層学習を含む機械学習と 人工知能、科学技術の見出しの流行語になっています。
機械学習はどこにでもあるように見えますが、この単語を使用する多くの人々は、それが何であるか、何をするか、そして何に最適であるかを適切に定義するのに苦労します。
この記事では、機械学習を明確にすると同時に、テクノロジーがどのように機能するかについての具体的な実例を示し、なぜそれが非常に有益であるかを説明します。
次に、さまざまな機械学習の方法論を見て、ビジネス上の課題に対処するためにそれらがどのように使用されているかを確認します。
最後に、機械学習の将来についての簡単な予測について、水晶玉を調べます。
機械学習とは何ですか?
機械学習は、コンピューターがデータからパターンを推測できるようにするコンピューターサイエンスの分野であり、それらのパターンが何であるかを明示的に教えられることはありません。
これらの結論は、多くの場合、アルゴリズムを使用してデータの統計的特徴を自動的に評価し、さまざまな値の間の関係を表す数学モデルを開発することに基づいています。
これを、決定論的システムに基づく従来のコンピューティングと比較してください。このコンピューティングでは、特定のタスクを実行するために従うべき一連のルールをコンピューターに明示的に与えます。
コンピュータをプログラミングするこの方法は、ルールベースのプログラミングとして知られています。 機械学習は、ルールベースのプログラミングとは異なり、ルールベースのプログラミングよりも優れています。これは、これらのルールを独自に推測できるという点です。
あなたが銀行のマネージャーで、ローンの申し込みが失敗するかどうかを判断したいとします。
ルールベースの方法では、銀行のマネージャー(または他の専門家)は、申請者のクレジットスコアが特定のレベルを下回っている場合、申請を拒否する必要があることをコンピューターに明示的に通知します。
ただし、機械学習プログラムは、クライアントの信用格付けとローンの結果に関する以前のデータを分析し、このしきい値を単独で決定するだけです。
マシンは以前のデータから学習し、この方法で独自のルールを作成します。 もちろん、これは機械学習の入門書にすぎません。 実際の機械学習モデルは、基本的なしきい値よりもはるかに複雑です。
それにもかかわらず、それは機械学習の可能性の優れたデモンストレーションです。
どのように 機械 学び?
物事を単純に保つために、マシンは比較可能なデータのパターンを検出することによって「学習」します。 データは、外の世界から収集した情報であると考えてください。 マシンに供給されるデータが多いほど、マシンは「よりスマート」になります。
ただし、すべてのデータが同じというわけではありません。 あなたが島に埋もれている富を暴くという人生の目的を持った海賊だとしましょう。 賞品を見つけるには、かなりの知識が必要になります。
この知識は、データと同様に、正しい方法または間違った方法であなたを導く可能性があります。
取得する情報/データが多ければ多いほど、あいまいさが少なくなり、その逆も同様です。 結果として、学習するためにマシンにフィードしているデータの種類を考慮することが重要です。
ただし、大量のデータが提供されると、コンピューターは予測を行うことができます。 機械は、過去から大きく逸脱しない限り、未来を予測することができます。
マシンは、履歴データを分析して何が起こりそうかを判断することで「学習」します。
古いデータが新しいデータに似ている場合、前のデータについて言えることが新しいデータに当てはまる可能性があります。 それはまるであなたが前向きに振り返っているようなものです。
機械学習の種類は何ですか?
機械学習のアルゴリズムは、多くの場合、大きくXNUMXつのタイプに分類されます(他の分類スキームも使用されます)。
- 教師あり学習
- 教師なし学習
- 強化学習
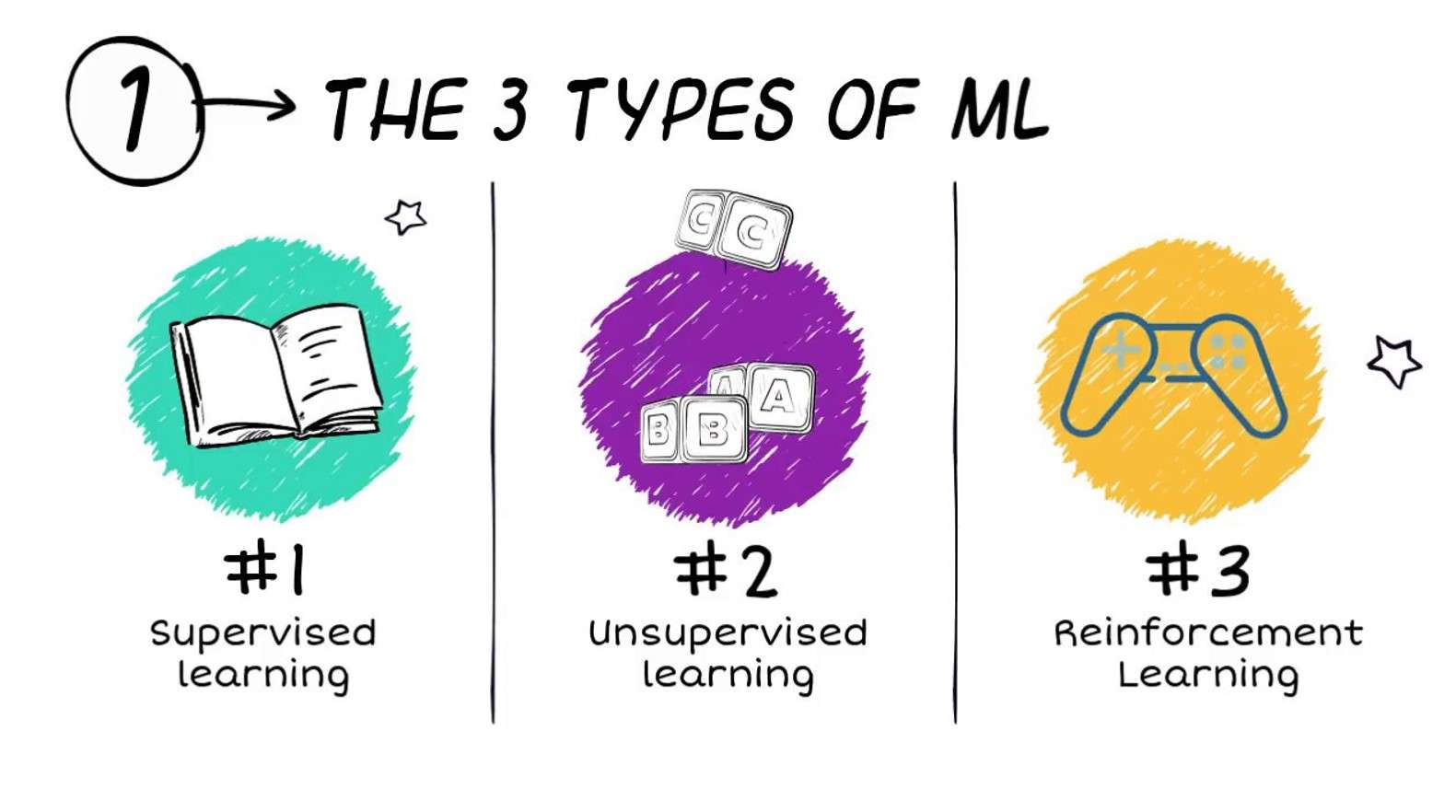
教師あり学習
教師あり機械学習とは、機械学習モデルに、対象の量の明示的なラベルが付いたデータのコレクションを与える手法を指します(この量は、多くの場合、応答またはターゲットと呼ばれます)。
AIモデルをトレーニングするために、半教師あり学習では、ラベル付きデータとラベルなしデータを組み合わせて使用します。
ラベルのないデータを使用している場合は、データのラベル付けを行う必要があります。
ラベリングは、サンプルにラベルを付けて支援するプロセスです。 機械学習のトレーニング モデル。 ラベル付けは主に人が行うため、費用と時間がかかる可能性があります。 ただし、ラベル付けプロセスを自動化する手法があります。
前に説明したローン申請の状況は、教師あり学習の優れた例です。 以前のローン申請者の信用格付け(およびおそらく収入レベル、年齢など)に関する履歴データと、問題の人物がローンをデフォルトしたかどうかを示す特定のラベルがありました。
回帰と分類は、教師あり学習手法のXNUMXつのサブセットです。
- Classification –アルゴリズムを使用してデータを正しく分類します。 スパムフィルターはその一例です。 「スパム」は主観的なカテゴリである可能性があります。スパム通信と非スパム通信の境界線はあいまいです。スパムフィルタアルゴリズムは、フィードバック(人間がスパムとしてマークする電子メール)に応じて絶えず改良されています。
- 不具合 –従属変数と独立変数の間の関係を理解するのに役立ちます。 回帰モデルは、特定の会社の売上高の見積もりなど、いくつかのデータソースに基づいて数値を予測できます。 線形回帰、ロジスティック回帰、および多項式回帰は、いくつかの顕著な回帰手法です。
教師なし学習
教師なし学習では、ラベルのないデータが与えられ、パターンを探しているだけです。 あなたがアマゾンだとしましょう。 クライアントの購入履歴に基づいてクラスター(類似した消費者のグループ)を見つけることができますか?
個人の好みに関する明確で決定的なデータはありませんが、この場合、特定の消費者が同等の商品を購入していることを知っているだけで、クラスター内の他の個人が購入したものに基づいて購入提案を行うことができます。
アマゾンの「あなたも興味があるかもしれない」カルーセルは、同様の技術を搭載しています。
教師なし学習では、グループ化する対象に応じて、クラスタリングまたは関連付けを通じてデータをグループ化できます。
- クラスタリング –教師なし学習は、データ内のパターンを検索することにより、この課題を克服しようとします。 同様のクラスターまたはグループがある場合、アルゴリズムはそれらを特定の方法で分類します。 以前の購入履歴に基づいてクライアントを分類しようとすることは、この例です。
- 協会 –教師なし学習は、さまざまなグループの根底にあるルールと意味を理解しようとすることで、この課題に取り組みます。 アソシエーションの問題のよくある例は、顧客の購入間のリンクを決定することです。 店舗は、一緒に購入した商品を知りたい場合があり、この情報を使用して、簡単にアクセスできるようにこれらの商品の配置を調整できます。
強化学習
強化学習は、機械学習モデルを教えて、インタラクティブな設定で一連の目標指向の意思決定を行うための手法です。 上記のゲームのユースケースは、これを示す優れた例です。
AlphaZeroの何千もの以前のチェスゲームを入力する必要はありません。それぞれに「良い」または「悪い」動きのラベルが付いています。 ゲームのルールと目標を教えてから、ランダムな行動を試してみましょう。
プログラムを目標に近づける活動(しっかりとしたポーンポジションの開発など)には、積極的な強化が与えられます。 行為が逆の効果をもたらす場合(王を時期尚早にシフトするなど)、それらは負の強化を獲得します。
ソフトウェアは、最終的にこの方法を使用してゲームをマスターできます。
強化学習 ロボット工学では、複雑でエンジニアリングが難しいアクションをロボットに教えるために広く使用されています。 交通の流れを改善するために、信号機などの道路インフラと組み合わせて使用されることがあります。
機械学習で何ができるでしょうか?
社会や産業で機械学習を使用することで、人間のさまざまな取り組みが進歩しています。
私たちの日常生活では、機械学習がGoogleの検索アルゴリズムと画像アルゴリズムを制御するようになり、必要なときに必要な情報とより正確に一致させることができます。
たとえば、医学では、機械学習が遺伝子データに適用され、医師が癌の広がりを理解して予測し、より効果的な治療法を開発できるようになっています。
深宇宙からのデータは、ここ地球上で巨大な電波望遠鏡を介して収集されています。機械学習で分析された後、ブラックホールの謎を解明するのに役立っています。
小売店での機械学習は、購入者とオンラインで購入したいものを結び付け、店舗の従業員が実店舗でクライアントに提供するサービスを調整するのにも役立ちます。
機械学習は、無実の人々を傷つけたい人々の行動を予測するために、テロや過激主義との戦いに採用されています。
自然言語処理(NLP)とは、コンピューターが機械学習を通じて人間の言語で私たちを理解し、コミュニケーションできるようにするプロセスを指します。これにより、翻訳テクノロジーや、次のような日常的に使用される音声制御デバイスに飛躍的な進歩がもたらされました。 Alexa、Googleドット、Siri、Googleアシスタント。
間違いなく、機械学習はそれが革新的なテクノロジーであることを示しています。
私たちと一緒に働き、完璧なロジックと超人的なスピードで私たち自身の独創性と想像力を高めることができるロボットは、もはや空想科学小説ではなく、多くの分野で現実のものになりつつあります。
機械学習のユースケース
1。 サイバーセキュリティ
ネットワークがより複雑になるにつれて、サイバーセキュリティの専門家は、拡大し続けるセキュリティの脅威に適応するためにたゆまぬ努力を重ねてきました。
急速に進化するマルウェアやハッキングの戦術に対抗することは十分に困難ですが、モノのインターネット(IoT)デバイスの急増により、サイバーセキュリティ環境は根本的に変化しました。
攻撃はいつでもどこでも発生する可能性があります。
ありがたいことに、機械学習アルゴリズムにより、サイバーセキュリティ運用はこれらの急速な発展に追いつくことができました。
予測分析 攻撃の迅速な検出と軽減を可能にし、機械学習はネットワーク内のアクティビティを分析して、既存のセキュリティメカニズムの異常と弱点を検出できます。
2.カスタマーサービスの自動化
ますます多くのオンラインクライアントの連絡先を管理することは、多くの組織に負担をかけています。
同社には、受け取っている大量の問い合わせに対応できるだけの十分な顧客サービス担当者がいないため、問題を専門業者にアウトソーシングする従来のアプローチが必要です。 コンタクトセンター それは今日のクライアントの多くにとっては受け入れがたいものです。
機械学習技術の進歩により、チャットボットやその他の自動システムがこれらの要求に対応できるようになりました。 企業は、日常的で優先度の低い活動を自動化することにより、人員を解放して、より高度な顧客サポートを引き受けることができます。
正しく使用すると、ビジネスでの機械学習は問題解決を合理化し、消費者が熱心なブランドチャンピオンになるための役立つサポートを提供するのに役立ちます。
3。 通信
エラーや誤解を避けることは、あらゆるタイプのコミュニケーションにおいて重要ですが、今日のビジネスコミュニケーションではさらに重要です。
単純な文法上の誤り、不適切なトーン、または誤った翻訳により、電子メールでの連絡、顧客評価、 ビデオ会議、またはさまざまな形式のテキストベースのドキュメント。
機械学習システムは、MicrosoftのClippyの忙しい日々をはるかに超えて高度なコミュニケーションを実現しています。
これらの機械学習の例は、自然言語処理、リアルタイムの言語翻訳、および音声認識を使用して、個人が簡単かつ正確にコミュニケーションするのに役立ちました。
多くの人は自動修正機能を嫌いますが、恥ずかしい間違いや不適切な口調から保護されることも大切にしています。
4.オブジェクト認識
データを収集して解釈する技術はしばらく前から存在していましたが、コンピューターシステムに、彼らが見ているものを理解するように教えることは、一見難しい作業であることが証明されています。
機械学習アプリケーションにより、オブジェクト認識機能がますます多くのデバイスに追加されています。
たとえば、自動運転車は、プログラマーが参照として使用するその車の正確な例を示していなくても、別の車を見るとそれを認識します。
このテクノロジーは現在、小売業でチェックアウトプロセスのスピードアップに使用されています。 カメラは消費者のカート内の製品を識別し、店を出るときに自動的にアカウントに請求できます。
5.デジタルマーケティング
今日のマーケティングの多くは、さまざまなデジタルプラットフォームとソフトウェアプログラムを使用してオンラインで行われています。
企業が消費者と購入行動に関する情報を収集すると、マーケティングチームはその情報を使用して、ターゲットオーディエンスの詳細な全体像を構築し、どの人々が自社の製品やサービスを探す傾向があるかを見つけることができます。
機械学習アルゴリズムは、マーケターがそのすべてのデータを理解し、可能性を厳密に分類できるようにする重要なパターンと属性を発見するのに役立ちます。
同じテクノロジーにより、大規模なデジタルマーケティングの自動化が可能になります。 広告システムは、新しい見込み消費者を動的に発見し、適切な時間と場所で関連するマーケティングコンテンツを提供するように設定できます。
機械学習の未来
より多くの企業や巨大な組織が特定の課題に取り組んだり、イノベーションを促進したりするためにテクノロジーを使用するにつれて、機械学習は確かに人気を集めています。
この継続的な投資は、特に上記の確立された再現可能なユースケースのいくつかを通じて、機械学習がROIを生み出しているという理解を示しています。
結局のところ、テクノロジーがNetflix、Facebook、Amazon、Googleマップなどに十分に適している場合、それはあなたの会社がそのデータを最大限に活用するのにも役立つ可能性があります。
新品同様 機械学習 モデルが開発され、発売されると、業界全体で使用されるアプリケーションの数が増加します。
これはすでに起こっています 顔認識、これはかつて iPhone の新しい機能でしたが、現在ではさまざまなプログラムやアプリケーション、特に公安に関連するものに実装されています。
機械学習を始めようとしているほとんどの組織にとって重要なのは、明るい未来的なビジョンを見過ごして、テクノロジーが役立つ実際のビジネス上の課題を発見することです。
まとめ
工業化後の時代に、科学者や専門家は、より人間のように振る舞うコンピューターを作成しようとしてきました。
思考機械は、AIが人類に最も重要な貢献をしているものです。 この自走式機械の驚異的な登場により、企業の運用規制は急速に変化しました。
最近、自動運転車、自動アシスタント、自律製造の従業員、スマートシティがスマートマシンの実行可能性を実証しています。 機械学習の革命、そして機械学習の未来は、長い間私たちと共にあります。





コメントを残す