大規模なテキストから画像へのモデルは、特定のテキスト プロンプトから高品質で多様な画像合成を生成することにより、AI の開発に大きな進歩をもたらしました。
これらのモデルは、さまざまな設定で対象の一意の表現を合成したり、特定の参照セットで対象の外観を複製したりすることができません。
OpenAI の DALL.E2 や StabilityAI のような新しくリリースされたテクノロジー 安定拡散 と Midjourney は、すでにインターネットを席巻しています。 ここで、結果をカスタマイズします。 しかし、どのように?
Google DreamBooth AI が登場しました。
DreamBooth には、写真のトピックを認識し、元のコンテキストから解体し、新しい望ましいコンテキストに正確に合成する機能があります。 さらに、現在の AI 画像ジェネレーターで使用できます。
この記事では、DreamBooth、その使用法、チュートリアル、制限事項などについて詳しく見ていきます。
ドリームブースとは?
ドリームブーステキストから画像へのまったく新しい拡散モデルである が、Google によって発表されました。 書面によるプロンプトは、Google DreamBooth AI によるガイダンスとして使用され、ユーザーが選択した被写体の幅広い写真をさまざまな設定で生成できます。
ボストン大学と Google の研究グループは、DreamBooth を開発しました。DreamBooth は、広範な事前トレーニングを受けたテキストから画像へのモデルを変更する最先端の技術です。
全体的なコンセプトはかなり単純です。彼らは、言語と視覚の辞書を増やして、一般的ではないトークン ID をユーザーが定義できるカスタム トピックに関連付けたいと考えています。
モデルの主な目標は、ユーザーを テキストから画像への拡散モデル 選択した主題のインスタンスの写実的な表現を作成するために必要なリソースを提供することによって。
結果として、この手法は、さまざまな状況で課題を要約するのにうまく機能するようです。
Google の DreamBooth は、次のような以前のテキストから画像へのツールとは異なります。 DALL-E2, 安定拡散, ミッドジャーニー、ユーザーがテキストベースの入力を使用して拡散モデルを操作できるようにする前に、トピック画像をより詳細に制御できるという点で。
特徴
- DreamBooth AI は、3 ~ 5 個の画像でテキストから画像へのモデルを改善する可能性があります。
- DreamBooth AI を使用して、フォトリアリスティックなオリジナル写真を作成できます。
- さらに、DreamBooth AI は、トピックの複数の角度からの写真を作成できます。
申し込み
アート演出
このタスクは、元のシーンに別のイメージのスタイルを組み込みながらソース シーンのセマンティクスを保持するスタイル転送とは特に異なります。

創造的なアプローチに基づいて、AI は、識別とトピック インスタンスの詳細を維持しながら、重要なシーンの変更を実現できます。
プロパティの変更
サブジェクト インスタンスの特性は、DreamBooth AI によって変更できます。

アクセサリー化
オブジェクトを装飾する DreamBooth AI の能力を非常に興味深いものにしているのは、生成モデルの前の強力な構成です。

再文脈化
DreamBooth AI は、トレーニング済みのモデルに一意の識別子とクラス名詞を含む文を与えることで、特定のサブジェクト インスタンスの特徴的な画像を生成できます。

周囲を変えるのではなく、これまでにないユニークなポーズ、アーティキュレーション、シーン構造で被写体を生成できます。 リアルな反射と影、および被写体と周囲のオブジェクト間の相互作用。
ドリームブースのチュートリアル
このチュートリアルでは、 Google コラボ ノート、私はそれを順を追って説明します。これにより、あなたはそれを理解し、自分で使用できるようになります.
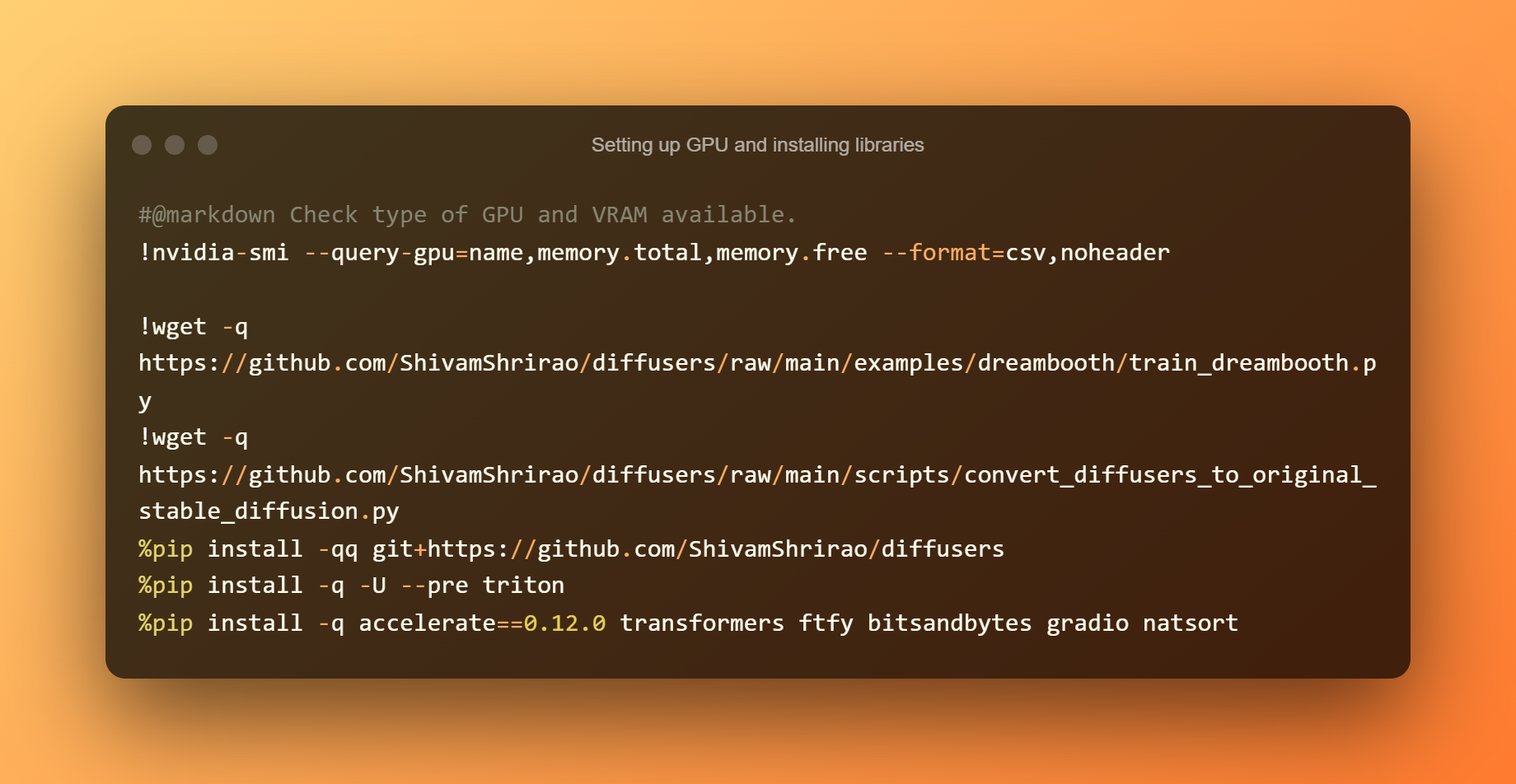
GPU のセットアップとライブラリのインストール
利用可能な GPU と VRAM の種類を調べることが最初のステップです。 いくつかの要件と依存関係をインストールすることも必要です。 再生ボタンを押すだけで、終了するのを待ちます。
Huggingface でアカウントを作成し、トークンを生成します
次のステップは、Huggingface アカウントの登録です。 完了したら、右上隅の [設定] をクリックします。 次のページにたどり着きます。
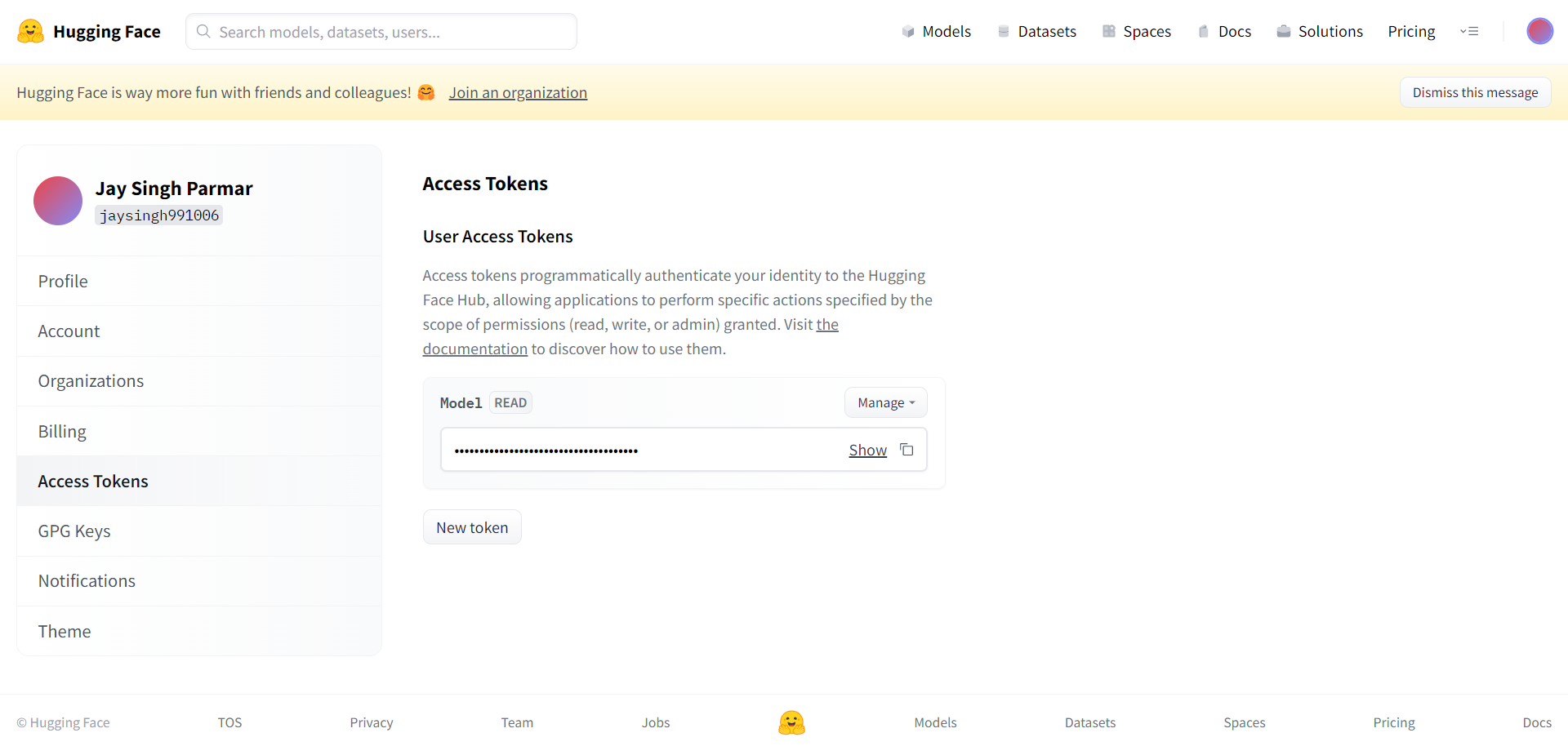
ここから要求されたトークンと名前を作成します。 トークンをコピーして、下のセルの Google コラボに貼り付ける必要があります。

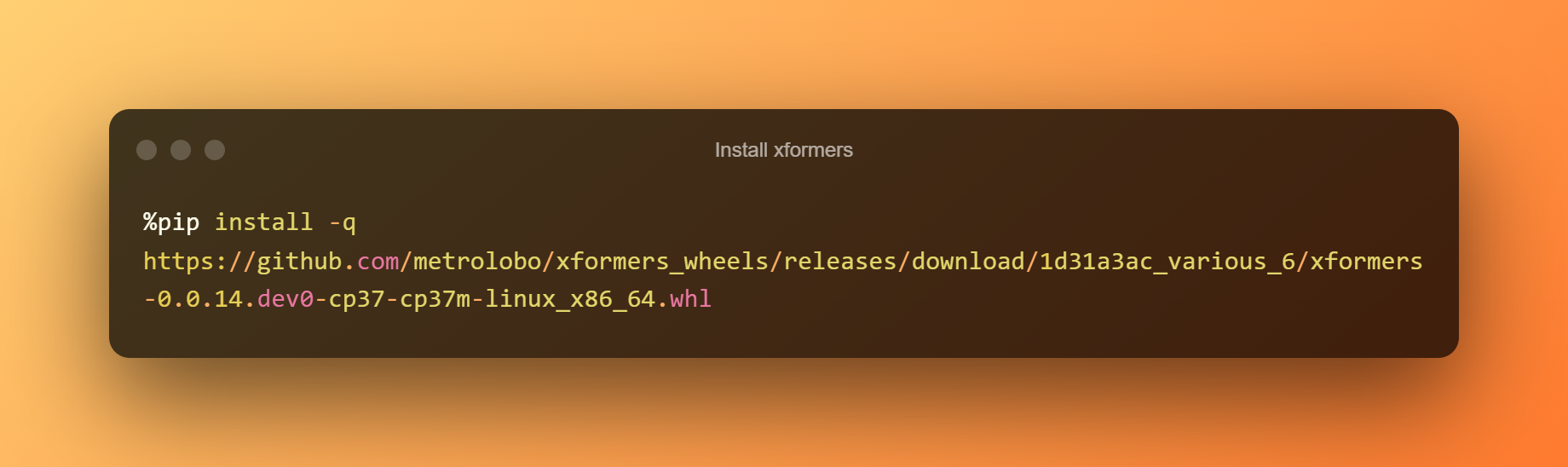
xformers をインストールする
この段階では、再生ボタンを押すだけで、ランタイムをクリックして xformers をインストールできます。
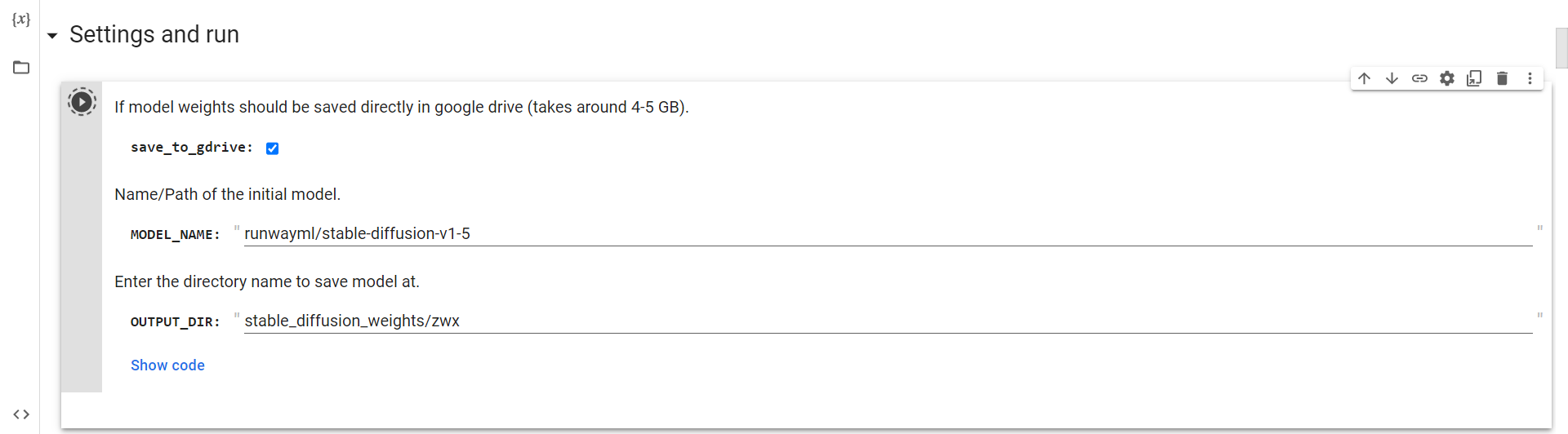
ドライブに接続
あとは、このセルを実行して Google ドライブに接続するだけです。
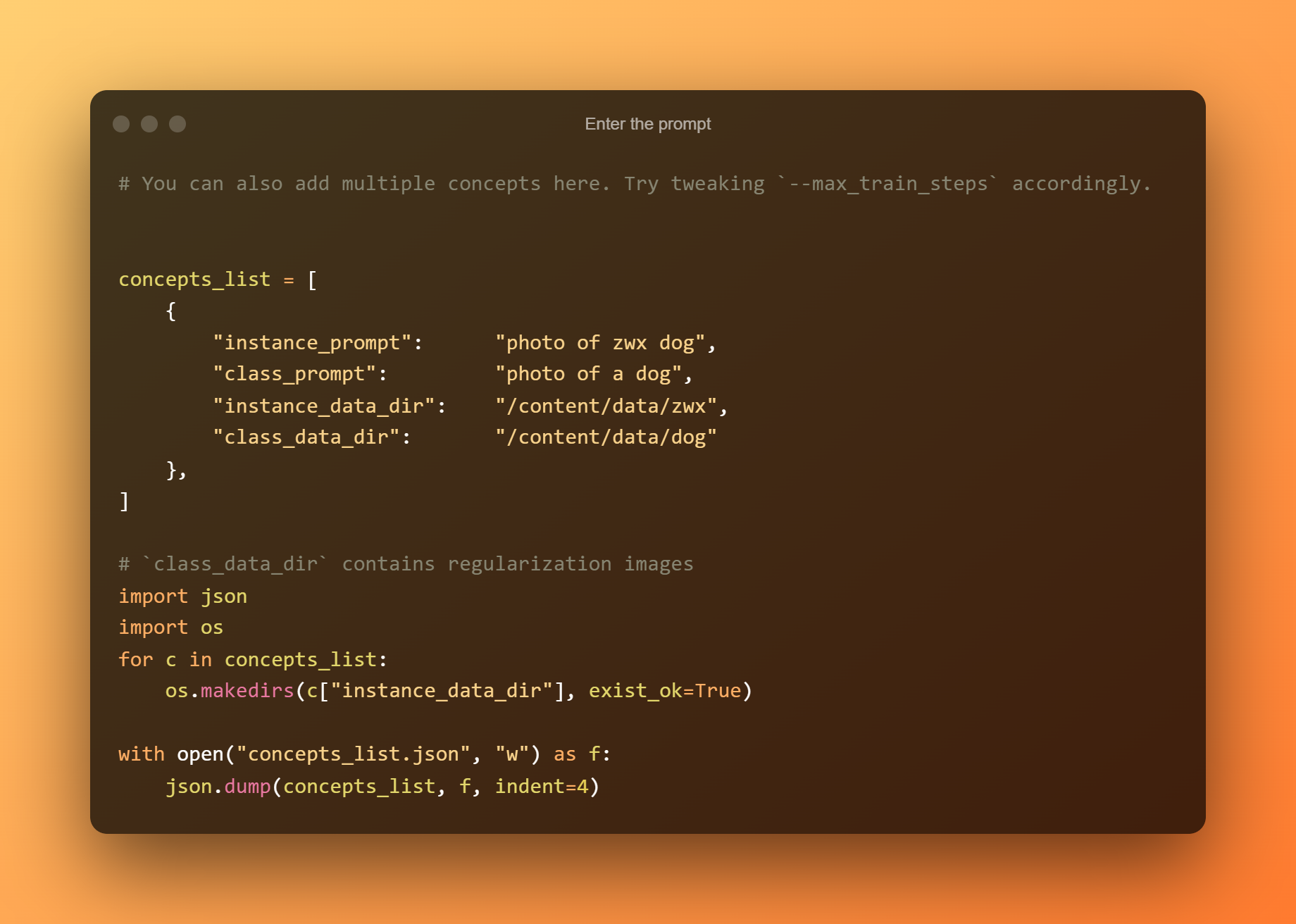
プロンプトを入力してください
次のセルでは、プロンプトを入力するだけです。
写真のアップロード
このステップでは、トレーニングしたい写真をアップロードするだけです。

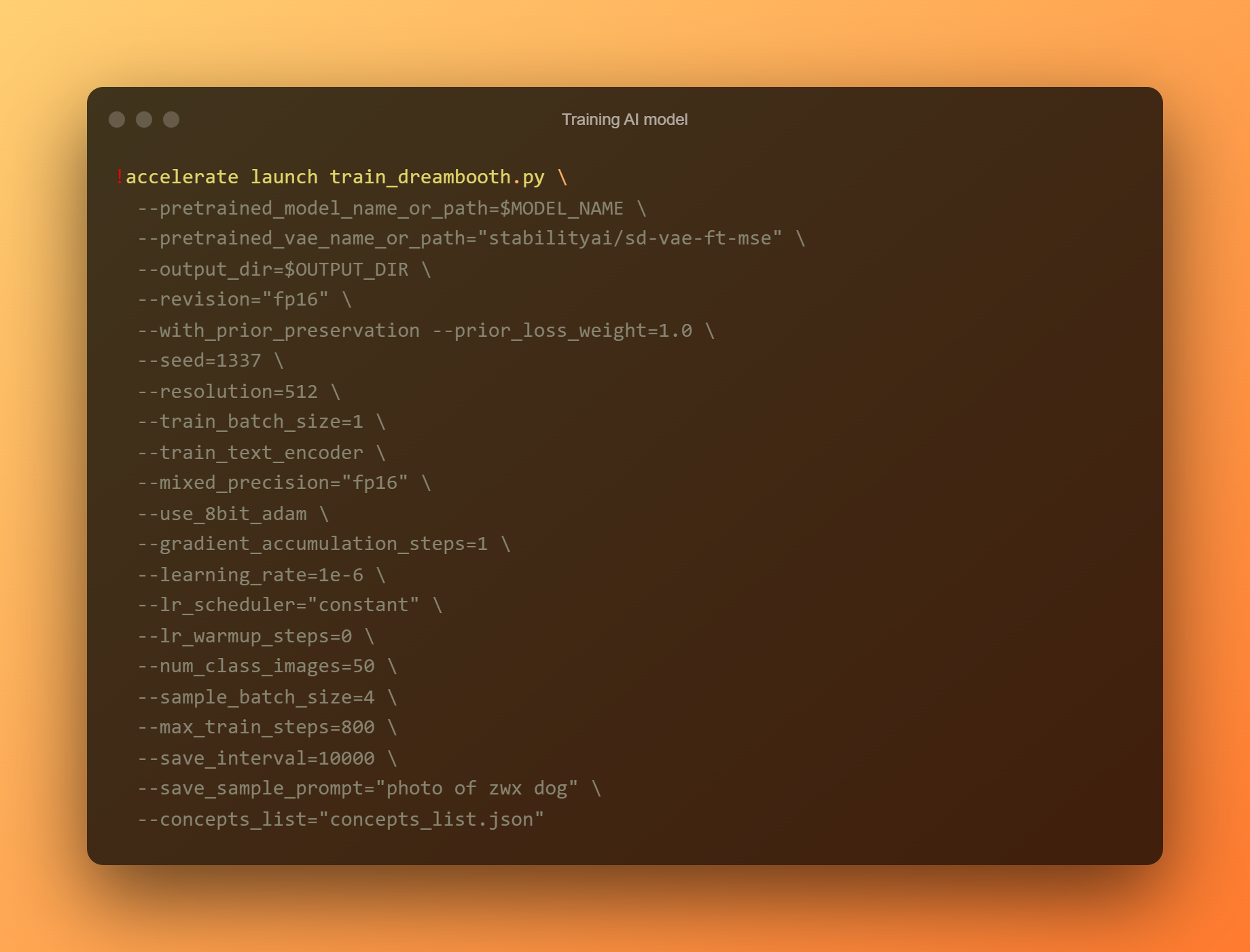
AI モデルのトレーニング
DreamBooth を利用して、提出されたすべての参照写真に基づいて新しい AI モデルをトレーニングするため、これは最も重要なフェーズです。 注意を XNUMX つの入力フィールドに限定する必要があります。 「—インスタンス プロンプト」は最初のパラメータです。 ここでは、明確に区別できる名前を指定する必要があります。
「–concept list」引数は、XNUMX 番目の重要な入力フィールドです。 「プロンプトの変更」セクションで使用したものと一致するように名前を変更する必要があります。
AI 画像の生成
この段階で AI 画像が作成され、テキストの指示を入力できます。

ドリームブースの制限事項
- コマンド プロンプトは、非常に詳細なトピックで反復を行う際の障壁になります。 DreamBooth は被写体のコンテキストを変更できますが、モデルが被写体自体を変更したい場合は、フレームに問題があります。
- もう XNUMX つの問題は、出力画像を入力画像に過剰適合させることです。 十分な写真が提供されていない場合、被写体は考慮されないか、提出された画像の文脈に溶け込む可能性があります。 奇数世代の文脈が問われると、同じことが起こる。
まとめ
単一のテキスト入力から出力を生成するには、大量のテキストから画像へのモデルで数百万のパラメーターとライブラリが必要です。
DreamBooth は、XNUMX ~ XNUMX 枚のトピックの写真とテキストの背景を入力するだけでよいため、消費者はコンテンツの取得と使用を簡素化できます。





コメントを残す