企業は、重要なビジネス上の意思決定を通知し、提供する製品を強化し、より良い顧客サービスを提供するためにデータへの依存がますます高まっており、これまで以上に多くのデータを取得しています。
指数関数的な速度で作成されるデータの量に応じて、クラウドは、スケーラビリティ、信頼性、可用性など、データ処理と分析にいくつかの利点をもたらします。
クラウド エコシステムには、データ処理と分析のためのツールとテクノロジーもいくつかあります。 最も頻繁に利用される XNUMX 種類のビッグ データ ストレージ構造は、データ ウェアハウスとデータ レイクです。
データ レイクを利用することは、モデルやデータが関連している間はクエリできないためあまり魅力的ではありませんが、ストリーミング データ ストレージにデータ ウェアハウスを採用するのは無駄です。

Wどのタイプのクラウド アーキテクチャを選択すればよいでしょうか?
データ レイクハウスの新しいコンセプトを検討すべきでしょうか、それともウェアハウスの制約やレイクの制約に満足すべきでしょうか?
「データ レイクハウス」と呼ばれる新しいデータ ストレージ アーキテクチャは、データ レイクの適応性とデータ ウェアハウスのデータ管理を組み合わせたものです。
ビジネス インテリジェンス (BI)、データ分析、およびデータ分析のための信頼できるデータ ストレージ パイプラインを構築するには、さまざまなビッグデータ ストレージ方法を理解することが不可欠です。 機械学習 (ML) ワークロード (企業の要求に応じて)。
この投稿では、データ ウェアハウス、データ レイク、データ レイクハウスについて、利点、制限、長所と短所を含めて詳しく見ていきます。 さぁ、始めよう。
データウェアハウスとは何ですか?
データ ウェアハウスは、組織がさまざまなソースからの膨大な量のデータを保持するために使用する集中化されたデータ リポジトリです。 データ ウェアハウスは、組織の「データの真実」の単一ソースとして機能し、レポート作成とビジネス分析に不可欠です。
通常、データ ウェアハウスは、アプリケーション、ビジネス、トランザクション データなどの複数のソースからのリレーショナル データ セットを組み合わせて、履歴データを保存します。 データは、ウェアハウス システムにロードされる前に、データ ウェアハウス内で変換およびクリーンアップされ、データの真実性を示す単一のソースとして使用できるようになります。
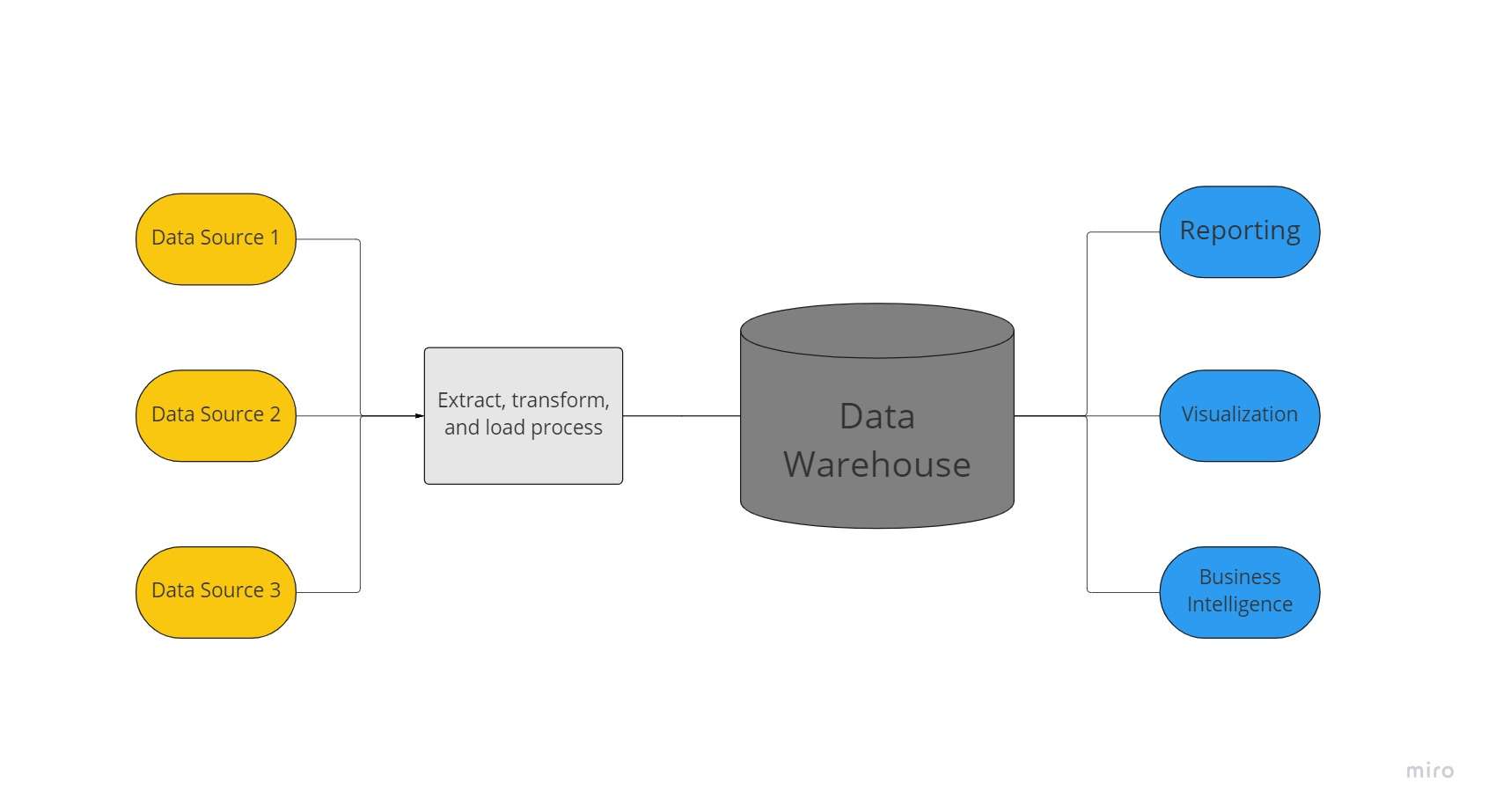
企業のあらゆる分野からビジネスに関する洞察を迅速に提供できる能力があるため、企業はデータ ウェアハウスに投資しています。 BI ツール、SQL クライアント、およびその他のあまり高度でない (つまり、データ サイエンスではない) 分析ソリューションを使用することで、 ビジネスアナリスト、データ エンジニア、および意思決定者は、データ ウェアハウスからデータにアクセスできます。
増え続けるデータ量を保管するウェアハウスの維持にはコストがかかり、データ ウェアハウスは生のデータや非構造化データを処理できません。 さらに、機械学習や予測モデリングなどの高度なデータ分析手法には理想的なオプションではありません。
したがって、データ ウェアハウスは、より高速なクエリ応答と高品質のデータを提供します。 Google Big Query、Amazon Redshift、Azure SQL データ ウェアハウス、および Snowflake は、データ ウェアハウスで利用できるクラウド サービスです。
データ ウェアハウスの利点
- ビジネス インテリジェンスとデータ分析ワークロードの効率と速度を向上: データ ウェアハウスは、データの準備と分析に必要な時間を短縮します。 データ ウェアハウスからのデータは信頼性があり一貫性があるため、データ分析ツールやビジネス インテリジェンス ツールに簡単にリンクできます。 さらに、データ ウェアハウスはデータ収集に必要な時間を節約し、チームがレポート、ダッシュボード、その他の分析要件にデータを使用できるようにします。
- データの一貫性、品質、標準化の向上: 組織は、ユーザー、販売、トランザクション データなど、さまざまなソースからデータを収集します。 データ ウェアハウジングは企業データを統一された標準化された形式にコンパイルし、データの真実性を示す単一の情報源として機能するため、企業はビジネス要件に対してデータを信頼できます。
- 一般的な意思決定の強化: データ ウェアハウジングは、最新データと古いデータの両方を一元的に保存できるため、より適切な意思決定を促進します。 データ ウェアハウス内のデータを処理して正確な洞察を得ることで、意思決定者はリスクを評価し、顧客の要望を理解し、商品やサービスを向上させることができます。
- より優れたビジネス インテリジェンスの提供:データ ウェアハウジングは、当然のこととして日常的に頻繁に収集される大量の生データと、洞察を提供する厳選されたデータの間のギャップを埋めます。 これらは組織のデータ ストレージの基盤として機能し、組織がデータに関する複雑な質問に答え、その回答を利用して防御可能なビジネス上の意思決定を行うことができるようにします。
データ ウェアハウスの制限
- データの柔軟性の欠如: データ ウェアハウスは構造化データの処理に優れていますが、ログ分析、ストリーミング、ソーシャル メディア データなどの半構造化および非構造化データ形式は、データ ウェアハウスにとって困難な場合があります。 これにより、機械学習と 人工知能 難しい
- 設置と維持に費用がかかる: データ ウェアハウスのインストールと維持には費用がかかる場合があります。 さらに、データ ウェアハウスは静的でないことがよくあります。 古くなり、頻繁なメンテナンスが必要になり、費用がかかります。
メリット
- データの検索、取得、クエリは簡単です。
- データがすでにクリーンであれば、SQL データの準備は簡単です。
デメリット
- XNUMX つの分析ベンダーのみを使用する必要があります。
- 非構造化データまたは流動データの分析と保存には、かなりのコストがかかります。
データレイクとは何ですか?
あらゆる種類のデータが約束されており、データ レイクによって可能になります。 アクセスしやすい方法でデータを中央に配置し、読み取り可能にすることは有益です。
データ レイクは、集中化された非常に適応性の高いストレージ スペースであり、大量の組織化された非構造化データが、処理、変更、フォーマットされていない形式で保存されます。
データ レイクはフラット アーキテクチャを採用し、データを保存するためにオブジェクトを未処理の状態で保存します。これは、以前に「クリーンアップ」されたリレーショナル データを保存するデータ ウェアハウスとは対照的です。
この形式のデータの処理が難しいデータ ウェアハウスとは対照的に、データ レイクは適応性があり、信頼性が高く、手頃な価格であり、企業は非構造化データから高度な洞察を得ることができます。
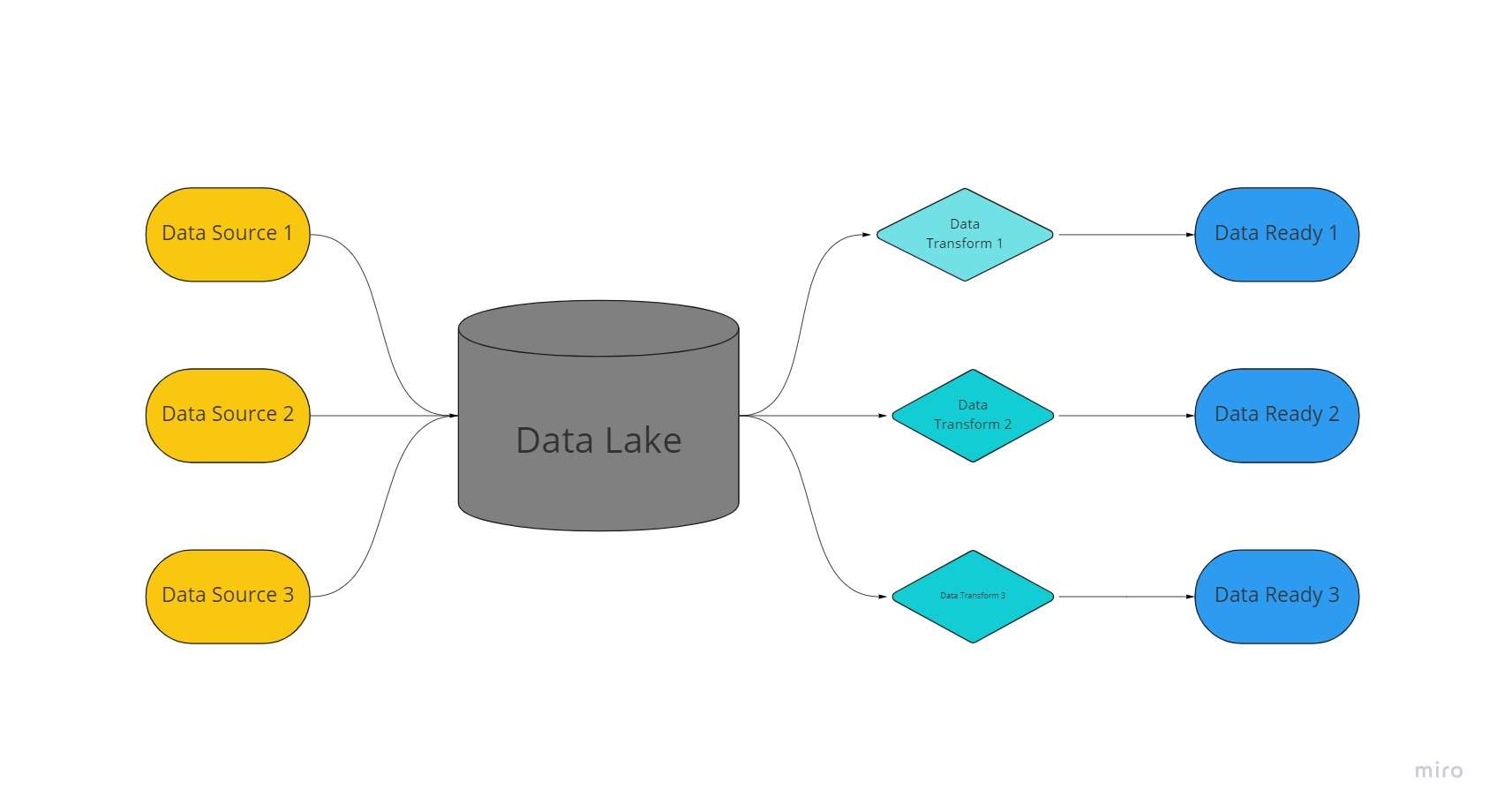
データ レイクでは、データ収集時にスキーマやデータを確立するのではなく、分析目的でデータが抽出、ロード、変換 (ELT) されます。
IoTデバイスから得られる様々なデータの技術を活用し、 ソーシャルメディア、ストリーミング データ、データ レイクにより、機械学習と予測分析が可能になります。
さらに、生データを処理できるデータ サイエンティストはデータ レイクを使用できます。 一方、データ ウェアハウスは企業にとって使いやすいものです。 ユーザープロファイリングに最適です。 予測分析、機械学習、その他のタスク。
データ レイクはデータ ウェアハウスに関するいくつかの問題に対処していますが、データの品質は低く、クエリ速度も不十分です。 さらに、ビジネス ユーザーが SQL クエリを実行するには追加のツールが必要です。 データレイクの構造が不十分だと、データの停滞という問題が発生する可能性があります。
データレイクの利点
- 幅広い機械学習およびデータ サイエンスのアプリケーション ケースのサポート データはオープンな生の形式で保持されるため、データ レイク内のデータを処理するために別のマシンおよびディープ ラーニング アルゴリズムを使用する方が簡単です。
- 事前に設定されたスキーマを必要とせずに、あらゆる形式やメディアでデータを保存できるデータ レイクの汎用性は、大きな利点です。 将来のデータのユースケースもサポートでき、データが元の状態のままであれば、より多くのデータを分析できます。
- さまざまなコンテキストで両方のタイプのデータを保存する必要を避けるために、データ レイクには構造化データと非構造化データの両方を含めることができます。 さまざまな種類の組織データを XNUMX か所で保管できます。
- 従来のデータ ウェアハウスと比較して、データ レイクは、オブジェクト ストレージなどの安価な汎用ハードウェア上に保存されるように構築されているため、コストが低くなります。オブジェクト ストレージは、多くの場合、保存される XNUMX ギガバイトあたりのコストが低くなるように設計されています。
データレイクの制限
- データ分析とビジネス インテリジェンスのユース ケースのスコアが低い: データ レイクは、適切に維持されていないと組織化されない可能性があり、ビジネス インテリジェンスと分析ツールにリンクすることが難しくなります。 さらに、レポートと分析のユースケースで必要な場合、一貫性の欠如 データ構造 ACID (原子性、一貫性、分離、および持続性) トランザクション サポートは、最適でないクエリ パフォーマンスにつながる可能性があります。
- データ レイクの不整合により、データの信頼性とセキュリティを強制することができなくなり、その結果、両方が欠如してしまいます。 データレイクはあらゆるデータ形式を処理できるため、機密データの種類に対応する適切なデータセキュリティとガバナンスの標準を開発するのは難しい場合があります。
メリット
- あらゆる種類のデータに手頃な価格のソリューション。
- 組織化されたデータと半構造化されたデータの両方を処理できます。
- 複雑なデータ処理やストリーミングに最適です。
デメリット
- 高度なパイプラインを構築する必要があります。
- データがクエリ可能になるまでしばらく時間を置きます。
- データの信頼性と品質を保証するには時間がかかります。
データレイクハウスとは何ですか?
「データ レイクハウス」と呼ばれる新しいビッグデータ ストレージ アーキテクチャは、データ レイクとデータ ウェアハウスの最も優れた側面を組み合わせたものです。 データ レイクハウスのおかげで、構造化、半構造化、非構造化のいずれであっても、すべてのデータを XNUMX か所に保存でき、最高級の機械学習、ビジネス インテリジェンス、ストリーミング機能を利用できます。
多くの場合、あらゆる種類のデータ レイクがデータ レイクハウスの出発点となります。 その後、データは Delta Lake 形式 (データ レイクに信頼性をもたらすオープンソースのストレージ レイヤー) に変換されます。
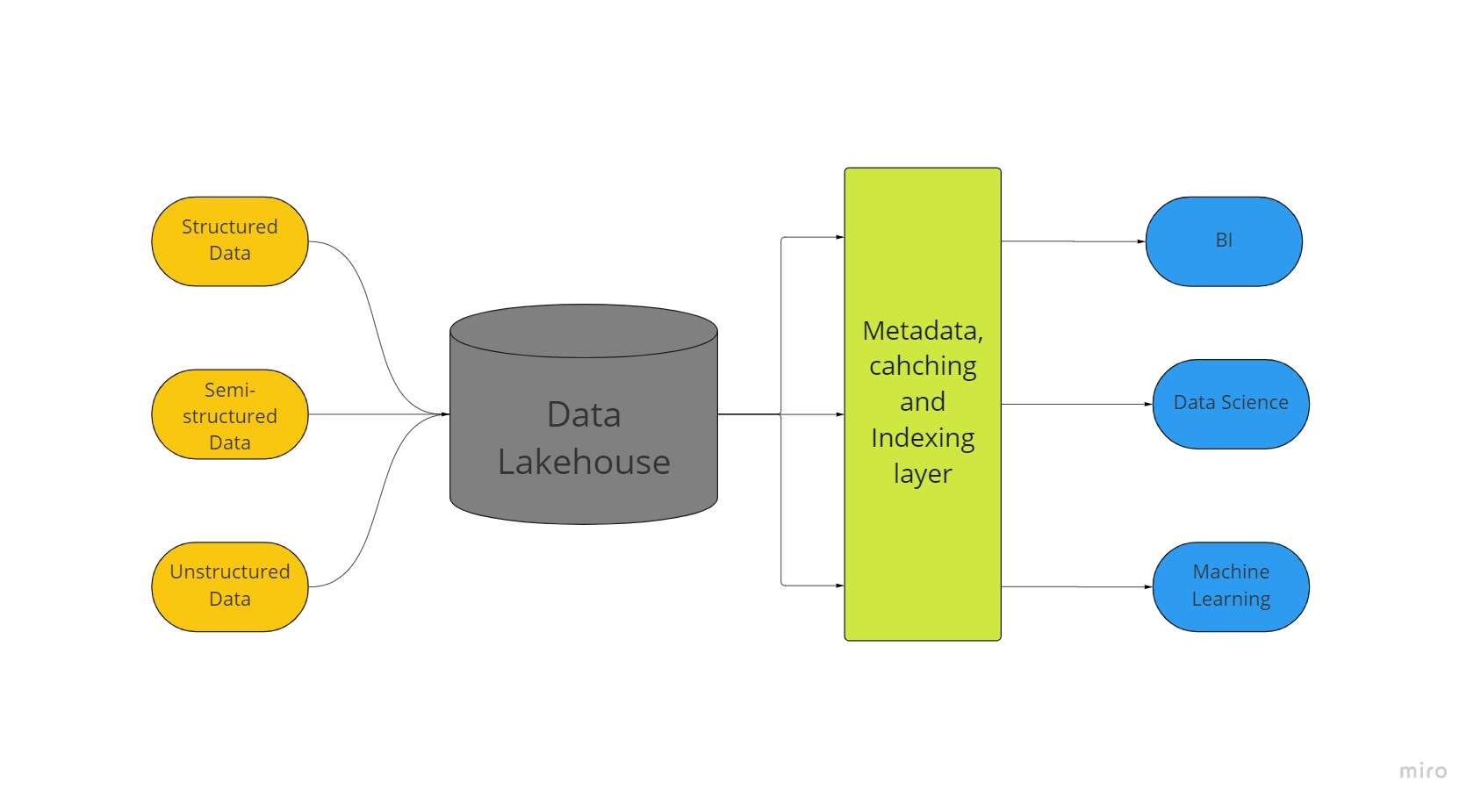
デルタ レイクを備えたデータ レイクにより、従来のデータ ウェアハウスからの ACID トランザクション手順が可能になります。 本質的に、レイクハウス システムは、データ レイクと同様に、安価なストレージを使用して大量のデータを元の形式で維持します。
ストアの最上位にメタデータ レイヤーを追加すると、データ構造も提供され、データ ウェアハウスにあるようなデータ管理ツールが強化されます。
これにより、多くのチームが単一のシステムを介して企業データのすべてにアクセスし、データ サイエンス、機械学習、ビジネス インテリジェンスなどのさまざまな取り組みを行うことが可能になります。
データ レイクハウスのメリット
- 幅広いワークロードのサポート: 高度な分析を容易にするために、データ レイクハウスではユーザーが最も人気のあるビジネス インテリジェンス ツール (Tableau、PowerBI) に直接アクセスできるようになります。 さらに、データ レイクハウスではオープンデータ形式 (Parquet など) と API および Python/R などの機械学習フレームワークが採用されているため、データ サイエンティストや機械学習エンジニアはデータを簡単に使用できます。
- 費用対効果: データ レイクハウスは、データ レイクの費用対効果の高いストレージ特性を実装するために、安価なオブジェクト ストレージ ソリューションを採用しています。 データ レイクハウスは、単一のソリューションを提供することで、さまざまなデータ ストレージ システムの管理にかかる費用と時間を削減します。
- データ レイクハウスの設計により、スキーマとデータの整合性が確保され、効果的なデータ セキュリティとガバナンス システムの構築が容易になります。 使いやすさ データのバージョン管理、ガバナンス、セキュリティ。
- データ レイクハウスは、企業のあらゆるデータ需要に対応できる単一の多目的データ ストレージ プラットフォームを提供し、データの重複を削減します。 大多数の企業は、データ ウェアハウスとデータ レイクの両方の利点により、ハイブリッド ソリューションを選択します。 一方、この戦略では、データの重複にコストがかかる可能性があります。
- オープンフォーマットのサポート。 オープン形式は、多くのソフトウェア アプリケーションで使用でき、仕様が公開されているファイル タイプです。 レポートによると、Lakehouse は、Apache Parquet や ORC (Optimized Row Columnar) などの一般的なファイル形式でデータを保存できます。
データ レイクハウスの制限
データ レイクハウスの最大の欠点は、それがまだ新しく発展途上のテクノロジーであることです。 その結果として約束を果たせるかどうかは不透明だ。 データ レイクハウスが確立されたビッグデータ ストレージ システムと競合できるようになるまでには、何年もかかる可能性があります。
ただし、最新のイノベーションが起こっている速度を考えると、最終的に別のデータ ストレージ システムがそれに置き換わらないかどうかを言うのは困難です。
メリット
- XNUMX つのプラットフォームにすべてのデータが含まれるため、維持するホスト名が少なくなります。
- 原子性、一貫性、分離性、および靭性は影響を受けません。
- 大幅にお求めやすくなりました。
- XNUMX つのプラットフォームにすべてのデータが含まれるため、維持するホスト名が少なくなります。
- 管理が簡単で、問題があればすぐに解決できる
- パイプラインの構築を簡素化する
デメリット
- セットアップには時間がかかる場合があります。
- 確立されたストレージ システムとして認定するには、あまりにも若く、あまりにも遠いです。
データウェアハウスとデータレイクとデータレイクハウス
データ ウェアハウスには、企業インテリジェンス、レポート、分析アプリケーションにおいて長い歴史があり、最初のビッグデータ ストレージ テクノロジです。
一方、データ ウェアハウスは高価であり、ストリーミング データなどの多様な非構造化データの処理に問題があります。 機械学習とデータ サイエンスのワークロード向けに、手頃な価格のストレージでさまざまな形式の生データを管理するためにデータ レイクが開発されました。
データ レイクは非構造化データには効果的ですが、データ ウェアハウスの ACID トランザクション機能が欠けているため、データの一貫性と信頼性を保証することが困難になります。
「データ レイクハウス」として知られる最新のデータ ストレージ アーキテクチャは、データ ウェアハウスの信頼性と一貫性と、データ レイクの手頃な価格と適応性を組み合わせています。
まとめ
結論として、データ レイクハウスをゼロから構築するのは難しいかもしれません。 さらに、ほぼ確実に、オープン データ レイクハウス アーキテクチャを可能にするように設計されたプラットフォームを使用することになります。
したがって、購入する前に、各プラットフォームの多くの機能と実装を慎重に調査してください。 ビジネス インテリジェンスとデータ分析のユースケースに重点を置いた成熟した構造化データ ソリューションを探している企業は、データ ウェアハウスを検討できます。
ただし、非構造化データでのデータ サイエンスや機械学習のワークロードを強化する、スケーラブルで手頃なビッグ データ ソリューションを探している企業は、データ レイクを検討する必要があります。
データ ウェアハウスやデータ レイク テクノロジが提供できるよりも多くのデータがビジネスで必要とされていること、またはデータに対する高度な分析と機械学習操作を統合するソリューションを探していることを考慮してください。 あ データレイクハウス 状況では賢明なオプションです。





コメントを残す