Il web scraping è diventato un metodo cruciale per ottenere dati approfonditi dalle piattaforme Internet nella società odierna basata sui dati.
Essendo un sito di social media estremamente popolare, Instagram fornisce molto materiale generato dagli utenti. E questi dati generati possono essere utilizzati per marketing, ricerca e altri motivi.
Gli utenti possono estrarre i dati da Instagram con facilità ed efficacia grazie agli scraper Instagram ricchi di funzionalità di Bright Data, leader raschiatura del web attrezzo. In questo post, forniremo una panoramica completa e dettagliata del processo di scraping di Instagram.
Quindi, vediamo i passaggi su come possiamo raccogliere dati da Instagram.
Comprensione degli scraper di Instagram da Bright Data
Con l'aiuto di due web scraper multiuso e un set di dati precompilato, Bright Data offre una varietà di servizi di scraping di Instagram. Queste tecnologie offrono versatilità nell'estrazione dei dati e si adattano alle diverse esigenze.
Esaminiamo ciascuna di queste scelte in modo più dettagliato:
a. Browser raschiante
L'innovativa tecnologia nota come Scraping Browser è stata creata per soddisfare le esigenze dei progetti di scraping dei dati. Offre tutto il necessario per lo scraping su larga scala all'interno di un singolo browser. Si distingue grazie alla sua automazione integrata per lo sblocco del sito Web, che lo rende l'unico browser del suo genere in tutto il mondo.
Scraping Browser offre agli utenti l'accesso a funzionalità robuste che vanno oltre i browser automatizzati e senza testa, consentendo loro di superare anche gli script più difficili e le barriere dei siti Web per il rilevamento dei bot.
Lo scraping dei dati è più efficace e senza problemi grazie alle sue funzionalità di regolazione automatizzata, che gestiscono facilmente nuovi blocchi, soluzioni CAPTCHA, impronte digitali e tentativi e appare come un vero utente.
Usare l'intelligenza artificiale per superare in astuzia i sistemi di rilevamento dei bot
Utilizzando una tecnologia AI all'avanguardia, Scraping Browser può superare in astuzia i sistemi di rilevamento dei bot e adattarsi continuamente alle loro mutevoli strategie. Per sbloccare meglio le pagine Web, Scraping Browser apprende dai tentativi di questi sistemi di rilevare e bloccare i tentativi di scraping e modifica il suo comportamento in modo appropriato.
Supera l'efficienza dei proxy convenzionali imitando il comportamento di un browser utilizzato da un utente reale. Di conseguenza, i clienti possono concentrarsi sui loro obiettivi per lo scraping dei dati senza dover affrontare la difficoltà e la spesa delle procedure di rilevamento dei bot in corso.
b. IDE raschietto web
Un robusto strumento di web scraping creato per gli sviluppatori, Web Scraper IDE è in grado di gestire complesse attività di scraping. Riduce notevolmente i tempi di sviluppo fornendo allo stesso tempo una scalabilità infinita grazie alla sua soluzione completamente ospitata e alle funzionalità di scraping predefinite. L'applicazione consente la creazione rapida e scalabile di scraper online fornendo modelli di codice e funzioni JavaScript già pronte da siti Web popolari.
Tutto ciò che è necessario per il successo del web scraping è fornito dall'IDE Web Scraper. È una soluzione completa per l'estrazione di dati online poiché le opzioni di integrazione consentono ai clienti di pianificare le scansioni o avviarle tramite API e collegarle ai principali sistemi di archiviazione.
Come usarlo? – Tutorial
Innanzitutto, vai alla dashboard utente sul sito web.

Iniziamo con i nostri passaggi per raschiare Instagram.
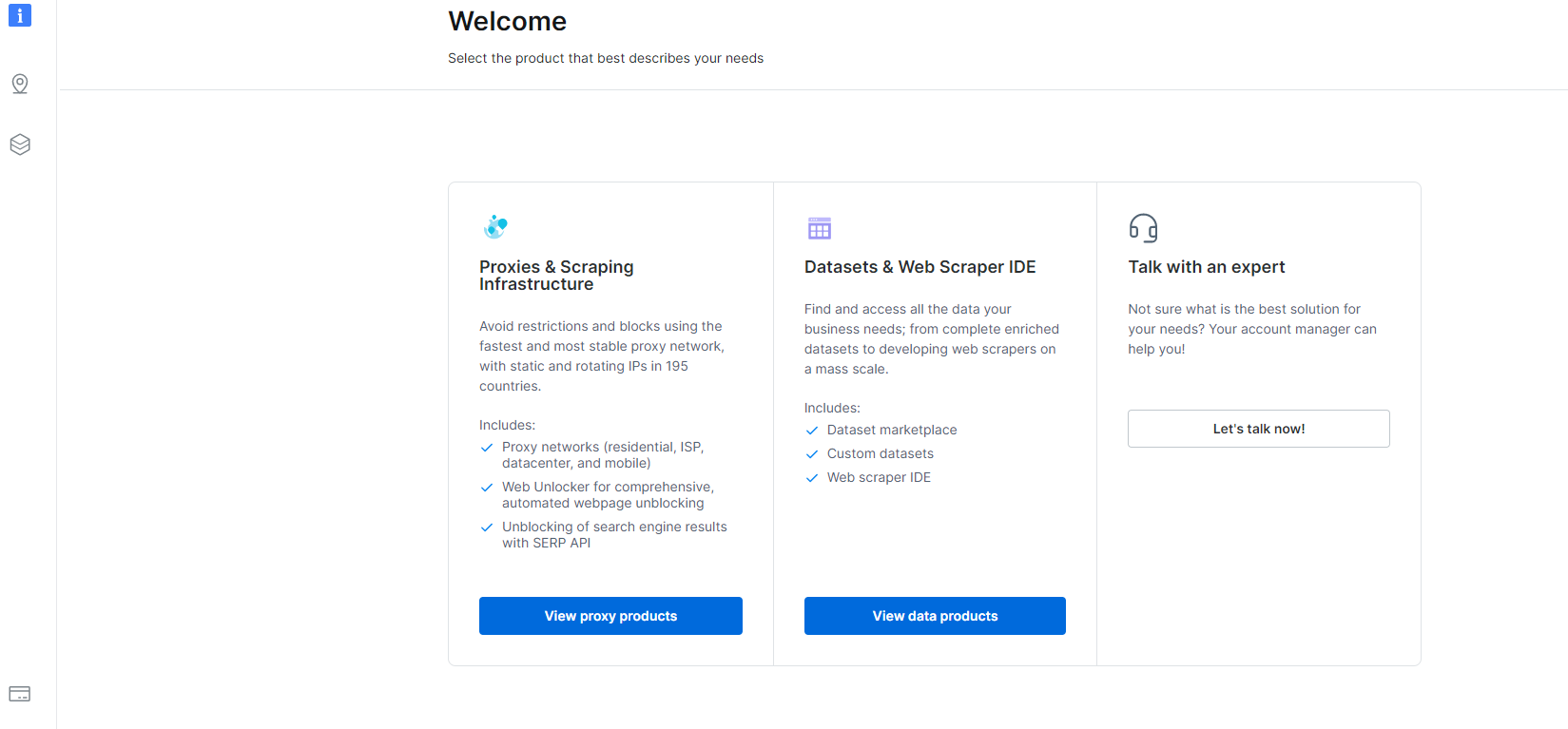
1- Vai al Performance modelli/hostess e fare clic sulla sezione Datasets & Web Scraper IDE.
2- Una volta che sei lì, fai clic su My Scrapers.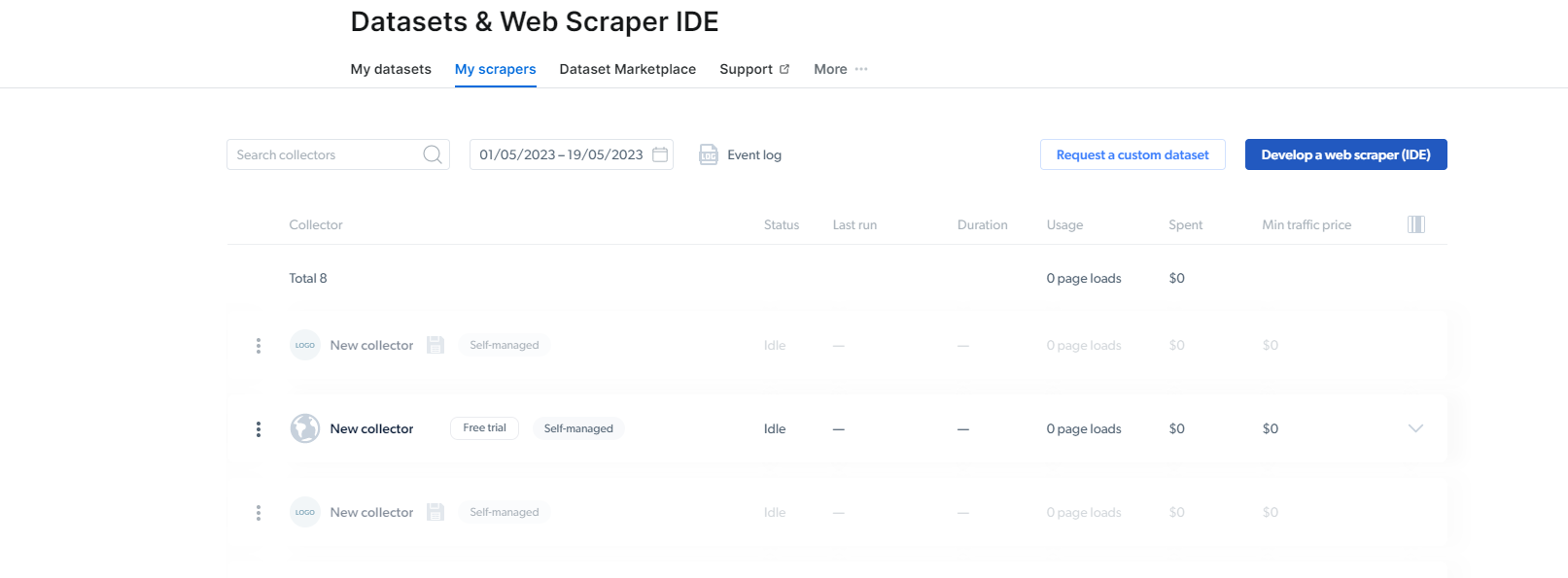
Qui, devi fare clic su "Sviluppa un web scraper (IDE)". Qui creeremo il nostro scraper per Instagram.
3-Ora, dobbiamo sviluppare un nuovo web scraper. Solo per questo esempio, scelgo di raschiare l'account "NASA". Questo è solo per il bene di questo esempio.
Quindi, il mio codice sarà simile a questo:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Devi fare clic sul pulsante "Riproduci" in alto a destra per eseguire questo codice.
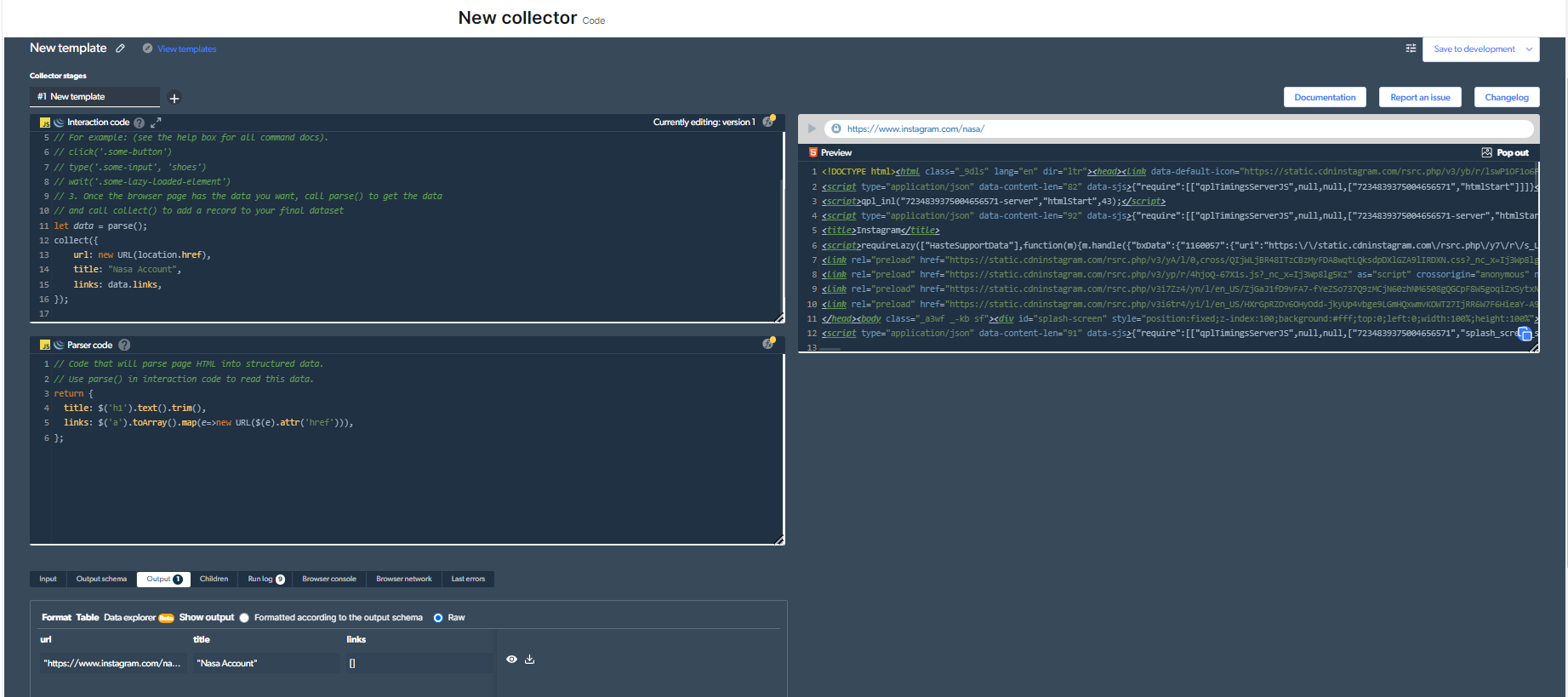
4- Ora avremo un output.
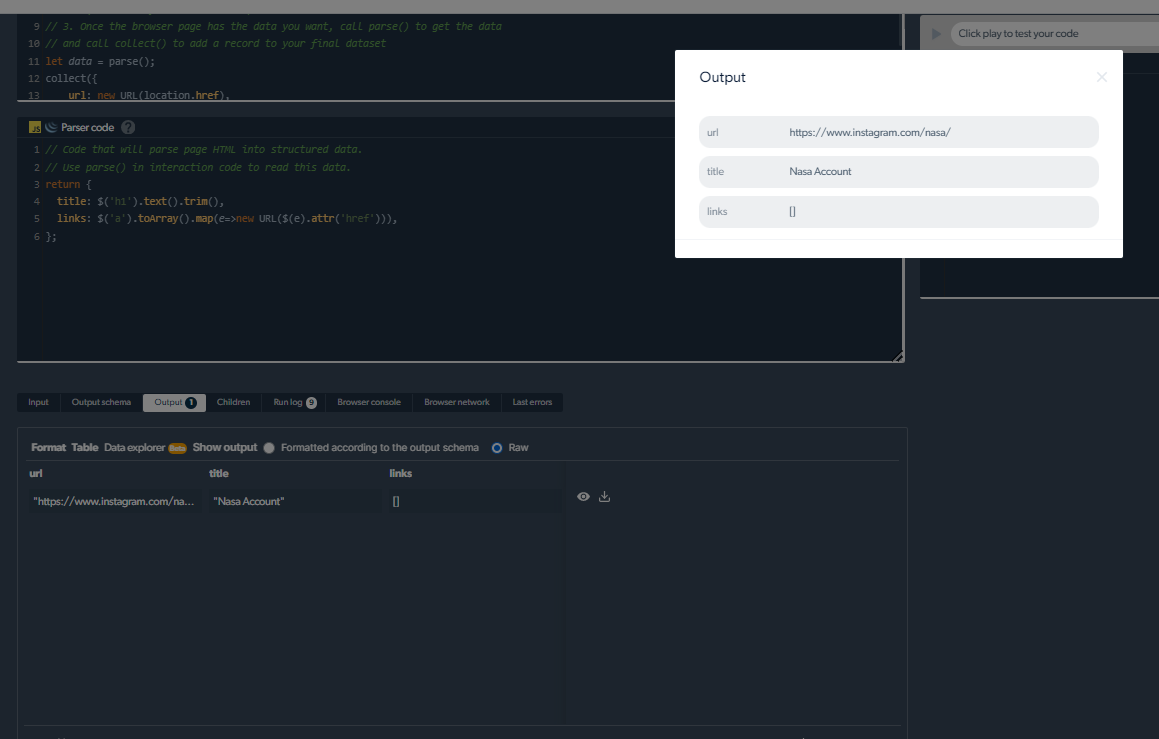
Gestione dei problemi di raschiatura
I post di Instagram con il pulsante "mostra altro" potrebbero essere difficili da acquisire per gli scraper. Tuttavia, gli scraper Instagram di Bright Data sono fatti per gestire con successo tale complessità. Questi scraper hanno abilità all'avanguardia per attraversare l'impaginazione e il caricamento di pulsanti aggiuntivi.
Gli scraper Instagram di Bright Data gestiscono efficacemente queste difficoltà per consentire un'estrazione completa dei dati, consentendoti di raccogliere l'intera raccolta di informazioni necessarie per la tua analisi o studio.
Puoi aggirare le sfide presentate dalla natura dinamica dei post di Instagram utilizzando questi strumenti di scraping.
c. Set di dati pre-raccolti
Bright Data comprende che non tutti vogliono eseguire il proprio scraper. Forniscono un set di dati pre-raccolti per Instagram per attrarre tali consumatori.
Questo set di dati offre una vasta gamma di informazioni utili, come follower, profili, post e altro ancora.
Bright Data offre opzioni di personalizzazione per personalizzare il set di dati in base alle tue esigenze, sia che tu voglia un intero set di dati o un sottoinsieme di dati specializzati. Questo approccio evita di costruire e gestire uno scraper, fornendo dati pronti all'uso per analisi e approfondimenti.
Ora, controlliamo l'infrastruttura che rende questi strumenti così efficaci: l'infrastruttura proxy e Web Unlocker.
Scatena il potere dei proxy
utilizzando proxy è fondamentale durante il web scraping per garantire che le tue azioni passino inosservate.
Bright Data offre un'ampia selezione di servizi proxy personalizzati in base alle tue esigenze. Puoi scegliere tra Proxy residenziali, che offrono oltre 72 milioni di IP ruotati da dispositivi peer reali in 195 nazioni.
Puoi scegliere i proxy ISP, che offrono oltre 700,000 IP domestici reali in tutto il mondo per un utilizzo a lungo termine; Datacenter Proxy, che hanno oltre 770,000 IP condivisi da qualsiasi geolocalizzazione; e Mobile Proxy, che costituiscono la più grande rete mobile 3G/4G real-peer con oltre 7,000,000 di IP.
Con l'uso di questi proxy, è possibile raccogliere facilmente dati fingendosi utenti autorizzati in numerosi luoghi.

Gestore proxy: semplifica la gestione dei proxy
La gestione di più proxy potrebbe essere difficile, ma Proxy Manager lo rende facile.
Questa interfaccia open source ti consente di gestire tutti i tuoi proxy da un'unica piattaforma. Dì addio all'impostazione e alla commutazione manuale dei proxy. Proxy Manager semplifica la procedura e ti fa risparmiare tempo e fatica.
Estensione del browser proxy: cambia facilmente la tua posizione
Hai bisogno di raccogliere dati web da diverse regioni? Sei coperto dalla nostra estensione del browser proxy. È possibile modificare la posizione di navigazione con un solo clic per ottenere informazioni specifiche sulla regione.
Sfrutta la flessibilità e la semplicità di raccogliere dati da diverse regioni senza alcuna complicazione tecnologica.
Come funziona? – Tutorial
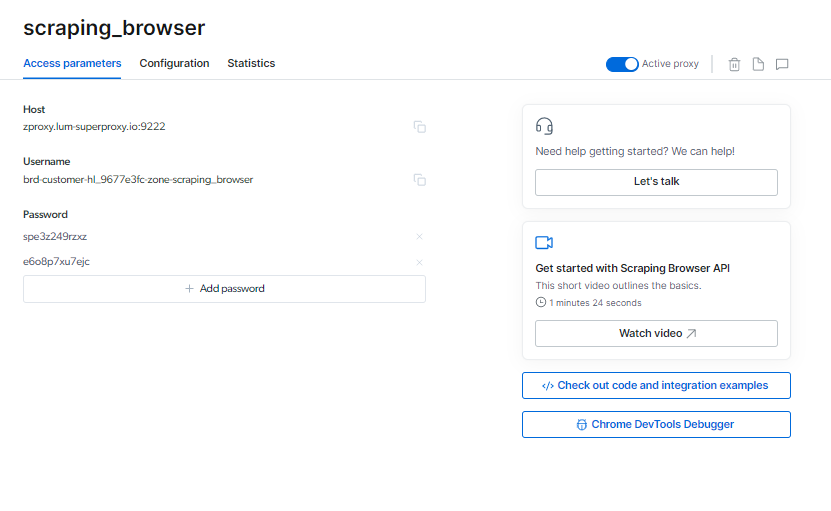
Puoi localizzare il tuo Browser raschiante informazioni di accesso nella pagina Parametri di accesso, che verranno utilizzate quando si avvia una nuova sessione del browser.
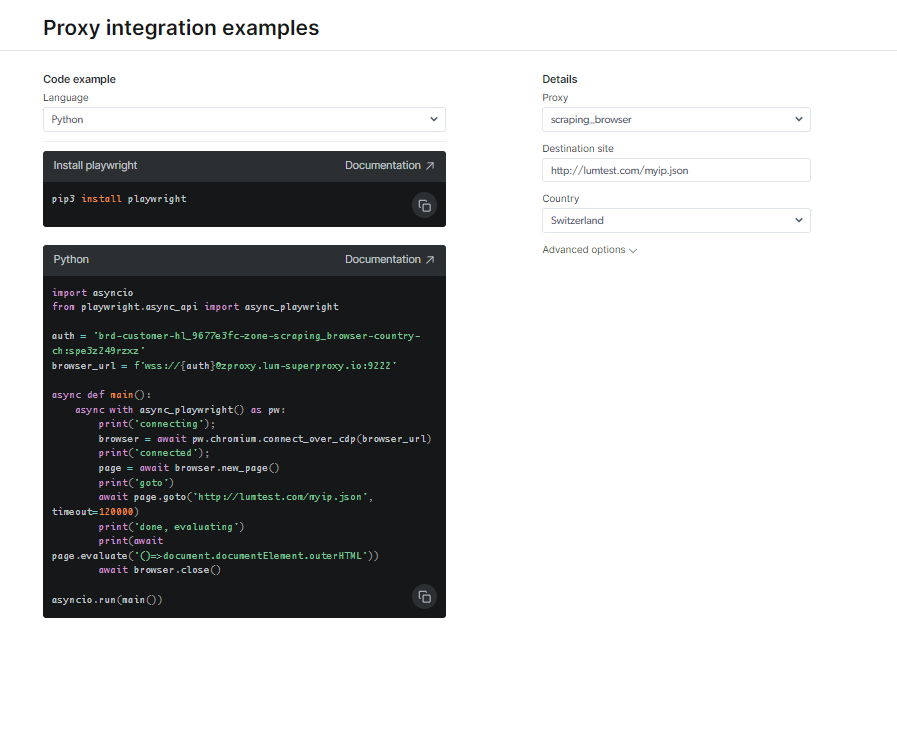
Consulta la documentazione e gli esempi di codice, incluso uno script di esempio completamente funzionale pronto per l'uso, oppure guarda un breve video di istruzioni iniziali. Per esempio; Ecco un Codice Python esempio per l'integrazione:
Vuoi assistenza? Per una conversazione con uno degli specialisti, puoi fare clic sull'icona della chat.
Tieni presente che hai il controllo completo sulle sessioni del browser durante l'utilizzo di Scraping Browser e puoi eseguire qualsiasi operazione supportata da Puppeteer, Playwright o dall'uso diretto del protocollo Chrome DevTools.
Sblocco del sito web senza blocchi
Scraping Browser è progettato per funzionare su larga scala e secondo necessità. Non devi preoccuparti di essere bannato; puoi avviare tutte le sessioni del browser di cui hai bisogno.
Questa capacità, se abbinata alla forza dei proxy, garantisce la raccolta continua dei dati, consentendoti di ottenere in modo efficace i dati desiderati.
Le capacità di sblocco integrate di Scraping Browser e la solida rete proxy ti aiutano a risparmiare tempo, migliorare la produttività e scoprire nuove opportunità.
Puoi anche controllare direttamente le statistiche dalla stessa pagina.
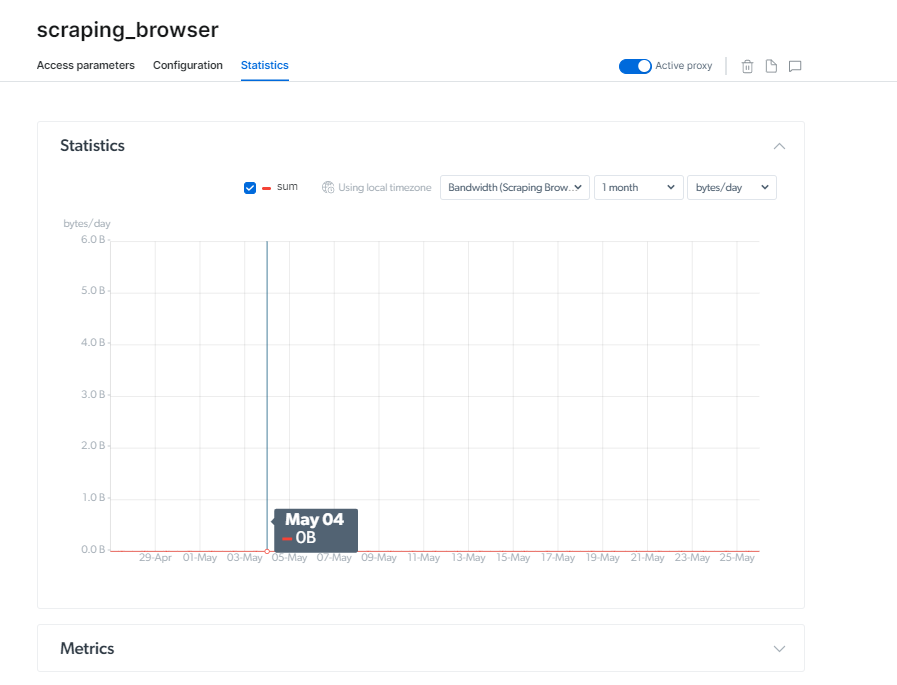
Prezzi di Scraping Browser
Bright Data offre opzioni di prezzo personalizzabili per soddisfare una varietà di scopi. Puoi scegliere un periodo di fatturazione mensile o annuale.
L'opzione Pay as You Go ti consente di pagare solo per ciò che utilizzi, senza impegno, a partire da $ 20.00/GB e $ 0.1/ora.
Il piano di crescita da $ 500 è adatto alle aziende in crescita, con una tariffa scontata di $ 15.30/GB e $ 0.1/ora.
I Pacchetto aziendale, che costa $ 1000, è l'opzione più popolare, con l'API Scraping Browser che costa $ 13.50/GB e $ 0.1/ora.
Contattando direttamente il team di Bright Data, gli utenti aziendali possono usufruire di scalabilità infinita e prezzi personalizzati. Inizia oggi una prova gratuita per scoprire il potenziale di Scraping Browser di Bright Data e modificare i tuoi sforzi di scraping online.
Sblocco del sito web
Web Unlocker è un potente strumento creato per andare oltre le restrizioni del sito Web e fornire una facile raccolta dei dati. Supera diverse sfide, inclusi cookie, agenti utente del browser specifici del sito e soluzioni captcha, utilizzando procedure automatizzate.
Utilizzando la rotazione automatica degli indirizzi IP, gli utenti di Web Unlocker possono continuamente eseguire lo scraping dei siti Web di destinazione, garantendo un accesso costante a dati importanti.
Miglioramento dei percorsi delle richieste degli sviluppatori
Diverse funzionalità rendono Web Unlocker popolare tra gli sviluppatori. Il programma semplifica il processo di raccolta dei dati identificando automaticamente gli agenti utente necessari per ciascun sito Web, risparmiando tempo e risorse preziose.
Web Unlocker si adatta in tempo reale per evitare il rilevamento in risposta alle strategie in continua evoluzione utilizzate per bloccare i bot, garantendo un accesso continuo ai siti Web di interesse. Gli algoritmi di apprendimento automatico della piattaforma possono risolvere rapidamente i captcha, un ostacolo frequente alle iniziative di raccolta dati.

Prezzi di Web Unlocker
A partire da circa $ 2.03 per mille richieste (CPM), Web Unlocker offre più opzioni di prezzo per soddisfare le varie richieste. Una prova gratuita di 7 giorni è disponibile per gli utenti per iniziare e consentire loro di provare le funzionalità di Web Unlocker prima di impegnarsi.
Web Unlocker ha l'adattabilità per supportare vari modelli di utilizzo, indipendentemente dal fatto che i consumatori desiderino un approccio pay-as-you-go o necessitino di un piano personalizzato adatto alle loro particolari esigenze. Inoltre, chi sceglie piani tariffari a lungo termine potrebbe risparmiare il 32%.
Confronto tra Web Unlocker e proxy autogestiti
Web Unlocker offre numerosi vantaggi immediati rispetto ai proxy autogestiti. Per un'implementazione agevole, offre un'ampia tecnica di integrazione che combina le funzioni di super proxy e Proxy Manager. Gli utenti possono aumentare efficacemente le loro operazioni di raccolta dati con un numero infinito di connessioni simultanee.
Web Unlocker offre lo sblocco automatico, risolve i CAPTCHA e gestisce con successo le modifiche al markup sui siti Web di destinazione.
La piattaforma garantisce l'estrazione continua e affidabile dei dati implementando un sistema di ripetizione automatica ed effettuando chiamate asincrone per determinati domini. Inoltre, la crescente raccolta di richieste di intestazioni HTTP, cookie del browser specifici del sito e gadget simulati di Unlocker online consente agli utenti di non essere rilevati consentendo loro di acquisire dati online in tempo reale.
Considerazioni finali e cose importanti da ricordare
Infine, durante l'utilizzo di Bright Data per lo scraping di Instagram, è fondamentale tenere a mente alcuni punti vitali.
Si prega di notare che le loro capacità di scraping sono limitate ai dati pubblicamente disponibili, per pratiche etiche.
Dovresti sempre seguire i termini di servizio e le politiche sulla privacy di Instagram. Lo scraping dovrebbe essere fatto in modo etico e responsabile, senza intromettersi nei diritti degli utenti o violare alcuna legge.
In secondo luogo, aggiorna e perfeziona regolarmente i tuoi parametri di scraping per garantire l'accuratezza e la pertinenza dei dati recuperati. La piattaforma e gli algoritmi di Instagram sono soggetti a modifiche, pertanto devi modificare di conseguenza le tue strategie di scraping.
Infine, utilizza l'aiuto e le risorse della piattaforma di Bright Data per ottimizzare il successo dei tuoi sforzi di scraping su Instagram. Interagisci con la loro documentazione, tutorial e servizio clienti per migliorare la tua conoscenza dei loro strumenti di scraping.
Puoi ottenere informazioni utili, influenzare il processo decisionale saggio e avere successo nelle tue iniziative basate sui dati sulla piattaforma Instagram seguendo queste best practice e utilizzando la forza delle capacità di scraping di Instagram di Bright Data.





Lascia un Commento