Viviamo in tempi entusiasmanti, con annunci su tecnologia all'avanguardia ogni settimana. OpenAI ha appena rilasciato il modello all'avanguardia di sintesi tra testo e immagine DALLE 2.
Solo poche persone hanno ottenuto l'accesso anticipato a un nuovo sistema di intelligenza artificiale in grado di generare grafica realistica da descrizioni in linguaggio naturale. È ancora chiuso al pubblico.
Stability AI ha quindi rilasciato il file Diffusione stabile model, una variante open source di DALLE2. Questo lancio ha cambiato tutto. Le persone su Internet pubblicavano risultati rapidi e rimanevano sorprese dall'arte realistica.
Che cos'è la diffusione stabile?
Diffusione stabile è un modello di apprendimento automatico in grado di creare immagini dal testo, modificare le immagini a seconda del testo e compilare dettagli su immagini a bassa risoluzione o a basso dettaglio.
È stato addestrato su miliardi di foto e può fornire risultati equivalenti a DALL-MI2 ed Mezzo viaggio. Stabilità AI lo ha inventato ed è stato reso pubblico il 22 agosto 2022.
Ma con risorse di calcolo locali limitate, il modello Stable Diffusion richiede molto tempo per creare immagini di alta qualità. L'esecuzione del modello online utilizzando un provider cloud ci fornisce risorse di calcolo pressoché infinite e ci consente di acquisire risultati eccellenti molto più velocemente.
L'hosting del modello come microservizio consente inoltre ad altre app creative di sfruttare più prontamente il potenziale del modello senza dover affrontare le complessità dell'esecuzione di modelli ML online.
In questo post, cercheremo di dimostrare come sviluppare un modello di diffusione stabile e distribuirlo in AWS.
Costruisci e distribuisci una diffusione stabile
BentoML e Amazon Web Services EC2 sono due opzioni per l'hosting online del modello Stable Diffusion. BentoML è un framework open source per il ridimensionamento machine learning Servizi. Con BentoML, creeremo un servizio di dispersione affidabile e lo implementeremo in AWS EC2.
Preparazione dell'ambiente e download del modello di diffusione stabile
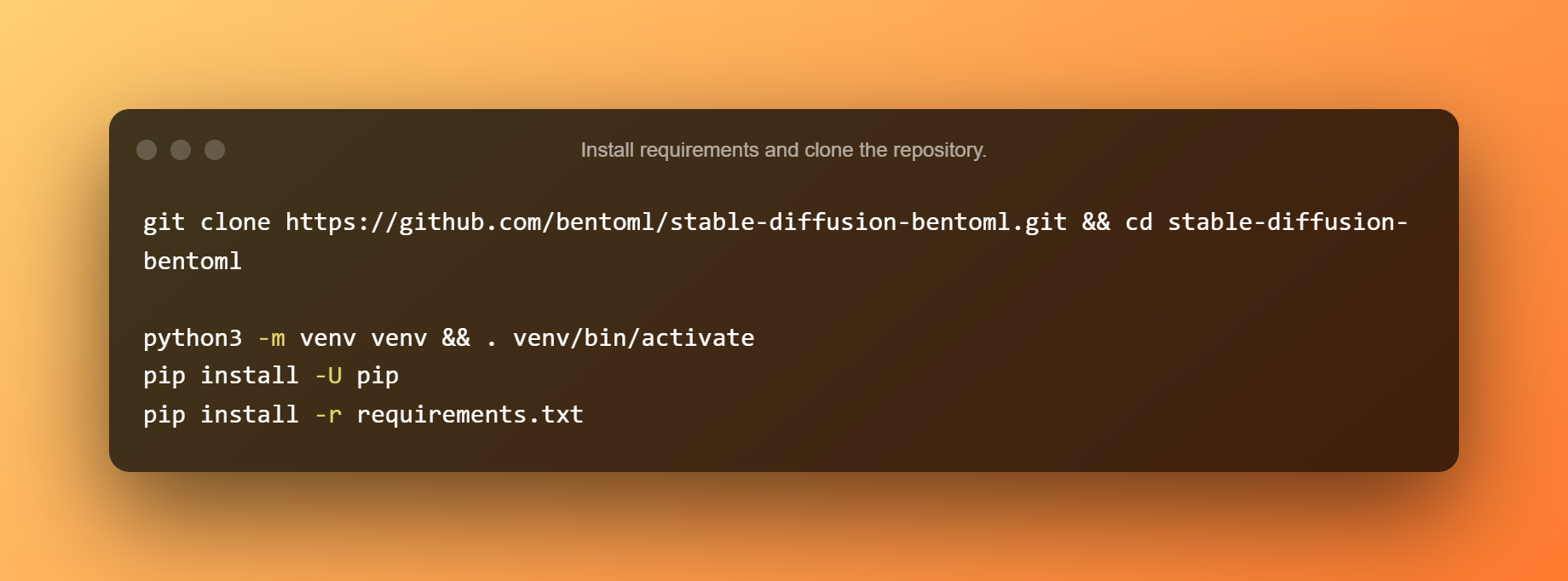
Installa i requisiti e clona il repository.
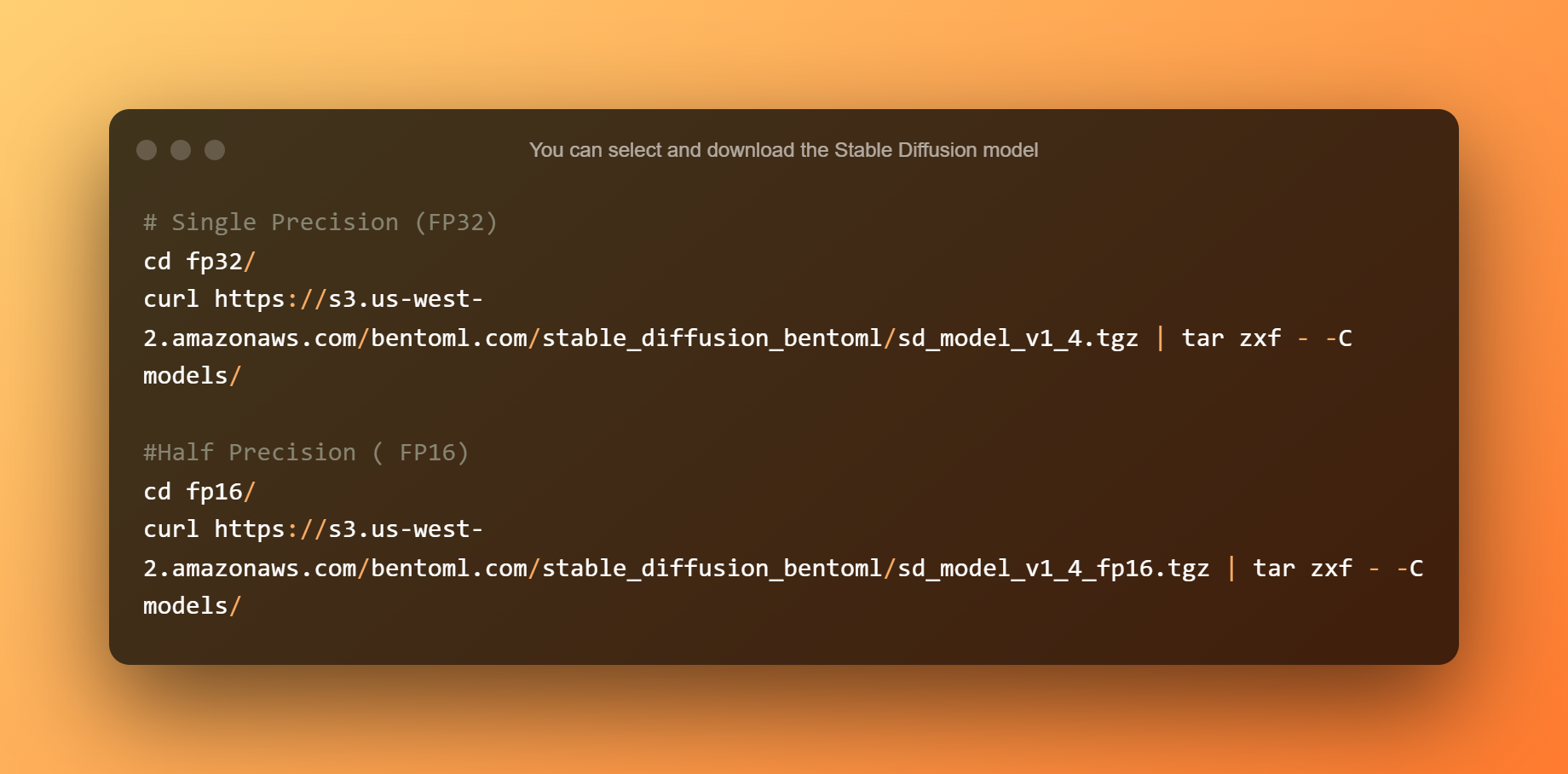
È possibile selezionare e scaricare il modello di diffusione stabile. La precisione singola è adatta per CPU o GPU con più di 10 GB di VRAM. La mezza precisione è l'ideale per le GPU con meno di 10 GB di VRAM.
Costruire una diffusione stabile
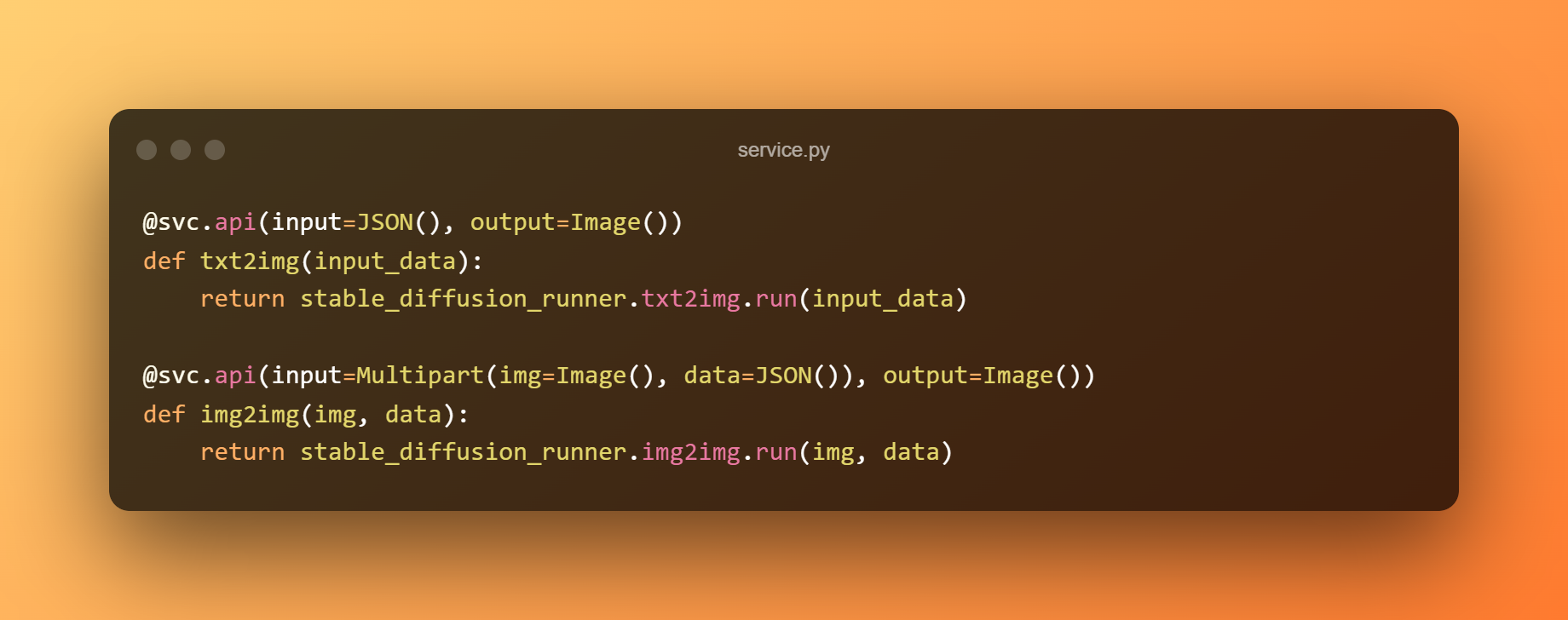
Costruiremo un servizio BentoML per servire il modello dietro a API RESTful. L'esempio seguente usa il modello a precisione singola per la previsione e il modulo service.py per connettere il servizio alla logica aziendale. Possiamo esporre le funzioni come API taggandole con @svc.api.
Inoltre, possiamo definire i tipi di input e output delle API nei parametri. L'endpoint txt2img, ad esempio, riceve un input JSON e produce un output Image, mentre l'endpoint img2img accetta un input Image e JSON e restituisce un output Image.
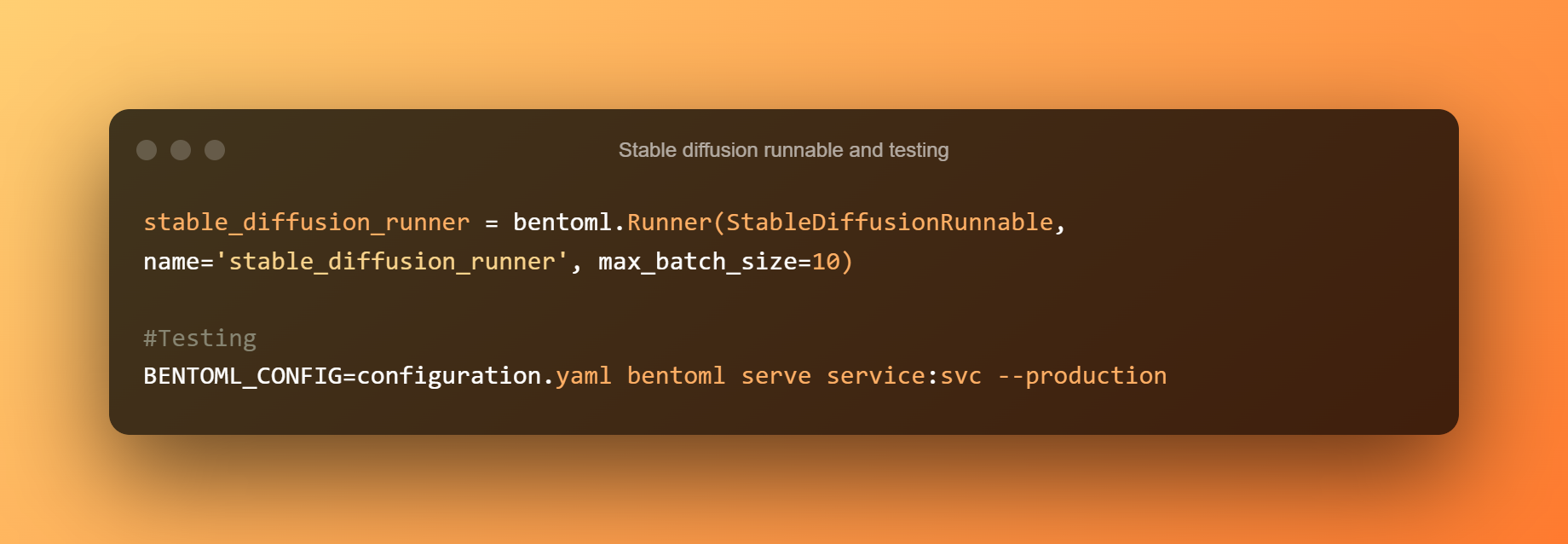
Un StableDiffusionRunnable definisce la logica di inferenza essenziale. Il runnable è responsabile dell'esecuzione dei metodi pipe txt2img del modello e dell'invio degli input pertinenti. Per eseguire la logica di inferenza del modello nelle API, viene creato un Runner personalizzato da StableDiffusionRunnable.
Quindi, utilizza il seguente comando per avviare un servizio BentoML per il test. Esecuzione locale del file Modello di diffusione stabile l'inferenza sulle CPU è piuttosto lenta. Ogni richiesta richiederà circa 5 minuti per l'elaborazione.
Da testo a immagine
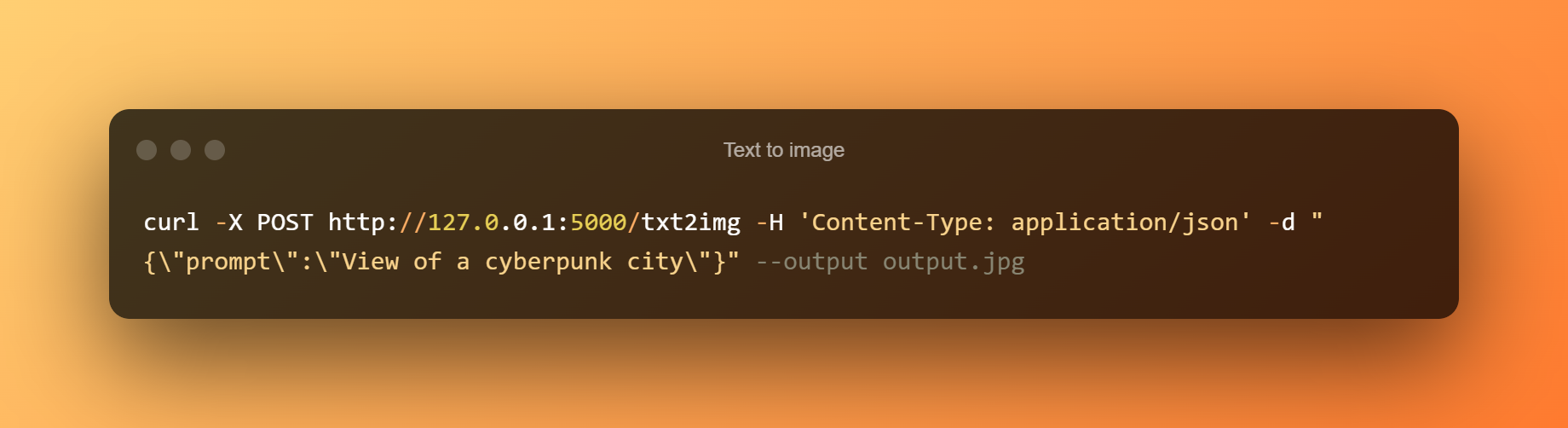
Output da testo a immagine

Il file bentofile.yaml definisce i file e le dipendenze richiesti.
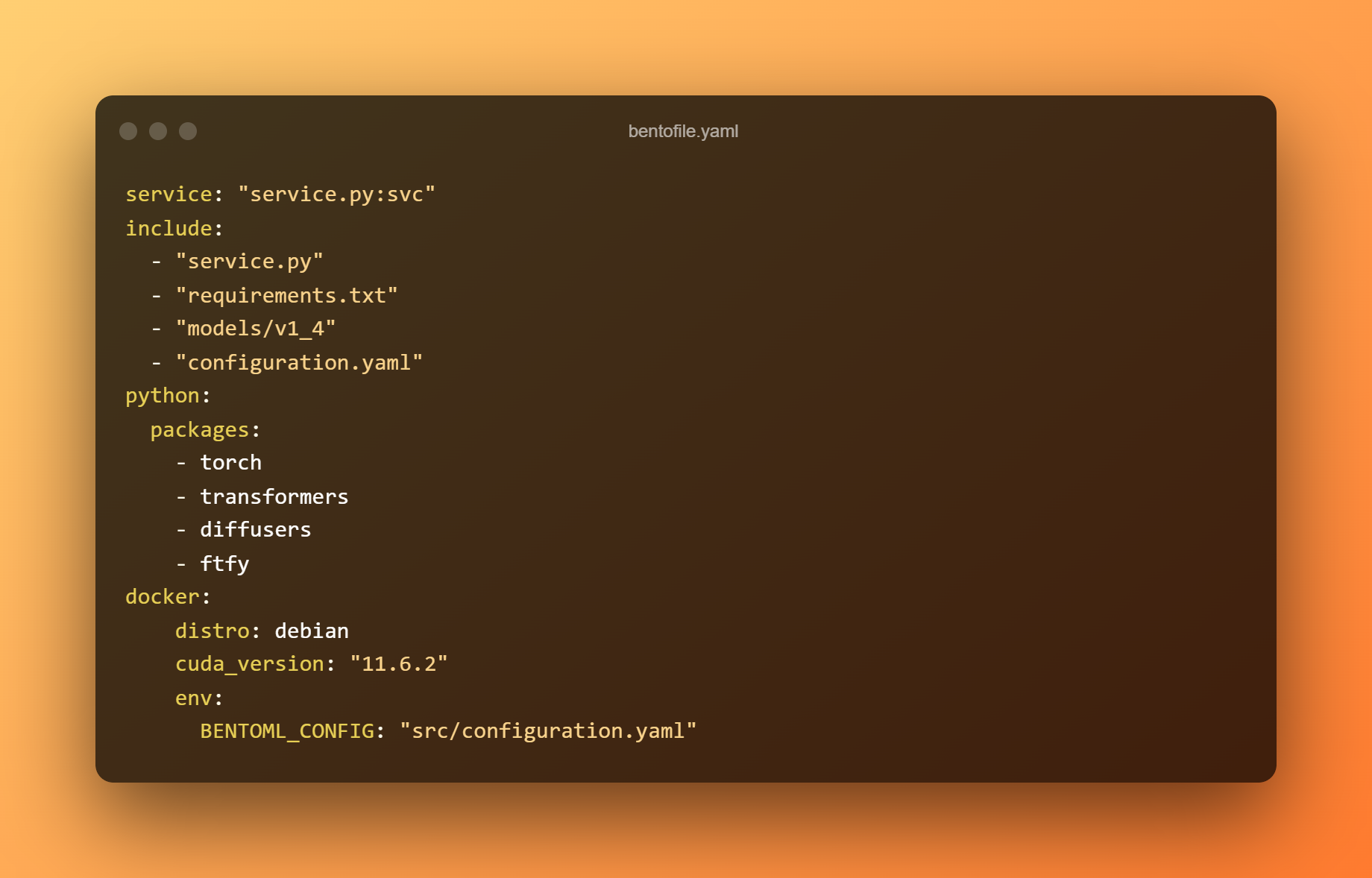
Usa il comando seguente per costruire un bento. Un Bento è il formato di distribuzione per un servizio BentoML. È un archivio autonomo che contiene tutti i dati e le configurazioni necessarie per avviare il servizio.

Il bento Stable Diffusion è stato completato. Se non sei riuscito a generare correttamente il bento, niente panico; puoi scaricare il modello pre-costruito usando i comandi elencati nella sezione successiva.
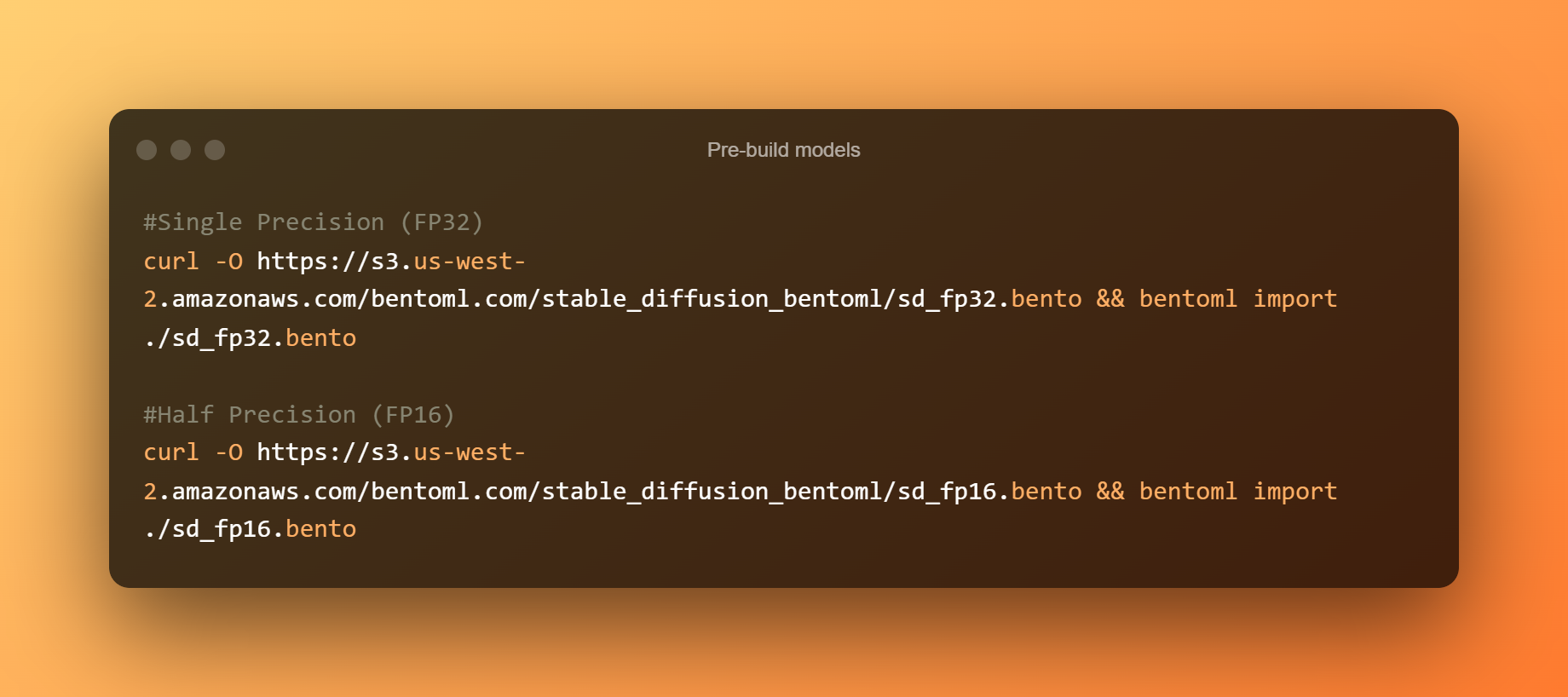
Modelli precompilati
Di seguito sono riportati i modelli pre-compilazione:
Distribuire il modello di diffusione stabile a EC2
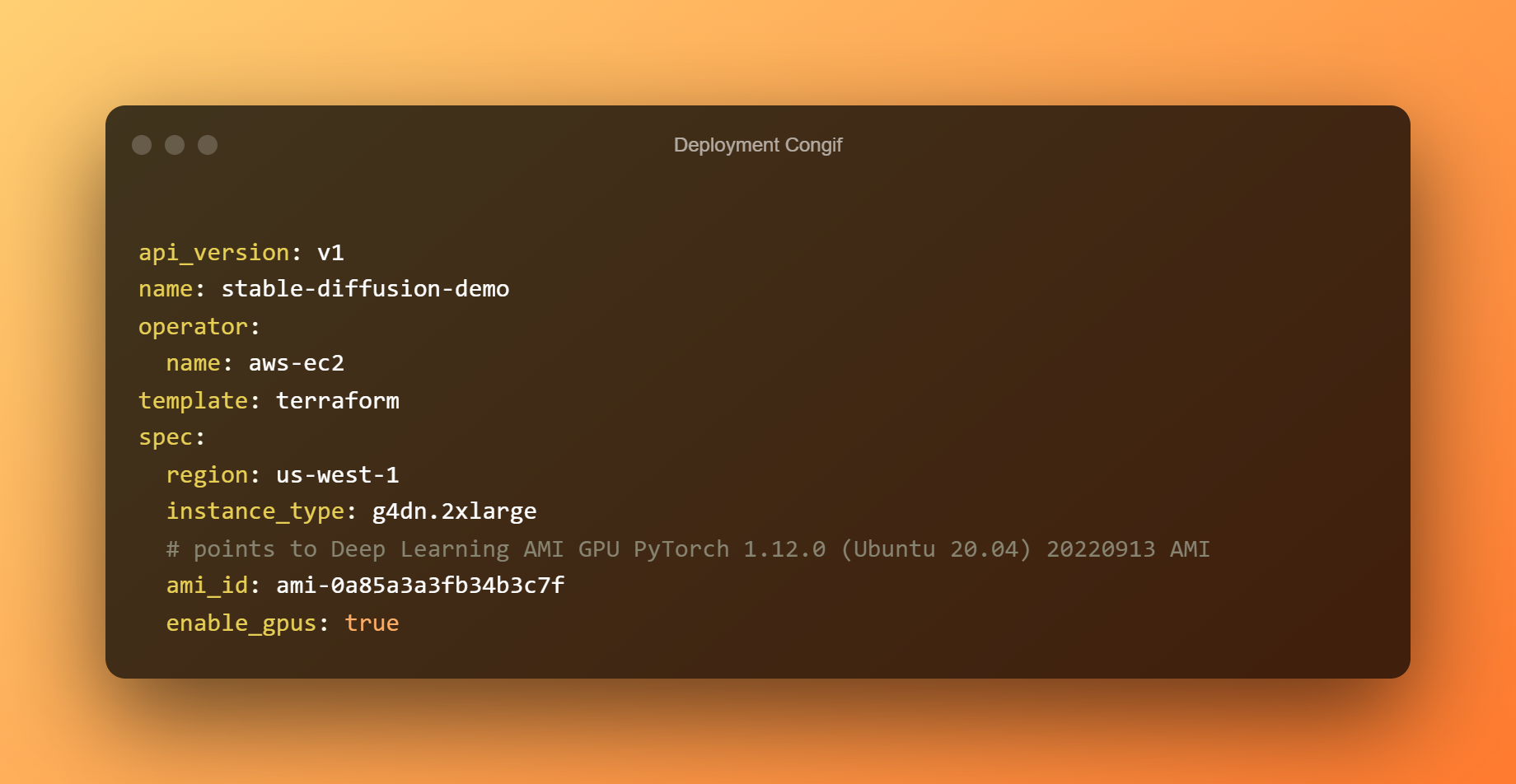
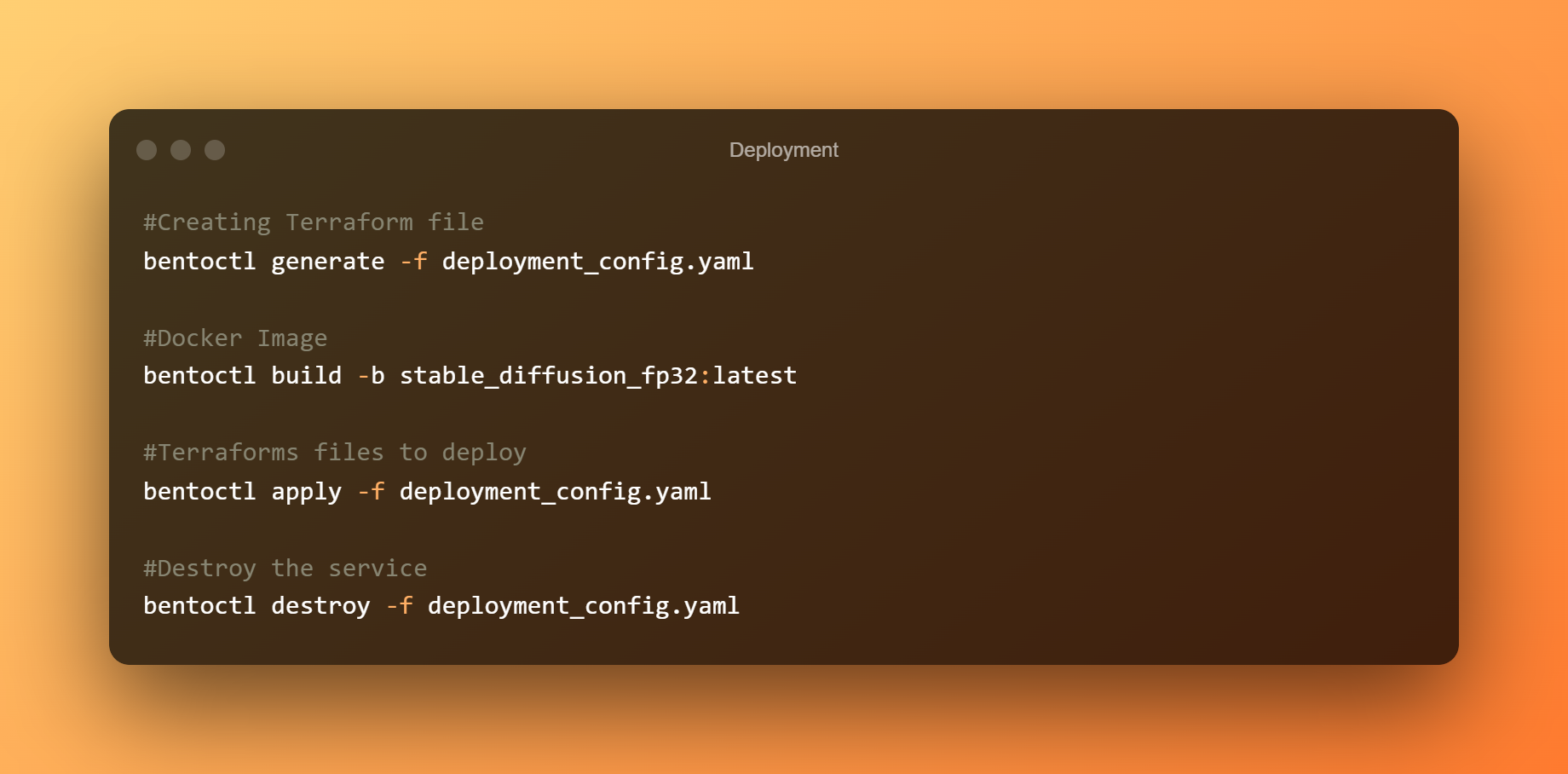
Per distribuire il bento su EC2, useremo bentoctl. bentoctl ti consente di distribuire i tuoi bento su qualsiasi piattaforma cloud usando Terraform. Per creare e applicare file Terraform, installa l'operatore AWS EC2.

Nel file config.yaml di distribuzione, la distribuzione è già stata configurata. Sentiti libero di modificare le tue esigenze. Il Bento viene distribuito per impostazione predefinita su un host g4dn.xlarge con Deep Learning AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) AMI nella regione us-west-1.
Crea ora i file Terraform. Crea l'immagine Docker e caricala su AWS ECR. A seconda della larghezza di banda, il caricamento delle immagini potrebbe richiedere molto tempo. Durante la distribuzione del bento in AWS EC2, utilizza i file Terraform.
Per accedere all'interfaccia utente di Swagger, connettiti alla console EC2 e apri l'indirizzo IP pubblico in un browser. Infine, se il servizio Stable Diffusion BentoML non è più necessario, rimuovere la distribuzione.
Conclusione
Dovresti essere in grado di vedere quanto siano affascinanti e potenti SD e i suoi modelli compagni. Il tempo ci dirà se ripeteremo ulteriormente il concetto o passeremo ad approcci più sofisticati.
Tuttavia, sono attualmente in corso iniziative per addestrare modelli più grandi con aggiustamenti per cogliere meglio l'ambiente circostante e le istruzioni. Abbiamo tentato di sviluppare il servizio Stable Diffusion utilizzando BentoML e lo abbiamo distribuito in AWS EC2.
Siamo stati in grado di eseguire il modello Stable Diffusion su hardware più potente, creare immagini con bassa latenza ed estenderlo oltre un singolo computer distribuendo il servizio su AWS EC2.





Lascia un Commento