Sommario[Nascondere][Spettacolo]
I grandi modelli da testo a immagine hanno fatto un progresso significativo nello sviluppo dell'IA producendo una sintesi di immagini diversificata e di alta qualità da un determinato prompt di testo.
Questi modelli non sono in grado di sintetizzare rappresentazioni uniche di soggetti in vari contesti o di replicare l'aspetto dei soggetti in un dato set di riferimento.
Tecnologie appena rilasciate come DALL.E2 di OpenAI o StabilityAI Diffusione stabile e Midjourney stanno già prendendo d'assalto Internet. Ora è il momento di personalizzare i risultati. Eppure come?
Google DreamBooth AI è arrivato.
DreamBooth ha la capacità di riconoscere l'argomento di un'immagine, decostruirlo dal suo contesto originale e quindi sintetizzarlo con precisione in un nuovo contesto desiderato. Inoltre, può essere utilizzato con gli attuali generatori di immagini AI.
In questo articolo, daremo uno sguardo approfondito a DreamBooth, al suo utilizzo, al suo tutorial, ai suoi limiti e molto altro.
Cos'è Dreambooth?
Dream Booth, un nuovissimo modello di diffusione da testo a immagine, è stato presentato da Google. Un messaggio scritto può essere utilizzato come guida da Google DreamBooth AI per generare un'ampia gamma di foto del soggetto selezionato dall'utente in diverse impostazioni.
Un gruppo di ricerca della Boston University e di Google ha sviluppato DreamBooth, una tecnica all'avanguardia per alterare i modelli da testo a immagine che sono stati sottoposti a un'ampia formazione preliminare.
Il concetto generale è piuttosto semplice: vogliono aumentare il dizionario di language-vision in modo tale che ID token non comuni siano associati ad argomenti personalizzati che gli utenti possono definire.
L'obiettivo principale del modello è connettere gli utenti al modello di diffusione da testo a immagine fornendo loro le risorse di cui hanno bisogno per produrre rappresentazioni fotorealistiche delle istanze dell'argomento selezionato.
Di conseguenza, questa tecnica sembra funzionare bene per riassumere le sfide in una serie di situazioni.
DreamBooth di Google differisce dai precedenti strumenti di conversione da testo a immagine, come DALL-MI2, Diffusione stabilee Metà viaggio, in quanto offre agli utenti un maggiore controllo sull'immagine dell'argomento prima di consentire loro di manipolare il modello di diffusione utilizzando input basati su testo.
Caratteristiche
- DreamBooth AI potrebbe migliorare un modello da testo a immagine con 3-5 immagini.
- È possibile creare foto fotorealistiche originali con DreamBooth AI.
- Inoltre, DreamBooth AI può creare foto di un argomento da più angolazioni.
Applicazioni
Rappresentazioni d'arte
Questa attività differisce specificamente dal trasferimento di stile, che mantiene la semantica della scena di origine incorporando lo stile di un'altra immagine nella scena originale.

Sulla base dell'approccio creativo, l'IA può apportare modifiche significative alla scena mantenendo l'identificazione e le specifiche dell'istanza dell'argomento.
Modifica della proprietà
Le caratteristiche dell'istanza del soggetto possono essere modificate da DreamBooth AI.

Accessorizzazione
La forte composizione prima del modello di generazione è ciò che rende così interessante la capacità di DreamBooth AI di adornare gli oggetti.

Ricontestualizzazione
DreamBooth AI può produrre immagini distintive per una determinata istanza di soggetto assegnando a un modello addestrato una frase che include l'identificatore univoco e il nome della classe.

Può generare il soggetto in posizioni, articolazioni e struttura della scena uniche e mai viste prima, piuttosto che cambiare l'ambiente circostante. Riflessi e ombre realistici, nonché interazioni tra il soggetto e gli oggetti circostanti.
Tutorial di Dreambooth
In questo tutorial, seguiremo il Quaderno di Google Collab, e ti guiderò attraverso di esso, che ti farà capire e usarlo da solo.
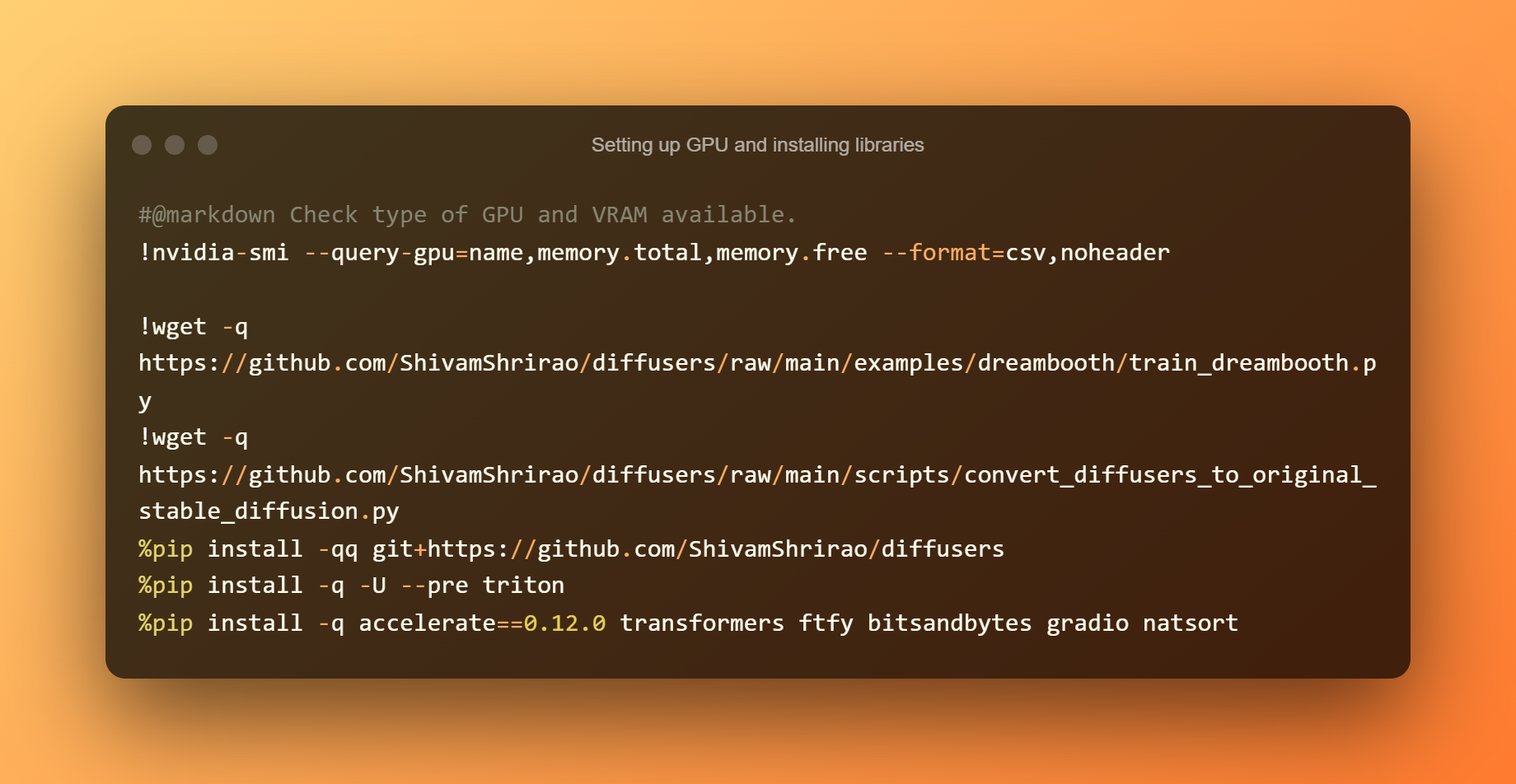
Configurazione della GPU e installazione delle librerie
Scoprire quali tipi di GPU e VRAM sono disponibili è il primo passo. È anche necessaria l'installazione di alcuni requisiti e dipendenze. Premi semplicemente il pulsante di riproduzione, quindi attendi che finisca.
Crea un account su Huggingface e genera un token
Il prossimo passo è registrarsi per un account Huggingface. Al termine, fai clic su Impostazioni nell'angolo in alto a destra. Arriverai alla pagina successiva.
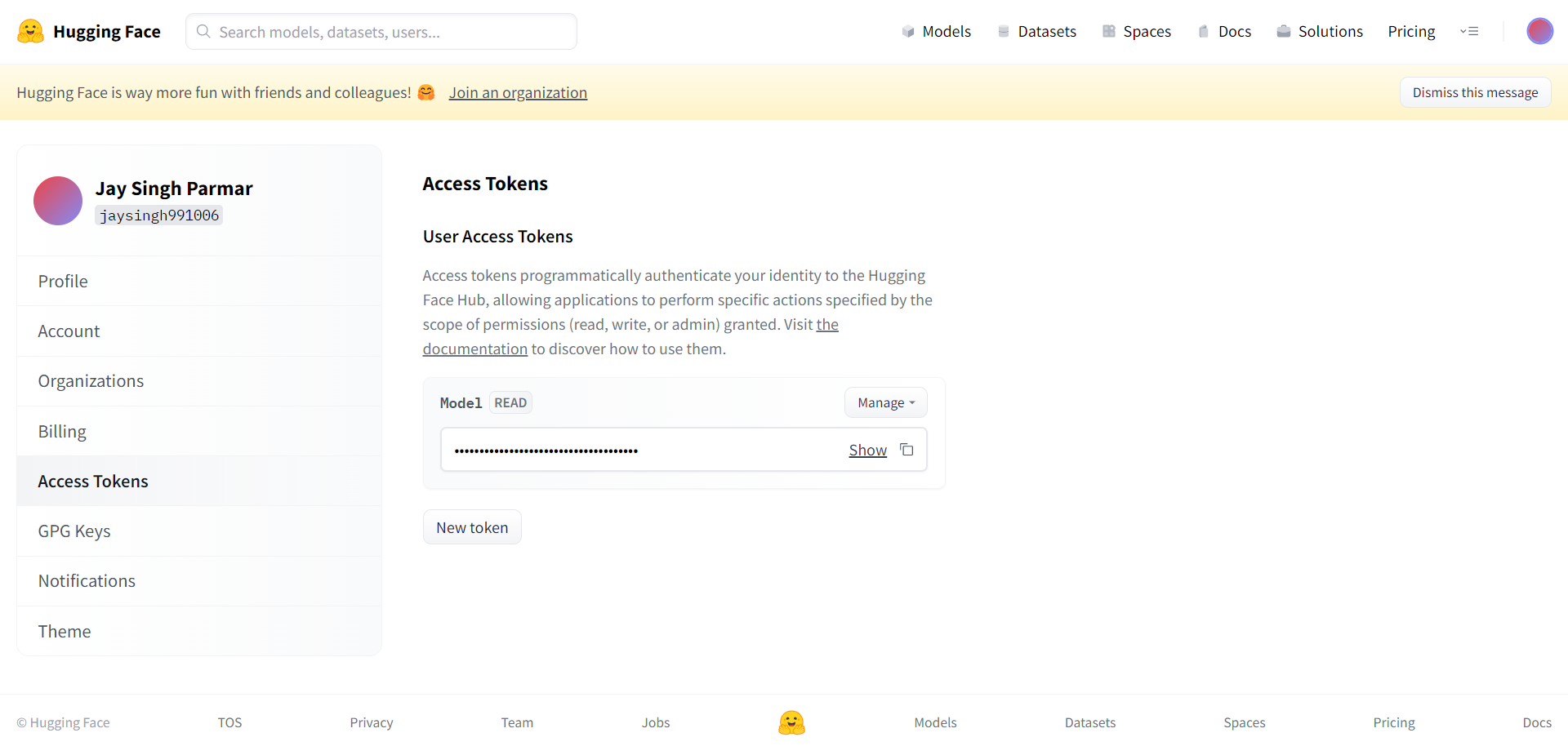
Crea il token e il nome come richiesto da qui. Il token deve essere copiato e incollato nella collaborazione di Google nella cella sottostante.

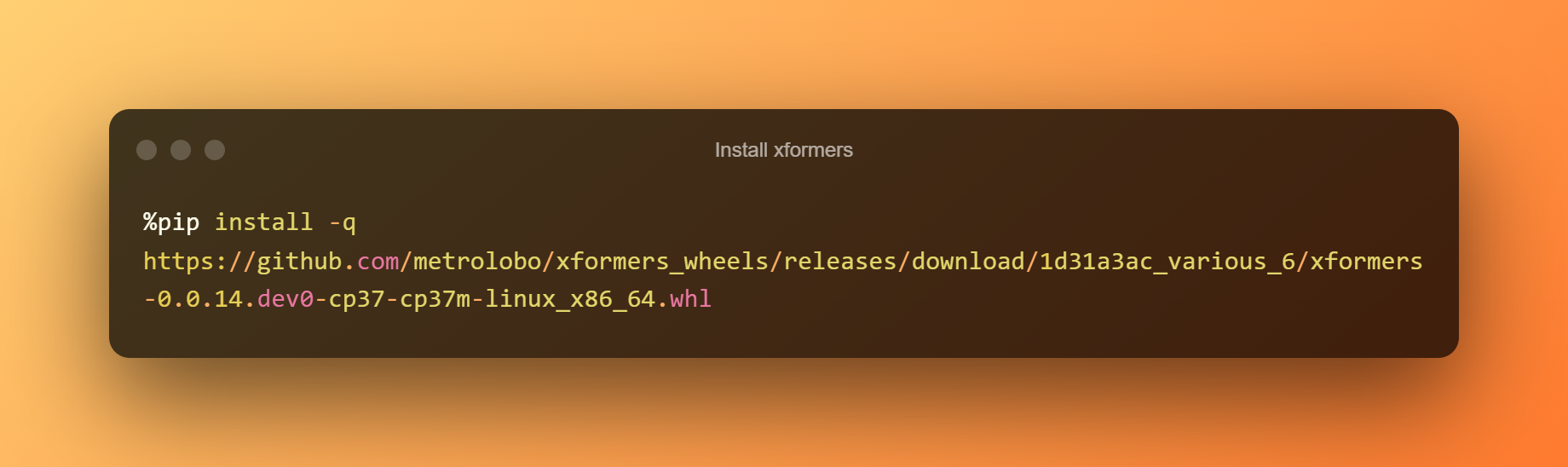
Installa xformers
In questa fase, puoi semplicemente premere il pulsante di riproduzione per installare xformers facendo clic sul runtime.
Connetti a Drive
Ora devi solo eseguire questa cella per connetterti a Google Drive.
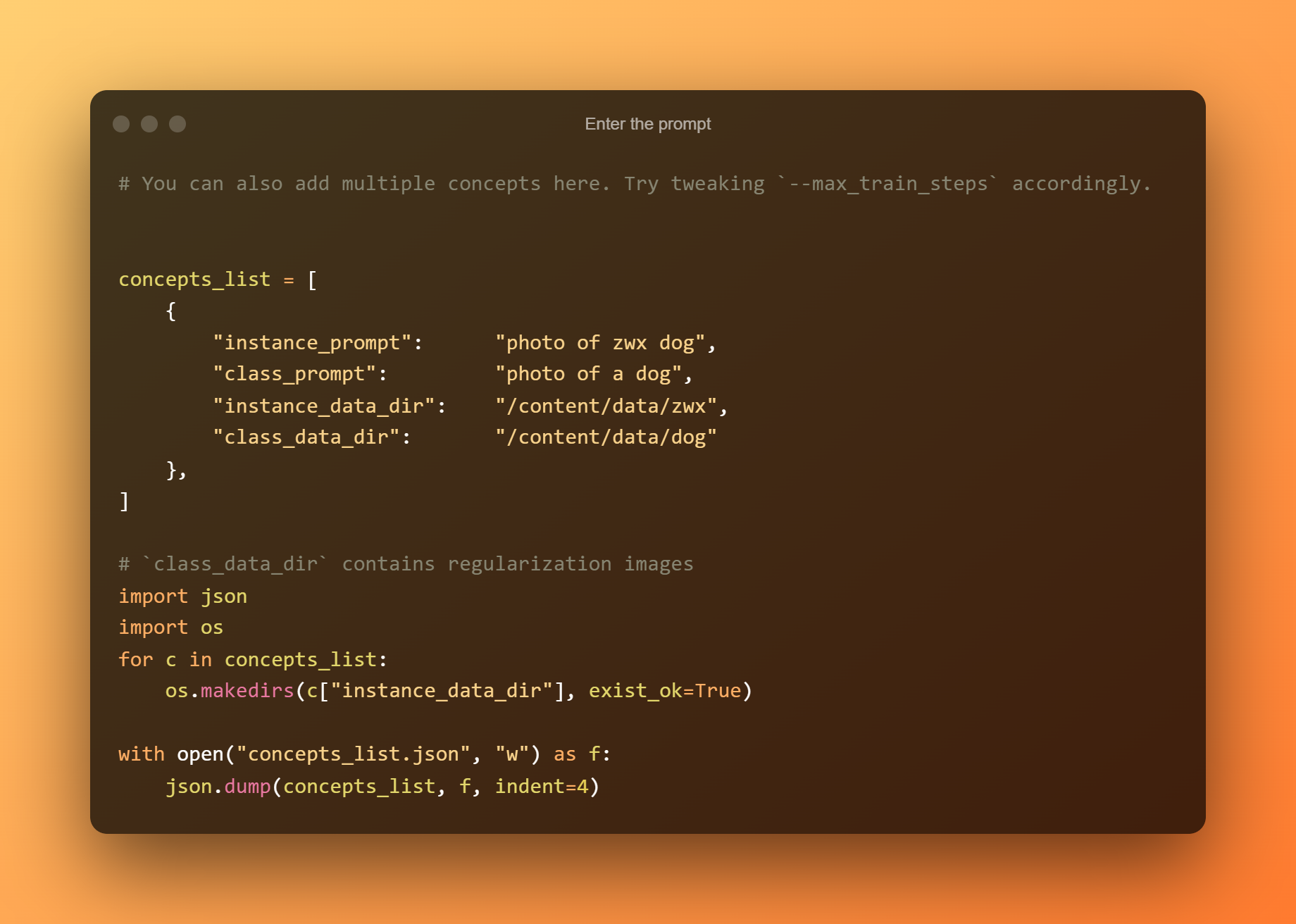
Immettere la richiesta
Nella cella seguente, devi solo inserire il prompt.
Caricamento di immagini
In questo passaggio, devi solo caricare le immagini che volevi allenare.

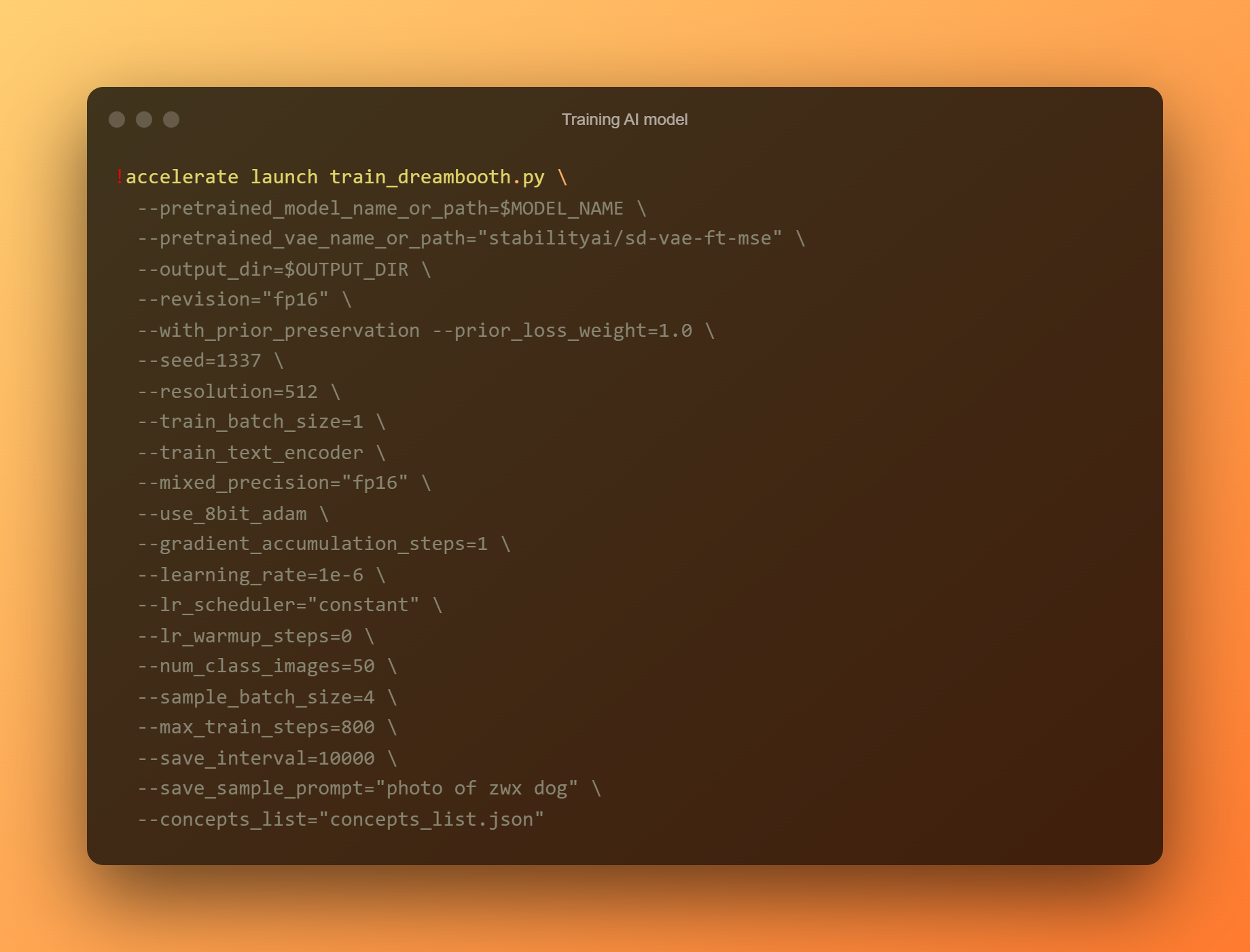
Allena il modello AI
Questa è la fase più importante, poiché utilizzerai DreamBooth per addestrare un nuovo modello di intelligenza artificiale basato su tutte le tue fotografie di riferimento inviate. Devi limitare la tua attenzione a due campi di input. "—prompt di istanza" è il primo parametro. Devi fornire un nome molto distinto qui.
L'argomento '-concept list' è il secondo campo di input critico. Deve essere rinominato in modo che corrisponda a quello utilizzato nella sezione "Modifica il prompt".
Genera immagini AI
Le immagini AI verranno create in questa fase, dove puoi inserire le istruzioni di testo.

Limitazioni di Dreambooth
- Il prompt dei comandi diventa un ostacolo all'esecuzione di iterazioni nell'argomento con livelli di dettaglio elevati. DreamBooth può cambiare il contesto del soggetto, ma se il modello desidera cambiare il soggetto stesso, ci sono problemi con la cornice.
- Un altro problema è il sovraadattamento dell'immagine di output all'immagine di input. Se non ci sono abbastanza immagini fornite, il soggetto potrebbe non essere considerato o essere mescolato con il contesto delle immagini inviate. Quando viene chiesto un contesto per una generazione dispari, accade la stessa cosa.
Conclusione
Per produrre output da un singolo input di testo, la maggior parte dei modelli da testo a immagine richiede milioni di parametri e librerie.
DreamBooth semplifica l'acquisizione e l'utilizzo dei contenuti per i consumatori richiedendo solo l'inserimento di tre o cinque fotografie di argomenti insieme a uno sfondo testuale.





Lascia un Commento