Sommario[Nascondere][Spettacolo]
Il futuro è qui. E, in questo futuro, le macchine comprendono il mondo che le circonda allo stesso modo delle persone. I computer possono guidare automobili, diagnosticare malattie e prevedere accuratamente il futuro.
Può sembrare fantascienza, ma i modelli di deep learning lo stanno trasformando in realtà.
Questi sofisticati algoritmi stanno svelando i segreti di intelligenza artificiale, consentendo ai computer di autoapprendere e svilupparsi. In questo post, approfondiremo il regno dei modelli di deep learning.
E indagheremo sull'enorme potenziale che hanno per rivoluzionare le nostre vite. Preparati a conoscere la tecnologia all'avanguardia che sta cambiando il futuro dell'umanità.

Cosa sono esattamente i modelli di deep learning?
Hai mai giocato a un gioco in cui devi identificare le differenze tra due immagini?
Tuttavia è divertente, può anche essere difficile, giusto? Immagina di poter insegnare a un computer a giocare a quel gioco e vincere ogni volta. I modelli di deep learning realizzano proprio questo!
I modelli di deep learning sono simili a macchine super intelligenti che possono esaminare un gran numero di immagini e determinare cosa hanno in comune. Lo fanno smontando le immagini e studiandole singolarmente.
Quindi applicano ciò che hanno imparato per identificare modelli e fare previsioni su nuove immagini che non hanno mai visto prima.

I modelli di deep learning sono reti neurali artificiali in grado di apprendere ed estrarre schemi e caratteristiche complicati da enormi set di dati. Questi modelli sono costituiti da diversi strati di nodi collegati, o neuroni, che analizzano e modificano i dati in arrivo per generare un output.
I modelli di deep learning sono particolarmente adatti a lavori che richiedono grande accuratezza e precisione, come l'identificazione di immagini, il riconoscimento vocale, l'elaborazione del linguaggio naturale e la robotica.
Sono stati utilizzati in qualsiasi cosa, dalle auto a guida autonoma alla diagnostica medica, ai sistemi di raccomandazione e analisi predittiva.
Ecco una versione semplificata della visualizzazione per illustrare il flusso di dati in un modello di deep learning.
I dati di input fluiscono nel livello di input del modello, che quindi passa i dati attraverso un numero di livelli nascosti prima di fornire una previsione di output.
Ogni livello nascosto esegue una serie di operazioni matematiche sui dati di input prima di passarli al livello successivo, che fornisce la previsione finale.
Ora vediamo cosa sono i modelli di deep learning e come possiamo usarli nella nostra vita.
1. Reti neurali convoluzionali (CNN)
Le CNN sono un modello di deep learning che ha trasformato l'area della visione artificiale. Le CNN vengono utilizzate per classificare le immagini, riconoscere oggetti e segmentare le immagini. La struttura e la funzione della corteccia visiva umana hanno informato la progettazione delle CNN.
Come funzionano?
Una CNN è costituita da un numero di livelli convoluzionali, livelli di raggruppamento e livelli completamente collegati. L'input è un'immagine e l'output è una previsione dell'etichetta di classe dell'immagine.
Gli strati convoluzionali di una CNN costruiscono una mappa delle caratteristiche eseguendo un prodotto scalare tra l'immagine di input e una serie di filtri. I livelli di raggruppamento riducono le dimensioni della mappa delle caratteristiche eseguendo il downsampling.
Infine, la mappa delle caratteristiche viene utilizzata dai livelli completamente connessi per prevedere l'etichetta della classe dell'immagine.

Perché le CNN sono importanti?
Le CNN sono essenziali perché possono imparare a rilevare modelli e caratteristiche nelle immagini che le persone trovano difficile notare. Alle CNN può essere insegnato a riconoscere caratteristiche come bordi, angoli e trame utilizzando grandi set di dati. Dopo aver appreso queste proprietà, una CNN può usarle per identificare oggetti in nuove foto. Le CNN hanno dimostrato prestazioni all'avanguardia su una varietà di applicazioni di identificazione delle immagini.
Dove usiamo le CNN
La sanità, l'industria automobilistica e la vendita al dettaglio sono solo alcuni dei settori che impiegano le CNN. Nel settore sanitario, possono essere utili per la diagnosi delle malattie, lo sviluppo di farmaci e l'analisi delle immagini mediche.
Nel settore automobilistico, aiutano con il rilevamento della corsia, rilevamento oggettie guida autonoma. Sono anche molto utilizzati nella vendita al dettaglio per la ricerca visiva, la raccomandazione di prodotti basata su immagini e il controllo dell'inventario.
Per esempio; Google impiega le CNN in una varietà di applicazioni, tra cui Google Lens, uno strumento di identificazione delle immagini molto apprezzato. Il programma utilizza le CNN per valutare le fotografie e fornire informazioni agli utenti.
Google Lens, ad esempio, può riconoscere le cose in un'immagine e offrire dettagli su di esse, come il tipo di fiore.

Può anche tradurre il testo estratto da un'immagine in più lingue. Google Lens è in grado di fornire ai consumatori informazioni utili grazie all'assistenza delle CNN nell'identificare accuratamente gli articoli e nell'estrarre le caratteristiche dalle foto.
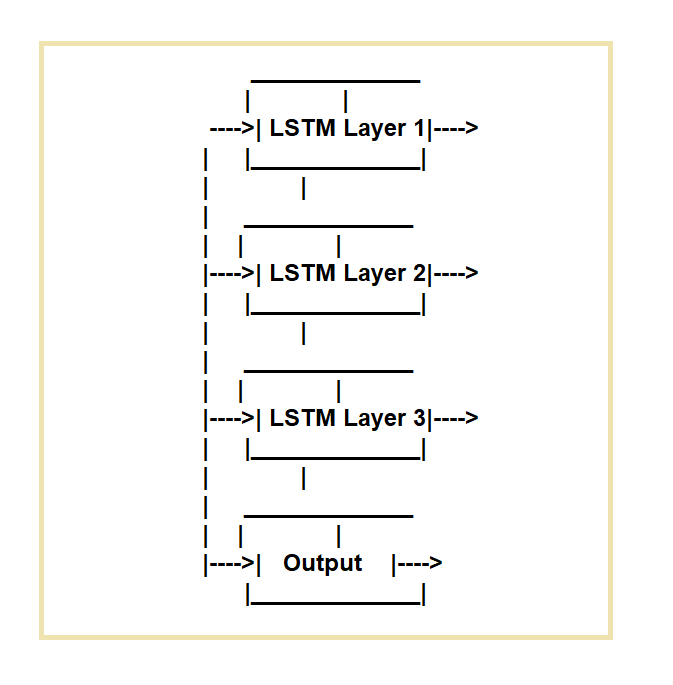
2. Reti LSTM (Long Short-Term Memory).
Le reti LSTM (Long Short-Term Memory) vengono create per affrontare le carenze delle normali reti neurali ricorrenti (RNN). Le reti LSTM sono ideali per attività che richiedono l'elaborazione di sequenze di dati nel tempo.
Funzionano impiegando una cella di memoria specifica e tre meccanismi di gating.
Regolano il flusso di informazioni dentro e fuori la cellula. La porta di ingresso, la porta dimenticata e la porta di uscita sono le tre porte.
La porta di ingresso regola il flusso di dati nella cella di memoria, la porta di dimenticanza regola la cancellazione dei dati dalla cella e la porta di uscita regola il flusso di dati fuori dalla cella.
Qual è il loro significato?
Le reti LSTM sono utili perché possono rappresentare e prevedere con successo sequenze di dati con relazioni a lungo termine. Possono registrare e conservare informazioni sugli input precedenti, consentendo loro di fare previsioni più accurate sugli input futuri.
Riconoscimento vocale, riconoscimento della grafia, elaborazione del linguaggio naturale e sottotitoli delle immagini sono solo alcune delle applicazioni che hanno utilizzato le reti LSTM.
Dove utilizziamo le reti LSTM?
Molte applicazioni software e tecnologiche utilizzano reti LSTM, inclusi sistemi di riconoscimento vocale, strumenti di elaborazione del linguaggio naturale come sentiment analysis, sistemi di traduzione automatica e sistemi di generazione di testo e immagini.
Sono stati utilizzati anche nella creazione di auto e robot a guida autonoma, nonché nel settore finanziario per rilevare frodi e anticipare borsa movimenti.
3. Generative Adversarial Network (GAN)
I GAN sono un apprendimento profondo tecnica utilizzata per generare nuovi campioni di dati simili a un determinato set di dati. I GAN sono composti da due reti neurali: uno che impara a produrre nuovi campioni e uno che impara a distinguere tra campioni genuini e generati.
In un approccio simile, queste due reti vengono addestrate insieme finché il generatore non può generare campioni indistinguibili da quelli effettivi.
Perché utilizziamo i GAN
I GAN sono significativi per la loro capacità di produrre prodotti di alta qualità dati sintetici che può essere utilizzato per una varietà di applicazioni, tra cui la produzione di immagini e video, la generazione di testo e persino la generazione di musica.
I GAN sono stati utilizzati anche per l'aumento dei dati, che è la generazione di dati sintetici integrare i dati del mondo reale e migliorare le prestazioni dei modelli di apprendimento automatico.
Inoltre, creando dati sintetici che possono essere utilizzati per addestrare modelli e imitare le prove, i GAN hanno il potenziale per trasformare settori come la medicina e lo sviluppo di farmaci.

Applicazioni dei GAN
I GAN possono integrare set di dati, creare nuove immagini o filmati e persino generare dati sintetici per simulazioni scientifiche. Inoltre, i GAN hanno il potenziale per essere impiegati in una varietà di applicazioni che vanno dall'intrattenimento alla medicina.
età e video. StyleGAN2 di NVIDIA, ad esempio, è stato utilizzato per creare fotografie di alta qualità di celebrità e opere d'arte.
4. Reti di credenze profonde (DBN)
I Deep Belief Network (DBN) lo sono intelligenza artificiale sistemi che possono imparare a individuare modelli nei dati. Lo fanno segmentando i dati in blocchi sempre più piccoli, acquisendone una comprensione più approfondita a ogni livello.
I DBN possono apprendere dai dati senza essere informati di cosa si tratta (questo è indicato come "apprendimento non supervisionato"). Ciò li rende estremamente preziosi per rilevare modelli nei dati che una persona troverebbe difficile o impossibile discernere.
Cosa rende i DBN significativi?
I DBN sono significativi per la loro capacità di apprendere rappresentazioni di dati gerarchici. Queste rappresentazioni possono essere utilizzate per una varietà di applicazioni come la classificazione, il rilevamento di anomalie e la riduzione della dimensionalità.
La capacità dei DBN di intraprendere un pre-addestramento senza supervisione, che può aumentare le prestazioni dei modelli di deep learning con dati etichettati minimi, è un vantaggio significativo.

Quali sono le applicazioni dei DBN?
Una delle applicazioni più significative è rilevamento oggetti, in cui i DBN vengono utilizzati per riconoscere determinati tipi di cose come aeroplani, uccelli e esseri umani. Sono anche utilizzati per la generazione e la classificazione di immagini, il rilevamento del movimento nei film e la comprensione del linguaggio naturale per l'elaborazione vocale.
Inoltre, i DBN sono comunemente impiegati nei set di dati per valutare le posture umane. I DBN sono un ottimo strumento per una varietà di settori, tra cui sanità, banche e tecnologia.
5. Deep Reinforcement Learning Networks (DRL)
In profondità Insegnamento rafforzativo Le reti (DRL) integrano reti neurali profonde con tecniche di apprendimento per rinforzo per consentire agli agenti di apprendere in un ambiente complicato tramite tentativi ed errori.
I DRL vengono utilizzati per insegnare agli agenti come ottimizzare un segnale di ricompensa interagendo con l'ambiente circostante e imparando dai propri errori.
Cosa li rende straordinari?
Sono stati utilizzati efficacemente in una varietà di applicazioni, tra cui giochi, robotica e guida autonoma. I DRL sono importanti perché possono apprendere direttamente dall'input sensoriale grezzo, consentendo agli agenti di prendere decisioni in base alle loro interazioni con l'ambiente.
Applicazioni importanti
I DRL sono impiegati in circostanze del mondo reale perché possono gestire problemi difficili.
I DRL sono stati inclusi in diverse importanti piattaforme software e tecnologiche, tra cui OpenAI's Gym, Agenti ML di Unitye DeepMind Lab di Google. AlphaGo, creato da Google DeepMind, ad esempio, utilizza DRL per giocare al gioco da tavolo Go a livello di campione del mondo.

Un altro utilizzo del DRL è nella robotica, dove viene utilizzato per controllare i movimenti dei bracci robotici per eseguire compiti come afferrare oggetti o impilare blocchi. I DRL hanno molti usi e sono uno strumento utile per agenti di formazione per imparare e prendere decisioni in contesti complicati.
6. Codificatori automatici
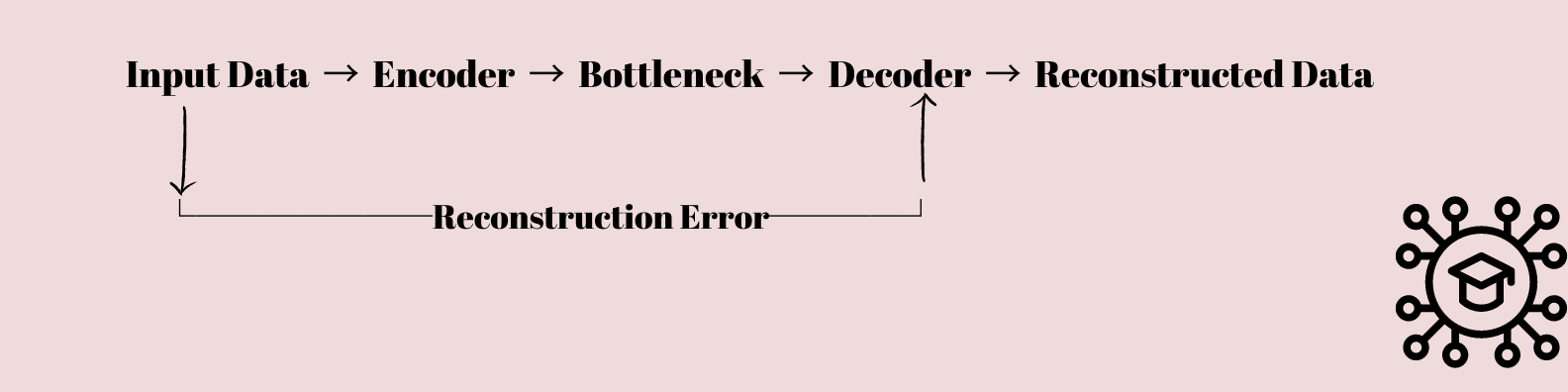
Gli autoencoder sono un tipo interessante di rete neurale che ha catturato l'interesse sia degli studiosi che dei data scientist. Sono fondamentalmente progettati per imparare a comprimere e ripristinare i dati.
I dati di input vengono alimentati attraverso una successione di livelli che riducono gradualmente la dimensionalità dei dati fino a quando non vengono compressi in uno strato di collo di bottiglia con meno nodi rispetto ai livelli di input e output.
Questa rappresentazione compressa viene quindi utilizzata per ricreare i dati di input originali utilizzando una sequenza di livelli che riportano gradualmente la dimensionalità dei dati alla sua forma originale.
Perché è importante?
Gli autoencoder sono una componente cruciale di apprendimento profondo perché rendono possibile l'estrazione di caratteristiche e la riduzione dei dati.
Sono in grado di identificare gli elementi chiave dei dati in arrivo e di tradurli in una forma compressa che può quindi essere applicata ad altre attività come la classificazione, il raggruppamento o la creazione di nuovi dati.
Dove utilizziamo gli autoencoder?
Rilevamento delle anomalie, elaborazione del linguaggio naturale e visione computerizzata sono solo alcune delle discipline in cui vengono utilizzati gli autoencoder. Gli autocodificatori, ad esempio, possono essere utilizzati per la compressione delle immagini, il denoising delle immagini e la sintesi delle immagini nella visione artificiale.
Possiamo utilizzare i codificatori automatici in attività come la creazione di testo, la categorizzazione del testo e il riepilogo del testo nell'elaborazione del linguaggio naturale. Può identificare attività anomale nei dati che si discostano dalla norma nell'identificazione delle anomalie.
7. Reti di capsule
Capsule Networks è una nuova architettura di deep learning che è stata sviluppata in sostituzione delle reti neurali convoluzionali (CNN).
I Capsule Network si basano sull'idea di raggruppare unità cerebrali chiamate capsule che sono responsabili del riconoscimento dell'esistenza di un determinato elemento in un'immagine e della codifica dei suoi attributi, come l'orientamento e la posizione, nei loro vettori di output. Le Capsule Network possono quindi gestire le interazioni spaziali e le fluttuazioni di prospettiva meglio delle CNN.
Perché scegliamo Capsule Networks rispetto a CNN?
Le Capsule Network sono utili perché superano le difficoltà della CNN nel catturare le relazioni gerarchiche tra gli elementi in un'immagine. Le CNN sono in grado di riconoscere oggetti di varie dimensioni, ma fanno fatica a capire come questi elementi si colleghino tra loro.
Capsule Networks, d'altra parte, può imparare a riconoscere le cose e le loro parti, nonché il modo in cui sono posizionate spazialmente in un'immagine, rendendole un valido concorrente per le applicazioni di visione artificiale.
Aree di applicazione
Capsule Networks ha già dimostrato risultati promettenti in una varietà di applicazioni, tra cui la classificazione delle immagini, l'identificazione degli oggetti e la segmentazione delle immagini.
Sono stati usati per distinguere le cose nelle foto mediche, riconoscere le persone nei film e persino creare modelli 3D da immagini 2D.
Per aumentare le loro prestazioni, le Capsule Network sono state combinate con altre architetture di deep learning come le Generative Adversarial Network (GAN) e i Variational Autoencoders (VAE). Si prevede che le Capsule Network svolgano un ruolo sempre più vitale nel migliorare le tecnologie di visione artificiale man mano che la scienza del deep learning si evolve.
Per esempio; Nibabele è un noto strumento Python per la lettura e la scrittura di tipi di file di neuroimaging. Per la segmentazione delle immagini, utilizza Capsule Networks.
8. Modelli basati sull'attenzione
I modelli di deep learning noti come modelli basati sull'attenzione, noti anche come meccanismi di attenzione, si sforzano di aumentare la precisione di modelli di apprendimento automatico. Questi modelli funzionano concentrandosi su determinate caratteristiche dei dati in entrata, con conseguente elaborazione più efficiente ed efficace.
Nelle attività di elaborazione del linguaggio naturale come la traduzione automatica e l'analisi dei sentimenti, i metodi di attenzione hanno dimostrato di avere un discreto successo.
Qual è il loro significato?
I modelli basati sull'attenzione sono utili perché consentono un'elaborazione più efficace ed efficiente di dati complessi.
Reti neurali tradizionali valutare tutti i dati di input come ugualmente importanti, con conseguente elaborazione più lenta e minore precisione. I processi di attenzione si concentrano su aspetti cruciali dei dati di input, consentendo previsioni più rapide e accurate.

Aree di utilizzo
Nel campo dell'intelligenza artificiale, i meccanismi di attenzione hanno una vasta gamma di applicazioni, tra cui l'elaborazione del linguaggio naturale, il riconoscimento di immagini e audio e persino i veicoli senza conducente.
I metodi di attenzione, ad esempio, possono essere utilizzati per migliorare la traduzione automatica nell'elaborazione del linguaggio naturale consentendo al sistema di concentrarsi su determinate parole o frasi essenziali per il contesto.
I metodi di attenzione nelle auto autonome possono essere impiegati per aiutare il sistema a concentrarsi su determinati elementi o sfide nell'ambiente circostante.
9. Reti di trasformatori
Le reti Transformer sono modelli di deep learning che esaminano e producono sequenze di dati. Funzionano elaborando la sequenza di input un elemento alla volta e producendo una sequenza di output della stessa lunghezza o di lunghezze diverse.
Le reti di trasformatori, a differenza dei modelli sequenza-sequenza standard, non elaborano sequenze utilizzando reti neurali ricorrenti (RNN). Invece, impiegano processi di auto-attenzione per apprendere i collegamenti tra i pezzi della sequenza.
Qual è l'importanza delle reti di trasformatori?
Le reti di trasformatori sono cresciute in popolarità negli ultimi anni grazie alle loro migliori prestazioni nei lavori di elaborazione del linguaggio naturale.
Sono particolarmente adatti per attività di creazione di testi come la traduzione linguistica, il riepilogo del testo e la produzione di conversazioni.
Le reti di trasformatori sono significativamente più efficienti dal punto di vista computazionale rispetto ai modelli basati su RNN, il che le rende una scelta preferita per applicazioni su larga scala.

Dove puoi trovare reti di trasformatori?
Le reti di trasformatori sono ampiamente utilizzate in un'ampia gamma di applicazioni, in particolare nell'elaborazione del linguaggio naturale.
La serie GPT (Generative Pre-trained Transformer) è un importante modello basato su trasformatore che è stato utilizzato per attività come la traduzione linguistica, il riepilogo del testo e la generazione di chatbot.
BERT (Bidirectional Encoder Representations from Transformers) è un altro modello comune basato su trasformatore che è stato utilizzato per applicazioni di comprensione del linguaggio naturale come la risposta alle domande e l'analisi del sentimento.
Entrambi GPT e BERT sono stati creati con PyTorch, un framework di deep learning open source che è stato popolare per lo sviluppo di modelli basati su trasformatore.
10. Macchine Boltzmann limitate (RBM)
Le Restricted Boltzmann Machines (RBM) sono una sorta di rete neurale non supervisionata che apprende in modo generativo. A causa della loro capacità di apprendere ed estrarre caratteristiche essenziali da dati ad alta dimensione, sono stati ampiamente impiegati nei campi del machine learning e del deep learning.
Gli RBM sono costituiti da due strati, visibile e nascosto, con ogni strato costituito da un gruppo di neuroni collegati da bordi pesati. Gli RBM sono progettati per apprendere una distribuzione di probabilità che descrive i dati di input.
Cosa sono le macchine Boltzmann limitate?
Gli RBM utilizzano una strategia di apprendimento generativo. Negli RBM, lo strato visibile riflette i dati di input, mentre lo strato sepolto codifica le caratteristiche dei dati di input. I pesi degli strati visibili e nascosti mostrano la forza del loro legame.
Gli RBM regolano i pesi e le distorsioni tra gli strati durante l'allenamento utilizzando una tecnica nota come divergenza contrastiva. La divergenza contrastiva è una strategia di apprendimento non supervisionata che massimizza la probabilità di previsione del modello.
Qual è il significato delle macchine Boltzmann limitate?
Gli RBM sono significativi in machine learning e deep learning perché possono apprendere ed estrarre caratteristiche rilevanti da grandi quantità di dati.
Sono molto efficaci per il riconoscimento vocale e di immagini e sono stati impiegati in una varietà di applicazioni come i sistemi di raccomandazione, il rilevamento delle anomalie e la riduzione della dimensionalità. Gli RBM possono trovare modelli in vasti set di dati, con conseguenti previsioni e approfondimenti superiori.

Dove possono essere utilizzate le macchine Boltzmann limitate?
Le applicazioni per gli RBM includono la riduzione della dimensionalità, il rilevamento delle anomalie e i sistemi di raccomandazione. Gli RBM sono particolarmente utili per l'analisi del sentimento e modellazione tematica nel contesto dell'elaborazione del linguaggio naturale.
Anche le reti di credenze profonde, una sorta di rete neurale utilizzata per il riconoscimento di voci e immagini, utilizzano RBM. La cassetta degli attrezzi di Deep Belief Network, TensorFlowe Theano sono alcuni esempi particolari di software o tecnologia che utilizza RBM.
Incartare
I modelli di Deep Learning stanno diventando sempre più cruciali in una varietà di settori, tra cui il riconoscimento vocale, l'elaborazione del linguaggio naturale e la visione artificiale.
Le reti neurali convoluzionali (CNN) e le reti neurali ricorrenti (RNN) hanno mostrato le migliori promesse e sono ampiamente utilizzate in molte applicazioni, tuttavia, tutti i modelli di Deep Learning hanno i loro vantaggi e svantaggi.
Tuttavia, i ricercatori stanno ancora esaminando le Restricted Boltzmann Machines (RBM) e altre varietà di modelli di Deep Learning perché anch'essi presentano vantaggi speciali.
Si prevede la creazione di modelli nuovi e creativi man mano che l'area del deep learning continua ad avanzare per gestire problemi più difficili





Lascia un Commento