Sommario[Nascondere][Spettacolo]
La nuova e migliorata IA ha migliorato le capacità, la comprensione e la capacità di produrre immagini a risoluzione più elevata. Di recente potresti esserti imbattuto in alcune immagini strane e divertenti che circolano su Internet.
Un cane Shiba Inu è vestito con un berretto e un dolcevita nero. E una lontra marina alla maniera della "Ragazza con l'orecchino di perla" del pittore olandese Vermeer. E c'è una tazza di zuppa che sembra un mostro lanoso.
Queste immagini non sono stati creati da un artista umano.
Invece, DALL-E 2, un nuovo sistema di intelligenza artificiale in grado di convertire le descrizioni testuali in immagini, le ha create.
Scrivi semplicemente quello che vuoi vedere e l'IA lo creerà per te, con dettagli vividi, grande qualità e, in alcuni casi, genuina inventiva. In questo post, daremo uno sguardo approfondito all'ultimo studio di OpenAI, DALL.E 2, a come funziona e molto altro ancora. Iniziamo.
Quindi, cos'è esattamente DALL.E 2?
DALL-E 2 è un "modello generativo", un tipo di algoritmo di apprendimento automatico che genera un output complicato anziché eseguire attività di previsione o classificazione sui dati di input.
Fornisci a DALL-E 2 una descrizione scritta e crea un'immagine che corrisponde ad essa. Combinando concetti, qualità e stili, DALLE 2 di OpenAI può produrre grafica e arte innovative e realistiche da una descrizione linguistica di base.
Si dice che l'ultima versione, DALLE 2, sia più versatile, in grado di realizzare immagini da didascalie a risoluzioni più elevate e in uno spettro più ampio di stili creativi. Ad esempio, le immagini sottostanti (dal post del blog DALL-E 2) sono create dalla descrizione "Un astronauta a cavallo".
Una descrizione si conclude "come uno schizzo a matita", mentre l'altra conclude "in modo fotorealistico".

Può anche modificare le fotografie esistenti con una precisione sorprendente. Quindi, puoi aggiungere o eliminare elementi mantenendo colori, riflessi e ombre, il tutto mantenendo l'aspetto dell'immagine originale.
Come funziona?
DALL-E 2 si avvale dei modelli CLIP e di diffusione, due sofisticati apprendimento profondo approcci sviluppati negli ultimi anni. Tuttavia, si basa sulla stessa nozione di tutti gli altri deep reti neurali: apprendimento della rappresentazione. CLIP ne allena due contemporaneamente reti neurali su immagini e didascalie.
Una rete apprende le rappresentazioni visive nell'immagine, mentre l'altra apprende le rappresentazioni testuali. Durante l'addestramento, le due reti tentano di modificare i propri parametri in modo che immagini e descrizioni comparabili risultino in incorporamenti simili.
La "diffusione", un tipo di modello generativo che impara a creare immagini rumorizzando e denoising gradualmente i suoi campioni di addestramento, è l'altro approccio di apprendimento automatico utilizzato in DALL-E 2. I modelli di diffusione sono simili agli autoencoder in quanto trasformano i dati di input in un incorporare la rappresentazione e quindi utilizzare le informazioni di incorporamento per ricreare i dati originali.
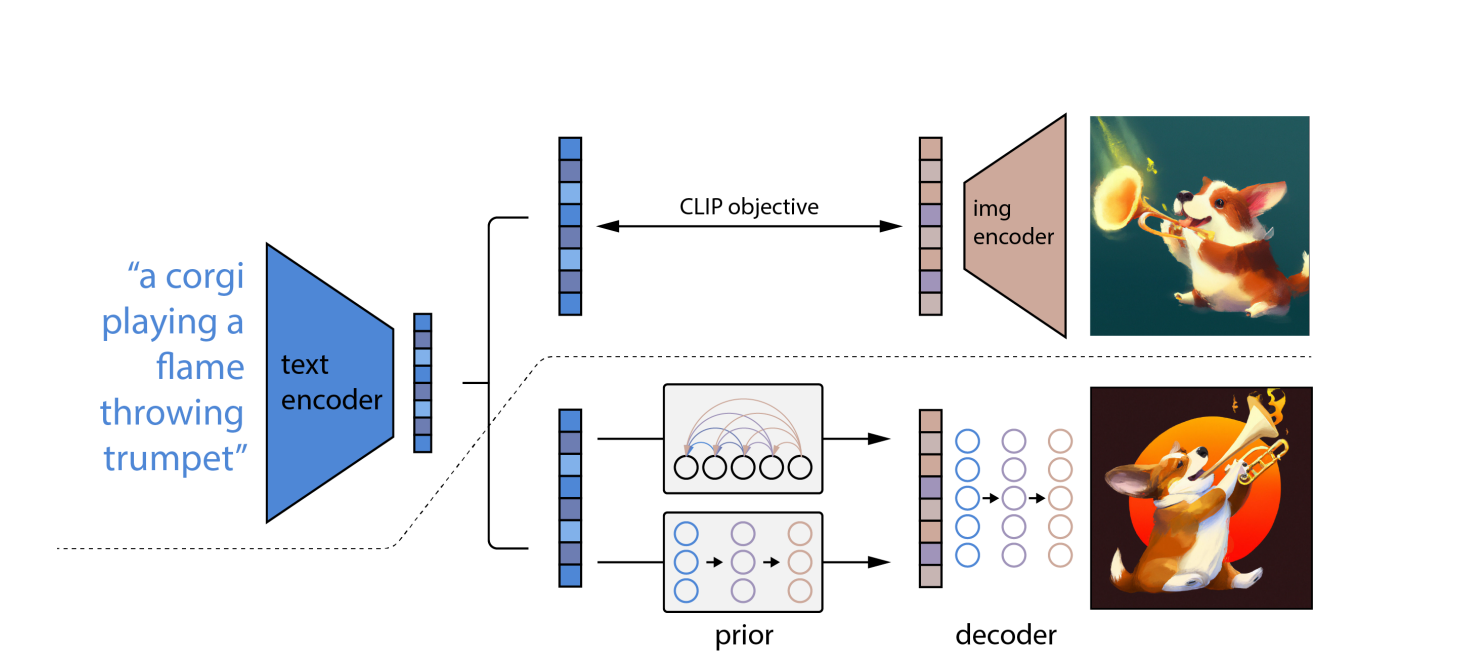
Utilizzo di OpenAI modello linguistico CLIP, che può collegare descrizioni testuali con fotografie, traduce innanzitutto il prompt scritto in una forma intermedia che incorpora le proprietà cruciali che un'immagine dovrebbe avere per corrispondere a quel prompt (secondo CLIP).
In secondo luogo, DALL-E 2 crea una compatibilità CLIP immagine utilizzando un modello di diffusione, che è una rete neurale.
Sulle foto distorte con pixel casuali, vengono appresi i modelli di diffusione. Imparano come ripristinare la forma originale delle foto. I modelli di diffusione possono produrre immagini sintetiche di alta qualità, soprattutto se utilizzati insieme a un approccio guida che privilegia l'accuratezza rispetto alla diversità.
Di conseguenza, il modello di diffusione prende i pixel casuali e usa CLIP per convertirli in una nuova immagine che corrisponda alla parola prompt. Grazie al concetto di diffusione, DALL-E 2 può produrre immagini ad alta risoluzione più velocemente di DALL-E.
Caso d'uso DALL.E 2
Negli ultimi venti anni, visione computerizzata la tecnologia è progredita da una semplice nozione a un importante passo avanti. Nonostante questi progressi, i modelli di riconoscimento di immagini e oggetti devono ancora affrontare ostacoli significativi nella vita di tutti i giorni. L'assenza di set di dati è uno degli svantaggi più significativi del riconoscimento delle immagini e della visione artificiale. Poiché vi è una carenza di dati da entrambe le parti, addestrare i modelli di riconoscimento delle immagini per fornire risultati accurati al 100% è quasi difficile.
Fortunatamente, il nuovo modello di apprendimento automatico di OpenAI può colmare il divario tecnologico. DALLE 2 è in grado di generare immagini straordinarie basate su descrizioni testuali. Questa produzione di immagini false può fornire dati ai modelli di riconoscimento delle immagini in base ai loro requisiti. L'assenza di dati è un ostacolo significativo per l'identificazione di oggetti e immagini.
Nell'era digitale, i set di dati sono onnipresenti, ma stiamo ancora cercando scorciatoie per alimentare il modello di intelligenza artificiale, in modo che possa fornire buoni risultati. Tuttavia, non è semplice addestrare un modello di riconoscimento delle immagini. Richiede un gran numero di set di dati con piccole differenze, che potremmo non essere stati in grado di recuperare semplicemente.
Allora, qual è la risposta: la risposta è DALLE 2. Il generatore di immagini OpenAI, con la sua capacità di produrre immagini da testi e modificare quelli esistenti, può aiutare a colmare il divario. Ciò aiuterà nella generazione di dati di addestramento aggiuntivi riducendo al contempo la quantità di etichettatura umana richiesta. Nonostante il vantaggio significativo, dovresti essere consapevole delle produzioni di immagini fraudolente e delle immagini che escludono l'inclusione. Ciò potrebbe portare a metodi di rilevamento delle immagini che producono risultati distorti.
Limiti
DALL.E 2 potrebbe avere un'influenza dannosa se cade nelle mani sbagliate, secondo OpenAI. Nel mondo odierno di deep fake, il modello potrebbe essere facilmente utilizzato per diffondere informazioni false o immagini razziste, motivo per cui OpenAI consente agli sviluppatori di utilizzare DALL.2 solo su invito. La modella deve rispettare una rigorosa restrizione sui contenuti per tutti i suggerimenti che riceve.
Per escludere la possibilità di DALL.E 2 di creare immagini ostili o violente, il set di dati è stato creato senza armi mortali. Sebbene OpenAI abbia dichiarato che prevede di trasformarla in un'API in futuro, nel caso di DALL.E 2, è disposta a procedere con cautela.
Conclusione
DALL-E 2 è un'altra interessante scoperta della ricerca OpenAI che apre le porte a nuove applicazioni.
Un esempio è la creazione di enormi set di dati per soddisfare uno dei principali colli di bottiglia della visione artificiale: i dati. Mentre il caso economico per molte app basate su DALL-E sarà determinato dal prezzo e dalle politiche che OpenAI stabilisce per i suoi utenti API, tutte senza dubbio faranno avanzare la produzione di immagini.





Lascia un Commento