Sommario[Nascondere][Spettacolo]
Per raccogliere informazioni dai siti Web per analisi, ricerche o obiettivi di marketing, il web scraping è una tecnica cruciale. Fortunatamente esistono numerosi strumenti che supportano sia browser headless che headful, entrambi utili per il web scraping.
I browser headful sono dotati di un'interfaccia utente grafica (GUI), mentre i browser headful no. Queste tecnologie possono estrarre dati sia manualmente che automaticamente dalle pagine Web, il che le rende molto vantaggiose.
Quando si gestiscono molti dati, i browser headless sono l'opzione migliore. Per automatizzare il processo di estrazione dei dati, avrai bisogno di questi strumenti, che ti faranno risparmiare un sacco di tempo e lavoro.
Inoltre, ti aiutano a migliorare la precisione e l'efficacia dell'estrazione dei dati, il che potrebbe portare a risultati complessivamente più fruttuosi.
Questi strumenti possono anche aiutare a ridurre la possibilità che si verifichino errori durante il copia e incolla manuale dei dati perché hanno la capacità di estrarre i dati in modo organizzato.
Detto semplicemente, è impossibile lavorare senza strumenti che supportino sia browser headless che headful se sei impegnato nel web scraping.
In questo articolo, esamineremo i migliori browser headless e headful per il web scraping.
1. Dati luminosi
Bright Data è un programma di web scraping che offre scelte per la raccolta di dati per aziende e privati. A differenza dei precedenti sistemi di scraping online, Bright Data è precaricato con un numero di browser ma funziona come un browser headless.
Anche se funziona come un browser senza testa sul back-end, ciò indica che gli utenti possono interagire con esso tramite un'interfaccia utente grafica (GUI), rendendolo più accessibile e intuitivo.
Questa funzionalità sarà particolarmente utile per coloro che non sanno molto di codifica o desiderano un approccio più semplice al web scraping. Gli utenti possono navigare rapidamente in siti Web complessi con interazioni simili a quelle umane grazie al browser headful di Bright Data.
Per mantenerti anonimo e sconosciuto, fornisce anche funzionalità all'avanguardia come la rotazione IP, l'impronta digitale del browser e la contraffazione dell'agente utente. Con l'uso dell'intelligenza artificiale, Scraping Browser sarà in grado di andare oltre anche le più avanzate protezioni di rilevamento dei bot.
In effetti, Scraping Browser è così sofisticato che può persino simulare le azioni del browser di un vero utente, fornendoti risultati più positivi e dati precisi.
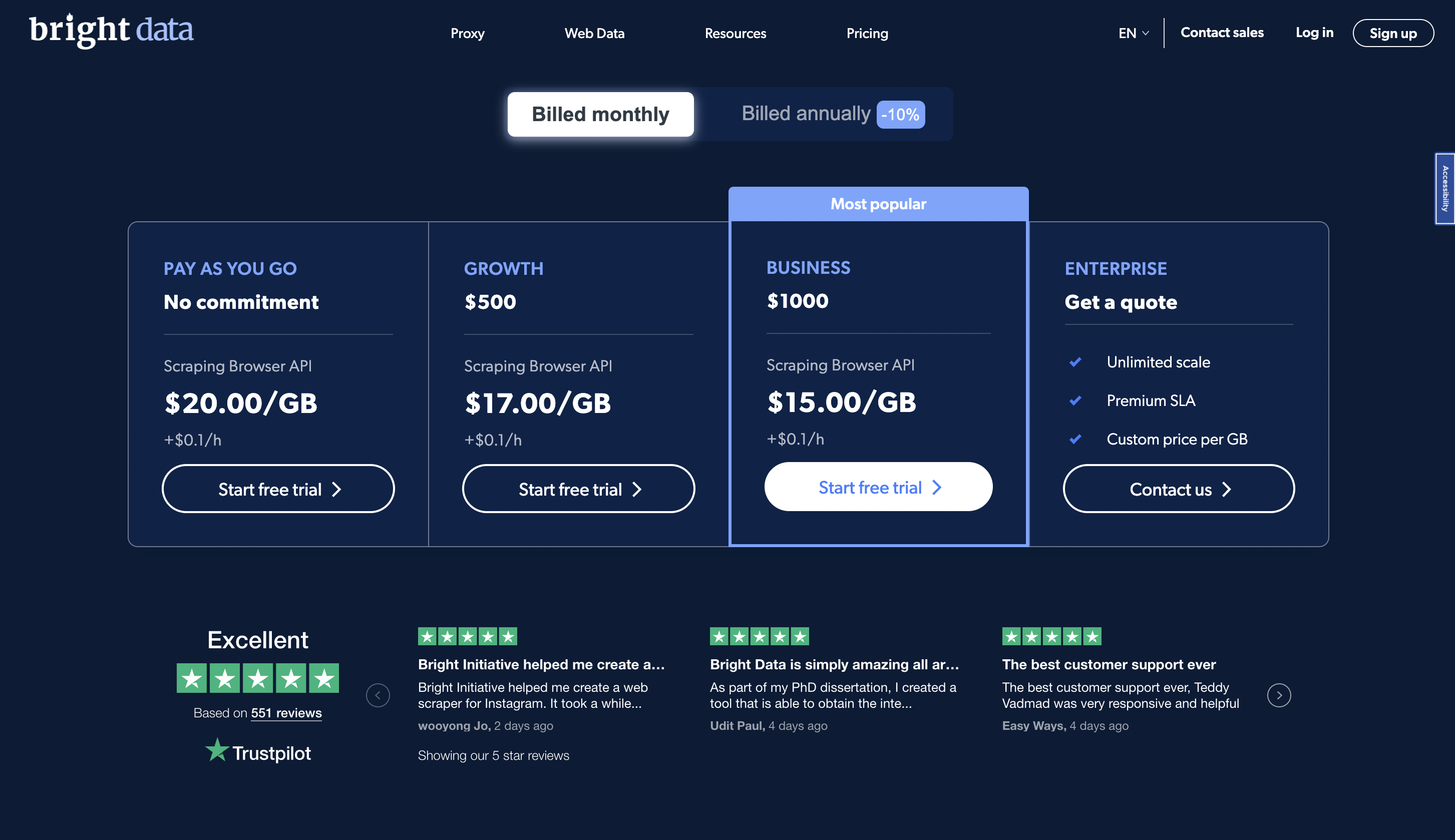
Prezzi
Puoi provare la piattaforma gratuitamente e i prezzi premium partono da $ 20 / GB in un piano pay-as-you-go.
2. Zite
In qualità di fornitore di strumenti di scraping online, Zyte, precedentemente noto come Scrapinghub, consente alle aziende di acquisire e analizzare i dati Internet su larga scala.
La piattaforma di scraping online di Zyte è progettata per gestire anche i siti Web più complicati e dinamici e include una varietà di funzionalità all'avanguardia come la rotazione automatica dell'IP, l'impronta digitale del browser e lo spoofing dell'agente utente per garantire che le tue operazioni di scraping rimangano private e inosservate.
Il fatto che la piattaforma di web scraping di Zyte supporti sia le modalità di navigazione headless che headful è uno dei suoi vantaggi distintivi. Il browser funziona in modalità headless in background senza un'interfaccia utente grafica, il che ne aumenta l'efficienza per operazioni di scraping estese.
Tuttavia, il browser funziona con una GUI in modalità headful, che potrebbe essere vantaggiosa quando è necessario estrarre dati da siti Web con interfacce utente complesse.
Inoltre, poiché la piattaforma di Zyte si basa sulla base Scrapy gratuita e open source, può essere adattata per soddisfare le tue esigenze specifiche ed è estremamente configurabile. Puoi recuperare rapidamente e semplicemente i dati che desideri utilizzando Zyte, offrendoti un vantaggio competitivo nella tua attività.
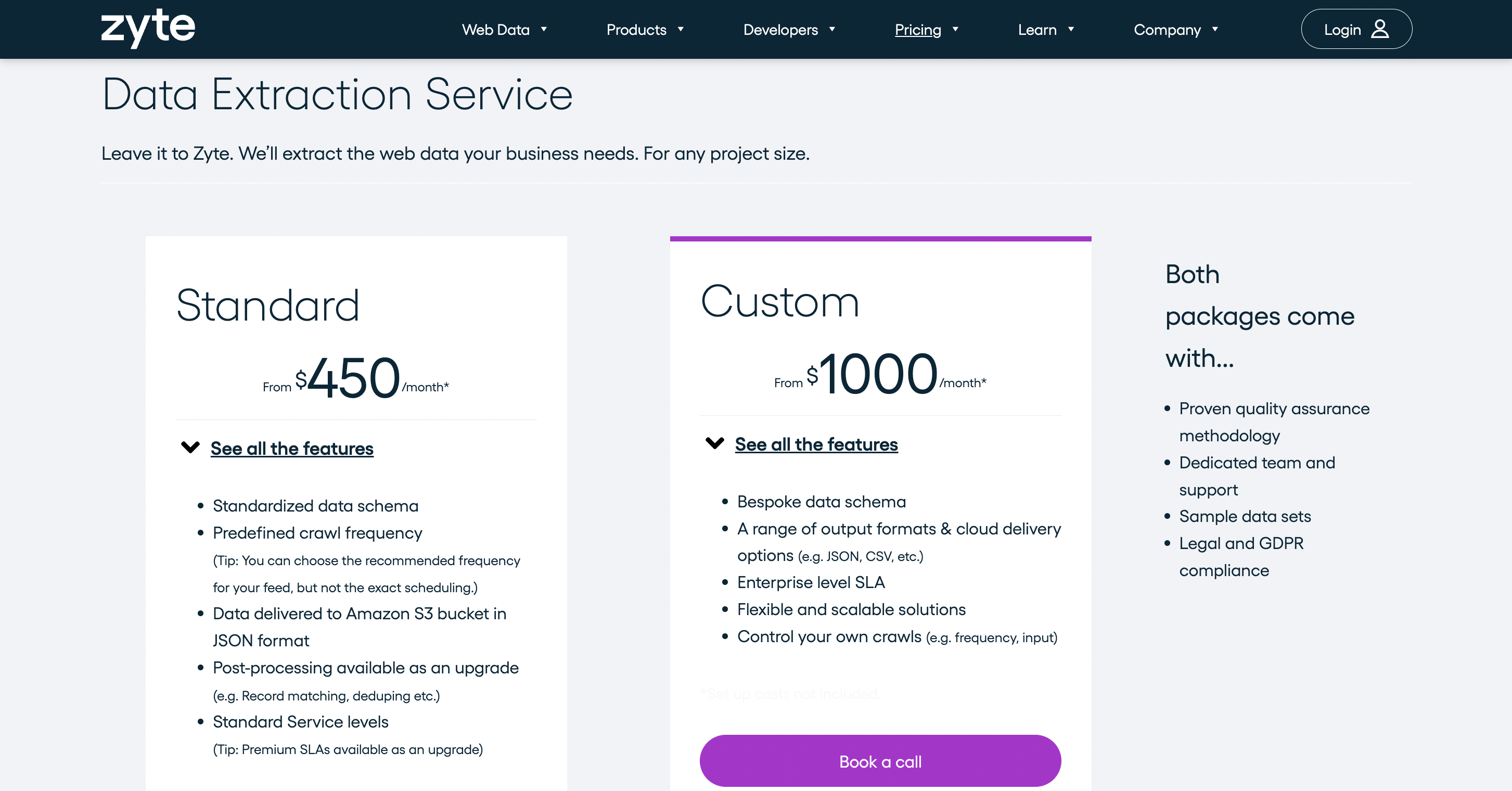
Prezzi
Offre più piani tariffari e addebita $ 450 al mese per il servizio di estrazione dei dati.
3. Octoparse
Puoi raccogliere dati dalle pagine Web senza scrivere alcun codice con Octoparse, un'applicazione di web scraping basata su cloud. Chiunque desideri raschiare testo, foto o video può sceglierli con facilità grazie all'interfaccia intuitiva.
Octoparse è uno strumento flessibile che supporta sia la navigazione headless che headful, è l'opzione migliore per progetti di web scraping di qualsiasi dimensione e complessità. Essere in grado di eseguire lo scraping di pagine Web dinamiche e interattive, che può essere difficile per molti altri programmi di scraping Web, è una delle sue caratteristiche più forti.
Puoi creare complessi processi di scraping con numerose fasi, istruzioni condizionali e cicli, aumentando la flessibilità e la personalizzazione dello scraping. Excel, CSV e SQL sono solo alcuni dei formati di esportazione forniti da Octoparse, semplificando l'utilizzo dei dati estratti in altri programmi.
Inoltre, Octoparse presenta un pool di proxy integrato che garantisce lo scraping anonimo e aiuta a evitare il divieto IP.
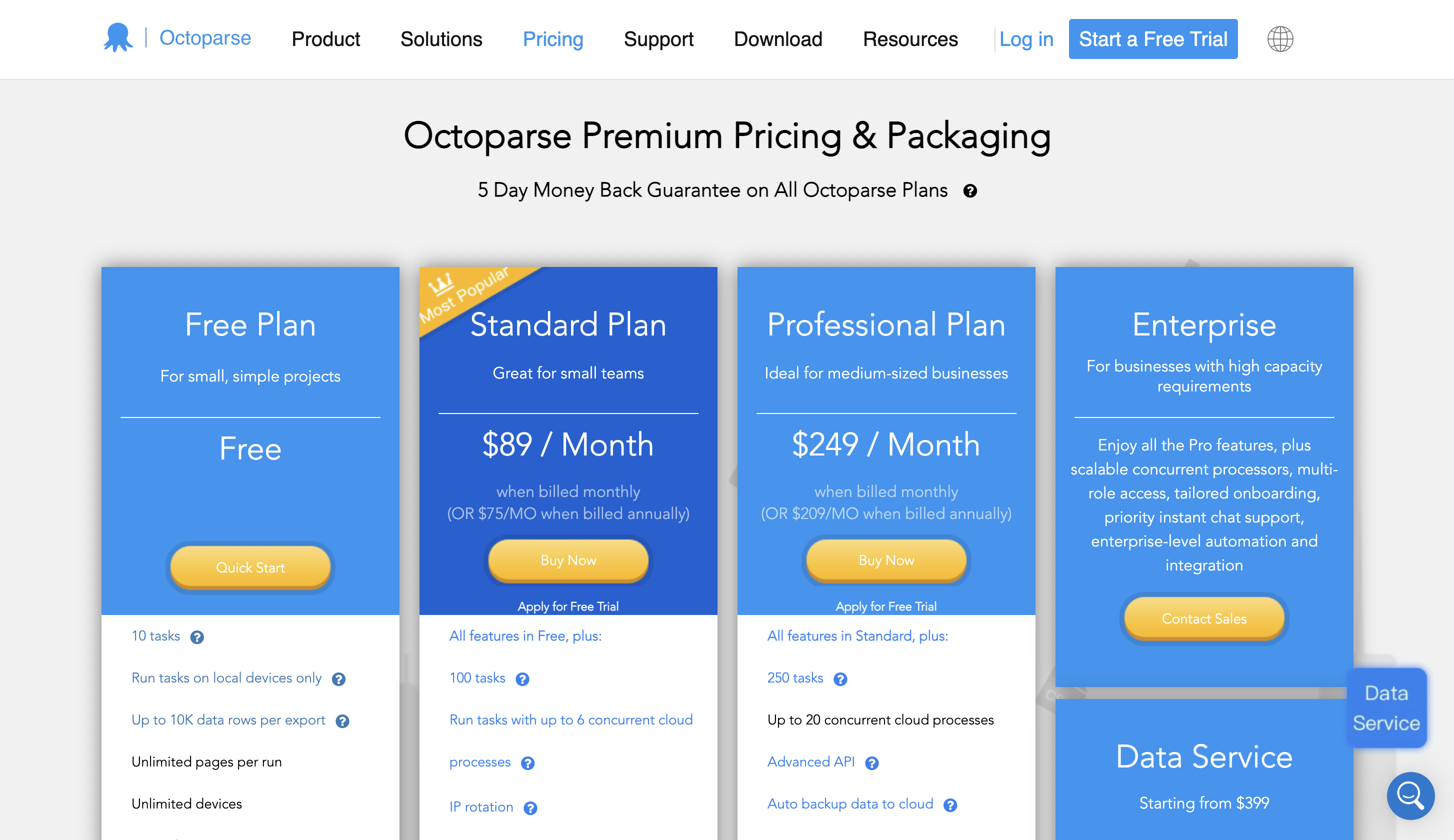
Prezzi
Puoi iniziare a usarlo gratuitamente e il prezzo premium parte da $ 89 al mese.
4. Apifica
Apify è una piattaforma all-in-one di web scraping e automazione che offre una varietà di potenti funzionalità. Supporta sia i browser headless che headful e ha un'interfaccia utente intuitiva che rende semplice anche per gli utenti non tecnici la creazione di attività di scraping.
La capacità di Apify di gestire lavori di scraping difficili, il supporto per diverse lingue e il ridimensionamento per gestire progetti di scraping su larga scala sono alcune delle sue migliori caratteristiche.
Inoltre, Apify fornisce l'accesso a un vasto mercato di scraper già pronti che possono essere rapidamente personalizzati per soddisfare le tue esigenze specifiche.
Con il suo supporto per i browser senza testa, Apify può navigare in interfacce utente impegnative e raccogliere dati da siti Web dinamici estraendo informazioni in modo rapido ed efficiente da enormi volumi di dati.
Apify è uno strumento utile per una varietà di applicazioni di scraping online, tra cui generazione di lead, analisi della concorrenza, ricerche di mercato e aggregazione di contenuti.
Apify aumenta la precisione e l'efficienza risparmiando tempo e fatica automatizzando il processo di estrazione dei dati. È uno strumento potente sia per utenti tecnici che non tecnici grazie alla sua funzionalità e al design intuitivo.
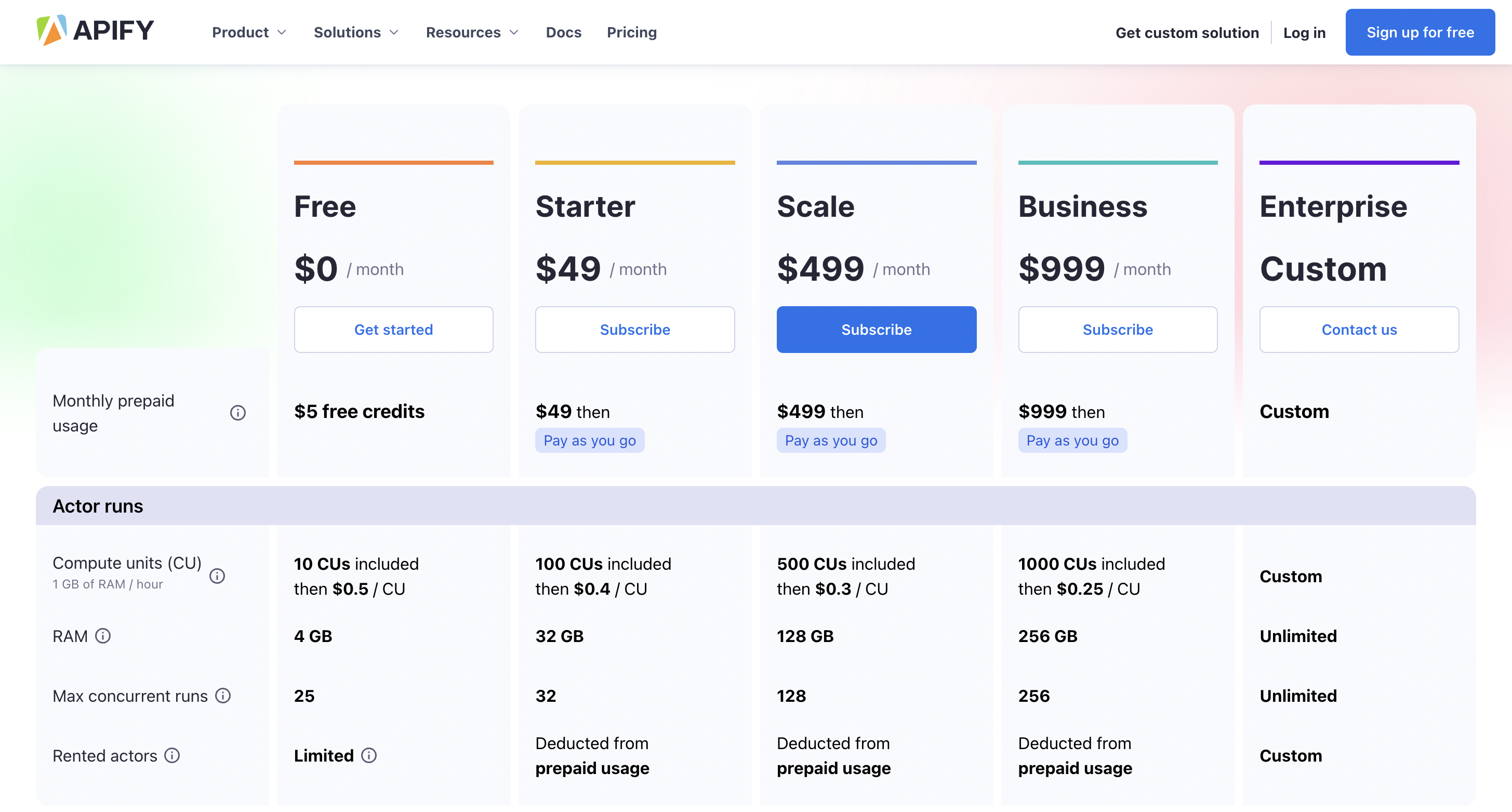
Prezzi
Puoi iniziare a usarlo gratuitamente e il prezzo premium parte da $ 49 al mese.
5. RaschiareApe
L'eccezionale applicazione di scraping online ScrapingBee semplifica l'automazione del processo di estrazione dei dati dai siti Web.
Le sue capacità, come quelle per la gestione del rendering JavaScript, la risoluzione CAPTCHA e la rotazione user-agent, consentono di aggirare le difese anti-scraping dei siti web. rendendolo quindi un'ottima opzione per le attività di web scraping.
Gli utenti hanno un grande grado di libertà con questo strumento perché funziona sia con browser headless che headful. È importante sottolineare che ScrapingBee utilizza browser headless per impostazione predefinita, il che è perfetto per il recupero automatico di enormi volumi di dati.
Per interagire con siti Web dotati di un'interfaccia complessa, gli utenti potrebbero passare a browser headful. Per garantire un'efficace estrazione dei dati, ScrapingBee mantiene anche un pool di proxy geolocalizzati che vengono regolarmente controllati e modificati.
Gli utenti possono ridurre il tempo e lo sforzo durante il web scraping utilizzando ScrapingBee come browser headless o headful pur garantendo la correttezza e la completezza dei dati recuperati. Ha anche molte funzioni utili, come la formattazione dei dati, la rotazione proxy e la connettività API, che lo rendono uno strumento utile sia per le aziende che per gli studenti.
Prezzi
Il prezzo premium parte da $ 49 al mese.
6. ParseHub
Senza la necessità di competenze tecniche, gli utenti possono raccogliere dati dai siti Web utilizzando l'applicazione di web scraping ParseHub. Una delle sue più grandi caratteristiche è quanto sia facile da usare; gli utenti possono scegliere i dati che desiderano raschiare semplicemente facendo clic sugli elementi.
Inoltre, ha la capacità di riconoscere automaticamente l'impaginazione, rendendo semplice per gli utenti raccogliere informazioni da più pagine. Per raccogliere dati da siti Web con interfacce utente semplici o complicate, ParseHub supporta sia browser headless che headful.
Inoltre, fornisce la rotazione automatica dell'IP, rendendo più difficile per i siti Web identificare e vietare l'attività di scraping. ParseHub garantisce che i dati vengano estratti in modo organizzato con l'aiuto delle sue ampie capacità di formattazione dei dati, semplificando l'analisi e l'integrazione del sistema.
Inoltre, ParseHub ha una modalità intelligente che riconosce e raccoglie automaticamente informazioni da siti Web simili. ParseHub può riconoscere e raccogliere dati da siti Web con strutture simili, come i siti Web di e-commerce, utilizzando intelligenza artificiale (AI). Questa funzione aumenta la precisione e la produttività richiedendo meno sforzi e risparmiando tempo.
Prezzi
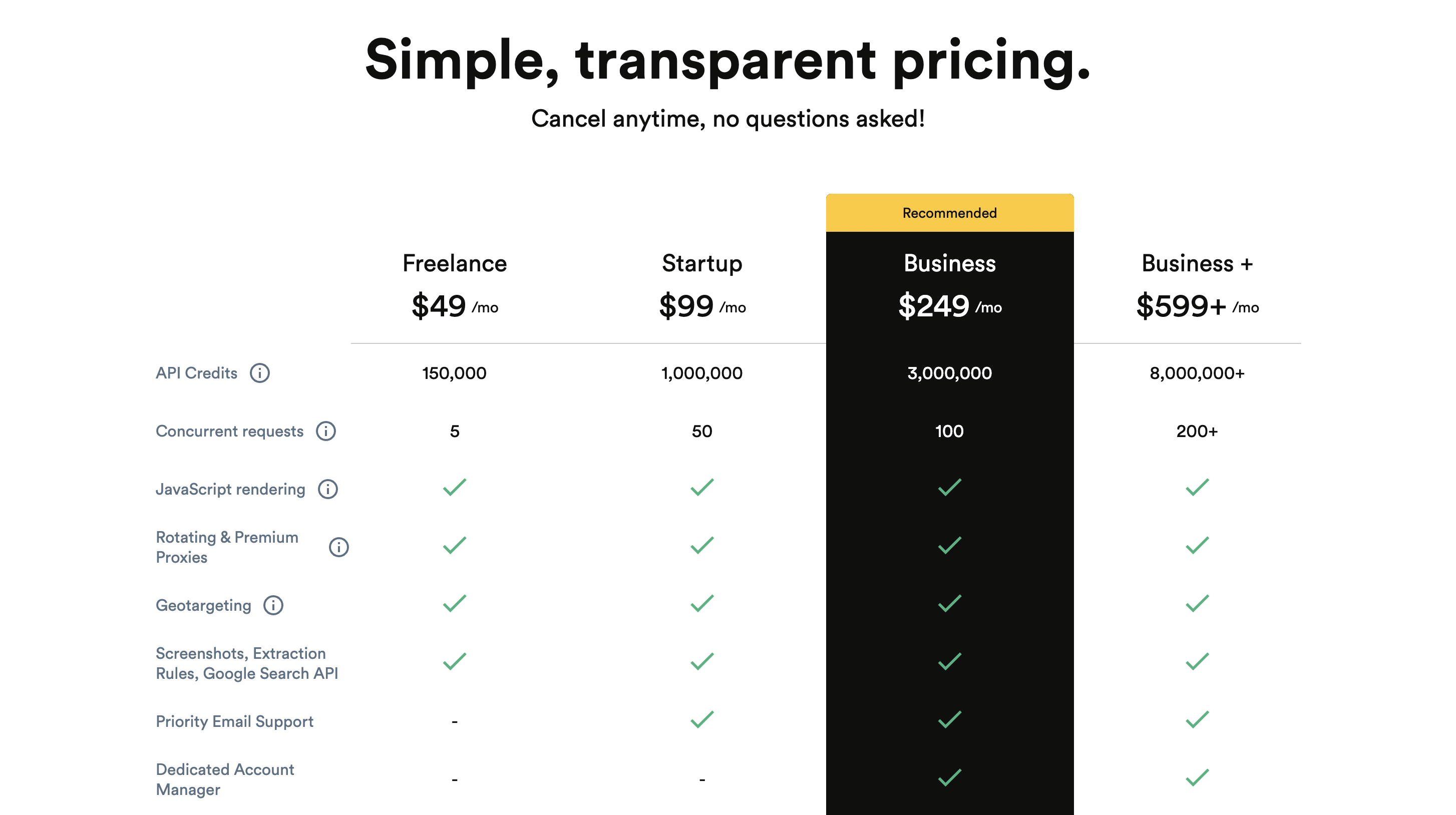
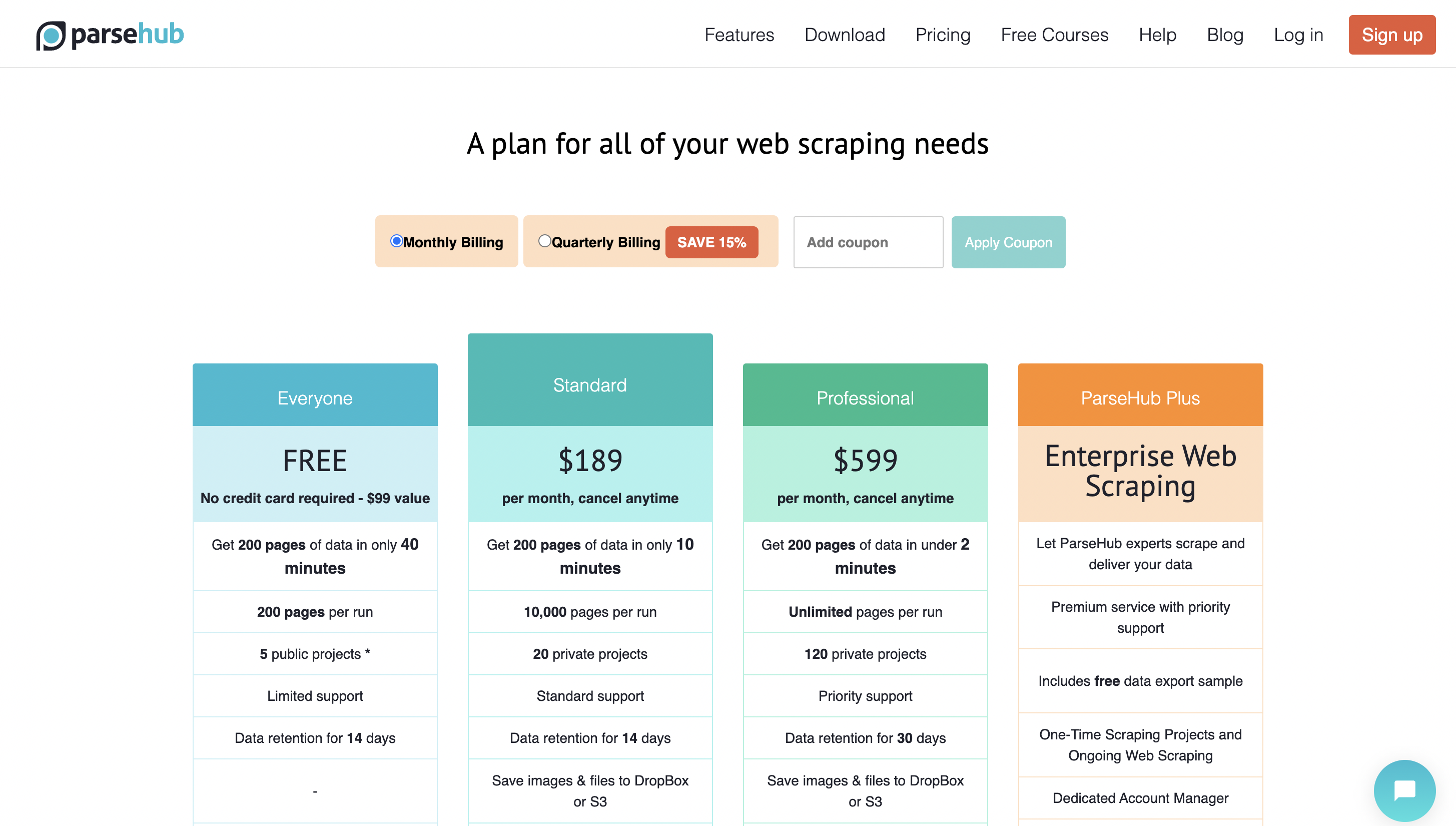
Puoi iniziare a usarlo gratuitamente e il prezzo premium parte da $ 189 al mese.
7. WebHarvy
WebHarvy è un potente strumento di scraping online che consente alle organizzazioni di raccogliere dati dai siti Web in modo rapido, accurato ed efficiente. È creato per raccogliere informazioni da molti siti Web, inclusi motori di ricerca, social media, siti di e-commerce e directory.
Senza alcuna precedente esperienza di codifica, gli utenti possono esplorare e creare facilmente lavori di scraping grazie alla sua interfaccia intuitiva. Una delle maggiori caratteristiche di WebHarvy è la sua capacità di recuperare dati da pagine Web alimentate da JavaScript e AJAX a cui altri strumenti di scraping potrebbero non essere in grado di accedervi.
Inoltre, offre un'interfaccia Point and Click che semplifica la scelta delle informazioni da una pagina Web che desideri raschiare. WebHarvy ha modalità di navigazione headless e headful. Per uno scraping dei dati più rapido ed efficace, può funzionare in modalità headless.
La modalità Headful è utile quando si lavora con siti Web complicati che richiedono l'input dell'utente. Può anche navigare tra numerose pagine e compilare moduli, utile quando si estraggono dati da siti Web con più pagine.
Prezzi
Il prezzo premium parte da $ 129 per una licenza per utente singolo.

8. Kit flusso di dati
Utilizzando Dataflow Kit, un robusto strumento di scraping online, i dati possono essere raccolti e analizzati da una varietà di siti Web, tra cui il social networking siti, motori di ricerca, siti di e-commerce e siti di notizie. Una delle sue migliori caratteristiche è la sua capacità di raccogliere dati in modo rapido ed efficiente da siti web complicati e dinamici.
È ideale per lo scraping di siti Web a cui è difficile accedere utilizzando altri metodi poiché è così semplice da usare. Un browser headless e un browser headful funzionano entrambi con Dataflow Kit. Funzionalità avanzate come la rotazione proxy e user-agent, l'elusione del blocco IP e il rilevamento anti-bot sono fornite per garantire uno scraping efficace.
Inoltre, offre un'interfaccia intuitiva che consente ai clienti di creare, pianificare e gestire le proprie attività di scraping senza alcuna esperienza di programmazione. Per le applicazioni di web scraping su larga scala, il suo efficace motore scraper è una soluzione fantastica perché è ottimizzato per gestire i dati in modo rapido ed efficace.
I dati raschiati possono essere semplicemente esportati in una varietà di formati, inclusi CSV, JSON e XML, consentendoti di analizzarli e utilizzarli come meglio credi. Inoltre, Dataflow Kit offre una varietà di opzioni di interfaccia, tra cui API e Zapier, per aiutarti a semplificare il flusso di lavoro e automatizzare il processo di estrazione dei dati.
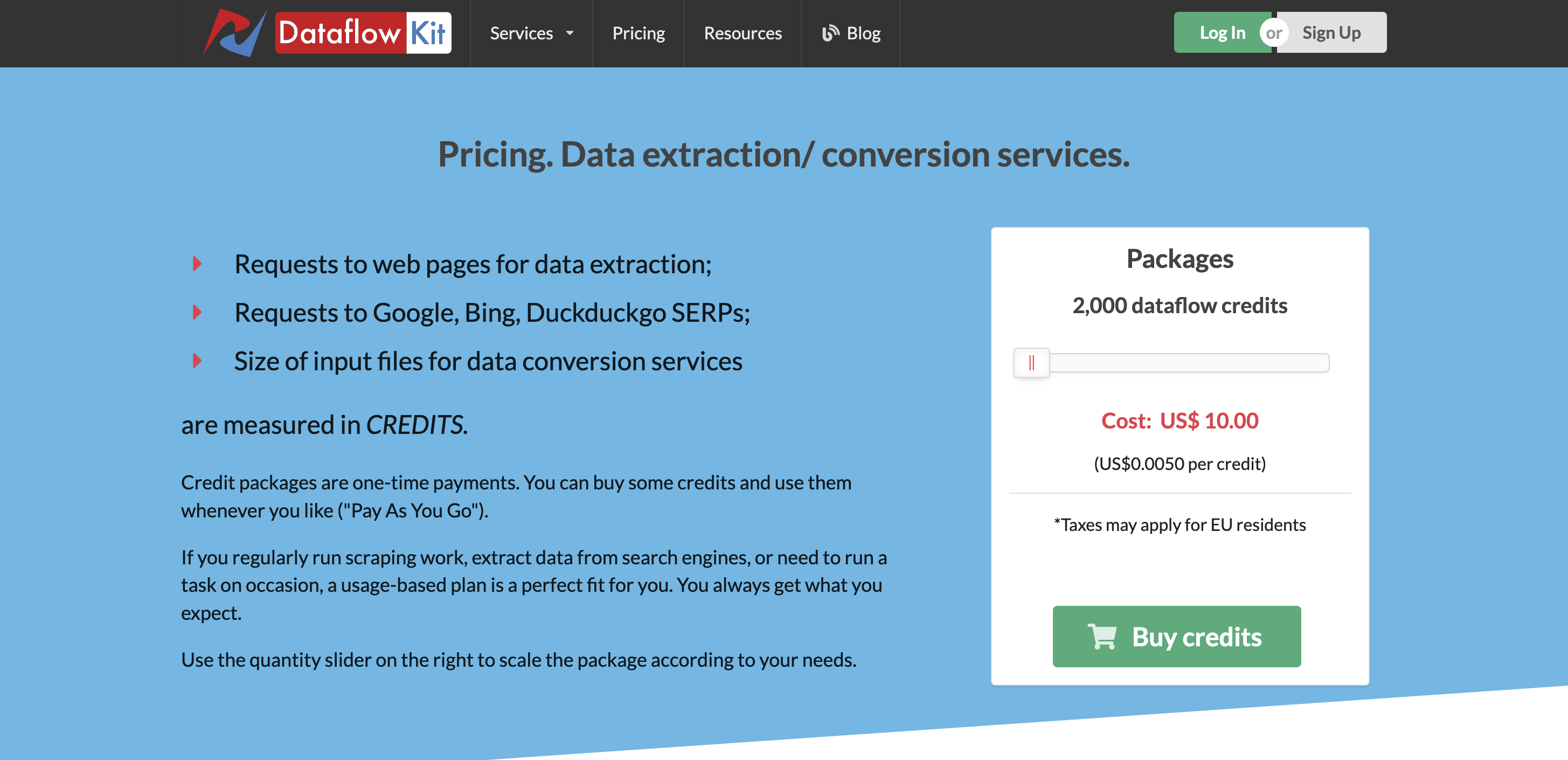
Prezzi
Il prezzo premium parte da $ 10 per 2000 crediti di flusso di dati, che puoi utilizzare in base alle tue esigenze.
9. Import.io
Con l'aiuto dello strumento di scraping Web basato su cloud Import.io, gli utenti possono estrarre dati dai siti Web senza alcuna esperienza di programmazione. La semplicità d'uso è una delle caratteristiche più allettanti di Import.io; tutto quello che devi fare è puntare e fare clic per trovare i dati che vuoi raschiare.
Gli utenti possono valutare i dati estratti in tempo reale grazie alle sue potenti funzionalità di visualizzazione. Import.io è un browser senza testa che imita un browser Web e si connette ai siti Web nello stesso modo in cui farebbe una persona, ma senza il requisito di un'interfaccia utente grafica.
Ciò migliora l'efficienza del web scraping e consente agli utenti di estrarre dati da siti Web dinamici che richiedono il coinvolgimento dell'utente per mostrare informazioni. Il suo estrattore basato sull'intelligenza artificiale consente agli utenti di estrarre i dati con pochi clic. L'estrattore può anche identificare modelli di dati ed estrarre dati comparabili da numerose fonti.
Gli utenti possono automatizzare i loro sforzi di scraping e ricevere aggiornamenti frequenti sui dati che desiderano con le sue funzionalità di pianificazione complete. Import.io semplifica l'utilizzo dei dati estratti in altre app consentendoti di collegarti a strumenti popolari come Fogli Google e Zapier.
Prezzi
I prezzi non sono elencati sul sito Web, si prega di parlarne con un esperto.
10 Dexi.io
L'estrazione dei dati è semplice con l'aiuto del robusto strumento di web scraping Dexi.io. È possibile raccogliere dati dai siti Web utilizzando questo strumento senza alcuna esperienza di codifica grazie alla sua interfaccia intuitiva e alle possibilità automatizzate.
Una delle sue migliori caratteristiche è la capacità di raccogliere e combinare dati da molte fonti, tra cui pagine Web, API e database. Grazie alla capacità di elaborazione parallela di Dexi.io, puoi raschiare in modo rapido ed efficace enormi volumi di dati.
Dexi.io ti offre la possibilità di selezionare l'alternativa migliore per le tue esigenze di scraping perché funziona sia come browser headless che come browser headful. Mentre l'opzione del browser headful ti consente di vedere e interagire con il sito Web come se stessi utilizzando un browser tipico, l'opzione del browser headless ti consente di raccogliere dati senza visualizzare la pagina in un browser.
Ciò semplifica la risoluzione di eventuali problemi di raschiatura e l'adeguamento della procedura di raschiatura alle proprie preferenze. Puoi esportare rapidamente i dati raccolti da Dexi.io in una varietà di formati, come CSV, JSON ed Excel, per ulteriori analisi o interazioni con altre applicazioni.
Inoltre, fornisce un cloud hosting affidabile e sicuro per i tuoi dati raschiati, garantendone la sicurezza e l'accessibilità.
Prezzi
Puoi provare la piattaforma con il suo piano di prova gratuito e contattare il team per i suoi prezzi.
Conclusione
In conclusione, sul mercato esistono diverse soluzioni di web scraping, ognuna con vantaggi e capacità specifici. Ci sono molte alternative di dati tra cui scegliere, che vanno da soluzioni all-in-one come Bright Data e ScrapingBee a strumenti più specializzati come Apify e ParseHub.
Questi sistemi hanno spesso funzionalità come la navigazione headless, la rotazione IP, lo spoofing dell'agente utente e il fingerprinting del browser per aumentare l'efficacia, l'affidabilità e la segretezza dello scraping online.
Gli strumenti di web scraping possono darti un accesso rapido e semplice a una grande quantità di informazioni, sia che tu sia un piccolo imprenditore che cerca di indagare sui tuoi concorrenti, un ricercatore che cerca dati per supportare il tuo lavoro o un analista di dati che cerca approfondimenti sul comportamento dei consumatori .
La possibilità di errori e incoerenze può essere ridotta mentre puoi potenzialmente risparmiare tempo e denaro automatizzando il processo di raccolta dei dati.





Lascia un Commento