Sommario[Nascondere][Spettacolo]
Il modo in cui comunichiamo con macchine e altri gadget è stato completamente trasformato dallo sviluppo del software di riconoscimento vocale AI.
Converte le parole pronunciate in testo stampato con incredibile precisione ed efficienza utilizzando algoritmi di intelligenza artificiale. Questa tecnologia ha applicazioni in molti settori, dall'assistenza sanitaria e al servizio clienti all'istruzione e all'intrattenimento.
Negli ultimi anni, c'è stato un enorme aumento della domanda di conversione da parlato a testo precisa ed efficace.
Sia le aziende che le persone stanno vedendo l'enorme utilità del software di riconoscimento vocale AI data la rapida crescita della tecnologia e la crescente dipendenza dalla comunicazione digitale.
Questa esigenza deriva dal desiderio di migliorare la produttività, semplificare le procedure e aumentare l'accessibilità per le persone con disabilità.
Al fine di conservare le cartelle cliniche dei pazienti e consentire un'efficace erogazione dell'assistenza sanitaria, la trascrizione accurata e tempestiva dei dettati medici è essenziale in settori come l'assistenza sanitaria.
Automatizzando il processo di trascrizione, eliminando la necessità di inserimento manuale dei dati e fornendo maggiore accuratezza e velocità, è emerso il software di riconoscimento vocale AI.
Inoltre, le divisioni del servizio clienti stanno utilizzando questa tecnologia per accelerare i tempi di risposta e fornire esperienze personalizzate.
Le aziende possono rilevare modelli, migliorare i loro servizi e fare scelte guidate dai dati trascrivendo le chiamate dei clienti e raccogliendo informazioni approfondite da queste interazioni.
Un altro settore che beneficia del software di riconoscimento vocale AI è l'istruzione poiché consente di creare strumenti didattici all'avanguardia.
È possibile promuovere un ambiente di apprendimento più dinamico e coinvolgente consentendo agli studenti di dettare i loro compiti o di interagire con gli istruttori virtuali tramite la voce.
Anche il settore dell'intrattenimento ha abbracciato la tecnologia di riconoscimento vocale AI, aprendo la strada a prodotti intelligenti ad attivazione vocale e assistenti virtuali che migliorano l'esperienza dell'utente.
Grazie ai comandi vocali per la riproduzione multimediale e ai motori di ricerca ad attivazione vocale, questa tecnologia rende facile e conveniente godersi l'intrattenimento.
In questo pezzo, esamineremo il miglior software di riconoscimento vocale AI.
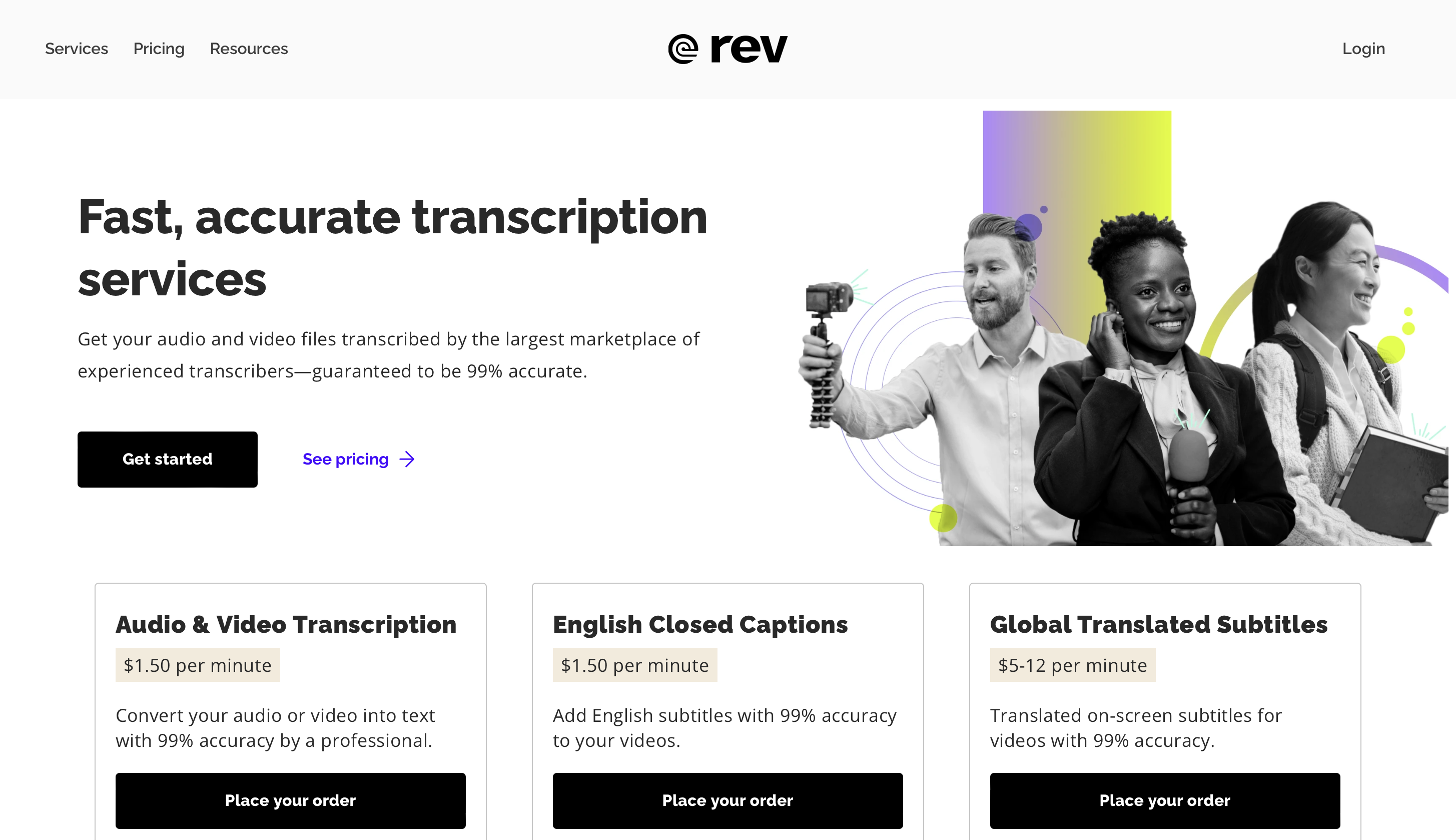
1. Rev
Rev è un programma di riconoscimento vocale basato su cloud che è diventato più popolare tra le aziende e le persone alla ricerca di servizi di trascrizione precisi ed efficaci per dati audio e video. L'uso di Rev di algoritmi AI all'avanguardia per la conversione da voce a testo lo rende unico.
Per convertire correttamente le parole pronunciate in testo scritto, questi complessi algoritmi sfruttano i punti di forza di machine learning e l'elaborazione del linguaggio naturale.
Un'ampia varietà di accenti, dialetti e lingue può essere riconosciuta e interpretata dagli algoritmi AI di Rev poiché sono stati addestrati su enormi volumi di dati.
Di conseguenza, Rev può fornire servizi di trascrizione estremamente accurati che possono anche essere personalizzati per soddisfare esigenze linguistiche specifiche. Il programma può gestire una varietà di tipi di file audio, inclusi podcast, conferenze, interviste e video.
Rev privilegia l'efficienza rispetto alla precisione, fornendo tempi di consegna rapidi senza sacrificare la qualità. Il programma è in grado di elaborare rapidamente enormi quantità di dati audio e video grazie al flusso di lavoro ottimizzato e all'infrastruttura scalabile.
La gamma dei servizi di trascrizione di Rev va oltre la semplice traduzione vocale in testo.
Inoltre, il programma offre scelte per la formattazione, l'identificazione del relatore e la marcatura temporale.
Il timestamp fornisce al testo trascritto un riferimento cronologico e l'identificazione del relatore facilita la distinzione tra partecipanti alla conversazione distinti.
Le scelte di formattazione offrono ai clienti la possibilità di adattare la presentazione e il layout della trascrizione in base alle proprie esigenze.
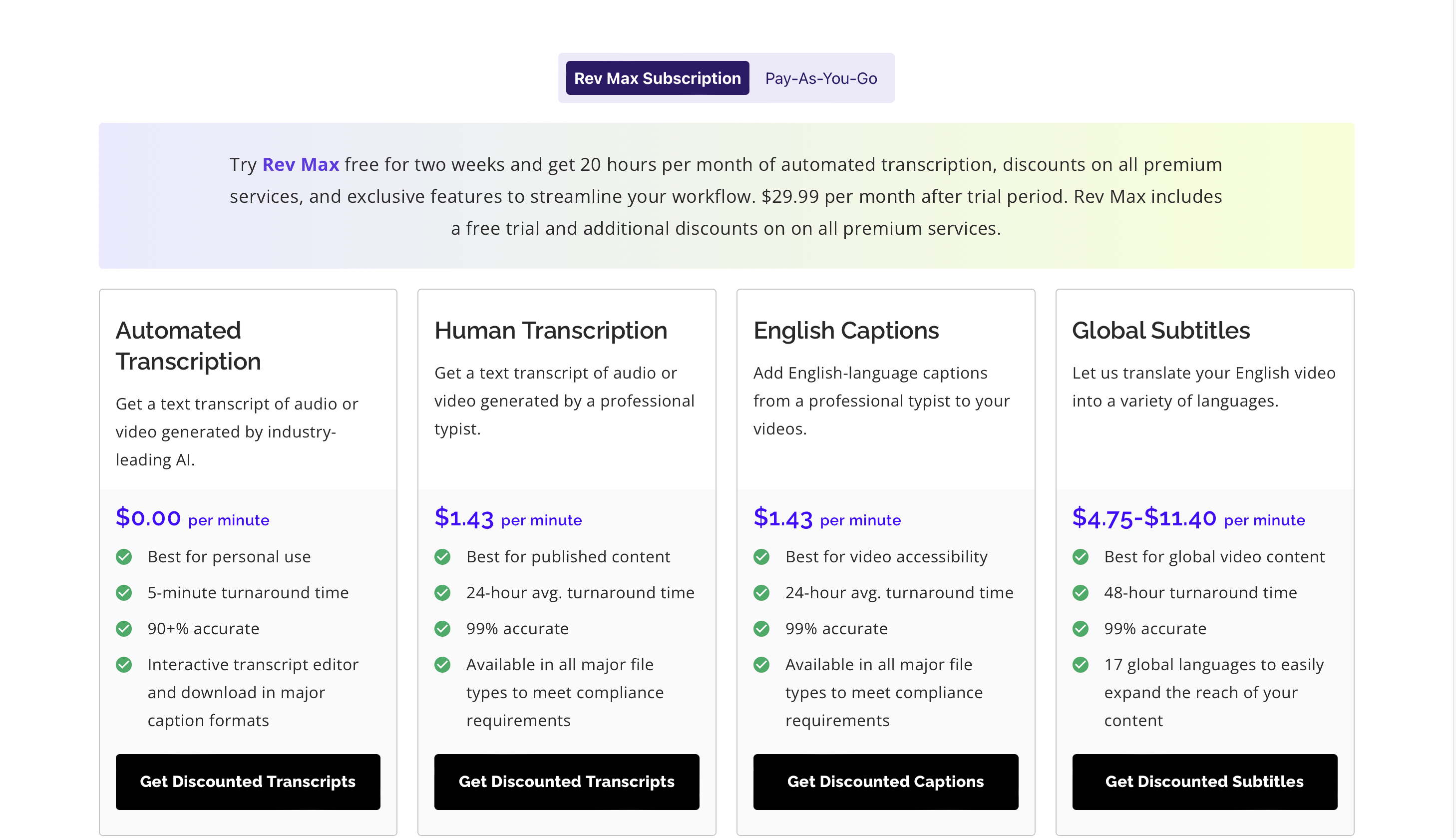
Prezzi
Puoi prova Rev Max gratis per 2 settimane e il prezzo premium parte da $ 29.99 al mese.
2. Nuance Drago Professionale
Nuance Dragon Professional è un software di riconoscimento vocale leader di mercato che fornisce un set completo di funzionalità e capacità per consentire ai professionisti di un'ampia varietà di settori.
Con le sue sofisticate funzioni di comando vocale, puoi utilizzare il computer a mani libere mentre navighi tra le app e dettami documenti, aumentando l'efficienza e la produttività. Il programma ha un livello eccezionale di accuratezza della trascrizione, quindi le parole pronunciate vengono convertite in modo affidabile in forma scritta.
Offrendo vocabolari specializzati e modelli linguistici, Nuance Dragon Professional soddisfa le esigenze di settori particolari. Con l'uso di dizionari specializzati e scelte di vocabolario, i professionisti in settori come la sanità, la legge e la finanza possono aumentare la produttività e produrre trascrizioni più accurate.
Inoltre, il programma è in grado di riconoscere diversi schemi vocali e dialetti grazie a profili vocali personalizzabili dall'utente.
Gli operatori sanitari possono registrare le note dei pazienti, i dati medici e le prescrizioni con notevole precisione utilizzando Nuance Dragon Professional nel settore sanitario, che alleggerisce l'onere amministrativo e migliora l'assistenza ai pazienti.
Le sue funzionalità di riconoscimento vocale possono essere utilizzate dagli operatori del diritto per preparare in modo rapido ed efficace atti giudiziari e creare appunti sui casi.
Il programma semplifica inoltre le procedure di documentazione nei settori bancario e assicurativo, consentendo agli esperti di comporre in modo rapido e preciso comunicazioni, reclami e rapporti.
Oltre alla semplice dettatura, le funzionalità avanzate di comando vocale del software consentono di utilizzare istruzioni vocali per eseguire istruzioni sofisticate, gestire programmi ed eseguire attività del computer. Le persone con problemi di mobilità o coloro che preferiscono il funzionamento a mani libere troveranno questa funzione particolarmente utile.
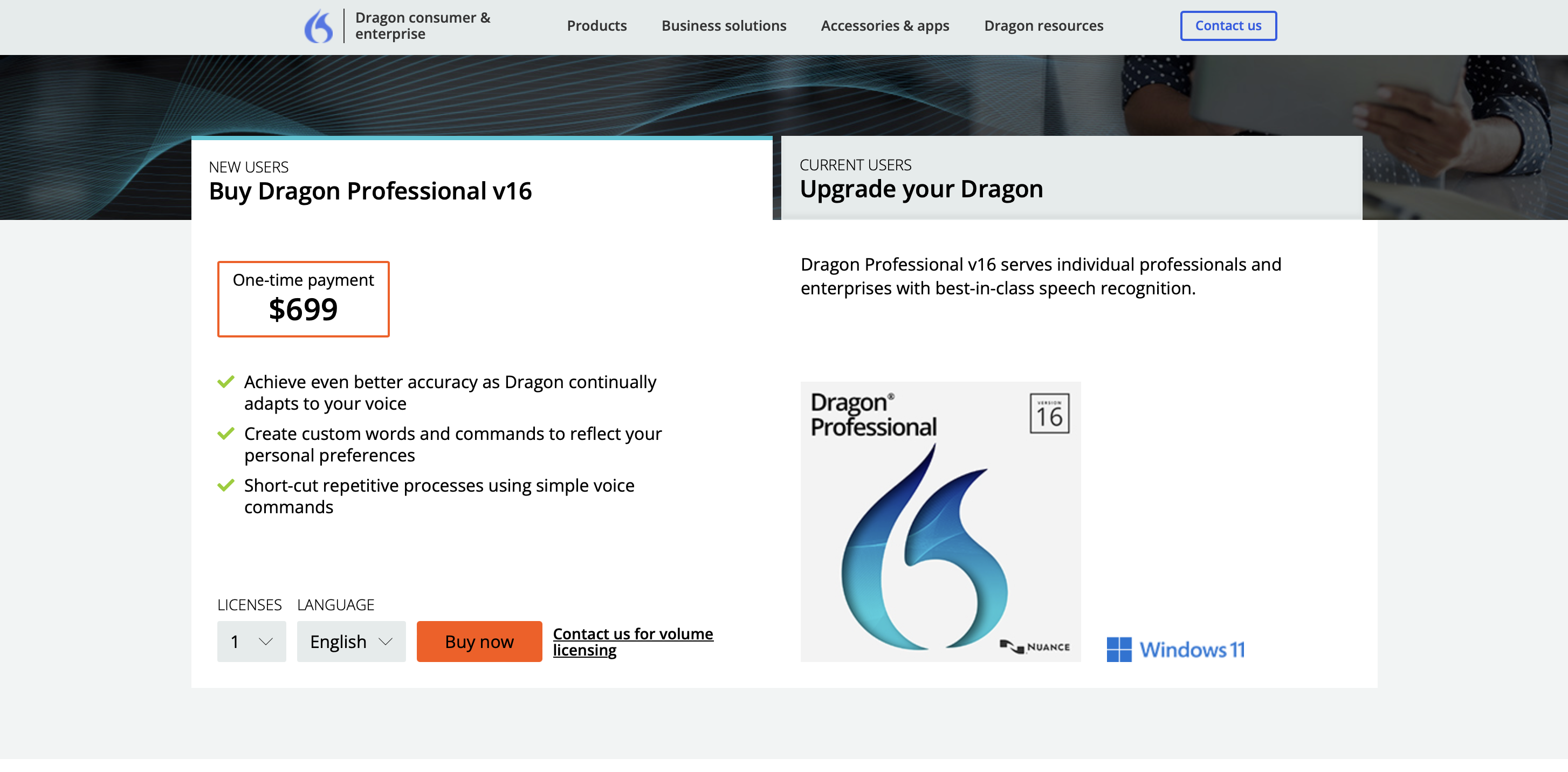
Prezzi
Il prezzo premium del software da acquistare è di $ 699.
3. Sintesi vocale di Google Cloud
Google Cloud Speech-to-Text è un noto programma di riconoscimento vocale AI con eccezionali poteri e competenza tecnologica.
È un'opzione ideale per le aziende e gli sviluppatori che cercano una conversione vocale precisa in testo perché è un componente di Google Cloud Platform e offre una gamma completa di funzionalità.
Una qualità unica del programma è la sua grande precisione, che utilizza sofisticati algoritmi di apprendimento automatico per convertire le parole pronunciate in testo scritto con straordinaria precisione.
Inoltre, Google Cloud Speech-to-Text offre un'ampia gamma di compatibilità linguistica, consentendoti di tradurre l'audio in una varietà di lingue, dialetti e accenti. È uno strumento utile per le multinazionali e le app che utilizzano diverse lingue grazie alla sua ampia copertura linguistica.
Il programma è appropriato per le applicazioni con un'elevata richiesta di trascrizione poiché può gestire rapidamente enormi quantità di dati audio utilizzando la potenza del cloud.
Grazie all'architettura basata su cloud di Google Cloud Speech-to-Text, gli sviluppatori possono integrarla facilmente con altri servizi e API di Google Cloud per creare app completamente basate sulla voce.
Il programma offre anche altre funzionalità che migliorano l'accuratezza e l'utilità della trascrizione, come la registrazione del relatore, la punteggiatura automatica e la comprensione contestuale.
Mentre la registrazione di un oratore consente di riconoscere e distinguere tra più oratori in una discussione, la punteggiatura automatica fornisce chiarezza e struttura all'output.
La comprensione contestuale aiuta nell'interpretazione e nella trascrizione dell'audio a seconda di particolari domini o gergo aziendale.
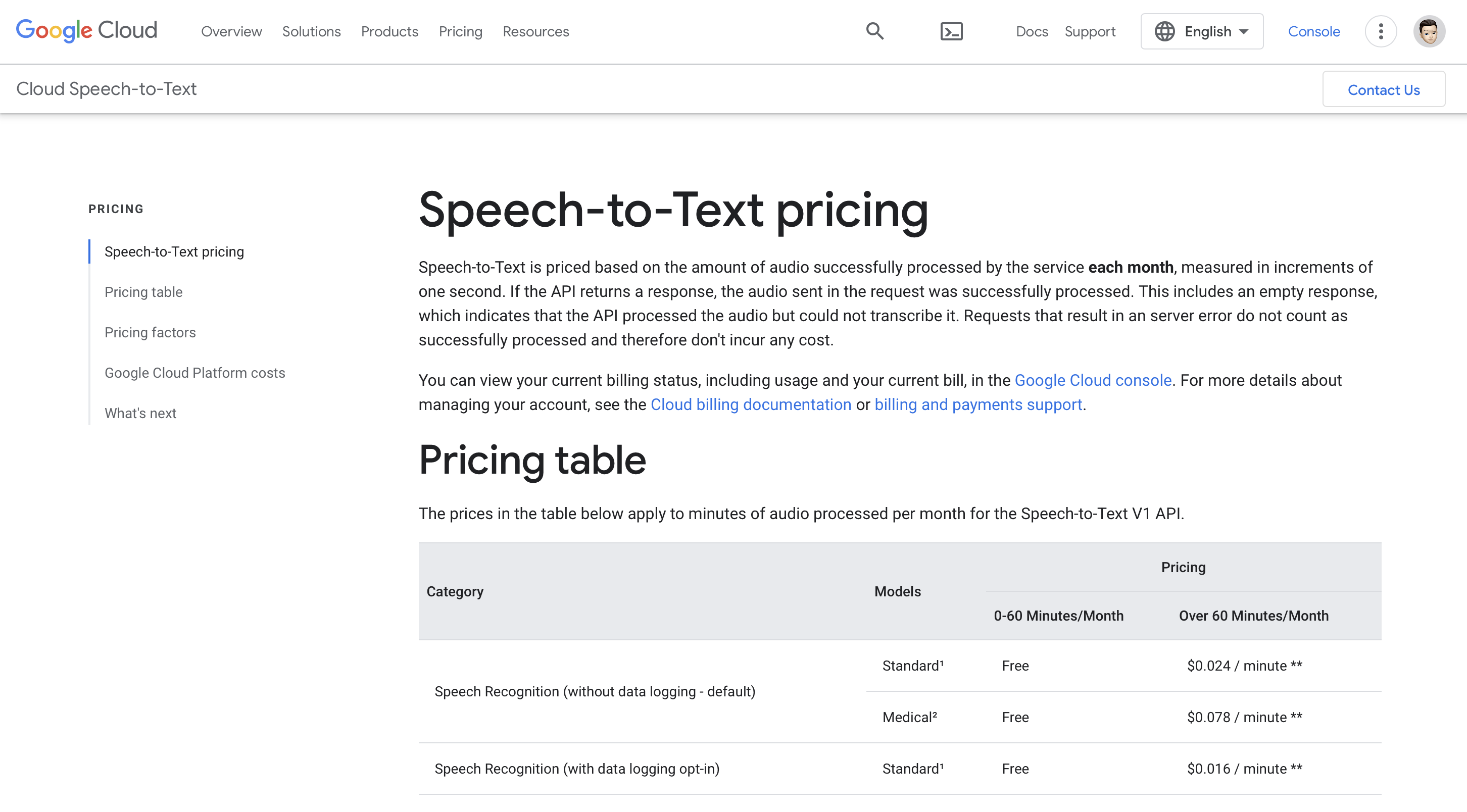
Prezzi
È gratuito da utilizzare per 0-60 minuti/mese e il prezzo premium inizia oltre 60 minuti/mese, ovvero $ 0.024/minuto.
4. Servizi vocali di Microsoft Azure
Microsoft Azure Speech Services è una rivoluzionaria tecnologia di riconoscimento vocale che ha trasformato le nostre interazioni con macchine e gadget. Le sue sofisticate capacità di trascrizione consentono di convertire le parole pronunciate in testo scritto con precisione ed efficienza.
Di conseguenza, le operazioni possono essere semplificate e l'accessibilità migliorata, consentendo alle organizzazioni e alle persone di ottenere informazioni approfondite dai dati audio. Va oltre il semplice riconoscimento vocale includendo funzionalità di comprensione del linguaggio naturale (NLU).
Può comprendere le intenzioni dell'utente e fornire risposte contestualmente più appropriate esaminando il contesto e il significato delle parole pronunciate. Semplificando la comunicazione con app e assistenti virtuali, questa capacità di comprensione del linguaggio naturale migliora l'esperienza dell'utente.
Inoltre, gli sviluppatori possono sviluppare app completamente guidate dalla voce con le possibilità di integrazione agevole di Microsoft Azure Speech Services con altri servizi e API di Azure.
Offre kit di sviluppo software (SDK) e API che consentono una semplice integrazione con applicazioni e sistemi già esistenti e supporta numerosi linguaggi di programmazione.
Microsoft Azure Speech Services offre funzionalità tra cui sintesi vocale, riconoscimento del parlatore, traduzione linguistica e comprensione del linguaggio naturale oltre alla trascrizione e all'NLU.
Un livello più elevato di sicurezza e personalizzazione è offerto attraverso il riconoscimento del relatore, che consente di identificare e convalidare determinati relatori.
La comunicazione multilingue è facilitata dalle tecnologie di traduzione linguistica che consentono la traduzione vocale in tempo reale in molte lingue.
Inoltre, la sintesi vocale migliora la qualità delle app e dei servizi basati sulla voce producendo un parlato che suona come il parlato umano.
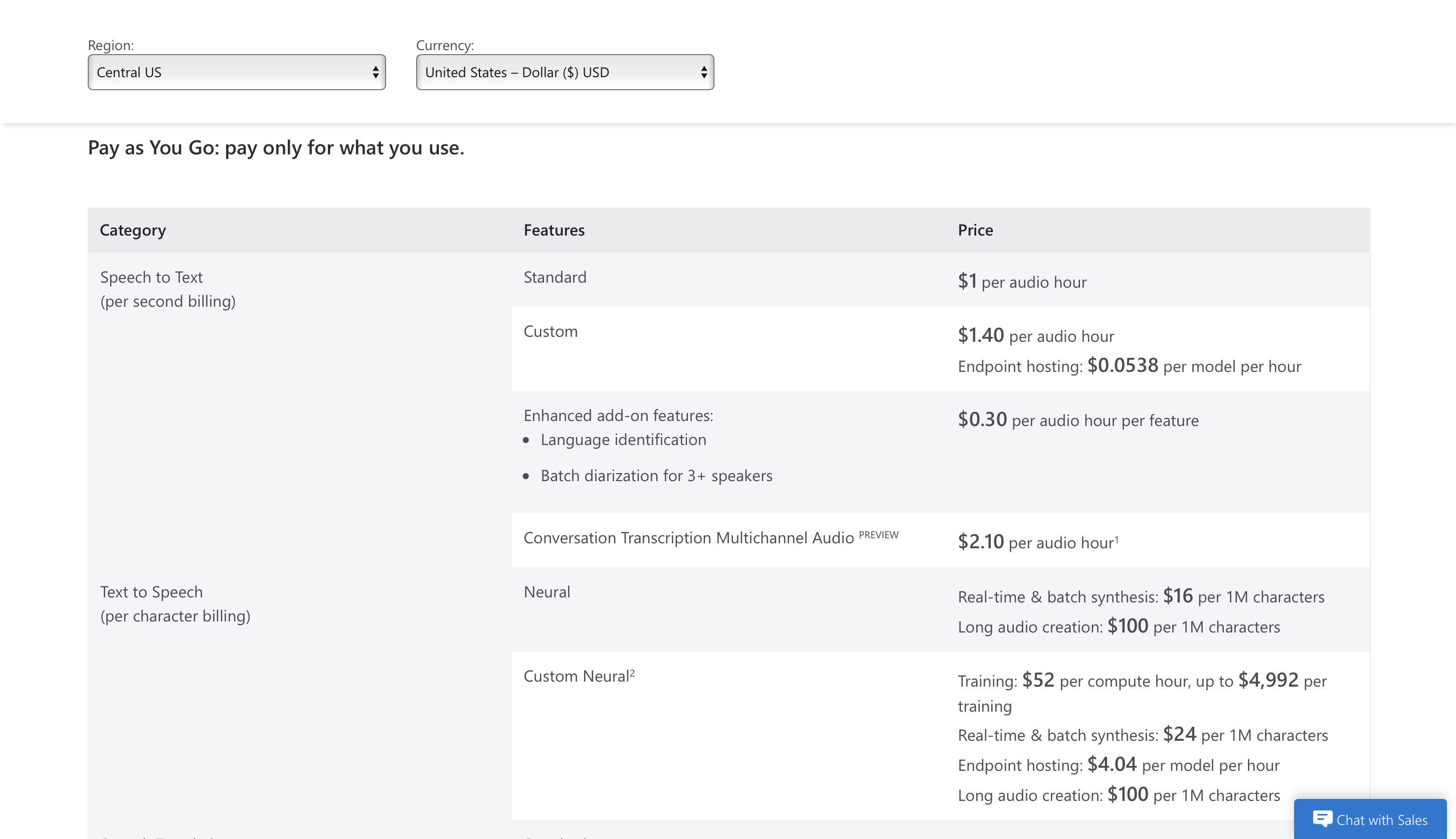
Prezzi
Puoi iniziare a usarlo gratuitamente per 5 ore audio gratuite al mese e il prezzo premium parte da $ 1 per ora audio.
5. Amazon Transcribe
Amazon Transcribe è un'applicazione molto utile che offre numerosi vantaggi quando si tratta di convertire efficacemente la voce in testo e riconoscimento vocale.
Con l'eccezionale scalabilità di questa soluzione basata su cloud di Amazon Web Services (AWS), le aziende possono gestire efficacemente enormi quantità di dati audio.
Amazon Transcribe è in grado di adattarsi facilmente ai mutevoli requisiti di trascrizione, che si tratti di riunioni, colloqui o chiamate all'assistenza clienti. Le aziende possono ricevere informazioni preziose dalle informazioni audio utilizzando trascrizioni accurate fornite regolarmente dalla tecnologia di riconoscimento vocale automatico.
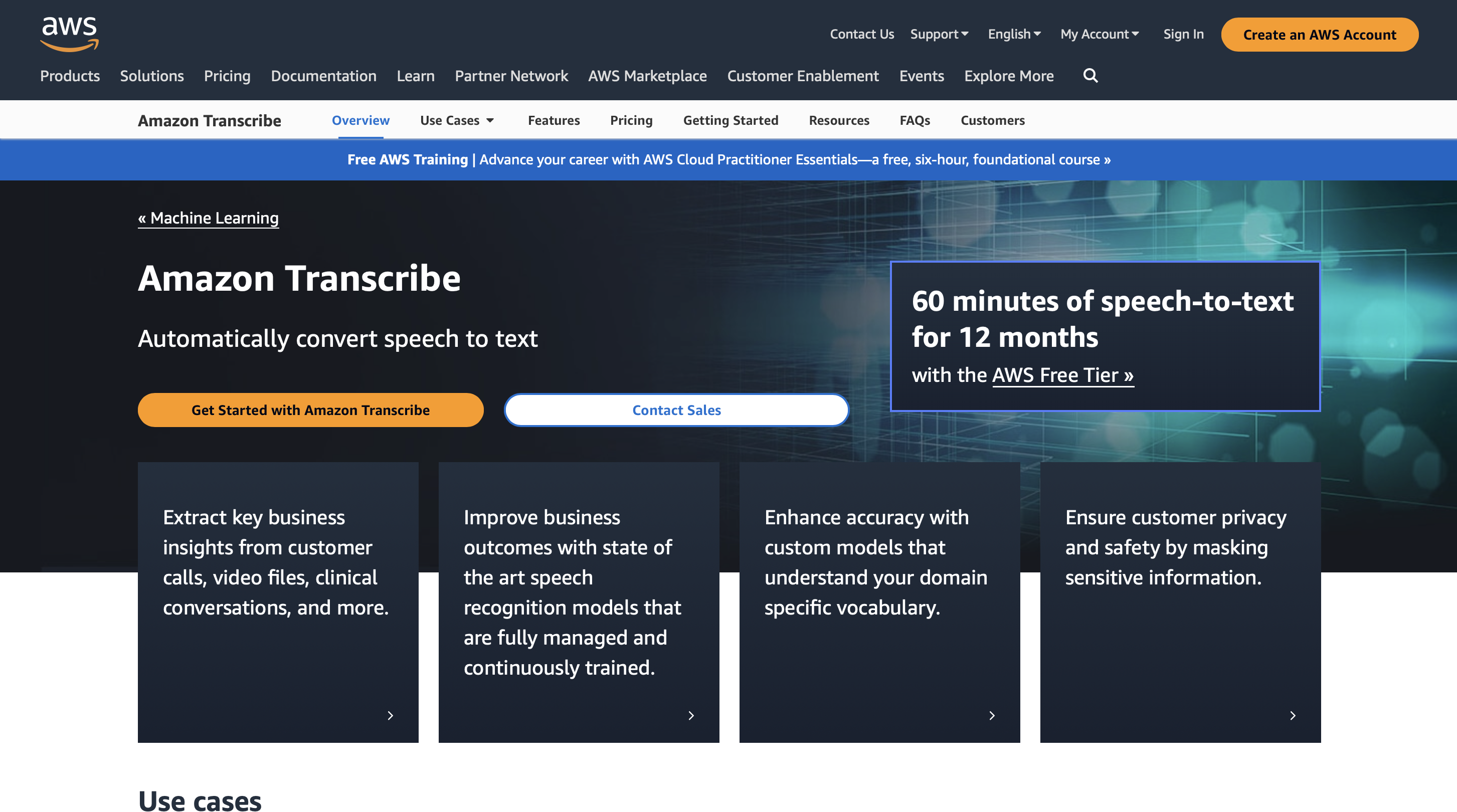
L'utilizzo di sofisticati algoritmi di machine learning, che apprendono continuamente e migliorano nel tempo, migliora significativamente la precisione di Amazon Transcribe.
Si integra con altri Amazon Web Services senza problemi. Con l'aiuto di questa connessione, le organizzazioni possono aggiungere rapidamente funzionalità di riconoscimento vocale alla loro attuale infrastruttura AWS, riducendo i processi e aumentando l'efficacia complessiva.
Inoltre, Amazon Transcribe offre metadati aggiuntivi, come timestamp, che ti consentono di navigare e cercare più facilmente nel testo trascritto.
Può analizzare e trascrivere efficacemente qualsiasi dimensione del file audio. Le aziende possono utilizzare Amazon Transcribe per gestire il carico, assicurando trascrizioni tempestive e accurate sia che abbiano pochi minuti o diverse ore di audio da trascrivere.
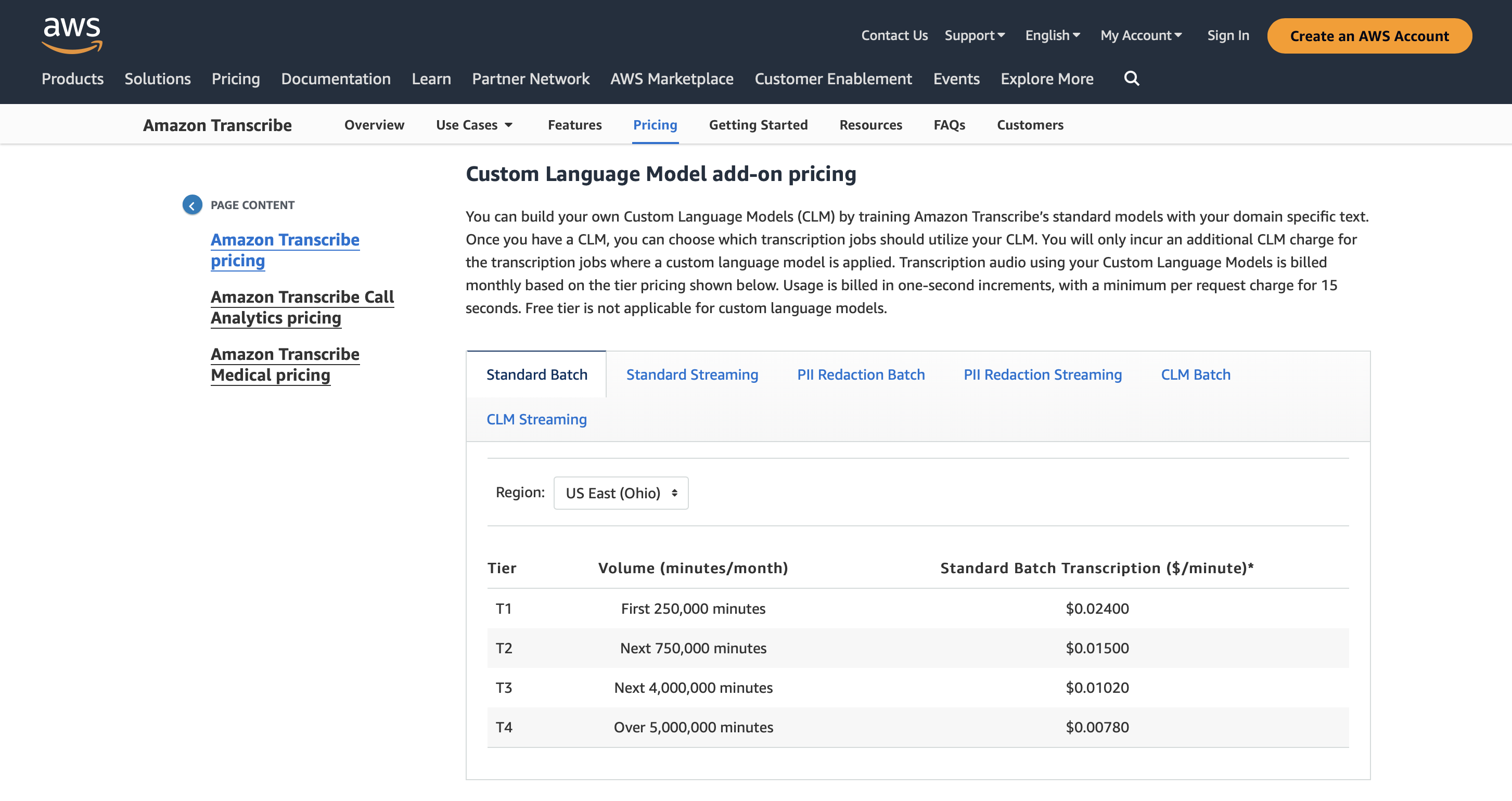
Prezzi
Puoi utilizzare Amazon Transcribe per 60 minuti al mese per 12 mesi e il prezzo premium parte da $ 0.02400/minuto
6. IBM Watson Discorso al testo
IBM Watson Speech to Text è un solido strumento per il riconoscimento vocale e la trascrizione che include una varietà di funzionalità avanzate e scelte di personalizzazione. La lingua parlata viene tradotta con precisione in testo scritto utilizzando questo servizio basato su cloud, che si avvale di una tecnologia all'avanguardia come apprendimento profondo e l'elaborazione del linguaggio naturale.
Come risultato del suo supporto linguistico completo, gli utenti possono trascrivere l'audio in una varietà di lingue e dialetti. Per le aziende che operano a livello internazionale o necessitano di servizi di trascrizione multilingue, questa adattabilità lo rende uno strumento prezioso.
Inoltre, IBM Watson Speech to Text offre modelli e vocabolari specializzati in un determinato settore per essere adattati alle sue esigenze.
IBM Watson Speech to Text può adattarsi alle esigenze specifiche di molte aziende, siano esse nel settore legale, finanziario o sanitario.
La capacità di IBM Watson Speech to Text di gestire l'audio in modalità batch o in tempo reale ti offre flessibilità in base alle tue esigenze. Mentre la trascrizione in batch funziona bene per i file audio preregistrati, la trascrizione in tempo reale è la migliore per applicazioni come l'analisi vocale e i sottotitoli in tempo reale.
Inoltre, IBM Watson Speech to Text dispone di potenti funzionalità di diarizzazione degli oratori che consentono il riconoscimento e la separazione di vari oratori all'interno di una sorgente audio.
Quando sono presenti numerosi relatori, ad esempio durante le registrazioni di conferenze o interviste, questa funzione è molto utile. Grazie alla sua perfetta connessione con altri servizi e API di IBM Watson, gli sviluppatori possono creare rapidamente e facilmente solide app guidate dalla voce.
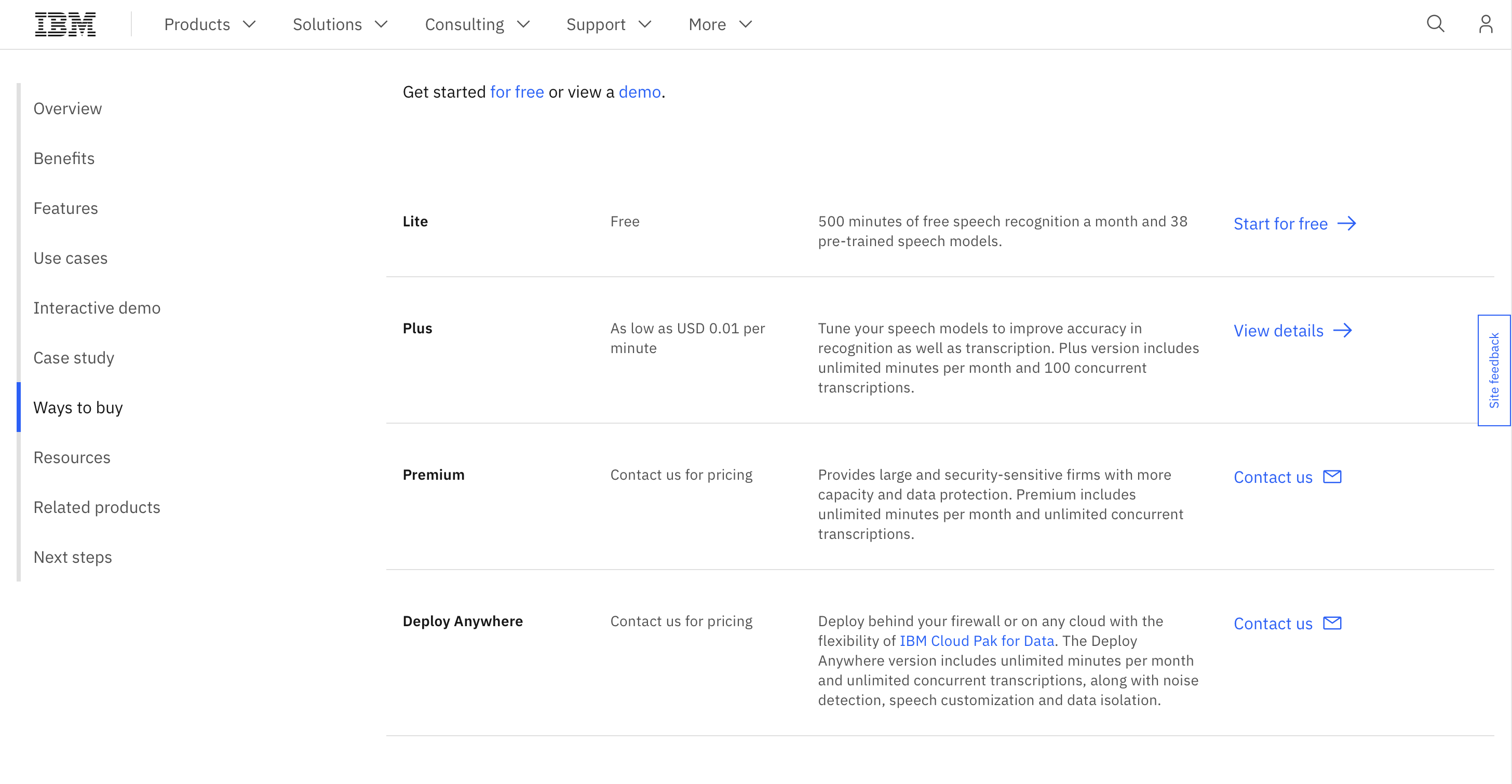
Prezzi
Puoi utilizzare il servizio per 500 minuti di riconoscimento vocale gratuito al mese e il prezzo premium parte da $ 0.01/minuto.
7. OpenAI Whisper
OpenAI Whisper è un'API di riconoscimento vocale all'avanguardia che utilizza tecnologie all'avanguardia per ottenere prestazioni eccezionali. Whisper è una soluzione affidabile per organizzazioni e sviluppatori poiché converte accuratamente la lingua parlata in testo scritto grazie ai suoi potenti modelli di apprendimento automatico.
Questa API si distingue per le sue capacità multilingue, che le consentono di tradurre contenuti audio in altre lingue, dialetti e accenti, servendo una base di utenti diversificata.
Il sistema OpenAI Whisper è in grado di riconoscere e comprendere una varietà di schemi vocali e variazioni poiché è costruito su un ampio set di dati di addestramento.
Sussurro reti neurali profonde sono stati addestrati su enormi volumi di dati audio grazie ai quali ora è in grado di riconoscere e trascrivere frasi pronunciate con sorprendente precisione.
Offre servizi di trascrizione precisi ed efficaci e trova impiego in settori quali l'assistenza sanitaria, il servizio clienti e i media. Whisper può aiutare con la dettatura medica nel settore sanitario, assistendo gli esperti nel mantenere i dati dei pazienti corretti.
Consente la trascrizione delle interazioni dei consumatori nel servizio clienti, migliorando l'analisi e il controllo di qualità. Al fine di migliorare l'accessibilità e la scoperta dei contenuti, le organizzazioni dei media possono inoltre utilizzare Whisper per trascrivere interviste, podcast e materiale video.
La grande accuratezza di OpenAI Whisper è il prodotto del suo continuo apprendimento e sviluppo. Le capacità di trascrizione di Whisper sono migliorate grazie ai modelli che utilizza, che cambiano man mano che vengono elaborati più dati e vengono ricevuti input.
Questo costante miglioramento garantisce che l'API rimanga all'avanguardia nella tecnologia di riconoscimento vocale, offrendo ai consumatori i migliori risultati.
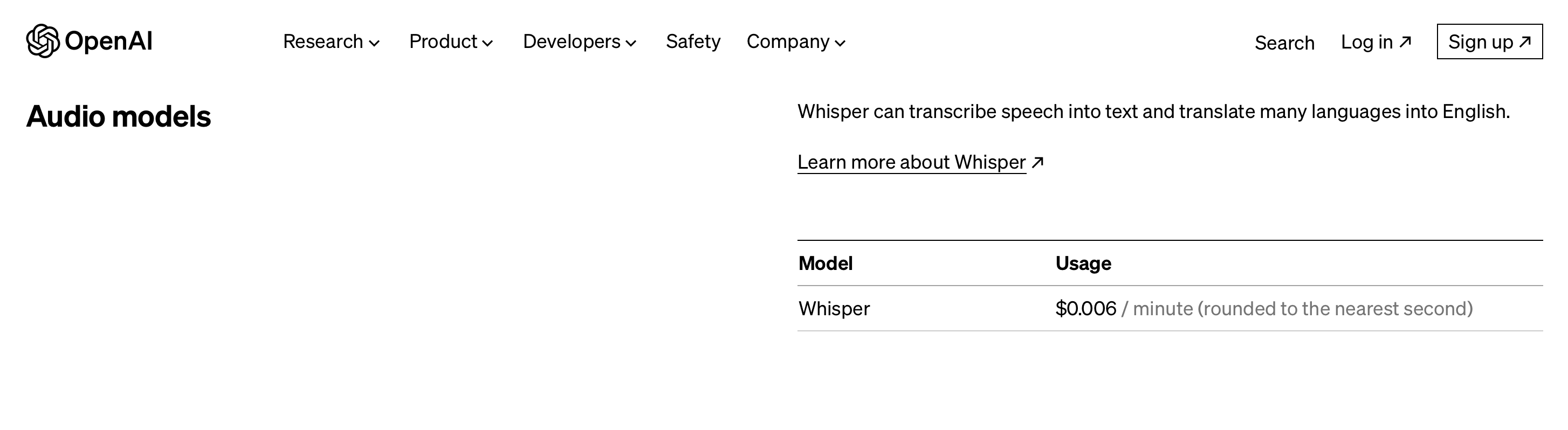
Prezzi
Il prezzo premium del modello parte da $ 0.006/minuto.
8. Speechmatics
Speechmatics è leader di mercato nella tecnologia di riconoscimento vocale, fornendo un'API di sintesi vocale forte e accurata. Speechmatics eccelle nel convertire accuratamente la lingua parlata in testo scritto utilizzando algoritmi all'avanguardia e metodi di deep learning.
È uno strumento utile per una varietà di applicazioni, tra cui sottotitoli multimediali, centralino analisi e indicizzazione dei contenuti grazie alle sue accurate capacità di trascrizione.
Speechmatics può trascrivere in modo affidabile informazioni audio da una varietà di origini linguistiche grazie al suo ampio supporto linguistico, che include dialetti e accenti regionali.
Indipendentemente dalla lingua pronunciata, sarai in grado di copiare e comprendere accuratamente il testo parlato grazie a questa capacità multilingue. Speechmatics fornisce risultati affidabili e precisi sia che si tratti di inglese, spagnolo, mandarino o altre lingue.
La tecnologia di base di Speechmatics viene continuamente migliorata e appresa da essa, consentendole di adattarsi a vari schemi vocali, accenti e fattori ambientali.
La dedizione di Speechmatics all'innovazione continua garantisce che continuerà a guidare il campo della tecnologia di riconoscimento vocale e ad offrire ai propri clienti la conversione da voce a testo più precisa.
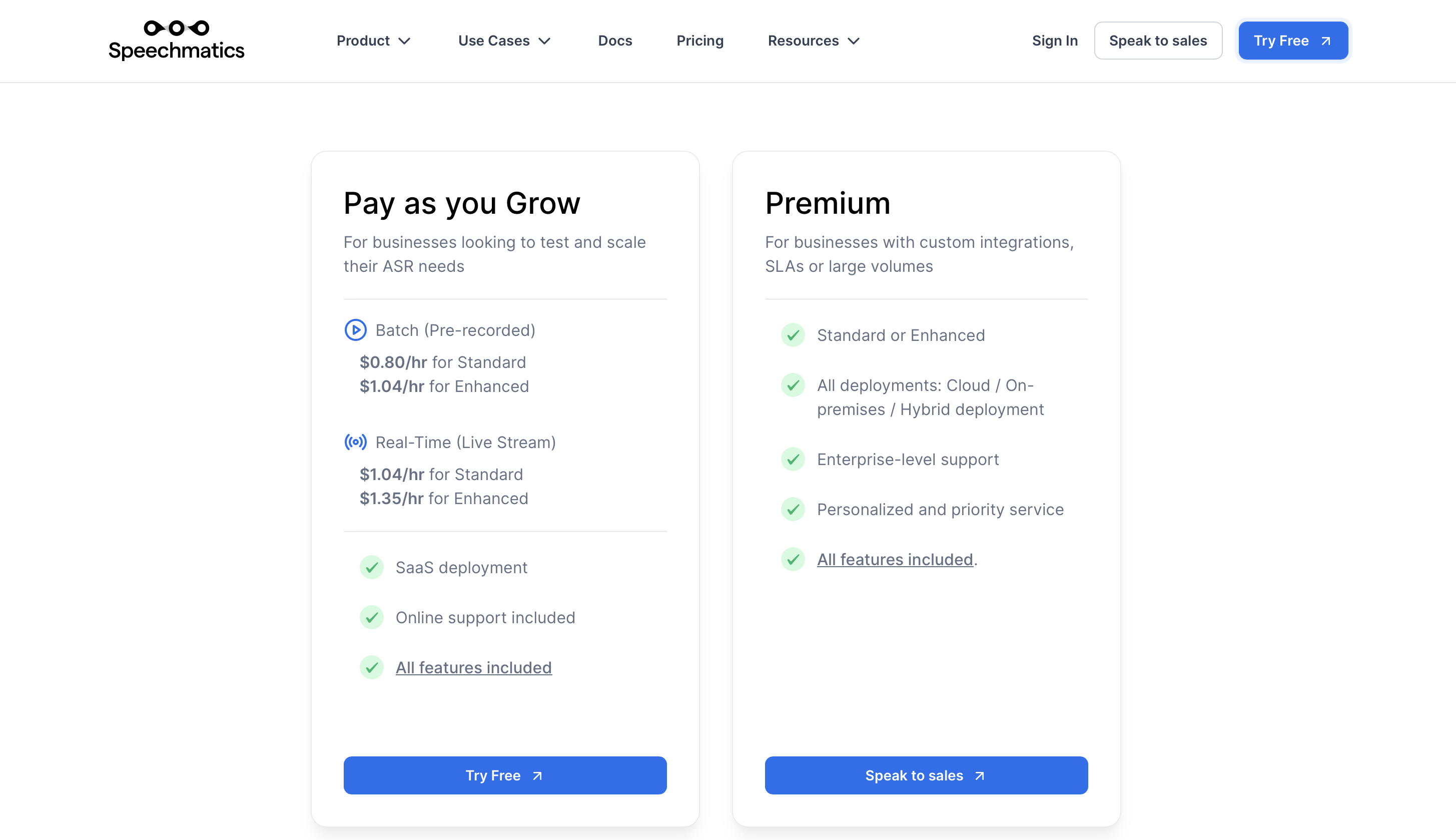
Prezzi
Il prezzo premium parte da $ 0.80/ora in batch (preregistrato) e $ 1.04/ora in tempo reale (trasmissione in diretta).
9. Deepgram
Deepgram, pioniere nel riconoscimento vocale e nella tecnologia di trascrizione, fornisce una solida base per una conversione estremamente precisa da audio a testo modelli di deep learning.
I modelli di deep learning costruiti all'interno della piattaforma possono comprendere e impaginare un'ampia varietà di modelli e variazioni vocali poiché sono stati addestrati su enormi quantità di dati.
La grande accuratezza e la capacità di Deepgram di cogliere sottili sottigliezze nei contenuti parlati sono entrambe il risultato della sua formazione intensiva. Grazie alla versatilità della piattaforma, le trascrizioni sono più accurate poiché può gestire una varietà di accenti, lingue e termini specifici del settore.
Può produrre risultati accurati anche in circostanze tutt'altro che ideali grazie ai suoi modelli di deep learning, che gli consentono anche di gestire situazioni uditive difficili e rumori di fondo.
Inoltre, sulla piattaforma di riconoscimento vocale e trascrizione di Deepgram sono disponibili numerose funzionalità tecnologiche per migliorare l'esperienza dell'utente.
Puoi ricevere trascrizioni immediate di conversazioni o eventi dal vivo grazie alle sue capacità di elaborazione in tempo reale. Deepgram consente inoltre l'elaborazione in batch, rendendo possibile la trascrizione efficiente di grandi set di dati audio.
Prezzi
Puoi iniziare a usarlo gratuitamente e il prezzo premium parte da $ 4 all'anno.
10 Siri
Siri è cresciuto in popolarità come una delle applicazioni software di riconoscimento vocale più riconoscibili e comunemente utilizzate oggi accessibili. Un assistente virtuale preferito da milioni di proprietari di dispositivi Apple in tutto il mondo, Siri è noto per il suo design intuitivo e le interazioni ad attivazione vocale.
Siri è un assistente ad attivazione vocale che può eseguire una varietà di operazioni con un solo comando vocale, inclusa la creazione di promemoria, l'invio di messaggi, l'effettuazione di telefonate e persino la risposta a domande di cultura generale.
La perfetta integrazione di Siri con i prodotti Apple, come iPhone, iPad, Mac e HomePod, è ciò che lo distingue dagli altri assistenti digitali.

Puoi accedere a Siri utilizzando diversi dispositivi grazie a questa integrazione, che garantisce un'esperienza utente comoda e coerente. Siri è sempre disponibile, sia che tu stia lavorando sul tuo Mac o su un iPhone quando sei in viaggio.
Non si può negare l'utilità e l'adattabilità di Siri nella vita quotidiana. Con solo la loro voce, puoi utilizzare Siri per gestire i loro programmi, inviare e-mail, navigare tramite mappe e utilizzare gadget per la casa intelligente. Puoi continuare a essere connesso e produttivo mentre sei in viaggio grazie a questo metodo a mani libere, che consente anche di risparmiare tempo.
Inoltre, Siri è in continua evoluzione e migliora. Apple cambia spesso le capacità di Siri, aumentando la sua capacità di interpretazione ed elaborazione del linguaggio naturale, ampliando la sua base di conoscenze e aggiungendo nuove funzioni.
Mantenendo la sua leadership nella tecnologia di riconoscimento vocale attraverso il continuo sviluppo, Siri può continuare a offrirti un'esperienza fluida e personalizzata.
Prezzi
È gratuito per tutti.
Conclusione
In conclusione, il software di riconoscimento vocale alimentato dall'intelligenza artificiale ha cambiato completamente il modo in cui interagiamo con la tecnologia ed è diventato uno strumento cruciale per molti settori diversi.
La varietà di possibilità, da Microsoft Azure Speech Services e OpenAI Whisper a Google Cloud Speech-to-Text e Nuance Dragon Professional, dimostra lo sviluppo e l'adattabilità di questi sistemi.
Esorto i lettori a ricercare e analizzare a fondo i loro desideri e requisiti individuali prima di selezionare il software di riconoscimento vocale AI che soddisfa al meglio i loro obiettivi perché ogni software ha una varietà di caratteristiche e capacità speciali.
Puoi raggiungere nuovi livelli di produttività, efficienza ed esperienza utente nelle tue attività personali e professionali abbracciando questa potente tecnologia.





Ho fatto confronti per lavoro, ci sono alcune cose che potresti voler sistemare.
1. Siri non è paragonabile agli altri. Siri non è uno strumento per sviluppatori.
2. Il prezzo di Rev che hai condiviso è per la trascrizione umana, mentre altri si basano esclusivamente sulla trascrizione automatica. Se guardi la trascrizione automatica di Rev, anche il suo prezzo è competitivo. https://www.rev.ai/pricing
3. Ti manca Picovoice che offre l'unico modello su dispositivo che funziona come offerta di servizi. Normalmente le soluzioni su dispositivo come Whisper non vengono fornite con il supporto tecnico e la personalizzazione è molto difficile. Offrono un ottimo supporto e la personalizzazione è semplicissima. https://picovoice.ai/platform/cat/