Daftar Isi[Bersembunyi][Menunjukkan]
Model teks-ke-gambar besar membuat kemajuan signifikan dalam pengembangan AI dengan menghasilkan sintesis gambar berkualitas tinggi dan beragam dari perintah teks yang diberikan.
Model-model ini tidak dapat mensintesis representasi subjek yang unik dalam berbagai pengaturan atau mereplikasi penampilan subjek dalam kumpulan referensi yang diberikan.
Teknologi yang baru dirilis seperti DALL.E2 OpenAI atau StabilityAI Difusi Stabil dan Midjourney sudah menguasai internet. Sekarang saatnya untuk menyesuaikan hasilnya. Namun bagaimana?
Google DreamBooth AI telah hadir.
DreamBooth memiliki kemampuan untuk mengenali topik gambar, mendekonstruksinya dari konteks aslinya, dan kemudian secara tepat mensintesiskannya ke dalam konteks baru yang diinginkan. Selain itu, dapat digunakan dengan generator gambar AI saat ini.
Pada artikel ini, kita akan melihat secara mendalam DreamBooth, penggunaannya, tutorialnya, batasannya, dan banyak lagi.
Apa itu Dreambooth?
bilik mimpi, model difusi teks-ke-gambar terbaru, dipersembahkan oleh Google. Prompt tertulis dapat digunakan sebagai panduan oleh Google DreamBooth AI untuk menghasilkan berbagai foto subjek yang dipilih pengguna dalam pengaturan yang berbeda.
Sebuah kelompok riset dari Boston University dan Google mengembangkan DreamBooth, teknik mutakhir untuk mengubah model teks-ke-gambar yang telah menjalani pra-pelatihan ekstensif.
Konsep keseluruhan agak mudah: mereka ingin meningkatkan kamus bahasa-visi sehingga ID token yang tidak biasa dikaitkan dengan topik khusus yang dapat ditentukan pengguna.
Tujuan utama dari model ini adalah untuk menghubungkan pengguna ke model difusi teks-ke-gambar dengan memberi mereka sumber daya yang mereka butuhkan untuk menghasilkan representasi fotorealistik dari contoh materi pelajaran pilihan mereka.
Akibatnya, teknik ini tampaknya bekerja dengan baik untuk meringkas tantangan dalam berbagai situasi.
DreamBooth Google berbeda dari alat teks-ke-gambar sebelumnya, seperti DALL-E2, Difusi Stabil, dan tengah perjalanan, yang memberi pengguna lebih banyak kontrol atas gambar topik sebelum membiarkan mereka memanipulasi model difusi menggunakan input berbasis teks.
Fitur
- DreamBooth AI mungkin meningkatkan model teks-ke-gambar dengan 3-5 gambar.
- Foto fotorealistik asli dapat dibuat dengan DreamBooth AI.
- Selain itu, AI DreamBooth dapat membuat foto suatu topik dari berbagai sudut.
Aplikasi
Rendisi Seni
Tugas ini berbeda secara khusus dari transfer gaya, yang menjaga semantik adegan sumber sambil menggabungkan gaya gambar lain ke dalam adegan aslinya.

Berdasarkan pendekatan kreatif, AI dapat mencapai perubahan adegan yang signifikan sambil mempertahankan identifikasi dan topik spesifik contoh.
Modifikasi Properti
Karakteristik instance subjek dapat dimodifikasi oleh DreamBooth AI.

Aksesori
Komposisi yang kuat sebelum model generasi inilah yang membuat kemampuan DreamBooth AI menghiasi objek begitu menarik.

Rekontekstualisasi
DreamBooth AI dapat menghasilkan gambar khusus untuk contoh subjek tertentu dengan memberikan model terlatih sebuah kalimat yang menyertakan pengenal unik dan kata benda kelas.

Ini dapat menghasilkan subjek dalam postur, artikulasi, dan struktur pemandangan yang unik dan belum pernah terdengar sebelumnya, alih-alih mengubah lingkungan sekitar. Refleksi dan bayangan yang realistis, serta interaksi antara subjek dan objek di sekitarnya.
Tutorial Dream Booth
Dalam tutorial ini, kita akan mengikuti Buku catatan Kolaborasi Google, dan saya akan memandu Anda melewatinya, yang akan membuat Anda memahami dan menggunakannya sendiri.
Menyiapkan GPU dan menginstal perpustakaan
Mencari tahu jenis GPU dan VRAM apa yang tersedia adalah langkah pertama. Menginstal beberapa persyaratan dan dependensi juga diperlukan. Cukup tekan tombol play, lalu tunggu hingga selesai.
Buat akun di Huggingface dan hasilkan token
Langkah selanjutnya adalah mendaftar akun Huggingface. Jika sudah selesai, klik setting di pojok kanan atas. Anda akan tiba di halaman berikutnya.
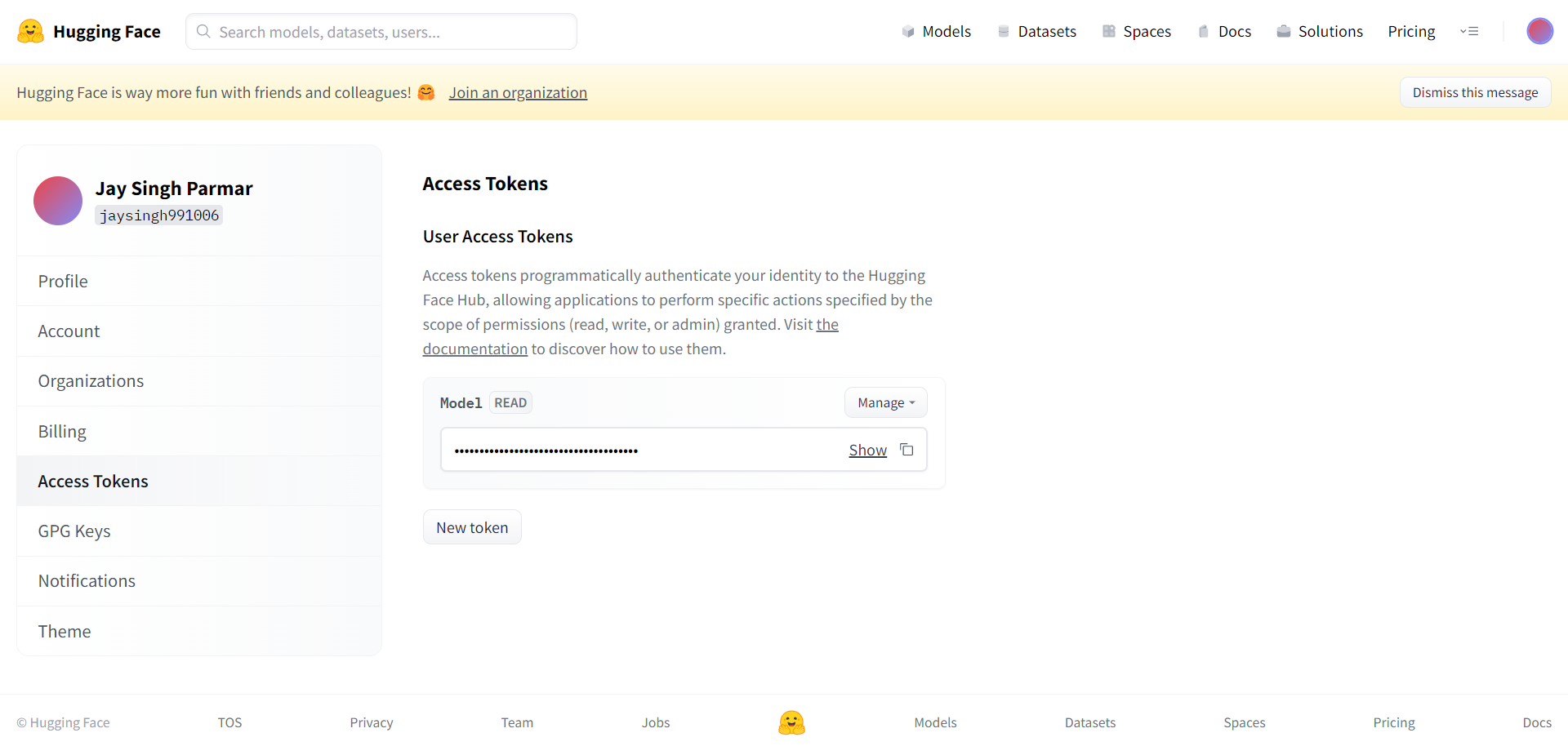
Buat token dan nama seperti yang diminta dari sini. Token harus disalin dan ditempelkan ke collab Google di sel di bawah ini.

Instal xformers
Pada tahap ini, Anda cukup menekan tombol putar untuk menginstal xformers dengan mengklik runtime.
Hubungkan ke Drive
Sekarang, Anda hanya perlu menjalankan sel ini untuk terhubung ke Google Drive.
Masukkan prompt
Di sel berikutnya, Anda hanya perlu memasukkan prompt.
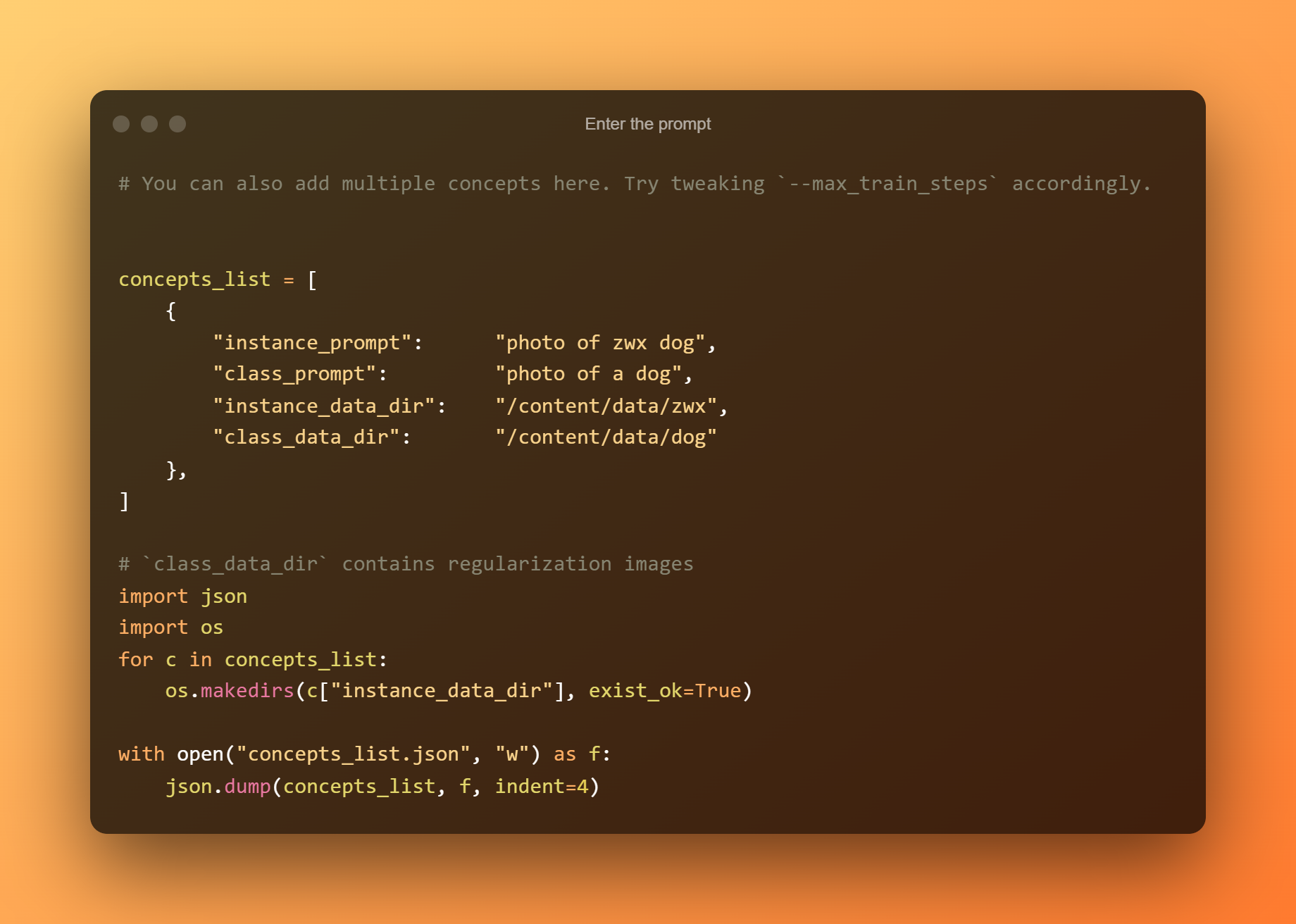
Mengunggah gambar
Pada langkah ini, Anda hanya perlu mengunggah gambar yang ingin Anda latih.

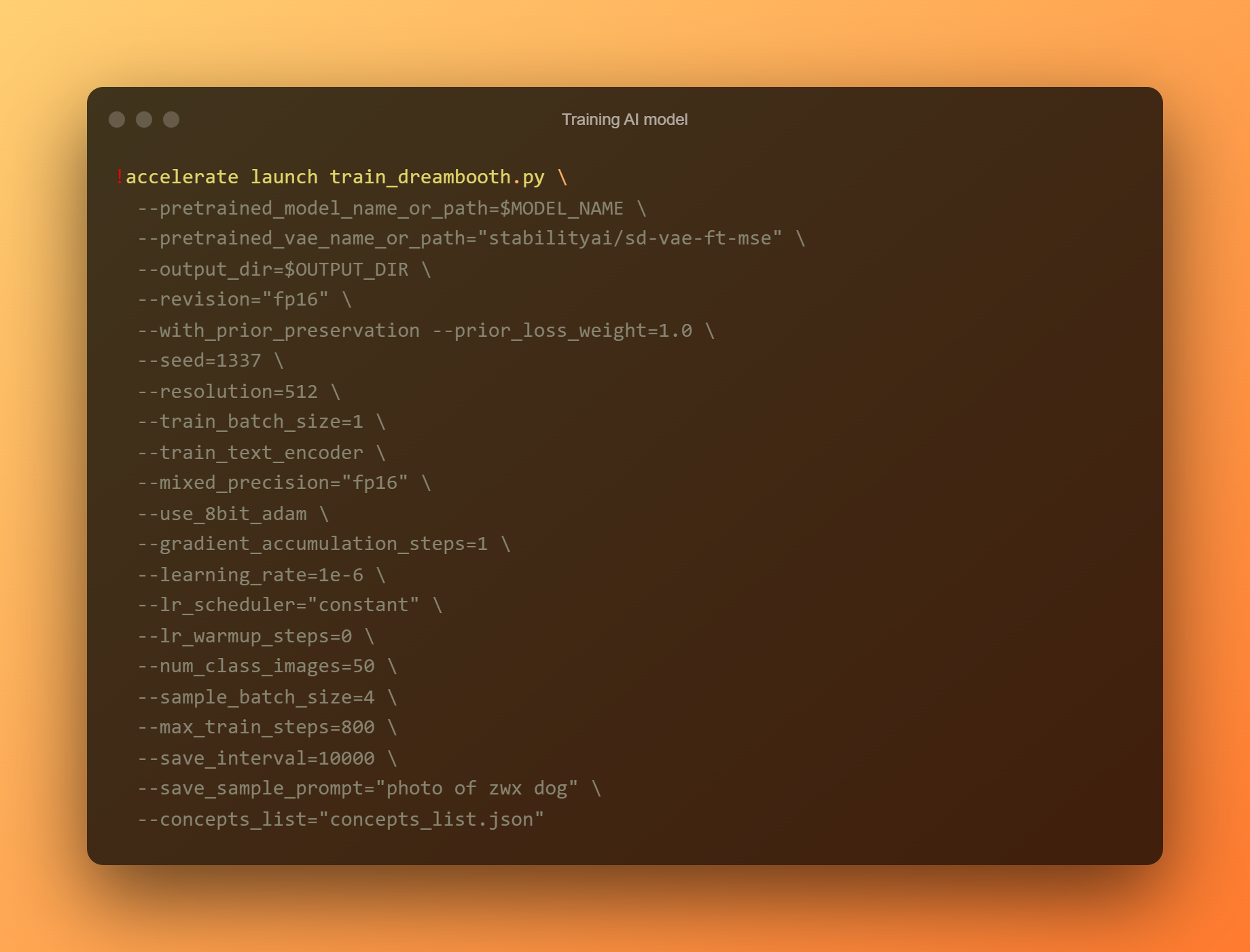
Melatih model AI
Ini adalah fase yang paling penting, karena Anda akan menggunakan DreamBooth untuk melatih model AI baru berdasarkan semua foto referensi yang Anda kirimkan. Anda harus membatasi perhatian Anda pada dua kolom input. “—instance prompt” adalah parameter pertama. Anda harus memberikan nama yang sangat berbeda di sini.
Argumen '–daftar konsep' adalah bidang input kritis kedua. Itu harus diganti namanya agar cocok dengan yang digunakan di bagian 'Ubah prompt'.
Hasilkan gambar AI
Gambar AI akan dibuat pada tahap ini, di mana Anda dapat memasukkan instruksi teks.

Keterbatasan Dreambooth
- Prompt perintah menjadi penghalang untuk membuat iterasi dalam topik dengan tingkat detail yang tinggi. DreamBooth dapat mengubah konteks subjek, tetapi jika model ingin mengubah subjek itu sendiri, ada masalah dengan bingkai.
- Masalah lainnya adalah overfitting gambar keluaran ke gambar masukan. Jika tidak ada cukup gambar yang disediakan, subjek mungkin tidak dipertimbangkan atau dicampur dengan konteks gambar yang dikirimkan. Ketika konteks untuk generasi ganjil ditanyakan, hal yang sama terjadi.
Kesimpulan
Untuk menghasilkan output dari input teks tunggal, sebagian besar model teks-ke-gambar memerlukan jutaan parameter dan pustaka.
DreamBooth menyederhanakan perolehan dan penggunaan konten untuk konsumen dengan hanya memerlukan input dari tiga hingga lima foto topik bersama dengan latar belakang tekstual.





Tinggalkan Balasan