Daftar Isi[Bersembunyi][Menunjukkan]
AI yang baru dan lebih baik telah meningkatkan kemampuan, pemahaman, dan kapasitas untuk menghasilkan gambar beresolusi lebih tinggi. Anda mungkin akhir-akhir ini menemukan beberapa gambar aneh dan lucu yang beredar di internet.
Seekor anjing Shiba Inu mengenakan baret dan turtleneck hitam. Dan berang-berang laut dengan cara pelukis Belanda Vermeer "Girl with a Pearl Earring." Dan ada secangkir sup yang terlihat seperti monster berbulu.
Gambar-gambar ini tidak diciptakan oleh seniman manusia.
Sebagai gantinya, DALL-E 2, sistem AI baru yang dapat mengubah deskripsi tekstual menjadi gambar, menciptakannya.
Cukup tuliskan apa yang ingin Anda lihat, dan AI akan membuatnya untuk Anda – dengan detail yang jelas, kualitas luar biasa, dan, dalam beberapa kasus, daya cipta asli. Dalam posting ini, kita akan melihat secara mendalam studi terbaru OpenAI, DALL.E 2, serta cara kerjanya, dan banyak lagi. Mari kita mulai.
Jadi, apa sebenarnya? DALL.E 2?
DALL-E 2 adalah “model generatif”, sejenis algoritme pembelajaran mesin yang menghasilkan keluaran rumit daripada melakukan tugas prediksi atau klasifikasi pada data masukan.
Anda memberi DALL-E 2 deskripsi tertulis, dan itu membuat gambar yang sesuai dengannya. Dengan menggabungkan konsep, kualitas, dan gaya, DALLE 2 OpenAI dapat menghasilkan grafik dan seni yang inovatif dan realistis dari deskripsi linguistik dasar.
Versi terbaru, DALLE 2, dikatakan lebih fleksibel, mampu membuat gambar dari teks pada resolusi lebih tinggi dan dalam spektrum gaya kreatif yang lebih luas. Misalnya, gambar di bawah ini (dari posting blog DALL-E 2) dibuat dengan deskripsi “Seorang astronot menunggang kuda.”
Satu deskripsi menyimpulkan, "seperti sketsa pensil," sedangkan yang lain menyimpulkan, "secara fotorealistik."

Itu juga dapat mengubah foto yang ada dengan presisi yang menakjubkan. Jadi, Anda dapat menambah atau menghapus elemen sambil mempertahankan warna, pantulan, dan bayangan, sambil mempertahankan tampilan gambar aslinya.
Bagaimana cara kerjanya?
DALL-E 2 menggunakan model CLIP dan difusi, dua yang canggih belajar mendalam pendekatan yang dikembangkan dalam beberapa tahun terakhir. Namun, itu didasarkan pada gagasan yang sama seperti semua kedalaman lainnya jaringan saraf: pembelajaran representasi. CLIP secara bersamaan melatih dua jaringan saraf pada gambar dan keterangan.
Satu jaringan mempelajari representasi visual dalam gambar, sementara yang lain mempelajari representasi teks. Selama pelatihan, kedua jaringan berusaha mengubah parameternya sehingga gambar dan deskripsi yang sebanding menghasilkan penyematan yang serupa.
“Diffusion”, sejenis model generatif yang belajar membuat gambar dengan menghilangkan noise dan menghilangkan noise sampel pelatihannya secara bertahap, adalah pendekatan pembelajaran mesin lain yang digunakan di DALL-E 2. Model difusi mirip dengan autoencoder karena mereka mengubah data input menjadi representasi embedding dan kemudian menggunakan informasi embedding untuk membuat ulang data asli.
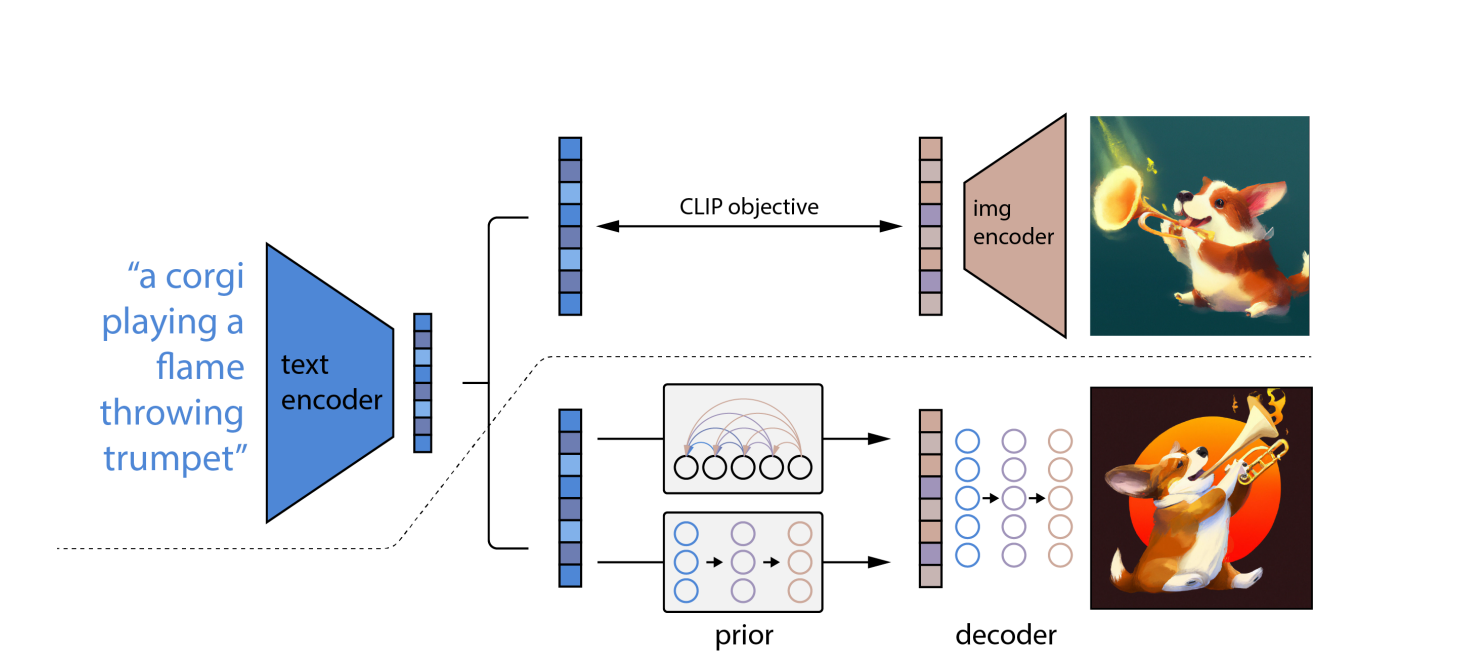
Menggunakan OpenAI model bahasa CLIP, yang dapat menghubungkan deskripsi tekstual dengan foto, pertama-tama menerjemahkan petunjuk tertulis ke dalam bentuk perantara yang menggabungkan properti penting yang harus dimiliki gambar agar sesuai dengan petunjuk tersebut (menurut CLIP).
Kedua, DALL-E 2 membuat CLIP-compliant gambar menggunakan model difusi, yang merupakan jaringan saraf.
Pada foto terdistorsi dengan piksel acak, model difusi dipelajari. Mereka belajar bagaimana mengembalikan bentuk asli foto. Model difusi dapat menghasilkan gambar sintetis berkualitas tinggi, terutama bila digunakan bersama dengan pendekatan pemandu yang memprioritaskan akurasi daripada keragaman.
Akibatnya, model difusi mengambil piksel acak dan menggunakan CLIP untuk mengubahnya menjadi gambar baru yang cocok dengan kata prompt. Karena konsep difusi, DALL-E 2 dapat menghasilkan gambar beresolusi lebih tinggi lebih cepat daripada DALL-E.
Kasus penggunaan DALL.E 2
Dalam dua puluh tahun terakhir, visi komputer teknologi telah berkembang dari gagasan sederhana menjadi terobosan besar. Terlepas dari kemajuan ini, model pengenalan gambar dan objek masih menghadapi kendala yang signifikan dalam kehidupan sehari-hari. Tidak adanya kumpulan data adalah salah satu kelemahan paling signifikan dari pengenalan gambar dan visi komputer. Karena ada kekurangan data di kedua ujungnya, melatih model pengenalan gambar untuk memberikan hasil yang akurat 100 persen hampir sulit.
Untungnya, model pembelajaran mesin baru OpenAI dapat menjembatani kesenjangan dalam teknologi. DALLE 2 mampu menghasilkan gambar yang menakjubkan berdasarkan deskripsi teks. Produksi gambar palsu ini dapat memberikan data ke model pengenalan gambar berdasarkan kebutuhan mereka. Ketiadaan data merupakan batu sandungan yang signifikan untuk identifikasi objek dan gambar.
Di era digital, kumpulan data ada di mana-mana, namun kami masih mencari jalan pintas untuk memberi makan model AI, sehingga dapat memberikan hasil yang baik. Namun, tidak mudah untuk melatih model pengenalan gambar. Ini memerlukan sejumlah besar kumpulan data dengan sedikit perbedaan, yang mungkin tidak dapat kita ambil dengan mudah.
Jadi, apa jawabannya: Jawabannya adalah DALLE 2. Generator gambar OpenAI, dengan kapasitasnya untuk menghasilkan gambar dari teks dan mengubah yang sudah ada, dapat membantu menjembatani kesenjangan tersebut. Ini akan membantu dalam pembuatan data pelatihan tambahan sekaligus mengurangi jumlah pelabelan manusia yang diperlukan. Terlepas dari manfaat yang signifikan, Anda harus waspada terhadap produksi gambar palsu dan gambar yang mengecualikan penyertaan. Hal ini dapat menyebabkan metode deteksi gambar menghasilkan hasil yang bias.
keterbatasan
DALL.E 2 mungkin memiliki pengaruh yang berbahaya jika jatuh ke tangan yang salah, menurut OpenAI. Di dunia palsu saat ini, model tersebut dapat dengan mudah digunakan untuk menyebarkan informasi palsu atau citra rasis, itulah sebabnya OpenAI hanya mengizinkan pengembang untuk menggunakan DALL.2 melalui undangan. Model harus mematuhi batasan konten yang ketat untuk semua saran yang dia dapatkan.
Untuk mengecualikan potensi DALL.E 2 membuat gambar bermusuhan atau kekerasan, kumpulan data dibuat tanpa persenjataan mematikan. Sementara OpenAI telah menyatakan bahwa ia berencana untuk mengubahnya menjadi API di masa depan, dalam kasus DALL.E 2, ia bersedia untuk melanjutkan dengan hati-hati.
Kesimpulan
DALL-E 2 adalah penemuan penelitian OpenAI menarik lainnya yang membuka pintu bagi aplikasi baru.
Salah satu contohnya adalah membuat kumpulan data besar-besaran untuk memenuhi salah satu hambatan utama computer vision–data. Sementara kasus ekonomi untuk banyak aplikasi berbasis DALL-E akan ditentukan oleh harga dan kebijakan yang ditetapkan OpenAI untuk pengguna API-nya, semuanya pasti akan memajukan produksi gambar.





Tinggalkan Balasan