Բառը[Թաքցնել][Ցուցադրում]
Տեսախաղերը շարունակում են մարտահրավեր նետել միլիարդավոր խաղացողների ամբողջ աշխարհում: Գուցե դուք դեռ չգիտեք դա, բայց մեքենայական ուսուցման ալգորիթմները նույնպես սկսել են դիմակայել մարտահրավերին:
Ներկայումս AI-ի ոլորտում զգալի հետազոտություններ կան՝ պարզելու, թե արդյոք մեքենայական ուսուցման մեթոդները կարող են կիրառվել տեսախաղերի վրա: Այս ոլորտում զգալի առաջընթացը ցույց է տալիս դա Machine Learning գործակալները կարող են օգտագործվել մարդու խաղացողին ընդօրինակելու կամ նույնիսկ փոխարինելու համար:
Ի՞նչ է սա նշանակում ապագայի համար Տեսախաղեր?
Արդյո՞ք այս նախագծերը պարզապես զվարճանքի համար են, թե՞ ավելի խորը պատճառներ կան, թե ինչու են այդքան շատ հետազոտողներ կենտրոնանում խաղերի վրա:
Այս հոդվածը համառոտ կուսումնասիրի AI-ի պատմությունը տեսախաղերում: Այնուհետև մենք ձեզ կտրամադրենք մեքենայական ուսուցման որոշ տեխնիկայի արագ ակնարկ, որոնք կարող ենք օգտագործել՝ սովորելու համար, թե ինչպես հաղթել խաղերը: Այնուհետև մենք կանդրադառնանք որոշ հաջողված ծրագրերին նյարդային ցանցեր սովորել և տիրապետել հատուկ տեսախաղերին:
AI-ի համառոտ պատմությունը խաղերում
Նախքան հասկանալը, թե ինչու են նեյրոնային ցանցերը դարձել տեսախաղեր լուծելու իդեալական ալգորիթմ, եկեք համառոտ նայենք, թե ինչպես են համակարգչային գիտնականներն օգտագործել տեսախաղերը՝ արհեստական ինտելեկտի ոլորտում իրենց հետազոտությունն առաջ մղելու համար:
Կարող եք պնդել, որ իր սկզբից տեսախաղերը եղել են AI-ով հետաքրքրված հետազոտողների հետազոտության թեժ ոլորտ:
Թեև ի սկզբանե վիդեոխաղ չէ, շախմատը մեծ ուշադրություն է դարձրել AI-ի վաղ օրերին: 1951 թվականին դոկտոր Դիտրիխ Պրինցը գրեց շախմատային ծրագիր՝ օգտագործելով Ferranti Mark 1 թվային համակարգիչը: Սա դեռևս այն դարաշրջանն էր, երբ այս ծավալուն համակարգիչները ստիպված էին ծրագրեր կարդալ թղթե ժապավենից:

Ծրագիրն ինքնին ամբողջական շախմատային AI չէր: Համակարգչի սահմանափակումների պատճառով Պրինցը կարող էր միայն ծրագիր ստեղծել, որը կլուծեր mate-in-two շախմատային խնդիրներ: Սպիտակ և սև խաղացողների յուրաքանչյուր հնարավոր քայլը հաշվարկելու համար ծրագիրը միջինում 15-20 րոպե էր պահանջում։
Շախմատի և շաշկի կատարելագործման ուղղությամբ AI-ն անշեղորեն բարելավվել է տասնամյակների ընթացքում: Առաջընթացն իր գագաթնակետին հասավ 1997 թվականին, երբ IBM-ի Deep Blue-ը վեց պարտիայից բաղկացած զույգ մենամարտերում հաղթեց ռուս գրոսմայստեր Գարրի Կասպարովին: Մեր օրերում, շախմատային շարժիչները, որոնք կարող եք գտնել ձեր բջջային հեռախոսում, կարող են հաղթել Deep Blue-ին:
AI հակառակորդները սկսեցին ժողովրդականություն ձեռք բերել վիդեո արկադային խաղերի ոսկե դարաշրջանում: 1978-ի Space Invaders-ը և 1980-ականների Pac-Man-ը արդյունաբերության մի քանի ռահվիրաներից են արհեստական ինտելեկտի ստեղծման գործում, որը կարող է բավականաչափ մարտահրավեր նետել նույնիսկ արկադային խաղացողների ամենավետերաններին:
Pac-Man-ը, մասնավորապես, հայտնի խաղ էր արհեստական ինտելեկտի հետազոտողների համար, որոնց վրա կարող էին փորձարկել: Տարբեր մրցույթներ տիկին Փաք-Մենի համար կազմակերպվել է որոշելու, թե որ թիմը կարող է լավագույն արհեստական ինտելեկտը գտնել խաղը հաղթելու համար:
Խաղային AI-ն և էվրիստիկական ալգորիթմները շարունակեցին զարգանալ, քանի որ առաջացավ ավելի խելացի հակառակորդների անհրաժեշտությունը: Օրինակ, մարտական արհեստական ինտելեկտը մեծ ժողովրդականություն է վայելել, քանի որ այնպիսի ժանրեր, ինչպիսիք են առաջին դեմքով հրաձիգները, դարձել են ավելի հիմնական:
Մեքենայի ուսուցում վիդեո խաղերում
Քանի որ մեքենայական ուսուցման տեխնիկան արագորեն մեծ ժողովրդականություն էր վայելում, տարբեր հետազոտական նախագծեր փորձեցին օգտագործել այս նոր տեխնիկան տեսախաղեր խաղալու համար:
Խաղերը, ինչպիսիք են Dota 2-ը, StarCraft-ը և Doom-ը, կարող են խնդիրներ ունենալ դրանց համար մեքենայի ուսուցման ալգորիթմներ լուծել. Խորը ուսուցման ալգորիթմներ, մասնավորապես, կարողացան հասնել և նույնիսկ գերազանցել մարդկային մակարդակի կատարողականը:
The Արկադային ուսումնական միջավայր կամ ALE-ն հետազոտողներին ինտերֆեյս է տվել ավելի քան հարյուր Atari 2600 խաղերի համար: Բաց կոդով հարթակը հետազոտողներին թույլ է տվել համեմատել մեքենայական ուսուցման տեխնիկայի կատարողականը դասական Atari տեսախաղերի վրա: Google-ը նույնիսկ հրապարակեց իրենց սեփականը թուղթ օգտագործելով յոթ խաղ ALE-ից

Մինչդեռ նախագծերը, ինչպիսիք են VizDoom AI հետազոտողներին հնարավորություն է տվել ուսուցանել մեքենայական ուսուցման ալգորիթմներ՝ խաղալու 3D առաջին դեմքով հրաձիգներ:

Ինչպես է այն աշխատում. որոշ հիմնական հասկացություններ
Նյարդային ցանցեր
Մեքենայական ուսուցմամբ տեսախաղերի լուծման մոտեցումների մեծ մասը ներառում է մի տեսակ ալգորիթմ, որը հայտնի է որպես նյարդային ցանց:
Դուք կարող եք պատկերացնել նեյրոնային ցանցը որպես ծրագիր, որը փորձում է ընդօրինակել, թե ինչպես կարող է գործել ուղեղը: Ինչպես մեր ուղեղը կազմված է ազդանշան փոխանցող նեյրոններից, նեյրոնային ցանցը նույնպես պարունակում է արհեստական նեյրոններ:
Այս արհեստական նեյրոնները նաև ազդանշաններ են փոխանցում միմյանց, ընդ որում յուրաքանչյուր ազդանշան իրական թիվ է: Նյարդային ցանցը պարունակում է բազմաթիվ շերտեր մուտքային և ելքային շերտերի միջև, որոնք կոչվում են խորը նյարդային ցանց:
Ամրապնդման ուսուցում
Մեկ այլ տարածված մեքենայական ուսուցման տեխնիկա, որը վերաբերում է տեսախաղեր սովորելուն, ամրապնդման ուսուցման գաղափարն է:
Այս տեխնիկան գործակալին պարգևների կամ պատիժների կիրառմամբ վերապատրաստելու գործընթաց է: Այս մոտեցմամբ գործակալը պետք է կարողանա խնդրի լուծում գտնել փորձության և սխալի միջոցով:
Ենթադրենք, մենք ուզում ենք, որ AI-ն պարզի, թե ինչպես խաղալ Snake խաղը: Խաղի նպատակը պարզ է. ստացեք որքան հնարավոր է շատ միավորներ՝ սպառելով իրերը և խուսափելով ձեր աճող պոչից:
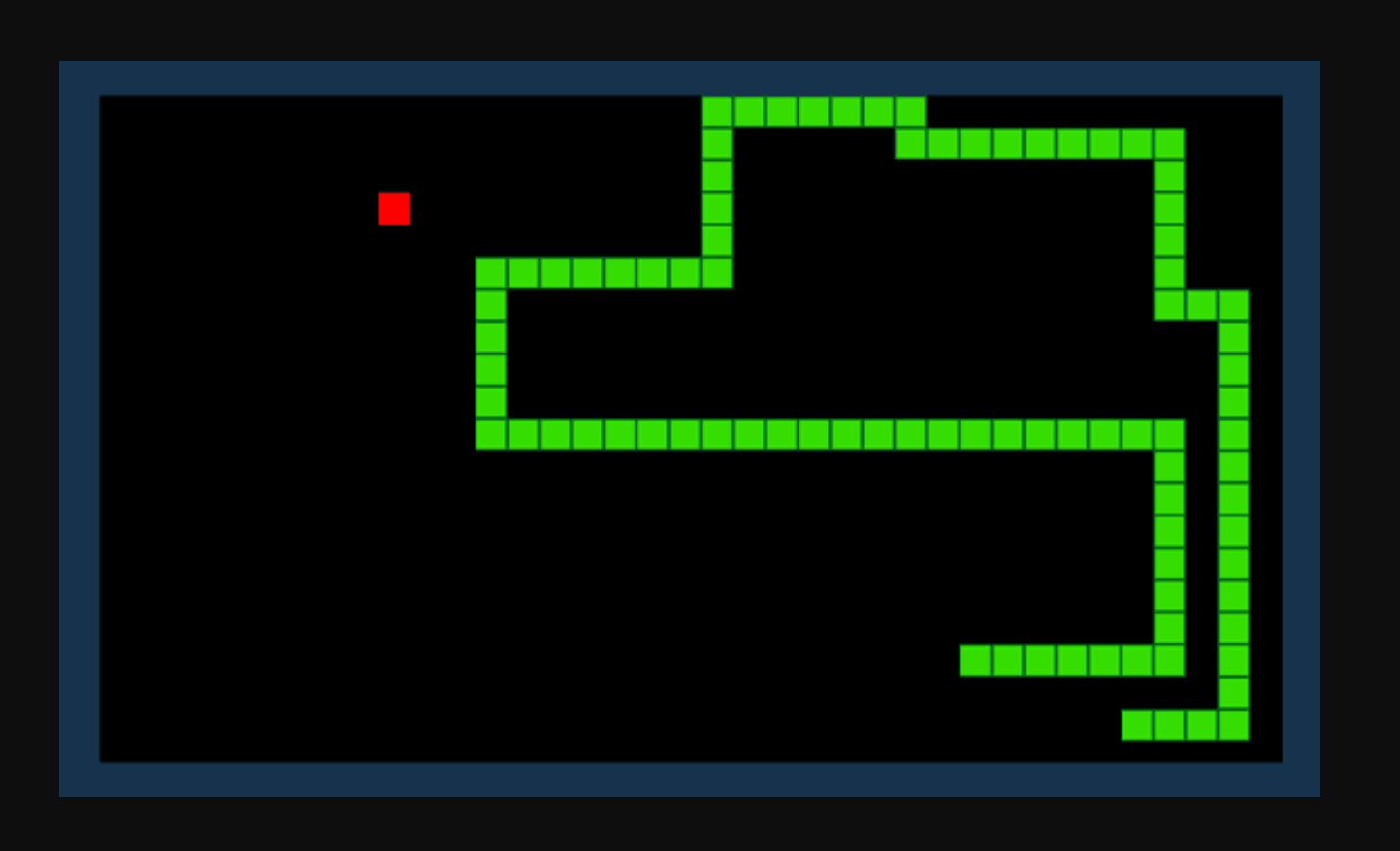
Ամրապնդման ուսուցման միջոցով մենք կարող ենք սահմանել պարգևատրման ֆունկցիա R: Ֆունկցիան միավորներ է ավելացնում, երբ Օձը սպառում է իրը և նվազեցնում միավորները, երբ Օձը դիպչում է խոչընդոտին: Հաշվի առնելով ներկա միջավայրը և հնարավոր գործողությունների մի շարք, մեր ուժեղացման ուսուցման մոդելը կփորձի հաշվարկել օպտիմալ «քաղաքականությունը», որը առավելագույնի կհասցնի մեր պարգևատրման գործառույթը:
Նեյրոէվոլյուցիա
Հետազոտողները, հետևելով բնությունից ոգեշնչված լինելու թեմային, հաջողության են հասել նաև ML-ի կիրառման մեջ տեսախաղերում՝ նեյրոէվոլյուցիա անունով հայտնի տեխնիկայի միջոցով:
Օգտագործելու փոխարեն գրադիենտ վայրէջք ցանցում նեյրոնները թարմացնելու համար մենք կարող ենք օգտագործել էվոլյուցիոն ալգորիթմներ՝ ավելի լավ արդյունքների հասնելու համար:
Էվոլյուցիոն ալգորիթմները սովորաբար սկսվում են պատահական անհատների սկզբնական պոպուլյացիա ստեղծելով: Այնուհետև մենք գնահատում ենք այս անհատներին՝ օգտագործելով որոշակի չափանիշներ: Լավագույն անհատներն ընտրվում են որպես «ծնողներ» և բուծվում են միասին՝ անհատների նոր սերունդ ձևավորելու համար: Այդ անհատներն այնուհետև կփոխարինեն բնակչության ամենաքիչ պիտանի անհատներին:
Այս ալգորիթմները նաև սովորաբար ներմուծում են մուտացիայի գործողության որոշակի ձև խաչմերուկի կամ «բուծման» քայլի ընթացքում՝ գենետիկական բազմազանությունը պահպանելու համար:
Տեսախաղերում մեքենայական ուսուցման վերաբերյալ հետազոտության օրինակ
OpenAI Five

OpenAI Five OpenAI-ի համակարգչային ծրագիր է, որի նպատակն է խաղալ DOTA 2՝ բազմախաղացող շարժական մարտադաշտի (MOBA) հայտնի խաղ:
Ծրագիրը օգտագործել է ուժեղացման ուսուցման գոյություն ունեցող տեխնիկան, որը չափվել է վայրկյանում միլիոնավոր կադրերից սովորելու համար: Բաշխված ուսուցման համակարգի շնորհիվ OpenAI-ն կարողացավ ամեն օր խաղալ 180 տարվա խաղեր:
Վերապատրաստման շրջանից հետո OpenAI Five-ը կարողացավ հասնել փորձագիտական մակարդակի և ցույց տալ համագործակցություն մարդկային խաղացողների հետ: 2019 թվականին OpenAI հինգը կարողացավ հաղթել Հանրային խաղերում խաղացողների 99.4%-ը:
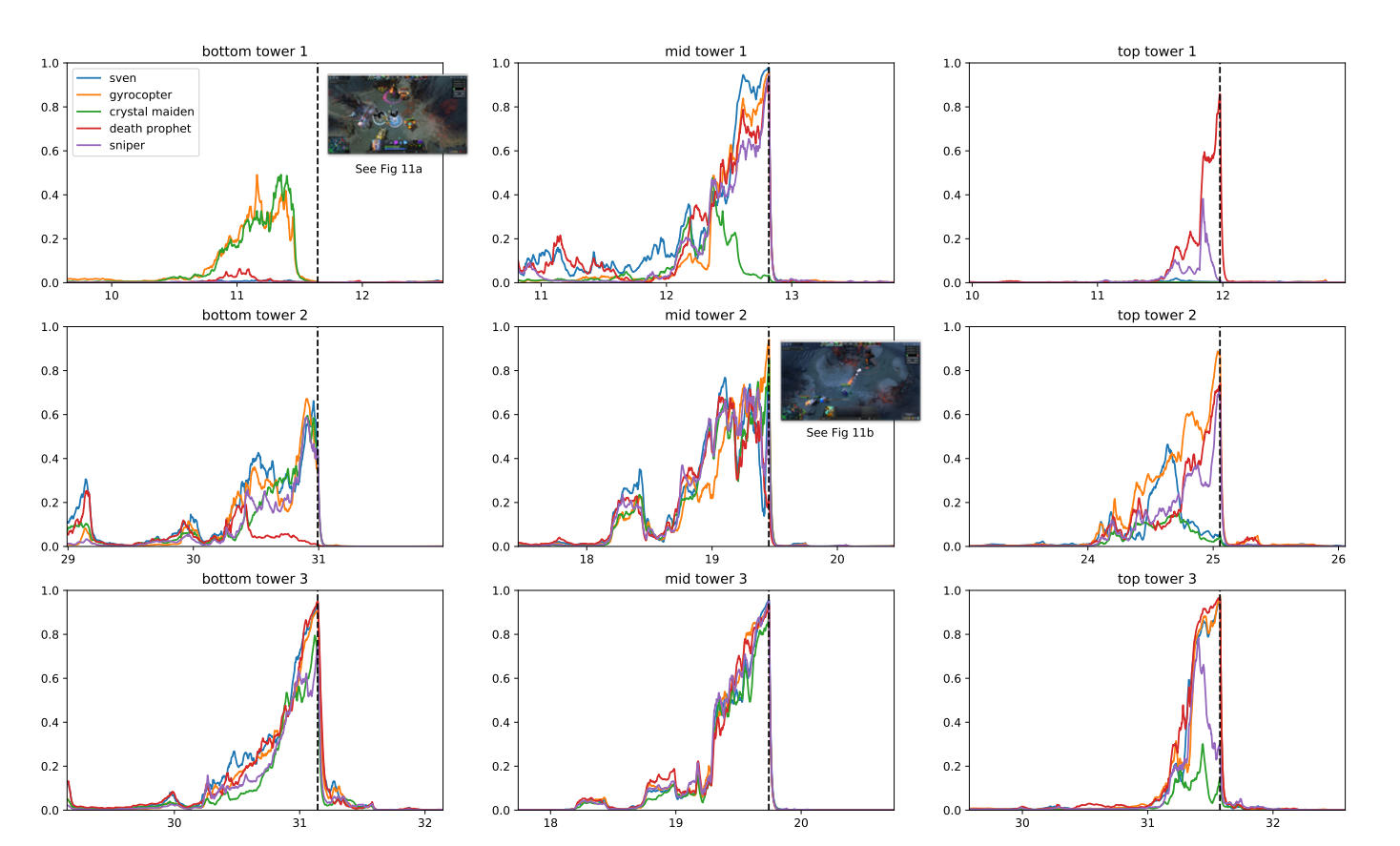
Ինչու՞ OpenAI-ը որոշեց այս խաղը: Ըստ հետազոտողների, DOTA 2-ն ուներ բարդ մեխանիկա, որը գտնվում էր գոյություն ունեցող խորքերի հասանելիությունից դուրս ամրապնդման ուսուցում ալգորիթմներ:
Super Mario Bros.
Նյարդային ցանցերի մեկ այլ հետաքրքիր կիրառություն տեսախաղերում նեյրոէվոլյուցիայի օգտագործումն է պլատֆորմներ խաղալու համար, ինչպիսիք են Super Mario Bros-ը:
Օրինակ ՝ սա Հեքըթոնի մուտք սկսում է խաղի մասին գիտելիքներ չունենալով և կամաց-կամաց հիմք է կառուցում, թե ինչ է անհրաժեշտ մակարդակի միջով առաջադիմելու համար:
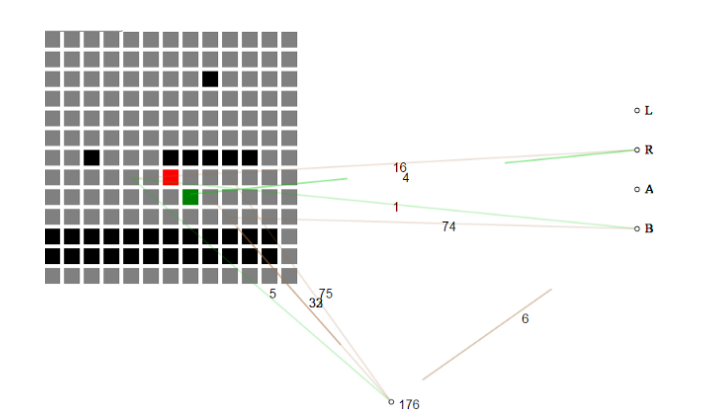
Ինքնազարգացող նեյրոնային ցանցը խաղի ներկա վիճակն ընդունում է որպես սալիկների ցանց: Սկզբում նեյրոնային ցանցը չի հասկանում, թե ինչ է նշանակում յուրաքանչյուր սալիկ, միայն այն է, որ «օդային» սալիկները տարբերվում են «հողային սալիկներից» և «թշնամի սալիկներից»:
Հեքըթոնային նախագծի նեյրոէվոլյուցիայի իրականացումը օգտագործել է NEAT գենետիկական ալգորիթմը տարբեր նյարդային ցանցեր ընտրովի ձևավորելու համար:
Նշանակություն
Այժմ, երբ տեսել եք նեյրոնային ցանցերի մի քանի օրինակներ, որոնք խաղում են տեսախաղեր, կարող եք մտածել, թե որն է այս ամենի իմաստը:
Քանի որ տեսախաղերը ներառում են բարդ փոխազդեցություններ գործակալների և նրանց միջավայրի միջև, դրանք կատարյալ փորձադաշտ են AI ստեղծման համար: Վիրտուալ միջավայրերը անվտանգ են և վերահսկելի և ապահովում են տվյալների անսահման մատակարարում:
Այս ոլորտում կատարված հետազոտությունները հետազոտողներին պատկերացում են տվել այն մասին, թե ինչպես կարելի է նեյրոնային ցանցերը օպտիմիզացնել՝ սովորելու, թե ինչպես լուծել խնդիրները իրական աշխարհում:
Նյարդային ցանցեր ոգեշնչված են այն բանից, թե ինչպես է ուղեղը աշխատում բնական աշխարհում: Ուսումնասիրելով, թե ինչպես են արհեստական նեյրոններն իրենց պահում, երբ սովորում են, թե ինչպես խաղալ տեսախաղ, մենք կարող ենք նաև պատկերացում կազմել, թե ինչպես են մարդու ուղեղը աշխատանքներ.
Եզրափակում
Նյարդային ցանցերի և ուղեղի նմանությունները հանգեցրել են երկու ոլորտների պատկերացումների: Շարունակական հետազոտությունն այն մասին, թե ինչպես են նեյրոնային ցանցերը կարող են լուծել խնդիրները, մի օր կարող է հանգեցնել ավելի առաջադեմ ձևերի Արհեստական բանականություն.
Պատկերացրեք, որ օգտագործում եք ձեր առանձնահատկություններին հարմարեցված AI, որը կարող է խաղալ մի ամբողջ տեսախաղ, նախքան այն գնելը, որպեսզի իմանաք, արդյոք արժե ձեր ժամանակը: Տեսախաղերի ընկերությունները կօգտագործե՞ն նեյրոնային ցանցեր՝ բարելավելու խաղի դիզայնը, կսմթելու մակարդակը և հակառակորդի դժվարությունը:
Ի՞նչ եք կարծում, ի՞նչ կլինի, երբ նյարդային ցանցերը դառնան վերջնական խաղացողները:





Թողնել գրառում