Kretanje i pohranjivanje podataka postalo je sve važnije kao rezultat stalnog širenja IT industrije i milijuna podatkovnih točaka koje se proizvode svake sekunde.
Osim toga, ti podaci moraju biti jasni i jednostavni za razumijevanje kako bi podržali precizno donošenje odluka.
Kako bi održala konkurentnost i postigla dugoročni uspjeh, vaša tvrtka mora pohranjivati i premještati podatke koristeći najučinkovitija dostupna rješenja.
Zbog toga sve više tvrtki koristi podatkovne strukture. Jedan od najboljih načina da uštedite svoje vrijeme, novac i resurse je korištenje podatkovne mreže za obradu podataka i omogućavanje strojnog učenja umjetne inteligencije.
U ovom ćemo članku detaljno proučiti Data Fabric, uključujući njegovu upotrebu, glavne komponente, prednosti i druge vitalne detalje.
Dakle, što je Data Fabric?
Bez obzira gdje se nalaze, upravljajte i nadzirite svoje podatke i aplikacije. U svojoj srži, data fabric je integrirana podatkovna arhitektura koja je sigurna, svestrana i prilagodljiva.
Tvornica podataka, koja kombinira najbolje od oblaka, jezgre i ruba, na mnogo je načina novi strateški pristup operaciji pohrane podataka u vašem poslovanju.
Iako je centralno kontroliran, može doseći posvuda, uključujući lokalne, javne i privatne oblake, kao i rubne i IoT uređaje.
Podatkovni silosi veličine nebodera i raznolike, nepovezane infrastrukture stvar su prošlosti. Mreža podataka temelji se na sveobuhvatnoj zbirci alata za upravljanje podacima koji jamče dosljednost u vašim povezanim okruženjima.
Putem automatizacije, pojednostavljuje dugotrajno upravljanje, ubrzava razvoj, testiranje i implementaciju te štiti vašu imovinu XNUMX sata dnevno.
Bez obzira gdje se nalaze vaši podaci i aplikacije, možete pratiti troškove pohrane, izvedbu i učinkovitost s jedne platforme.
Možete brzo (i, u nekim slučajevima, automatski) unijeti promjene u svoju infrastrukturu hibridnog oblaka nakon što steknete djelotvorno znanje o njoj, kao što je ispravljanje pogrešaka, rješavanje problema sigurnosti i usklađenosti te povećavanje i smanjivanje računarstva.
Ukratko, Data Fabric poboljšava implementaciju infrastrukture i učinkovitost održavanja, smanjuje troškove i povećava performanse.
Zašto biste trebali koristiti Data Fabric?
Svaka tvrtka usmjerena na podatke treba sveobuhvatnu strategiju koja nadilazi prepreke poput vremena, prostora, raznih vrsta softvera i lokacija podataka. Podaci ne bi trebali biti skriveni iza vatrozida ili raspršeni na nekoliko mjesta, već bi trebali biti dostupni ljudima kojima su potrebni.
Da bi uspjele, tvrtke trebaju podatkovno rješenje za budućnost i sigurno, učinkovito, jedinstveno okruženje. To se može učiniti pomoću podatkovne tkanine.
Potrebe modernih tvrtki za povezivanjem u stvarnom vremenu, samoposluživanjem, automatizacijom i univerzalnim promjenama ne mogu se zadovoljiti tradicionalnom integracijom podataka.
Iako prikupljanje podataka iz mnogih izvora često nije problem, mnoge tvrtke bore se s integracijom, obradom, kuriranjem i transformacijom podataka s podacima iz drugih izvora.
Kako bismo pružili dubinsko razumijevanje potrošača, partnera i robe, mora se dogoditi ovaj ključni korak u procesu upravljanja podacima. Zbog njihove sposobnosti da nadograde svoje sustave, bolje služe klijentima i iskoriste cloud computing, tvrtke kao rezultat dobivaju konkurentsku prednost.
Gdje god se nalazili korisnici organizacije, podatkovna tkanina može se zamisliti kao tkanina koja je raširena globalno. Na ovoj mreži korisnik može biti na bilo kojem mjestu i još uvijek imati neograničen pristup podacima u stvarnom vremenu na bilo kojem drugom mjestu.
Osnovne komponente Data Fabric-a
Osnovne komponente koje čine strukturu podataka mogu se birati i prikupljati na razne načine. Podatkovna tkanina se stoga može implementirati na različite načine. Pogledajmo primarne elemente podatkovne strukture.
- Katalog proširenih podataka
- Sloj postojanosti
- Znanje Graf
- Motor za uvide i preporuke
- Sloj pripreme i dostave podataka
- Orkestracija i operacije podataka
Možete pogledati ključne stupove Data Fabric arhitekture prema Gartner.
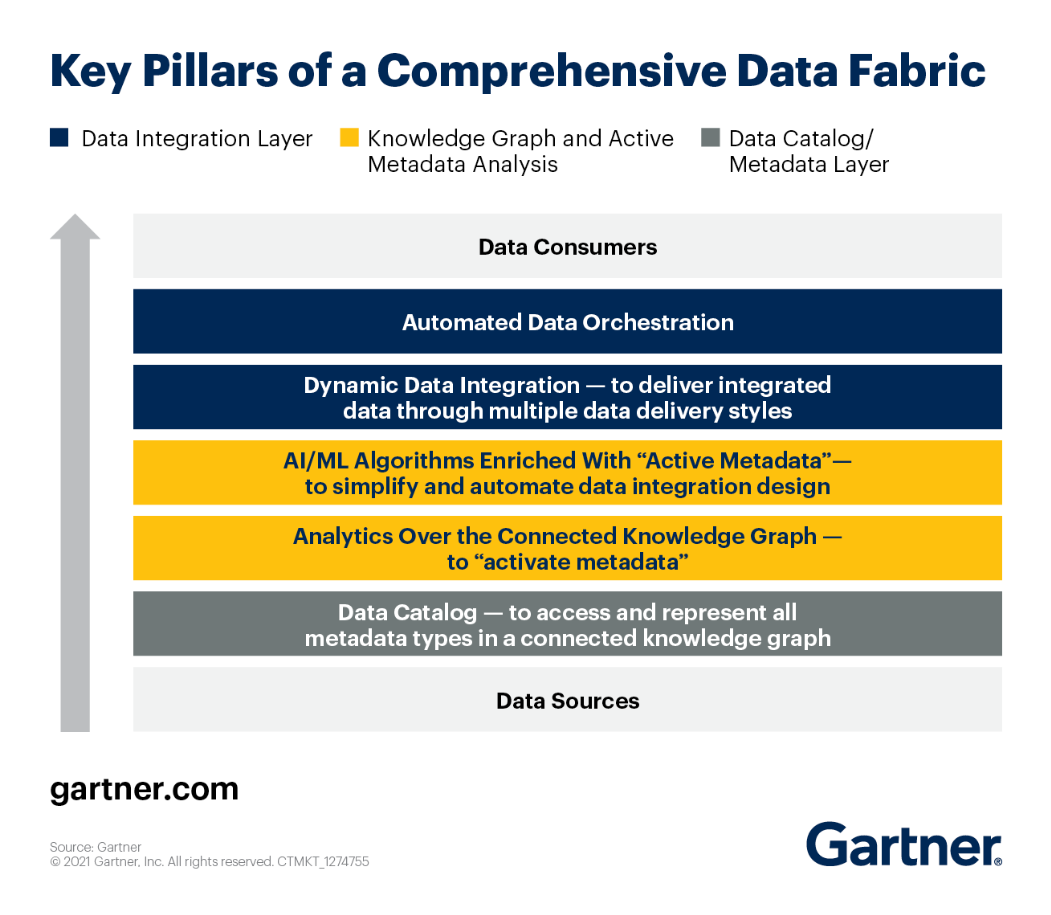
Pogledajmo svaki od njih pobliže.
- Katalog proširenih podataka – korisnicima daje pristup svim vrstama metapodataka putem snažnog grafikona znanja. Osim toga, razvija različite asocijacije između postojećih informacija i vizualno ih prikazuje na razumljiv način. Pomoću stroj za učenje za povezivanje podatkovne imovine s organizacijskom terminologijom, poboljšani katalozi podataka stvaraju poslovni semantički sloj za strukturu podataka.
- Sloj postojanosti – Ovisno o slučaju uporabe, za dinamičko pohranjivanje podataka mogu se koristiti različiti relacijski i nerelacijski modeli.
- Aktivni metapodaci – razlikovni dio podatkovne strukture. daje strukturi podataka mogućnost prikupljanja, dijeljenja i analize mnogih vrsta metapodataka. Za razliku od pasivnih metapodataka, aktivni metapodaci prate stalnu upotrebu podataka od strane sustava i ljudi (metapodaci koji se temelje na dizajnu i metapodaci u vremenu izvođenja).
- Znanje Graf – Još jedna temeljna jedinica za podatkovne tkanine. Oni koriste standardne ID-ove, prilagodljive sheme itd. za prikaz okruženja povezanih podataka. Grafikoni znanja čine strukturu podataka pretraživom i pomažu u njezinu razumijevanju.
- Motor za uvide i preporuke – gradi pouzdane, snažne podatkovne kanale za operativne i analitičke slučajeve uporabe.
- Sloj pripreme i dostave podataka – Podaci se mogu dohvatiti iz bilo kojeg izvora i poslati bilo kojem cilju koristeći bilo koji mehanizam, uključujući ETL (skupno), slanje poruka, CDC, virtualizaciju i API.
- Orkestracija i operacije podataka – Ova komponenta koristi podatke za koordinaciju svih zadataka u svakoj fazi tijeka rada od početka do kraja. Omogućuje vam da odaberete kada i koliko često pokretati cjevovode kao i kako upravljati podacima koje ti cjevovodi proizvode.
Prednosti
Zdravi podaci u distribuiranom kontekstu su dostupni, učitani, integrirani i dijeljeni preko podatkovne mreže. Čineći to, tvrtke mogu ubrzati digitalnu tranziciju i maksimalno povećati vrijednost svojih podataka.
U nastavku su navedene ključne prednosti modela podatkovne strukture.
Učinkovitost:
Tvornica podataka može kompilirati rezultate iz ranijih upita, omogućujući sustavu da skenira agregiranu tablicu umjesto neobrađenih podataka u pozadini.
Zbog bržeg vremena odgovora pojedinačnih zahtjeva, dopuštanje zahtjevima da pristupe manjim skupovima podataka umjesto skeniranja neobrađenih podataka cijele trgovine također rješava problem nekoliko istodobnih zahtjeva.
Poduzeća mogu brzo odgovoriti na hitne upite zbog sposobnosti podatkovne strukture da značajno skrati vrijeme odgovora na upite.
Pametna integracija
Za integraciju podataka kroz različite vrste podataka i krajnje točke, podatkovne strukture koriste semantičke grafikone znanja, upravljanje metapodacima i strojno učenje.
To pomaže timovima za upravljanje podacima da zajedno grupiraju relevantne skupove podataka i uključe potpuno nove izvore podataka u podatkovni ekosustav tvrtke.
Ova značajka automatizira dijelove upravljanja zadacima podataka, što rezultira gore navedenim uštedama produktivnosti, ali također pomaže u razbijanju silosa podatkovnog sustava, centraliziranju postupaka upravljanja podacima i poboljšanju ukupne kvalitete podataka.
Učinkovitija sigurnost podataka
To također ne podrazumijeva žrtvovanje sigurnosti podataka i zaštite privatnosti radi proširenja pristupa podacima.
Zapravo, to zahtijeva pooštravanje zaštitnih ograda za kontrolu pristupa i provedbu više mjera za upravljanje podacima kako bi se zajamčilo da određene uloge jedine imaju pristup određenom skupu podataka.
Osim toga, strukture podatkovne strukture omogućuju tehničke i sigurnosni timovi za implementaciju maskiranja podataka i šifriranje oko povjerljivih i osjetljivih informacija, smanjujući vjerojatnost dijeljenja podataka i hakiranja sustava.
Demokratizacija podataka
Samouslužne aplikacije olakšane su dizajnom podatkovne strukture, proširujući doseg pristupa podacima izvan više tehničkog osoblja poput podatkovnih inženjera, programera i timova za analizu podataka.
Omogućujući poslovnim korisnicima da donose brže poslovne odluke i puštajući tehničke korisnike da daju prioritet aktivnostima koje najbolje iskorištavaju njihove vještine, uklanjanje uskih grla podataka dovodi do povećanja produktivnosti.
Koristite slučajevi
Arhitektura podatkovne strukture namijenjena je ponudi sveobuhvatne strukture za rukovanje svim oblicima pohranjenih informacija tako da se mogu učiniti upotrebljivima kada je potrebno.
Ove vrste podataka mogu se koristiti za bilo što, od predviđanja prodaje do izvješća o stanju IT infrastrukture organizacije ili korisničkih krajnjih točaka.
Slučajevi upotrebe arhitekture podatkovne strukture identični su slučajevima upotrebe za bilo koju drugu vrstu podataka u poslovanju, uključujući prodaju, marketing, IT, kibersigurnost itd.
Međutim, podaci u organizaciji često su organizirani, polustrukturirani ili nestrukturirani u gotovo svim slučajevima upotrebe. Relacijska baza podataka može pohranjivati strukturirane podatke i odmah se koristiti, kao što su zapisi baze podataka.
Podaci koji nisu očišćeni ili kategorizirani nazivaju se nestrukturiranim podacima i moraju se pripremiti za korištenje po potrebi.
Uključuje nekoliko oblika nestrukturiranih podataka koje mnoge tvrtke mogu nabaviti i pohraniti za buduću upotrebu stroj za učenje, analitiku, podatke senzora, računalstvo u oblaku i aplikacije za produktivnost.
U polustrukturiranim podacima, koji uključuju podatke prepoznate vrste spremljene s nestrukturiranim podacima (kao što su zip datoteke, web stranice i e-pošta), prisutna su oba aspekta.
Brojni mogući slučajevi upotrebe koji se temelje na kapacitetu podatkovne strukture da pomogne tvrtkama u bržem i učinkovitijem pristupu i korištenju njihovih podataka mogu se pronaći istraživanjem njezine upotrebe.
Tipični primjeri uključuju:
- Otkrivanje prijevare
- IoT analitika
- Logistika opskrbnog lanca
- Analitika podataka u stvarnom vremenu
- Inteligencija kupaca
- Povećanje operativne učinkovitosti
- Analiza preventivnog održavanja
- Dodatno, modeli rizika povratka na posao
- Osiguranje transakcija kreditnim karticama
- Predviđanje odljeva, otkrivanje prijevara i kreditno bodovanje
Zaključak
Zaključno, silosi podataka moraju se postupno raspadati kako se naše razine upotrebe podataka povećavaju kako bi se napravilo mjesta za povezane tvrtke.
Uvođenje podatkovnih struktura predstavlja značajan napredak na tom putu, svrstavajući se među najrevolucionarnija otkrića od razvoja relacijskih baza podataka 1970-ih.
To je tako jer je data fabric više od tehnologije ili jedne stavke.
Podaci i poslovne operacije zamršeno su isprepleteni kroz dizajn arhitekture, sustavnu proceduru i promjenu mentaliteta.
Data Fabric smanjuje troškove, povećava performanse i olakšava učinkovitiju implementaciju i održavanje infrastrukture. To bi mogla biti ključna komponenta za osiguravanje da svaki proces, aplikacija i poslovna odluka budu vođeni podacima.





Ostavi odgovor