वीडियो गेम दुनिया भर के अरबों खिलाड़ियों को चुनौती देना जारी रखता है। आप इसे अभी तक नहीं जानते होंगे, लेकिन मशीन लर्निंग एल्गोरिदम ने भी चुनौती का सामना करना शुरू कर दिया है।
वीडियो गेम में मशीन सीखने के तरीकों को लागू किया जा सकता है या नहीं, यह देखने के लिए एआई के क्षेत्र में वर्तमान में काफी शोध है। इस क्षेत्र में पर्याप्त प्रगति दर्शाती है कि यंत्र अधिगम एजेंटों का उपयोग मानव खिलाड़ी का अनुकरण करने या उसे बदलने के लिए भी किया जा सकता है।
के भविष्य के लिए इसका क्या अर्थ है वीडियो गेम?
क्या ये प्रोजेक्ट केवल मनोरंजन के लिए हैं, या क्या ऐसे गहरे कारण हैं कि इतने सारे शोधकर्ता खेलों पर ध्यान केंद्रित कर रहे हैं?
यह लेख संक्षेप में वीडियो गेम में एआई के इतिहास का पता लगाएगा। बाद में, हम आपको कुछ मशीन लर्निंग तकनीकों का त्वरित अवलोकन देंगे जिनका उपयोग हम गेम को हराने के तरीके सीखने के लिए कर सकते हैं। इसके बाद हम के कुछ सफल अनुप्रयोगों को देखेंगे तंत्रिका जाल विशिष्ट वीडियो गेम सीखने और मास्टर करने के लिए।
गेमिंग में एआई का संक्षिप्त इतिहास
इससे पहले कि हम वीडियो गेम को हल करने के लिए न्यूरल नेट आदर्श एल्गोरिथम क्यों बन गए हैं, आइए संक्षेप में देखें कि कैसे कंप्यूटर वैज्ञानिकों ने एआई में अपने शोध को आगे बढ़ाने के लिए वीडियो गेम का उपयोग किया है।
आप तर्क दे सकते हैं कि, अपनी स्थापना से, एआई में रुचि रखने वाले शोधकर्ताओं के लिए वीडियो गेम अनुसंधान का एक गर्म क्षेत्र रहा है।
हालांकि मूल रूप से एक वीडियो गेम नहीं है, एआई के शुरुआती दिनों में शतरंज एक बड़ा फोकस रहा है। 1951 में, डॉ. डिट्रिच प्रिंज़ ने फेरांती मार्क 1 डिजिटल कंप्यूटर का उपयोग करते हुए एक शतरंज-खेलने का कार्यक्रम लिखा। यह उस युग में वापस आ गया था जब इन भारी कंप्यूटरों को कागज़ के टेप से प्रोग्राम पढ़ना पड़ता था।

कार्यक्रम अपने आप में एक पूर्ण शतरंज एआई नहीं था। कंप्यूटर की सीमाओं के कारण, प्रिंज़ केवल एक ऐसा प्रोग्राम बना सका जो मेट-इन-टू शतरंज की समस्याओं को हल कर सके। श्वेत और अश्वेत खिलाड़ियों के लिए हर संभव कदम की गणना करने में औसतन 15-20 मिनट का समय लगा।
शतरंज और चेकर्स एआई में सुधार के काम में पूरे दशकों में लगातार सुधार हुआ है। प्रगति 1997 में अपने चरमोत्कर्ष पर पहुंच गई जब आईबीएम के डीप ब्लू ने रूसी शतरंज ग्रैंडमास्टर गैरी कास्परोव को छह-गेम मैचों की एक जोड़ी में हराया। आजकल, शतरंज के इंजन जो आप अपने मोबाइल फोन पर पा सकते हैं, डीप ब्लू को हरा सकते हैं।
वीडियो आर्केड गेम के स्वर्ण युग के दौरान एआई विरोधियों ने लोकप्रियता हासिल करना शुरू कर दिया। 1978 के अंतरिक्ष आक्रमणकारी और 1980 के दशक के पीएसी-मैन एआई बनाने में उद्योग के कुछ अग्रणी हैं जो आर्केड गेमर्स के सबसे अनुभवी को भी पर्याप्त रूप से चुनौती दे सकते हैं।
पीएसी-मैन, विशेष रूप से, एआई शोधकर्ताओं के प्रयोग के लिए एक लोकप्रिय खेल था। विविध प्रतियोगिताओं सुश्री पीएसी-मैन के लिए यह निर्धारित करने के लिए आयोजित किया गया है कि कौन सी टीम खेल को हराने के लिए सर्वश्रेष्ठ एआई के साथ आ सकती है।
जैसे-जैसे होशियार विरोधियों की आवश्यकता उत्पन्न हुई, गेम एआई और अनुमानी एल्गोरिदम विकसित होते रहे। उदाहरण के लिए, मुकाबला एआई लोकप्रियता में बढ़ गया क्योंकि पहले व्यक्ति निशानेबाजों जैसे शैलियों अधिक मुख्यधारा बन गए।
वीडियो गेम में मशीन लर्निंग
जैसे-जैसे मशीन लर्निंग तकनीक लोकप्रियता में तेजी से बढ़ी, विभिन्न शोध परियोजनाओं ने वीडियो गेम खेलने के लिए इन नई तकनीकों का उपयोग करने की कोशिश की।
Dota 2, StarCraft, और Doom जैसे गेम इनके लिए समस्या का काम कर सकते हैं मशीन लर्निंग एल्गोरिदम का समाधान। गहन शिक्षण एल्गोरिदम, विशेष रूप से, मानव-स्तर के प्रदर्शन को प्राप्त करने और उससे भी आगे निकलने में सक्षम थे।
RSI आर्केड सीखना पर्यावरण या ALE ने शोधकर्ताओं को सौ से अधिक अटारी 2600 खेलों के लिए एक इंटरफ़ेस दिया। ओपन-सोर्स प्लेटफॉर्म ने शोधकर्ताओं को क्लासिक अटारी वीडियो गेम पर मशीन लर्निंग तकनीकों के प्रदर्शन को बेंचमार्क करने की अनुमति दी। Google ने अपना खुद का भी प्रकाशित किया काग़ज़ ALE . से सात गेम का उपयोग करना

इस बीच, परियोजनाओं की तरह विज़डूम एआई शोधकर्ताओं को 3डी फर्स्ट-पर्सन शूटर खेलने के लिए मशीन लर्निंग एल्गोरिदम को प्रशिक्षित करने का अवसर दिया।

यह कैसे काम करता है: कुछ प्रमुख अवधारणाएं
तंत्रिका नेटवर्क
मशीन लर्निंग के साथ वीडियो गेम को हल करने के अधिकांश तरीकों में एक प्रकार का एल्गोरिदम शामिल होता है जिसे तंत्रिका नेटवर्क के रूप में जाना जाता है।
आप एक तंत्रिका जाल के बारे में एक प्रोग्राम के रूप में सोच सकते हैं जो नकल करने की कोशिश करता है कि मस्तिष्क कैसे कार्य कर सकता है। जिस तरह हमारा मस्तिष्क एक सिग्नल संचारित करने वाले न्यूरॉन्स से बना होता है, उसी तरह एक तंत्रिका जाल में भी कृत्रिम न्यूरॉन्स होते हैं।
ये कृत्रिम न्यूरॉन्स एक दूसरे को संकेत भी स्थानांतरित करते हैं, प्रत्येक संकेत एक वास्तविक संख्या है। एक तंत्रिका जाल में इनपुट और आउटपुट परतों के बीच कई परतें होती हैं, जिन्हें डीप न्यूरल नेटवर्क कहा जाता है।
सुदृढीकरण सीखना
वीडियो गेम सीखने के लिए प्रासंगिक एक अन्य सामान्य मशीन लर्निंग तकनीक सुदृढीकरण सीखने का विचार है।
यह तकनीक एक एजेंट को पुरस्कार या दंड का उपयोग करके प्रशिक्षित करने की प्रक्रिया है। इस दृष्टिकोण के साथ, एजेंट को परीक्षण और त्रुटि के माध्यम से किसी समस्या का समाधान निकालने में सक्षम होना चाहिए।
मान लीजिए कि हम चाहते हैं कि एआई यह पता लगाए कि गेम स्नेक कैसे खेलें। खेल का उद्देश्य सरल है: वस्तुओं का उपभोग करके और अपनी बढ़ती पूंछ से बचकर अधिक से अधिक अंक प्राप्त करें।
सुदृढीकरण सीखने के साथ, हम एक इनाम समारोह आर को परिभाषित कर सकते हैं। जब सांप एक वस्तु का उपभोग करता है तो फ़ंक्शन अंक जोड़ता है और जब सांप एक बाधा को मारता है तो अंक काटता है। वर्तमान परिवेश और संभावित कार्रवाइयों के एक सेट को देखते हुए, हमारा सुदृढीकरण सीखने का मॉडल इष्टतम 'नीति' की गणना करने का प्रयास करेगा जो हमारे इनाम समारोह को अधिकतम करता है।
तंत्रिका विकास
प्रकृति से प्रेरित होने के विषय को ध्यान में रखते हुए, शोधकर्ताओं ने न्यूरोइवोल्यूशन नामक तकनीक के माध्यम से वीडियो गेम में एमएल लागू करने में भी सफलता पाई है।
के बजाय का उपयोग करने का ढतला हुआ वंश किसी नेटवर्क में न्यूरॉन्स को अद्यतन करने के लिए, हम बेहतर परिणाम प्राप्त करने के लिए विकासवादी एल्गोरिदम का उपयोग कर सकते हैं।
विकासवादी एल्गोरिदम आमतौर पर यादृच्छिक व्यक्तियों की प्रारंभिक आबादी उत्पन्न करके शुरू होते हैं। फिर हम कुछ मानदंडों का उपयोग करके इन व्यक्तियों का मूल्यांकन करते हैं। सर्वश्रेष्ठ व्यक्तियों को "माता-पिता" के रूप में चुना जाता है और नई पीढ़ी के व्यक्तियों को बनाने के लिए एक साथ पाला जाता है। ये व्यक्ति तब आबादी में सबसे कम फिट व्यक्तियों की जगह लेंगे।
ये एल्गोरिदम आमतौर पर आनुवंशिक विविधता को बनाए रखने के लिए क्रॉसओवर या "प्रजनन" चरण के दौरान कुछ प्रकार के उत्परिवर्तन ऑपरेशन का परिचय देते हैं।
वीडियो गेम में मशीन लर्निंग पर नमूना अनुसंधान
OpenAI पाँच

OpenAI पाँच OpenAI का एक कंप्यूटर प्रोग्राम है जिसका उद्देश्य DOTA 2, एक लोकप्रिय मल्टीप्लेयर मोबाइल बैटल एरीना (MOBA) गेम खेलना है।
कार्यक्रम ने मौजूदा सुदृढीकरण सीखने की तकनीक का लाभ उठाया, जिसे लाखों फ्रेम प्रति सेकंड से सीखने के लिए बढ़ाया गया। एक वितरित प्रशिक्षण प्रणाली के लिए धन्यवाद, ओपनएआई प्रत्येक दिन 180 साल के खेल खेलने में सक्षम था।
प्रशिक्षण अवधि के बाद, OpenAI Five विशेषज्ञ स्तर के प्रदर्शन को प्राप्त करने और मानव खिलाड़ियों के साथ सहयोग प्रदर्शित करने में सक्षम था। 2019 में, OpenAI पांच सक्षम था हार सार्वजनिक मैचों में 99.4% खिलाड़ी।
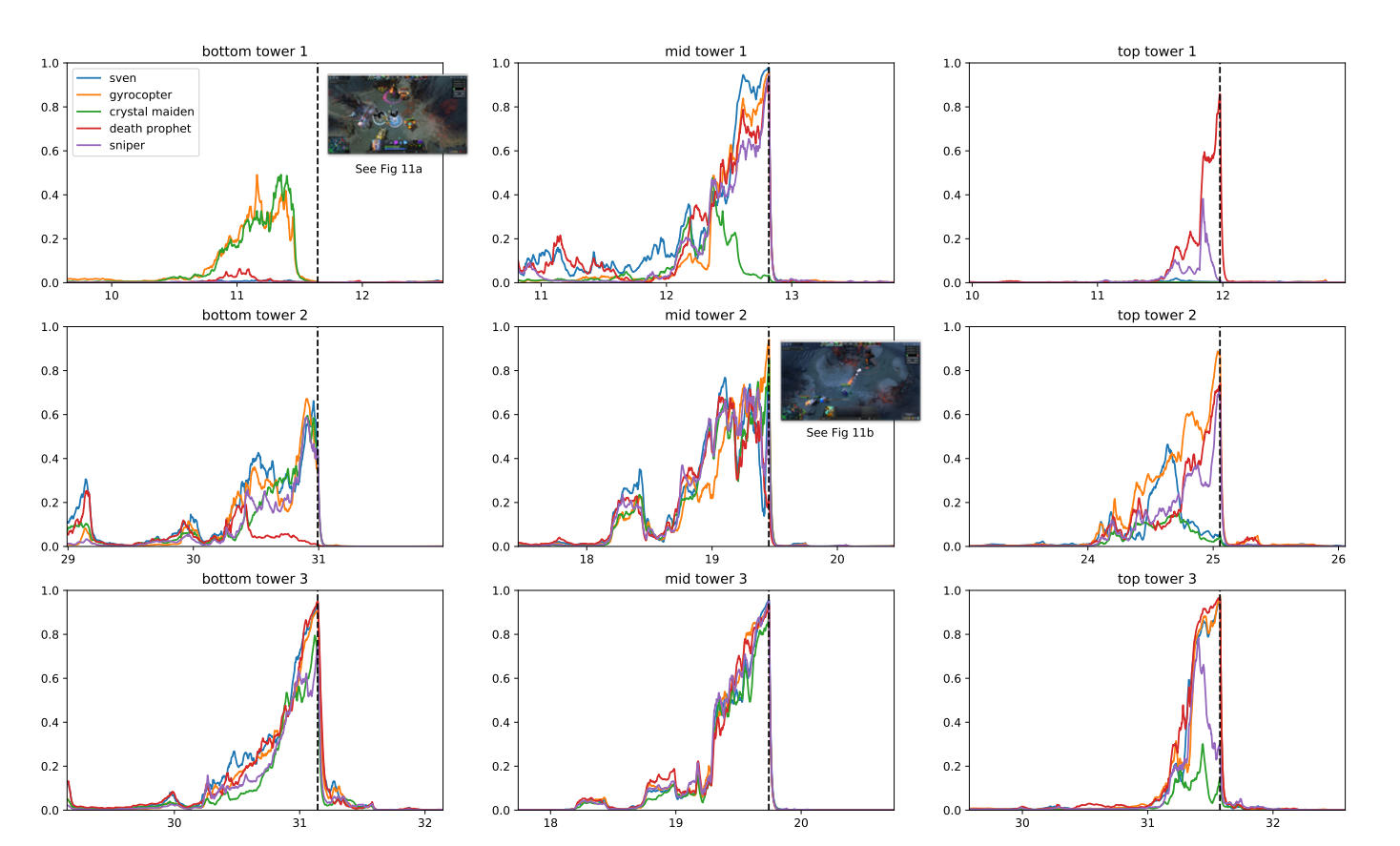
OpenAI ने इस गेम का निर्णय क्यों लिया? शोधकर्ताओं के अनुसार, DOTA 2 में जटिल यांत्रिकी थी जो मौजूदा गहराई की पहुंच से बाहर थी सुदृढीकरण सीखना एल्गोरिदम।
सुपर मारियो Bros
वीडियो गेम में तंत्रिका जाल का एक और दिलचस्प अनुप्रयोग सुपर मारियो ब्रदर्स जैसे प्लेटफ़ॉर्मर्स को चलाने के लिए न्यूरोएवोल्यूशन का उपयोग है।
उदाहरण के लिए, यह हैकाथॉन प्रविष्टि खेल का कोई ज्ञान नहीं होने के साथ शुरू होता है और धीरे-धीरे एक स्तर के माध्यम से प्रगति के लिए जो आवश्यक है उसकी नींव बनाता है।
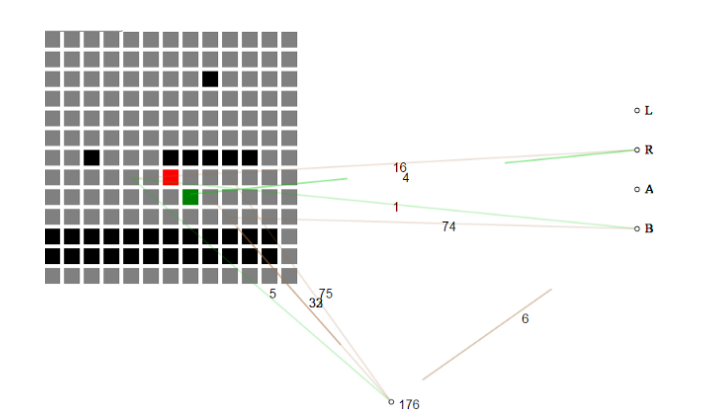
स्व-विकसित तंत्रिका जाल खेल की वर्तमान स्थिति को टाइलों के ग्रिड के रूप में लेता है। सबसे पहले, तंत्रिका जाल को इस बात की कोई समझ नहीं है कि प्रत्येक टाइल का क्या अर्थ है, केवल यह कि "हवा" टाइलें "ग्राउंड टाइल" और "दुश्मन टाइल" से अलग हैं।
हैकाथॉन परियोजना के एक न्यूरोएवोल्यूशन के कार्यान्वयन ने एनईएटी आनुवंशिक एल्गोरिथम का उपयोग विभिन्न तंत्रिका जालों को चुनिंदा रूप से प्रजनन करने के लिए किया।
महत्व
अब जब आपने वीडियो गेम खेलने वाले तंत्रिका जाल के कुछ उदाहरण देखे हैं, तो आप सोच रहे होंगे कि इस सब का क्या मतलब है।
चूंकि वीडियो गेम में एजेंटों और उनके वातावरण के बीच जटिल बातचीत शामिल होती है, इसलिए यह AI बनाने के लिए एकदम सही परीक्षण का मैदान है। आभासी वातावरण सुरक्षित और नियंत्रणीय हैं और डेटा की अनंत आपूर्ति प्रदान करते हैं।
इस क्षेत्र में किए गए शोध ने शोधकर्ताओं को यह जानकारी दी है कि वास्तविक दुनिया में समस्याओं को कैसे हल किया जाए, यह जानने के लिए तंत्रिका जाल को कैसे अनुकूलित किया जा सकता है।
तंत्रिका जाल प्राकृतिक दुनिया में दिमाग कैसे काम करता है, इससे प्रेरित हैं। वीडियो गेम खेलना सीखते समय कृत्रिम न्यूरॉन्स कैसे व्यवहार करते हैं, इसका अध्ययन करके, हम यह भी समझ सकते हैं कि कैसे मानव मस्तिष्क काम करता है।
निष्कर्ष
तंत्रिका नेटवर्क और मस्तिष्क के बीच समानता ने दोनों क्षेत्रों में अंतर्दृष्टि पैदा की है। तंत्रिका जाल कैसे समस्याओं को हल कर सकते हैं, इस पर निरंतर शोध से किसी दिन और अधिक उन्नत रूप हो सकते हैं कृत्रिम बुद्धिमत्ता.
अपने विनिर्देशों के अनुरूप एआई का उपयोग करने की कल्पना करें जो आपके द्वारा खरीदे जाने से पहले एक संपूर्ण वीडियो गेम चला सकता है ताकि आपको पता चल सके कि यह आपके समय के लायक है या नहीं। क्या वीडियो गेम कंपनियां गेम डिज़ाइन, ट्वीक स्तर और प्रतिद्वंद्वी कठिनाई को बेहतर बनाने के लिए तंत्रिका जाल का उपयोग करेंगी?
आपको क्या लगता है जब तंत्रिका जाल परम गेमर बन जाएंगे तो क्या होगा?





एक जवाब लिखें