विषय - सूची[छिपाना][प्रदर्शन]
- 1. पायथन स्क्रिप्टिंग क्या है, और यह पायथन प्रोग्रामिंग से कैसे भिन्न है?
- 2. पायथन का कचरा संग्रहण कैसे काम करता है?
- 3. सूची और टुपल के बीच अंतर स्पष्ट करें
- 4. सूची बोध क्या हैं और उनके उपयोग का एक उदाहरण दें?
- 5. डीपकॉपी और कॉपी के बीच अंतर बताएं?
- 6. पायथन में मल्टीथ्रेडिंग कैसे प्राप्त की जाती है और यह मल्टीप्रोसेसिंग से कैसे भिन्न है?
- 7. डेकोरेटर क्या हैं और पायथन में उनका उपयोग कैसे किया जाता है?
- 8. *आर्ग्स और **क्वार्ग्स के बीच अंतर स्पष्ट करें?
- 9. आप यह कैसे सुनिश्चित करेंगे कि किसी फ़ंक्शन को डेकोरेटर का उपयोग करके केवल एक बार ही कॉल किया जा सकता है?
- 10. पायथन में इनहेरिटेंस कैसे काम करता है?
- 11. मेथड ओवरलोडिंग और ओवरराइडिंग क्या है?
- 12. बहुरूपता की अवधारणा का उदाहरण सहित वर्णन करें।
- 13. इंस्टेंस, क्लास और स्टैटिक तरीकों के बीच अंतर स्पष्ट करें।
- 14. वर्णन करें कि पायथन सेट आंतरिक रूप से कैसे काम करता है।
- 15. पायथन में शब्दकोश कैसे लागू किया जाता है?
- 16. नामित टुपल्स के उपयोग के लाभ बताएं।
- 17. ट्राई-एक्सेप्ट ब्लॉक कैसे काम करता है?
- 18. उठाओ और जोर देने वाले कथनों के बीच क्या अंतर है?
- 19. आप पायथन में बाइनरी फ़ाइल से डेटा कैसे पढ़ते और लिखते हैं?
- 20. फ़ाइल I/O के साथ काम करते समय with कथन और इसके लाभों की व्याख्या करें।
- 21. आप पायथन में सिंगलटन मॉड्यूल कैसे बनाएंगे?
- 22. पायथन स्क्रिप्ट में मेमोरी उपयोग को अनुकूलित करने के कुछ तरीकों का नाम बताइए।
- 23. आप रेगेक्स का उपयोग करके किसी दिए गए स्ट्रिंग से सभी ईमेल पते कैसे निकालेंगे?
- 24. फ़ैक्टरी डिज़ाइन पैटर्न और पायथन में इसके अनुप्रयोग की व्याख्या करें
- 25. इटरेटर और जनरेटर के बीच क्या अंतर है?
- 26. @प्रॉपर्टी डेकोरेटर कैसे काम करता है?
- 27. आप पायथन में एक बुनियादी REST API कैसे बनाएंगे?
- 28. HTTP POST अनुरोध करने के लिए अनुरोध लाइब्रेरी का उपयोग करने का तरीका बताएं।
- 29. आप Python का उपयोग करके PostgreSQL डेटाबेस से कैसे जुड़ेंगे?
- 30. पायथन में ओआरएम की क्या भूमिका है और एक लोकप्रिय का नाम बताएं?
- 31. आप पायथन लिपि को कैसे प्रोफ़ाइल करेंगे?
- 32. सीपीथॉन में जीआईएल (ग्लोबल इंटरप्रेटर लॉक) की व्याख्या करें
- 33. पायथन के एसिंक/प्रतीक्षा को समझाइये। यह पारंपरिक थ्रेडिंग से किस प्रकार भिन्न है?
- 34. वर्णन करें कि आप पायथन के concurrent.futures का उपयोग कैसे करेंगे।
- 35. उपयोग के मामले और स्केलेबिलिटी के संदर्भ में Django और फ्लास्क की तुलना करें।
- निष्कर्ष
ऐसे समय में जब प्रौद्योगिकी हमारे जीवन के हर पहलू में मौजूद है, अजगर स्क्रिप्टिंग विशाल और जटिल आईटी बुनियादी ढांचे के एक प्रमुख घटक के रूप में उभरती है, जो उपयोग में आसानी और उपयोगिता के प्रतिमान की शुरुआत करती है।
पायथन की ताकत न केवल इसकी वाक्यात्मक सरलता और पठनीयता में निहित है, बल्कि इसकी अनुकूलनशीलता में भी निहित है, जो इसे कम जोखिम, शुरुआती स्तर की स्क्रिप्टिंग और उच्च-स्टेक, एंटरप्राइज़-स्तरीय सॉफ़्टवेयर विकास के बीच अंतर को आसानी से पाटने की अनुमति देती है।
पायथन की विस्तृत लाइब्रेरी और रूपरेखा एक तरल, कल्पनाशील तकनीकी साहसिक कार्य का मार्ग प्रशस्त करती है, चाहे वह डेटा विश्लेषण, वेब विकास, कृत्रिम बुद्धिमत्ता या नेटवर्क सर्वर के क्षेत्र में हो।
समस्या-समाधान के लिए एक उपकरण होने के अलावा, पायथन एक ऐसे माहौल को भी बढ़ावा देता है जहां नवाचार को न केवल अपनाया जाता है बल्कि स्वाभाविक रूप से इसके विशाल पुस्तकालयों और ढांचे के लिए धन्यवाद शामिल किया जाता है, जैसे कि वेब विकास के लिए Django या डेटा विश्लेषण के लिए पांडा।
ऐसी दुनिया में जहां डेटा राजा है, पायथन हेरफेर, विश्लेषण और के लिए शक्तिशाली उपकरण प्रदान करता है विज़ुअलाइज़िंग डेटा, जिसके परिणामस्वरूप कार्रवाई योग्य अंतर्दृष्टि और रणनीतिक विकल्पों का मार्गदर्शन मिलता है।
पायथन केवल एक प्रोग्रामिंग भाषा नहीं है; यह एक संपन्न समुदाय भी है, एक ऐसा केंद्र जहां डेवलपर्स, डेटा वैज्ञानिक और तकनीकी उत्साही आईटी उद्योग का आविष्कार, निर्माण और अगले स्तर पर ले जाने के लिए एक साथ आते हैं।
नवाचार, प्रक्रिया सुधार और बेहतर ग्राहक सेवा के उत्प्रेरक के रूप में, नए स्टार्टअप से लेकर अच्छी तरह से स्थापित संगठनों तक, सभी आकार के व्यवसायों द्वारा पायथन डेवलपर्स की मांग की जाती है।
इसके अतिरिक्त, इसकी ओपन-सोर्स प्रकृति साझा सीखने और सहयोगात्मक विकास की संस्कृति को बढ़ावा देती है, यह गारंटी देती है कि यह तेजी से बदलती तकनीकी दुनिया के साथ आगे बढ़ना जारी रखेगी।
2023 में पायथन सीखना एक ऐसी भाषा में निवेश है जो प्रौद्योगिकी के उतार-चढ़ाव के प्रबंधन के लिए वर्तमान, लचीली और आवश्यक बनी रहने का वादा करती है।
यह के क्षेत्रों तक पहुंच प्रदान करता है यंत्र अधिगम, डेटा एनालिटिक्स, साइबर सुरक्षा, और बहुत कुछ, ये सभी डिजिटल युग को आकार देने के लिए महत्वपूर्ण हैं।
इसलिए, हमने आपके लिए सर्वश्रेष्ठ पायथन स्क्रिप्टिंग साक्षात्कार प्रश्नों की एक सूची तैयार की है, जो आपको एक डेवलपर के रूप में चमकने और साक्षात्कार में सफल होने में सक्षम बनाएगी।
1. पायथन स्क्रिप्टिंग क्या है, और यह पायथन प्रोग्रामिंग से कैसे भिन्न है?
पायथन अपनी अनुकूलनशीलता के लिए जाना जाता है और स्क्रिप्टिंग और प्रोग्रामिंग कौशल दोनों प्रदान करता है, प्रत्येक विशेष नौकरियों और लक्ष्यों के लिए उपयुक्त है।
पायथन स्क्रिप्टिंग मूल रूप से छोटी, अधिक कुशल स्क्रिप्ट लिखने की प्रक्रिया है जिसका उद्देश्य फ़ाइलों को प्रबंधित करना, दोहराव वाली प्रक्रियाओं को स्वचालित करना या विचारों को जल्दी से प्रोटोटाइप करना है।
ये स्क्रिप्ट, जो अक्सर स्टैंड-अलोन होती हैं, क्रम में कार्यों की एक सूची को कुशलतापूर्वक पूरा करती हैं।
दूसरी ओर, पायथन प्रोग्रामिंग, पुस्तकालयों, रूपरेखाओं और सर्वोत्तम प्रथाओं का उपयोग करके संरचित कोड के साथ बड़े, अधिक जटिल कार्यक्रमों के निर्माण पर जोर देती है।
हालाँकि वे दोनों एक ही भाषा से आते हैं, स्क्रिप्टिंग सरल और स्वचालित होती है जबकि प्रोग्रामिंग बनाता और आविष्कार करता है। यह अंतर प्रत्येक अनुशासन के दायरे और लक्ष्यों में देखा जा सकता है।
2. पायथन का कचरा संग्रहण कैसे काम करता है?
प्रभावी मेमोरी प्रबंधन सुनिश्चित करने में एक प्रमुख तत्व पायथन की कचरा संग्रहण प्रणाली है।
यह सिस्टम संसाधनों को मेमोरी लीक से ओवररन होने से बचाने के लिए पृष्ठभूमि में अथक रूप से काम करता है। यह स्वचालित दृष्टिकोण अधिकतर संदर्भ गिनती पद्धति पर आधारित है, जहां प्रत्येक वस्तु इस बात पर नज़र रखती है कि कितनी अन्य वस्तुएँ उसे संदर्भित कर रही हैं।
जब यह गिनती 0 तक गिर जाती है तो यह ऑब्जेक्ट मेमोरी रिक्लेमेशन के लिए उम्मीदवार बन जाता है, जो इंगित करता है कि आइटम की अब आवश्यकता नहीं है।
इसके अलावा, संदर्भ चक्रों को खोजने और साफ़ करने के लिए पायथन एक चक्रीय कचरा संग्रहकर्ता का उपयोग करता है, जिसे सरल संदर्भ गणना दृष्टिकोण याद कर सकता है।
इस प्रकार, संदर्भ गिनती और चक्रीय कचरा संग्रह दोहरी-स्तरित रणनीति मेमोरी का सावधानीपूर्वक और प्रभावी उपयोग प्रदान करती है, विशेष रूप से मेमोरी-गहन अनुप्रयोगों में पायथन के प्रदर्शन को मजबूत करती है।
पायथन के कचरा संग्रहण प्रणाली के साथ इंटरफ़ेस करने का तरीका दिखाने वाला एक सरल कोड नमूना नीचे दिया गया है:
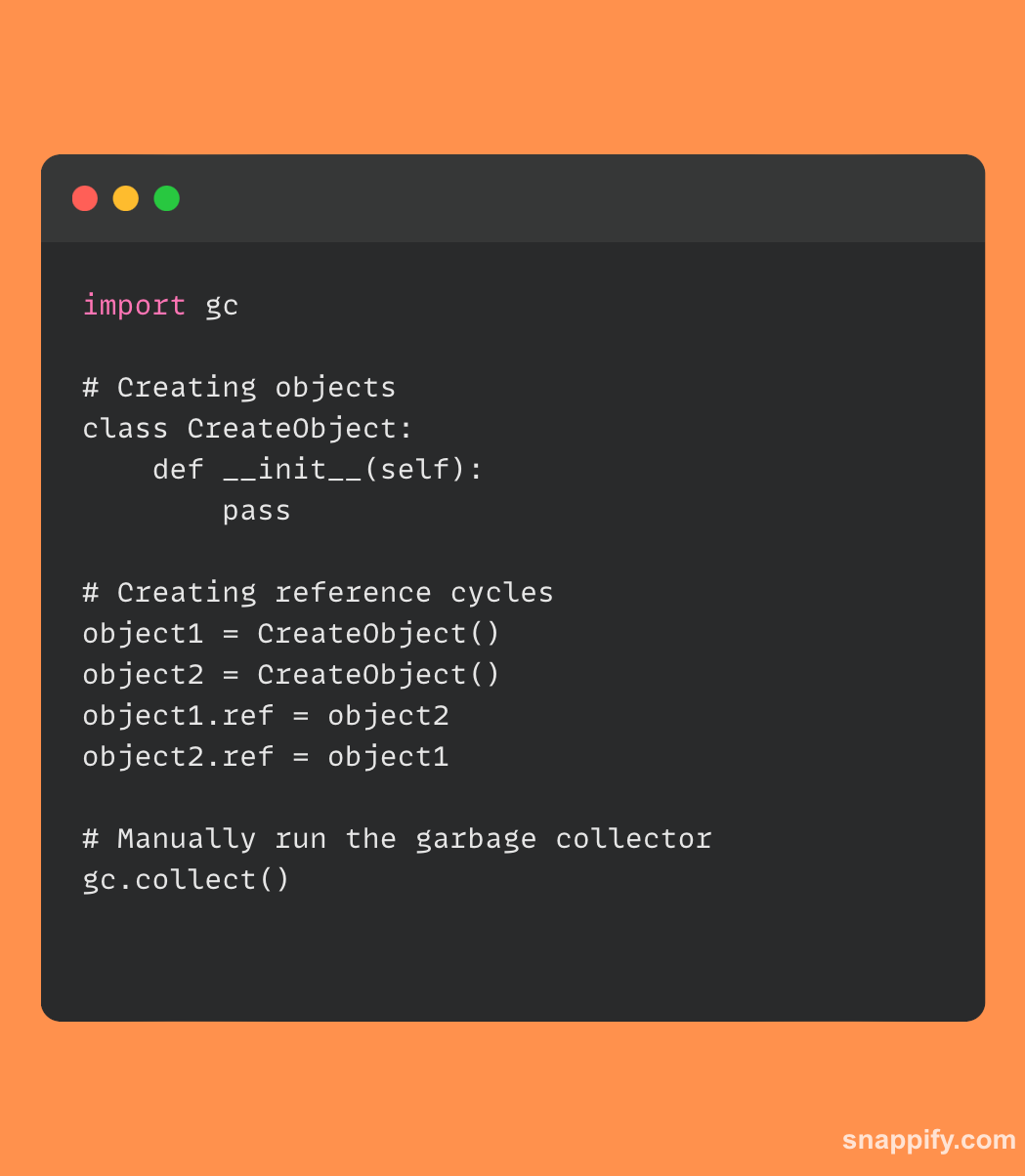
इस अंश में दो वस्तुएं उत्पन्न होती हैं और एक चक्र स्थापित करने के लिए क्रॉस-रेफ़र किया जाता है। फिर कचरा संग्रहकर्ता को मैन्युअल रूप से gc.collect() का उपयोग करके चालू किया जाता है, जिससे पता चलता है कि प्रोग्रामर आवश्यकतानुसार पायथन के मेमोरी प्रबंधन तंत्र के साथ कैसे जुड़ सकते हैं।
3. सूची और टुपल के बीच अंतर स्पष्ट करें
पायथन दुनिया में डेटा के लिए सूचियाँ और टुपल्स प्रभावी कंटेनर हैं, लेकिन उनके पास अलग-अलग गुण हैं जो विभिन्न प्रोग्रामिंग उद्देश्यों को पूरा करते हैं।
वर्गाकार कोष्ठकों द्वारा दर्शाई गई एक सूची, अपने घटकों के बदलते और गतिशील आकार बदलने की अनुमति देकर लचीलेपन को सक्षम बनाती है।
दूसरी ओर, कोष्ठक में संलग्न टपल अपरिवर्तनीय है और फ़ंक्शन निष्पादित होने के दौरान अपनी प्रारंभिक स्थिति बनाए रखता है।
टुपल्स एक ठोस, अपरिवर्तनीय अनुक्रम देते हैं जबकि सूचियाँ लचीलापन प्रदान करती हैं, जिससे डेटा प्रोसेसिंग और संशोधन में विभिन्न प्रकार के उपयोग की अनुमति मिलती है।
यहाँ थोड़ा है पायथन कोड नमूना दिखाता है कि सूचियों और टुपल्स दोनों का उपयोग कैसे करें:

4. सूची बोध क्या हैं और उनके उपयोग का एक उदाहरण दें?
सूची समझ पायथन में सूचियाँ बनाने का एक कुशल और अभिव्यंजक तरीका है जो सशर्त तर्क और लूप की शक्ति को कोड की एक, समझने योग्य पंक्ति में जोड़ती है।
वे हमारे इरादों को एक सूची में बदलने के लिए एक सरल वाक्यविन्यास प्रदान करते हैं, पुनरावृत्ति और सशर्तता को एक एकल, परिष्कृत संरचना में जोड़ते हैं।
सूची समझ अनिवार्य रूप से प्रोग्रामर को प्रत्येक सदस्य पर परिचालन निष्पादित करके सूचियां बनाने की क्षमता देती है और शायद एक साफ कोडबेस रखते हुए, कुछ मानदंडों के आधार पर उन्हें फ़िल्टर कर सकती है।
यह अभिव्यंजक सुविधा पठनीयता में सुधार करके पायथन प्रोग्रामिंग में स्पष्टता के साथ दक्षता को जोड़ती है जबकि संभवतः कुछ परिस्थितियों में कम्प्यूटेशनल लाभ भी प्रदान करती है।
पायथन सूची समझ का एक उदाहरण नीचे दिखाया गया है:
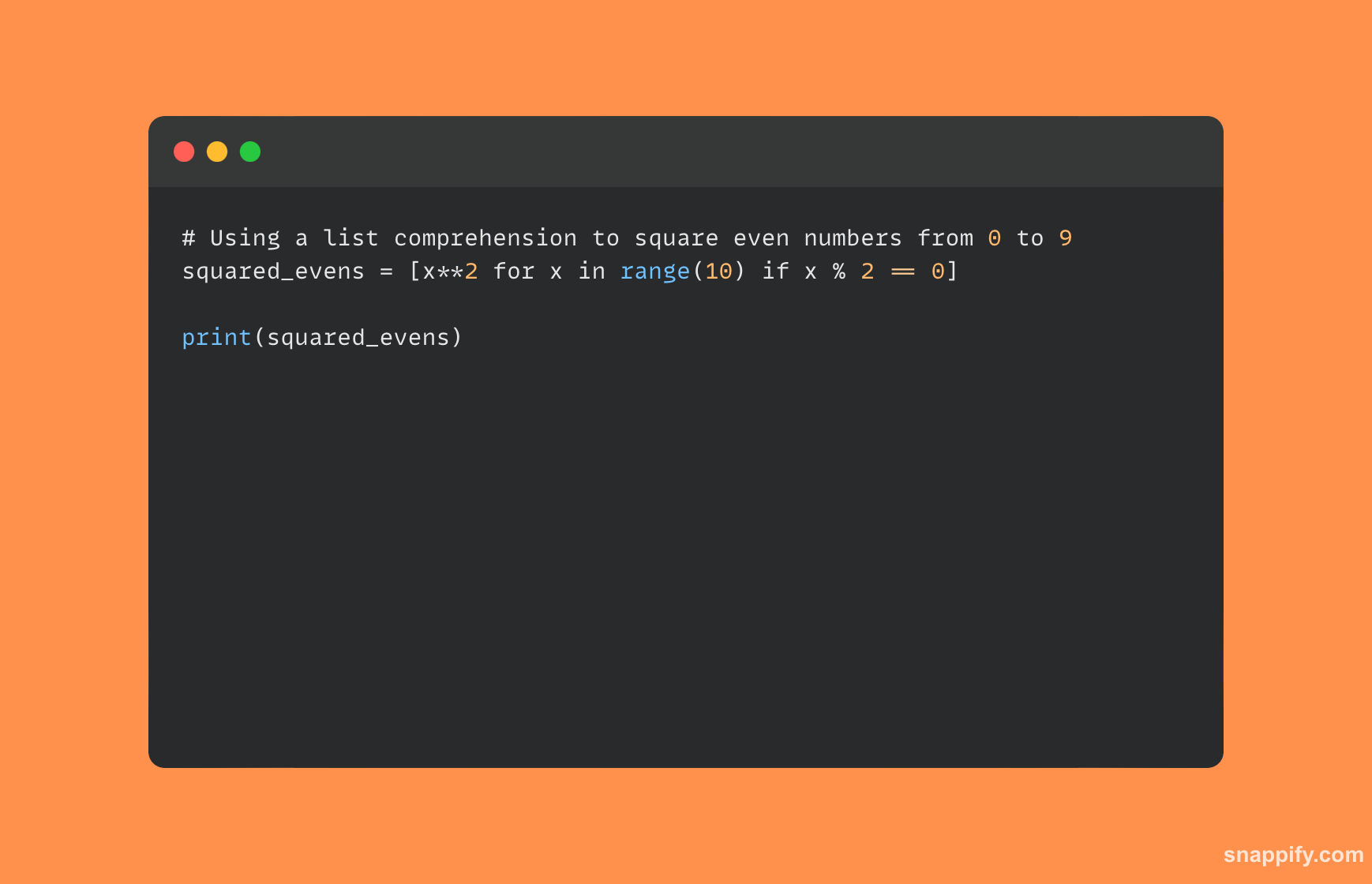
5. डीपकॉपी और कॉपी के बीच अंतर बताएं?
डुप्लिकेट की गई वस्तुओं की गहराई और अखंडता उनके बीच अंतर निर्धारित करती है deepcopy और copy अजगर में।
मूल नेस्टेड वस्तुओं का संदर्भ रखते हुए एक नया आइटम बनाकर, a copy एक उथली प्रतिकृति बनाता है जो उनके भाग्य को परस्पर निर्भरता के जाल में एक साथ बुनता है।
Deepcopy मूल वस्तु और उसके सभी पदानुक्रमित घटकों को पुनरावर्ती रूप से कॉपी करके, सभी कनेक्शनों को काटकर और परिवर्तनों में स्वायत्तता बनाए रखकर एक पूरी तरह से स्वायत्त क्लोन बनाता है।
इसलिए, वस्तु स्वतंत्रता के आवश्यक स्तर के आधार पर, deepcopy व्यापक पुनरुत्पादन का आश्वासन देता है जबकि प्रतिलिपि केवल सतह-स्तरीय दोहराव देती है।
कैसे दिखाने के लिए यहां कुछ कोड दिया गया है copy और deepcopy एक दूसरे से भिन्न:
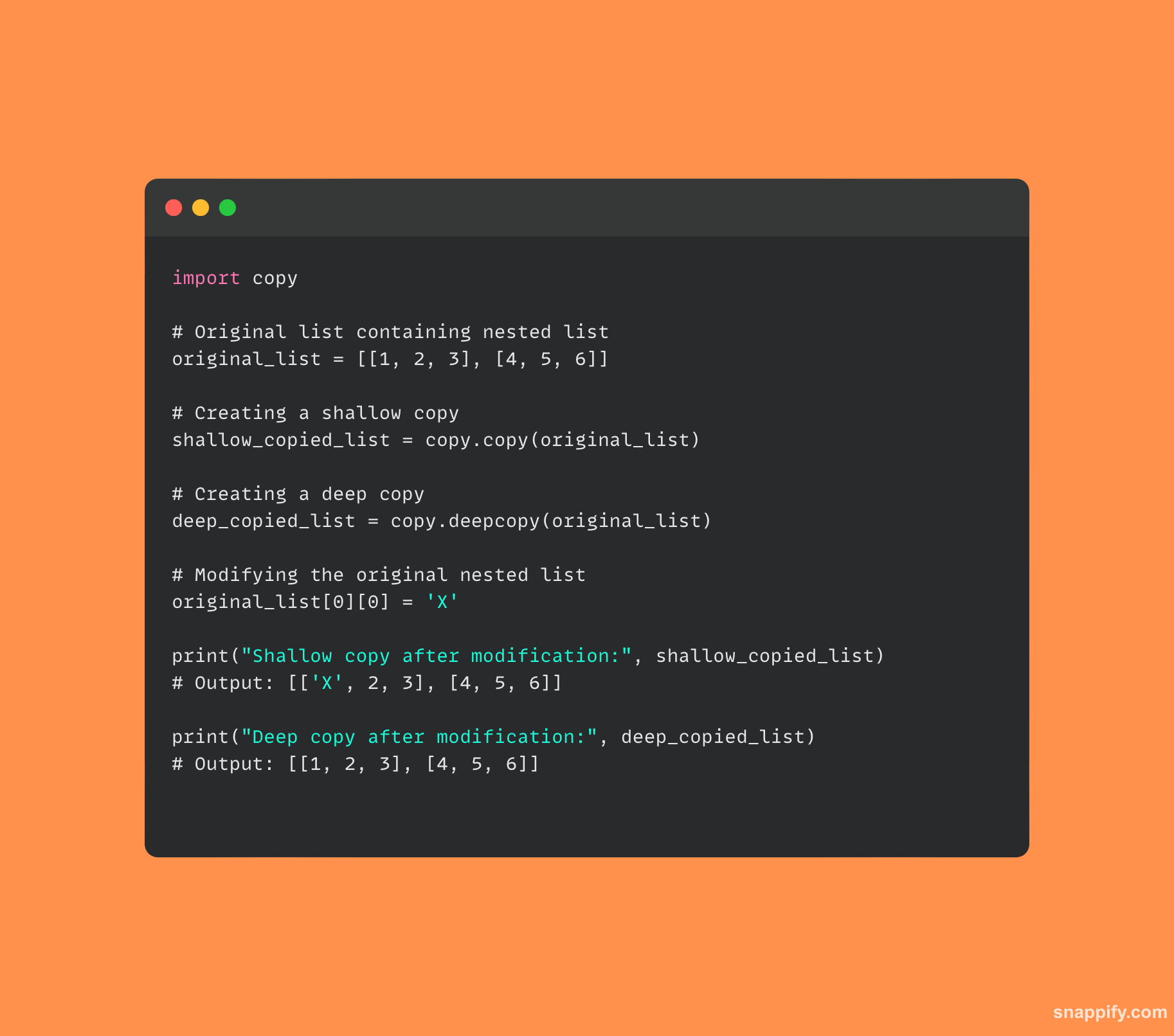
6. पायथन में मल्टीथ्रेडिंग कैसे प्राप्त की जाती है और यह मल्टीप्रोसेसिंग से कैसे भिन्न है?
पायथन की मल्टीप्रोसेसिंग और मल्टीथ्रेडिंग दोनों समवर्ती निष्पादन को संबोधित करती हैं, लेकिन विभिन्न प्रतिमानों का उपयोग करती हैं।
एक ही प्रक्रिया के अंदर कई थ्रेड्स का उपयोग करते हुए, मल्टीथ्रेडिंग एक साझा मेमोरी स्पेस के भीतर समवर्ती कार्य निष्पादन को सक्षम बनाता है।
हालाँकि, पायथन के ग्लोबल इंटरप्रेटर लॉक (जीआईएल) के कारण वास्तविक समानांतर थ्रेड निष्पादन को प्राप्त करना मुश्किल हो सकता है।
दूसरी ओर, मल्टीप्रोसेसिंग कई प्रक्रियाओं का उपयोग करती है, प्रत्येक एक अलग पायथन दुभाषिया और मेमोरी स्पेस के साथ, सच्ची समानता सुनिश्चित करता है।
I/O-बाउंड गतिविधियों के लिए, मल्टीथ्रेडिंग अधिक हल्का और व्यावहारिक है, लेकिन सीपीयू-बाउंड स्थितियों में मल्टीप्रोसेसिंग एक्सेल होता है जहां वास्तविक समानांतर निष्पादन महत्वपूर्ण होता है।
यहां एक संक्षिप्त कोड नमूना है जो मल्टीप्रोसेसिंग बनाम मल्टीथ्रेडिंग के बीच अंतर बताता है:
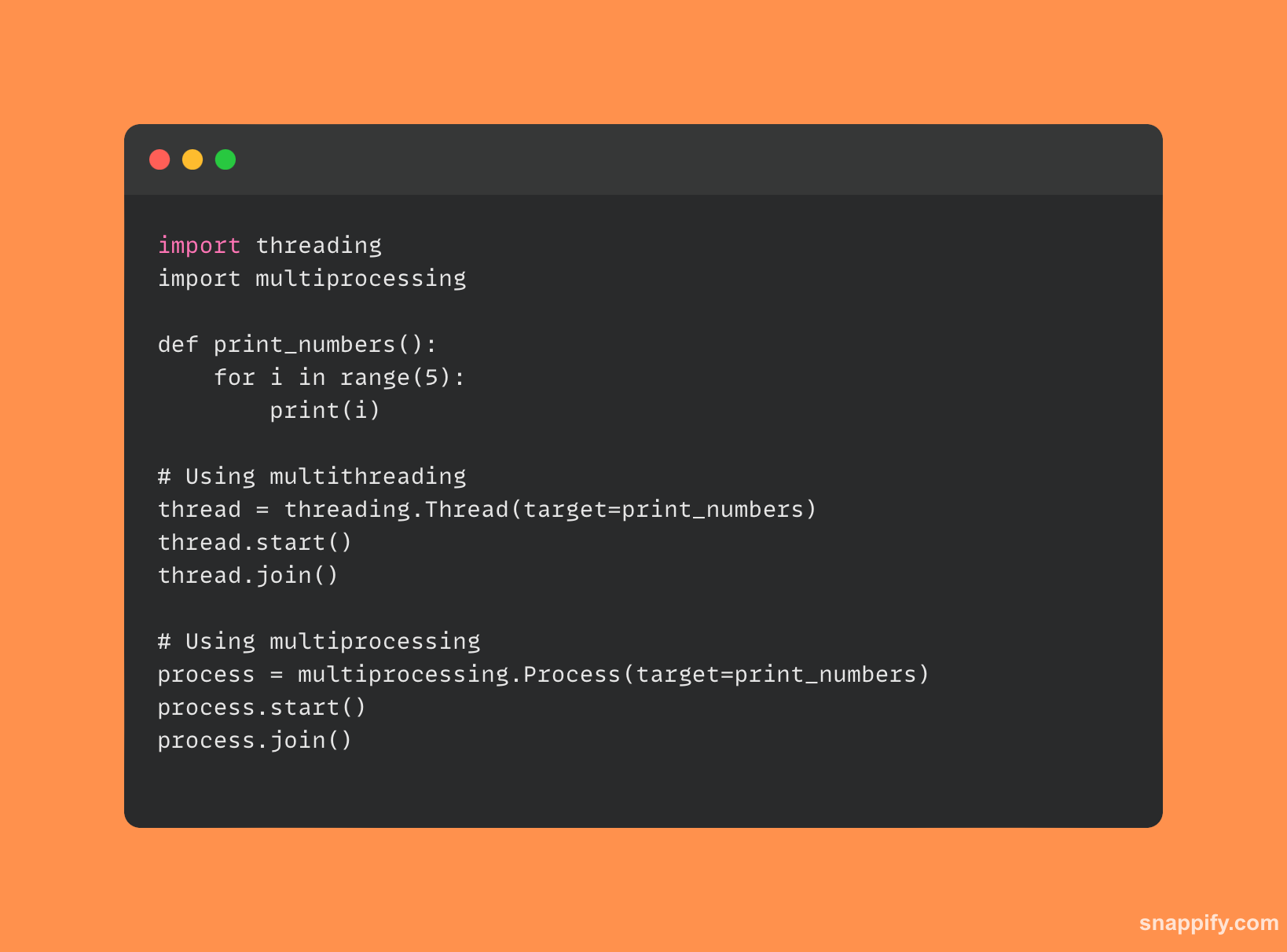
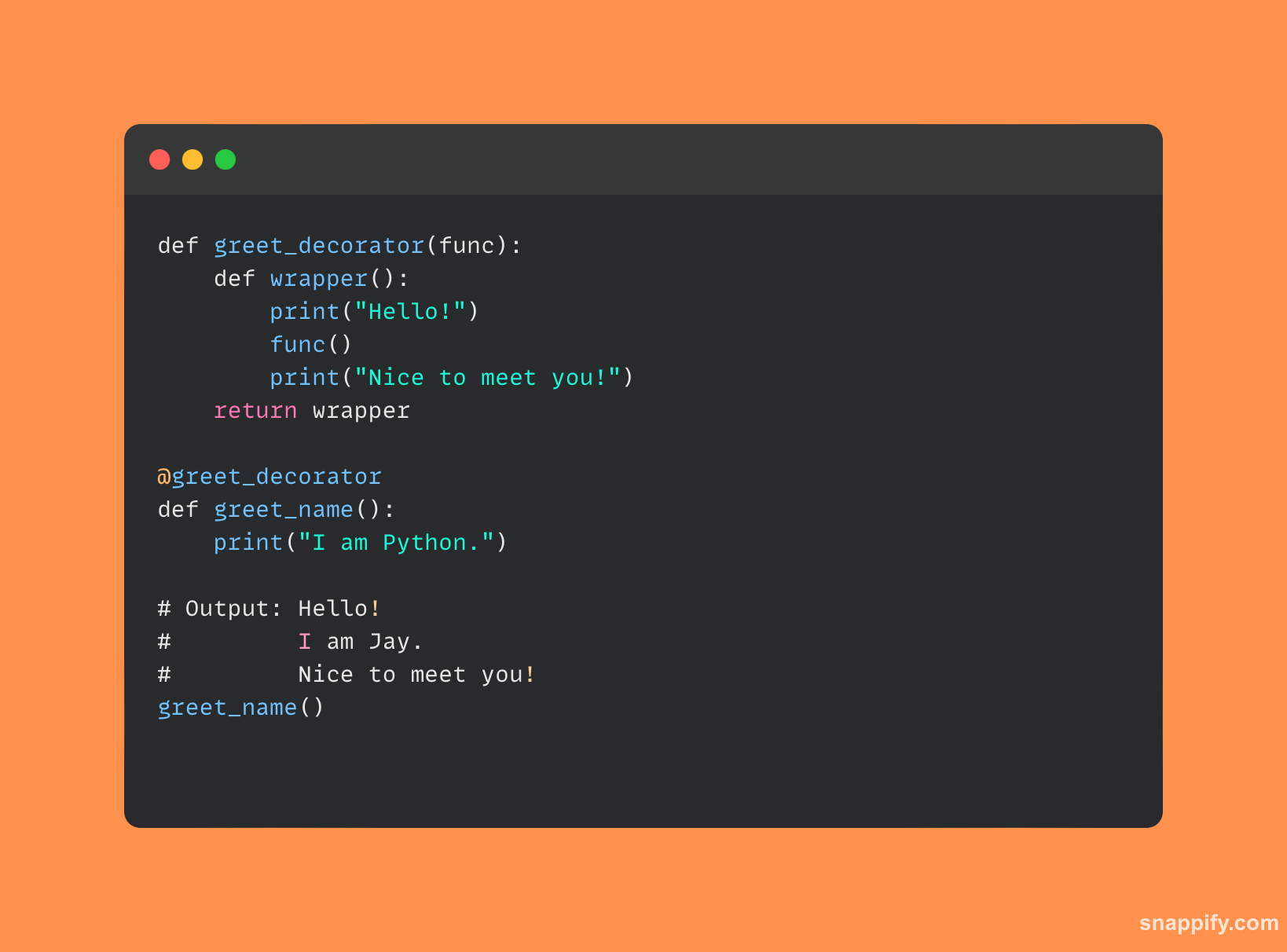
7. डेकोरेटर क्या हैं और पायथन में उनका उपयोग कैसे किया जाता है?
पायथन में, डेकोरेटर कार्यों को सूक्ष्मता से बढ़ाने या बदलने के दौरान उपयोगिता और सरलता को खूबसूरती से जोड़ते हैं।
डेकोरेटर्स को एक घूंघट के रूप में सोचें जो किसी समारोह को खूबसूरती से ढक देता है, उसकी आवश्यक प्रकृति को बदले बिना उसकी क्षमताओं को बढ़ाता है।
ये इकाइयाँ, प्रतीक द्वारा निरूपित होती हैं @, एक फ़ंक्शन को इनपुट के रूप में स्वीकार करें और एक बिल्कुल नया फ़ंक्शन आउटपुट करें, जो फ़ंक्शन व्यवहार को संशोधित करने का एक सहज साधन प्रदान करता है।
डेकोरेटर लॉगिंग से लेकर एक्सेस कंट्रोल तक, स्पष्ट, समझने योग्य सिंटैक्स को बनाए रखते हुए नई परतों के साथ कोड को बढ़ाने जैसी कई प्रकार की सुविधाएँ प्रदान करते हैं।
यहां एक सरल पायथन कोड उदाहरण दिया गया है जो दिखाता है कि डेकोरेटर का उपयोग कैसे किया जाता है:
8. *आर्ग्स और **क्वार्ग्स के बीच अंतर स्पष्ट करें?
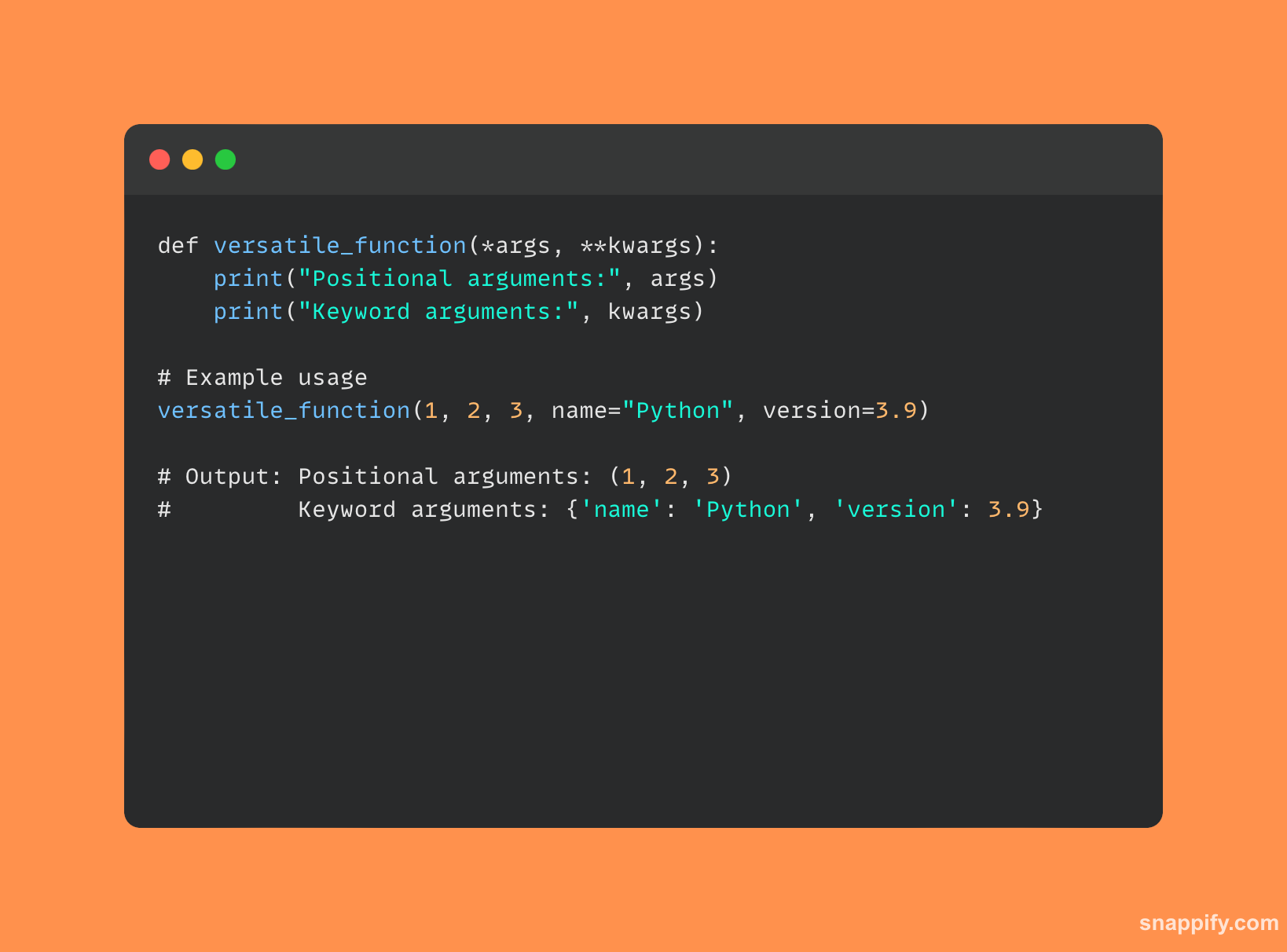
पायथन के लचीले पैरामीटर *args और **kwargs फ़ंक्शंस को उचित रूप से तर्कों की एक श्रृंखला लेने की अनुमति दें।
एक फ़ंक्शन किसी भी संख्या में स्थितीय तर्कों को स्वीकार कर सकता है *args पैरामीटर, जो उन्हें टुपल में समूहित करता है।
इसके विपरीत, कोई फ़ंक्शन किसी भी संख्या में कीवर्ड तर्कों को स्वीकार कर सकता है **kwargs पैरामीटर, जो उन्हें एक शब्दकोश में समूहित करता है।
दोनों फ़ंक्शन निर्माण और कॉलिंग में गतिशीलता और लचीलेपन के लिए चैनल के रूप में कार्य करते हैं, **kwargs कीवर्ड इनपुट की मनमानी मात्रा को संभालने के लिए एक संरचित विधि की पेशकश करना *args अपरिभाषित स्थितीय इनपुट को खूबसूरती से संभालता है।
साथ में, वे एप्लिकेशन परिदृश्यों की एक विस्तृत श्रृंखला को कुशलतापूर्वक और स्पष्ट रूप से संभालकर पायथन कार्यों के लचीलेपन और स्थायित्व में सुधार करते हैं।
पायथन कोड का एक उदाहरण जो उपयोग करता है *args और **kwargs नीचे दिया गया है:
9. आप यह कैसे सुनिश्चित करेंगे कि किसी फ़ंक्शन को डेकोरेटर का उपयोग करके केवल एक बार ही कॉल किया जा सकता है?
पायथन डेकोरेटर उपयोगिता को सुंदरता के साथ संयोजित करने में माहिर हैं, जो निष्पादन में किसी फ़ंक्शन की विलक्षणता सुनिश्चित करने के लिए आवश्यक है।
किसी फ़ंक्शन को संलग्न करने और आंतरिक स्थिति को ध्यान में रखते हुए इस जानकारी का ट्रैक रखने के लिए डेकोरेटर को डिज़ाइन करना संभव है।
इनकैप्सुलेटेड फ़ंक्शन को एक बार कॉल किया जाता है, और निष्पादित किया जाता है, और डेकोरेटर कॉल को रिकॉर्ड करता है। बाद की कॉलों को अवरुद्ध कर दिया जाता है, यह सुनिश्चित करके फ़ंक्शन को बार-बार निष्पादित होने से बचाया जाता है कि यह परेशान न हो।
डेकोरेटर्स के इस एप्लिकेशन की मदद से, फ़ंक्शन कॉल को सूक्ष्म लेकिन प्रभावी तरीके से नियंत्रित किया जा सकता है, जो एक तरह से विशिष्टता की गारंटी देता है जो सुंदर और विनीत दोनों है।
यह दिखाने के लिए यहां एक कोड नमूना दिया गया है कि किसी फ़ंक्शन को कॉल करने की संख्या को सीमित करने के लिए डेकोरेटर का उपयोग कैसे किया जा सकता है:

10. पायथन में इनहेरिटेंस कैसे काम करता है?
पायथन की वंशानुक्रम प्रणाली कक्षाओं के बीच पदानुक्रमित लिंक का एक जाल बनाती है, जिससे मूल वर्ग की विशेषताओं और कार्यों को उसकी संतानों के साथ साझा किया जा सकता है।
यह एक वंशावली का प्रबंधन करता है जो व्युत्पन्न (बच्चे) वर्गों को उनके आधार (मूल) वर्गों से कार्यक्षमता प्राप्त करने, बदलने या जोड़ने की अनुमति देता है, कोड के पुन: उपयोग और एक तार्किक, पदानुक्रमित डिजाइन को बढ़ावा देता है।
चाइल्ड क्लास अपने माता-पिता से क्षमताओं को अवशोषित करने के अलावा, एक मजबूत, बहुस्तरीय ऑब्जेक्ट मॉडल बनाकर अपनी अनूठी विशेषताओं और व्यवहारों का परिचय दे सकता है।
इस दृष्टिकोण में, वंशानुक्रम कुशलतापूर्वक वर्ग पदानुक्रम की धमनियों में कार्यक्षमता वितरित करता है, जिससे एक एकीकृत, सुव्यवस्थित वस्तु-उन्मुख वास्तुकला का निर्माण होता है।
निम्नलिखित सरलीकृत पायथन कोड वंशानुक्रम को प्रदर्शित करता है:

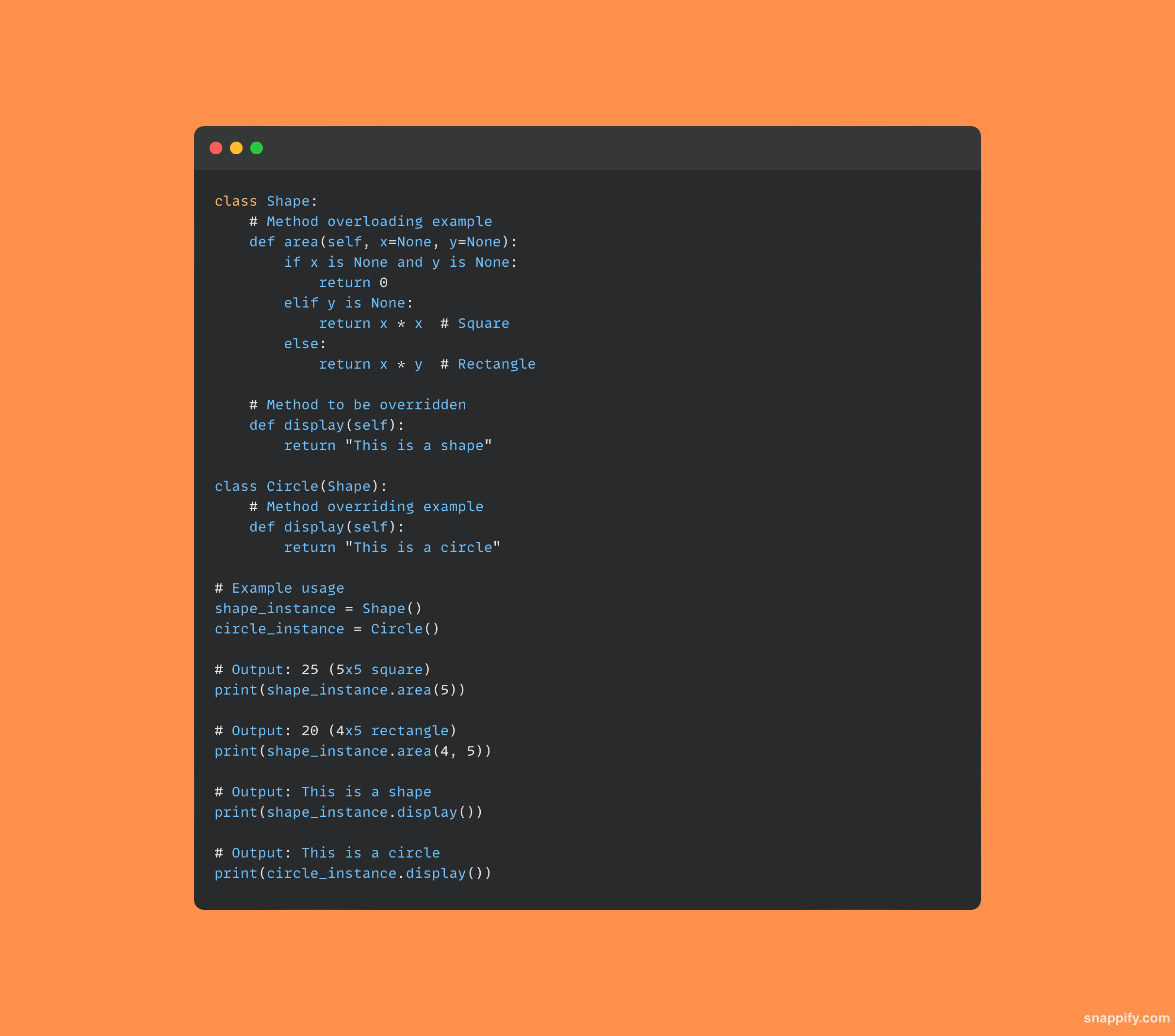
11. मेथड ओवरलोडिंग और ओवरराइडिंग क्या है?
की दो आधारशिलाएं ऑब्जेक्ट ओरिएंटेड प्रोग्रामिंग, मेथड ओवरलोडिंग और मेथड ओवरराइडिंग, डेवलपर्स को कई उद्देश्यों के लिए एक ही मेथड नाम का उपयोग करने में सक्षम बनाता है।
विधि ओवरलोडिंग के कारण कई हस्ताक्षरों के कारण एक एकल विधि विभिन्न प्रकार के डेटा प्रकारों और तर्क गणनाओं को समायोजित कर सकती है।
दूसरी ओर, मेथड ओवरराइडिंग एक उपवर्ग को अपने स्वयं के विशेष कार्यान्वयन को उस विधि में जोड़ने की अनुमति देता है जो पहले से ही उसके मूल वर्ग में परिभाषित है, यह गारंटी देता है कि बच्चे के संस्करण को बुलाया जाता है।
साथ में, ये रणनीतियाँ संदर्भ और एप्लिकेशन की विशेष आवश्यकताओं पर निर्भर विधि व्यवहार को सक्षम करके अनुकूलन क्षमता में सुधार करती हैं।
यहां कोड का एक नमूना है जो दोनों अवधारणाओं का उदाहरण देता है:
12. बहुरूपता की अवधारणा का उदाहरण सहित वर्णन करें।
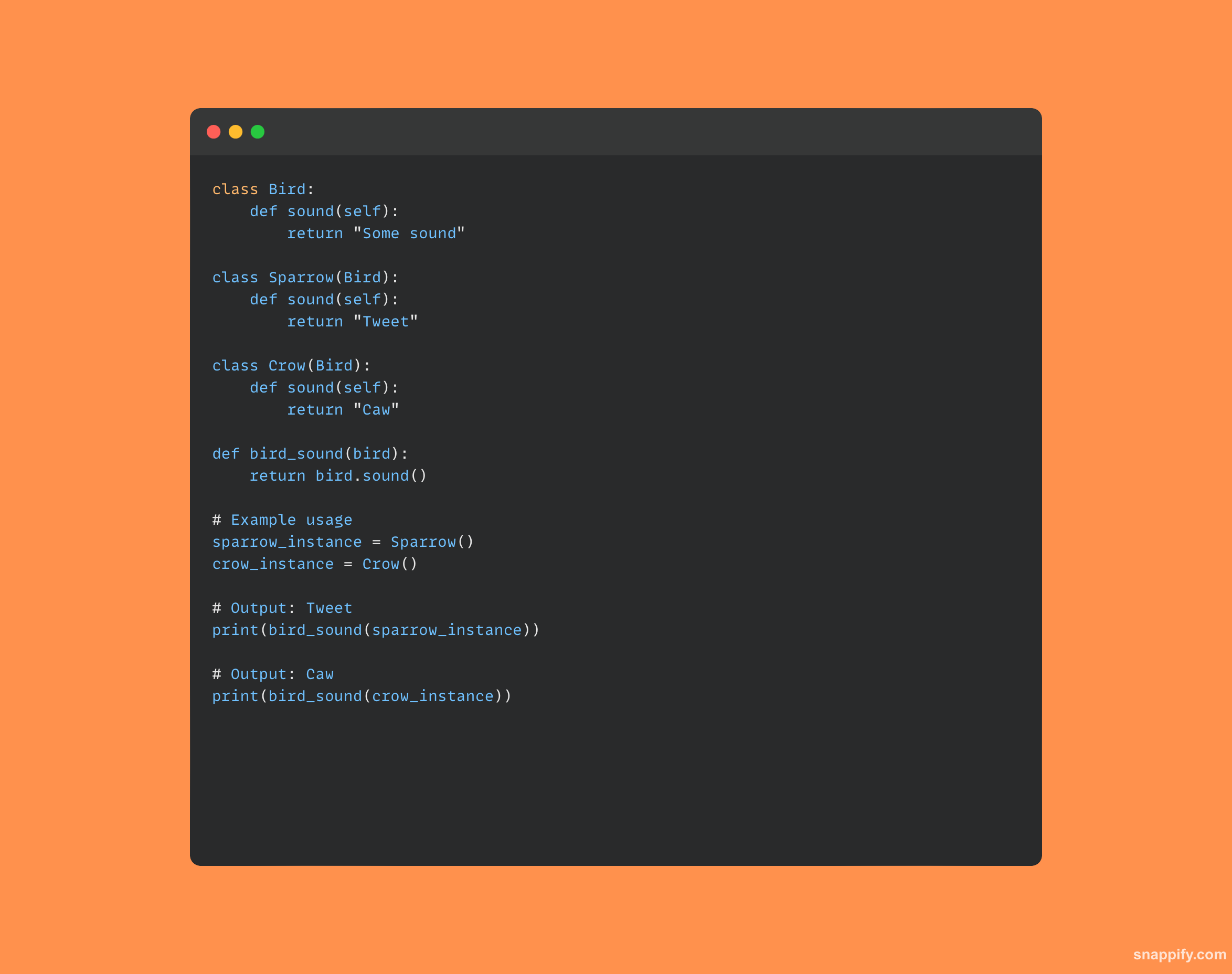
बहुरूपता विभिन्न डेटा प्रकारों के लिए एकल इंटरफ़ेस का उपयोग करने का अभ्यास है।
यह विचार वस्तुओं को उनके आंतरिक प्रकार या वर्ग के आधार पर कई तरीकों से संसाधित करने की स्वतंत्रता देकर डिजाइन में अनुकूलनशीलता और मापनीयता सुनिश्चित करता है।
संक्षेप में, बहुरूपता विभिन्न वर्गों की वस्तुओं को विरासत के माध्यम से एक ही वर्ग के उदाहरणों के रूप में विचार करने की अनुमति देकर अलग-अलग व्यवहार रखते हुए एकीकृत इंटरैक्शन को सक्षम बनाता है।
यह गतिशील सुविधा एकल फ़ंक्शन या ऑपरेटर को बिना किसी समस्या के विभिन्न प्रकार के ऑब्जेक्ट के साथ इंटरैक्ट करने की अनुमति देकर कोड सरलता को प्रोत्साहित करती है।
यहां एक स्पष्ट कोड नमूना है जो बहुरूपता प्रदर्शित करता है:
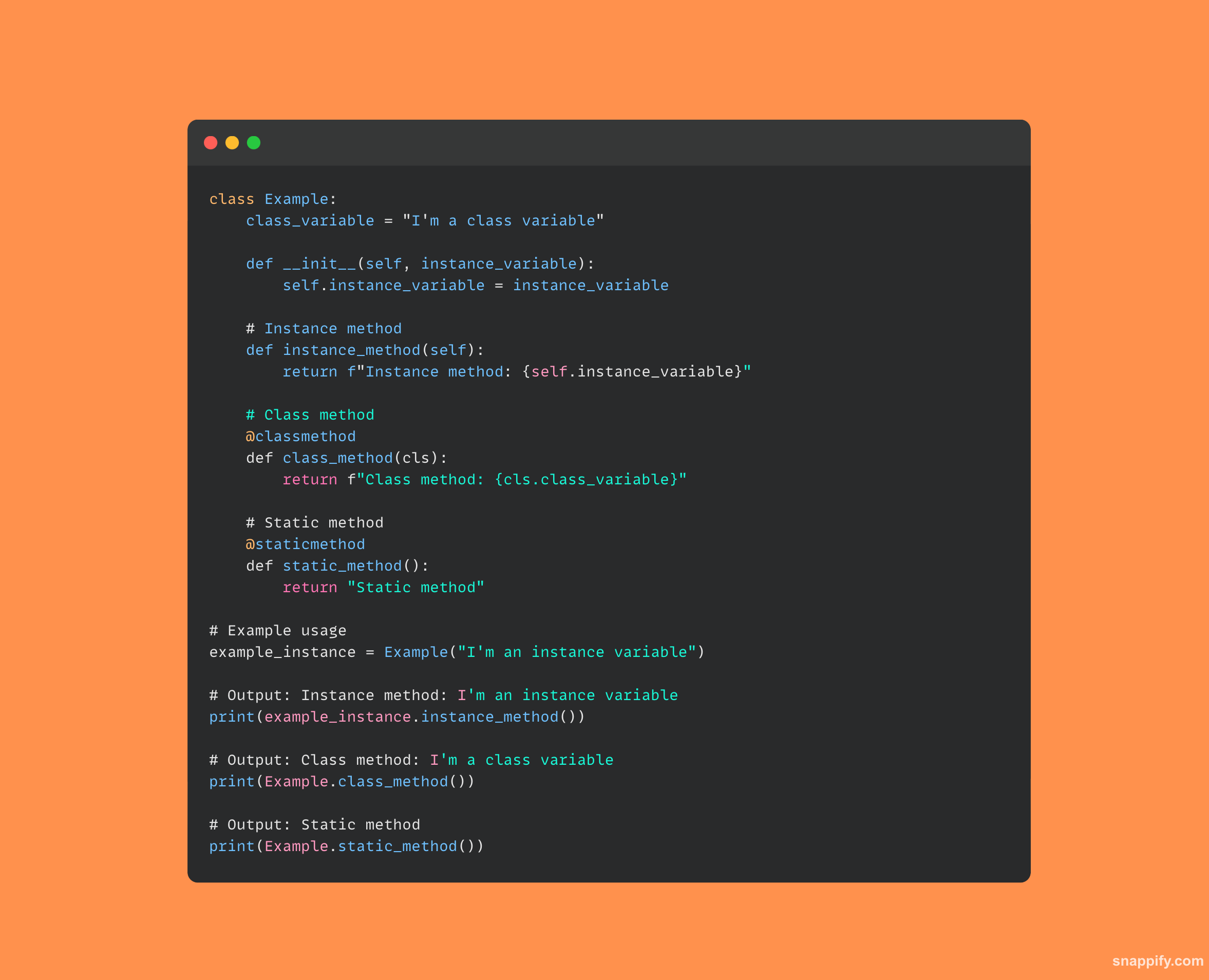
13. इंस्टेंस, क्लास और स्टैटिक तरीकों के बीच अंतर स्पष्ट करें।
पायथन में इंस्टेंस, क्लास और स्टैटिक तरीकों के ऑब्जेक्ट और क्लास डेटा के साथ इंटरैक्ट करने के अपने-अपने अलग तरीके हैं।
सबसे प्रचलित प्रकार, इंस्टेंस विधियां, क्लास इंस्टेंस डेटा पर कार्य करती हैं और इनपुट के रूप में क्लास का एक इंस्टेंस लेती हैं, जिसे आमतौर पर सेल्फ कहा जाता है।
क्लास को ही (अक्सर सीएलएस के रूप में संदर्भित) क्लास विधियों द्वारा एक तर्क के रूप में स्वीकार किया जाता है, जिसे @classmethod के साथ दर्शाया जाता है, और वे क्लास-स्तरीय डेटा में हेरफेर करते हैं।
हैश प्रतीक @staticmethod द्वारा निरूपित स्टेटिक विधियाँ, क्लास या इंस्टेंस स्थिति को प्रभावित नहीं करती हैं क्योंकि वे क्लास के भीतर निहित फ्रीस्टैंडिंग फ़ंक्शन हैं और पहले पैरामीटर के रूप में self या cls को नहीं लेते हैं।
क्योंकि प्रत्येक विधि प्रकार अलग-अलग पहुंच और उपयोगिता प्रदान करता है, ऑब्जेक्ट-ओरिएंटेड आर्किटेक्चर लचीले और सटीक होते हैं।
कोड में इन विधि प्रकारों में से एक के उदाहरण के रूप में:
14. वर्णन करें कि पायथन सेट आंतरिक रूप से कैसे काम करता है।
एक आंतरिक डेटा संरचना जिसे हैशटेबल कहा जाता है, उसका उपयोग पायथन सेट द्वारा किया जाता है, जो शक्तिशाली और प्रभावी संचालन करने के लिए अलग-अलग घटकों का एक अव्यवस्थित संग्रह है।
जब किसी सेट में कोई तत्व जोड़ा जाता है, तो डेटा को तुरंत प्रबंधित और पुनर्प्राप्त करने के लिए पायथन एक हैश फ़ंक्शन का उपयोग करता है, तत्व को हैश मान में बदल देता है जो फिर मेमोरी में उसके स्थान को परिभाषित करता है।
त्वरित सदस्यता जांच की सुविधा प्रदान करके और डुप्लिकेट प्रविष्टियों को हटाकर, यह तकनीक सुनिश्चित करती है कि सेट में प्रत्येक तत्व अद्वितीय और आसानी से पहुंच योग्य है।
इसलिए, सेट की अंतर्निहित वास्तुकला यूनियनों, क्रॉसिंग और मतभेदों जैसे संचालन को अनुकूलित करती है, जिसके परिणामस्वरूप एक छोटी, प्रभावी डेटा संरचना होती है।
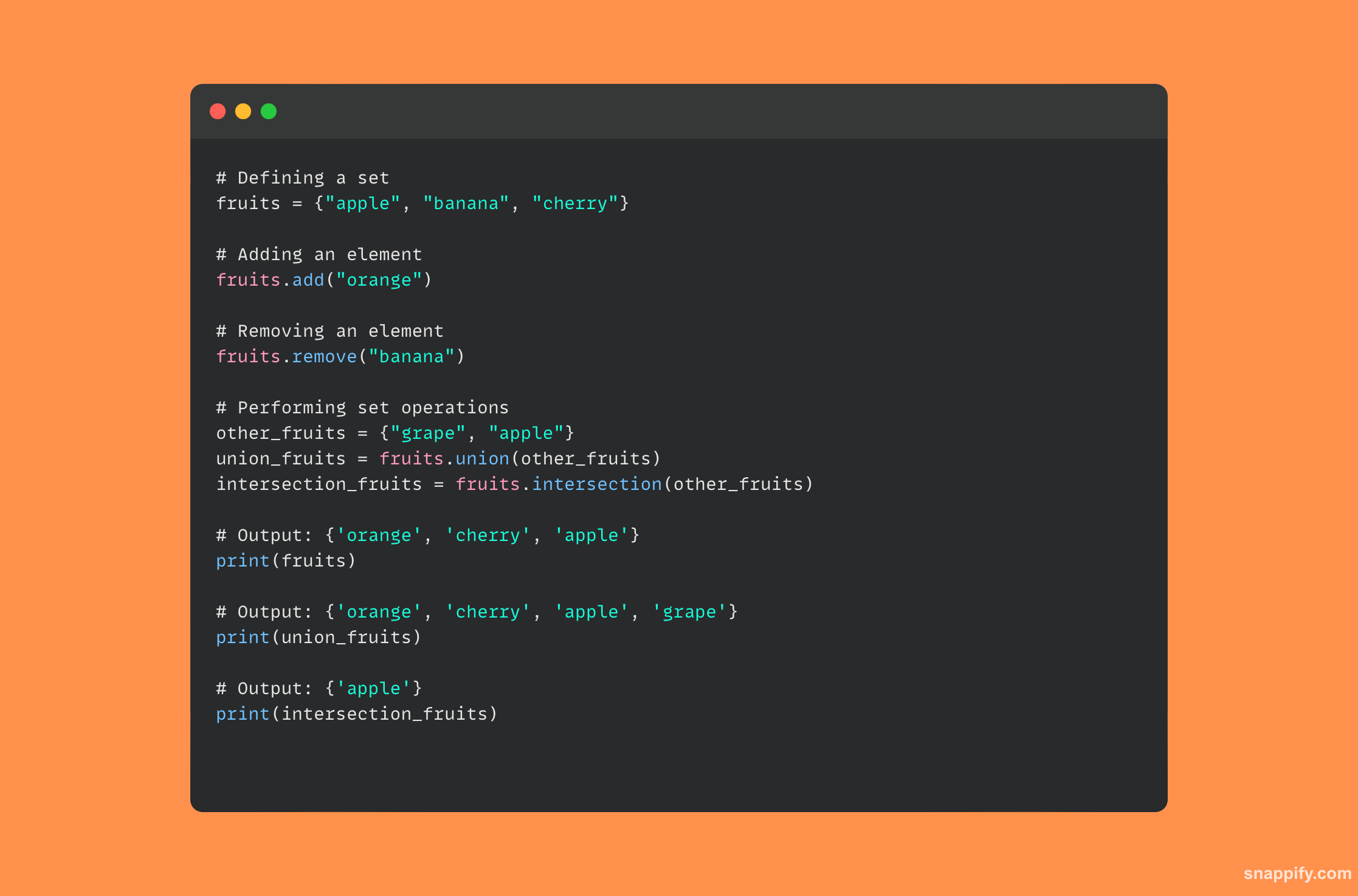
यहां कोड का एक टुकड़ा है जो दिखाता है कि पाइथॉन सेट के साथ आसानी से कैसे इंटरैक्ट किया जाए:
15. पायथन में शब्दकोश कैसे लागू किया जाता है?
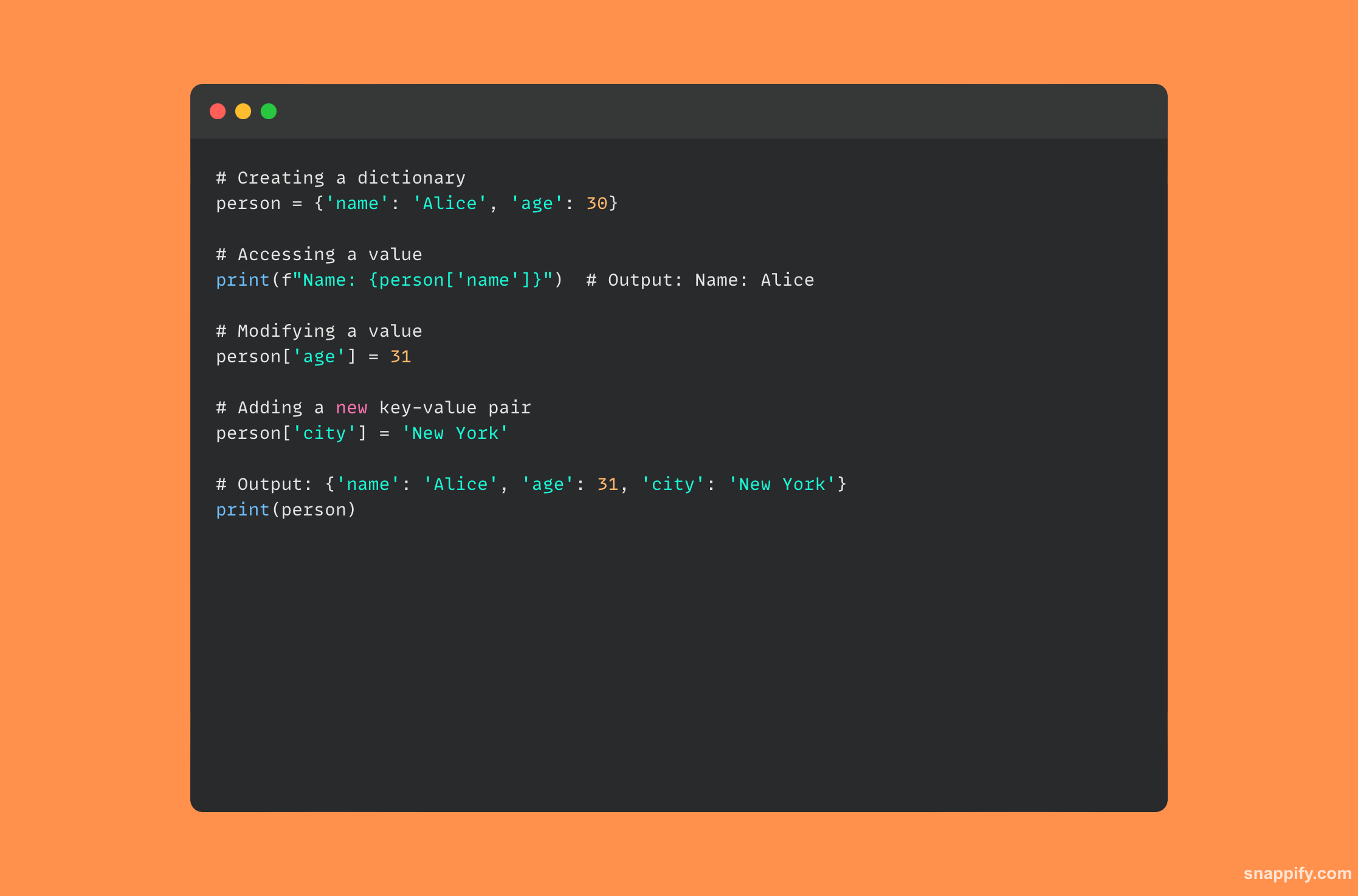
एक हैशटेबल पायथन में एक शब्दकोश की नींव के रूप में कार्य करता है और त्वरित डेटा पुनर्प्राप्ति और हेरफेर की अनुमति देता है। शब्दकोश कुंजी-मूल्य युग्मों का गतिशील, अव्यवस्थित संग्रह हैं।
जब कुंजी-मूल्य जोड़ी जारी की जाती है, तो कुंजी के हैश की गणना करने के लिए पायथन एक हैश फ़ंक्शन का उपयोग करता है, जो मेमोरी में मूल्य के भंडारण पते के स्थान का पता लगाता है।
चूंकि हैश फ़ंक्शन तुरंत दुभाषिया को मेमोरी पते पर इंगित करता है, यह डिज़ाइन कुंजी के आधार पर डेटा तक त्वरित पहुंच प्रदान करता है और पुनर्प्राप्ति, सम्मिलन और विलोपन संचालन में आश्चर्यजनक रूप से कुशल है।
पायथन शब्दकोशों द्वारा प्रदान की गई गति और लचीलेपन के आकर्षक संयोजन के कारण डेव डेटा को आसानी से और प्रभावी ढंग से प्रबंधित कर सकते हैं।
नीचे सूचीबद्ध एक कोड नमूना है जो दिखाता है कि पायथन डिक्शनरी का उपयोग कैसे करें:
16. नामित टुपल्स के उपयोग के लाभ बताएं।
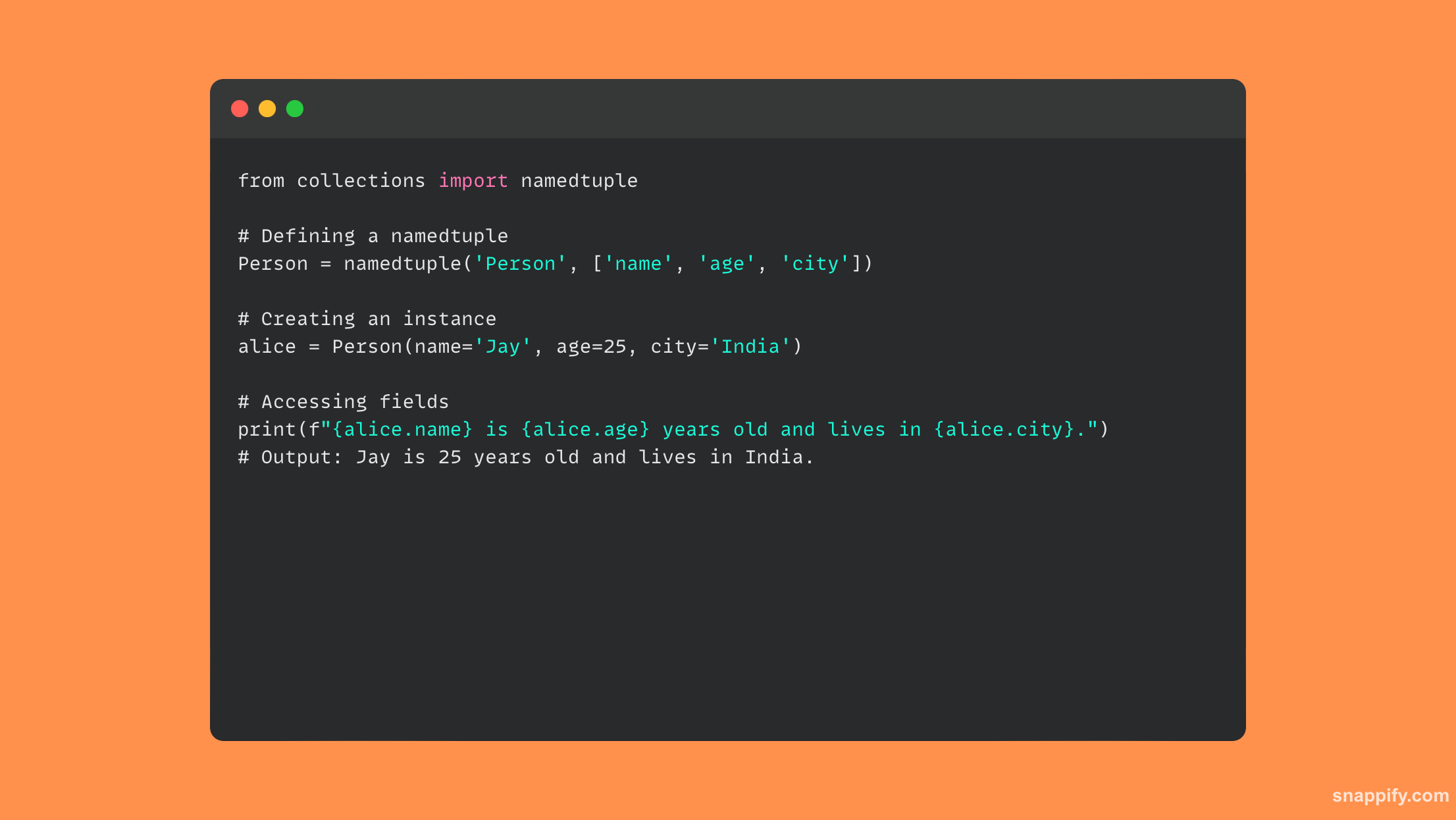
पायथन में नामित टुपल्स का उपयोग कुशलतापूर्वक कक्षाओं की अभिव्यक्ति को टुपल्स की सादगी के साथ जोड़ता है, जिसके परिणामस्वरूप एक छोटी, आत्म-व्याख्यात्मक डेटा संरचना बनती है।
पारंपरिक टुपल को नामित टुपल्स द्वारा विस्तारित किया जाता है, जो कोड पठनीयता और स्व-विवरण में सुधार के लिए नामित फ़ील्ड जोड़ते समय टुपल्स की अपरिवर्तनीयता और स्मृति दक्षता को बनाए रखता है।
नामांकित टुपल्स बिना किसी विधि के सीधे, हल्के ऑब्जेक्ट स्थापित करके स्पष्ट, समझने योग्य और निष्पादन योग्य कोड को बढ़ावा देते हैं, जिससे डेवलपर अनुभव और कम्प्यूटेशनल प्रदर्शन दोनों में सुधार होता है।
परिणामस्वरूप, नामित टुपल्स एक शक्तिशाली उपकरण के रूप में विकसित होते हैं जो गति से समझौता किए बिना डेटा संरचना और पठनीयता में सुधार करता है।
नामित टुपल्स के उपयोग को दर्शाने वाला एक कोड नमूना नीचे दिखाया गया है:
17. ट्राई-एक्सेप्ट ब्लॉक कैसे काम करता है?
ट्राइ-एक्सेप्ट ब्लॉक पायथन अभिव्यंजक वाक्यविन्यास में एक प्रहरी के रूप में कार्य करता है, जो रनटाइम अनियमितताओं के खिलाफ सतर्कता से रक्षा करता है और संभावित समस्याओं के बावजूद निष्पादन के सुचारू प्रवाह को बनाए रखता है।
जब किसी प्रयास ब्लॉक में कोई त्रुटि आती है, तो नियंत्रण स्वचालित रूप से ब्लॉक को छोड़कर उपयुक्त स्थान पर स्थानांतरित हो जाता है, जहां समस्या को रिपोर्टिंग, फिक्सिंग या शायद अपवाद को फिर से स्थापित करके ठीक किया जाता है।
उद्देश्यपूर्ण, नियंत्रित तरीके से अपवादों को संभालकर, यह प्रणाली न केवल विघटनकारी दुर्घटनाओं से बचाती है बल्कि सुधार भी करती है उपयोगकर्ता अनुभव और डेटा अखंडता.
परिणामस्वरूप, ट्राई-एक्सेप्ट ब्लॉक प्रोग्राम निष्पादन के साथ त्रुटि प्रबंधन को कुशलता से मिश्रित करता है, एप्लिकेशन की मजबूती और स्थिरता की गारंटी देता है।
यहां कोड का एक छोटा सा नमूना है जो ट्राई-एक्सेप्ट ब्लॉक का उपयोग करता है:
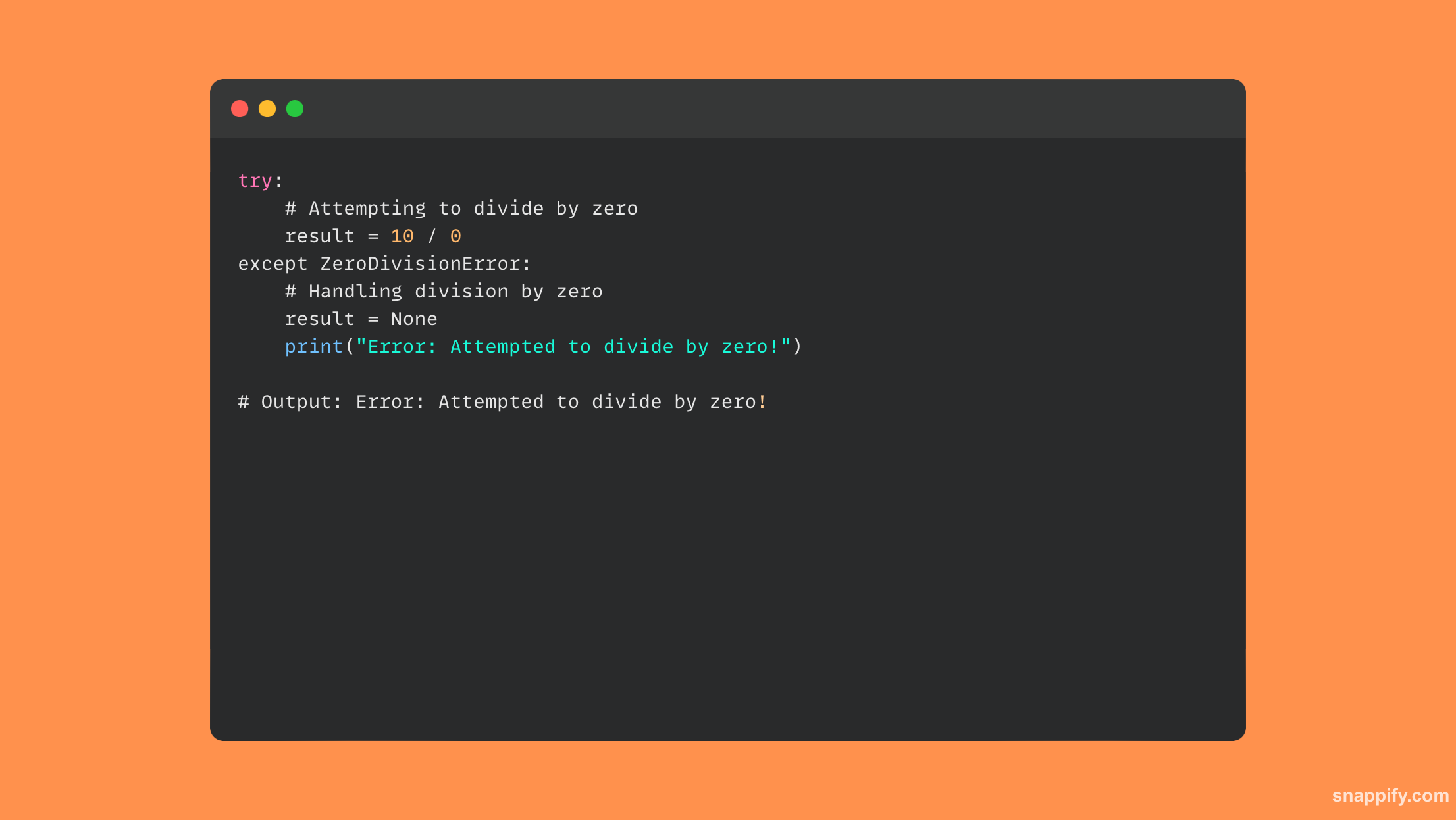
18. उठाओ और जोर देने वाले कथनों के बीच क्या अंतर है?
पायथन की त्रुटि प्रबंधन में raise औरassert कथन अपवाद प्रबंधन की दो अलग लेकिन संबंधित अभिव्यक्तियों का प्रतिनिधित्व करते हैं।
RSI raise स्टेटमेंट प्रोग्रामर को त्रुटि संदेशों और प्रवाह पर स्पष्ट नियंत्रण देता है, जिससे उन्हें स्पष्ट रूप से निर्दिष्ट अपवाद उत्पन्न करने की अनुमति मिलती है।
Assertदूसरी ओर, स्वचालित रूप से उत्पन्न करके डिबगिंग टूल के रूप में कार्य करता है AssertionError यदि इसकी संबंधित शर्त पूरी नहीं होती है, तो यह गारंटी दी जाती है कि कार्यक्रम विकास के दौरान इच्छित कार्य करता है।
Assert बस स्थितियों की जांच करता है, डिबगिंग और सत्यापन में सुधार करता है, जबकि raise व्यापक, अधिक स्पष्ट नियंत्रण सक्षम करता है। दोनों नियंत्रित अपवाद उत्पादन की अनुमति देते हैं और जोर देते हैं।
यहां कुछ नमूना कोड दिया गया है जो दिखाता है कि कैसे उपयोग करें raise और assert:
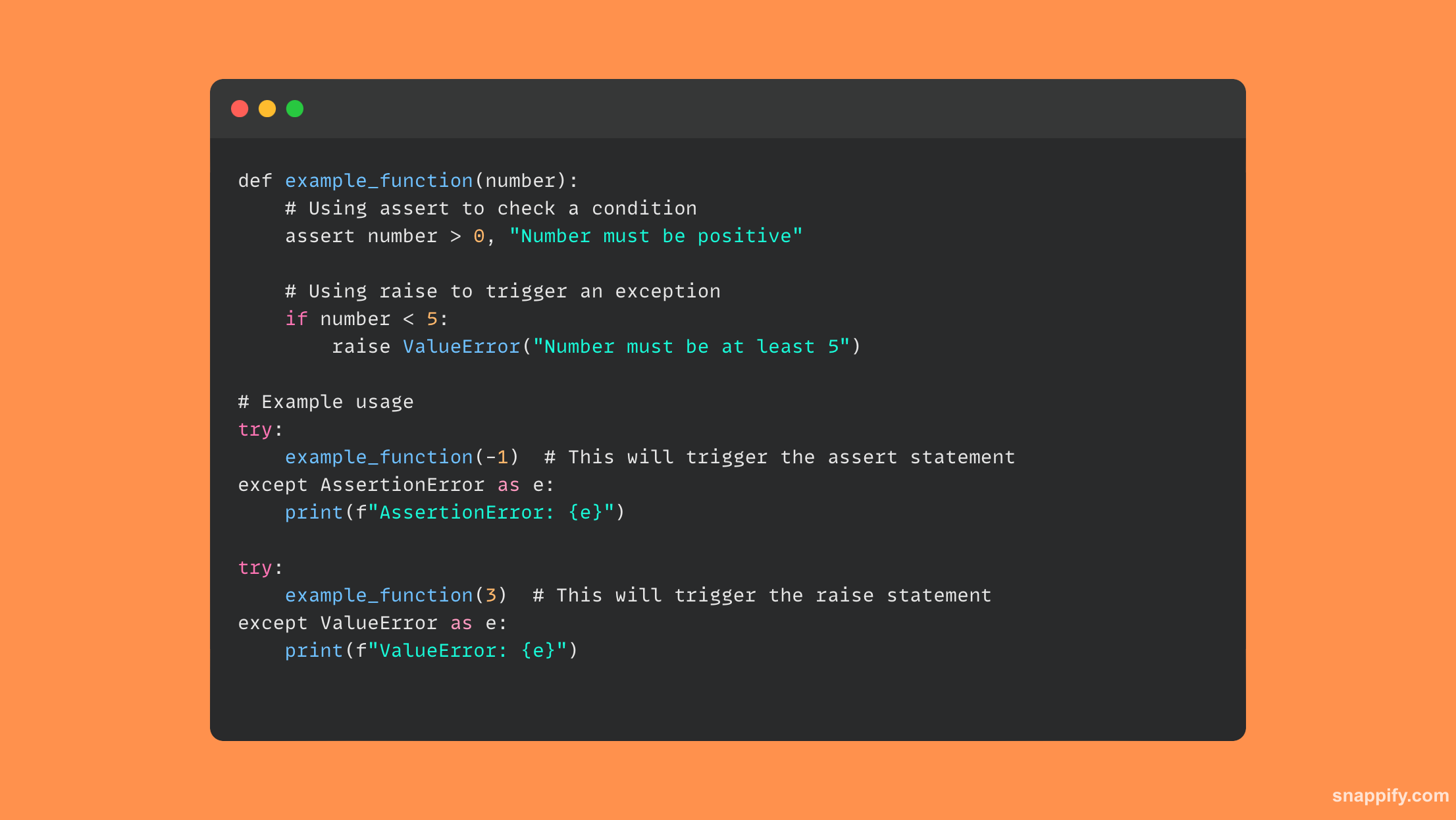
19. आप पायथन में बाइनरी फ़ाइल से डेटा कैसे पढ़ते और लिखते हैं?
बाइनरी मोड विनिर्देशक के साथ अंतर्निहित ओपन फ़ंक्शन का उपयोग करते हुए, पायथन में बाइनरी फ़ाइलों के साथ इंटरफेसिंग में सटीकता और सरलता का संतुलन शामिल होता है।
ऊपर दिए rb or wb बाइनरी फ़ाइल खोलते समय मोड यह सुनिश्चित करेंगे कि बाइनरी डेटा को पढ़ते या लिखते समय डेटा को उसके अनएन्कोडेड, कच्चे रूप में व्यवहार किया जाए।
इन मोड का उपयोग करके, पायथन गैर-पाठ डेटा, जैसे चित्र या निष्पादन योग्य फ़ाइलों के प्रबंधन को सरल बनाता है, जिससे प्रोग्रामर बाइनरी डेटा को सटीक और आसानी से संभालने और विश्लेषण करने में सक्षम होते हैं।
इसलिए, पायथन में बाइनरी फ़ाइल संचालन कुछ अनुप्रयोगों का उल्लेख करने के लिए डेटा क्रमबद्धता, छवि प्रसंस्करण और बाइनरी विश्लेषण सहित अनुप्रयोगों की एक विस्तृत श्रृंखला के लिए द्वार खोलता है।
बाइनरी फ़ाइल का उपयोग करते हुए, कोड का यह उदाहरण दिखाता है कि डेटा को कैसे पढ़ा और लिखा जाए:
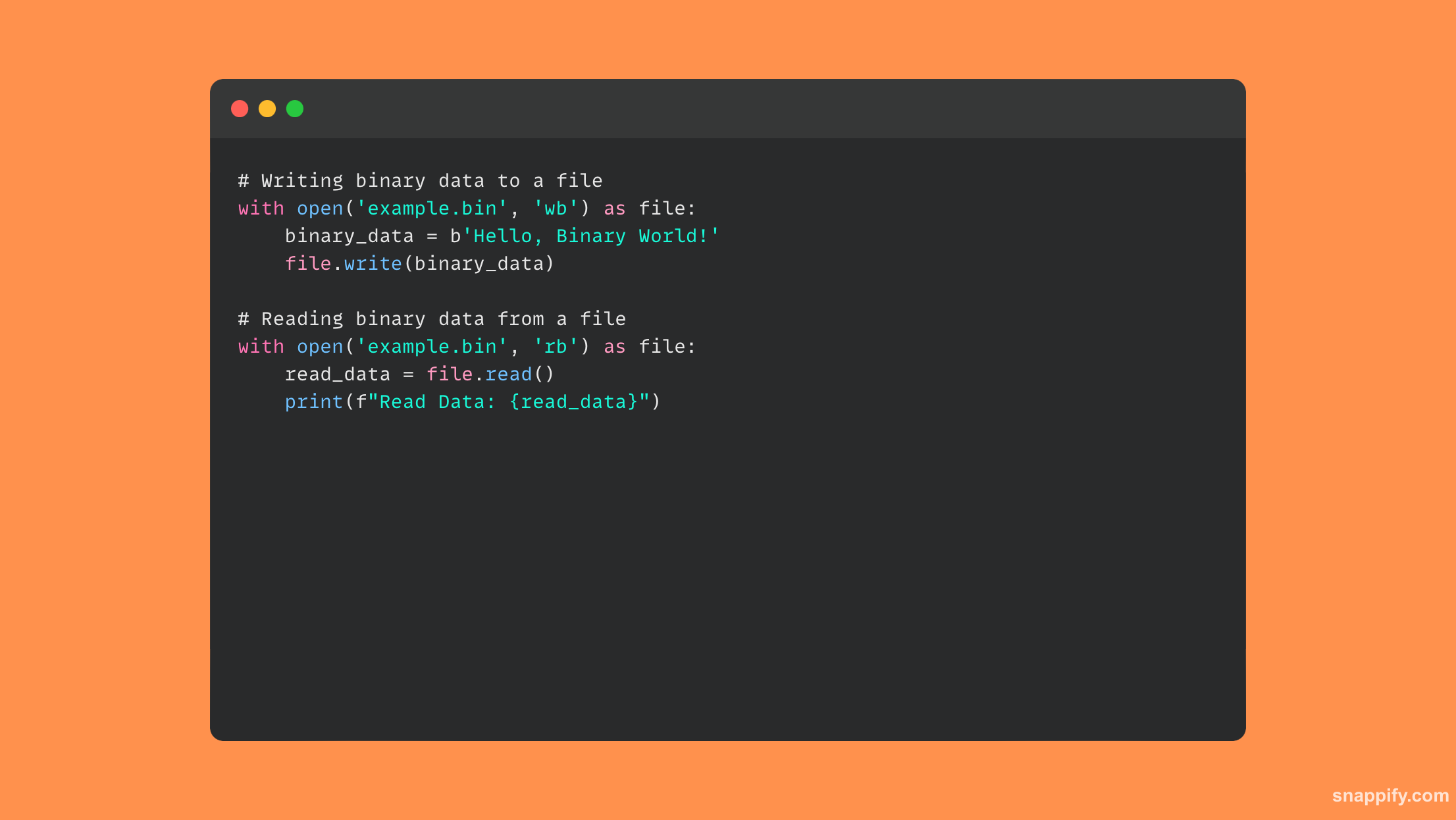
20. स्पष्ट करें with फ़ाइल I/O के साथ काम करते समय कथन और इसके लाभ।
पायथन का with स्टेटमेंट, जिसे अक्सर फ़ाइल I/O के साथ उपयोग किया जाता है, यह सुरुचिपूर्ण ढंग से सुनिश्चित करता है कि संदर्भ प्रबंधन के विचार के कारण संसाधनों को प्रभावी ढंग से प्रबंधित किया जाता है।
फाइलों से निपटते समय, withउपयोग के बाद स्टेटमेंट फ़ाइल को तुरंत बंद कर देता है, भले ही कार्रवाई करते समय कोई अपवाद होता है, संसाधन लीक से बचाता है और एक साफ समाप्ति की गारंटी देता है।
बॉयलरप्लेट कोड को हटाकर, यह सिंटैक्टिक शुगर कोड पठनीयता में सुधार करता है। यह संसाधन प्रबंधन और अपवाद प्रबंधन को एकीकृत करके निर्भरता और सरलता भी बढ़ाता है।
परिणामस्वरूप, with कथन यह सुनिश्चित करने के लिए आवश्यक हो जाता है कि आपकी फ़ाइल संचालन विश्वसनीय और साफ़-सुथरी है, अप्रत्याशित समस्याओं से रक्षा करती है और कोड स्पष्टता में सुधार करती है।
यहां कोड का एक उदाहरण दिया गया है जो इसका उपयोग करता है with फ़ाइल संचालन में कथन:
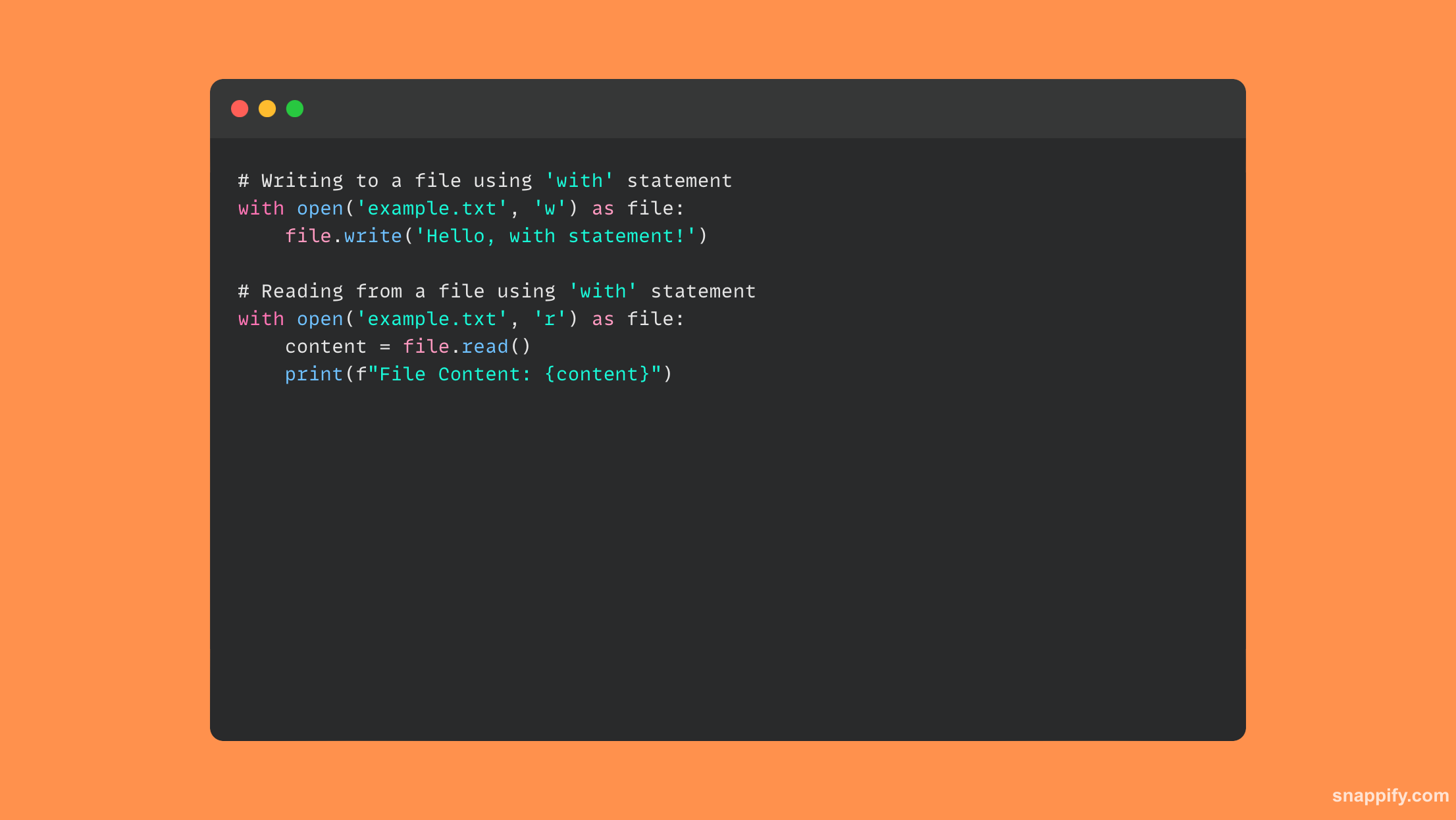
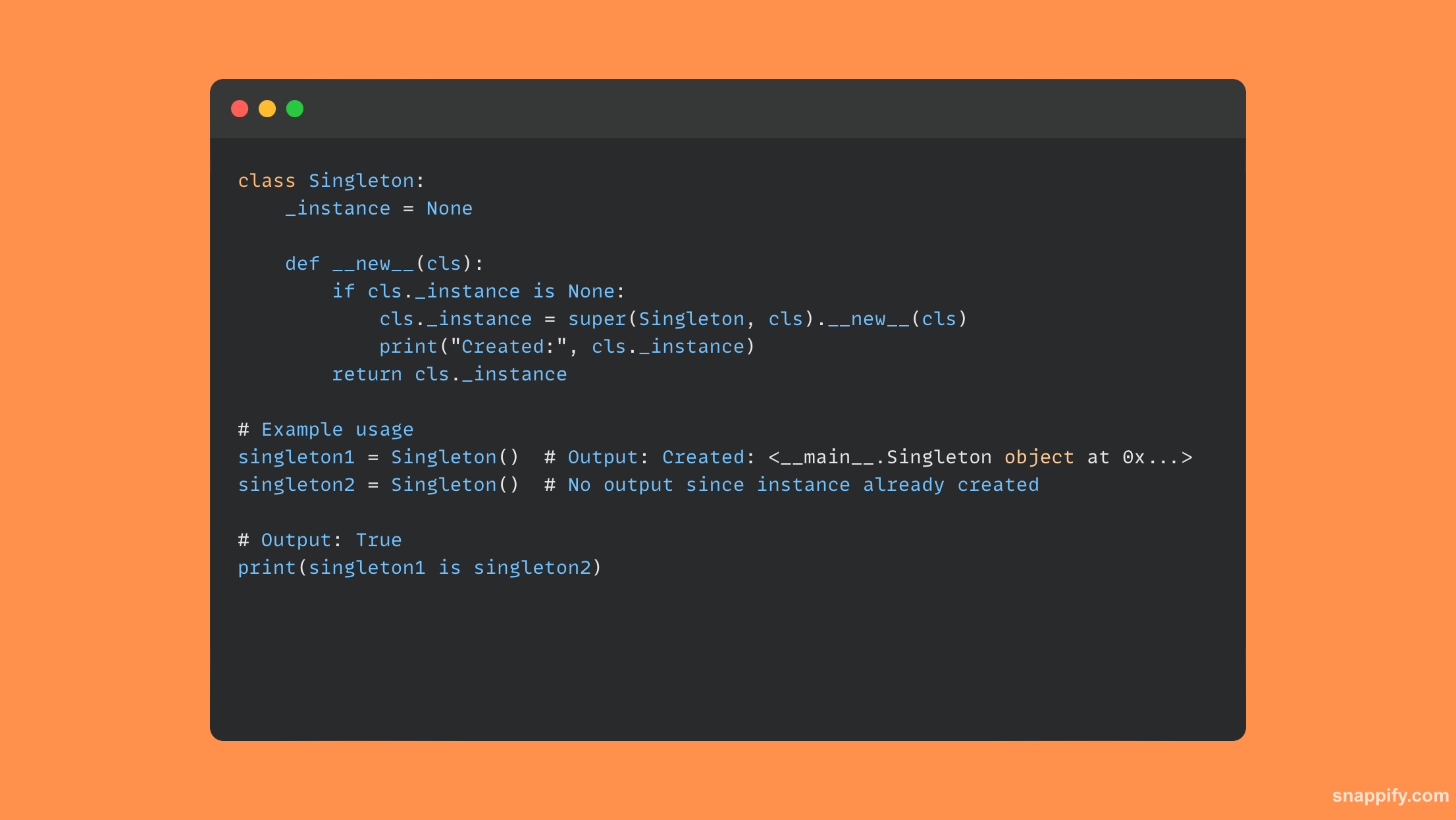
21. आप पायथन में सिंगलटन मॉड्यूल कैसे बनाएंगे?
पायथन में सिंगलटन मॉड्यूल बनाने के लिए क्लास विधियों और आंतरिक जांचों के संयोजन का उपयोग किया जाता है, एक डिज़ाइन पैटर्न जो केवल क्लास के एकल उदाहरण के निर्माण की अनुमति देता है।
अपने स्वयं के उदाहरण का ट्रैक बनाए रखने और इसे उत्पन्न करने या वापस करने के लिए एक विधि प्रदान करके, एक वर्ग यह सुनिश्चित करने के लिए इस पैटर्न का पालन करता है कि बाद के इंस्टेंटिएशन पहले उदाहरण को दोहराते हैं।
नियंत्रण के एक बिंदु, संसाधनों तक एकीकृत पहुंच और प्रतिस्पर्धी हेरफेर के खिलाफ सुरक्षा के साथ, सिंगलटन नियंत्रण के एक बिंदु का आश्वासन देता है।
परिणामस्वरूप, यह साझा संसाधनों को समाहित करने, पूरे कार्यक्रम में लगातार पहुंच और संशोधन की गारंटी देने के लिए एक प्रभावी उपकरण के रूप में विकसित होता है।
यहां सिंगलटन वर्ग को प्रदर्शित करने वाला एक छोटा पायथन कोड नमूना है:
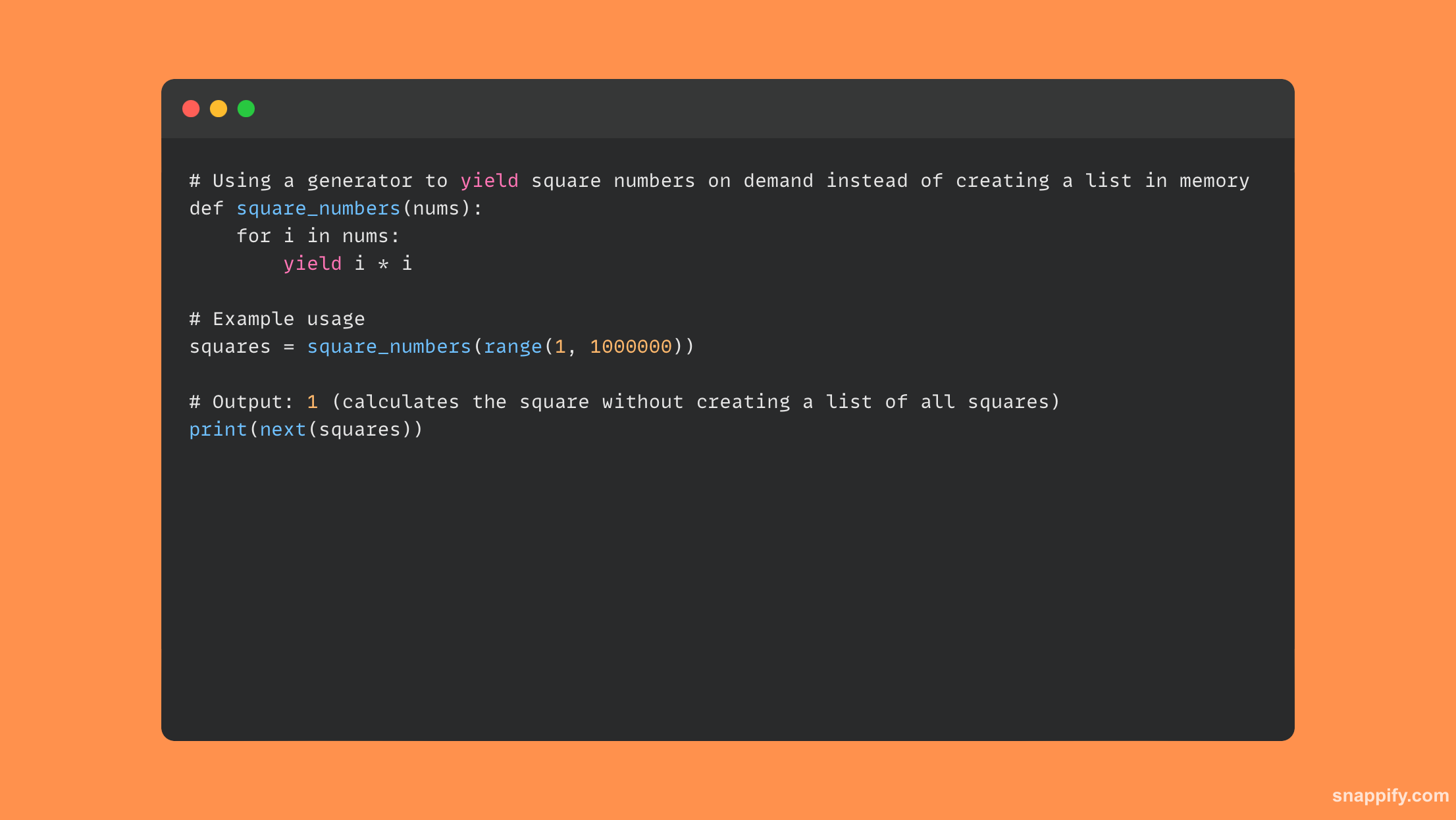
22. पायथन स्क्रिप्ट में मेमोरी उपयोग को अनुकूलित करने के कुछ तरीकों का नाम बताइए।
पायथन स्क्रिप्ट मेमोरी खपत अनुकूलन में अक्सर डेटा संरचना विकल्प, एल्गोरिदम सुधार और संसाधन प्रबंधन के बीच सावधानीपूर्वक संतुलन कार्य शामिल होता है।
उदाहरण के लिए, विशाल डेटासेट के साथ काम करते समय, सूचियों के बजाय जेनरेटर का उपयोग करने से वस्तुओं को मेमोरी में रखने के बजाय तुरंत उनका आकलन करने से मेमोरी के उपयोग को काफी कम किया जा सकता है।
सूचियों के बजाय सरणी डेटा संरचनाओं के साथ संख्यात्मक डेटा को संभालने और संयम से उपयोग करके मेमोरी उपयोग को और कम करना संभव है __slots__ गतिशील विशेषताओं के निर्माण को नियंत्रित करने के लिए इन-क्लास घोषणाएँ।
इस प्रकार, प्रदर्शन और संसाधन उपयोग को संतुलित करके, आप यह सुनिश्चित कर सकते हैं कि पायथन प्रोग्राम न केवल प्रभावी हैं बल्कि वे कितनी मेमोरी का उपयोग करते हैं इसके बारे में भी विचारशील हैं।
यहां कोड का एक संक्षिप्त उदाहरण दिया गया है जो उपयोग की गई मेमोरी की मात्रा को कम करने के लिए जनरेटर का उपयोग करता है:
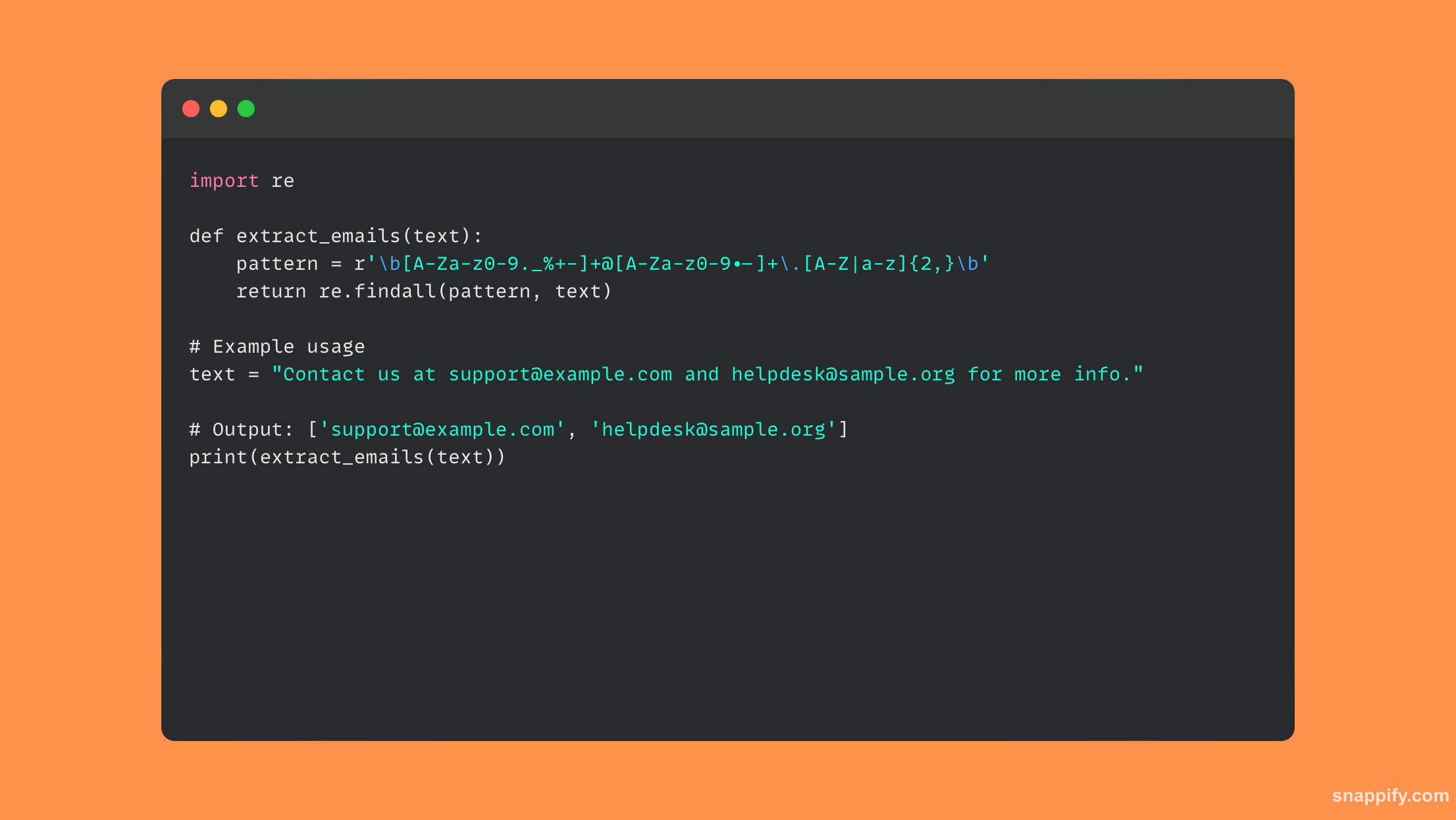
23. आप रेगेक्स का उपयोग करके किसी दिए गए स्ट्रिंग से सभी ईमेल पते कैसे निकालेंगे?
पायथन में नियमित अभिव्यक्ति (रेगेक्स) एक स्ट्रिंग से ईमेल पते निकालने के लिए सटीकता और बहुमुखी प्रतिभा को जोड़ती है, जिससे डेवलपर को पाठ्य सामग्री के माध्यम से चतुराई से फ़िल्टर करने और वांछनीय पैटर्न की पहचान करने की अनुमति मिलती है।
ईमेल पते की संरचना स्थापित करने के लिए, री-मॉड्यूल का उपयोग करके एक रेगेक्स पैटर्न बनाया जाता है। फिर, आप उपयोग कर सकते हैं findall लक्ष्य स्ट्रिंग से सभी घटनाएँ प्राप्त करने के लिए।
यह विधि सभी छिपे हुए ईमेल पते प्राप्त करने के लिए पाठ्य भूलभुलैया को कुशलतापूर्वक नेविगेट करती है, जो न केवल निष्कर्षण प्रक्रिया को गति देती है बल्कि शुद्धता का भी आश्वासन देती है।
रेगेक्स का उपयोग स्ट्रिंग्स से कुछ डेटा को प्रभावी ढंग से निकालने, पायथन स्क्रिप्ट के डेटा प्रोसेसिंग और विश्लेषण को बढ़ाने के लिए कुशलतापूर्वक किया जा सकता है।
यहां कोड का एक टुकड़ा है जो ईमेल निकालने के लिए रेगेक्स का उपयोग करता है:
24. फ़ैक्टरी डिज़ाइन पैटर्न और पायथन में इसके अनुप्रयोग की व्याख्या करें
ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग का मूल सिद्धांत, फ़ैक्टरी डिज़ाइन पैटर्न, उत्पन्न होने वाली वस्तुओं के सटीक वर्ग की पहचान किए बिना वस्तुओं का निर्माण है।
फ़ैक्टरी पैटर्न को पायथन में एक ऐसी विधि बनाकर सुरुचिपूर्ण ढंग से लागू किया जा सकता है जो विधि इनपुट या कॉन्फ़िगरेशन के आधार पर कई वर्गों के उदाहरण लौटाता है।
यह प्रक्रिया, जिसे कभी-कभी "फ़ैक्टरी" के रूप में संदर्भित किया जाता है, कई वर्ग उदाहरणों को बुनने के लिए एक केंद्र के रूप में कार्य करती है, यह गारंटी देती है कि कॉल करने वाले को मैन्युअल रूप से कक्षाओं को इंस्टेंट करने की आवश्यकता के बिना ऑब्जेक्ट बनाए जाते हैं।
इस प्रकार, फ़ैक्टरी पैटर्न कोड मॉड्यूलैरिटी और सामंजस्य में सुधार करते हुए एक डिकॉउप्ड, स्केलेबल आर्किटेक्चर को बनाए रखता है। यह वस्तुओं के निर्माण के लिए एक सरलीकृत तकनीक भी प्रदान करता है।
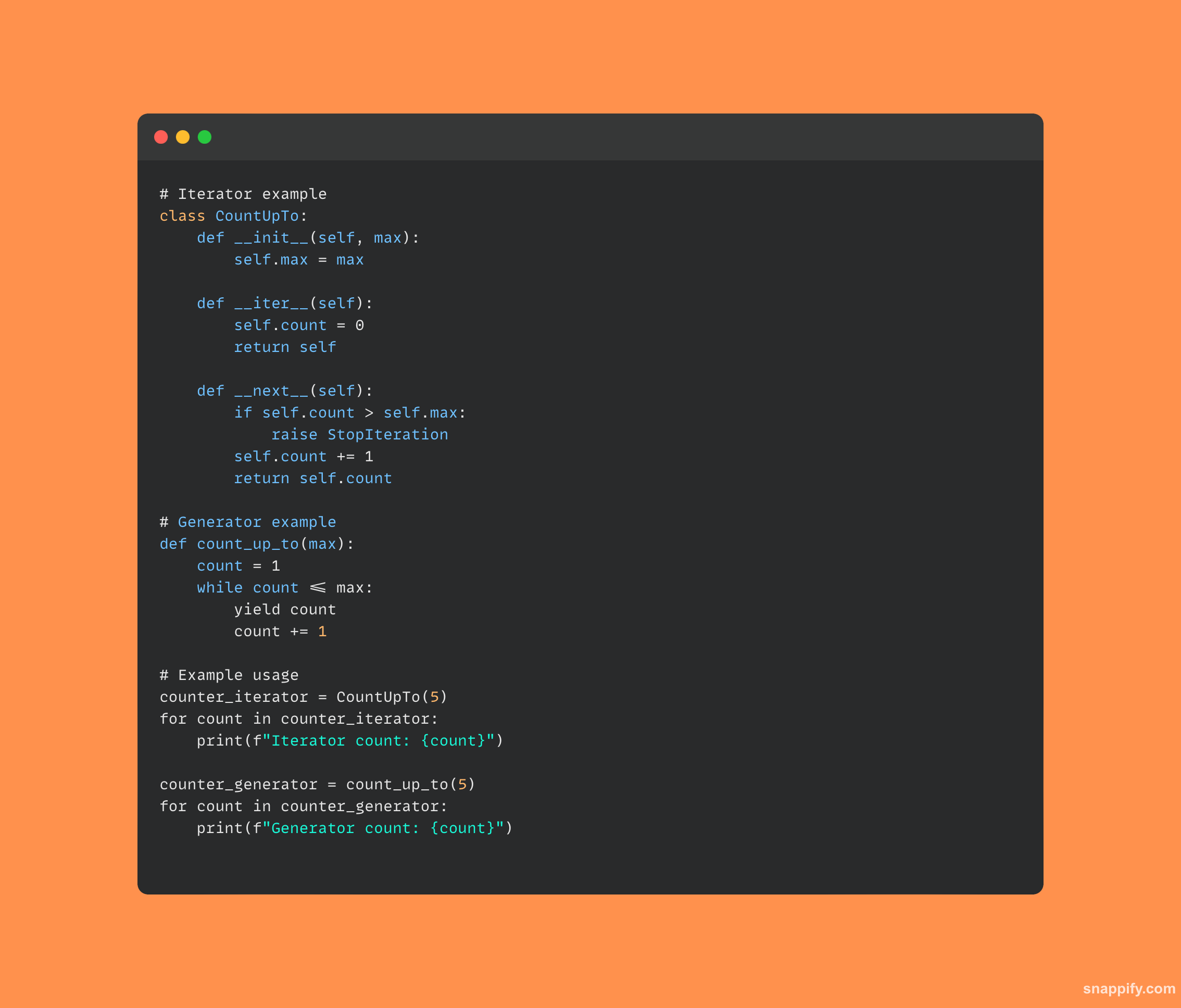
25. इटरेटर और जनरेटर के बीच क्या अंतर है?
पायथन के पुनरावृत्तियों और जनरेटरों से यह स्पष्ट है कि दोनों निर्माण मूल्यों के माध्यम से लूप करना संभव बनाते हैं, हालांकि, उन्हें कैसे कार्यान्वित और उपयोग किया जाता है, इसमें सूक्ष्म अंतर हैं।
एक जनरेटर, जिसे अक्सर उपज के उपयोग से पहचाना जाता है, स्वचालित रूप से अपनी स्थिति बनाए रखता है और एक फ़ंक्शन के साथ कार्यान्वित किया जाता है, जो तुरंत मूल्यों का उत्पादन करने के लिए एक संक्षिप्त और स्मृति-कुशल तरीका प्रदान करता है।
एक पुनरावर्तक, जिसे आम तौर पर एक वर्ग के रूप में कार्यान्वित किया जाता है, जैसे तरीकों का उपयोग करता है __iter__ और __next__ इसकी पुनरावृत्ति स्थिति को प्रबंधित करने और मूल्यों का उत्पादन करने के लिए।
परिणामस्वरूप, विशेष उपयोग के मामले के आधार पर प्रत्येक की अपनी खूबियाँ होती हैं, जिसमें पुनरावर्तक डेटा को पार करने के लिए एक संपूर्ण, वस्तु-उन्मुख तरीका प्रदान करते हैं जबकि जनरेटर एक हल्के, आलसी मूल्यांकन तकनीक की पेशकश करते हैं।
दोनों तकनीकें डेवलपर के शस्त्रागार में इजाफा करती हैं और विभिन्न स्थितियों में डेटा का त्वरित और प्रभावी ढंग से पता लगाना संभव बनाती हैं।
यहां पायथन में एक इटरेटर और जनरेटर के कोड का एक टुकड़ा है:
26. कैसे करता है @property डेकोरेटर का काम?
पायथन में '@प्रॉपर्टी' डेकोरेटर एक सुंदर धुन बजाता है जो विधि कॉल को विशेषता-जैसी पहुंच में परिवर्तित करता है, जिससे ऑब्जेक्ट की उपयोगिता और अभिव्यक्ति में सुधार होता है।
@property का उपयोग करके कोष्ठक का उपयोग किए बिना एक विधि को कॉल किया जा सकता है, जो एक विशेषता तक पहुंचने के समान है। यह ऑब्जेक्ट इंटरैक्शन के लिए एक स्पष्ट और उपयोग में आसान इंटरफ़ेस बनाता है।
इसके अतिरिक्त, यह कार्यक्षमता और एनकैप्सुलेशन का कुशल संतुलन प्रदान करता है, एक सहज इंटरफ़ेस प्रदान करते हुए ऑब्जेक्ट स्थिति की सुरक्षा करता है, डेवलपर्स को गेटर और सेटर तरीकों का उपयोग करके आसानी से विशेषताओं को निर्दिष्ट करने में सक्षम बनाता है।
विशेषता पहुंच के साथ विधि कार्यक्षमता को जोड़कर, @property डेकोरेटर एक महत्वपूर्ण उपकरण के रूप में उभरता है और एक सीधा लेकिन प्रभावी ऑब्जेक्ट इंटरैक्शन प्रतिमान प्रदान करता है।
पायथन का एक उदाहरण @property डेकोरेटर नीचे दिखाया गया है:
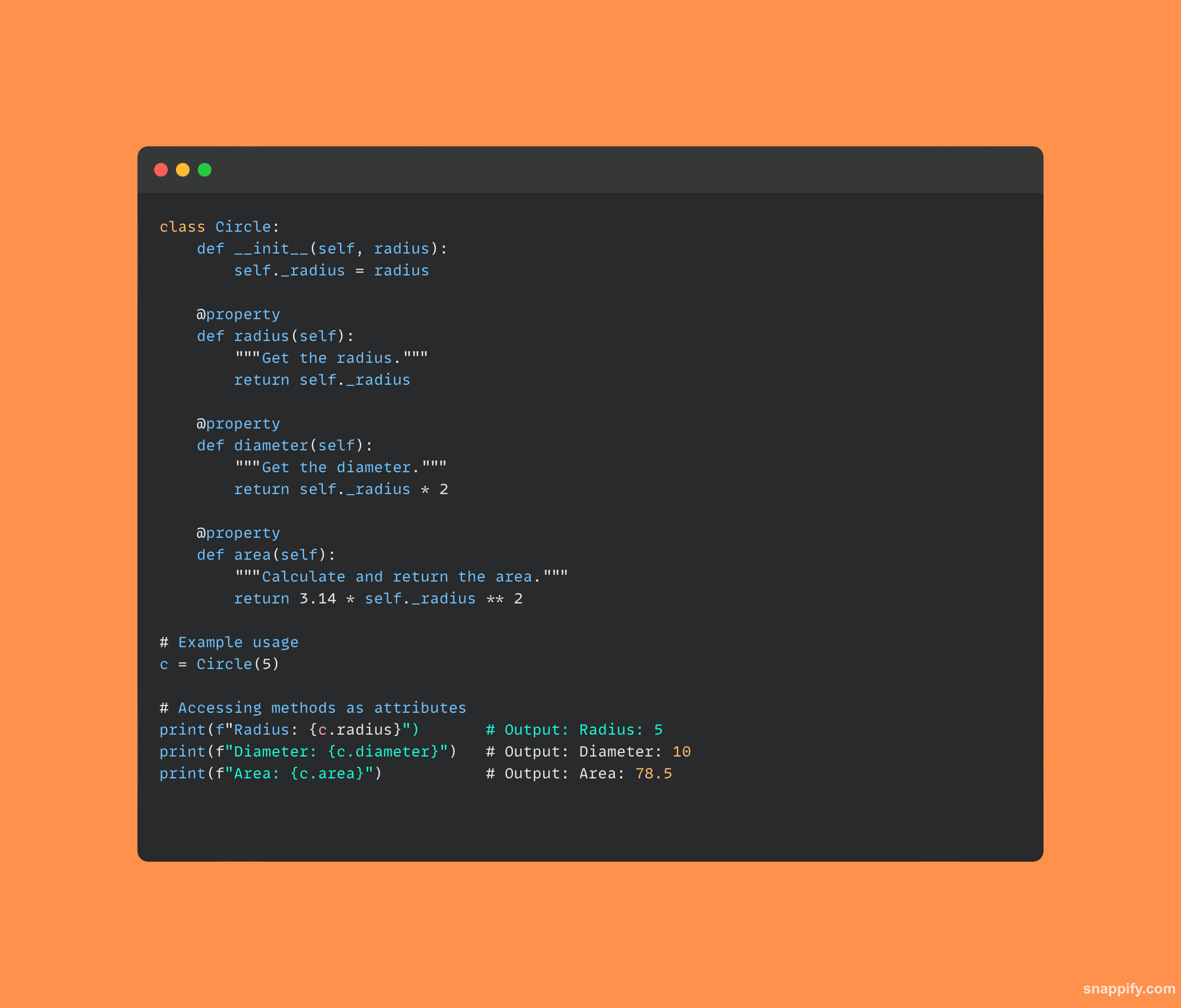
27. आप पायथन में एक बुनियादी REST API कैसे बनाएंगे?
HTTP अनुरोधों के माध्यम से इंटरैक्ट करने वाली वेब सेवाओं का निर्माण करने के लिए, डेवलपर्स अक्सर एक सरल निर्माण करते समय फ्लास्क जैसे फ्रेमवर्क की अभिव्यंजक क्षमता का उपयोग करते हैं। बाकी एपीआई अजगर में।
अपने सरल और समझने योग्य सिंटैक्स के साथ, फ्लास्क डेवलपर्स को ऐसे मार्ग बनाने में सक्षम बनाता है जिन्हें अंतर्निहित एप्लिकेशन के साथ संचार करने के लिए GET और POST सहित कई HTTP तरीकों से एक्सेस किया जा सकता है।
फ्लास्क का उपयोग करके निर्मित एक REST API आसानी से HTTP अनुरोधों को स्वीकार कर सकता है, निहित डेटा को संसाधित कर सकता है, और विभिन्न कार्यक्षमता से जुड़े अद्वितीय समापन बिंदुओं को निर्दिष्ट करके प्रतिक्रिया में प्रासंगिक जानकारी प्रदान कर सकता है।
नेटवर्क वाले वातावरण में विभिन्न सॉफ़्टवेयर घटकों के बीच निर्बाध संचार सुनिश्चित करने के लिए, डेवलपर्स पायथन और फ्लास्क के संयोजन का उपयोग करके शक्तिशाली REST API का उपयोग कर सकते हैं।
यहां कोड का एक छोटा सा टुकड़ा है जो REST API बनाने के लिए फ्लास्क का उपयोग करता है:
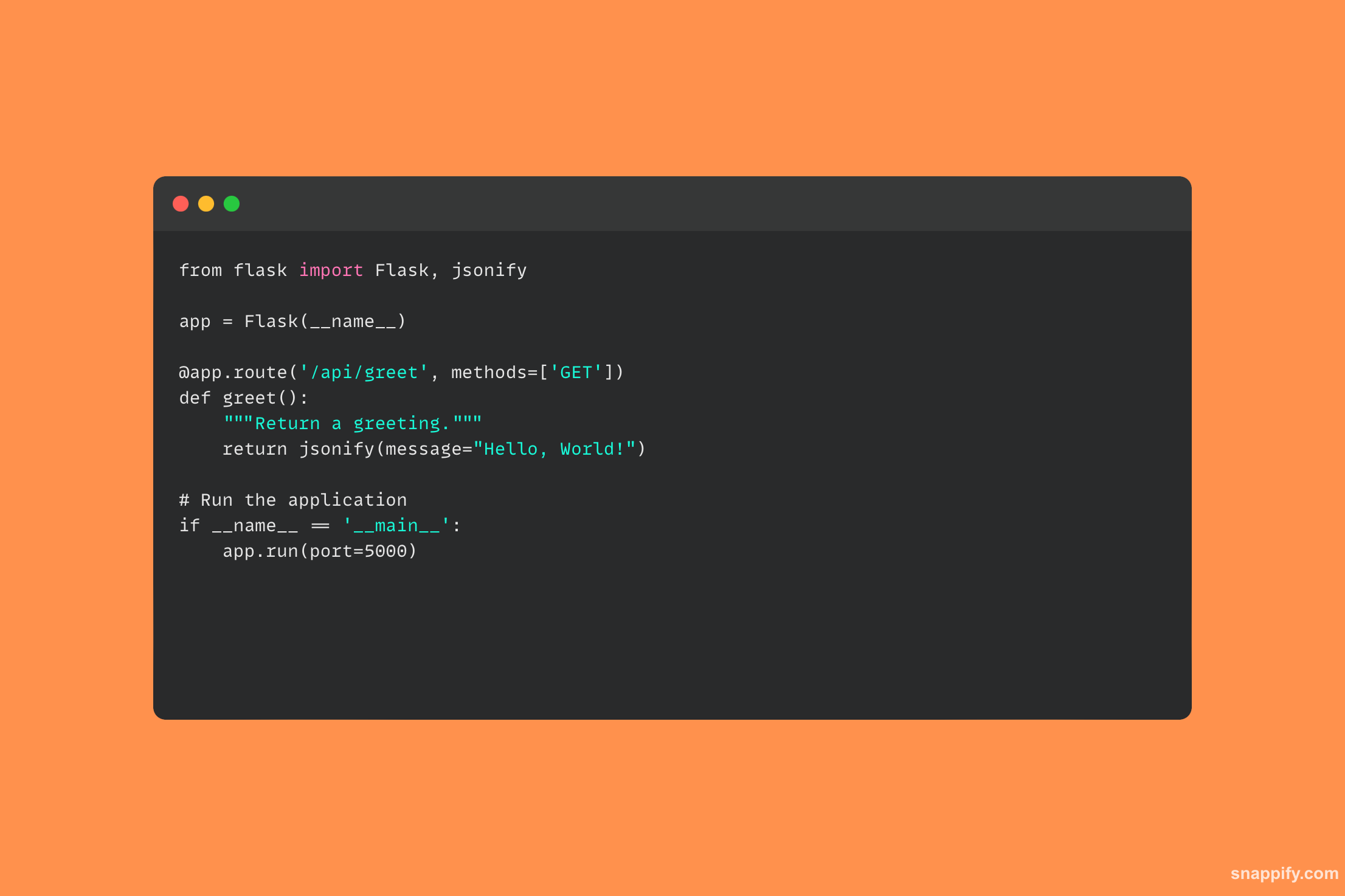
28. HTTP POST अनुरोध करने के लिए अनुरोध लाइब्रेरी का उपयोग करने का तरीका बताएं।
पायथन की अनुरोध लाइब्रेरी एक शक्तिशाली उपकरण है जो HTTP संचार की कठिनाइयों को एक स्वागत योग्य एपीआई में बदल देती है और HTTP POST अनुरोधों का उपयोग करके ऑनलाइन सेवाओं के साथ बातचीत करना सरल और स्वाभाविक बनाती है।
एक POST अनुरोध पोस्ट विधि का उपयोग करके, गंतव्य URL देकर और भेजी जाने वाली सामग्री को संलग्न करके किया जाता है, जिसमें फॉर्म डेटा, JSON, फ़ाइलें और बहुत कुछ हो सकता है।
अनुरोध लाइब्रेरी तब अंतर्निहित HTTP कनेक्शन का प्रबंधन करती है, डेटा को निर्दिष्ट यूआरएल पर भेजती है और तरल वेब इंटरैक्शन को सक्षम करने के लिए सर्वर की प्रतिक्रिया एकत्र करती है।
डेवलपर्स आसानी से ऑनलाइन सेवाओं से जुड़ सकते हैं, फॉर्म डेटा जमा कर सकते हैं और अनुरोधों के माध्यम से वेब एपीआई के साथ इंटरफेस कर सकते हैं, जिससे स्थानीय ऐप्स और वैश्विक वेब के बीच अंतर कम हो सकता है।
अनुरोध लाइब्रेरी का उपयोग करते हुए, निम्न कोड नमूना दिखाता है कि HTTP POST अनुरोध कैसे भेजा जाए:
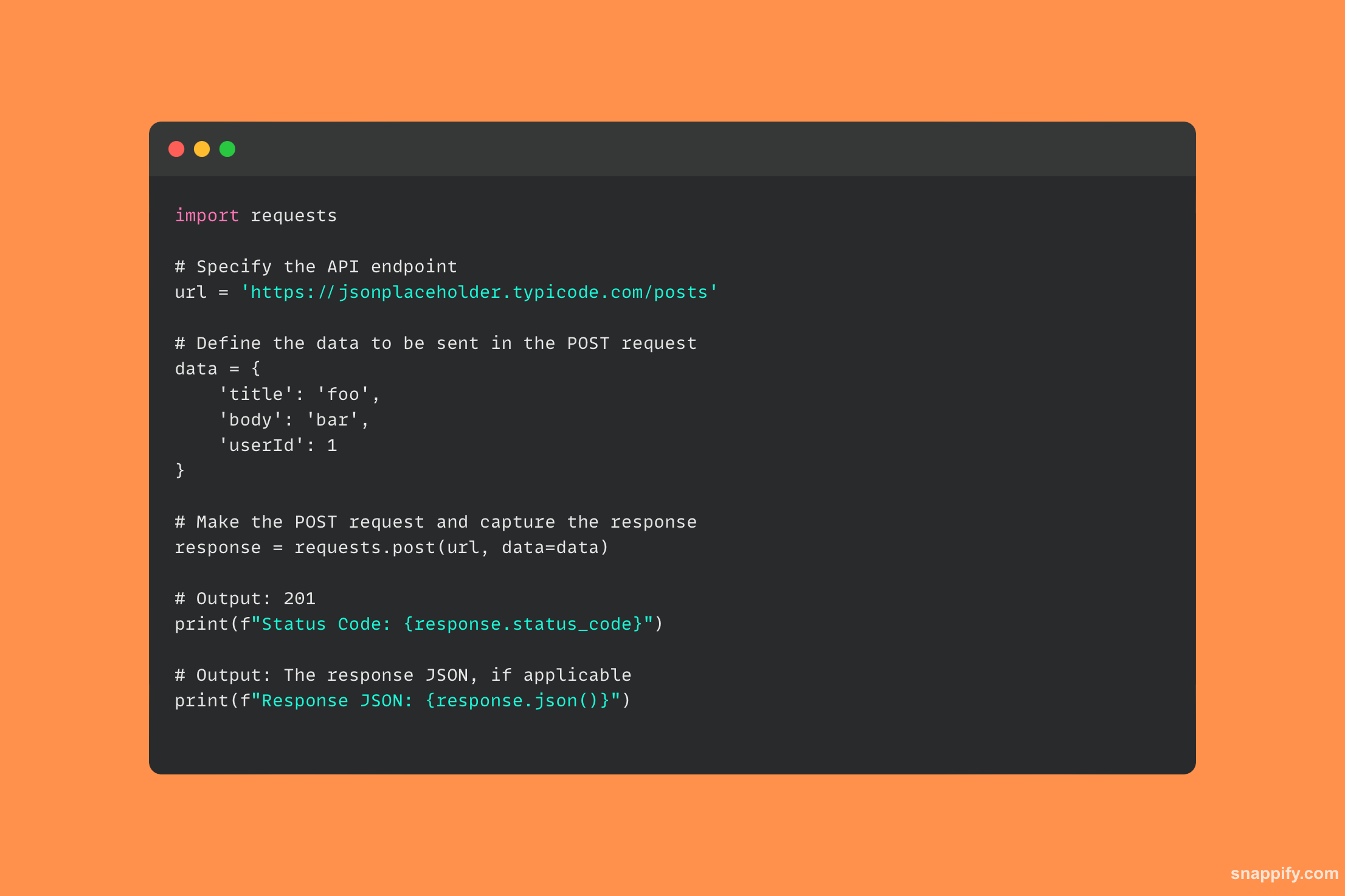
29. आप Python का उपयोग करके PostgreSQL डेटाबेस से कैसे जुड़ेंगे?
Python वातावरण से PostgreSQL डेटाबेस के साथ जुड़ना psycopg2 पैकेज द्वारा सुरुचिपूर्ण ढंग से नियंत्रित किया जाता है, एक शक्तिशाली पुल जो निर्बाध डेटाबेस इंटरैक्शन की अनुमति देता है।
का उपयोग करके psycopg2, प्रोग्रामर आसानी से कनेक्शन बना सकते हैं, SQL क्वेरी चला सकते हैं और परिणाम प्राप्त कर सकते हैं, PostgreSQL की क्षमता को सीधे Python प्रोग्राम में एकीकृत कर सकते हैं।
आप कोड की केवल कुछ पंक्तियों के साथ जटिल डेटाबेस फ़ंक्शंस को अनलॉक कर सकते हैं, यह गारंटी देते हुए कि डेटा सटीकता और दक्षता के साथ एक्सेस, संशोधित और सहेजा गया है।
यह मॉड्यूल डेवलपर्स को पायथन और पोस्टग्रेएसक्यूएल के बीच तालमेल का एहसास करके अपने अनुप्रयोगों में रिलेशनल डेटाबेस का पूरी तरह से उपयोग करने की अनुमति देता है।
यहां नमूना कोड है जो दर्शाता है कि इसका उपयोग कैसे करना है psycopg2 PostgreSQL डेटाबेस से कनेक्शन स्थापित करने के लिए लाइब्रेरी:
30. पायथन में ओआरएम की क्या भूमिका है और एक लोकप्रिय का नाम बताएं?
पायथन में ऑब्जेक्ट-रिलेशनल मैपिंग (ओआरएम) डेवलपर्स को पायथन कक्षाओं और ऑब्जेक्ट प्रतिमानों का उपयोग करके डेटाबेस से जुड़ने में सक्षम बनाता है।
यह ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग और रिलेशनल डेटाबेस प्रशासन के बीच एक हार्मोनिक मध्यस्थ के रूप में कार्य करता है।
SQLAlchemy, Python वातावरण में सबसे प्रसिद्ध ORM में से एक, उच्च-स्तरीय, ऑब्जेक्ट-ओरिएंटेड सिंटैक्स का उपयोग करके कई SQL डेटाबेस के साथ इंटरैक्ट करने के लिए टूल का एक पूरा सेट प्रदान करता है।
SQLAlchemy की मदद से, डेटाबेस इकाइयों को पायथन कक्षाओं के रूप में दर्शाया जा सकता है, इन कक्षाओं के उदाहरण डेटाबेस तालिकाओं में पंक्तियों के रूप में कार्य करते हैं।
यह प्रोग्रामर्स को बिना कोई कच्ची SQL क्वेरी लिखे डेटाबेस के साथ काम करने की अनुमति देता है।
SQL और डेटाबेस कनेक्टिविटी की जटिलता के कारण, SQLAlchemy जैसे ORM अधिक उपयोगकर्ता-अनुकूल, सुरक्षित और रखरखाव योग्य डेटाबेस इंटरैक्शन को संभव बनाते हैं।
यहां एक सरल उदाहरण दिया गया है जो दिखाता है कि SQLAlchemy कैसे काम करता है:
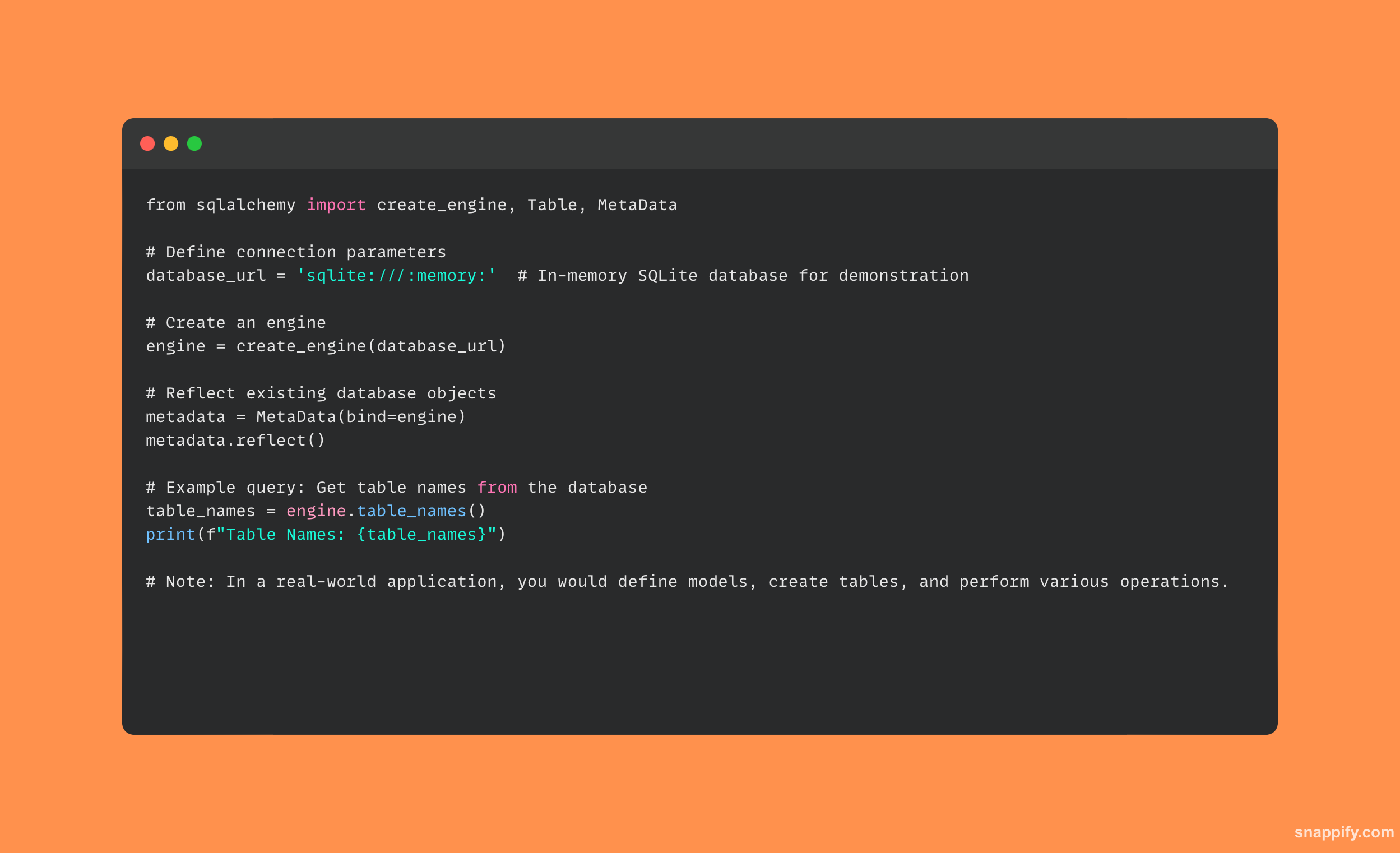
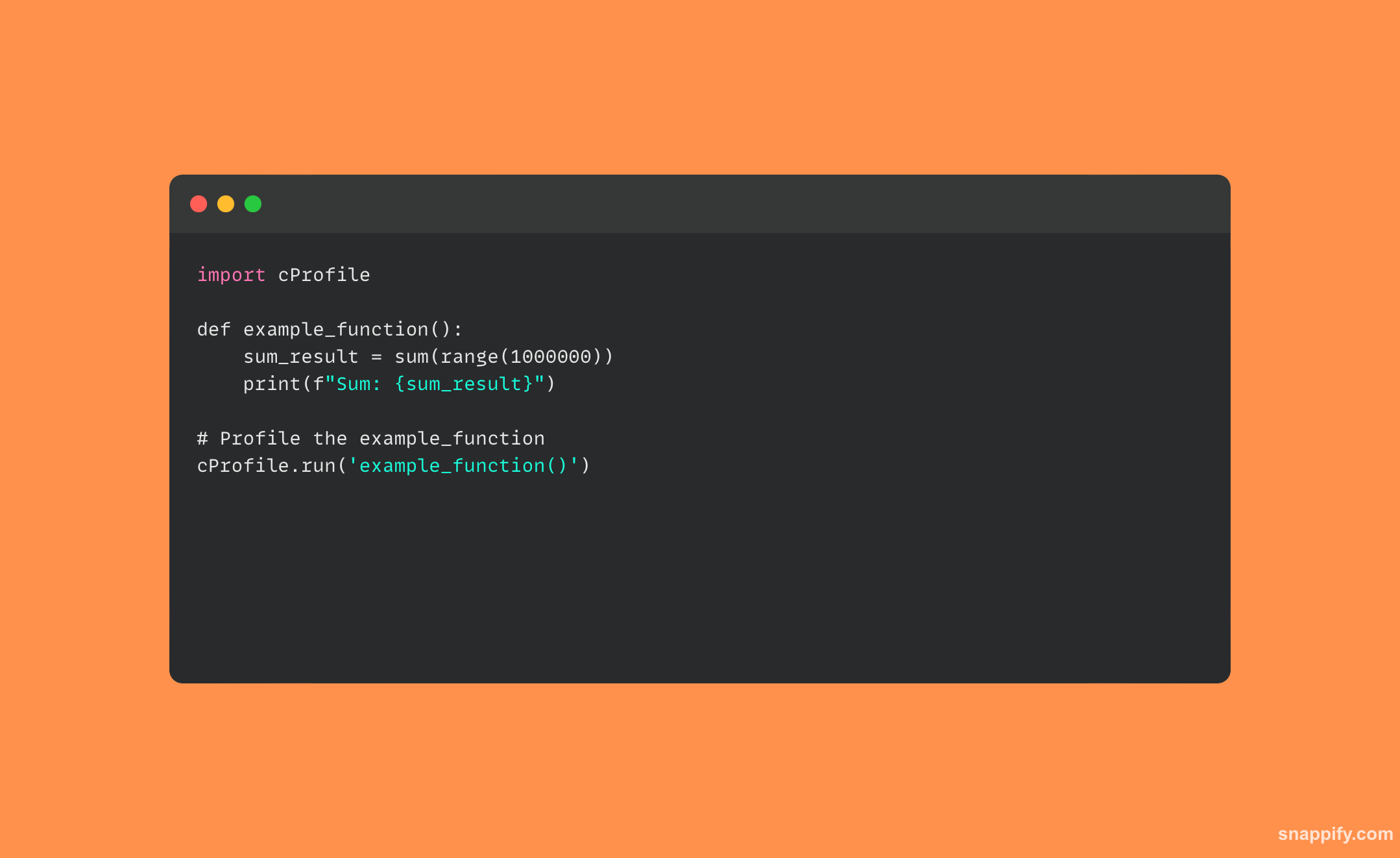
31. आप पायथन लिपि को कैसे प्रोफ़ाइल करेंगे?
किसी भी संभावित प्रदर्शन बाधाओं को खोजने और दक्षता में सुधार करने के लिए इसकी कम्प्यूटेशनल संरचना और इसके निष्पादन के समय और स्थान विवरण का विश्लेषण करके एक पायथन स्क्रिप्ट को प्रोफाइल किया जाता है।
डेवलपर्स बिल्ट-इन का उपयोग करके रनटाइम के दौरान अपने कोड के व्यवहार का सावधानीपूर्वक विश्लेषण कर सकते हैं cProfile मॉड्यूल।
ऐसा करने से, वे फ़ंक्शन कॉल, निष्पादन समय और कॉल संबंधों पर संपूर्ण डेटा प्राप्त कर सकते हैं, जिससे उन्हें प्रदर्शन बाधाओं की पहचान करने और उन्हें संबोधित करने की अनुमति मिलती है।
विकास जीवनचक्र में प्रोफाइलिंग को शामिल करके आप यह गारंटी दे सकते हैं कि कोड न केवल सही ढंग से बल्कि कुशलतापूर्वक काम करता है, कंप्यूटिंग संसाधनों को संतुलित करता है और समग्र एप्लिकेशन प्रदर्शन में सुधार करता है।
इसलिए डेवलपर्स सावधानीपूर्वक प्रोफाइलिंग करके कार्यक्रमों को अक्षमताओं से बचा सकते हैं, यह सुनिश्चित करते हुए कि वे कम्प्यूटेशनल मांगों की एक श्रृंखला में विश्वसनीय रूप से ट्यून और प्रदर्शन कर रहे हैं।
यहां का उपयोग करके पायथन स्क्रिप्ट प्रोफाइलिंग का एक सरल उदाहरण दिया गया है cProfile मॉड्यूल:
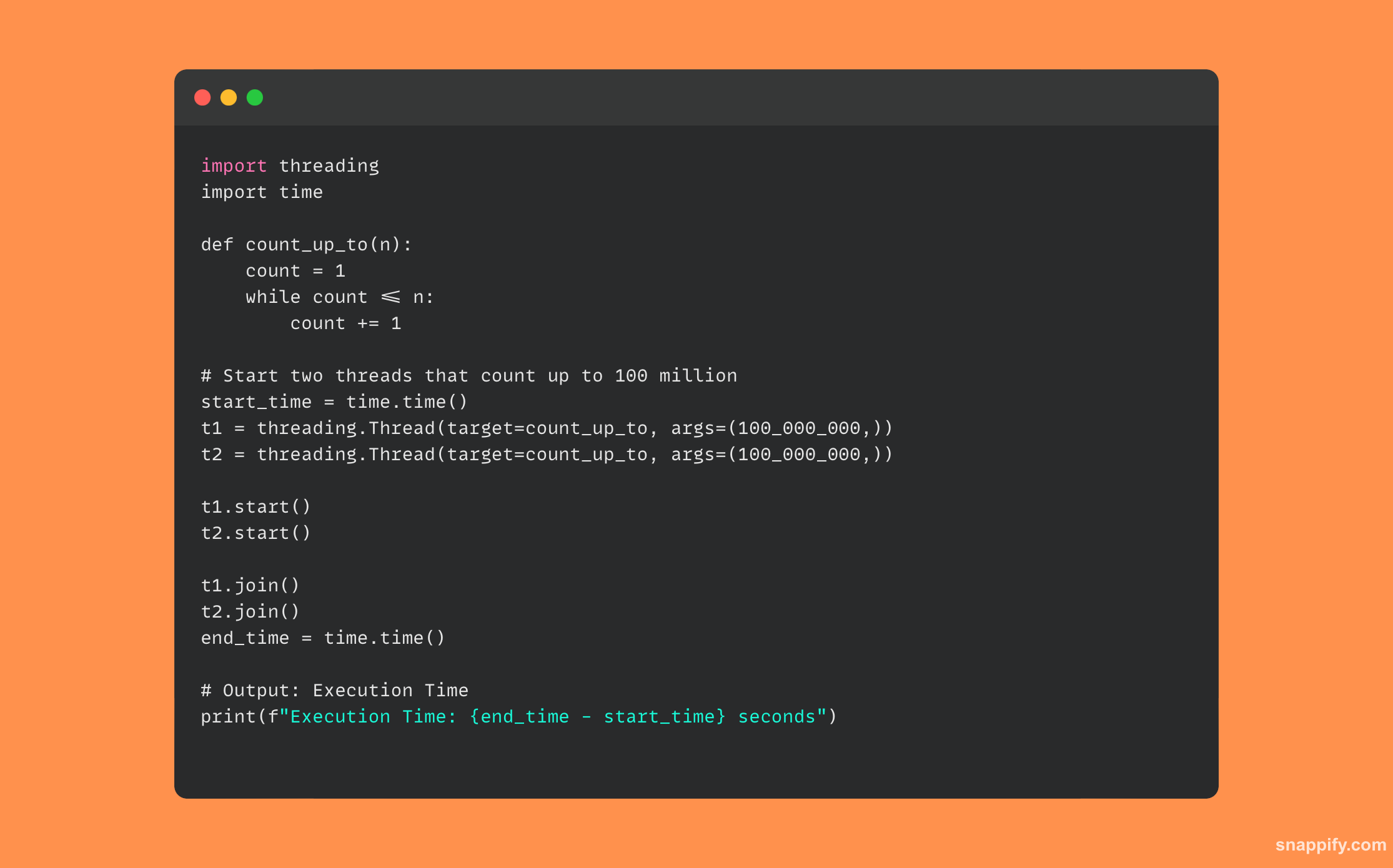
32. सीपीथॉन में जीआईएल (ग्लोबल इंटरप्रेटर लॉक) की व्याख्या करें
CPython में ग्लोबल इंटरप्रेटर लॉक (GIL) एक प्रहरी के रूप में कार्य करता है, जो यह गारंटी देता है कि एक ही प्रक्रिया में एक समय में केवल एक थ्रेड Python बाइटकोड चलाता है, यहां तक कि बहु-थ्रेडेड अनुप्रयोगों में भी।
भले ही यह एक बाधा प्रतीत हो, जीआईएल सीपीथॉन की मेमोरी प्रबंधन और आंतरिक डेटा संरचनाओं को समवर्ती पहुंच से बचाने और सिस्टम अखंडता को संरक्षित करने में महत्वपूर्ण है।
हालांकि, I/O-बाउंड गतिविधियों में मल्टीथ्रेडिंग की आवश्यकता को ध्यान में रखा जाना चाहिए, जहां थ्रेड्स को डेटा वितरित या प्राप्त होने के लिए इंतजार करना होगा, क्योंकि जीआईएल इस आवश्यकता को समाप्त नहीं करता है।
इस प्रकार, भले ही जीआईएल सीपीयू-बाध्य गतिविधियों के लिए कठिनाइयाँ पैदा करता है, इसके व्यवहार की समझ और मल्टीप्रोसेसिंग या समवर्ती प्रोग्रामिंग को नियोजित करने जैसी तकनीकों का अनुकूलन, डेवलपर्स को प्रभावी, समवर्ती पायथन प्रोग्राम बनाने की अनुमति देता है।
यहां पायथन कोड का एक उदाहरण दिया गया है जो थ्रेड्स का उपयोग करता है और दिखाता है कि जीआईएल सीपीयू-बाउंड कार्यों पर कैसे प्रभाव डाल सकता है:
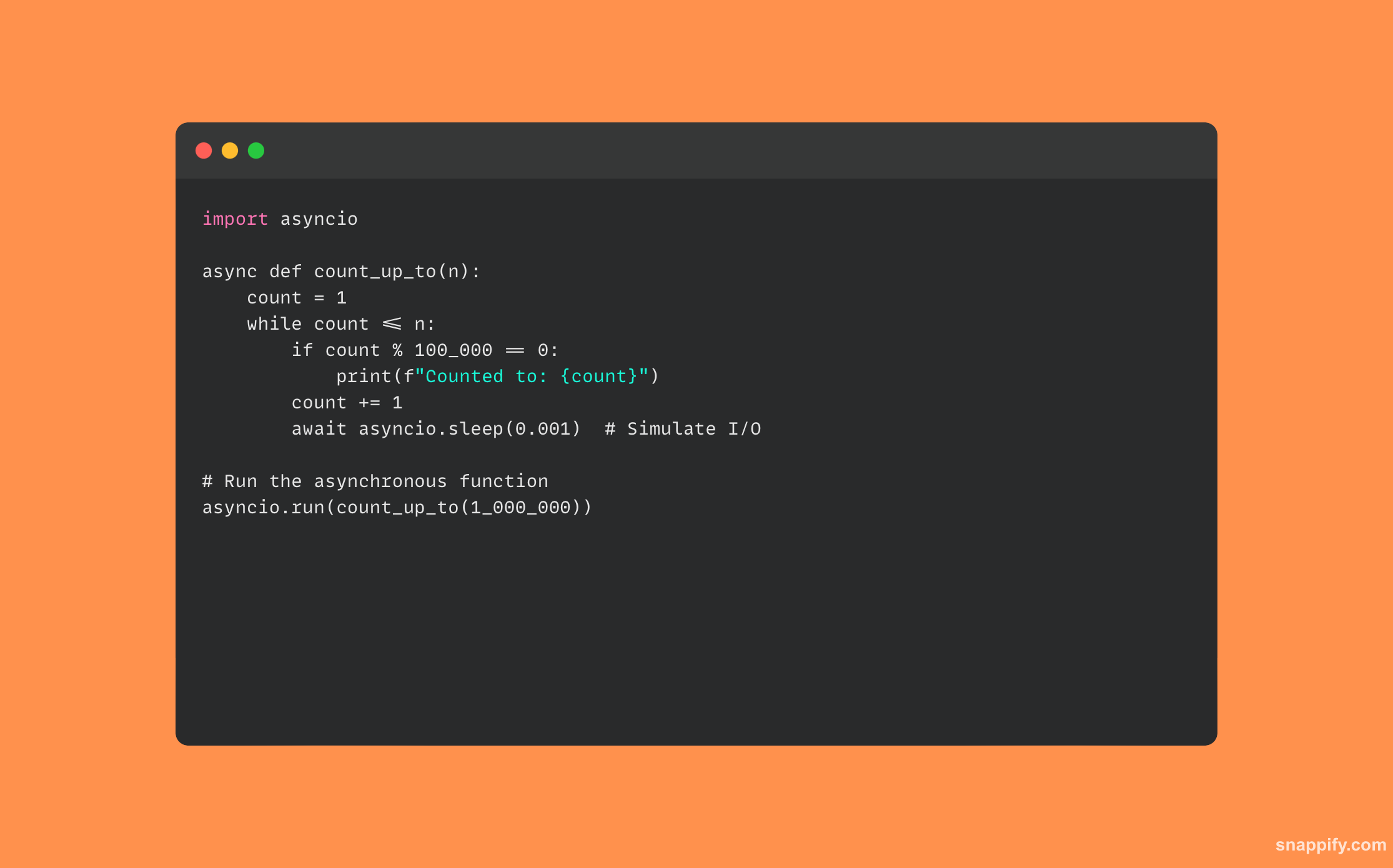
33. पायथन के एसिंक/प्रतीक्षा को समझाइये। यह पारंपरिक थ्रेडिंग से किस प्रकार भिन्न है?
पायथन में एसिंक/वेट सिंटैक्स एसिंक्रोनस प्रोग्रामिंग की दुनिया को खोलता है, एक प्रतिमान जो कुछ कार्यों को रनटाइम वातावरण पर नियंत्रण सौंपने देता है ताकि अन्य गतिविधियां इस बीच प्रदर्शन कर सकें, जिससे प्रोग्राम दक्षता में सुधार हो सके।
Async/await गतिविधियों को एक ही थ्रेड में बनाए रखता है लेकिन निष्पादन को कार्यों के बीच कूदने में सक्षम बनाता है, जिससे थ्रेड प्रबंधन की जटिलता के बिना गैर-अवरुद्ध व्यवहार सुनिश्चित होता है।
यह क्लासिकल थ्रेडिंग के विपरीत है, जहां थ्रेड समानांतर में निष्पादित होते हैं और अक्सर जटिल प्रबंधन और सिंक्रनाइज़ेशन की आवश्यकता होती है।
परिणामस्वरूप, डेवलपर्स समवर्ती I/O-बाउंड गतिविधियों को प्रभावी ढंग से और समवर्ती को नियंत्रित करने के लिए अधिक सरल दृष्टिकोण के साथ संभाल सकते हैं।
यह एक सहकारी मल्टीटास्किंग मॉडल को बढ़ावा देता है जिसमें प्रक्रियाएं स्वेच्छा से नियंत्रण प्रदान करती हैं।
परिणामस्वरूप, async/await समवर्ती अनुप्रयोगों को डिज़ाइन करने के लिए एक विशिष्ट, सरलीकृत तरीका प्रदान करता है, विशेष रूप से जहां I/O संचालन सामान्य होते हैं, प्रदर्शन और जटिलता के बीच संतुलन ढूंढते हैं।
एसिंक/प्रतीक्षा का उपयोग करने वाले पायथन कोड का एक उदाहरण नीचे दिया गया है:
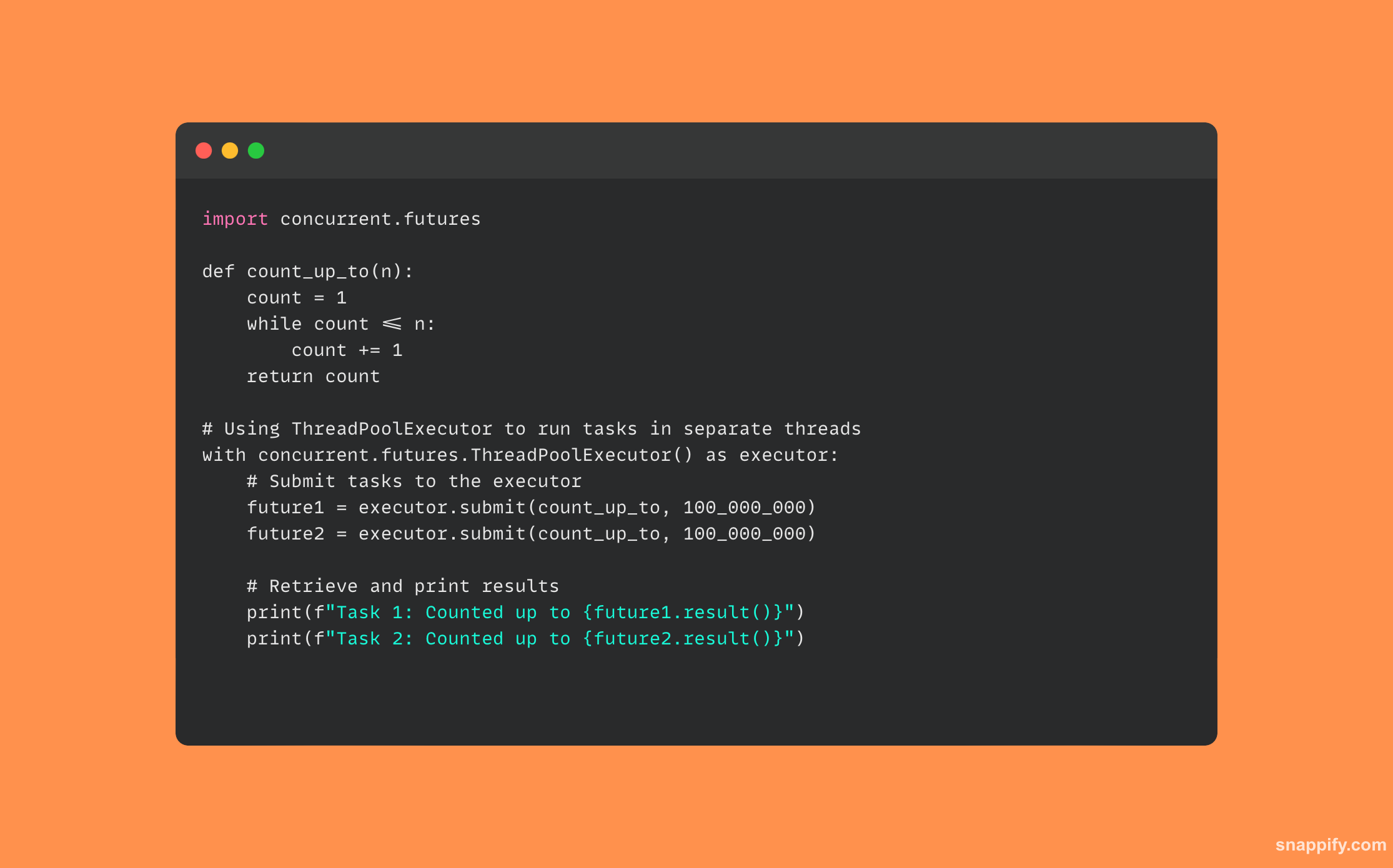
34. वर्णन करें कि आप पायथन का उपयोग कैसे करेंगे concurrent.futures.
थ्रेड या प्रक्रियाओं के माध्यम से कॉलेबल्स को अतुल्यकालिक रूप से निष्पादित करने के लिए इंटरफ़ेस, डेवलपर्स अतुल्यकालिक और समानांतर संचालन को शानदार ढंग से प्रबंधित कर सकते हैं।
यह मॉड्यूल एक्ज़ीक्यूटर्स (थ्रेडपूल एक्ज़ीक्यूटर और प्रोसेसपूल एक्ज़ीक्यूटर) के माध्यम से थ्रेडिंग और मल्टीप्रोसेसिंग के नाजुक पहलुओं को समाहित करते हुए कॉलेबल्स के संसाधन आवंटन और निष्पादन का प्रबंधन करता है।
डेवलपर्स सीपीयू-बाउंड गतिविधियों के लिए मल्टी-कोर प्रोसेसर का प्रभावी ढंग से उपयोग कर सकते हैं और एक निष्पादक को कार्य भेजकर गैर-अवरुद्ध I/O संचालन प्रदान कर सकते हैं, जो उन्हें समवर्ती रूप से निष्पादित कर सकता है और यहां तक कि उनके परिणामों को एकत्रित भी कर सकता है।
यह सुनिश्चित करने के लिए कि एप्लिकेशन प्रतिक्रियाशील और निष्पादन योग्य हैं, concurrent.futures एक ऐसा स्थान बनाता है जहाँ जटिल गणनाएँ और I/O गतिविधियाँ आसानी से विलीन हो सकती हैं।
यहां उपयोग किए जाने वाले कोड का एक नमूना है concurrent.futures:
35. उपयोग के मामले और स्केलेबिलिटी के संदर्भ में Django और फ्लास्क की तुलना करें।
पायथन के वेब फ्रेमवर्क के समूह में दो सितारे, Django और फ्लास्क, प्रत्येक विभिन्न डेवलपर आवश्यकताओं को पूरा करते हुए चमकते हैं।
बड़े पैमाने पर, डेटाबेस-संचालित एप्लिकेशन बनाने वाले प्रोग्रामर्स के लिए, Django पसंद का उपकरण है क्योंकि यह ORM और एक अंतर्निहित एडमिन इंटरफ़ेस के साथ आता है।
हालाँकि, फ्लास्क का सरल और मॉड्यूलर डिज़ाइन डेवलपर्स को अपने स्वयं के घटकों का चयन करने की स्वतंत्रता देता है, जिससे यह छोटी परियोजनाओं या स्थितियों के लिए सही विकल्प बन जाता है जहां एक हल्का, अनुकूलनीय समाधान आवश्यक है।
जब स्केलेबिलिटी की बात आती है तो अधिक मांगों को समायोजित करने के लिए दोनों रूपरेखाओं को बढ़ाया जा सकता है।
हालाँकि, फ्लास्क की दुबली प्रकृति अनुकूलित स्केलिंग रणनीति की अनुमति देती है जो विशेष आवश्यकताओं के अनुरूप होती है, जबकि Django की अंतर्निहित क्षमताएं इसे बड़े, अधिक जटिल परियोजनाओं में त्वरित विकास के लिए एक छोटा सा लाभ दे सकती हैं।
निष्कर्ष
पायथन स्क्रिप्टिंग साक्षात्कार के लिए भाषा की क्षमताओं, जटिलताओं और अनुप्रयोगों के गहन ज्ञान की आवश्यकता होती है।
संपूर्ण तैयारी न केवल किसी की तकनीकी क्षमता को मजबूत करती है, बल्कि आत्मविश्वास भी जगाती है, जिससे आवेदकों को प्रश्नों के कठिन चक्रव्यूह से तेजी से और सटीक रूप से आगे बढ़ने में मदद मिलती है।
अभ्यर्थी यह सुनिश्चित कर सकते हैं कि वे समवर्ती, ओओपी सिद्धांतों और डेटा संरचनाओं जैसे प्रमुख विचारों की समीक्षा करने के साथ-साथ वेब प्रोग्रामिंग और डेटा हेरफेर जैसे व्यावहारिक अनुप्रयोगों में गोता लगाकर बुनियादी और व्यावहारिक दोनों पायथन समस्याओं को संभालने के लिए तैयार हैं।
परिणामस्वरूप, सफलता के लिए एक सर्वांगीण शिक्षा आवश्यक हो जाती है और इससे ऐसी स्थितियाँ पैदा हो सकती हैं जहाँ किसी की पायथन प्रोग्रामिंग क्षमताएँ उत्कृष्ट हो सकती हैं और रचनात्मक हो सकती हैं। देखना हैशडॉर्क की साक्षात्कार श्रृंखला साक्षात्कार की तैयारी में मदद के लिए।





एक जवाब लिखें