विषय - सूची[छिपाना][प्रदर्शन]
अब हम कंप्यूटर की बदौलत अंतरिक्ष के विस्तार और उप-परमाणु कणों की सूक्ष्म जटिलताओं की गणना कर सकते हैं।
जब गिनती और गणना की बात आती है तो कंप्यूटर मनुष्यों को हरा देते हैं, साथ ही तार्किक हां/नहीं प्रक्रियाओं का पालन करते हैं, इसके सर्किटरी के माध्यम से प्रकाश की गति से यात्रा करने वाले इलेक्ट्रॉनों के लिए धन्यवाद।
हालाँकि, हम अक्सर उन्हें "बुद्धिमान" के रूप में नहीं देखते हैं, क्योंकि अतीत में, कंप्यूटर मनुष्यों द्वारा सिखाए (प्रोग्राम किए बिना) कुछ भी नहीं कर सकते थे।
मशीन लर्निंग, जिसमें डीप लर्निंग शामिल है और कृत्रिम बुद्धिमत्ता, वैज्ञानिक और प्रौद्योगिकी सुर्खियों में चर्चा का विषय बन गया है।
मशीन लर्निंग सर्वव्यापी प्रतीत होता है, लेकिन इस शब्द का उपयोग करने वाले बहुत से लोग पर्याप्त रूप से यह परिभाषित करने के लिए संघर्ष करेंगे कि यह क्या है, यह क्या करता है और इसका सबसे अच्छा उपयोग किस लिए किया जाता है।
यह लेख मशीन लर्निंग को स्पष्ट करने का प्रयास करता है, साथ ही ठोस, वास्तविक दुनिया के उदाहरण भी प्रदान करता है कि तकनीक कैसे काम करती है, यह बताने के लिए कि यह इतना फायदेमंद क्यों है।
फिर, हम विभिन्न मशीन लर्निंग पद्धतियों को देखेंगे और देखेंगे कि व्यावसायिक चुनौतियों का समाधान करने के लिए उनका उपयोग कैसे किया जा रहा है।
अंत में, हम मशीन लर्निंग के भविष्य के बारे में कुछ त्वरित भविष्यवाणियों के लिए अपने क्रिस्टल बॉल से परामर्श करेंगे।
मशीन लर्निंग क्या है?
मशीन लर्निंग कंप्यूटर विज्ञान का एक अनुशासन है जो कंप्यूटर को स्पष्ट रूप से सिखाए बिना डेटा से पैटर्न का अनुमान लगाने में सक्षम बनाता है कि वे पैटर्न क्या हैं।
ये निष्कर्ष अक्सर डेटा की सांख्यिकीय विशेषताओं का स्वचालित रूप से आकलन करने और विभिन्न मूल्यों के बीच संबंधों को चित्रित करने के लिए गणितीय मॉडल विकसित करने के लिए एल्गोरिदम का उपयोग करने पर आधारित होते हैं।
शास्त्रीय कंप्यूटिंग के साथ इसकी तुलना करें, जो नियतात्मक प्रणालियों पर आधारित है, जिसमें हम कंप्यूटर को एक निश्चित कार्य करने के लिए पालन करने के लिए नियमों का एक सेट स्पष्ट रूप से देते हैं।
कंप्यूटर प्रोग्रामिंग के इस तरीके को नियम-आधारित प्रोग्रामिंग के रूप में जाना जाता है। मशीन लर्निंग नियम-आधारित प्रोग्रामिंग से अलग है और इससे बेहतर प्रदर्शन करता है कि यह इन नियमों को स्वयं ही निकाल सकता है।
मान लें कि आप एक बैंक प्रबंधक हैं जो यह निर्धारित करना चाहते हैं कि उनके ऋण पर ऋण आवेदन विफल होने वाला है या नहीं।
नियम-आधारित पद्धति में, बैंक प्रबंधक (या अन्य विशेषज्ञ) कंप्यूटर को स्पष्ट रूप से सूचित करेंगे कि यदि आवेदक का क्रेडिट स्कोर एक निश्चित स्तर से नीचे है, तो आवेदन को अस्वीकार कर दिया जाना चाहिए।
हालांकि, एक मशीन लर्निंग प्रोग्राम केवल क्लाइंट क्रेडिट रेटिंग और ऋण परिणामों पर पूर्व डेटा का विश्लेषण करेगा और यह निर्धारित करेगा कि यह सीमा अपने आप क्या होनी चाहिए।
मशीन पिछले डेटा से सीखती है और इस तरह से अपने नियम बनाती है। बेशक, यह मशीन लर्निंग पर केवल एक प्राइमर है; वास्तविक दुनिया के मशीन लर्निंग मॉडल एक बुनियादी दहलीज की तुलना में काफी अधिक जटिल हैं।
बहरहाल, यह मशीन लर्निंग की क्षमता का एक उत्कृष्ट प्रदर्शन है।
कैसे करता है a मशीन सीखना?
चीजों को सरल रखने के लिए, तुलनीय डेटा में पैटर्न का पता लगाकर मशीनें "सीखती हैं"। डेटा को ऐसी जानकारी मानें जो आप बाहरी दुनिया से इकट्ठा करते हैं। मशीन को जितना अधिक डेटा खिलाया जाता है, वह उतना ही "होशियार" होता जाता है।
हालांकि, सभी डेटा समान नहीं हैं। मान लें कि आप द्वीप पर दबे हुए धन को उजागर करने के लिए एक जीवन उद्देश्य के साथ एक समुद्री डाकू हैं। आप पुरस्कार का पता लगाने के लिए पर्याप्त मात्रा में ज्ञान चाहते हैं।
यह ज्ञान, डेटा की तरह, आपको सही या गलत तरीके से ले जा सकता है।
जितनी अधिक जानकारी/डेटा प्राप्त होता है, उतनी ही कम अस्पष्टता होती है, और इसके विपरीत। नतीजतन, यह विचार करना महत्वपूर्ण है कि आप अपनी मशीन को किस प्रकार का डेटा खिला रहे हैं, जिससे आप सीख सकें।
हालाँकि, एक बार पर्याप्त मात्रा में डेटा प्रदान करने के बाद, कंप्यूटर भविष्यवाणियाँ कर सकता है। मशीनें भविष्य का अनुमान तब तक लगा सकती हैं जब तक वह अतीत से ज्यादा विचलित न हो जाए।
क्या होने की संभावना है यह निर्धारित करने के लिए ऐतिहासिक डेटा का विश्लेषण करके मशीनें "सीखती हैं"।
यदि पुराना डेटा नए डेटा से मिलता-जुलता है, तो आप पिछले डेटा के बारे में जो बातें कह सकते हैं, उनके नए डेटा पर लागू होने की संभावना है। यह ऐसा है जैसे आप आगे देखने के लिए पीछे मुड़कर देख रहे हों।
मशीन लर्निंग कितने प्रकार की होती है?
मशीन लर्निंग के लिए एल्गोरिदम को अक्सर तीन व्यापक प्रकारों में वर्गीकृत किया जाता है (हालांकि अन्य वर्गीकरण योजनाओं का भी उपयोग किया जाता है):
- पर्यवेक्षित अध्ययन
- अशिक्षित शिक्षा
- सुदृढीकरण सीखना
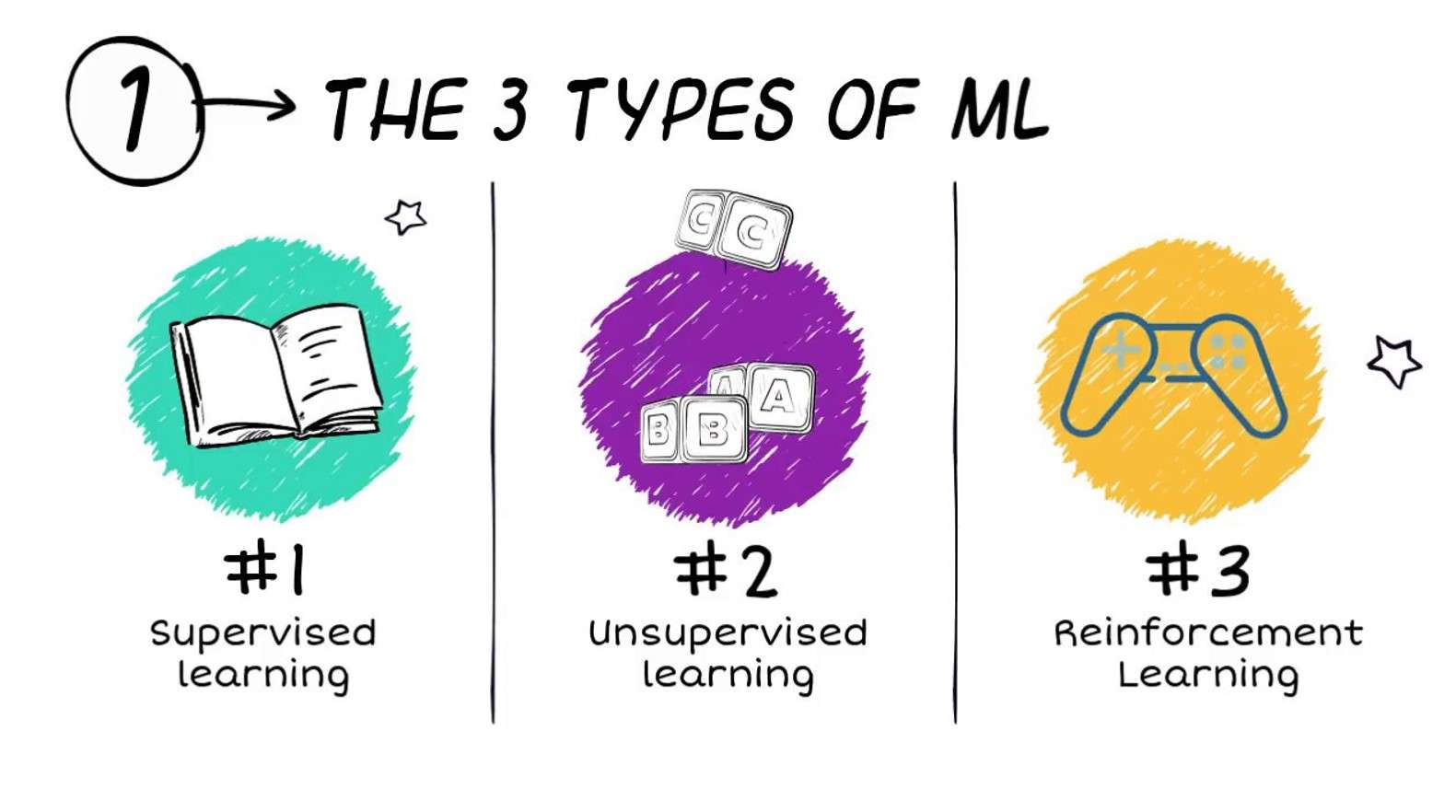
पर्यवेक्षित अध्ययन
पर्यवेक्षित मशीन लर्निंग उन तकनीकों को संदर्भित करता है जिसमें मशीन लर्निंग मॉडल को ब्याज की मात्रा के लिए स्पष्ट लेबल वाले डेटा का संग्रह दिया जाता है (इस मात्रा को अक्सर प्रतिक्रिया या लक्ष्य के रूप में जाना जाता है)।
एआई मॉडल को प्रशिक्षित करने के लिए, अर्ध-पर्यवेक्षित शिक्षण लेबल और बिना लेबल वाले डेटा के मिश्रण को नियोजित करता है।
यदि आप लेबल रहित डेटा के साथ काम कर रहे हैं, तो आपको कुछ डेटा लेबलिंग करने की आवश्यकता होगी।
लेबलिंग मदद करने के लिए नमूनों को लेबल करने की प्रक्रिया है एक मशीन सीखने का प्रशिक्षण नमूना। लेबलिंग मुख्य रूप से लोगों द्वारा किया जाता है, जो महंगा और समय लेने वाला हो सकता है। हालाँकि, लेबलिंग प्रक्रिया को स्वचालित करने की तकनीकें हैं।
हमने पहले जिस ऋण आवेदन स्थिति पर चर्चा की, वह पर्यवेक्षित शिक्षण का एक उत्कृष्ट उदाहरण है। हमारे पास पूर्व ऋण आवेदकों की क्रेडिट रेटिंग (और शायद आय स्तर, आयु, और इसी तरह) के साथ-साथ विशिष्ट लेबल के बारे में ऐतिहासिक डेटा था जो हमें बताता है कि प्रश्न में व्यक्ति ने अपने ऋण पर चूक की है या नहीं।
प्रतिगमन और वर्गीकरण पर्यवेक्षित शिक्षण तकनीकों के दो सबसेट हैं।
- वर्गीकरण - यह डेटा को सही ढंग से वर्गीकृत करने के लिए एक एल्गोरिथम का उपयोग करता है। स्पैम फ़िल्टर एक उदाहरण हैं। "स्पैम" एक व्यक्तिपरक श्रेणी हो सकती है—स्पैम और गैर-स्पैम संचार के बीच की रेखा धुंधली होती है—और स्पैम फ़िल्टर एल्गोरिथम लगातार आपकी प्रतिक्रिया के आधार पर खुद को परिष्कृत कर रहा है (मतलब ईमेल जिसे मनुष्य स्पैम के रूप में चिह्नित करते हैं)।
- प्रतीपगमन - यह आश्रित और स्वतंत्र चर के बीच संबंध को समझने में सहायक है। रिग्रेशन मॉडल कई डेटा स्रोतों के आधार पर संख्यात्मक मानों का अनुमान लगा सकते हैं, जैसे किसी निश्चित कंपनी के लिए बिक्री राजस्व अनुमान। लीनियर रिग्रेशन, लॉजिस्टिक रिग्रेशन और पॉलीनोमियल रिग्रेशन कुछ प्रमुख रिग्रेशन तकनीकें हैं।
अशिक्षित शिक्षा
बिना पर्यवेक्षित शिक्षण में, हमें बिना लेबल वाला डेटा दिया जाता है और हम केवल पैटर्न की तलाश में रहते हैं। आइए दिखाते हैं कि आप अमेज़न हैं। क्या हम ग्राहक खरीद इतिहास के आधार पर कोई क्लस्टर (समान उपभोक्ताओं के समूह) ढूंढ सकते हैं?
भले ही हमारे पास किसी व्यक्ति की प्राथमिकताओं के बारे में स्पष्ट, निर्णायक डेटा न हो, इस उदाहरण में, केवल यह जानकर कि उपभोक्ताओं का एक विशिष्ट समूह तुलनीय सामान खरीदता है, हमें क्लस्टर में अन्य व्यक्तियों ने भी क्या खरीदा है, इसके आधार पर खरीदारी के सुझाव देने की अनुमति देता है।
अमेज़ॅन का "आप में भी रुचि हो सकती है" हिंडोला समान तकनीकों द्वारा संचालित है।
आप जिसे एक साथ समूहित करना चाहते हैं, उसके आधार पर अप्रशिक्षित शिक्षण डेटा को क्लस्टरिंग या एसोसिएशन के माध्यम से समूहित कर सकता है।
- क्लस्टरिंग - अप्रशिक्षित शिक्षण डेटा में पैटर्न की खोज करके इस चुनौती को दूर करने का प्रयास करता है। यदि कोई समान क्लस्टर या समूह है, तो एल्गोरिथ्म उन्हें एक निश्चित तरीके से वर्गीकृत करेगा। पिछले खरीदारी इतिहास के आधार पर ग्राहकों को वर्गीकृत करने का प्रयास इसका एक उदाहरण है।
- संघ - विभिन्न समूहों में अंतर्निहित नियमों और अर्थों को समझने की कोशिश करके इस चुनौती से निपटने के लिए अप्रशिक्षित शिक्षण प्रयास करता है। साहचर्य समस्या का एक सामान्य उदाहरण ग्राहक खरीद के बीच एक कड़ी का निर्धारण कर रहा है। स्टोर्स को यह जानने में दिलचस्पी हो सकती है कि कौन से सामान एक साथ खरीदे गए थे और इस जानकारी का उपयोग इन उत्पादों की स्थिति को आसान बनाने के लिए व्यवस्थित करने के लिए कर सकते हैं।
सुदृढीकरण सीखना
रीइन्फोर्समेंट लर्निंग मशीन लर्निंग मॉडल को इंटरएक्टिव सेटिंग में लक्ष्य-उन्मुख निर्णयों की एक श्रृंखला बनाने के लिए एक तकनीक है। ऊपर वर्णित गेमिंग उपयोग के मामले इसके उत्कृष्ट उदाहरण हैं।
आपको पिछले हजारों शतरंज खेलों में अल्फाज़ेरो को इनपुट करने की ज़रूरत नहीं है, प्रत्येक में "अच्छा" या "खराब" लेबल वाला चाल है। बस इसे खेल के नियम और लक्ष्य सिखाएं, और फिर इसे यादृच्छिक कृत्यों को आजमाने दें।
उन गतिविधियों को सकारात्मक सुदृढीकरण दिया जाता है जो कार्यक्रम को लक्ष्य के करीब ले जाते हैं (जैसे कि एक ठोस प्यादा स्थिति विकसित करना)। जब कृत्यों का विपरीत प्रभाव पड़ता है (जैसे समय से पहले राजा को स्थानांतरित करना), तो वे नकारात्मक सुदृढीकरण अर्जित करते हैं।
सॉफ्टवेयर अंततः इस पद्धति का उपयोग करके खेल में महारत हासिल कर सकता है।
सुदृढीकरण सीखना जटिल और कठिन-से-इंजीनियर कार्यों के लिए रोबोटों को पढ़ाने के लिए रोबोटिक्स में व्यापक रूप से उपयोग किया जाता है। यातायात प्रवाह में सुधार के लिए कभी-कभी सड़क के बुनियादी ढांचे, जैसे ट्रैफिक सिग्नल के संयोजन के साथ इसका उपयोग किया जाता है।
मशीन लर्निंग से क्या किया जा सकता है?
समाज और उद्योग में मशीन लर्निंग के उपयोग के परिणामस्वरूप मानव प्रयासों की एक विस्तृत श्रृंखला में प्रगति हुई है।
हमारे दैनिक जीवन में, मशीन लर्निंग अब Google की खोज और छवि एल्गोरिदम को नियंत्रित करती है, जिससे हमें उस जानकारी के साथ अधिक सटीक मिलान करने की अनुमति मिलती है जब हमें इसकी आवश्यकता होती है।
चिकित्सा में, उदाहरण के लिए, मशीन लर्निंग को आनुवंशिक डेटा पर लागू किया जा रहा है ताकि डॉक्टरों को यह समझने और भविष्यवाणी करने में मदद मिल सके कि कैंसर कैसे फैलता है, जिससे अधिक प्रभावी उपचार विकसित करने की अनुमति मिलती है।
बड़े पैमाने पर रेडियो दूरबीनों के माध्यम से पृथ्वी पर गहरे अंतरिक्ष से डेटा एकत्र किया जा रहा है - और मशीन लर्निंग के साथ विश्लेषण करने के बाद, यह हमें ब्लैक होल के रहस्यों को जानने में मदद कर रहा है।
रिटेल में मशीन लर्निंग खरीदारों को उन चीजों से जोड़ता है जिन्हें वे ऑनलाइन खरीदना चाहते हैं, और दुकान के कर्मचारियों को उनके द्वारा अपने ग्राहकों को ईंट-और-मोर्टार दुनिया में प्रदान की जाने वाली सेवा को तैयार करने में भी मदद करता है।
मशीन लर्निंग का उपयोग आतंकवाद और उग्रवाद के खिलाफ लड़ाई में उन लोगों के व्यवहार का अनुमान लगाने के लिए किया जाता है जो निर्दोषों को चोट पहुंचाना चाहते हैं।
प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कंप्यूटर को मशीन सीखने के माध्यम से मानव भाषा में हमारे साथ समझने और संवाद करने की अनुमति देने की प्रक्रिया को संदर्भित करता है, और इसके परिणामस्वरूप अनुवाद तकनीक के साथ-साथ आवाज नियंत्रित उपकरणों में भी सफलता मिली है जिसका हम हर दिन तेजी से उपयोग करते हैं, जैसे कि एलेक्सा, गूगल डॉट, सिरी और गूगल असिस्टेंट।
बिना किसी सवाल के, मशीन लर्निंग यह प्रदर्शित कर रहा है कि यह एक परिवर्तनकारी तकनीक है।
रोबोट हमारे साथ काम करने में सक्षम हैं और अपने निर्दोष तर्क और अलौकिक गति के साथ अपनी मौलिकता और कल्पना को बढ़ावा देने में सक्षम हैं - वे अब एक विज्ञान कथा कल्पना नहीं हैं - वे कई क्षेत्रों में एक वास्तविकता बन रहे हैं।
मशीन लर्निंग उपयोग के मामले
1. साइबर सुरक्षा
जैसे-जैसे नेटवर्क अधिक जटिल होते गए हैं, साइबर सुरक्षा विशेषज्ञों ने सुरक्षा खतरों की लगातार बढ़ती सीमा के अनुकूल होने के लिए अथक प्रयास किया है।
तेजी से विकसित हो रहे मैलवेयर और हैकिंग रणनीति का मुकाबला करना काफी चुनौतीपूर्ण है, लेकिन इंटरनेट ऑफ थिंग्स (IoT) उपकरणों के प्रसार ने साइबर सुरक्षा वातावरण को मौलिक रूप से बदल दिया है।
हमले किसी भी क्षण और कहीं भी हो सकते हैं।
शुक्र है, मशीन लर्निंग एल्गोरिदम ने साइबर सुरक्षा संचालन को इन तेज विकासों के साथ बनाए रखने में सक्षम बनाया है।
भविष्यिक विश्लेषण हमलों का तेजी से पता लगाने और उन्हें कम करने में सक्षम बनाता है, जबकि मशीन लर्निंग मौजूदा सुरक्षा तंत्र में असामान्यताओं और कमजोरियों का पता लगाने के लिए नेटवर्क के अंदर आपकी गतिविधि का विश्लेषण कर सकता है।
2. ग्राहक सेवा का स्वचालन
ऑनलाइन क्लाइंट संपर्कों की बढ़ती संख्या के प्रबंधन ने बहुत अधिक संगठन को तनावपूर्ण बना दिया है।
उनके पास प्राप्त होने वाली पूछताछ की मात्रा को संभालने के लिए पर्याप्त ग्राहक सेवा कर्मी नहीं हैं, और मुद्दों को आउटसोर्स करने का पारंपरिक दृष्टिकोण संपर्क केंद्र आज के कई ग्राहकों के लिए यह बिल्कुल अस्वीकार्य है।
मशीन लर्निंग तकनीकों में हुई प्रगति की बदौलत चैटबॉट और अन्य स्वचालित सिस्टम अब इन मांगों को पूरा कर सकते हैं। कंपनियां सांसारिक और निम्न-प्राथमिकता वाली गतिविधियों को स्वचालित करके अधिक उच्च-स्तरीय ग्राहक सहायता करने के लिए कर्मियों को मुक्त कर सकती हैं।
जब सही तरीके से उपयोग किया जाता है, तो व्यवसाय में मशीन लर्निंग समस्या समाधान को कारगर बनाने में मदद कर सकता है और उपभोक्ताओं को उस प्रकार का सहायक समर्थन प्रदान कर सकता है जो उन्हें प्रतिबद्ध ब्रांड चैंपियन बनने में मदद करता है।
3. संचार
किसी भी प्रकार के संचार में त्रुटियों और गलतफहमियों से बचना महत्वपूर्ण है, लेकिन आज के व्यावसायिक संचार में इससे भी अधिक महत्वपूर्ण है।
सरल व्याकरण संबंधी गलतियाँ, गलत स्वर, या गलत अनुवाद ईमेल संपर्क, ग्राहक मूल्यांकन में कई तरह की कठिनाइयों का कारण बन सकते हैं, वीडियो कॉन्फ्रेंसिंग, या टेक्स्ट-आधारित दस्तावेज़ कई रूपों में।
मशीन लर्निंग सिस्टम में माइक्रोसॉफ्ट के क्लीपी के प्रमुख दिनों से परे उन्नत संचार है।
इन मशीन लर्निंग उदाहरणों ने लोगों को प्राकृतिक भाषा प्रसंस्करण, रीयल-टाइम भाषा अनुवाद और वाक् पहचान का उपयोग करके सरल और सटीक रूप से संवाद करने में मदद की है।
जबकि कई व्यक्ति स्वत: सुधार क्षमताओं को नापसंद करते हैं, वे शर्मनाक गलतियों और अनुचित स्वर से सुरक्षित होने को भी महत्व देते हैं।
4. वस्तु पहचान
जबकि डेटा एकत्र करने और व्याख्या करने की तकनीक कुछ समय के लिए आसपास रही है, कंप्यूटर सिस्टम को यह समझने के लिए कि वे क्या देख रहे हैं, यह एक भ्रामक कठिन काम साबित हुआ है।
मशीन सीखने के अनुप्रयोगों के कारण उपकरणों की बढ़ती संख्या में वस्तु पहचान क्षमताओं को जोड़ा जा रहा है।
एक सेल्फ-ड्राइविंग ऑटोमोबाइल, उदाहरण के लिए, एक अन्य कार को पहचानता है, जब वह एक को देखता है, भले ही प्रोग्रामर ने इसे संदर्भ के रूप में उपयोग करने के लिए उस कार का सटीक उदाहरण न दिया हो।
चेकआउट प्रक्रिया को गति देने में मदद के लिए अब इस तकनीक का उपयोग खुदरा व्यवसायों में किया जा रहा है। कैमरे उपभोक्ताओं की कार्ट में उत्पादों की पहचान करते हैं और जब वे स्टोर छोड़ते हैं तो स्वचालित रूप से उनके खातों को बिल कर सकते हैं।
5। अंकीय क्रय विक्रय
आज की अधिकांश मार्केटिंग डिजिटल प्लेटफॉर्म और सॉफ्टवेयर प्रोग्राम की एक श्रृंखला का उपयोग करके ऑनलाइन की जाती है।
जैसा कि व्यवसाय अपने उपभोक्ताओं और उनके क्रय व्यवहार के बारे में जानकारी एकत्र करते हैं, मार्केटिंग टीम उस जानकारी का उपयोग अपने लक्षित दर्शकों की विस्तृत तस्वीर बनाने के लिए कर सकती है और यह पता लगा सकती है कि कौन से लोग अपने उत्पादों और सेवाओं की तलाश में अधिक इच्छुक हैं।
मशीन लर्निंग एल्गोरिदम विपणक को उस सभी डेटा को समझने में सहायता करते हैं, महत्वपूर्ण पैटर्न और विशेषताओं की खोज करते हैं जो उन्हें संभावनाओं को कसकर वर्गीकृत करने की अनुमति देते हैं।
वही तकनीक बड़े डिजिटल मार्केटिंग ऑटोमेशन की अनुमति देती है। नए संभावित उपभोक्ताओं को गतिशील रूप से खोजने और उन्हें उचित समय और स्थान पर प्रासंगिक विपणन सामग्री प्रदान करने के लिए विज्ञापन प्रणाली स्थापित की जा सकती है।
मशीन लर्निंग का भविष्य
मशीन लर्निंग निश्चित रूप से लोकप्रियता प्राप्त कर रहा है क्योंकि अधिक व्यवसाय और विशाल संगठन विशिष्ट चुनौतियों या ईंधन नवाचार से निपटने के लिए प्रौद्योगिकी का उपयोग करते हैं।
यह निरंतर निवेश इस समझ को प्रदर्शित करता है कि मशीन लर्निंग आरओआई का उत्पादन कर रहा है, विशेष रूप से उपर्युक्त कुछ स्थापित और प्रतिलिपि प्रस्तुत करने योग्य उपयोग के मामलों के माध्यम से।
आखिरकार, अगर तकनीक नेटफ्लिक्स, फेसबुक, अमेज़ॅन, गूगल मैप्स, और इसी तरह के लिए पर्याप्त है, तो संभावना है कि यह आपकी कंपनी को अपने डेटा का अधिकतम लाभ उठाने में मदद कर सकती है।
नए जैसा यंत्र अधिगम मॉडल विकसित और लॉन्च किए गए हैं, हम उन अनुप्रयोगों की संख्या में वृद्धि देखेंगे जिनका उपयोग उद्योगों में किया जाएगा।
यह पहले से ही हो रहा है चेहरा पहचान, जो कभी आपके iPhone पर एक नया कार्य था लेकिन अब इसे कार्यक्रमों और अनुप्रयोगों की एक विस्तृत श्रृंखला में लागू किया जा रहा है, विशेष रूप से सार्वजनिक सुरक्षा से संबंधित।
मशीन लर्निंग के साथ शुरुआत करने की कोशिश करने वाले अधिकांश संगठनों की कुंजी उज्ज्वल भविष्य के दृष्टिकोण को देखना और वास्तविक व्यावसायिक चुनौतियों की खोज करना है, जिसमें तकनीक आपकी मदद कर सकती है।
निष्कर्ष
औद्योगीकरण के बाद के युग में, वैज्ञानिक और पेशेवर एक ऐसा कंप्यूटर बनाने की कोशिश कर रहे हैं जो इंसानों की तरह व्यवहार करे।
थिंकिंग मशीन एआई का मानवता के लिए सबसे महत्वपूर्ण योगदान है; इस स्व-चालित मशीन के अभूतपूर्व आगमन ने तेजी से कॉर्पोरेट परिचालन नियमों को बदल दिया है।
स्व-ड्राइविंग वाहन, स्वचालित सहायक, स्वायत्त विनिर्माण कर्मचारी और स्मार्ट शहरों ने हाल ही में स्मार्ट मशीनों की व्यवहार्यता का प्रदर्शन किया है। मशीन लर्निंग क्रांति और मशीन लर्निंग का भविष्य लंबे समय तक हमारे साथ रहेगा।





एक जवाब लिखें