वेब स्क्रैपिंग आज के डेटा-संचालित समाज में इंटरनेट प्लेटफॉर्म से व्यावहारिक डेटा प्राप्त करने का एक महत्वपूर्ण तरीका बन गया है।
एक बेहद लोकप्रिय सोशल मीडिया साइट के रूप में, Instagram बहुत सारी उपयोगकर्ता-जनित सामग्री प्रदान करता है। और, इन जनरेट किए गए डेटा का उपयोग मार्केटिंग, रिसर्च और अन्य कारणों से किया जा सकता है।
उपयोगकर्ता आसानी से और प्रभावशीलता के साथ इंस्टाग्राम से डेटा निकाल सकते हैं, ब्राइट डेटा के फीचर-समृद्ध इंस्टाग्राम स्क्रेपर्स, एक अग्रणी के लिए धन्यवाद वेब स्क्रेपिंग औजार। इस पोस्ट में, हम Instagram स्क्रैपिंग प्रक्रिया के बारे में संपूर्ण, चरण-दर-चरण पूर्वाभ्यास देंगे।
तो, आइए देखते हैं कि हम इंस्टाग्राम से डेटा कैसे खंगाल सकते हैं।
ब्राइट डेटा से इंस्टाग्राम स्क्रेपर्स को समझना
दो सर्व-उद्देश्यीय वेब स्क्रेपर्स और एक पूर्व-संकलित डेटासेट की मदद से, ब्राइट डेटा विभिन्न प्रकार की इंस्टाग्राम स्क्रैपिंग सेवाएं प्रदान करता है। ये प्रौद्योगिकियां डेटा निष्कर्षण में बहुमुखी प्रतिभा प्रदान करती हैं और विभिन्न मांगों के अनुकूल होती हैं।
आइए इनमें से प्रत्येक विकल्प की अधिक विस्तार से जांच करें:
a. स्क्रैपिंग ब्राउज़र
स्क्रैपिंग ब्राउज़र के रूप में जानी जाने वाली नवीन तकनीक को डेटा स्क्रैपिंग प्रोजेक्ट की मांगों को पूरा करने के लिए बनाया गया था। यह एकल ब्राउज़र के अंदर बड़े पैमाने पर स्क्रैपिंग के लिए आवश्यक सब कुछ प्रदान करता है। यह अपनी एकीकृत वेबसाइट अनब्लॉकिंग ऑटोमेशन की वजह से अलग दिखता है, जो इसे पूरी दुनिया में अपनी तरह का एकमात्र ब्राउज़र बनाता है।
स्क्रैपिंग ब्राउज़र उपयोगकर्ताओं को मजबूत सुविधाओं तक पहुंच प्रदान करता है जो स्वचालित और हेडलेस ब्राउज़र से परे जाते हैं, जिससे उन्हें बॉट डिटेक्शन के लिए सबसे कठिन स्क्रिप्ट और वेबसाइट बाधाओं से भी आगे निकलने की अनुमति मिलती है।
डेटा स्क्रैपिंग इसकी स्वचालित समायोजन सुविधाओं के कारण अधिक प्रभावी और परेशानी मुक्त है, जो आसानी से ताज़ा ब्लॉक, कैप्चा समाधान, फ़िंगरप्रिंट और रिट्रीट का प्रबंधन करते हैं और एक वास्तविक उपयोगकर्ता के रूप में दिखाई देते हैं।
बॉट-डिटेक्शन सिस्टम को मात देने के लिए AI का उपयोग करना
अत्याधुनिक एआई तकनीक का उपयोग करके, स्क्रैपिंग ब्राउज़र बॉट-डिटेक्शन सिस्टम को मात दे सकता है और उनकी स्थानांतरण रणनीतियों को लगातार समायोजित कर सकता है। वेबपृष्ठों को बेहतर ढंग से अनलॉक करने के लिए, स्क्रैपिंग ब्राउज़र इन सिस्टम के स्क्रैपिंग प्रयासों का पता लगाने और ब्लॉक करने के प्रयासों से सीखता है और इसके व्यवहार को उचित रूप से संशोधित करता है।
यह एक वास्तविक उपयोगकर्ता द्वारा उपयोग किए जाने वाले ब्राउज़र के व्यवहार की नकल करके पारंपरिक प्रॉक्सी की दक्षता को बेहतर बनाता है। नतीजतन, ग्राहक चल रही बॉट-डिटेक्शन प्रक्रियाओं की कठिनाई और खर्च से निपटने के बिना डेटा स्क्रैपिंग के लिए अपने लक्ष्यों पर ध्यान केंद्रित कर सकते हैं।
b. वेब स्क्रैपर आईडीई
डेवलपर्स के लिए बनाया गया एक मजबूत वेब स्क्रैपिंग टूल, वेब स्क्रैपर आईडीई जटिल स्क्रैपिंग कार्यों को संभाल सकता है। इसके पूरी तरह से होस्ट किए गए समाधान और पूर्व-निर्मित स्क्रैपिंग सुविधाओं के लिए असीम मापनीयता प्रदान करते हुए यह विकास के समय को काफी कम करता है। एप्लिकेशन लोकप्रिय वेबसाइटों से कोड टेम्प्लेट और रेडी-मेड जावास्क्रिप्ट फ़ंक्शंस प्रदान करके ऑनलाइन स्क्रेपर्स के तेज़ और स्केलेबल निर्माण को सक्षम बनाता है।
सफल वेब स्क्रैपिंग के लिए आवश्यक सब कुछ वेब स्क्रैपर आईडीई द्वारा प्रदान किया जाता है। यह ऑनलाइन डेटा निष्कर्षण के लिए एक पूर्ण समाधान है क्योंकि एकीकरण विकल्प ग्राहकों को क्रॉल की योजना बनाने या उन्हें एपीआई के माध्यम से लॉन्च करने और मुख्य स्टोरेज सिस्टम के साथ लिंक करने में सक्षम बनाता है।
इसका उपयोग कैसे करना है? - ट्यूटोरियल
सबसे पहले, वेबसाइट पर उपयोगकर्ता डैशबोर्ड पर जाएँ।

आइए इंस्टाग्राम को खंगालने के लिए अपने कदमों से शुरुआत करें।
1- नेविगेट करें डैशबोर्ड और Datasets & Web Scraper IDE सेक्शन पर क्लिक करें।
2- एक बार जब आप वहां पहुंच जाएं, तो माई स्क्रेपर्स पर क्लिक करें।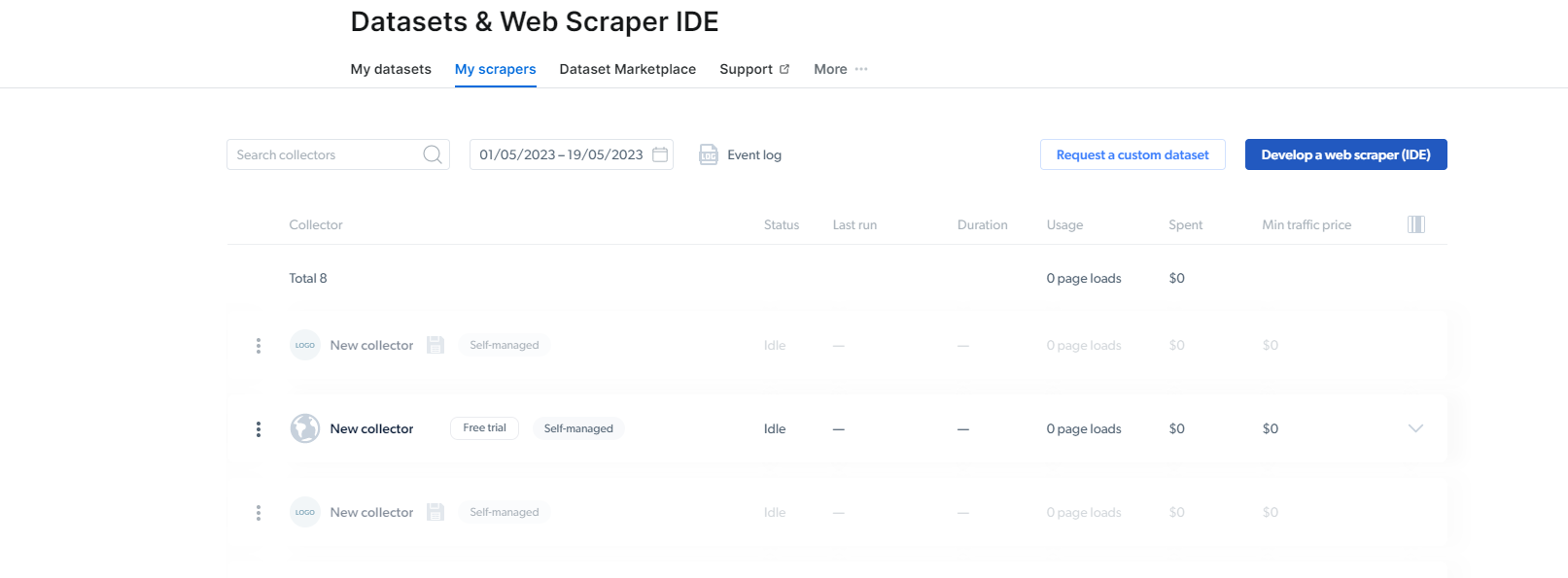
यहां, आपको “डेवलप ए वेब स्क्रैपर (आईडीई)” पर क्लिक करना होगा। यहां हम इंस्टाग्राम के लिए अपना स्क्रेपर बनाएंगे।
3-अब, हमें एक नया वेब स्क्रैपर विकसित करने की आवश्यकता है। इस उदाहरण के लिए, मैं "नासा" खाते को परिमार्जन करना चुनता हूं। यह सिर्फ इस उदाहरण के लिए है।
तो, मेरा कोड इस तरह दिखेगा:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
इस कोड को चलाने के लिए आपको ऊपर दाईं ओर 'प्ले' बटन पर क्लिक करना होगा।
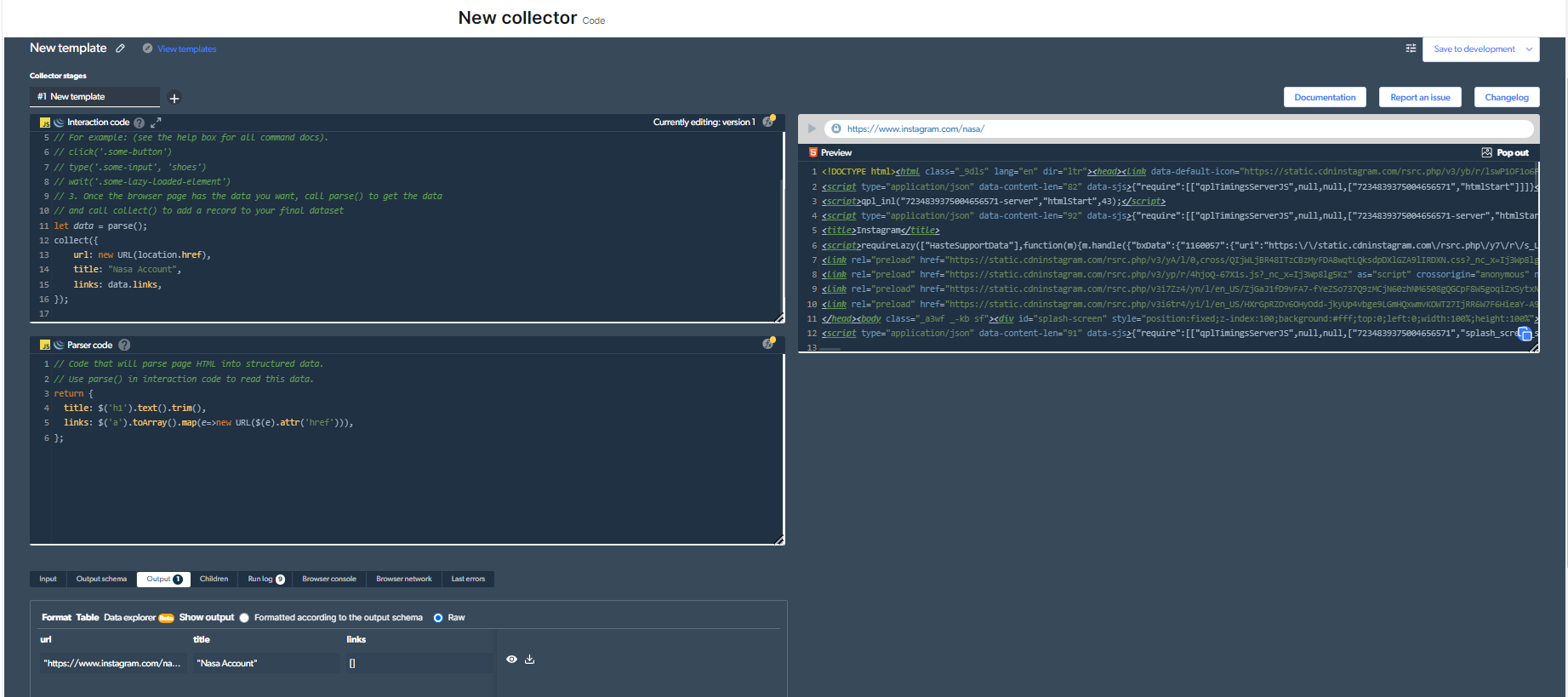
4- अब, हमारे पास एक आउटपुट होगा।
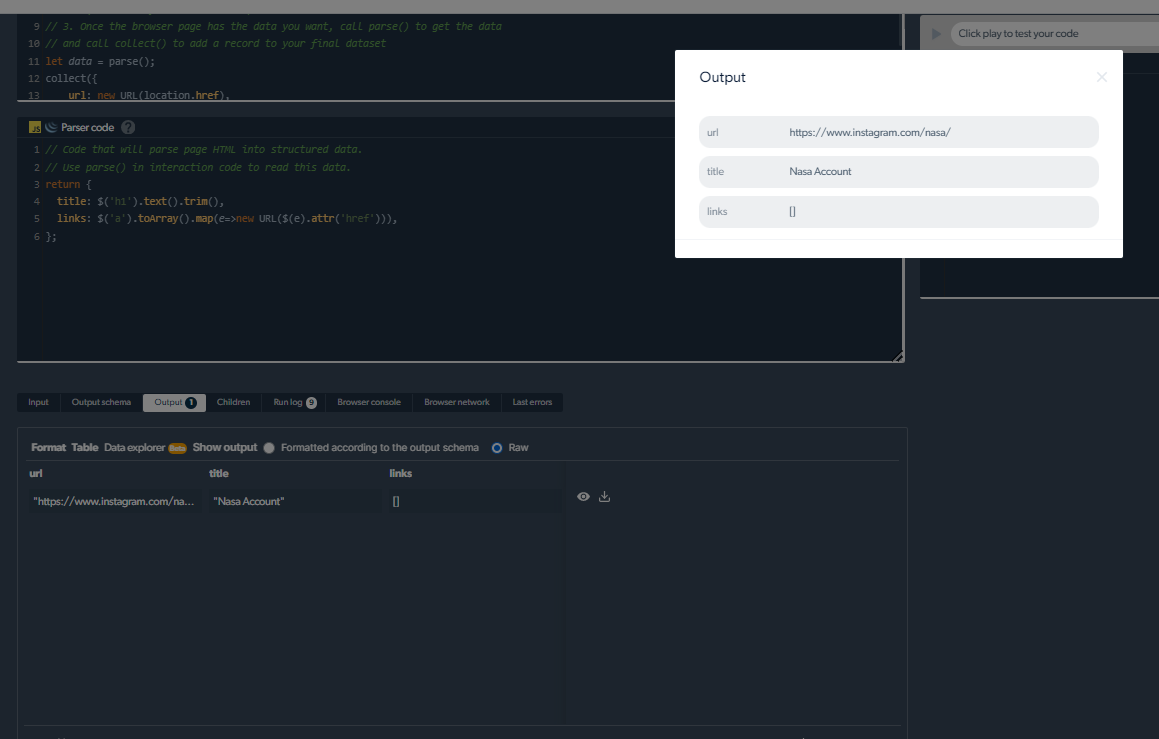
स्क्रैपिंग समस्याओं का प्रबंधन
स्क्रेपर्स के लिए "शो मोर बटन" वाले इंस्टाग्राम पोस्ट को कैप्चर करना मुश्किल हो सकता है। हालाँकि, ब्राइट डेटा के इंस्टाग्राम स्क्रैपर्स को इस तरह की जटिलता को सफलतापूर्वक संभालने के लिए बनाया गया है। इन स्क्रेपर्स में पेजिनेशन और अतिरिक्त बटनों को लोड करने के माध्यम से पार करने के लिए अत्याधुनिक कौशल हैं।
ब्राइट डेटा के इंस्टाग्राम स्क्रेपर्स पूरी तरह से डेटा निष्कर्षण को सक्षम करने के लिए इन कठिनाइयों को प्रभावी ढंग से संभालते हैं, जिससे आप अपने विश्लेषण या अध्ययन के लिए आवश्यक जानकारी का पूरा संग्रह एकत्र कर सकते हैं।
आप इन स्क्रैपिंग टूल का उपयोग करके इंस्टाग्राम पोस्ट की गतिशील प्रकृति द्वारा प्रस्तुत चुनौतियों से बच सकते हैं।
c. पूर्व-संग्रहित डेटासेट
ब्राइट डेटा समझता है कि हर कोई अपना स्क्रैपर नहीं चलाना चाहता। वे ऐसे उपभोक्ताओं से अपील करने के लिए इंस्टाग्राम के लिए एक पूर्व-संग्रहित डेटासेट की आपूर्ति करते हैं।
यह डेटासेट ढेर सारी उपयोगी जानकारी प्रदान करता है, जैसे अनुयायी, प्रोफाइल, पोस्ट, और बहुत कुछ।
ब्राइट डेटा आपकी आवश्यकताओं के लिए डेटासेट को वैयक्तिकृत करने के लिए अनुकूलन विकल्प प्रदान करता है, चाहे आप संपूर्ण डेटासेट चाहते हों या विशेष डेटा का एक सबसेट। यह दृष्टिकोण एक स्क्रैपर के निर्माण और प्रबंधन से बचता है, जिससे आपको विश्लेषण और अंतर्दृष्टि के लिए रेडी-टू-यूज़ डेटा मिलता है।
अब, आइए बुनियादी ढांचे की जांच करें जो इन उपकरणों को इतना प्रभावी बनाता है: प्रॉक्सी आधारभूत संरचना और वेब अनलॉकर।
प्रॉक्सी की शक्ति को उजागर करें
का प्रयोग प्रॉक्सी वेब स्क्रैपिंग के दौरान यह सुनिश्चित करने के लिए महत्वपूर्ण है कि आपके कार्यों पर किसी का ध्यान न जाए।
ब्राइट डेटा विस्तृत चयन प्रदान करता है प्रॉक्सी सेवाएं जो आपकी आवश्यकताओं के अनुसार अनुकूलित हैं। आप से चुन सकते हैं आवासीय प्रॉक्सी, जो 72 देशों में वास्तविक-सहकर्मी उपकरणों से घुमाए गए 195 मिलियन से अधिक आईपी की पेशकश करते हैं।
आप आईएसपी प्रॉक्सी चुन सकते हैं, जो लंबी अवधि के उपयोग के लिए दुनिया भर में 700,000+ वास्तविक घरेलू आईपी प्रदान करते हैं; डाटासेंटर प्रॉक्सी, जिनके पास किसी भी भौगोलिक स्थान से 770,000+ साझा आईपी हैं; और मोबाइल प्रॉक्सी, जो 3+ आईपी के साथ सबसे बड़ा रियल-पीयर 4जी/7,000,000जी मोबाइल नेटवर्क बनाते हैं।
इन प्रॉक्सी के उपयोग से, कई स्थानों पर अधिकृत उपयोगकर्ता के रूप में प्रस्तुत करते हुए आसानी से डेटा एकत्र किया जा सकता है।

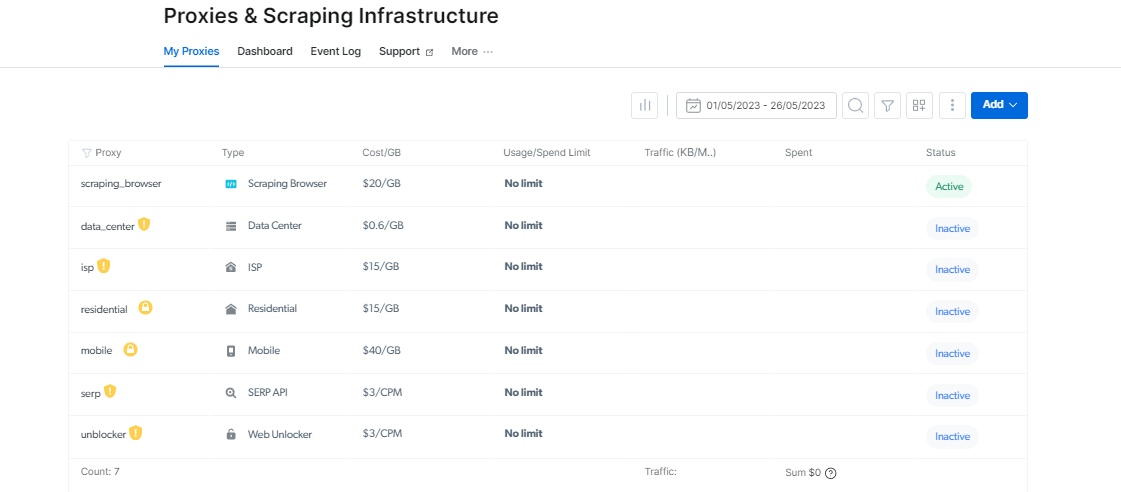
प्रॉक्सी मैनेजर: प्रॉक्सी प्रबंधन को आसान बनाएं
कई प्रॉक्सी प्रबंधित करना मुश्किल हो सकता है, लेकिन प्रॉक्सी मैनेजर इसे आसान बनाता है।
यह ओपन-सोर्स इंटरफ़ेस आपको एक ही मंच से अपने सभी प्रॉक्सी प्रबंधित करने में सक्षम बनाता है। प्रॉक्सी को मैन्युअल रूप से सेट करने और स्विच करने के लिए अलविदा कहें। प्रॉक्सी मैनेजर प्रक्रिया को सरल करता है और आपका समय और प्रयास बचाता है।
प्रॉक्सी ब्राउज़र एक्सटेंशन: अपना स्थान आसानी से बदलें
क्या आपको कई क्षेत्रों से वेब डेटा एकत्र करने की आवश्यकता है? आप हमारे प्रॉक्सी ब्राउज़र एक्सटेंशन द्वारा कवर किए गए हैं। क्षेत्र-विशिष्ट जानकारी प्राप्त करने के लिए आप एक क्लिक से अपना ब्राउज़िंग स्थान बदल सकते हैं।
बिना किसी तकनीकी जटिलता के कई क्षेत्रों से डेटा एकत्र करने के लचीलेपन और सरलता का लाभ उठाएं।
यह कैसे काम करता है? - ट्यूटोरियल
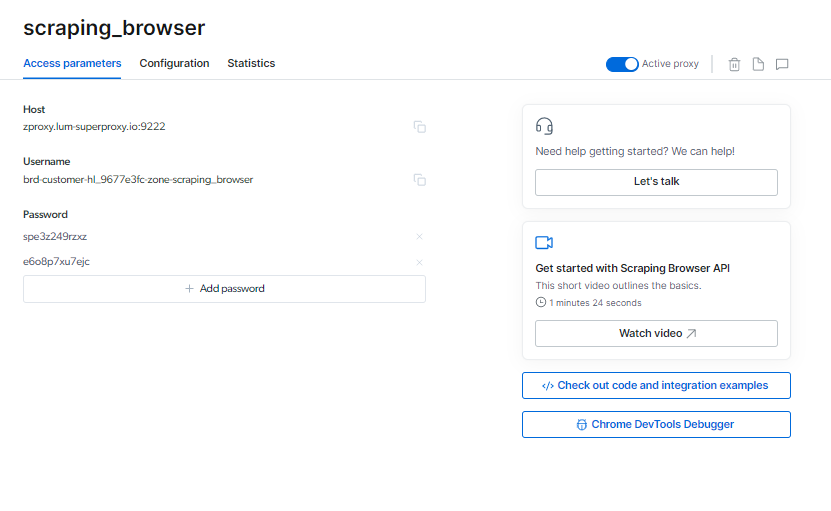
आप अपना पता लगा सकते हैं स्क्रैपिंग ब्राउज़र एक्सेस पैरामीटर पृष्ठ पर लॉगिन जानकारी, जिसका उपयोग आपके द्वारा नया ब्राउज़र सत्र प्रारंभ करने पर किया जाएगा।
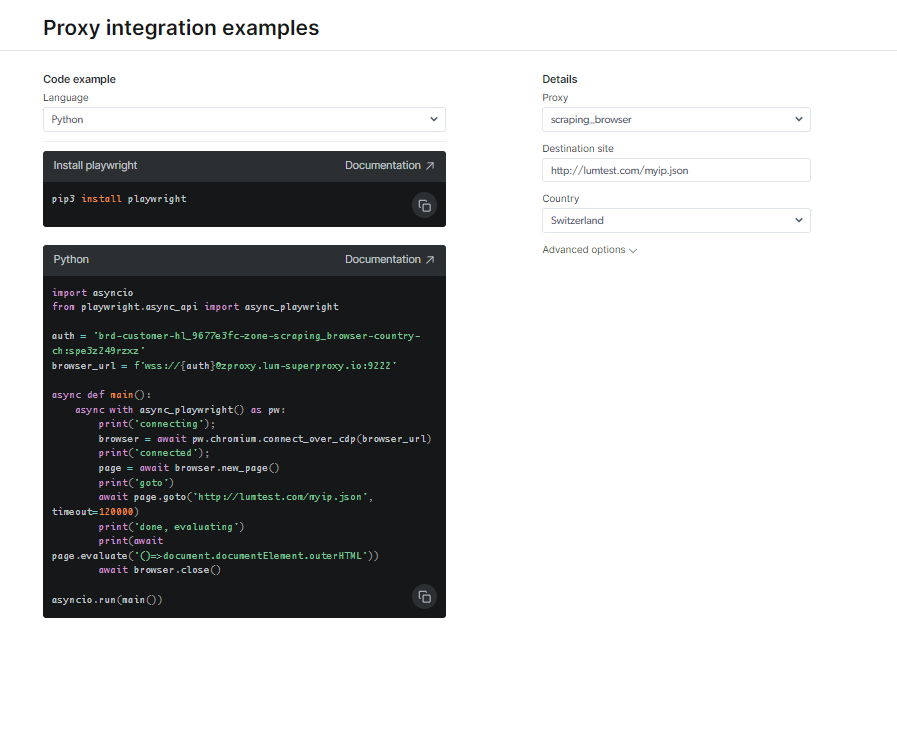
दस्तावेज़ीकरण और कोड नमूने देखें, जिसमें पूरी तरह कार्यात्मक उदाहरण स्क्रिप्ट शामिल है जो उपयोग करने के लिए तैयार है, या एक संक्षिप्त प्रारंभिक निर्देश वीडियो देखें। उदाहरण के लिए; यहां है पायथन कोड एकीकरण के लिए उदाहरण:
सहायता चाहते हैं? किसी एक विशेषज्ञ के साथ बातचीत के लिए, आप चैट आइकन पर क्लिक कर सकते हैं।
ध्यान रखें कि स्क्रैपिंग ब्राउज़र का उपयोग करते समय ब्राउज़र सत्रों पर आपका पूर्ण नियंत्रण होता है और आप कठपुतली, नाटककार, या सीधे क्रोम देवटूल प्रोटोकॉल उपयोग द्वारा समर्थित किसी भी ऑपरेशन को अंजाम दे सकते हैं।
वेबसाइट बिना ब्लॉक के अनलॉक हो रही है
स्क्रैपिंग ब्राउज़र को बड़े पैमाने पर और आवश्यकतानुसार संचालित करने के लिए बनाया गया है। आपको प्रतिबंधित होने की चिंता करने की आवश्यकता नहीं है; आप जितने चाहें उतने ब्राउज़र सत्र शुरू कर सकते हैं।
यह क्षमता, जब प्रॉक्सी की ताकत के साथ जोड़ी जाती है, तो निरंतर डेटा एकत्रण की गारंटी देता है, जिससे आप अपने इच्छित डेटा को प्रभावी ढंग से प्राप्त कर सकते हैं।
स्क्रैपिंग ब्राउज़र के अंतर्निहित अनलॉकिंग कौशल और मजबूत प्रॉक्सी नेटवर्क आपको समय बचाने, उत्पादकता बढ़ाने और नए अवसरों की खोज करने में मदद करते हैं।
आप सीधे उसी पृष्ठ से आँकड़ों की जाँच भी कर सकते हैं।
स्क्रैपिंग ब्राउज़र का मूल्य निर्धारण
ब्राइट डेटा विभिन्न उद्देश्यों को पूरा करने के लिए अनुकूलन योग्य मूल्य निर्धारण विकल्प प्रदान करता है। आप मासिक या वार्षिक बिलिंग अवधि चुन सकते हैं।
भुगतान के रूप में आप जाते हैं विकल्प आपको $20.00/GB और $0.1/घंटे से शुरू होने वाली किसी भी प्रतिबद्धता के बिना केवल आपके द्वारा उपयोग की जाने वाली चीज़ों के लिए भुगतान करने की अनुमति देता है।
$500/जीबी और $15.30/घंटा के रियायती शुल्क के साथ, $0.1 की विकास योजना बढ़ते व्यवसायों के लिए उपयुक्त है।
RSI बिजनेस पैकेज, जिसकी कीमत $1000 है, यह सबसे लोकप्रिय विकल्प है, जिसमें स्क्रैपिंग ब्राउज़र API की कीमत $13.50/GB और $0.1/घंटा है।
ब्राइट डेटा टीम से सीधे संपर्क करके, एंटरप्राइज़ उपयोगकर्ता अनंत स्केलिंग और व्यक्तिगत मूल्य निर्धारण का आनंद ले सकते हैं। ब्राइट डेटा के स्क्रैपिंग ब्राउज़र की क्षमता का पता लगाने और अपने ऑनलाइन स्क्रैपिंग प्रयासों को बदलने के लिए आज ही नि:शुल्क परीक्षण शुरू करें।
वेबसाइट अनलॉकर
वेब अनलॉकर वेबसाइट प्रतिबंधों से परे जाने और आसान डेटा संचयन प्रदान करने के लिए बनाया गया एक शक्तिशाली उपकरण है। यह स्वचालित प्रक्रियाओं का उपयोग करके कुकीज़, साइट-विशिष्ट ब्राउज़र उपयोगकर्ता एजेंटों और कैप्चा समाधानों सहित कई चुनौतियों पर विजय प्राप्त करता है।
स्वचालित आईपी एड्रेस रोटेशन का उपयोग करके, वेब अनलॉकर के उपयोगकर्ता महत्वपूर्ण डेटा तक निरंतर पहुंच सुनिश्चित करते हुए लक्षित वेबसाइटों को लगातार स्क्रैप कर सकते हैं।
डेवलपर अनुरोध यात्रा को बढ़ाना
कई विशेषताएं वेब अनलॉकर को डेवलपर्स के बीच लोकप्रिय बनाती हैं। कार्यक्रम मूल्यवान समय और संसाधनों की बचत करते हुए, प्रत्येक वेबसाइट के लिए आवश्यक उपयोगकर्ता एजेंटों की स्वचालित रूप से पहचान करके डेटा-एकत्रीकरण प्रक्रिया को सुव्यवस्थित करता है।
वेब अनलॉकर, बॉट्स को ब्लॉक करके उपयोग की जाने वाली लगातार बदलती रणनीतियों के जवाब में पता लगाने से बचने के लिए रीयल-टाइम में अनुकूलित होता है, जिससे रुचि की वेबसाइटों तक निरंतर पहुंच सुनिश्चित होती है। प्लेटफॉर्म के मशीन-लर्निंग एल्गोरिदम कैप्चा को जल्दी से हल कर सकते हैं, जो डेटा-एकत्र करने की पहल के लिए लगातार बाधा है।

वेब अनलॉकर का मूल्य निर्धारण
लगभग $2.03 प्रति हजार अनुरोध (CPM) से शुरू होकर, वेब अनलॉकर विभिन्न मांगों को पूरा करने के लिए कई मूल्य विकल्प प्रदान करता है। उपयोगकर्ताओं को शुरू करने के लिए 7-दिन का नि: शुल्क परीक्षण उपलब्ध है और उन्हें प्रतिबद्ध करने से पहले वेब अनलॉकर की सुविधाओं का परीक्षण करने दें।
वेब अनलॉकर में विभिन्न उपयोग पैटर्न का समर्थन करने की अनुकूलन क्षमता है, भले ही उपभोक्ता पे-एज़-यू-गो दृष्टिकोण चाहते हों या उनकी विशेष आवश्यकताओं के अनुकूल अनुकूलित योजना की आवश्यकता हो। इसके अतिरिक्त, जो लोग दीर्घकालिक मूल्य योजनाएँ चुनते हैं, वे 32% बचा सकते हैं।
स्व-प्रबंधित प्रॉक्सी के साथ वेब अनलॉकर के बीच तुलना
वेब अनलॉकर स्व-प्रबंधित प्रॉक्सी पर कई त्वरित लाभ प्रदान करता है। सुचारू कार्यान्वयन के लिए, यह एक व्यापक एकीकरण तकनीक प्रदान करता है जो सुपर प्रॉक्सी और प्रॉक्सी प्रबंधक कार्यों को जोड़ती है। उपयोगकर्ता समवर्ती कनेक्शनों की अनंत संख्या के साथ प्रभावी रूप से अपने डेटा-संग्रह कार्यों को बढ़ा सकते हैं।
वेब अनलॉकर स्वचालित अनब्लॉकिंग प्रदान करता है, कैप्चा को हल करता है, और लक्षित वेबसाइटों पर मार्कअप संशोधनों का सफलतापूर्वक प्रबंधन करता है।
प्लेटफ़ॉर्म ऑटो-रिट्री सिस्टम को लागू करके और कुछ डोमेन के लिए एसिंक्रोनस कॉल करके निरंतर और भरोसेमंद डेटा निष्कर्षण की गारंटी देता है। इसके अतिरिक्त, ऑनलाइन अनलॉकर के एचटीटीपी हेडर अनुरोधों, साइट-विशिष्ट ब्राउज़र कुकीज़, और सिम्युलेटेड गैजेट्स के बढ़ते संग्रह ने उपयोगकर्ताओं को वास्तविक समय में ऑनलाइन डेटा प्राप्त करने में सक्षम बनाते हुए उनकी पहचान नहीं होने दी।
अंतिम विचार और याद रखने योग्य महत्वपूर्ण बातें
अंत में, इंस्टाग्राम स्क्रैपिंग के लिए ब्राइट डेटा का उपयोग करते समय, कुछ महत्वपूर्ण बिंदुओं को ध्यान में रखना महत्वपूर्ण है।
कृपया ध्यान दें कि नैतिक प्रथाओं द्वारा उनकी स्क्रैपिंग क्षमताएं सार्वजनिक रूप से उपलब्ध डेटा तक सीमित हैं।
आपको हमेशा Instagram की सेवा की शर्तों और गोपनीयता नीतियों का पालन करना चाहिए। स्क्रैपिंग को नैतिक और जिम्मेदारी से किया जाना चाहिए, उपयोगकर्ताओं के अधिकारों पर घुसपैठ किए बिना या किसी भी कानून को तोड़े बिना।
दूसरा, पुनर्प्राप्त डेटा की सटीकता और प्रासंगिकता सुनिश्चित करने के लिए अपने स्क्रैपिंग मापदंडों को नियमित रूप से अपडेट और फाइन-ट्यून करें। इंस्टाग्राम का प्लेटफॉर्म और एल्गोरिदम परिवर्तन के अधीन हैं, इसलिए आपको अपनी स्क्रैपिंग रणनीतियों को तदनुसार बदलना होगा।
अंत में, अपने Instagram स्क्रैपिंग प्रयासों की सफलता को ऑप्टिमाइज़ करने के लिए Bright Data के प्लेटफ़ॉर्म की सहायता और संसाधनों का उपयोग करें। उनके स्क्रैपिंग टूल के बारे में अपने ज्ञान को बेहतर बनाने के लिए उनके दस्तावेज़ीकरण, ट्यूटोरियल और ग्राहक सेवा से जुड़ें।
आप इन सर्वोत्तम प्रथाओं का पालन करके और ब्राइट डेटा की इंस्टाग्राम स्क्रैपिंग क्षमताओं की ताकत का उपयोग करके इंस्टाग्राम प्लेटफॉर्म पर उपयोगी अंतर्दृष्टि प्राप्त कर सकते हैं, बुद्धिमान निर्णय लेने को प्रभावित कर सकते हैं और अपनी डेटा-संचालित पहलों में सफल हो सकते हैं।





एक जवाब लिखें