विषय - सूची[छिपाना][प्रदर्शन]
डेटा आपके आसपास हर जगह है। वास्तविक अर्थ में, यह आपके व्यवसाय के हर पहलू को प्रभावित करता है। ऐसा महसूस हो सकता है कि जब आप अपने डेटा को कैसे संभालना है, इस बारे में निर्णय लेने में व्यस्त हैं, तो यह आपके व्यवसाय की कितनी अच्छी तरह से सेवा कर रहा है, इसकी बारीकियों की जांच करने के लिए पर्याप्त समय नहीं है।
इस पर गौर करें। आपका संगठन 24 घंटे डेटा का उपयोग कर रहा है। इसलिए यह समझना कि यह कहां से आया, यह वहां कैसे पहुंचा, और यह कंपनी के माध्यम से कैसे आगे बढ़ रहा है, इसकी कीमत को समझने के लिए महत्वपूर्ण है।
इस स्थिति में डेटा वंशावली महत्वपूर्ण हो जाती है। यह समझना आसान है कि डेटा कैसे बनाया गया था, यह कहाँ से आया था, और यह कहाँ जा रहा है जब हम डेटा की उत्पत्ति, माइग्रेशन और परिवर्तनों को ट्रैक कर सकते हैं।
इस पोस्ट में, हम डेटा वंशावली, यह कैसे काम करता है, इसके उपयोग के मामले, तकनीक और बहुत कुछ पर करीब से नज़र डालेंगे।
डेटा वंश क्या है?
डेटा वंश एक प्रकार के डिजिटल पासपोर्ट के रूप में कार्य करता है। यह एक डेटा यात्रा का सबसे व्यापक खाता है, इसके सभी स्टॉप, डेट्रोज़ और इसके मूल स्थान से लेकर इसके अंतिम गंतव्य तक के संशोधनों का विवरण देता है।
In सार, डेटा वंश कई प्रणालियों और प्लेटफार्मों में डेटा के एक टुकड़े की उत्पत्ति, संशोधन और उपयोग का वर्णन करता है। यह एक जासूस के उपकरण के रूप में उपयोगकर्ताओं को यह जानकारी देकर कार्य करता है कि डेटा कैसे बनाया गया था, यह कहाँ से उत्पन्न हुआ था और इसका उपयोग कैसे किया गया था। यह जानकारी उपयोगकर्ताओं को किसी भी संभावित समस्या को पहचानने और हल करने में सक्षम बनाती है।
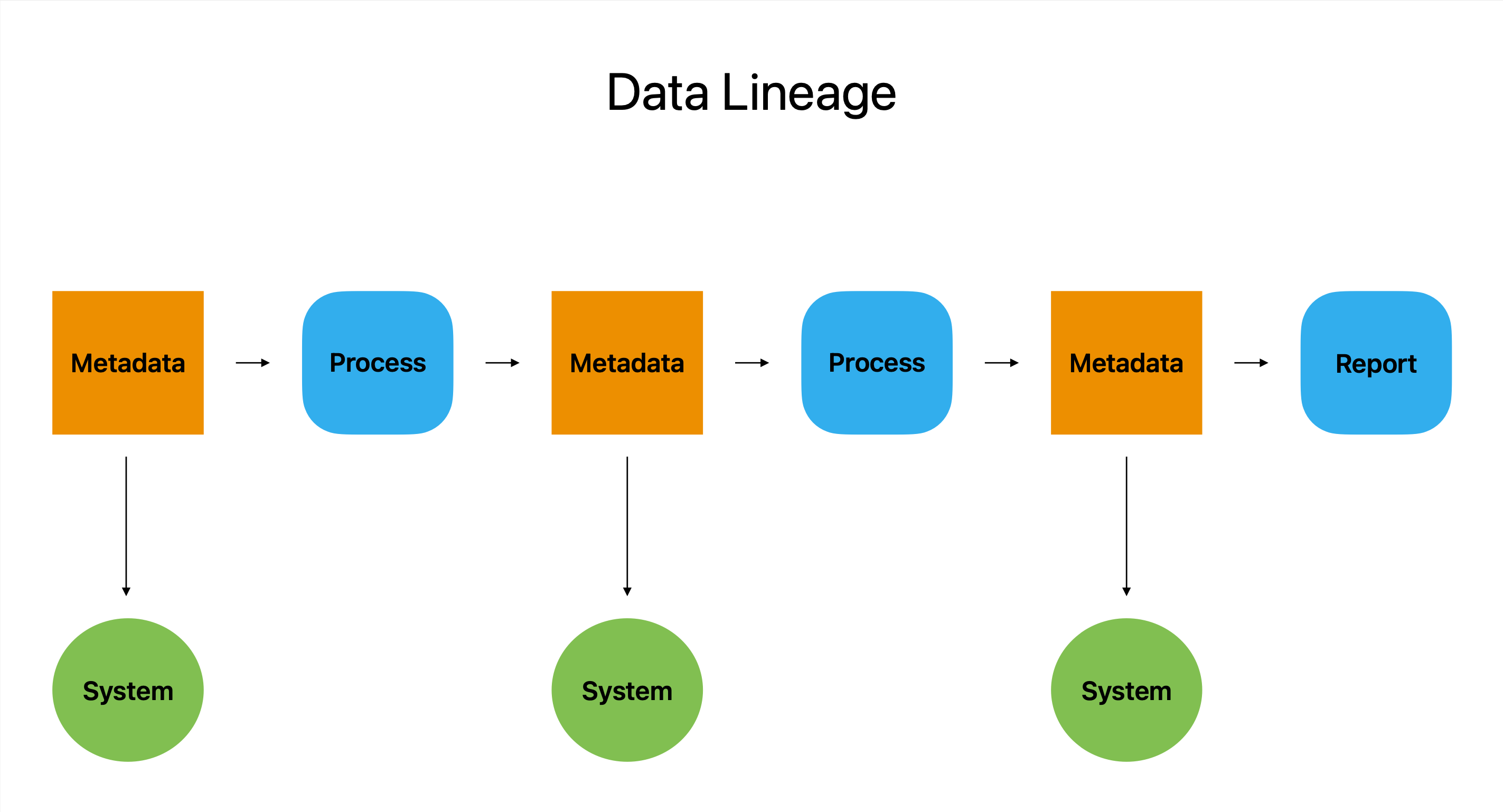
डेटा वंशावली उन कंपनियों के लिए एक अमूल्य संसाधन है जो अपने संचालन को चलाने के लिए डेटा पर निर्भर करती हैं क्योंकि यह उपयोगकर्ताओं को कौन, क्या, कब और कहाँ जैसे महत्वपूर्ण सवालों का जवाब देने की अनुमति देती है।
सरल शब्दों में कहा जाए तो डेटा वंशानुक्रम अंतिम डेटा ट्रेल है जो डेटा के पूर्ण पथ के स्पष्ट और संक्षिप्त परिप्रेक्ष्य की पेशकश करते हुए डेटा सटीकता, पूर्णता और स्थिरता की गारंटी देता है।
डेटा वंश कैसे काम करता है?
डेटा वंश एक रोड मैप है जो हमें डेटा के एक टुकड़े को उसके शुरुआती बिंदु से उसके समापन बिंदु तक अनुसरण करने में सक्षम बनाता है। एक यात्री के रूप में एक डेटा बिंदु पर विचार करें, और यह कैसे कार्य करता है इसे बेहतर ढंग से समझने के लिए इसके पासपोर्ट को इसकी डेटा वंशावली मानें।
डेटा स्रोत, डेटा ट्रांसफ़ॉर्मेशन, डेटा स्टोरेज और डेटा आउटपुट पासपोर्ट के चार प्राथमिक घटक हैं।
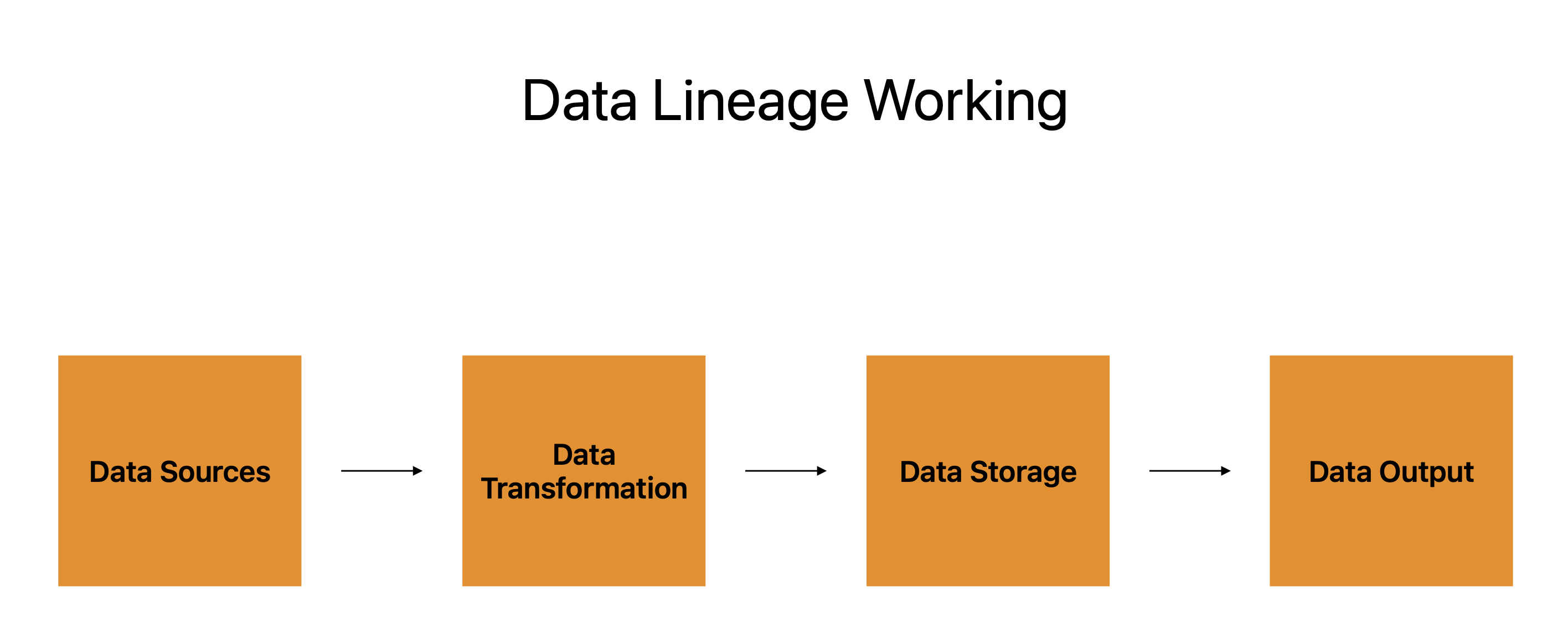
कई प्रणालियाँ, एप्लिकेशन और प्लेटफ़ॉर्म जिनसे डेटा उत्पन्न होता है, डेटा स्रोतों द्वारा दर्शाए जाते हैं, जो डेटा की यात्रा के शुरुआती बिंदुओं के रूप में काम करते हैं। डेटा परिवर्तन बाद का चरण है, और डेटा वंश इन स्रोतों से डेटा की प्रगति को चार्ट करता है।
डेटा परिवर्तन उपयोगकर्ता की जरूरतों को पूरा करने के लिए डेटा को आकार देने, संशोधित करने और हेरफेर करने को संदर्भित करता है। यह डेटा की यात्रा के दौरान रेस्ट स्टॉप के रूप में कार्य करता है, इसे अगले चरण के लिए तैयार करता है।
डेटा को उसके अंतिम स्थान पर जाने से पहले संग्रहीत किया जाता है। इसे क्लाउड सर्वर, डेटाबेस या किसी अन्य प्रकार के स्टोरेज डिवाइस पर रखा जा सकता है। डेटा वंश इस बात का ट्रैक रखता है कि डेटा कहाँ संग्रहीत किया जाता है, साथ ही यह कैसे संरक्षित, बैकअप और पुनर्प्राप्त किया जाता है।
अंतिम चरण डेटा आउटपुट है, जहां डेटा को उपयोग के लिए भेजा जाता है। इसे प्रस्तुत करने के लिए रिपोर्ट, इन्फोग्राफिक्स, या किसी अन्य प्रकार के डेटा उत्पाद का उपयोग किया जा सकता है। डेटा वंशावली आउटपुट का ट्रैक रखती है और डेटा की स्थिरता, सटीकता और पूर्णता की गारंटी देती है।
डेटा वंश मूल रूप से डेटा की यात्रा के प्रत्येक चरण को रिकॉर्ड करने से लेकर इसके आउटपुट तक, और यह सुनिश्चित करने के लिए काम करता है कि यह विश्वसनीय, सुसंगत और सभी तरह से सही रहता है। डेटा वंशानुक्रम संगठनों को डेटा के अस्तित्व के बारे में पूरी जानकारी देकर शिक्षित निर्णय लेने, समस्याओं को ठीक करने और कानूनी दायित्वों का पालन करने में मदद करता है।
डेटा संपत्तियों को समझने के लिए और वे डेटा पाइपलाइन के माध्यम से कैसे आगे बढ़ते हैं, मेटाडेटा डेटा वंशावली प्रक्रिया का एक महत्वपूर्ण हिस्सा है।
आप देख सकते हैं कि डेटा वंशावली उपकरण का उपयोग करके संगठन के भीतर डेटा कैसे परिवर्तित और उपयोग किया जाता है, जो डेटा प्रवाह का दृश्य चित्रण प्रदान करने के लिए मेटाडेटा का लाभ उठाता है। यह उपयोगकर्ताओं को डेटा की क्षमता का आकलन करने में सक्षम बनाता है जिससे उन्हें बेहतर-सूचित निर्णय लेने में मदद मिलती है।
डेटा वंश के प्रकार
डेटा वंशानुक्रम के तीन मूल रूप हैं: आगे डेटा वंश, पश्च डेटा वंश और द्वि-दिशात्मक डेटा वंश।
फॉरवर्ड डेटा वंश
वन-वे स्ट्रीट की तरह, फॉरवर्ड डेटा लाइनेज में डेटा के एक टुकड़े को उसके शुरुआती बिंदु से उसके अंतिम बिंदु तक ट्रैक करना शामिल है। डेटा स्रोत से शुरू होकर, यह डेटा का अनुसरण करता है क्योंकि यह अपने आउटपुट तक पहुँचने के लिए कई परिवर्तनों और भंडारण प्रणालियों से गुजरता है।
डेटा के प्रसंस्करण और परिवर्तन को समझने के साथ-साथ इस तरह की कोई भी समस्या उत्पन्न हो सकती है, इस तरह की डेटा वंशावली होने से सुविधा होती है। हर कदम अगले की ओर ले जाता है; यह ब्रेडक्रंब के निशान का अनुसरण करने जैसा है।
पिछड़ा डेटा वंश
बैकवर्ड डेटा लाइनेज रिवर्स में एक यात्रा के समान है जहां हम डेटा के आउटपुट को उसके स्रोत पर वापस ट्रेस करते हैं। प्रक्रिया डेटा के अंतिम स्थान पर शुरू होती है और डेटा स्रोत तक पहुंचने तक विभिन्न भंडारण और परिवर्तन तकनीकों के माध्यम से पीछे की ओर बढ़ती है।
डेटा के मूल स्रोत की पहचान, इसके परिवर्तन की समझ, और इसकी शुद्धता और पूर्णता का सत्यापन इस तरह के डेटा वंश की मदद से संभव है। यह एक जासूस के उपकरण की तरह काम करता है, जिससे हमें डेटा के पिछड़े रास्ते का अनुसरण करने की अनुमति मिलती है।
द्वि-दिशात्मक डेटा वंश
एक दो-तरफ़ा सड़क, द्वि-दिशात्मक डेटा वंश आगे और पीछे के डेटा वंश के लाभों को जोड़ती है। यह डेटा के मार्ग को उसके स्रोत से उसके गंतव्य तक और साथ ही उस स्थान से उसके शुरुआती बिंदु तक ट्रैक करके एक व्यापक दृश्य प्रदान करता है।
डेटा के मूल स्रोत को निर्धारित करने के लिए, यह समझने के लिए कि इसे कैसे बदला गया था, और इसकी गुणवत्ता, निरंतरता और संपूर्णता की गारंटी देता है, यह डेटा की वंशावली को ट्रैक करने में मददगार है। इसके स्थान और स्थिति पर वास्तविक समय की जानकारी के साथ, यह डेटा के लिए एक जीपीएस ट्रैकर होने जैसा है।
डेटा वंश का कार्यान्वयन
किसी संगठन में डेटा वंशानुक्रम को लागू करने में अक्सर निम्नलिखित चरण शामिल होते हैं।
डेटा स्रोतों को परिभाषित करें
सिस्टम और डेटाबेस जो आपके द्वारा ट्रैक किए जाने वाले डेटा को रखते हैं, सभी की पहचान की जानी चाहिए। ऐसा करने के लिए, आपको पहले फाइलों, एपीआई और क्लाउड सेवाओं सहित विभिन्न डेटा स्रोतों की पहचान करनी होगी।
मेटाडेटा एकत्र करें
अगला चरण डेटा के स्थान, प्रारूप और संगठन सहित उसके बारे में विवरण प्राप्त करना है। डेटा की विशेषताओं को समझना और इसका उपयोग कैसे किया जाता है, इस मेटाडेटा द्वारा संभव बनाया गया है।
डेटा दोषों की पहचान करें
यह समझना आसान है कि डेटा को कैसे अद्यतन किया जाता है और संगठन के भीतर उपयोग किया जाता है यदि डेटा के प्रवाह को उसके स्रोत से उसके गंतव्य तक मैप किया जाता है, जिसमें मार्ग के साथ होने वाले किसी भी परिवर्तन या प्रसंस्करण शामिल हैं।
डेटा एक्सेस ट्रैक करें
डेटा सुरक्षा और अनुपालन बनाए रखने के लिए, ट्रैक करें और रिकॉर्ड करें कि कौन डेटा एक्सेस करता है।
वंशावली को स्टोर और कल्पना करें
सरल समझ और विश्लेषण के लिए वंशावली प्रस्तुत करने के लिए विज़ुअलाइज़ेशन टूल का उपयोग करें। एकत्रित मेटाडेटा और डेटा प्रवाह की जानकारी को एक ही रिपॉजिटरी में स्टोर करें।
एक स्वचालित समाधान लागू करें
आप सत्यापित कर सकते हैं कि स्वचालन के माध्यम से डेटा वंशावली एकत्र की जा रही है और उसकी निगरानी की जा रही है, जो गलतियों को कम करने और उत्पादकता को बढ़ावा देने में भी मदद करेगा।
समीक्षा और अद्यतन
सुनिश्चित करें कि वंशावली रिकॉर्ड नियमित रूप से सही और चालू हैं, और इसे उपयुक्त रूप से अपडेट करें।
प्रत्येक संगठन की अनूठी आवश्यकताओं और सीमाओं के आधार पर कार्यान्वयन प्रक्रिया को संशोधित करने या चरणों में जोड़ने की आवश्यकता हो सकती है।
डेटा वंश तकनीक
पैटर्न-आधारित वंश
इस पद्धति के साथ, डेटा उत्पन्न या रूपांतरित करने वाले प्रोग्रामिंग के साथ बातचीत किए बिना वंशावली का प्रदर्शन किया जाता है। टेबल्स, कॉलम्स और बिजनेस रिपोर्ट्स के लिए मेटाडेटा असेसमेंट सभी इसका हिस्सा हैं। यह इस मेटाडेटा का उपयोग करके प्रवृत्तियों की खोज करके वंशावली की खोज करता है।
उदाहरण के लिए, यह काफी संभावना है कि एक ही नाम और समान डेटा मान वाले दो डेटासेट में एक कॉलम अपने अस्तित्व के विभिन्न चरणों में एक ही डेटा का प्रतिनिधित्व करता है। एक डेटा वंशावली चार्ट का उपयोग तब उन दो स्तंभों को जोड़ने के लिए किया जाता है।
पैटर्न-आधारित वंशावली का प्रौद्योगिकी स्वतंत्र होने का महत्वपूर्ण लाभ है क्योंकि यह केवल डेटा की जांच करती है, डेटा प्रोसेसिंग विधियों की नहीं। Oracle, MySQL और Spark सहित कोई भी डेटाबेस तकनीक इसे उसी तरह लागू कर सकती है। दोष यह है कि यह दृष्टिकोण हमेशा सटीक नहीं होता है।
जब डेटा प्रोसेसिंग लॉजिक कंप्यूटर कोड में छुपा होता है और मानव-पठनीय मेटाडेटा में आसानी से स्पष्ट नहीं होता है, तो यह कभी-कभी डेटासेट के बीच संबंधों को अनदेखा कर सकता है।
डेटा टैगिंग द्वारा वंशावली
यह विधि इस धारणा पर आधारित है कि एक परिवर्तन इंजन डेटा को टैग या अन्यथा मार्कर करता है। वंश को खोजने के लिए यह शुरुआत से अंत तक टैग का पता लगाता है। यह दृष्टिकोण तभी सफल हो सकता है जब आपके पास एक विश्वसनीय परिवर्तन उपकरण हो जो सभी डेटा स्थानांतरण का प्रबंधन करता हो और आप उपकरण द्वारा उपयोग की जाने वाली टैगिंग संरचना से परिचित हों।
यहां तक कि अगर ऐसा कोई उपकरण मौजूद था, तो कोई भी डेटा जो इसके बिना बनाया या बदला गया था, डेटा टैगिंग के माध्यम से वंशावली के अधीन हो सकता है। यह इस संबंध में बंद डेटा सिस्टम पर डेटा वंश प्रदर्शन करने के लिए सीमित है।
स्व-निहित वंश
कुछ व्यवसायों में डेटा वातावरण होता है जिसमें मेटाडेटा संग्रहण, प्रसंस्करण तर्क और मास्टर डेटा प्रबंधन (एमडीएम) शामिल होता है। इन सेटिंग्स में अक्सर एक शामिल होता है डेटा लेक जहां सभी डेटा को उसके पूरे जीवन काल में रखा जाता है।
अतिरिक्त संसाधनों की आवश्यकता के बिना इस प्रकार की स्व-निहित प्रणाली द्वारा स्वाभाविक रूप से वंश प्रदान किया जा सकता है। हालाँकि, डेटा टैगिंग विधि की तरह ही, वंश इस विनियमित वातावरण के बाहर होने वाली किसी भी चीज़ से अवगत नहीं होगा।
पार्सिंग द्वारा डेटा वंश
सबसे परिष्कृत प्रकार का वंश वह है जो डेटा-प्रोसेसिंग लॉजिक को स्वचालित रूप से पढ़ता है। पूरी तरह से एंड-टू-एंड ट्रेसिंग के लिए, यह विधि डेटा ट्रांसफ़ॉर्मेशन लॉजिक को रिवर्स इंजीनियर करती है।
चूंकि इस समाधान को सभी को समझना चाहिए प्रोग्रामिंग की भाषाएँ और उपकरण डेटा को परिवर्तित और परिवहन करने के लिए उपयोग किए जाते हैं, इसकी तैनाती जटिल है। यह एक्सट्रेक्ट-ट्रांसफॉर्म-लोड (ETL) लॉजिक, SQL- और जावा-आधारित समाधान, पुराने डेटा स्वरूप, XML-आधारित समाधान और अन्य तकनीकों का उपयोग कर सकता है।
डेटा वंशावली उपयोग के मामले
मॉडलिंग की दिनांक
कंपनियों को अंतर्निहित डेटा संरचनाओं को स्थापित करना चाहिए जो कई डेटा आइटम्स और कंपनी के अंदर उनके बीच के कनेक्शन की कल्पना करने के लिए उनका समर्थन करते हैं। ये कनेक्शन डेटा वंशावली का उपयोग करके तैयार किए गए हैं, जो डेटा पारिस्थितिकी तंत्र में मौजूद कई निर्भरताओं को भी दर्शाता है।
चूंकि डेटा समय के साथ बदलता है, नए डेटा स्रोत लगातार दिखाई देते हैं, नए डेटा एकीकरण आदि की आवश्यकता होती है, इस वजह से, अपने डेटा के प्रबंधन के लिए फर्मों के सामान्य डेटा मॉडल को पर्यावरण को प्रतिबिंबित करने के लिए इसी तरह बदलना चाहिए।
अनुपालन
डेटा लाइनेज ऑडिटिंग, जोखिम प्रबंधन को बढ़ाने और यह सुनिश्चित करने के लिए एक अनुपालन विधि प्रदान करता है कि डेटा को डेटा गवर्नेंस नीतियों और कानूनों के अनुसार रखा और प्रबंधित किया जाता है।
प्रभाव का विश्लेषण
कुछ व्यावसायिक परिवर्तनों के प्रभाव, जैसे कोई भी डाउनस्ट्रीम रिपोर्टिंग, डेटा वंशानुक्रम उपकरणों का उपयोग करके देखा जा सकता है। उदाहरण के लिए, डेटा वंश, अधिकारियों को यह निर्धारित करने में सहायता कर सकता है कि नाम परिवर्तन कितने डैशबोर्ड को प्रभावित करेगा और इसके परिणामस्वरूप कितने लोग उस रिपोर्टिंग तक पहुंचेंगे।
आंकड़ों का विस्थापन
संगठन डेटा माइग्रेशन को यह समझने के लिए नियोजित करते हैं कि डेटा कहाँ स्थित है और इसे नए स्टोरेज सिस्टम में स्थानांतरित करने या नए सॉफ़्टवेयर को लागू करने से पहले यह कितने समय तक रहा है।
डेटा वंशावली टीमों को सिस्टम अपग्रेड या माइग्रेशन के लिए तैयार करने में मदद करती है, जिससे उन्हें यह पता चलता है कि पूरे संगठन में डेटा कैसे स्थानांतरित हुआ है। यह समग्र रूप से नए भंडारण वातावरण में स्थानांतरण को गति देता है।
इसके अतिरिक्त, यह टीमों को पुराने या अनुपयोगी डेटा को संग्रहीत या समाप्त करके डेटा सिस्टम को अव्यवस्थित करने का अवसर देता है। ऐसा करने से, डेटा सिस्टम समग्र रूप से बेहतर प्रदर्शन करेगा और डेटा के कम प्रबंधन की आवश्यकता होगी।
डेटा वंशावली को लागू करने की चुनौतियाँ
- डेटा सुरक्षा: डेटा वंश का निर्माण करते समय डेटा सुरक्षा एक प्राथमिक चिंता है। अपने शुरुआती बिंदु से अपने अंतिम गंतव्य तक डेटा यात्रा का पालन करने के लिए, संवेदनशील डेटा तक पहुंच प्रदान की जानी चाहिए, और इस डेटा को अनधिकृत पहुंच और उल्लंघनों से सुरक्षित किया जाना चाहिए।
- मानकीकरण का अभाव: डेटा वंशावली को अपनाने में प्राथमिक बाधाओं में से एक मानकों की कमी है। चूंकि कई प्लेटफॉर्म, ऐप और सिस्टम डेटा उत्पत्ति को ट्रैक करने और रिकॉर्ड करने के लिए अद्वितीय तरीकों का इस्तेमाल करते हैं, इसलिए डेटा यात्रा की एक साथ मिलकर एक तस्वीर बनाना मुश्किल हो सकता है।
- डेटा सिलोस: डेटा साइलो एक और मुद्दा है जो डेटा वंश को लागू करते समय उत्पन्न होता है। जब डेटा कई अनुप्रयोगों और प्रणालियों में फैला हुआ है, तो इसकी यात्रा को एक से दूसरे में ट्रैक करना चुनौतीपूर्ण हो सकता है। इससे गलत या अपूर्ण डेटा वंशावली हो सकती है।
निष्कर्ष
अंत में, डेटा वंशावली हर डेटा-संचालित उद्यम का एक अनिवार्य हिस्सा है। यह डेटा के शुरुआती बिंदु से उसके अंतिम बिंदु तक के पथ का एक व्यापक परिप्रेक्ष्य प्रदान करता है, इसकी सटीकता, पूर्णता और स्थिरता की गारंटी देता है।
भविष्य के डेटा वंशावली स्वचालन और मानकीकरण में वृद्धि होने की उम्मीद है, जिससे संगठनों के लिए कार्यान्वयन और रखरखाव आसान हो जाएगा। अंत में, डेटा वंशावली के महत्व पर बल नहीं दिया जा सकता है।
यह कंपनियों को बुद्धिमान विकल्प बनाने, अपने संचालन को अधिक कुशलता से चलाने और सफलता प्राप्त करने के लिए आवश्यक उपकरण प्रदान करता है।





एक जवाब लिखें