विषय - सूची[छिपाना][प्रदर्शन]
यदि आप मशीन लर्निंग, आर्टिफिशियल इंटेलिजेंस या कंप्यूटर विज्ञान के प्रति उत्साही हैं, तो आप संभवतः किसी दिए गए सिस्टम या सेवा को बेहतर बनाने में मदद के लिए डेटा की अवधारणा और आवश्यकता को समझते हैं।
टेक दिग्गज और बहुराष्ट्रीय कंपनियां अपने डेटा को समझने के लिए बिजनेस इंटेलिजेंस की उन्नत तकनीकों को अपनाकर ग्राहक अनुभव और उनकी सेवा की समग्र गुणवत्ता को बढ़ाने के लिए बड़ी मात्रा में डेटा का उपयोग करती हैं। उभरती और सबसे महत्वपूर्ण तकनीकों में से एक को पूर्वानुमानित विश्लेषण कहा जाता है।
यह आलेख पूर्वानुमानित विश्लेषण टूल, उनके अनुप्रयोग और इसके कई उदाहरणों के विचार पर चर्चा करता है खुले स्रोत उपकरण जिनका आप उपयोग कर सकते हैं!
पूर्वानुमानित विश्लेषण उपकरण क्या हैं?
पूर्वानुमानित विश्लेषण उपकरण ऐसे सॉफ़्टवेयर हैं जो मौजूदा डेटासेट से जानकारी का विश्लेषण और निकालकर पैटर्न और रुझान निर्धारित करते हैं। ये उपकरण दिए गए डेटा का विश्लेषण करने और भविष्यवाणियां करने के लिए डेटा माइनिंग, पूर्वानुमानित मॉडलिंग और मशीन लर्निंग सहित विभिन्न सांख्यिकीय तकनीकों का उपयोग करते हैं।
इन उपकरणों का उपयोग किसी सेवा की लाभप्रदता और सफलता को बढ़ाने के लिए एक विशिष्ट समय अवधि के लिए योजना बनाने के लिए उपभोक्ता व्यवहार और पिछले रुझानों में पैटर्न को समझने के लिए किया जा सकता है।
पूर्वानुमानित विश्लेषण के अनुप्रयोग
भविष्य कहनेवाला विश्लेषण उपकरण के कई अनुप्रयोग हैं जो कई क्षेत्रों में फैले हुए हैं, जिनमें शामिल हैं:
ई - कॉमर्स
- लोगों को उनकी खरीदारी प्राथमिकताओं के आधार पर समूह बनाकर ग्राहक डेटा का विश्लेषण करना और फिर उत्पादों को खरीदने के लिए इन समूहों की संभावना का अनुमान लगाना।
- लक्षित विपणन अभियानों के निवेश की वापसी (आरओआई) की भविष्यवाणी करना।
- अमेज़ॅन मार्केटप्लेस जैसे ट्रेंडी ऑनलाइन स्टोर से डेटा एकत्र करना।
सामाजिक मीडिया विपणन
- पोस्ट करने के लिए सामग्री के प्रकार और प्रकार की योजना बनाना।
- दी गई सामग्री को पोस्ट करने के लिए सर्वोत्तम दिन और समय की भविष्यवाणी करना।
- सामान्य तौर पर Google विज्ञापनों और विज्ञापनों को संभालना।
बैंकिंग और बीमा (बैंकिंग एंड इन्शुरन्स)
- क्रेडिट रेटिंग का पता लगाना.
- कपटपूर्ण गतिविधियों की पहचान करना.
हेल्थकेयर
- सामान्य रूप से स्वास्थ्य की निगरानी करना।
- किसी व्यक्ति में स्वास्थ्य समस्याओं के शुरुआती लक्षणों की पहचान करना।
विनिर्माण
- इन्वेंट्री और आपूर्ति श्रृंखलाओं का प्रबंधन करना।
- शिपिंग और पूर्ति प्रक्रिया में सहायता करना।
ओपन-सोर्स प्रेडिक्टिव एनालिटिक्स टूल्स
1. ऑरेंज डेटा माइनिंग
ऑरेंज एक डेटा विज़ुअलाइज़ेशन और एनालिटिक्स टूल है जो विज़ुअल प्रोग्रामिंग या पायथन स्क्रिप्टिंग के माध्यम से पूर्वानुमानित विश्लेषण करता है। इस टूलकिट को पायथन लाइब्रेरी के रूप में आयात किया गया है और इसमें इसके घटक शामिल हैं मशीन लर्निंग, जैव सूचना विज्ञान, पाठ खनन, और अन्य डेटा विश्लेषणात्मक विशेषताएं।
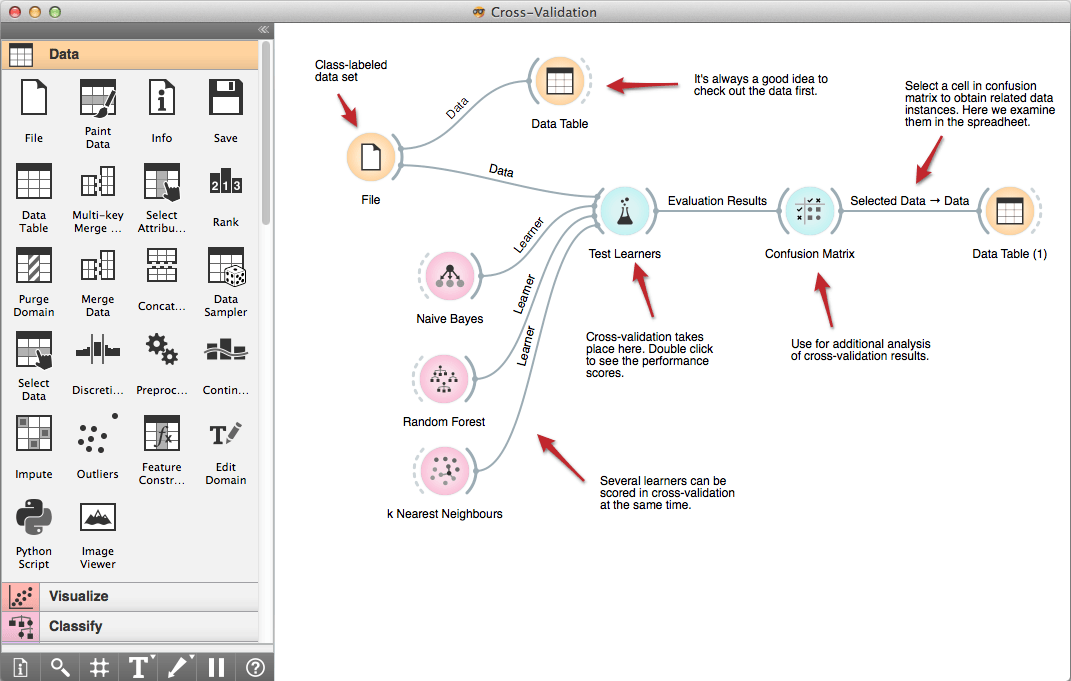
मुख्य विशेषताएं
- इंटरैक्टिव डेटा विज़ुअलाइज़ेशन और चित्रमय प्रतिनिधित्व सुविधाएँ।
- विज़ुअल प्रोग्रामिंग शामिल है।
- कैनवास-आधारित ग्राफिकल यूजर इंटरफेस (जीयूआई) इसे शुरुआती लोगों के लिए उपयोग करना आसान बनाता है।
- सरल और जटिल डेटा विश्लेषण निष्पादित करने में सक्षम।
2. एनाकोंडा
250 से अधिक विभिन्न लोकप्रिय पैकेजों के साथ एक ओपन-सोर्स डेटा साइंस पायथन और आर वितरण प्लेटफ़ॉर्म, जिसका उपयोग केवल पैकेज प्रबंधन और तैनाती के लिए किया जाता है। यह वितरण डेटा विज्ञान का उपयोग करता है, मशीन लर्निंग पूर्वानुमानित विश्लेषण करने के लिए अनुप्रयोग, और बड़े पैमाने पर डेटा प्रोसेसिंग।
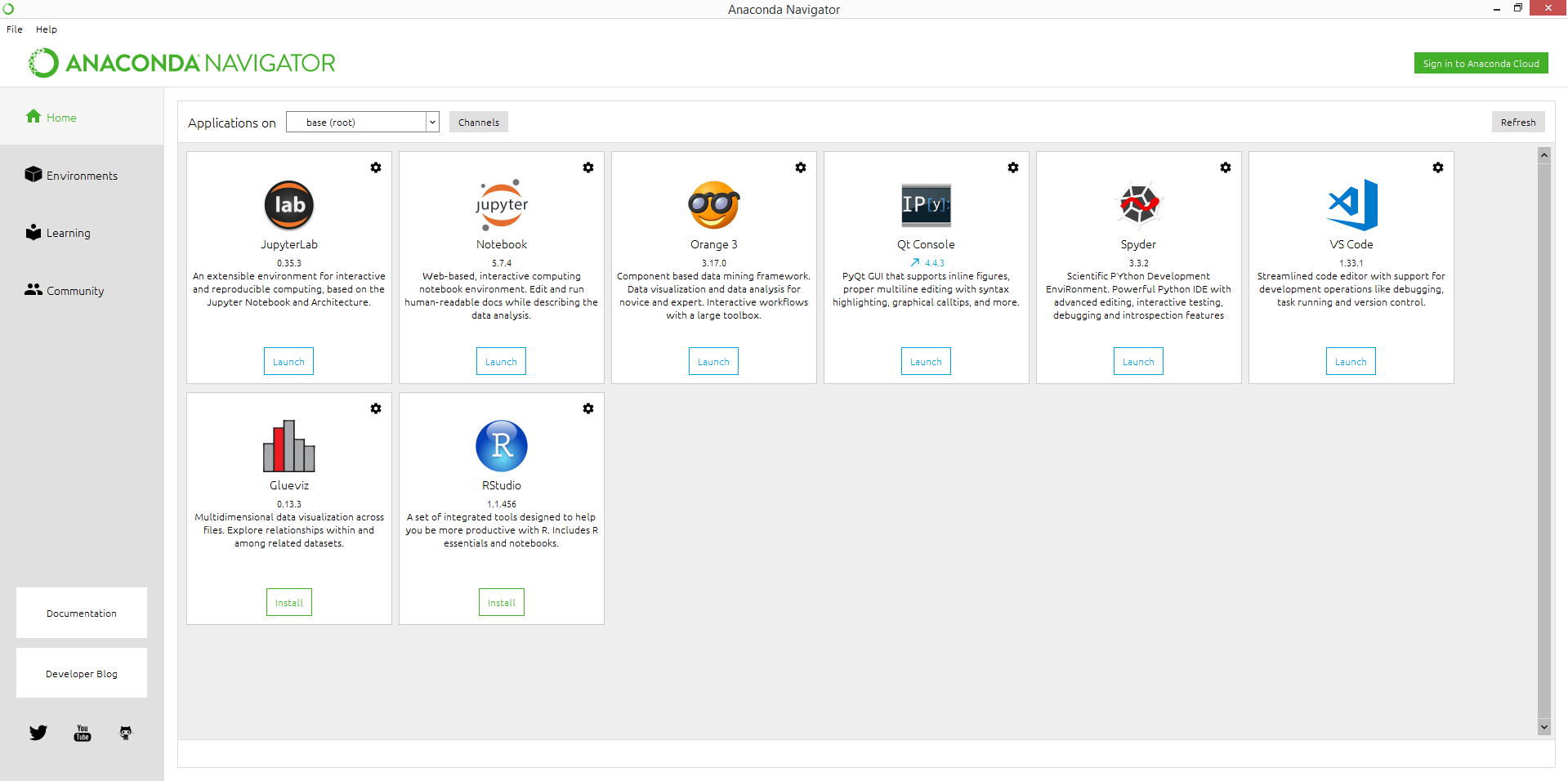
मुख्य विशेषताएं
- उन्नत विश्लेषण, वर्कफ़्लो का उपयोग और डेटा इंटरैक्शन।
- डेटा से अधिकतम मूल्य निकालने के लिए सभी डेटा स्रोतों को कनेक्ट करें।
- पायथन, आर, और . के साथ भविष्य कहनेवाला विश्लेषणात्मक मॉडल बनाएं जुपीटर नोटबुक.
- अपने पूर्वानुमानित विश्लेषणात्मक मॉडल को बुद्धिमान वेब ऐप्स और इंटरैक्टिव विज़ुअलाइज़ेशन में एकीकृत करें।
- एनाकोंडा का उपयोग करके संपूर्ण डेटा विज्ञान टीमों के साथ सहयोग करें।
3. आर सॉफ्टवेयर पर्यावरण
आर वातावरण का उपयोग सांख्यिकीय कंप्यूटिंग और ग्राफिक्स के लिए किया जाता है। यह UNIX, Windows और MAC OS सहित विभिन्न ऑपरेटिंग सिस्टमों को संकलित और चलाता है। इस वातावरण में डेटा एनालिटिक्स और डेटा एनालिटिक्स के ग्राफिकल डिस्प्ले के लिए मध्यवर्ती उपकरणों का एक बड़ा संग्रह है।
मुख्य विशेषताएं
- पूर्वानुमानित विश्लेषण के लिए विभिन्न प्रकार के सांख्यिकीय मॉडल और ग्राफिकल तकनीकें शामिल हैं।
- प्रभावी डेटा प्रबंधन और भंडारण सुविधाएं।
- जटिल डेटा सरणी गणना और सांख्यिकीय विश्लेषण के लिए ऑपरेटरों का एक सूट।
- आर समुदाय से सहायता ऑनलाइन उपलब्ध है।
4. Scikit-जानें
यह पायथन प्रोग्रामिंग भाषा के लिए एक मशीन लर्निंग लाइब्रेरी है। इसमें सपोर्ट वेक्टर मशीन (एसवीएम), रैंडम फॉरेस्ट और के-मीन्स क्लस्टरिंग सहित विभिन्न वर्गीकरण, प्रतिगमन और क्लस्टरिंग एल्गोरिदम शामिल हैं जो भविष्य कहनेवाला मॉडलिंग के लिए बहुत उपयोगी हैं। हालाँकि, स्किकिट-लर्न का उपयोग करके पूर्वानुमानित विश्लेषण करने में सक्षम होने के लिए उन्नत प्रोग्रामिंग ज्ञान की आवश्यकता होती है।
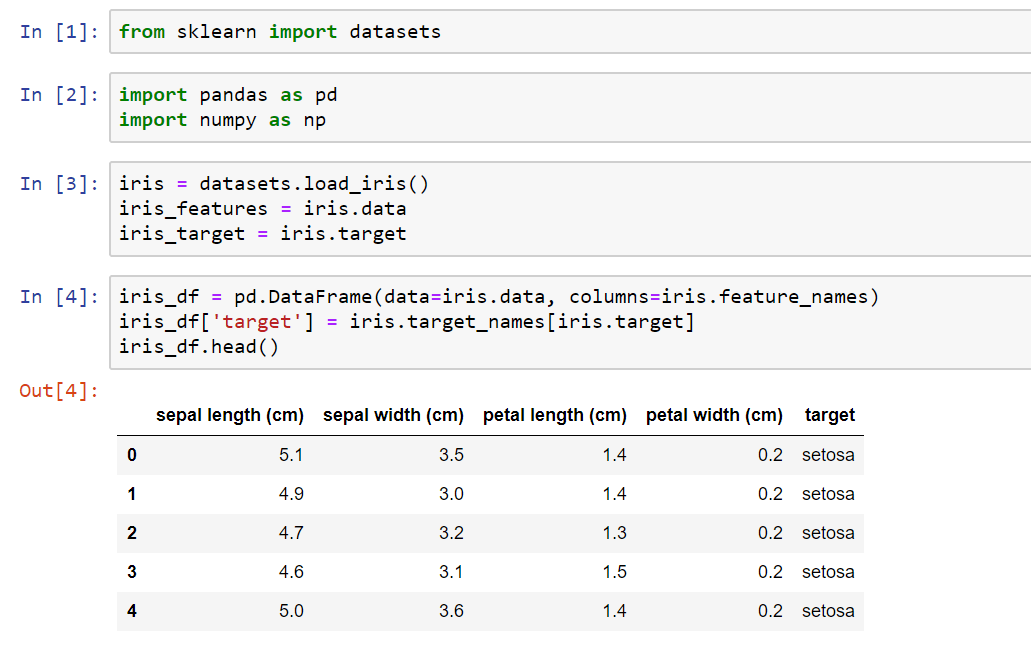
मुख्य विशेषताएं
- उन्नत डेटा प्रबंधन में डेटा को दृश्य और सारणीबद्ध रूप में प्रदर्शित करना, डेटा को फीचर मैट्रिक्स या लक्ष्य वैक्टर में व्यवस्थित करना शामिल है।
- पूर्वानुमानित विश्लेषण के लिए कई वर्गीकरण, प्रतिगमन और क्लस्टरिंग मॉडल उपलब्ध हैं।
- पूर्वानुमानित मॉडल प्रदर्शन का परीक्षण करने के लिए एकाधिक सटीकता मेट्रिक्स।
5. वेका डेटा माइनिंग
वेका जावा में लिखे गए पूर्वानुमानित मॉडलिंग कार्यों के लिए मशीन लर्निंग एल्गोरिदम का एक संग्रह है। इन एल्गोरिदम को सीधे आपके डेटा पर लागू किया जा सकता है या जावास्क्रिप्ट का उपयोग करके कॉल किया जा सकता है। वेका द्वारा प्रदान की गई डेटा एनालिटिक्स विधियों में डेटा माइनिंग, प्रीप्रोसेसिंग और विज़ुअलाइज़िंग तकनीक शामिल हैं। वेका पूर्वानुमानित विश्लेषण के लिए वर्गीकरण, प्रतिगमन और क्लस्टरिंग मॉडल का भी उपयोग करता है।
मुख्य विशेषताएं
- डेटा प्रीप्रोसेसिंग और विज़ुअलाइज़ेशन तकनीक।
- डेटा वर्गीकरण, प्रतिगमन और क्लस्टरिंग एल्गोरिदम।
- डेटा में रुझान की भविष्यवाणी करने के लिए व्यापक एसोसिएशन नियम।
- पोर्टेबल और मेमोरी स्पेस-फ्रेंडली सॉफ्टवेयर।
6. अपाचे महौत
स्केलेबल और परफॉर्मेंट मशीन लर्निंग एल्गोरिदम के निर्माण के लिए एक सरल और एक्स्टेंसिबल प्रोग्रामिंग वातावरण और ढांचा। पर्यावरण में कई पूर्व-निर्मित स्काला, अपाचे स्पार्क और अपाचे फ्लिंट एल्गोरिदम शामिल हैं। यह वातावरण R भाषा के समान एक वेक्टर गणित प्रयोग, संसार का उपयोग करता है जो बड़े पैमाने पर काम करता है।
मुख्य विशेषताएं
- अनुशंसा प्रणाली बनाने के लिए सहयोगात्मक फ़िल्टरिंग।
- पूर्वानुमानित मॉडलिंग के लिए क्लस्टरिंग और वर्गीकरण एल्गोरिदम।
- उन्नत डेटा निष्कर्षण के लिए लगातार आइटमसेट समय का समर्थन करता है।
- उन्नत सांख्यिकीय विश्लेषण के लिए रैखिक बीजगणित ऑपरेटर और वितरित बीजगणित अनुकूलक।
- पूर्वानुमानित विश्लेषण के लिए स्केलेबल एल्गोरिदम बनाता है।
7. जीएनयू ऑक्टेव
यह सॉफ़्टवेयर संख्यात्मक गणनाओं के लिए बनाई गई उच्च स्तरीय भाषा का प्रतिनिधित्व करता है। इस सॉफ़्टवेयर में उन्नत डेटा विश्लेषण के लिए अंतर्निहित प्लॉटिंग और विज़ुअलाइज़ेशन टूल के साथ एक शक्तिशाली गणित-उन्मुख वाक्यविन्यास है। GNU ऑक्टेव MATLAB स्क्रिप्ट और GNU/Linux, MAC OS और Windows सहित ऑपरेटिंग सिस्टम के साथ संगत है।
मुख्य विशेषताएं
- अंतर्निहित 2डी/3डी डेटा प्लॉटिंग और विज़ुअलाइज़ेशन उपकरण।
- डेटा विश्लेषण के लिए कई GNU सांख्यिकीय पैकेजों का समर्थन करता है।
- गणित-उन्मुख भविष्य कहनेवाला मॉडलिंग का उपयोग करता है।
- MATLAB पूर्वानुमानित मॉडल और मशीन लर्निंग एल्गोरिदम चलाने की क्षमता।
8. SciPy
तकनीकी और वैज्ञानिक कंप्यूटिंग के लिए उपयोग किए जाने वाले ओपन-सोर्स पायथन-आधारित सॉफ़्टवेयर का एक संग्रह। SciPy में मुख्य पैकेज हैं जो पायथन के लिए कंप्यूटिंग उपकरण प्रदान करते हैं। यह उन्नत डेटा हैंडलिंग तकनीकों और k निकटतम पड़ोसी, यादृच्छिक वन और पूर्वानुमानित मॉडल का उपयोग करता है तंत्रिका जाल.
SciPy के रूप में उपलब्ध है पायथन पुस्तकालय कई पायथन वितरणों में और एनाकोंडा में एक पैकेज है।
मुख्य विशेषताएं
- अनुकूलन, रैखिक बीजगणित, एकीकरण, प्रक्षेप, विशेष कार्य, एफएफटी और ओडीई सॉल्वर के लिए मॉड्यूल।
- सिग्नल, छवि और डेटा प्रोसेसिंग के लिए विभिन्न कार्य प्रदान करता है।
- NumPy और Matplot को सपोर्ट करता है।
निष्कर्ष
अब आपको ओपन सोर्स प्रेडिक्टिव एनालिटिक्स टूल, उनके अनुप्रयोगों और वे डेटा के माध्यम से भविष्यवाणियां करने के लिए उन्नत तकनीकों का उपयोग कैसे करते हैं, इसके बारे में एक अच्छा विचार होना चाहिए।
उल्लिखित सभी उपकरण उपयोग के लिए पूरी तरह से निःशुल्क हैं और सभी के लिए उपलब्ध हैं। यदि आपने पहले इन उपकरणों का उपयोग किया है, तो हमें टिप्पणियों में अपने अनुभव के बारे में बताएं।





एक जवाब लिखें