क्या होगा अगर हम जीवन के सबसे बड़े रहस्यों में से एक - प्रोटीन फोल्डिंग का उत्तर देने के लिए कृत्रिम बुद्धिमत्ता का उपयोग कर सकें? वैज्ञानिक दशकों से इस पर काम कर रहे हैं।
मशीनें अब गहन शिक्षण मॉडल, दवा विकास, जैव प्रौद्योगिकी और मौलिक जैविक प्रक्रियाओं के हमारे ज्ञान को बदलकर अद्भुत सटीकता के साथ प्रोटीन संरचनाओं की भविष्यवाणी कर सकती हैं।
एआई प्रोटीन फोल्डिंग के पेचीदा दायरे में एक अन्वेषण पर मेरे साथ जुड़ें, जहां अत्याधुनिक तकनीक जीवन की जटिलता से टकराती है।
प्रोटीन फोल्डिंग के रहस्य को उजागर करना
भोजन को तोड़ने या ऑक्सीजन के परिवहन जैसे महत्वपूर्ण कार्यों को करने के लिए प्रोटीन हमारे शरीर में छोटी मशीनों की तरह काम करते हैं। उन्हें प्रभावी ढंग से काम करने के लिए ठीक से मोड़ा जाना चाहिए, ठीक उसी तरह जैसे ताले में फिट होने के लिए चाबी को सही ढंग से काटा जाना चाहिए। जैसे ही प्रोटीन बनता है, एक बहुत ही जटिल फोल्डिंग प्रक्रिया शुरू हो जाती है।
प्रोटीन तह वह प्रक्रिया है जिसके द्वारा अमीनो एसिड की लंबी श्रृंखला, प्रोटीन के निर्माण खंड, त्रि-आयामी संरचनाओं में मोड़ते हैं जो प्रोटीन के कार्य को निर्देशित करते हैं।
मोतियों की एक लंबी स्ट्रिंग पर विचार करें जिसे एक सटीक रूप में क्रमबद्ध किया जाना चाहिए; यह तब होता है जब प्रोटीन फोल्ड हो जाता है। फिर भी, मोतियों के विपरीत, अमीनो एसिड में अद्वितीय विशेषताएं होती हैं और एक दूसरे के साथ विभिन्न तरीकों से बातचीत करती हैं, जिससे प्रोटीन तह एक जटिल और संवेदनशील प्रक्रिया बन जाती है।
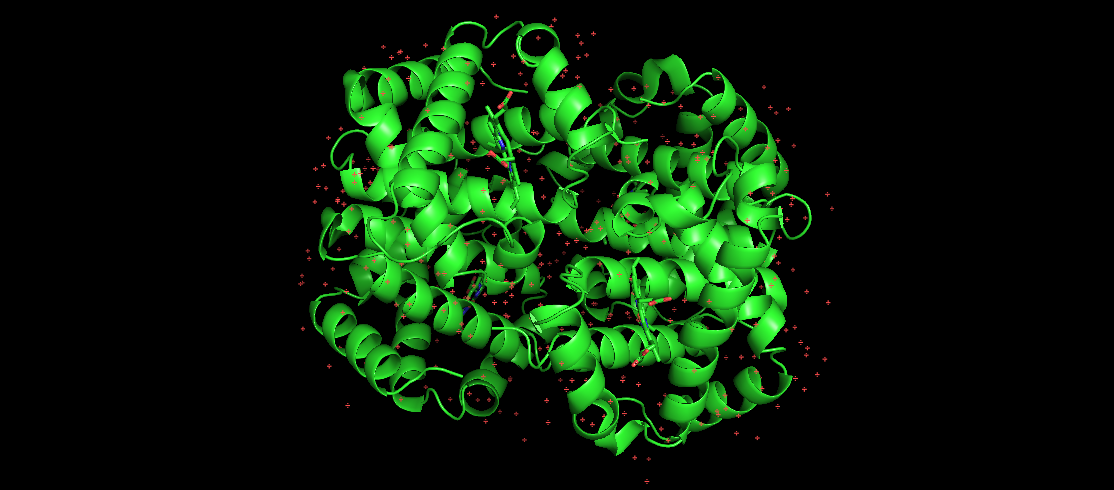
यहाँ चित्र मानव हीमोग्लोबिन का प्रतिनिधित्व करता है, जो एक प्रसिद्ध मुड़ा हुआ प्रोटीन है
प्रोटीन को तेजी से और ठीक से मोड़ना चाहिए, या वे मिसफोल्ड और खराब हो जाएंगे। इससे अल्जाइमर और पार्किंसंस जैसी बीमारियां हो सकती हैं। तापमान, दबाव, और कोशिका में अन्य अणुओं की उपस्थिति का तह प्रक्रिया पर प्रभाव पड़ता है।
दशकों के शोध के बाद, वैज्ञानिक अभी भी यह पता लगाने की कोशिश कर रहे हैं कि प्रोटीन कैसे मुड़ता है।
शुक्र है कि आर्टिफिशियल इंटेलिजेंस में प्रगति से क्षेत्र में विकास में सुधार हो रहा है। वैज्ञानिक उपयोग करके पहले से कहीं अधिक सटीक रूप से प्रोटीन की संरचना का अनुमान लगा सकते हैं मशीन लर्निंग एल्गोरिदम भारी मात्रा में डेटा की जांच करने के लिए।
इसमें दवा के विकास को बदलने और बीमारी के बारे में हमारे आणविक ज्ञान को बढ़ाने की क्षमता है।
क्या मशीनें बेहतर प्रदर्शन कर सकती हैं?
पारंपरिक प्रोटीन तह तकनीकों की सीमाएँ हैं
वैज्ञानिक दशकों से प्रोटीन फोल्डिंग का पता लगाने की कोशिश कर रहे हैं, लेकिन प्रक्रिया की पेचीदगी ने इसे एक चुनौतीपूर्ण विषय बना दिया है।
पारंपरिक प्रोटीन संरचना भविष्यवाणी दृष्टिकोण प्रयोगात्मक पद्धतियों और कंप्यूटर मॉडलिंग के संयोजन का उपयोग करते हैं, हालांकि, इन विधियों में सभी कमियां हैं।
एक्स-रे क्रिस्टलोग्राफी और परमाणु चुंबकीय अनुनाद (एनएमआर) जैसी प्रायोगिक तकनीकें समय लेने वाली और महंगी हो सकती हैं। और, कंप्यूटर मॉडल कभी-कभी सरल धारणाओं पर भरोसा करते हैं, जिससे गलत भविष्यवाणियां हो सकती हैं।
एआई इन बाधाओं को दूर कर सकता है
किस्मत से, कृत्रिम बुद्धिमत्ता अधिक सटीक और कुशल प्रोटीन संरचना भविष्यवाणी के लिए नया वादा प्रदान कर रहा है। मशीन लर्निंग एल्गोरिदम भारी मात्रा में डेटा की जांच कर सकता है। और, वे उन पैटर्नों को उजागर करते हैं जिन्हें लोग याद करेंगे।
इसके परिणामस्वरूप अद्वितीय सटीकता के साथ प्रोटीन संरचना की भविष्यवाणी करने में सक्षम नए सॉफ्टवेयर टूल और प्लेटफॉर्म का निर्माण हुआ है।
प्रोटीन संरचना भविष्यवाणी के लिए सबसे आशाजनक मशीन लर्निंग एल्गोरिदम
Google द्वारा निर्मित AlphaFold सिस्टम Deepmind टीम इस क्षेत्र में सबसे आशाजनक प्रगति में से एक है। हाल के वर्षों में इसका उपयोग करके इसने काफी प्रगति की है गहन शिक्षण एल्गोरिदम उनके अमीनो एसिड अनुक्रमों के आधार पर प्रोटीन की संरचना की भविष्यवाणी करने के लिए।
तंत्रिका नेटवर्क, वेक्टर मशीनों का समर्थन, और यादृच्छिक वन अधिक मशीन सीखने के तरीकों में से हैं जो प्रोटीन संरचना की भविष्यवाणी करने के लिए वादा दिखाते हैं।
ये एल्गोरिदम विशाल डेटासेट से सीख सकते हैं। और, वे विभिन्न अमीनो एसिड के बीच के संबंध का अनुमान लगा सकते हैं। तो, देखते हैं कि यह कैसे काम करता है।

सह-विकासवादी विश्लेषण और पहली अल्फाफोल्ड पीढ़ी
की सफलता अल्फाफोल्ड एक गहरे तंत्रिका नेटवर्क मॉडल पर बनाया गया है जिसे सह-विकासवादी विश्लेषण का उपयोग करके विकसित किया गया था। सह-विकास की अवधारणा बताती है कि यदि प्रोटीन में दो अमीनो एसिड एक दूसरे के साथ बातचीत करते हैं, तो वे अपने कार्यात्मक लिंक को बनाए रखने के लिए एक साथ विकसित होंगे।
शोधकर्ता यह पता लगा सकते हैं कि कई समान प्रोटीनों के अमीनो एसिड अनुक्रमों की तुलना करके 3 डी संरचना में कौन से जोड़े अमीनो एसिड के संपर्क में होने की संभावना है।
यह डेटा AlphaFold के पहले पुनरावृत्ति के लिए आधार के रूप में कार्य करता है। यह अमीनो एसिड जोड़े के साथ-साथ उन्हें जोड़ने वाले पेप्टाइड बॉन्ड के कोणों के बीच की लंबाई की भविष्यवाणी करता है। अनुक्रम से प्रोटीन संरचना की भविष्यवाणी करने के लिए इस विधि ने सभी पूर्व दृष्टिकोणों को बेहतर प्रदर्शन किया, हालांकि प्रोटीन के लिए सटीकता अभी भी प्रतिबंधित थी, जिसमें कोई स्पष्ट टेम्पलेट नहीं था।

अल्फाफोल्ड 2: एक मौलिक रूप से नई पद्धति
AlphaFold2 डीपमाइंड द्वारा बनाया गया एक कंप्यूटर सॉफ्टवेयर है जो प्रोटीन की 3डी संरचना की भविष्यवाणी करने के लिए प्रोटीन के अमीनो एसिड अनुक्रम का उपयोग करता है।
यह महत्वपूर्ण है क्योंकि एक प्रोटीन की संरचना यह निर्धारित करती है कि यह कैसे कार्य करता है, और इसके कार्य को समझने से वैज्ञानिकों को प्रोटीन को लक्षित करने वाली दवाएं विकसित करने में मदद मिल सकती है।
AlphaFold2 तंत्रिका नेटवर्क इनपुट के रूप में प्रोटीन के अमीनो एसिड अनुक्रम के साथ-साथ विवरण प्राप्त करता है कि यह अनुक्रम डेटाबेस में अन्य अनुक्रमों की तुलना कैसे करता है (इसे "अनुक्रम संरेखण" कहा जाता है)।
तंत्रिका नेटवर्क इस इनपुट के आधार पर प्रोटीन की 3डी संरचना के बारे में भविष्यवाणी करता है।
क्या इसे AlphaFold2 से अलग करता है?
अन्य दृष्टिकोणों के विपरीत, AlphaFold2 प्रोटीन की वास्तविक 3D संरचना की भविष्यवाणी करता है, न कि केवल अमीनो एसिड के जोड़े के बीच अलगाव या उन्हें जोड़ने वाले बॉन्ड के बीच के कोण (जैसा कि पूर्व एल्गोरिदम ने किया था)।
तंत्रिका नेटवर्क के लिए एक बार में पूरी संरचना का अनुमान लगाने के लिए, संरचना को एंड-टू-एंड एन्कोड किया गया है।
AlphaFold2 की एक अन्य प्रमुख विशेषता यह है कि यह अनुमान लगाता है कि यह अपने पूर्वानुमान में कितना आश्वस्त है। यह प्रत्याशित संरचना पर रंग कोडिंग के रूप में प्रस्तुत किया जाता है, जिसमें लाल उच्च आत्मविश्वास का प्रतिनिधित्व करता है और नीला कम आत्मविश्वास का सुझाव देता है।
यह उपयोगी है क्योंकि यह वैज्ञानिकों को भविष्यवाणी की स्थिरता के बारे में सूचित करता है।
कई अनुक्रमों की संयुक्त संरचना की भविष्यवाणी करना
Alphafold2 का नवीनतम विस्तार, जिसे Alphafold Multimer के रूप में जाना जाता है, कई अनुक्रमों की संयुक्त संरचना का पूर्वानुमान लगाता है। इसमें अभी भी उच्च त्रुटि दर है, भले ही यह पहले की तकनीकों से कहीं बेहतर प्रदर्शन करती हो। 25 प्रोटीन परिसरों में से सिर्फ 4500% का सफलतापूर्वक अनुमान लगाया गया था।
संपर्क गठन के 70% खुरदरे क्षेत्रों की सही भविष्यवाणी की गई थी, लेकिन दो प्रोटीनों का सापेक्ष अभिविन्यास गलत था। जब औसत संरेखण गहराई लगभग 30 अनुक्रमों से कम होती है, तो अल्फाफोल्ड मल्टीमर भविष्यवाणियों की सटीकता में काफी गिरावट आती है।
अल्फ़ाफ़ोल्ड भविष्यवाणियों का उपयोग कैसे करें
AlphaFold के अनुमानित मॉडल समान फ़ाइल स्वरूपों में पेश किए जाते हैं और प्रायोगिक संरचनाओं के समान ही उपयोग किए जा सकते हैं। गलतफहमियों को रोकने के लिए मॉडल के साथ पेश किए गए सटीकता अनुमानों को ध्यान में रखना महत्वपूर्ण है।
यह विशेष रूप से इंटरवॉवन होमोमर या प्रोटीन जैसी जटिल संरचनाओं के लिए सहायक होता है जो केवल एक की उपस्थिति में मोड़ते हैं
अज्ञात लिगैंड।
कुछ चुनौतियाँ
अनुमानित संरचनाओं का उपयोग करने में मुख्य समस्या प्रोटीन और बायोफिजिकल डेटा तक पहुंच के बिना गतिशीलता, लिगैंड चयनात्मकता, नियंत्रण, एलोस्टरी, पोस्ट-ट्रांसलेशनल परिवर्तन और बाइंडिंग के कैनेटीक्स को समझना है।
मशीन लर्निंग और इस समस्या को दूर करने के लिए भौतिकी-आधारित आणविक गतिकी अनुसंधान का उपयोग किया जा सकता है।
ये जांच विशेष और कुशल कंप्यूटर आर्किटेक्चर से लाभान्वित हो सकती हैं। जबकि अल्फाफोल्ड ने प्रोटीन संरचनाओं की भविष्यवाणी करने में जबरदस्त प्रगति हासिल की है, संरचनात्मक जीव विज्ञान के क्षेत्र में अभी भी बहुत कुछ सीखना बाकी है, और अल्फाफोल्ड भविष्यवाणियां भविष्य के अध्ययन के लिए केवल शुरुआती बिंदु हैं।
अन्य उल्लेखनीय उपकरण क्या हैं?
रोज़ टीटीएफोल्ड
वाशिंगटन विश्वविद्यालय के शोधकर्ताओं द्वारा बनाए गए RoseTTAFold, इसी तरह प्रोटीन संरचनाओं की भविष्यवाणी करने के लिए गहन शिक्षण एल्गोरिदम को नियोजित करते हैं, लेकिन यह अनुमानित संरचनाओं को बेहतर बनाने के लिए "मरोड़ कोण गतिकी सिमुलेशन" के रूप में जाना जाने वाला एक उपन्यास दृष्टिकोण भी एकीकृत करता है।
इस पद्धति के उत्साहजनक परिणाम मिले हैं और यह मौजूदा एआई प्रोटीन फोल्डिंग टूल्स की सीमाओं को पार करने में उपयोगी हो सकता है।
trरोसेटा
एक अन्य उपकरण, ट्ररोसेटा, a का उपयोग करके प्रोटीन फोल्डिंग की भविष्यवाणी करता है तंत्रिका नेटवर्क लाखों प्रोटीन अनुक्रमों और संरचनाओं पर प्रशिक्षित।
यह लक्ष्य प्रोटीन की तुलनात्मक ज्ञात संरचनाओं से तुलना करके अधिक सटीक भविष्यवाणियां करने के लिए "टेम्पलेट-आधारित मॉडलिंग" तकनीक का भी उपयोग करता है।
यह प्रदर्शित किया गया है कि ट्ररोसेटा छोटे प्रोटीन और प्रोटीन परिसरों की संरचनाओं की भविष्यवाणी करने में सक्षम है।
डीपमेटाप्सिकोव
DeepMetaPSICOV एक और उपकरण है जो प्रोटीन संपर्क मानचित्रों की भविष्यवाणी करने पर केंद्रित है। इनका उपयोग प्रोटीन फोल्डिंग की भविष्यवाणी करने के लिए एक गाइड के रूप में किया जाता है। यह उपयोगकर्ता है ध्यान लगा के पढ़ना या सीखना प्रोटीन के अंदर अवशेषों की परस्पर क्रियाओं की संभावना का पूर्वानुमान लगाने के लिए दृष्टिकोण।
इन्हें बाद में समग्र संपर्क मानचित्र की भविष्यवाणी करने के लिए उपयोग किया जाता है। DeepMetaPSICOV ने प्रोटीन संरचनाओं की बड़ी सटीकता के साथ भविष्यवाणी करने की क्षमता दिखाई है, भले ही पिछले दृष्टिकोण विफल हो गए हों।
भविष्य में क्या है?
एआई प्रोटीन फोल्डिंग का भविष्य उज्ज्वल है। डीप लर्निंग-आधारित एल्गोरिदम, विशेष रूप से अल्फाफोल्ड 2, ने हाल ही में प्रोटीन संरचनाओं की मज़बूती से भविष्यवाणी करने में बड़ी प्रगति की है।
इस खोज में वैज्ञानिकों को प्रोटीन की संरचना और कार्य को बेहतर ढंग से समझने की अनुमति देकर दवा के विकास को बदलने की क्षमता है, जो सामान्य चिकित्सीय लक्ष्य हैं।
बहरहाल, प्रोटीन परिसरों की भविष्यवाणी करने और प्रत्याशित संरचनाओं की वास्तविक कार्यात्मक स्थिति का पता लगाने जैसे मुद्दे बने हुए हैं। इन मुद्दों को हल करने और एआई प्रोटीन फोल्डिंग एल्गोरिदम की सटीकता और विश्वसनीयता बढ़ाने के लिए और अधिक शोध की आवश्यकता है।
फिर भी, इस तकनीक के संभावित लाभ बहुत अधिक हैं, और इसमें अधिक प्रभावी और सटीक दवाओं के उत्पादन की ओर ले जाने की क्षमता है।





एक जवाब लिखें