E se puidésemos usar a intelixencia artificial para responder a un dos maiores misterios da vida: o pregamento de proteínas? Os científicos levan décadas traballando nisto.
Agora as máquinas poden predecir estruturas de proteínas cunha precisión sorprendente utilizando modelos de aprendizaxe profunda, alterando o desenvolvemento de fármacos, a biotecnoloxía e o noso coñecemento dos procesos biolóxicos fundamentais.
Acompáñame nunha exploración no intrigante reino do pregamento de proteínas da IA, onde a tecnoloxía de punta choca coa complexidade da propia vida.
Desvelando o misterio do pregamento de proteínas
As proteínas traballan no noso corpo como pequenas máquinas para realizar tarefas cruciais como descompoñer alimentos ou transportar osíxeno. Deben estar dobrados correctamente para que funcionen eficazmente, do mesmo xeito que se debe cortar correctamente unha chave para encaixar nunha pechadura. Tan pronto como se crea a proteína, comeza un proceso de pregamento moi complicado.
O pregamento de proteínas é o proceso polo cal longas cadeas de aminoácidos, os bloques de construción da proteína, se pregan en estruturas tridimensionais que ditan a función da proteína.
Considere unha longa cadea de contas que debe ser ordenada nunha forma precisa; isto é o que ocorre cando unha proteína se prega. Non obstante, a diferenza das perlas, os aminoácidos teñen características únicas e interactúan entre si de varias maneiras, facendo que o pregamento das proteínas sexa un proceso complexo e sensible.
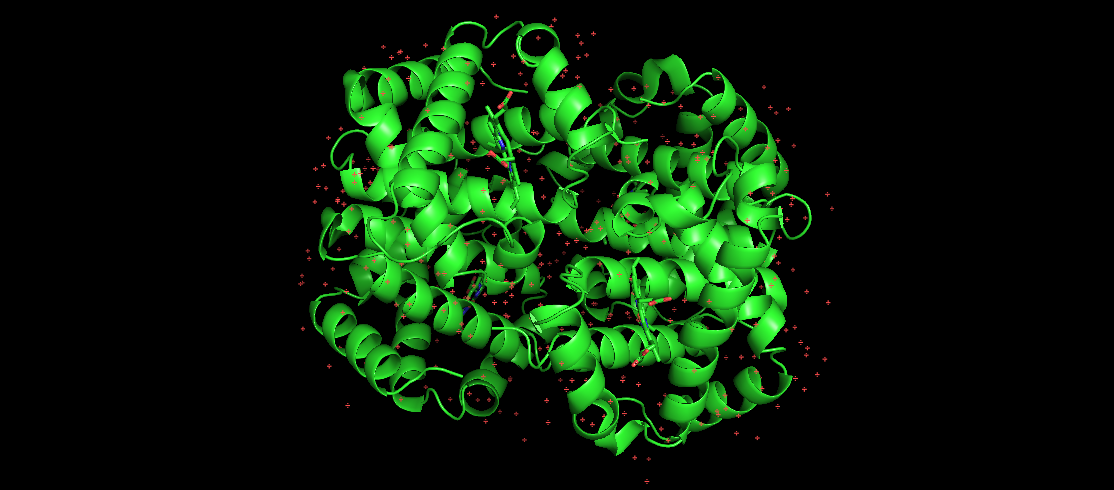
A imaxe aquí representa a hemoglobina humana, que é unha coñecida proteína pregada
As proteínas deben pregarse con rapidez e precisión, ou faranse mal e defectuosas. Isto pode levar a enfermidades como o alzhéimer e o párkinson. A temperatura, a presión e a presenza doutras moléculas na célula teñen un efecto no proceso de pregamento.
Despois de décadas de investigación, os científicos aínda están intentando descubrir exactamente como se pregan as proteínas.
Afortunadamente, os avances na intelixencia artificial están a mellorar o desenvolvemento do sector. Os científicos poden prever a estrutura das proteínas con máis precisión que nunca usando algoritmos de aprendizaxe automática examinar grandes cantidades de datos.
Isto ten o potencial de cambiar o desenvolvemento de medicamentos e aumentar o noso coñecemento molecular sobre a enfermidade.
As máquinas poden funcionar mellor?
As técnicas convencionais de pregamento de proteínas teñen limitacións
Os científicos estiveron intentando descubrir o pregamento das proteínas durante décadas, pero a complexidade do proceso fixo que este sexa un tema desafiante.
Os enfoques convencionais de predición da estrutura das proteínas usan unha combinación de metodoloxías experimentais e modelado por ordenador, pero todos estes métodos teñen inconvenientes.
As técnicas experimentais como a cristalografía de raios X e a resonancia magnética nuclear (RMN) poden ser lentas e custosas. E, ás veces, os modelos informáticos baséanse en suposicións simples, que poden levar a predicións erróneas.
A IA pode superar estes obstáculos
Afortunadamente, intelixencia artificial ofrece novas promesas para unha predición máis precisa e eficiente da estrutura das proteínas. Os algoritmos de aprendizaxe automática poden examinar volumes masivos de datos. E, descobren patróns que a xente perdería.
Isto deu lugar á creación de novas ferramentas de software e plataformas capaces de predicir a estrutura das proteínas cunha precisión incomparable.
Os algoritmos de aprendizaxe automática máis prometedores para a predición da estrutura das proteínas
O sistema AlphaFold construído por Google Deepmind equipo é un dos avances máis prometedores nesta área. Obtivo un gran progreso nos últimos anos co uso algoritmos de aprendizaxe profunda para predicir a estrutura das proteínas en función das súas secuencias de aminoácidos.
As redes neuronais, as máquinas vectoriais de apoio e os bosques aleatorios atópanse entre outros métodos de aprendizaxe automática que son prometedores para predicir a estrutura das proteínas.
Estes algoritmos poden aprender de enormes conxuntos de datos. E, poden anticipar as correlacións entre diferentes aminoácidos. Entón, imos ver como funciona.

Análises coevolutivas e a primeira xeración AlphaFold
O éxito do AlphaFold está construído sobre un modelo de rede neuronal profunda que foi desenvolvido utilizando análises coevolutivas. O concepto de coevolución establece que se dous aminoácidos dunha proteína interactúan entre si, desenvolveranse xuntos para manter o seu vínculo funcional.
Os investigadores poden detectar que pares de aminoácidos son susceptibles de estar en contacto na estrutura 3D comparando as secuencias de aminoácidos de numerosas proteínas similares.
Estes datos serven como base para a primeira iteración de AlphaFold. Predí as lonxitudes entre os pares de aminoácidos así como os ángulos dos enlaces peptídicos que os unen. Este método superou todos os enfoques anteriores para predicir a estrutura das proteínas a partir da secuencia, aínda que a precisión aínda estaba restrinxida para proteínas sen modelos aparentes.

AlphaFold 2: unha metodoloxía radicalmente nova
AlphaFold2 é un programa informático creado por DeepMind que utiliza a secuencia de aminoácidos dunha proteína para predicir a estrutura 3D da proteína.
Isto é significativo porque a estrutura dunha proteína dita como funciona, e comprender a súa función pode axudar aos científicos a desenvolver medicamentos que teñan como obxectivo a proteína.
A rede neuronal AlphaFold2 recibe como entrada a secuencia de aminoácidos da proteína, así como detalles sobre como se compara esa secuencia con outras secuencias dunha base de datos (isto chámase "aliñamento de secuencias").
A rede neuronal fai unha predición sobre a estrutura 3D da proteína en función desta entrada.
Que o diferencia de AlphaFold2?
En contraste con outros enfoques, AlphaFold2 predice a estrutura 3D real da proteína en lugar de só a separación entre pares de aminoácidos ou os ángulos entre os enlaces que os conectan (como facían os algoritmos anteriores).
Para que a rede neuronal anticipe a estrutura completa dunha soa vez, a estrutura está codificada de extremo a extremo.
Outra característica clave de AlphaFold2 é que ofrece unha estimación da confianza que ten na súa previsión. Isto preséntase como unha codificación de cores na estrutura prevista, co vermello que representa unha alta confianza e o azul que suxire unha baixa confianza.
Isto é útil xa que informa aos científicos sobre a estabilidade da predición.
Predicir a estrutura combinada de varias secuencias
A última expansión de Alphafold2, coñecida como Alphafold Multimer, prevé a estrutura combinada de varias secuencias. Aínda ten altas taxas de erro aínda que teña un rendemento moito mellor que as técnicas anteriores. Só o 25% dos 4500 complexos proteicos foron predidos con éxito.
O 70% das rexións ásperas de formación de contacto foron preditas correctamente, pero a orientación relativa das dúas proteínas era incorrecta. Cando a profundidade media de aliñamento é inferior a aproximadamente 30 secuencias, a precisión das predicións do multímero Alphafold diminúe significativamente.
Como usar as predicións Alphafold
Os modelos previstos de AlphaFold ofrécense nos mesmos formatos de ficheiro e pódense usar do mesmo xeito que as estruturas experimentais. É fundamental ter en conta as estimacións de precisión ofrecidas co modelo para evitar malentendidos.
É especialmente útil para estruturas complicadas como homómeros entretecidos ou proteínas que só se pregan en presenza dun
ligando descoñecido.
Algúns retos
O principal problema ao usar estruturas predidas é comprender a dinámica, a selectividade de ligandos, o control, a alosterería, os cambios post-traducionais e a cinética da unión sen acceso a proteínas e datos biofísicos.
Aprendizaxe automática e a investigación de dinámica molecular baseada na física pode utilizarse para superar este problema.
Estas investigacións poden beneficiarse dunha arquitectura informática especializada e eficiente. Aínda que AlphaFold conseguiu avances tremendos na predicción de estruturas de proteínas, aínda queda moito por aprender no campo da bioloxía estrutural, e as predicións de AlphaFold son só o punto de partida para estudos futuros.
Cales son outras ferramentas notables?
RoseTTAFfold
RoseTTAFold, creado polos investigadores da Universidade de Washington, tamén emprega algoritmos de aprendizaxe profunda para predicir estruturas de proteínas, pero tamén integra un novo enfoque coñecido como "simulacións dinámicas de ángulos de torsión" para mellorar as estruturas previstas.
Este método deu resultados alentadores e pode ser útil para superar as limitacións das ferramentas de pregamento de proteínas da IA existentes.
trRosetta
Outra ferramenta, trRosetta, prevé o pregamento das proteínas mediante a rede neural adestrados en millóns de secuencias e estruturas de proteínas.
Tamén utiliza unha técnica de "modelo baseado en modelos" para crear predicións máis precisas comparando a proteína diana con estruturas coñecidas comparables.
Demostrouse que trRosetta é capaz de predicir as estruturas de pequenas proteínas e complexos proteicos.
DeepMetaPSICOV
DeepMetaPSICOV é outra ferramenta que se centra na predicción de mapas de contacto con proteínas. Estes, utilízanse como guía para predicir o pregamento das proteínas. Usa aprendizaxe profunda enfoques para prever a probabilidade de interaccións de residuos dentro dunha proteína.
Estes utilízanse posteriormente para prognosticar o mapa xeral de contactos. DeepMetaPSICOV demostrou potencial para predecir estruturas de proteínas con gran precisión, mesmo cando os enfoques anteriores fallaron.
Que nos depara o futuro?
O futuro do pregamento de proteínas da IA é brillante. Os algoritmos baseados na aprendizaxe profunda, en particular AlphaFold2, fixeron recentemente grandes avances na predicción fiable das estruturas das proteínas.
Este achado ten o potencial de transformar o desenvolvemento de fármacos ao permitir aos científicos comprender mellor a estrutura e a función das proteínas, que son obxectivos terapéuticos comúns.
Non obstante, aínda quedan problemas como a previsión de complexos proteicos e a detección do estado funcional real das estruturas previstas. Requírese máis investigación para resolver estes problemas e aumentar a precisión e fiabilidade dos algoritmos de pregamento de proteínas da IA.
Non obstante, os beneficios potenciais desta tecnoloxía son enormes e ten o potencial de levar á produción de medicamentos máis eficaces e precisos.





Deixe unha resposta