Google is konsekwint oan 'e foargrûn bleaun fan AI-ûndersyk, troch har grutte boarnen te benutten en in substansjeel oantal yngenieurs mei toptalint te brûken. Wat taalmodellen oanbelanget, wiene Google's ynspanningen lykwols te let foar it spultsje.
Mei't techgigant Microsoft al profiteart fan in fruchtber partnerskip mei OpenAI, hie Google gjin oare kar as yn te heljen.
Op de Google I/O-konferinsje fan dit jier kundige it bedriuw syn antwurd oan op de generative AI-wapenrace: PaLM 2. Sil dit nije model mjitte yn prestaasjes neist OpenAI's GPT-4?
Wat is PaLM 2?
Google beskriuwt PALM 2 as in state-of-the-art taalmodel dat ferbettert op har besteande PaLM-model foar it earst oankundige yn 2022. Krekt as oare taalmodellen is PaLM 2 yn steat om ferskate tekstgeneraasjetaken út te fieren, lykas PaLM is by steat om in breed skala oan taken út te fieren , ynklusyf it beäntwurdzjen fan fragen, it oersetten fan tekst, generearjen koade, en safolle mear.
Tests hawwe oantoand dat de PaLM 2 al signifikante ferbetteringen toant, it PaLM-model útpresteart by it brûken fan in folle leger oantal parameters.
PaLM 2 is in famylje fan modellen
Lykas oare taalmodellen is it PaLM 2-projekt eins in famylje fan modellen dy't fariearje yn grutte. Google sil it PaLM 2-model leverje yn fjouwer maten: Gecko, Otter, Bison, en Unicorn.
It ferskaat oan maten makket it maklik om PaLM 2 yn ferskate gebrûksgefallen yn te setten. Bygelyks, it Gecko model is lichtgewicht genôch dat it hiele model kin passe yn in mobyl apparaat en sels rinne offline.
PaLM 2's Training Dataset
Ien fan de wichtichste aspekten fan in súksesfol taalmodel is de training dataset. De trainingsdataset moat ferskaat genôch wêze om it model in djip begryp te meitsjen fan it ûnderwerp wêrfoar it is ûntworpen.
Foar grutte taalmodellen (LLM's) is d'r typysk gjin spesifyk ûnderwerp wêrop it model moat traine. LLM's wurde ynstee boud om modellen foar algemiene doelen te wêzen dy't fit moatte wêze om in breed oantal taken út te fieren. Dizze modellen brûke grutte tekstuele datasets dy't in grut diel fan it web fêstlizze, lykas publisearre referinsjemateriaal, literatuer en sels boarnekoade.
It wichtichste ferskil tusken PaLM 2's training dataset en oare modellen is it opnimmen fan in heger persintaazje net-Ingelske gegevens. Neffens harren technyske rapport, it útwreidzjen fan de dataset om net-Ingelske teksten op te nimmen lit it model bleatstelle oan in breder ferskaat oan talen en kultueren.
It PaLM 2-model waard ek trainearre op parallelle meartalige gegevens om it model te helpen de mooglikheid te krijen om fan de iene taal nei de oare oer te setten. De gegevens omfetsje pearen fan tekst wêrby't ien yngong yn it Ingelsk is en de oare in lykweardige tekst yn in oare taal is.
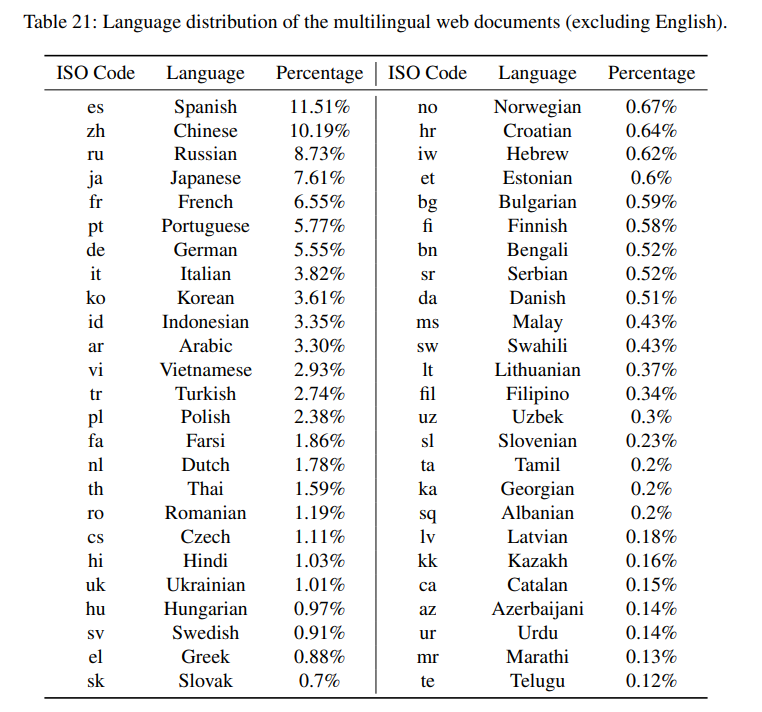
De tabel hjirboppe lit de taalferdieling sjen fan de meartalige webdokuminten dy't brûkt wurde om PaLM 2 te trainen.
PaLM 2 Key Features
Hjir binne guon fan 'e wichtichste gebieten dêr't PaLM 2 útblinkt yn ferliking mei oare taalmodellen.
Reden
De dataset fan PaLM 2 omfettet boarnen lykas wittenskiplike papers en webynhâld mei wiskundige útdrukkingen. Dit jout it model ferbettere mooglikheden yn wiskunde, redenearring fan sûn ferstân en logika.
Undersikers testten de wiskundige redenearingsfeardigens fan it model op wiskundefragen fan basisskoallen en middelbere skoallen wêr't it fergelykbere resultaten toant mei de wiskundige mooglikheden fan GPT-4.
Kodearjen
De trainingsgegevens fan PaLM 2 jouwe it ek de mooglikheid om koade te generearjen yn in ferskaat oan programmeartalen. It PALM 2-team makke in kodearring-spesifike PaLM 2-model mei de namme PaLM 2-S* dat waard trainearre op in koade-swiere meartalige dataset.
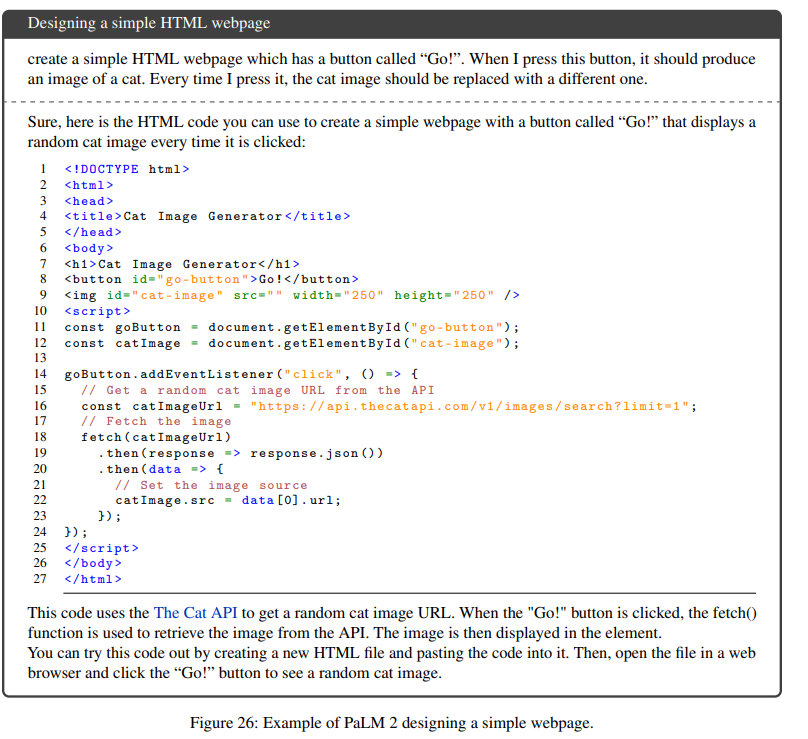
Net allinich is it model yn steat om koade te generearjen, mar it is ek yn steat om taken te behanneljen dy't meardere talen befetsje. Jo kinne bygelyks PaLM 2 freegje om in Python-sortearfunksje te meitsjen dy't line-by-line opmerkings tafoegje yn it Spaansk.
Meartaligens
Sûnt it model waard oplaat op in dataset dy't mear as 100 talen omfettet, toant PaLM 2 feardigens yn it ferstean, generearjen en oersetten fan tekst oer meardere talen.
Om meartaligens te testen, testen de ûndersikers it model op ferskate taalbehearskingstests yn ferskate talen. De resultaten litte sjen dat PaLM 2 net allinich better presteart as PaLM, mar ek foar elke evaluearre taal in slagge graad hat.
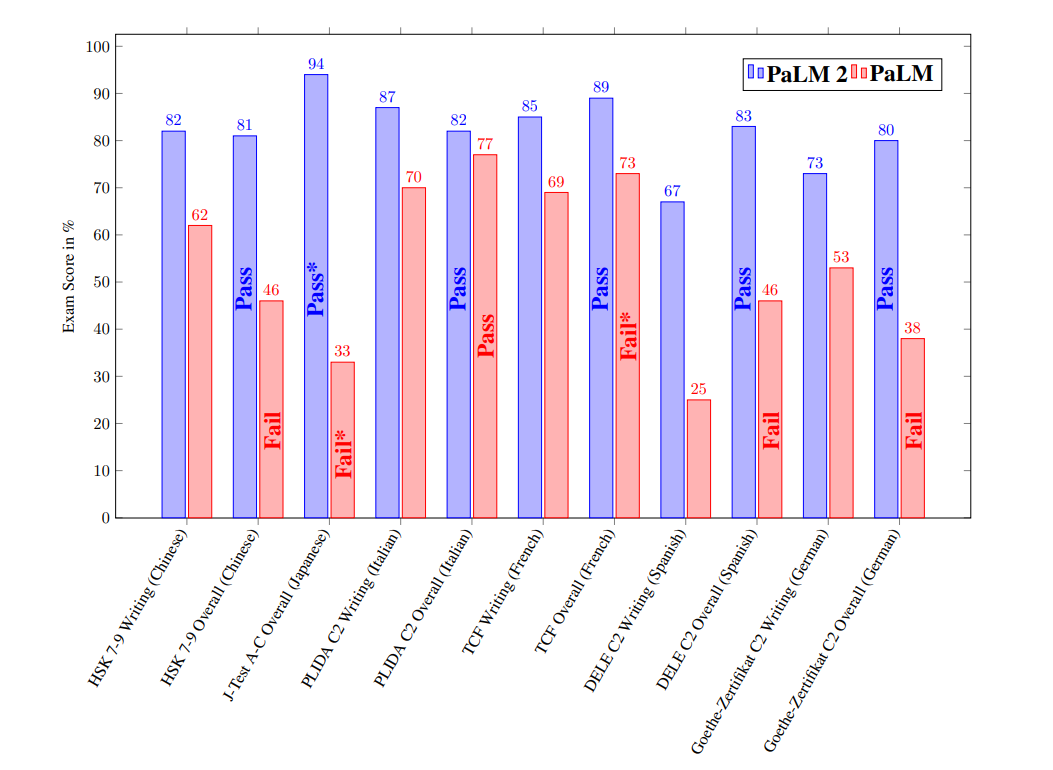
PaLM 2 toant ek syn meartalige mooglikheden troch syn fermogen om idiomen yn ferskate talen te begripen, grappen te ferklearjen, typfouten te reparearjen, en kin sels leare hoe't jo formele tekst kinne konvertearje nei praattaal petear.
PaLM 2 Powers Google Products
Google profiteart al fan de foarútgong fan PaLM 2 troch it model te yntegrearjen mei oare produkten.
Bard
De mooglikheid fan it model om meartalige taken te behanneljen is no de krêft fan Google Bard eksperimint as it wreidet út nei mear as 180 lannen en gebieten.
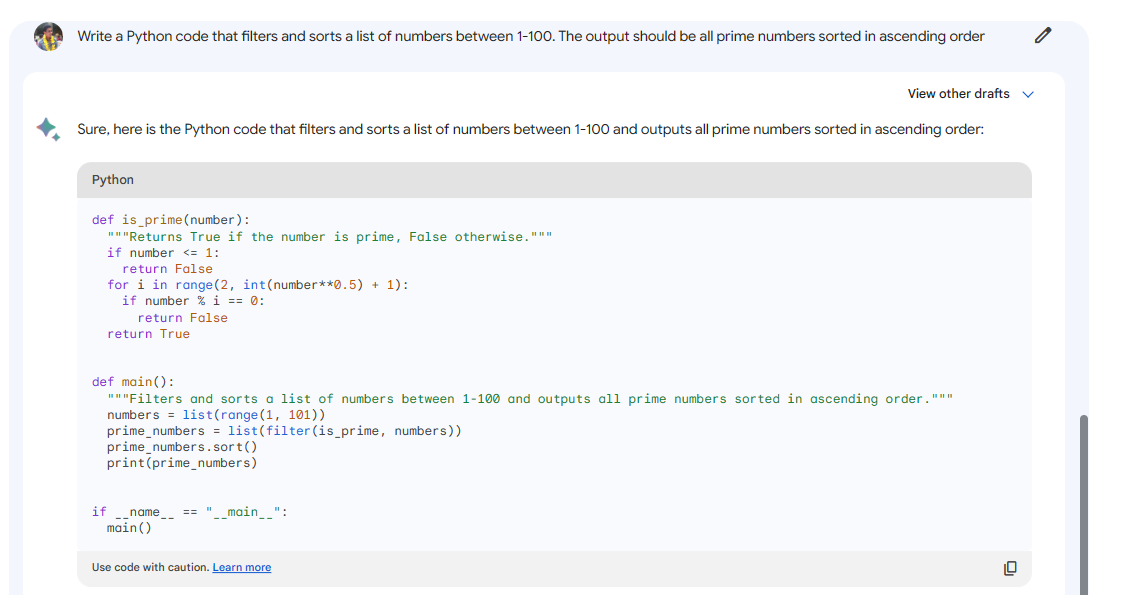
Bard brûkt no ek de kodearringmooglikheden fan PaLM 2 om te helpen by taken foar programmearring en softwareûntwikkeling lykas koadegeneraasje en koadedebuggen.
Duet AI foar Google Workspace
Google is ek fan plan om generative AI-funksjes ta te foegjen oan har Google Workspace-groep fan applikaasjes. Gmail en Docs sille ynkoarten in funksje omfetsje neamd Duet AI dat sil de brûker helpe om har antwurden op te stellen en te skriuwen mei prompts.
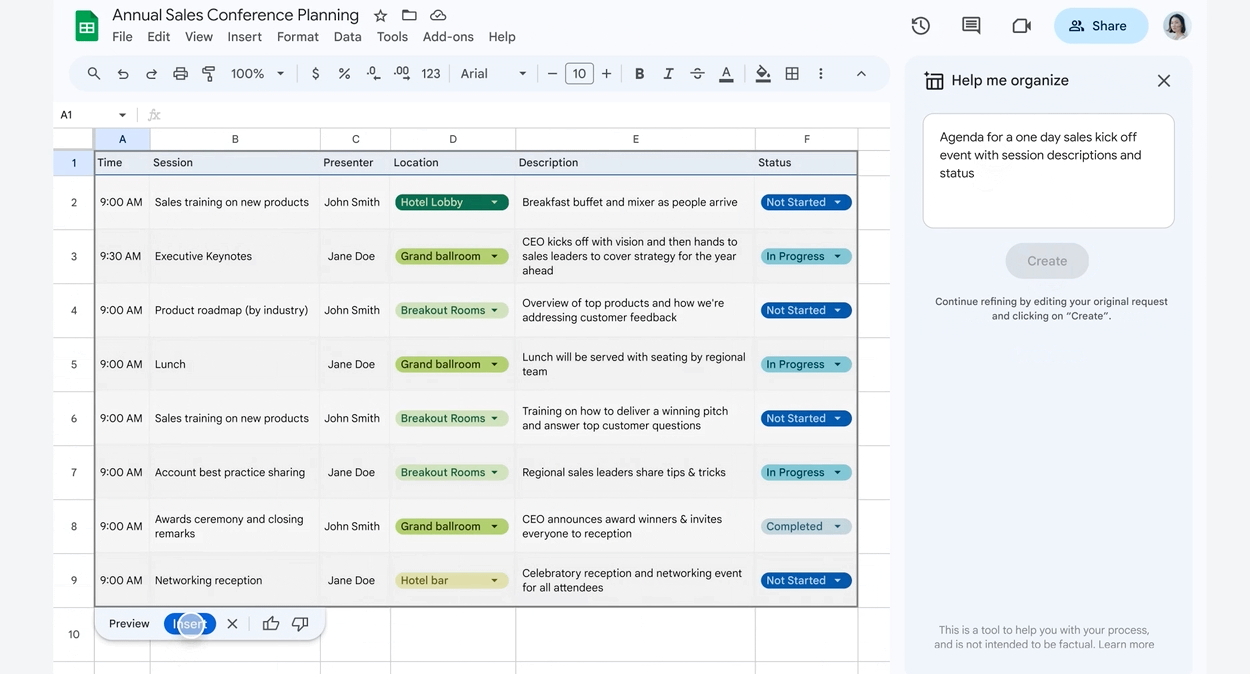
Duet AI sil brûkers ek tastean oanpaste plannen te meitsjen yn Google Sheets foar taken en projekten basearre op prompts jûn troch de brûker.
Konklúzje
Google hopet grif it gat yn 'e merk fan AI-taalark te sluten mei har PaLM 2-taalmodel. Wylst de API's fan it model noch net iepenbier beskikber is, litte de resultaten fan har ûndersyk sjen dat it model kompetitive genôch is om de prestaasjes fan GPT-4 te passen.
Mei de besteande brûkersbasis fan Google hawwe se grif it foardiel fan massive oanpassing as har AI yntegreare wurdt yn har tsjinsten lykas har sykmasjine as har suite fan produktiviteitsark.





Leave a Reply