C'est une tâche cruciale et souhaitable dans la vision et le graphisme par ordinateur de produire des films de portrait créatifs du plus haut calibre.
Bien que plusieurs modèles efficaces de toonification d'images de portrait basés sur le puissant StyleGAN aient été proposés, ces techniques orientées image présentent des inconvénients évidents lorsqu'elles sont utilisées avec des vidéos, telles que la taille d'image fixe, l'exigence d'alignement du visage, l'absence de détails non faciaux. , et incohérence temporelle.
Un cadre révolutionnaire VToonify est utilisé pour s'attaquer au difficile transfert de style vidéo portrait haute résolution contrôlé.
Nous examinerons l'étude la plus récente sur VToonify dans cet article, y compris ses fonctionnalités, ses inconvénients et d'autres facteurs.
Qu'est-ce que Vtoonify ?
Le cadre VToonify permet une transmission de style vidéo portrait haute résolution personnalisable.
VToonify utilise les calques moyenne et haute résolution de StyleGAN pour créer des portraits artistiques de haute qualité basés sur des caractéristiques de contenu à plusieurs échelles récupérées par un encodeur pour conserver les détails du cadre.
L'architecture entièrement convolutive qui en résulte prend en entrée des visages non alignés dans des films de taille variable, ce qui donne des régions de visage entier avec des mouvements réalistes dans la sortie.

Ce cadre est compatible avec les modèles actuels de toonification d'image basés sur StyleGAN, leur permettant d'être étendus à la toonification vidéo, et hérite de caractéristiques attrayantes telles que la personnalisation de la couleur et de l'intensité réglables.
Ce étude présente deux instanciations de VToonify basées sur Toonify et DualStyleGAN pour le transfert de style vidéo portrait basé sur la collection et sur l'exemple, respectivement.
De nombreuses découvertes expérimentales montrent que le cadre VToonify proposé surpasse les approches existantes dans la création de films de portraits artistiques de haute qualité et cohérents dans le temps avec des paramètres de style variables.
Les chercheurs fournissent le Bloc-notes Google Colab, pour que vous puissiez vous salir les mains dessus.
Comment cela fonctionne ?
Pour réaliser un transfert de style vidéo portrait haute résolution ajustable, VToonify combine les avantages du cadre de traduction d'image avec le cadre basé sur StyleGAN.
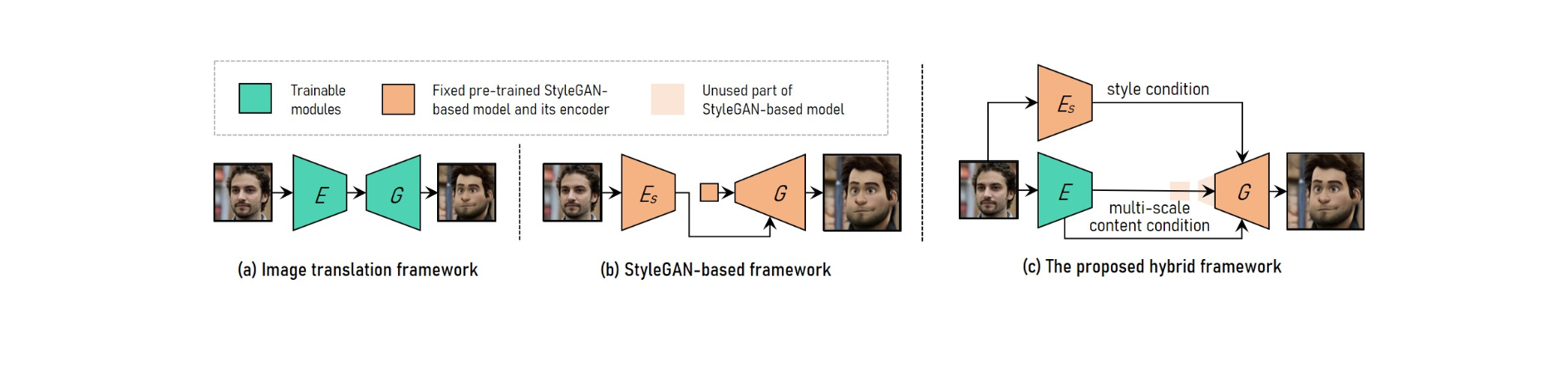
Pour s'adapter à différentes tailles d'entrée, le système de traduction d'images utilise des réseaux entièrement convolutifs. En revanche, l'entraînement à partir de zéro rend impossible la transmission de style haute résolution et contrôlée.
Le modèle StyleGAN pré-formé est utilisé dans le cadre basé sur StyleGAN pour un transfert de style haute résolution et contrôlé, bien qu'il soit limité à une taille d'image fixe et à des pertes de détails.
StyleGAN est modifié dans le cadre hybride en supprimant sa fonction d'entrée de taille fixe et ses couches basse résolution, ce qui donne une architecture de générateur d'encodeur entièrement convolutionnelle similaire à celle du cadre de traduction d'image.
Pour conserver les détails de la trame, formez un encodeur pour extraire les caractéristiques de contenu multi-échelle de la trame d'entrée en tant qu'exigence de contenu supplémentaire pour le générateur. Vtoonify hérite de la flexibilité de contrôle de style du modèle StyleGAN en le mettant dans le générateur pour distiller à la fois ses données et son modèle.
Limites de StyleGAN et Vtoonify proposé
Les portraits artistiques sont courants dans notre vie quotidienne ainsi que dans les entreprises créatives telles que l'art, réseaux sociaux avatars, films, publicités de divertissement, etc.
Avec le développement de l'apprentissage en profondeur technologie, il est désormais possible de créer des portraits artistiques de haute qualité à partir de photos de visage réelles à l'aide du transfert automatisé de style de portrait.
Il existe une variété de moyens réussis créés pour le transfert de style basé sur l'image, dont beaucoup sont facilement accessibles aux utilisateurs débutants sous la forme d'applications mobiles. Le matériel vidéo est rapidement devenu un pilier de nos flux de médias sociaux au cours des dernières années.
L'essor des médias sociaux et des films éphémères a accru la demande de montages vidéo innovants, tels que le transfert de style vidéo portrait, pour générer des vidéos réussies et intéressantes.
Les techniques orientées image existantes présentent des inconvénients importants lorsqu'elles sont appliquées aux films, ce qui limite leur utilité dans la stylisation vidéo de portrait automatisée.
StyleGAN est une colonne vertébrale commune pour le développement d'un modèle de transfert de style d'image de portrait en raison de sa capacité à créer des visages de haute qualité avec une gestion de style ajustable.
Un système basé sur StyleGAN (également connu sous le nom de toonification d'image) encode un vrai visage dans l'espace latent StyleGAN, puis applique le code de style résultant à un autre StyleGAN affiné sur l'ensemble de données de portrait artistique pour créer une version stylisée.
StyleGAN crée des images avec des visages alignés et à une taille fixe, ce qui ne favorise pas les visages dynamiques dans les images du monde réel. Le recadrage et l'alignement du visage dans la vidéo se traduisent parfois par un visage partiel et des gestes maladroits. Les chercheurs appellent ce problème la «restriction des cultures fixes» de StyleGAN.
Pour les faces non alignées, StyleGAN3 a été proposé ; cependant, il ne prend en charge qu'une taille d'image définie.
De plus, une étude récente a découvert que l'encodage des visages non alignés est plus difficile que celui des visages alignés. Un codage de visage incorrect est préjudiciable au transfert de style portrait, entraînant des problèmes tels que l'altération de l'identité et des composants manquants dans les cadres reconstruits et stylisés.
Comme indiqué, une technique efficace de transfert de style vidéo portrait doit gérer les problèmes suivants :
- Pour préserver des mouvements réalistes, l'approche doit pouvoir traiter des visages non alignés et des tailles de vidéo variées. Une grande taille de vidéo ou un grand angle de vue peut capturer plus d'informations tout en empêchant le visage de sortir du cadre.
- Pour rivaliser avec les gadgets HD couramment utilisés aujourd'hui, la vidéo haute résolution est nécessaire.
- Un contrôle de style flexible doit être offert aux utilisateurs pour qu'ils puissent modifier et choisir leur choix lors du développement d'un système d'interaction utilisateur réaliste.
À cette fin, les chercheurs suggèrent VToonify, un nouveau cadre hybride pour la toonification vidéo. Pour surmonter la contrainte de culture fixe, les chercheurs étudient d'abord l'équivariance de traduction dans StyleGAN.
VToonify combine les avantages de l'architecture basée sur StyleGAN et du cadre de traduction d'images pour obtenir un transfert de style vidéo portrait haute résolution réglable.
Voici les principaux apports :
- Les chercheurs étudient la contrainte de recadrage fixe de StyleGAN et proposent une solution basée sur l'équivariance de traduction.
- Les chercheurs présentent un cadre VToonify unique entièrement convolutif pour le transfert contrôlé de style vidéo portrait haute résolution qui prend en charge les visages non alignés et différentes tailles de vidéo.
- Les chercheurs construisent VToonify sur les dorsales de Toonify et DualStyleGAN et condensent les dorsales en termes de données et de modèle pour permettre un transfert de style vidéo portrait basé sur des collections et des exemples.
Comparer Vtoonify avec d'autres modèles de pointe
Toonifier
Il sert de base au transfert de style basé sur la collection sur les faces alignées à l'aide de StyleGAN. Pour récupérer les codes de style, les chercheurs doivent aligner les visages et recadrer 256256 photos pour PSP. Toonify est utilisé pour générer un résultat stylisé avec des codes de style 1024*1024.
Enfin, ils réalignent le résultat dans la vidéo sur son emplacement d'origine. La zone non stylisée a été mise en noir.

DoubleStyleGAN
Il s'agit d'une colonne vertébrale pour le transfert de style basé sur des exemplaires basé sur StyleGAN. Ils utilisent les mêmes techniques de pré- et post-traitement des données que Toonify.
Pix2pixHD
Il s'agit d'un modèle de traduction d'image à image couramment utilisé pour condenser des modèles pré-formés pour une édition haute résolution. Il est formé à l'aide de données appariées.
Les chercheurs utilisent pix2pixHD comme entrées de carte d'instance supplémentaires car il utilise une carte d'analyse extraite.
Motion de premier ordre
FOM est un modèle d'animation d'image typique. Il a été formé sur 256256 images et fonctionne mal avec d'autres tailles d'image. En conséquence, les chercheurs redimensionnent d'abord les images vidéo à 256*256 pour FOM en animation, puis redimensionnent les résultats à leur taille d'origine.
Pour une comparaison équitable, FOM utilise le premier cadre stylisé de son approche comme image de style de référence.
DaGAN
Il s'agit d'un modèle d'animation de visage en 3D. Ils utilisent les mêmes méthodes de préparation et de post-traitement des données que FOM.

Avantages
- Il peut être utilisé dans les arts, les avatars des médias sociaux, les films, la publicité de divertissement, etc.
- Vtoonify peut également être utilisé dans le métaverse.
Limites
- Cette méthodologie extrait à la fois les données et le modèle des dorsales basées sur StyleGAN, ce qui entraîne un biais de données et de modèle.
- Les artefacts sont principalement causés par des différences de taille entre la région du visage stylisé et les autres sections.
- Cette stratégie est moins efficace lorsqu'il s'agit de choses dans la région du visage.
Conclusion
Enfin, VToonify est un cadre pour la toonification vidéo haute résolution contrôlée par le style.
Ce cadre atteint d'excellentes performances dans la gestion des vidéos et permet un large contrôle sur le style structurel, le style de couleur et le degré de style en condensant les modèles de toonification d'image basés sur StyleGAN en termes de leur données synthétiques et des structures de réseau.





Soyez sympa! Laissez un commentaire