Table des matières[Cacher][Montrer]
L'informatique consiste à comprendre la complexité des algorithmes et des structures de données.
Vous avez une liste d'éléments à trier, mais vous n'avez ni le temps ni les ressources pour utiliser un algorithme de tri plus complexe.
Le tri par insertion est l'un des algorithmes de tri les plus simples, mais il peut être lent pour les grandes listes.
La mise en œuvre et la compréhension faciles ont fait de cette méthode un favori parmi les programmeurs. Il est parfait pour les petites listes ou lorsque vous avez besoin d'une solution rapide.
Dans cet article de blog, nous examinerons la complexité temporelle du tri par insertion. Cet algorithme est utilisé pour trier les tableaux, et il a un temps d'exécution de O(n2). Cela signifie que la complexité temporelle augmente avec la taille du tableau.
Cependant, cet algorithme peut souvent être plus rapide que d'autres algorithmes de tri, tels que le tri rapide.
Regardons de plus près comment fonctionne le tri par insertion !
Qu'est-ce que l'algorithme de tri par insertion ?
Un élément à la fois, le tri par insertion génère un tableau triable, souvent appelé liste.
Par exemple, le tri est appliqué dans des programmes informatiques complexes tels que des compilateurs, où l'ordre des jetons est important pour l'interprétation du programme.
Comment fonctionne le tri par insertion ?
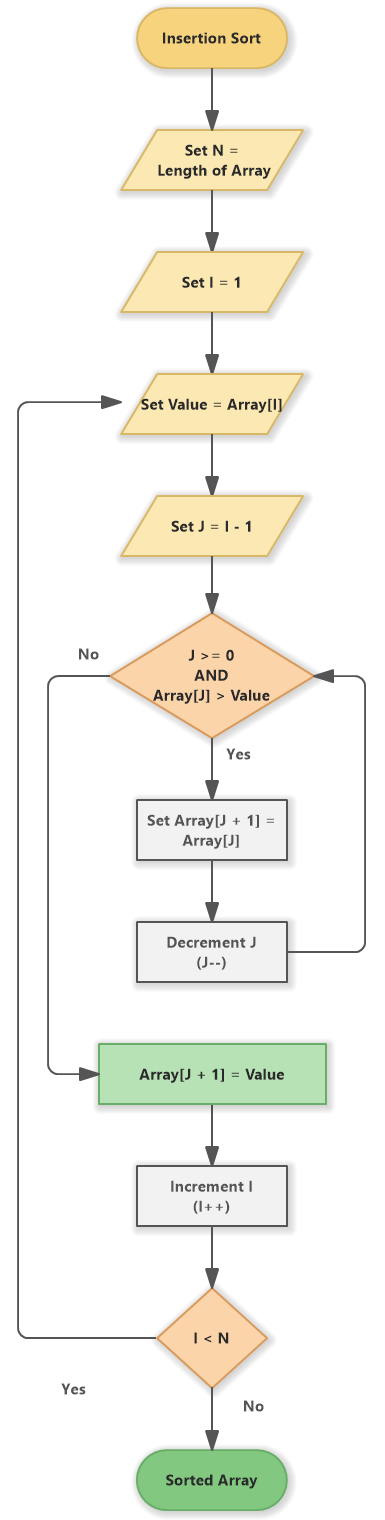
Lorsque nous utilisons le tri par insertion pour trier un tableau, l'algorithme commence par rechercher le plus petit élément de la liste et l'insère à la bonne position.
Il trouve ensuite le plus petit élément suivant et l'insère dans la position correcte, et ainsi de suite.
L'algorithme fonctionne en parcourant la liste en boucle, en comparant chaque élément à celui qui le précède.
Si les éléments sont dans le mauvais ordre, l'algorithme les permute. Il vérifie ensuite si la liste est triée, et si c'est le cas, l'algorithme se termine.
En pratique, le tri par insertion est souvent implémenté en utilisant quelques lignes de code, ce qui en fait un choix populaire pour trier de petits tableaux. Cependant, la complexité temporelle doit être prise en compte lors de l'utilisation de cet algorithme.
Mise en situation :
Voici un exemple du fonctionnement du tri par insertion. Nous utiliserons le tableau suivant :
1, 2, 3, 4, 5, 6
L'algorithme commence par trouver le plus petit élément de la liste, qui est 1. Il l'insère ensuite à la bonne position, la première position. Il trouve ensuite le plus petit élément suivant, qui est 2. Il l'insère dans la position correcte, qui est la deuxième position.
Il trouve ensuite le plus petit élément suivant, qui est 3. Il l'insère dans la position correcte, qui est la troisième position.
Il trouve ensuite le plus petit élément suivant, qui est 4. Il l'insère dans la position correcte, qui est la quatrième position, et ainsi de suite. La liste est maintenant triée !
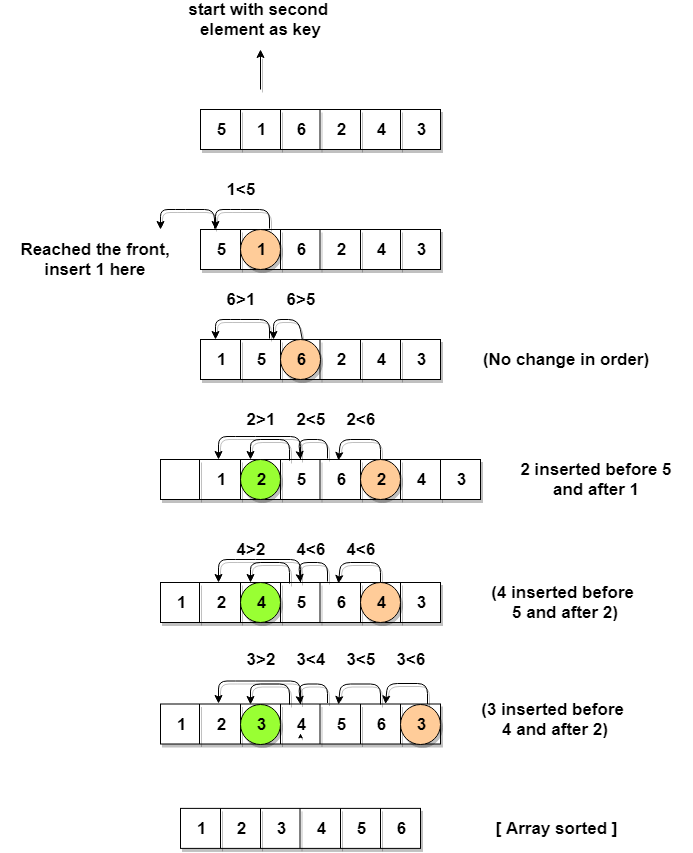
Nous pouvons voir dans l'exemple que l'algorithme prend six comparaisons et permutations pour trier la liste. C'est parce qu'il faut n2 comparaisons et permutations pour trier une liste de n éléments. Dans ce cas, n=6.
Comment améliorer la complexité du temps de tri d'insertion ?
Alors que le tri par insertion a un temps d'exécution de O(n2), il peut être amélioré en utilisant un meilleur algorithme de tri, tel que quicksort.
Quicksort a un temps d'exécution O(n log n), qui est beaucoup plus rapide que O(n2).
Cependant, dans certains cas, le tri par insertion peut être plus rapide que le tri rapide.
Par exemple, si la liste est déjà en ordre, le tri par insertion prendra moins de temps que le tri rapide.
En pratique, le tri par insertion est souvent implémenté en utilisant quelques lignes de code, ce qui en fait un choix populaire pour trier de petits tableaux.
Cependant, la complexité temporelle doit être prise en compte lors de l'utilisation de cet algorithme.
Complexités temporelles
Complexité du pire cas O(n2):
La complexité temporelle augmente avec la taille du tableau. Il faut n2 comparaisons et permutations pour trier une liste de n éléments.
Par exemple, si nous avons un tableau de taille 1000, l'algorithme prendra 1,000,000 XNUMX XNUMX de comparaisons et d'échanges pour trier le tableau.
Complexité du meilleur cas O(n) :
La complexité temporelle est la même que la taille du tableau d'entrée. je
t prend n comparaisons et permutations pour trier une liste de n éléments. Par exemple, considérons un tableau de taille 5. L'algorithme prendra cinq comparaisons et permutations pour trier le tableau.
Complexité moyenne des cas O(n2):
La complexité temporelle se situe entre les complexités des pires et des meilleurs cas dans ce cas.
Il faut n2 comparaisons et permutations pour trier une liste de n éléments.
Ainsi, le tri par insertion est un algorithme de tri stable.
Pourquoi le tri par insertion est-il stable ?
Le tri par insertion est stable car il préserve l'ordre des éléments égaux dans le tableau d'entrée.
Ceci est important pour de nombreuses applications, telles que la récupération de données ou l'analyse financière. Par exemple, si nous avons deux listes de nombres et que nous voulons les comparer, nous devons nous assurer que l'ordre des éléments est préservé.
Si les listes ne sont pas triées, nous ne les comparerons pas avec précision.





Soyez sympa! Laissez un commentaire