Table des matières[Cacher][Montrer]
L'avenir est ici. Et, dans ce futur, les machines comprennent le monde qui les entoure de la même manière que les gens. Les ordinateurs peuvent conduire des automobiles, diagnostiquer des maladies et prévoir l'avenir avec précision.
Cela peut sembler être de la science-fiction, mais les modèles d'apprentissage en profondeur en font une réalité.
Ces algorithmes sophistiqués révèlent les secrets de intelligence artificielle, permettant aux ordinateurs d'auto-apprendre et de se développer. Dans cet article, nous allons nous plonger dans le domaine des modèles d'apprentissage en profondeur.
Et, nous étudierons l'énorme potentiel qu'ils ont pour révolutionner nos vies. Préparez-vous à en apprendre davantage sur la technologie de pointe qui change l'avenir de l'humanité.

Que sont exactement les modèles d'apprentissage en profondeur ?
Avez-vous déjà joué à un jeu dans lequel vous devez identifier les différences entre deux images ?
C'est amusant, mais cela peut aussi être difficile, non ? Imaginez pouvoir apprendre à un ordinateur à jouer à ce jeu et à gagner à chaque fois. Les modèles d'apprentissage en profondeur accomplissent exactement cela !
Les modèles d'apprentissage en profondeur sont similaires à des machines super intelligentes qui peuvent examiner un grand nombre d'images et déterminer ce qu'elles ont en commun. Ils accomplissent cela en désassemblant les images et en étudiant chacune individuellement.
Ils appliquent ensuite ce qu'ils ont appris pour identifier des modèles et faire des prédictions sur de nouvelles images qu'ils n'ont jamais vues auparavant.

Les modèles d'apprentissage en profondeur sont des réseaux de neurones artificiels capables d'apprendre et d'extraire des modèles et des caractéristiques complexes à partir d'ensembles de données volumineux. Ces modèles sont constitués de plusieurs couches de nœuds liés, ou neurones, qui analysent et modifient les données entrantes pour générer une sortie.
Les modèles d'apprentissage en profondeur sont particulièrement bien adaptés aux tâches nécessitant une grande exactitude et précision, telles que l'identification d'images, la reconnaissance vocale, le traitement du langage naturel et la robotique.
Ils ont été utilisés dans tout, des voitures autonomes aux diagnostics médicaux, aux systèmes de recommandation et analyses prédictives.
Voici une version simplifiée de la visualisation pour illustrer le flux de données dans un modèle d'apprentissage en profondeur.
Les données d'entrée circulent dans la couche d'entrée du modèle, qui transmet ensuite les données à travers un certain nombre de couches cachées avant de fournir une prédiction de sortie.
Chaque couche cachée effectue une série d'opérations mathématiques sur les données d'entrée avant de les transmettre à la couche suivante, qui fournit la prédiction finale.
Voyons maintenant quels sont les modèles d'apprentissage en profondeur et comment pouvons-nous les utiliser dans notre vie.
1. Réseaux de neurones convolutionnels (CNN)
Les CNN sont un modèle d'apprentissage en profondeur qui a transformé le domaine de la vision par ordinateur. Les CNN sont utilisés pour classer les images, reconnaître les objets et segmenter les images. La structure et la fonction du cortex visuel humain ont éclairé la conception des CNN.
Comment travaillent-ils?
Un CNN est composé d'un certain nombre de couches convolutives, de couches de regroupement et de couches entièrement liées. L'entrée est une image et la sortie est une prédiction de l'étiquette de classe de l'image.
Les couches convolutives d'un CNN créent une carte de caractéristiques en effectuant un produit scalaire entre l'image d'entrée et un ensemble de filtres. Les couches de regroupement réduisent la taille de la carte d'entités en la sous-échantillonnant.
Enfin, la carte d'entités est utilisée par les couches entièrement connectées pour prédire l'étiquette de classe de l'image.

Pourquoi les CNN sont-ils importants ?
Les CNN sont essentiels car ils peuvent apprendre à détecter des modèles et des caractéristiques dans des images que les gens ont du mal à remarquer. Les CNN peuvent apprendre à reconnaître des caractéristiques telles que les bords, les coins et les textures à l'aide de grands ensembles de données. Après avoir appris ces propriétés, un CNN peut les utiliser pour identifier des objets sur de nouvelles photos. Les CNN ont démontré des performances de pointe sur une variété d'applications d'identification d'images.
Où utilisons-nous les CNN
La santé, l'industrie automobile et la vente au détail ne sont que quelques secteurs qui emploient des CNN. Dans le secteur de la santé, ils peuvent être bénéfiques pour le diagnostic des maladies, le développement de médicaments et l'analyse d'images médicales.
Dans le secteur automobile, ils aident à la détection de voie, détection d'objets, et la conduite autonome. Ils sont également largement utilisés dans le commerce de détail pour la recherche visuelle, la recommandation de produits basée sur des images et le contrôle des stocks.
Par exemple; Google utilise les CNN dans diverses applications, notamment Google Lens, un outil d'identification d'image très apprécié. Le programme utilise les CNN pour évaluer les photographies et donner des informations aux utilisateurs.
Google Lens, par exemple, peut reconnaître des éléments dans une image et fournir des détails à leur sujet, tels que le type de fleur.

Il peut également traduire le texte extrait d'une image en plusieurs langues. Google Lens est en mesure de fournir aux consommateurs des informations utiles grâce à l'assistance de CNN pour identifier avec précision les éléments et extraire les caractéristiques des photos.
2. Réseaux de mémoire longue à court terme (LSTM)
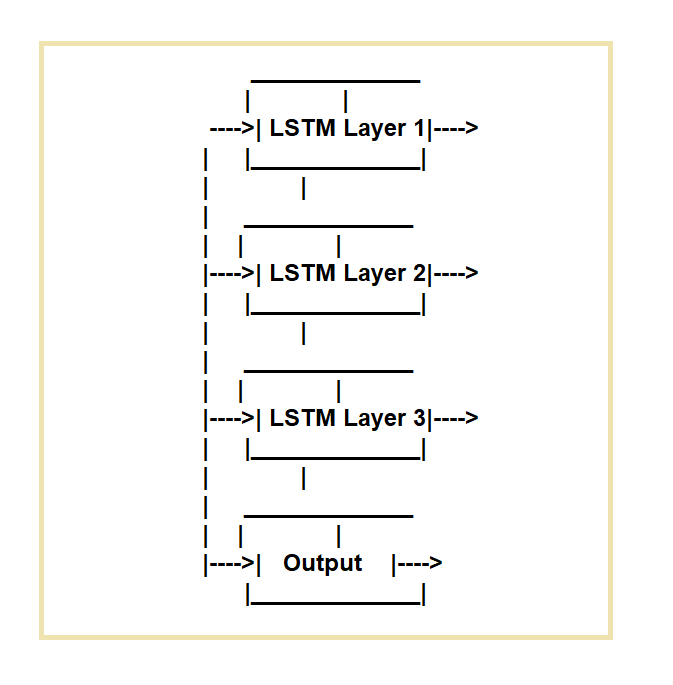
Les réseaux de mémoire longue à court terme (LSTM) sont créés pour combler les lacunes des réseaux de neurones récurrents (RNN) réguliers. Les réseaux LSTM sont idéaux pour les tâches qui exigent le traitement de séquences de données dans le temps.
Ils fonctionnent en utilisant une cellule mémoire spécifique et trois mécanismes de déclenchement.
Ils régulent le flux d'informations entrant et sortant de la cellule. La porte d'entrée, la porte d'oubli et la porte de sortie sont les trois portes.
La porte d'entrée régule le flux de données dans la cellule mémoire, la porte d'oubli régule la suppression de données de la cellule et la porte de sortie régule le flux de données hors de la cellule.
Quelle est leur signification ?
Les réseaux LSTM sont utiles car ils peuvent représenter et prévoir avec succès des séquences de données avec des relations à long terme. Ils peuvent enregistrer et conserver des informations sur les entrées précédentes, ce qui leur permet de faire des prédictions plus précises sur les entrées futures.
La reconnaissance vocale, la reconnaissance de l'écriture manuscrite, le traitement du langage naturel et le sous-titrage d'images ne sont que quelques-unes des applications qui ont utilisé les réseaux LSTM.
Où utilisons-nous les réseaux LSTM ?
De nombreuses applications logicielles et technologiques utilisent des réseaux LSTM, notamment des systèmes de reconnaissance vocale, des outils de traitement des langues naturelles tels que l'analyse des sentiments, les systèmes de traduction automatique et les systèmes de génération de texte et d'image.
Ils ont également été utilisés dans la création de voitures et de robots autonomes, ainsi que dans le secteur financier pour détecter la fraude et anticiper marché boursier mouvements.
3. Réseaux antagonistes génératifs (GAN)
Les GAN sont un l'apprentissage en profondeur technique utilisée pour générer de nouveaux échantillons de données similaires à un ensemble de données donné. Les GAN sont composés de deux les réseaux de neurones: celui qui apprend à produire de nouveaux échantillons et celui qui apprend à faire la distinction entre les échantillons authentiques et générés.
Dans une approche similaire, ces deux réseaux sont formés ensemble jusqu'à ce que le générateur puisse générer des échantillons qui ne se distinguent pas des vrais.
Pourquoi utilisons-nous les GAN
Les GAN sont importants en raison de leur capacité à produire des données synthétiques qui peuvent être utilisés pour une variété d'applications, y compris la production d'images et de vidéos, la génération de texte et même la génération de musique.
Les GAN ont également été utilisés pour l'augmentation des données, qui est la génération de données synthétiques pour compléter les données du monde réel et améliorer les performances des modèles d'apprentissage automatique.
De plus, en créant des données synthétiques pouvant être utilisées pour former des modèles et imiter des essais, les GAN ont le potentiel de transformer des secteurs tels que la médecine et le développement de médicaments.

Applications des GAN
Les GAN peuvent compléter des ensembles de données, créer de nouvelles images ou de nouveaux films, et même générer des données synthétiques pour des simulations scientifiques. De plus, les GAN ont le potentiel d'être utilisés dans une variété d'applications allant du divertissement au médical.
âges et vidéos. Le StyleGAN2 de NVIDIA, par exemple, a été utilisé pour créer des photographies de haute qualité de célébrités et d'œuvres d'art.
4. Réseaux de croyances profondes (DBN)
Les réseaux de croyances profondes (DBN) sont intelligence artificielle des systèmes qui peuvent apprendre à repérer des modèles dans les données. Ils accomplissent cela en segmentant les données en morceaux de plus en plus petits, en acquérant une compréhension plus approfondie à chaque niveau.
Les DBN peuvent apprendre à partir des données sans être informés de ce qu'elles sont (c'est ce qu'on appelle « l'apprentissage non supervisé »). Cela les rend extrêmement utiles pour détecter des modèles dans des données qu'une personne trouverait difficiles ou impossibles à discerner.
Qu'est-ce qui rend les DBN importants ?
Les DBN sont importants en raison de leur capacité à apprendre des représentations de données hiérarchiques. Ces représentations peuvent être utilisées pour une variété d'applications telles que la classification, la détection d'anomalies et la réduction de dimensionnalité.
La capacité des DBN à entreprendre une pré-formation non supervisée, qui peut augmenter les performances des modèles d'apprentissage en profondeur avec un minimum de données étiquetées, est un avantage significatif.

Quelles sont les applications des DBN ?
L'une des applications les plus importantes est détection d'objets, dans lequel les DBN sont utilisés pour reconnaître certains types de choses comme les avions, les oiseaux et les humains. Ils sont également utilisés pour la génération et la classification d'images, la détection de mouvement dans les films et la compréhension du langage naturel pour le traitement de la voix.
De plus, les DBN sont couramment utilisés dans les ensembles de données pour évaluer les postures humaines. Les DBN sont un excellent outil pour une variété d'industries, y compris la santé, la banque et la technologie.
5. Réseaux d'apprentissage par renforcement en profondeur (DRL)
Profond Apprentissage par renforcement Les réseaux (DRL) intègrent des réseaux de neurones profonds avec des techniques d'apprentissage par renforcement pour permettre aux agents d'apprendre dans un environnement compliqué par essais et erreurs.
Les DRL sont utilisés pour enseigner aux agents comment optimiser un signal de récompense en interagissant avec leur environnement et en apprenant de leurs erreurs.
Qu'est-ce qui les rend remarquables ?
Ils ont été utilisés efficacement dans une variété d'applications, y compris les jeux, la robotique et la conduite autonome. Les DRL sont importants car ils peuvent apprendre directement à partir des entrées sensorielles brutes, permettant aux agents de prendre des décisions en fonction de leurs interactions avec l'environnement.
Demandes importantes
Les DRL sont utilisés dans des circonstances réelles car ils peuvent gérer des problèmes difficiles.
Les DRL ont été inclus dans plusieurs plates-formes logicielles et technologiques de premier plan, notamment OpenAI's Gym, Agents ML de Unity, et DeepMind Lab de Google. AlphaGo, construit par Google DeepMind, par exemple, utilise DRL pour jouer au jeu de société Go à un niveau de champion du monde.

Une autre utilisation du DRL est la robotique, où il est utilisé pour contrôler les mouvements des bras robotiques pour exécuter des tâches telles que saisir des objets ou empiler des blocs. Les DRL ont de nombreuses utilisations et sont un outil utile pour former des agents à apprendre et prendre des décisions dans des contextes complexes.
6. Auto-encodeurs
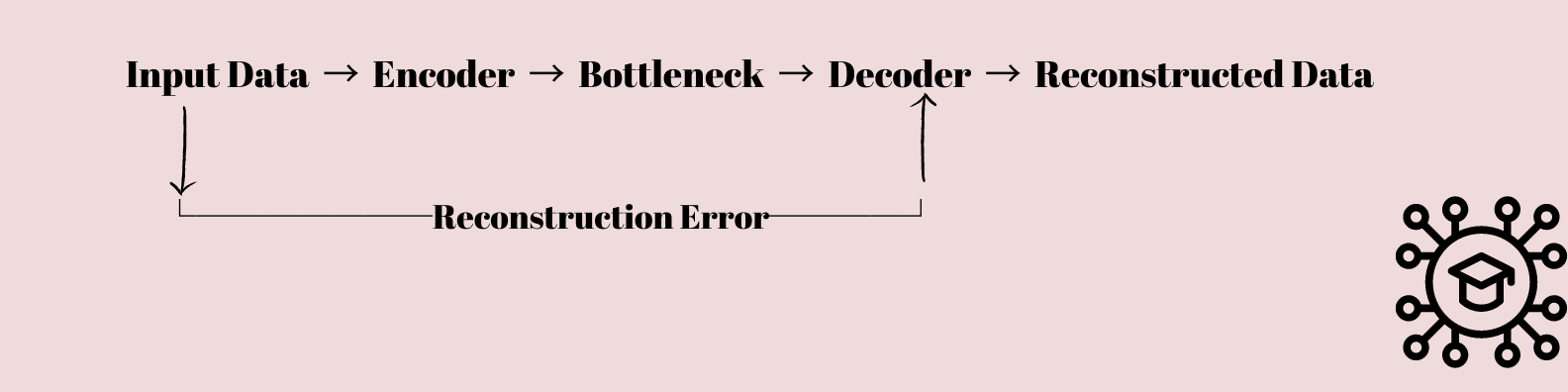
Les auto-encodeurs sont un type intéressant de Réseau neuronal qui a suscité l'intérêt des chercheurs et des scientifiques des données. Ils sont fondamentalement conçus pour apprendre à compresser et à restaurer des données.
Les données d'entrée sont alimentées à travers une succession de couches qui réduisent progressivement la dimensionnalité des données jusqu'à ce qu'elles soient compressées dans une couche de goulot d'étranglement avec moins de nœuds que les couches d'entrée et de sortie.
Cette représentation compressée est ensuite utilisée pour recréer les données d'entrée d'origine à l'aide d'une séquence de couches qui ramènent progressivement la dimensionnalité des données à sa forme d'origine.
Pourquoi c'est important?
Les encodeurs automatiques sont un composant crucial de l'apprentissage en profondeur car ils rendent possible l'extraction de caractéristiques et la réduction de données.
Ils sont capables d'identifier les éléments clés des données entrantes et de les traduire sous une forme compressée qui peut ensuite être appliquée à d'autres tâches telles que la classification, le regroupement ou la création de nouvelles données.
Où utilisons-nous les auto-encodeurs ?
Détection d'anomalies, traitement du langage naturel et vision par ordinateur ne sont que quelques-unes des disciplines où les auto-encodeurs sont utilisés. Les auto-encodeurs, par exemple, peuvent être utilisés pour la compression d'images, le débruitage d'images et la synthèse d'images en vision par ordinateur.
Nous pouvons utiliser les auto-encodeurs dans des tâches telles que la création de texte, la catégorisation de texte et la synthèse de texte dans le traitement du langage naturel. Il peut identifier une activité anormale dans les données qui s'écarte de la norme dans l'identification des anomalies.
7. Réseaux de capsules
Capsule Networks est une nouvelle architecture d'apprentissage en profondeur qui a été développée pour remplacer les réseaux de neurones convolutifs (CNN).
Les réseaux de capsules sont basés sur la notion de regroupement d'unités cérébrales appelées capsules qui sont chargées de reconnaître l'existence d'un certain élément dans une image et d'encoder ses attributs, tels que l'orientation et la position, dans leurs vecteurs de sortie. Les Capsule Networks peuvent donc mieux gérer les interactions spatiales et les fluctuations de perspective que les CNN.
Pourquoi choisissons-nous Capsule Networks plutôt que CNN ?
Les réseaux de capsules sont utiles car ils surmontent les difficultés de CNN à capturer les relations hiérarchiques entre les éléments d'une image. Les CNN peuvent reconnaître des objets de différentes tailles, mais ont du mal à comprendre comment ces éléments se connectent les uns aux autres.
Capsule Networks, d'autre part, peut apprendre à reconnaître les choses et leurs pièces, ainsi que la façon dont elles sont placées dans l'espace dans une image, ce qui en fait un concurrent viable pour les applications de vision par ordinateur.
Domaines d'application
Capsule Networks a déjà démontré des résultats prometteurs dans une variété d'applications, y compris la classification d'images, l'identification d'objets et la segmentation d'images.
Ils ont été utilisés pour distinguer des éléments sur des photos médicales, reconnaître des personnes dans des films et même créer des modèles 3D à partir d'images 2D.
Pour augmenter leurs performances, les Capsule Networks ont été combinés avec d'autres architectures d'apprentissage en profondeur telles que les réseaux antagonistes génératifs (GAN) et les auto-encodeurs variationnels (VAE). Les réseaux capsule devraient jouer un rôle de plus en plus vital dans l'amélioration des technologies de vision par ordinateur à mesure que la science de l'apprentissage en profondeur évolue.
Par exemple; Nibabel est un outil Python bien connu pour lire et écrire des types de fichiers de neuroimagerie. Pour la segmentation des images, il utilise Capsule Networks.
8. Modèles basés sur l'attention
Les modèles d'apprentissage en profondeur connus sous le nom de modèles basés sur l'attention, également appelés mécanismes d'attention, s'efforcent d'augmenter la précision de modèles d'apprentissage automatique. Ces modèles fonctionnent en se concentrant sur certaines caractéristiques des données entrantes, ce qui se traduit par un traitement plus efficace et efficient.
Dans les tâches de traitement du langage naturel telles que la traduction automatique et l'analyse des sentiments, les méthodes d'attention se sont avérées assez efficaces.
Quelle est leur signification?
Les modèles basés sur l'attention sont utiles car ils permettent un traitement plus efficace et efficient de données complexes.
Réseaux de neurones traditionnels évaluer toutes les données d'entrée comme étant d'égale importance, ce qui entraîne un traitement plus lent et une précision réduite. Les processus d'attention se concentrent sur des aspects cruciaux des données d'entrée, permettant des prédictions plus rapides et plus précises.

Zones d'utilisation
Dans le domaine de l'intelligence artificielle, les mécanismes d'attention ont un large éventail d'applications, y compris le traitement du langage naturel, la reconnaissance d'images et de sons, et même les véhicules sans conducteur.
Les méthodes d'attention, par exemple, peuvent être utilisées pour améliorer la traduction automatique dans le traitement du langage naturel en permettant au système de se concentrer sur certains mots ou expressions essentiels au contexte.
Les méthodes d'attention dans les voitures autonomes peuvent être utilisées pour aider le système à se concentrer sur certains éléments ou défis dans son environnement.
9. Réseaux de transformateurs
Les réseaux de transformateurs sont des modèles d'apprentissage en profondeur qui examinent et produisent des séquences de données. Ils fonctionnent en traitant la séquence d'entrée un élément à la fois et en produisant une séquence de sortie de longueurs identiques ou différentes.
Les réseaux de transformateurs, contrairement aux modèles séquence à séquence standard, ne traitent pas les séquences à l'aide de réseaux de neurones récurrents (RNN). Au lieu de cela, ils utilisent des processus d'auto-attention pour apprendre les liens entre les morceaux de la séquence.
Quelle est l'importance des réseaux de transformateurs ?
Les réseaux de transformateurs ont gagné en popularité ces dernières années en raison de leurs meilleures performances dans les travaux de traitement du langage naturel.
Ils sont particulièrement bien adaptés aux tâches de création de texte telles que la traduction, la synthèse de texte et la production de conversations.
Les réseaux de transformateurs sont beaucoup plus efficaces en termes de calcul que les modèles basés sur RNN, ce qui en fait un choix privilégié pour les applications à grande échelle.

Où pouvez-vous trouver des réseaux de transformateur ?
Les réseaux de transformateurs sont largement utilisés dans un large éventail d'applications, notamment le traitement du langage naturel.
La série GPT (Generative Pre-trained Transformer) est un modèle de premier plan basé sur un transformateur qui a été utilisé pour des tâches telles que la traduction linguistique, la synthèse de texte et la génération de chatbot.
BERT (Représentations d'encodeurs bidirectionnels de transformateurs) est un autre modèle commun basé sur les transformateurs qui a été utilisé pour les applications de compréhension du langage naturel telles que la réponse aux questions et l'analyse des sentiments.
Les deux GPT et BERT ont été créés avec PyTorch, un cadre d'apprentissage en profondeur open source qui a été populaire pour développer des modèles basés sur des transformateurs.
10. Machines Boltzmann restreintes (RBM)
Les machines de Boltzmann restreintes (RBM) sont une sorte de réseau neuronal non supervisé qui apprend de manière générative. En raison de leur capacité à apprendre et à extraire des caractéristiques essentielles à partir de données de grande dimension, ils ont été largement utilisés dans les domaines de l'apprentissage automatique et de l'apprentissage en profondeur.
Les RBM sont constitués de deux couches, visible et cachée, chaque couche étant constituée d'un groupe de neurones reliés par des bords pondérés. Les RBM sont conçus pour apprendre une distribution de probabilité qui décrit les données d'entrée.
Que sont les machines Boltzmann restreintes ?
Les RBM utilisent une stratégie d'apprentissage génératif. Dans les RBM, la couche visible reflète les données d'entrée, tandis que la couche enterrée encode les caractéristiques des données d'entrée. Les poids des couches visibles et cachées montrent la force de leur lien.
Les RBM ajustent les poids et les biais entre les couches pendant l'entraînement en utilisant une technique connue sous le nom de divergence contrastive. La divergence contrastive est une stratégie d'apprentissage non supervisée qui maximise la probabilité de prédiction du modèle.
Quelle est la signification des machines Boltzmann restreintes ?
Les RBM sont importants dans machine learning et l'apprentissage en profondeur, car ils peuvent apprendre et extraire des caractéristiques pertinentes à partir de grandes quantités de données.
Ils sont très efficaces pour la reconnaissance d'images et de la parole, et ils ont été utilisés dans une variété d'applications telles que les systèmes de recommandation, la détection d'anomalies et la réduction de la dimensionnalité. Les RBM peuvent trouver des modèles dans de vastes ensembles de données, ce qui se traduit par des prévisions et des informations supérieures.

Où les machines Boltzmann restreintes peuvent-elles être utilisées ?
Les applications des RBM incluent la réduction de la dimensionnalité, la détection des anomalies et les systèmes de recommandation. Les RBM sont particulièrement utiles pour l'analyse des sentiments et modélisation de sujet dans le cadre du traitement du langage naturel.
Les réseaux de croyances profondes, une sorte de réseau neuronal utilisé pour la reconnaissance de la voix et de l'image, utilisent également des RBM. La boîte à outils du réseau Deep Belief, TensorFlowet Theano sont quelques exemples particuliers de logiciels ou de technologies qui utilisent les RBM.
Emballer
Les modèles d'apprentissage en profondeur deviennent de plus en plus cruciaux dans une variété d'industries, y compris la reconnaissance vocale, le traitement du langage naturel et la vision par ordinateur.
Les réseaux de neurones convolutifs (CNN) et les réseaux de neurones récurrents (RNN) se sont révélés les plus prometteurs et sont largement utilisés dans de nombreuses applications, cependant, tous les modèles d'apprentissage en profondeur ont leurs avantages et leurs inconvénients.
Cependant, les chercheurs étudient toujours les machines Boltzmann restreintes (RBM) et d'autres variétés de modèles d'apprentissage en profondeur, car elles présentent également des avantages particuliers.
De nouveaux modèles créatifs devraient être créés à mesure que le domaine de l'apprentissage en profondeur continue de progresser afin de gérer des problèmes plus difficiles





Soyez sympa! Laissez un commentaire