Et si nous pouvions utiliser l'intelligence artificielle pour répondre à l'un des plus grands mystères de la vie : le repliement des protéines ? Les scientifiques y travaillent depuis des décennies.
Les machines peuvent désormais prédire les structures des protéines avec une précision étonnante à l'aide de modèles d'apprentissage en profondeur, modifiant le développement de médicaments, la biotechnologie et notre connaissance des processus biologiques fondamentaux.
Rejoignez-moi pour une exploration dans le domaine fascinant du repliement des protéines de l'IA, où la technologie de pointe se heurte à la complexité de la vie elle-même.
Percer le mystère du repliement des protéines
Les protéines fonctionnent dans notre corps comme de petites machines pour effectuer des tâches cruciales comme la décomposition des aliments ou le transport de l'oxygène. Ils doivent être pliés correctement pour qu'ils fonctionnent efficacement, tout comme une clé doit être coupée correctement pour s'insérer dans une serrure. Dès que la protéine est créée, un processus de pliage très compliqué commence.
Le repliement des protéines est le processus par lequel de longues chaînes d'acides aminés, les éléments constitutifs de la protéine, se replient en structures tridimensionnelles qui dictent la fonction de la protéine.
Considérez une longue chaîne de perles qui doit être ordonnée sous une forme précise ; c'est ce qui se produit lorsqu'une protéine se replie. Pourtant, contrairement aux billes, les acides aminés ont des caractéristiques uniques et interagissent les uns avec les autres de diverses manières, faisant du repliement des protéines un processus complexe et sensible.
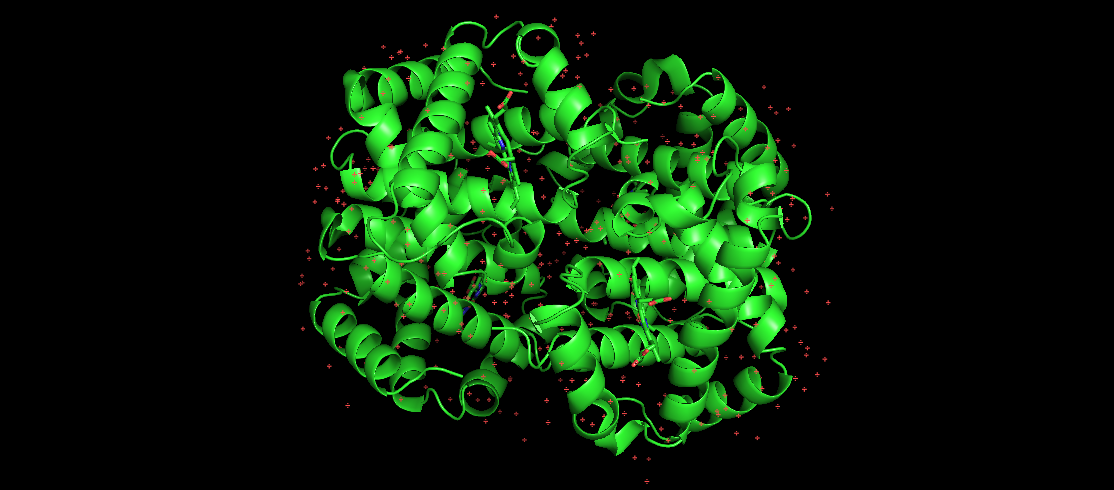
L'image ici représente l'hémoglobine humaine, qui est une protéine pliée bien connue
Les protéines doivent se replier rapidement et précisément, sinon elles deviendront mal repliées et défectueuses. Cela pourrait entraîner des maladies telles que la maladie d'Alzheimer et la maladie de Parkinson. La température, la pression et la présence d'autres molécules dans la cellule ont toutes un effet sur le processus de repliement.
Après des décennies de recherche, les scientifiques essaient toujours de comprendre exactement comment les protéines se replient.
Heureusement, les progrès de l'intelligence artificielle améliorent le développement du secteur. Les scientifiques peuvent anticiper la structure des protéines avec plus de précision que jamais en utilisant algorithmes d'apprentissage automatique pour examiner d'énormes volumes de données.
Cela a le potentiel de changer le développement des médicaments et d'augmenter notre connaissance moléculaire de la maladie.
Les machines peuvent-elles être plus performantes ?
Les techniques conventionnelles de repliement des protéines ont des limites
Les scientifiques essaient de comprendre le repliement des protéines depuis des décennies, mais la complexité du processus en a fait un sujet difficile.
Les approches conventionnelles de prédiction de la structure des protéines utilisent une combinaison de méthodologies expérimentales et de modélisation informatique, cependant, ces méthodes présentent toutes des inconvénients.
Les techniques expérimentales telles que la cristallographie aux rayons X et la résonance magnétique nucléaire (RMN) peuvent être longues et coûteuses. De plus, les modèles informatiques reposent parfois sur des hypothèses simples, ce qui peut conduire à des prédictions erronées.
L'IA peut surmonter ces obstacles
Heureusement, intelligence artificielle offre de nouvelles promesses pour une prédiction plus précise et plus efficace de la structure des protéines. Les algorithmes d'apprentissage automatique peuvent examiner d'énormes volumes de données. Et, ils découvrent des modèles que les gens manqueraient.
Cela a abouti à la création de nouveaux outils logiciels et plates-formes capables de prédire la structure des protéines avec une précision inégalée.
Les algorithmes d'apprentissage automatique les plus prometteurs pour la prédiction de la structure des protéines
Le système AlphaFold construit par Google DeepMind est l'une des avancées les plus prometteuses dans ce domaine. Il a fait de grands progrès ces dernières années en utilisant algorithmes d'apprentissage en profondeur pour prédire la structure des protéines en fonction de leurs séquences d'acides aminés.
Les réseaux de neurones, les machines à vecteurs de support et les forêts aléatoires font partie des méthodes d'apprentissage automatique les plus prometteuses pour prédire la structure des protéines.
Ces algorithmes peuvent apprendre à partir d'énormes ensembles de données. Et, ils peuvent anticiper les corrélations entre les différents acides aminés. Alors, voyons comment cela fonctionne.

Analyses co-évolutives et la première génération AlphaFold
Le succès de la AlphaFold est construit sur un modèle de réseau neuronal profond qui a été développé à l'aide d'une analyse co-évolutive. Le concept de co-évolution stipule que si deux acides aminés d'une protéine interagissent l'un avec l'autre, ils se développeront ensemble pour conserver leur lien fonctionnel.
Les chercheurs peuvent détecter quelles paires d'acides aminés sont susceptibles d'être en contact dans la structure 3D en comparant les séquences d'acides aminés de nombreuses protéines similaires.
Ces données servent de base à la première itération d'AlphaFold. Il prédit les longueurs entre les paires d'acides aminés ainsi que les angles des liaisons peptidiques qui les relient. Cette méthode a surpassé toutes les approches antérieures pour prédire la structure des protéines à partir de la séquence, bien que la précision soit encore limitée pour les protéines sans modèles apparents.

AlphaFold 2 : une méthodologie radicalement nouvelle
AlphaFold2 est un logiciel informatique créé par DeepMind qui utilise la séquence d'acides aminés d'une protéine pour prédire la structure 3D de la protéine.
Ceci est important car la structure d'une protéine dicte son fonctionnement, et comprendre sa fonction peut aider les scientifiques à développer des médicaments qui ciblent la protéine.
Le réseau neuronal AlphaFold2 reçoit en entrée la séquence d'acides aminés de la protéine ainsi que des détails sur la façon dont cette séquence se compare à d'autres séquences dans une base de données (c'est ce qu'on appelle un «alignement de séquence»).
Le réseau neuronal fait une prédiction sur la structure 3D de la protéine sur la base de cette entrée.
Qu'est-ce qui le distingue d'AlphaFold2 ?
Contrairement à d'autres approches, AlphaFold2 prédit la structure 3D réelle de la protéine plutôt que simplement la séparation entre les paires d'acides aminés ou les angles entre les liaisons les reliant (comme le faisaient les algorithmes antérieurs).
Pour que le réseau de neurones anticipe immédiatement la structure complète, la structure est codée de bout en bout.
Une autre caractéristique clé d'AlphaFold2 est qu'il offre une estimation de sa confiance dans ses prévisions. Ceci est présenté sous la forme d'un code couleur sur la structure anticipée, le rouge représentant une confiance élevée et le bleu suggérant une faible confiance.
Ceci est utile car il informe les scientifiques sur la stabilité de la prédiction.
Prédire la structure combinée de plusieurs séquences
La dernière extension d'Alphafold2, connue sous le nom d'Alphafold Multimer, prévoit la structure combinée de plusieurs séquences. Il a toujours des taux d'erreur élevés même s'il fonctionne bien mieux que les techniques précédentes. Seulement 25% des 4500 complexes protéiques ont été prédits avec succès.
70% des régions rugueuses de formation de contact ont été correctement prédites, mais l'orientation relative des deux protéines était incorrecte. Lorsque la profondeur d'alignement médiane est inférieure à environ 30 séquences, la précision des prédictions des multimères Alphafold diminue considérablement.
Comment utiliser les prédictions Alphafold
Les modèles prédits d'AlphaFold sont proposés dans les mêmes formats de fichiers et peuvent être utilisés de la même manière que les structures expérimentales. Il est crucial de prendre en compte les estimations de précision proposées avec le modèle afin d'éviter les malentendus.
Il est particulièrement utile pour les structures compliquées telles que les homomères entrelacés ou les protéines qui ne se replient qu'en présence d'un
ligand inconnu.
Quelques défis
Le principal problème lié à l'utilisation de structures prédites est de comprendre la dynamique, la sélectivité des ligands, le contrôle, l'allosterie, les changements post-traductionnels et la cinétique de liaison sans accès aux protéines et aux données biophysiques.
Apprentissage automatique et la recherche sur la dynamique moléculaire basée sur la physique peut être utilisée pour surmonter ce problème.
Ces enquêtes peuvent bénéficier d'une architecture informatique spécialisée et efficace. Bien qu'AlphaFold ait réalisé d'énormes progrès dans la prédiction des structures protéiques, il reste encore beaucoup à apprendre dans le domaine de la biologie structurale, et les prédictions d'AlphaFold ne sont que le point de départ d'études futures.
Quels sont les autres outils remarquables ?
RoseTTAFold
RoseTTAFold, créé par les chercheurs de l'Université de Washington, utilise également des algorithmes d'apprentissage en profondeur pour prédire les structures des protéines, mais il intègre également une nouvelle approche connue sous le nom de "simulations de la dynamique de l'angle de torsion" pour améliorer les structures prédites.
Cette méthode a donné des résultats encourageants et peut être utile pour surmonter les limites des outils de repliement de protéines AI existants.
trRosetta
Un autre outil, trRosetta, prédit le repliement des protéines en utilisant un Réseau neuronal formés sur des millions de séquences et de structures protéiques.
Il utilise également une technique de « modélisation basée sur des modèles » pour créer des prédictions plus précises en comparant la protéine cible à des structures connues comparables.
Il a été démontré que trRosetta est capable de prédire les structures de minuscules protéines et complexes protéiques.
DeepMetaPSICOV
DeepMetaPSICOV est un autre outil qui se concentre sur la prédiction des cartes de contact des protéines. Ceux-ci sont utilisés comme guide pour prédire le repliement des protéines. Il utilise l'apprentissage en profondeur approches pour prévoir la probabilité d'interactions de résidus à l'intérieur d'une protéine.
Ceux-ci sont ensuite utilisés pour prévoir la carte de contact globale. DeepMetaPSICOV a montré un potentiel dans la prédiction des structures protéiques avec une grande précision, même lorsque les approches précédentes ont échoué.
Que réserve l'avenir?
L'avenir du repliement des protéines d'IA est prometteur. Les algorithmes basés sur l'apprentissage en profondeur, notamment AlphaFold2, ont récemment fait de grands progrès dans la prédiction fiable des structures protéiques.
Cette découverte a le potentiel de transformer le développement de médicaments en permettant aux scientifiques de mieux comprendre la structure et la fonction des protéines, qui sont des cibles thérapeutiques courantes.
Néanmoins, des problèmes tels que la prévision des complexes protéiques et la détection du statut fonctionnel réel des structures anticipées demeurent. Des recherches supplémentaires sont nécessaires pour résoudre ces problèmes et augmenter la précision et la fiabilité des algorithmes de repliement des protéines de l'IA.
Pourtant, les avantages potentiels de cette technologie sont énormes, et elle a le potentiel de conduire à la production de médicaments plus efficaces et plus précis.





Soyez sympa! Laissez un commentaire