Sisällysluettelo[Piilottaa][Näytä]
Tietojenkäsittelytieteessä on kyse algoritmien ja tietorakenteiden monimutkaisuuden ymmärtämisestä.
Sinulla on luettelo kohteista, jotka on lajiteltava, mutta sinulla ei ole aikaa tai resursseja käyttää monimutkaisempaa lajittelualgoritmia.
Lisäyslajittelu on yksi yksinkertaisimmista lajittelualgoritmeista, mutta se voi olla hidasta suurilla listoilla.
Helppo käyttöönotto ja ymmärtäminen ovat tehneet tästä menetelmästä ohjelmoijien suosikin. Se on täydellinen pienille listoille tai kun tarvitset nopean ratkaisun.
Tässä blogiviestissä tarkastelemme lisäyslajittelun aikaista monimutkaisuutta. Tätä algoritmia käytetään taulukoiden lajitteluun, ja sen suoritusaika on O(n2). Tämä tarkoittaa, että aika monimutkaisuus kasvaa taulukon koon mukaan.
Tämä algoritmi voi kuitenkin olla nopeampi usein kuin muut lajittelualgoritmit, kuten pikalajittelu.
Katsotaanpa tarkemmin, miten lisäyslajittelu toimii!
Mikä on lisäyslajittelualgoritmi?
Elementti kerrallaan lisäyslajittelu luo lajiteltavan taulukon, jota usein kutsutaan luetteloksi.
Lajittelua käytetään esimerkiksi monimutkaisissa tietokoneohjelmissa, kuten kääntäjissä, joissa merkkien järjestys on tärkeä ohjelman tulkinnan kannalta.
Kuinka lisäyslajittelu toimii?
Kun käytämme lisäyslajittelua taulukon lajitteluun, algoritmi alkaa etsimällä luettelon pienin kohde ja lisäämällä se oikeaan paikkaan.
Sitten se löytää seuraavaksi pienimmän kohteen ja lisää sen oikeaan kohtaan ja niin edelleen.
Algoritmi toimii silmukalla luettelon läpi ja vertaamalla jokaista kohdetta sitä edeltävään.
Jos kohteet ovat väärässä järjestyksessä, algoritmi vaihtaa ne. Sitten se tarkistaa, onko luettelo lajiteltu, ja jos on, algoritmi päättyy.
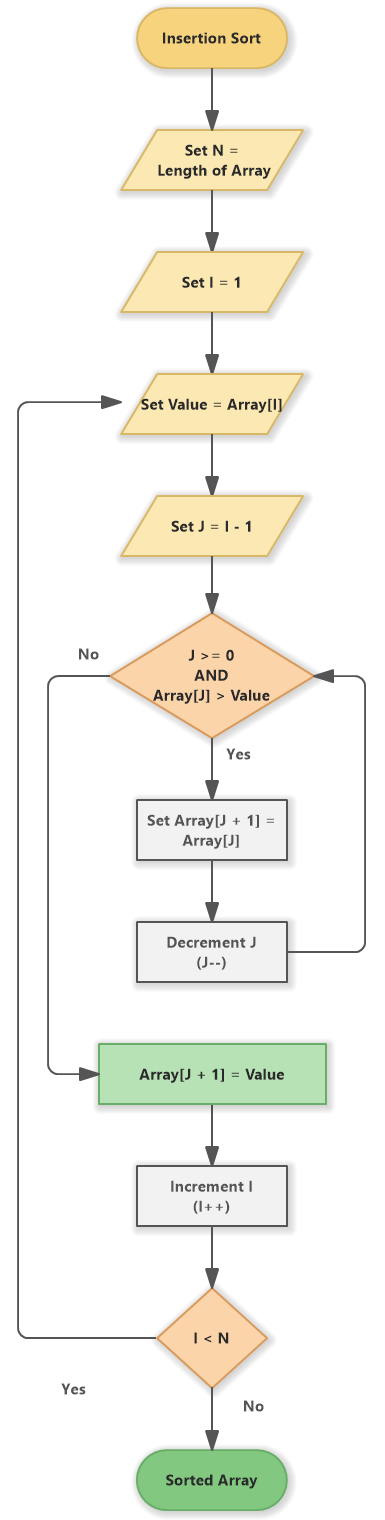
Käytännössä lisäyslajittelu toteutetaan usein käyttämällä muutaman rivin koodia, joten se on suosittu valinta pienten taulukoiden lajittelussa. Aika monimutkaisuus on kuitenkin otettava huomioon käytettäessä tätä algoritmia.
Esimerkiksi:
Tässä on esimerkki lisäyslajittelun toiminnasta. Käytämme seuraavaa taulukkoa:
1, 2, 3, 4, 5, 6
Algoritmi aloittaa etsimällä luettelon pienimmän kohteen, joka on 1. Sitten se lisää sen oikeaan kohtaan, ensimmäiseen kohtaan. Sitten se löytää seuraavaksi pienimmän kohteen, joka on 2. Se lisää sen oikeaan kohtaan, joka on toinen paikka.
Sitten se löytää seuraavaksi pienimmän kohteen, joka on 3. Se lisää sen oikeaan kohtaan, joka on kolmantena.
Sitten se löytää seuraavaksi pienimmän kohteen, joka on 4. Se lisää sen oikeaan kohtaan, joka on neljäs paikka ja niin edelleen. Lista on nyt järjestetty!
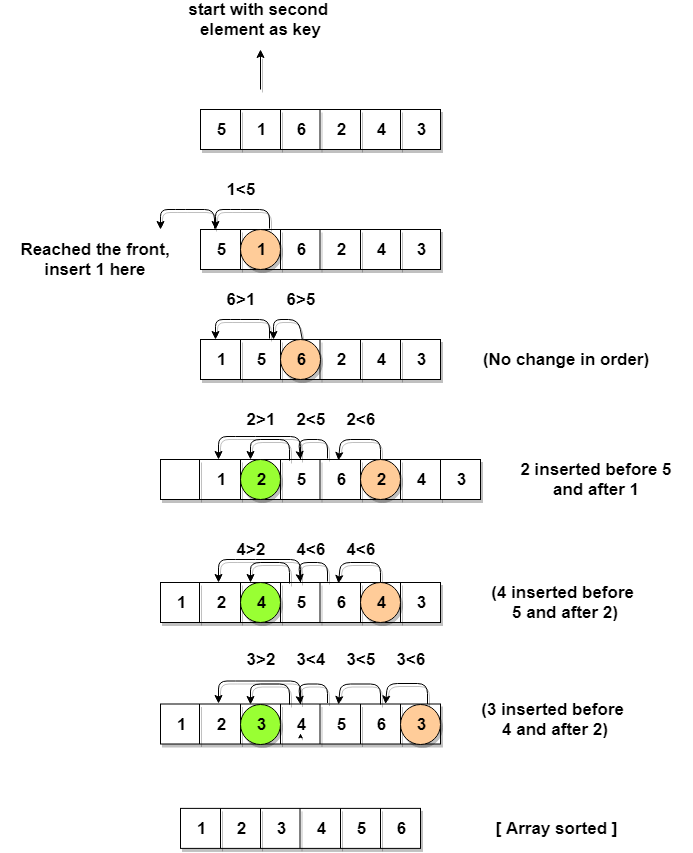
Näemme esimerkistä, että algoritmi lajittelee luettelon kuusi vertailua ja vaihtoa. Tämä johtuu siitä, että se kestää n2 vertailuja ja vaihtoja n kohteen luettelon lajittelemiseksi. Tässä tapauksessa n = 6.
Kuinka parantaa lisäyslajitteluajan monimutkaisuutta?
Vaikka lisäyslajittelun suoritusaika on O(n2), sitä voidaan parantaa käyttämällä parempaa lajittelualgoritmia, kuten pikalajittelua.
Quicksortilla on O(n log n) -ajoaika, joka on paljon nopeampi kuin O(n).2).
Joissakin tapauksissa lisäyslajittelu voi kuitenkin olla nopeampaa kuin pikalajittelu.
Jos esimerkiksi luettelo on jo järjestyksessä, lisäyslajittelu vie vähemmän aikaa kuin pikalajittelu.
Käytännössä lisäyslajittelu toteutetaan usein käyttämällä muutaman rivin koodia, joten se on suosittu valinta pienten taulukoiden lajittelussa.
Aika monimutkaisuus on kuitenkin otettava huomioon käytettäessä tätä algoritmia.
Aika monimutkaisuus
Huonoin tapauksen monimutkaisuus O(n2):
Aika monimutkaisuus kasvaa taulukon koon mukaan. Se kestää n2 vertailuja ja vaihtoja n kohteen luettelon lajittelemiseksi.
Jos meillä on esimerkiksi taulukko, jonka koko on 1000, algoritmi ottaa 1,000,000 XNUMX XNUMX vertailua ja vaihtoa taulukon lajittelemiseksi.
Paras tapauksen monimutkaisuus O(n):
Aika monimutkaisuus on sama kuin syötetaulukon koko. minä
t vaatii n vertailua ja vaihtoa n kohteen luettelon lajittelemiseksi. Tarkastellaan esimerkiksi taulukkoa, jonka koko on 5. Algoritmi ottaa viisi vertailua ja vaihtoa taulukon lajittelemiseksi.
Keskimääräinen tapauksen monimutkaisuus O(n2):
Aika monimutkaisuus on tässä tapauksessa pahimman ja parhaan tapauksen monimutkaisuuden välissä.
Se kestää n2 vertailuja ja vaihtoja n kohteen luettelon lajittelemiseksi.
Siten lisäyslajittelu on vakaa lajittelualgoritmi.
Miksi lisäyslajittelu on vakaa?
Lisäyslajittelu on vakaa, koska se säilyttää yhtäläisten elementtien järjestyksen syöttötaulukossa.
Tämä on tärkeää monissa sovelluksissa, kuten tiedonhaussa tai talousanalyysissä. Jos meillä on esimerkiksi kaksi numerolistaa ja haluamme verrata niitä, meidän on varmistettava, että elementtien järjestys säilyy.
Jos luetteloita ei ole lajiteltu, emme vertaa niitä tarkasti.





Jätä vastaus